|
Опрос
|
реклама
Быстрый переход
Трещины на дорогах будут затягиваться сами собой: ИИ помог создать асфальт со способностью к регенерации
03.02.2025 [13:57],
Владимир Мироненко
Исследователи из Королевского колледжа Лондона и Университета Суонси (Уэльс, Великобритания) в сотрудничестве с учеными из Чили, а также Google Cloud разработали новый тип асфальта, который способен со временем самостоятельно «заживлять» образовавшиеся трещины, устраняя необходимость в использовании ручного труда для их ремонта, сообщается в блоге Google. 
Источник изображения: Google Причины образования трещин в асфальте пока не изучены полностью, но одной из частых причин является чрезмерное затвердевание в связи с окислением битума, который входит в состав асфальта. Ученые занимаются разработкой способов обратить этот процесс вспять, чтобы привести асфальт в прежнее рабочее состояние. Для изучения органических молекул веществ со сложным химическим составом, таких как битум, команда учёных использовала машинное обучение. Была разработана новая модель на основе собранных данных для ускорения атомистического моделирования, что позволило значительно продвинуться в исследовании процессов окисления битума и образования трещин. Этот подход значительно быстрее и экономичнее традиционных вычислительных моделей, отмечено в блоге Google. В сотрудничестве с Google Cloud учёные работали над созданием инструментов ИИ, которые позволяют определять химические свойства и создавать виртуальные молекулы, предназначенные для определенных целей, аналогично методам, используемым при открытии лекарств. Эксперт по вычислительной химии, доктор Франциско Мартин-Мартинес (Francisco Martin-Martinez) отметил значительный вклад Google Cloud в создание инструментов ИИ для быстрой разработки самовосстанавливающихся дорожных покрытий, подчеркнув, что подражание природе в её способности к самовосстановлению позволит продлить срок службы дорог и создать более устойчивую и надёжную дорожную инфраструктуру. Исследователи продемонстрировали в лабораторных экспериментах, как новый асфальтовый материал может залечить микротрещину менее чем за час. Чтобы получить битум со способностью к устранению трещин, исследователи добавили в него крошечные пористые споры растений, пропитанные переработанными маслами. Когда дорожное покрытие сжимается при движении транспорта, споры выдавливаются, и масло попадает в близлежащие трещины, размягчая битум настолько, что он может заполнять трещины. Исследователи полагают, что через пару лет они выйдут на этап коммерческого выпуска нового материала для использования на дорогах Великобритании. Китайская ИИ-модель Kimi k1.5 освоила мультимодальные рассуждения и превзошла OpenAI o1
30.01.2025 [19:29],
Сергей Сурабекянц
Если 2024 год стал годом клонов ChatGPT, то 2025 год обещает стать эрой рассуждающих моделей ИИ, а лидерство в этой области захватывают китайские лаборатории. На прошлой неделе много шума наделала DeepSeek со своей рассуждающей моделью R1. А на днях Moonshot AI представила мультимодальную Kimi k1.5, которая обгоняет в тестах OpenAI o1, а стоит в разы меньше. Эти модели представляют собой смену представления о «мыслительном процессе» ИИ. 
Источник изображения: kimi.ai Новые модели далеко ушли от банального пересказа Википедии. Им по силам сложные проблемы — от решения головоломок до объяснения квантовой физики. А Kimi k1.5 уже успела заработать звание «первого настоящего конкурента o1». По оценкам экспертов, Kimi k1.5 — это не просто ещё одна модель ИИ — это скачок вперёд в мультимодальном рассуждении и обучении с подкреплением. Kimi k1.5 от Moonshot AI объединяет текст, код и визуальные данные для решения сложных задач, порою в разы превосходя таких лидеров отрасли, как GPT-4o и Claude Sonnet 3.5 в ключевых тестах. Контекстное окно Kimi k1.5 на 128 тыс. токенов позволяет модели «за один подход» обрабатывать объём информации, эквивалентный солидному роману. В математических задачах модель может планировать, отражать и корректировать свои шаги на протяжении сотен токенов, имитируя решение проблемы человеком. Вместо того, чтобы повторно генерировать полные ответы, Kimi использует фрагменты предыдущих траекторий, повышая эффективность и сокращая затраты на обучение. 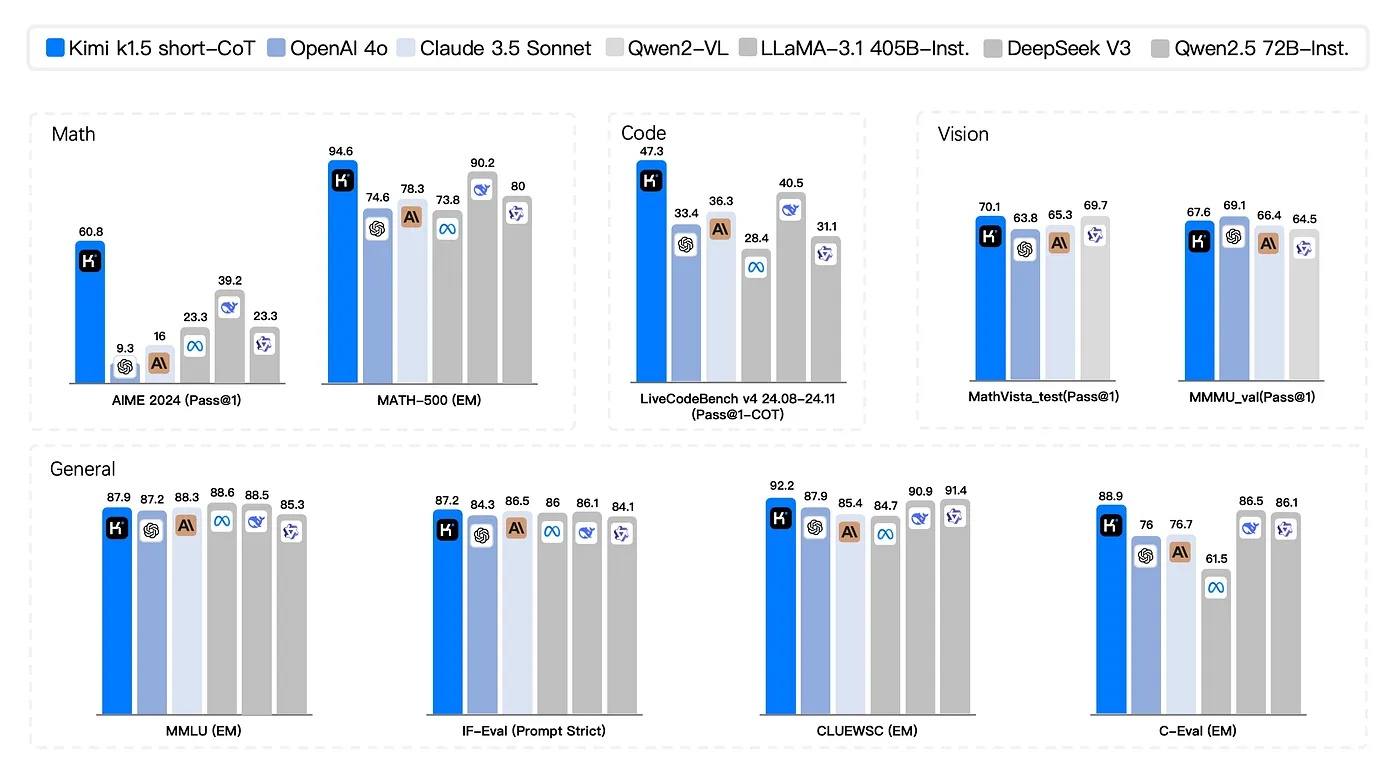
Источник изображений: medium.com Традиционный подход, основанный на принципах обучения с подкреплением, предполагает использование сложных инструментов, таких как поиск по дереву Монте-Карло или сети ценностей. Команда Moonshot AI отказалась от них и создала упрощённый фреймворк на базе обучения с подкреплением, используя штраф за длину и баланс между исследованием и эксплуатацией. В результате разработчикам удалось создать модель, которая обучается быстрее и избегает «чрезмерного обдумывания» — распространённой ошибки, когда ИИ тратит вычислительные ресурсы на ненужные шаги. Kimi k1.5 успела показать себя как мощный инструмент визуализации и одновременной работы с текстом. Модель умеет анализировать диаграммы, решать геометрические задачи и отлаживать код — в тесте MathVista модель показала точность 74,9 %, объединив текстовые подсказки с графическими диаграммами. 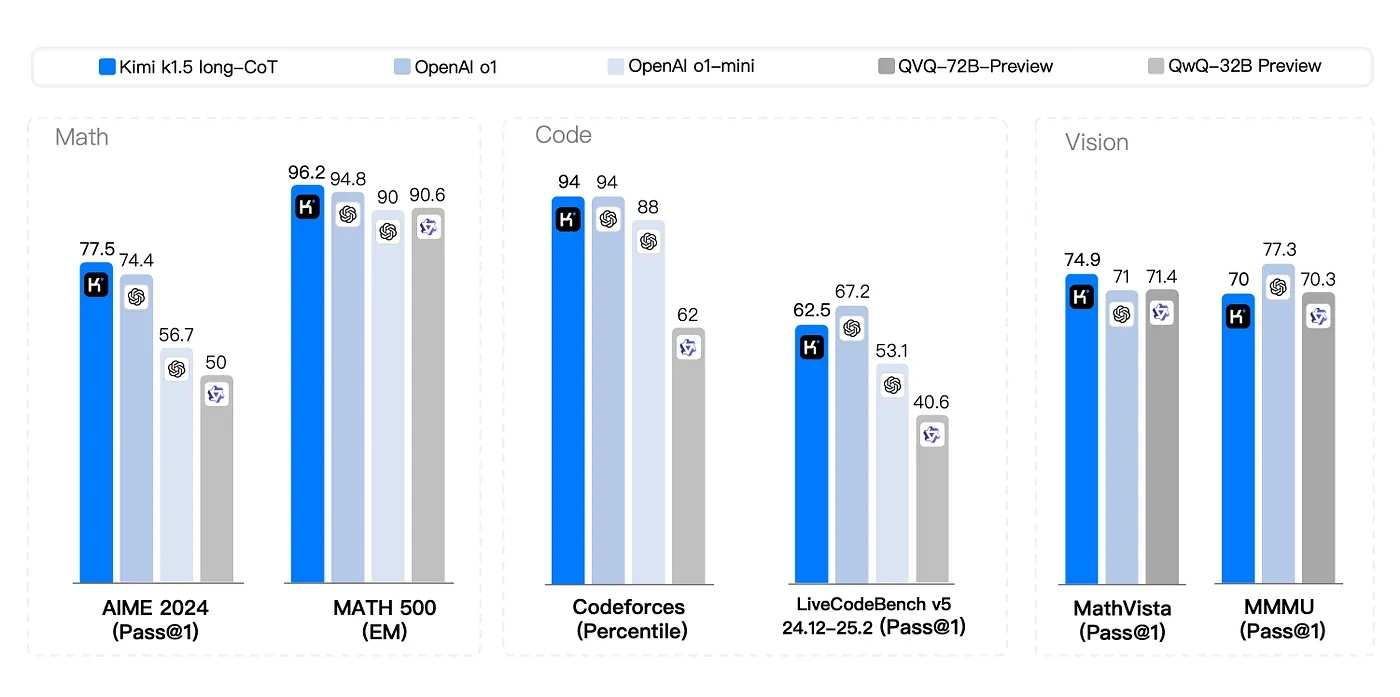 Исследователи Moonshot AI, вместо того чтобы полагаться на мощные, но медленные длинноцепочечные рассуждения (Long-CoT), использовали метод Long2Short («длинные-в-короткие»), добившись более лаконичных и быстрых ответов. Для этого применялись следующие методы:
Даже при прямом сравнении Kimi K1.5 оставляет GPT-4o и Claude Sonnet 3.5 далеко позади. Разработчикам Moonshot AI удалось оптимизировать процесс обучения с подкреплением благодаря:
По мнению экспертов, Kimi K1.5 — это не просто технологический прорыв, а взгляд в будущее ИИ. Объединяя обучение с подкреплением с мультимодальным рассуждением, эта модель решает задачи быстрее, умнее и эффективнее. Nvidia научит старые видеокарты GeForce повышать FPS с помощью ИИ, но потом
20.01.2025 [17:56],
Николай Хижняк
В интервью Digital Foundry Брайан Катандзаро (Bryan Catanzaro), вице-президент по исследованиям в области прикладного глубокого обучения в Nvidia сообщил, что не исключает возможности в будущем внедрения функции генерации кадров силами ИИ для повышения FPS, ставшей частью технологии DLSS, в старые видеокарты Nvidia GeForce. 
Источник изображений: Digital Foundry / Nvidia С момента своего дебюта в 2018 году технология масштабирования с глубоким обучением (DLSS) от Nvidia эволюционировала уже до четвёртой версии. Её последняя итерация перешла на ИИ-модель типа трансформер, что позволило реализовать ряд новых функций, включая мультикадровую генерацию (Multi Frame Generation, MFG). Последняя позволяет создавать до трёх дополнительных кадров на каждый традиционно отрисованный кадр для повышения FPS.  Nvidia смогла реализовать некоторые новые технологии, включая реконструкцию лучей (DLSS Ray Reconstruction), супер-разрешение (Super Resolution) и технологию сглаживания, опирающуюся на искусственный интеллект (Deep Learning Anti-Aliasing, DLAA) на всех видеокартах GeForce RTX, начиная с 20-й серии. Однако генератор кадров (Frame Generation) первого поколения, изначально представленный как эксклюзивная функция видеокарт GeForce RTX 40-й серии, не поддерживается моделями GeForce RTX 30-й и RTX 20-й серий. Новый мультикадровый генератор так и вовсе изначально заявлен только для новейших GeForce RTX 5000. В разговоре с журналистами Брайан Катандзаро отметил, что не исключает появления функции генерации кадров у старых моделей видеокарт Nvidia. «Я думаю, что ключевым здесь является вопрос проектирования и оптимизации, а также конечного пользовательского опыта. Мы запускаем этот генератор кадров, лучший генератор кадров, коим является технология Multi Frame Generation, с видеокартами 50-й серии. А в будущем посмотрим, сможем ли что-то выжать для старого поколения оборудования», — прокомментировал представитель Nvidia. 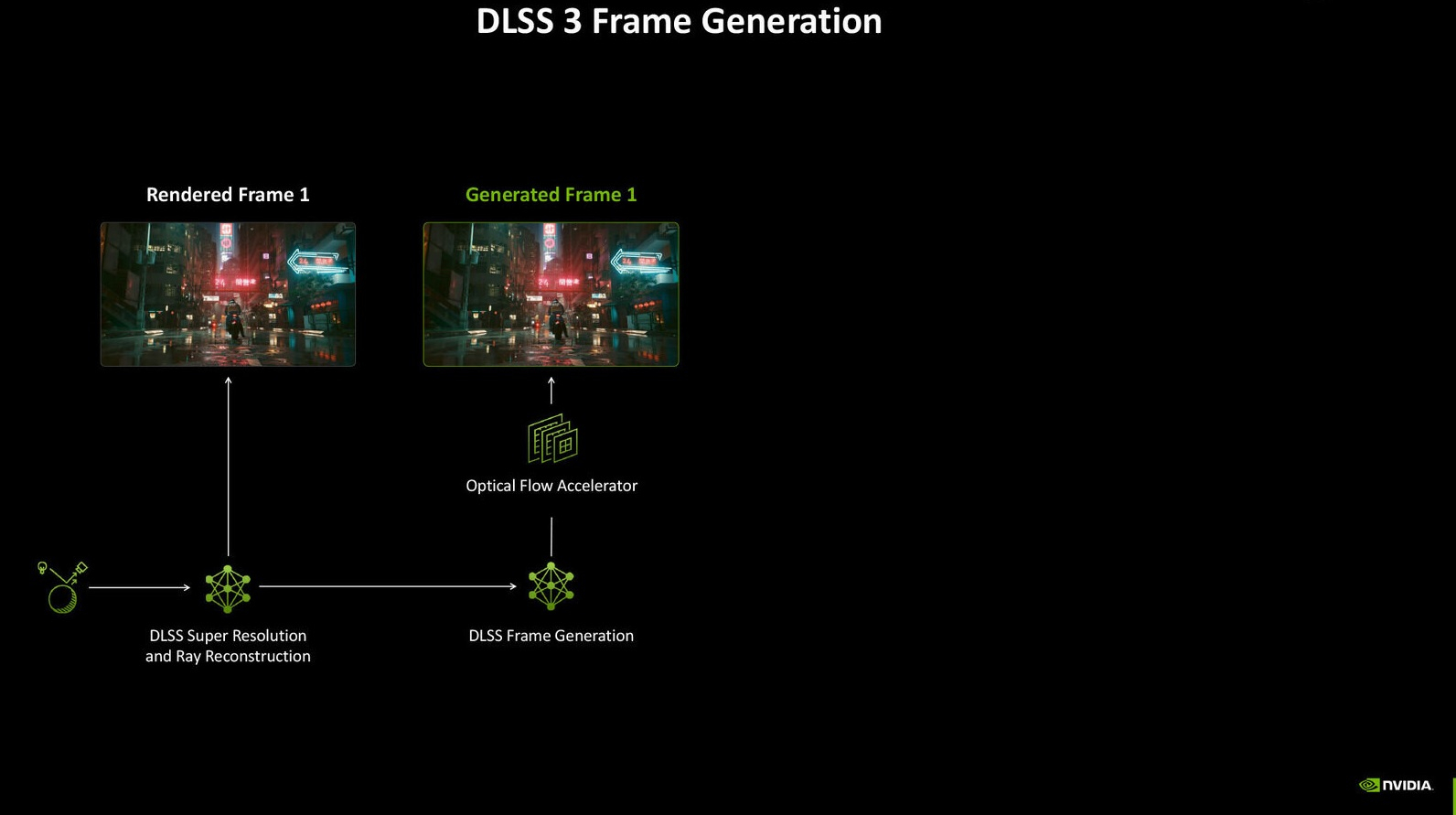 На фоне заявления Катандзаро можно предположить, что первая версия генератора кадров может в перспективе появиться на видеокартах GeForce RTX 30-й серии. Однако маловероятно, что она появится у моделей GeForce RTX 20-й серии. При этом, скорее всего, мультикадровый генератор кадров останется эксклюзивом видеокарт RTX 50-й серии, поскольку для его работы требуется значительно больше вычислительной мощности, заточенной под ИИ, которую у этих карт обеспечивают новые тензорные ядра. Один из ведущих разработчиков Nvidia также поделился некоторой информацией о разработке DLSS. «Когда мы создавали Nvidia DLSS 3 Frame Generation, нам было абсолютно необходимо аппаратное ускорение для вычислений Optical Flow. Но у нас не было достаточного количества тензорных ядер и не было достаточно хорошего алгоритма Optical Flow. Мы не создавали алгоритм Optical Flow для работы в реальном времени на тензорных ядрах, который мог бы вписаться в наш запас вычислительной мощности. У нас был аппаратный ускоритель Optical Flow, который Nvidia создавала годами как эволюцию нашей технологии видеокодирования. Он также был частью нашей технологии ускорения работы компьютерного зрения для беспилотных автомобилей. Казалось бы, для нас имело смысл использовать его и для Nvidia DLSS 3 Frame Generation. Но сложность в любой аппаратной реализации алгоритма типа Optical Flow заключается в том, что его действительно трудно улучшить. Он такой, какой он есть, и те сбои, которые возникли из-за этого аппаратного Optical Flow, мы не могли исправить с помощью более умной нейронной сети, пока не решили просто заменить его и перейти на решение, полностью основанное на ИИ. Именно это мы и сделали для Frame Generation в DLSS 4». Сильный ИИ не станет спасением для человечества — придётся ждать сверхинтеллект, считает глава OpenAI
05.12.2024 [00:02],
Николай Хижняк
Около двух лет назад OpenAI заявила, что искусственный интеллект общего назначения (Artificial General Intelligence, AGI), который также называнию сильным ИИ или ИИ уровня человека, «может возвысить человечество» и «предоставить всем невероятные новые возможности». Теперь же генеральный директор OpenAI Сэм Альтман (Sam Altman) пытается снизить градус ожидания от появления AGI. 
Источник изображения: OpenAI Forum «Я предполагаю, что мы достигнем AGI раньше, чем думает большинство людей в мире, и это будет иметь гораздо меньшее значение. И многие опасения по поводу безопасности, о которых говорили мы и другие стороны, на самом деле не возникнут в момент создания AGI. AGI можно создать. Мир после этого будет в основном развивается примерно так же, как и сейчас. Некоторые вещи начнут выполняться быстрее. Но переход от того, что мы называем AGI, до того, что мы называем сверхинтеллектом — это очень долгая дорога», — сказал Альтман во время интервью на саммите The New York Times DealBook в среду. Альтман уже не первый раз преуменьшает значимость, казалось бы, теперь точно неизбежного создания искусственного интеллекта общего назначения, о котором когда-то говорилось в уставе самой компании OpenAI, и который, как она же заявляла, сможет «автоматизировать большую часть интеллектуального труда» человечества. Недавно глава OpenAI намекнул, что это может произойти уже в 2025 году и будет достижимо с помощью актуального специализированного программного и аппаратного обеспечения. Ходят слухи, что OpenAI просто объединит все свои большие языковые модели и назовёт это AGI. Последующее заявление Альтмана об AGI прозвучало так, как будто OpenAI больше не рассматривает создание искусственного интеллекта общего назначения как нечто грандиозное, что способно решить все проблемы человечества: «Мне кажется, что экономические трудности в мире будут продолжаться немного дольше времени, чем думают люди, потому что в обществе много инерции. Поэтому в первые пару лет [после создания AGI], возможно, будет не так много изменений. А потом, возможно, последует много изменений». Те надежды и возможные достижения, которые OpenAI ранее приписывала AGI, компания теперь возлагает на так называемый «сверхинтеллект», который как недавно спрогнозировал Альтман, может появиться «через несколько тысяч дней». Искусственный интеллект научили разоблачать учёных-шарлатанов
27.11.2024 [18:56],
Геннадий Детинич
Научный поиск вскоре может претерпеть коренные изменения — искусственный интеллект показал себя в качестве непревзойдённого человеком инструмента для анализа невообразимых объёмов специальной литературы. В поставленном эксперименте ИИ смог точнее людей-экспертов дать оценку фейковым и настоящим научным открытиям. Это облегчит людям научный поиск, позволив машинам просеивать тонны сырой информации в поисках перспективных направлений. 
Источник изображения: ИИ-генерация Кандинский 3.1/3DNews С самого начала разработчики генеративных ИИ (ChatGPT и прочих) сосредоточились на возможности больших языковых моделей (LLM) отвечать на вопросы, обобщая обширные данные, на которых они обучались. Учёные из Университетского колледжа Лондона (UCL) поставили перед собой другую цель. Они задались вопросом, могут ли LLM синтезировать знания — извлекать закономерности из научной литературы и использовать их для анализа новых научных работ? Как показал опыт, ИИ удалось превзойти людей в точности выдачи оценок рецензируемым работам. «Научный прогресс часто основывается на методе проб и ошибок, но каждый тщательный эксперимент требует времени и ресурсов. Даже самые опытные исследователи могут упускать из виду важные выводы из литературы. Наша работа исследует, могут ли LLM выявлять закономерности в обширных научных текстах и прогнозировать результаты экспериментов», — поясняют авторы работы. Нетрудно представить, что привлечение ИИ к рецензированию далеко выйдет за пределы простого поиска знаний. Это может оказаться прорывом во всех областях науки, экономя учёным время и деньги. Эксперимент был поставлен на анализе пакета научных работ по нейробиологии, но может быть распространён на любые области науки. Исследователи подготовили множество пар рефератов, состоящих из одной настоящей научной работы и одной фейковой — содержащей правдоподобные, но неверные результаты и выводы. Пары документов были проанализированы 15 LLM общего назначения и 117 экспертами по неврологии человека, прошедшими специальный отбор. Все они должны были отделить настоящие работы от поддельных. Все LLM превзошли нейробиологов: точность ИИ в среднем составила 81 %, а точность людей — 63 %. В случае анализа работ лучшими среди экспертов-людей точность повышалась до 66 %, но даже близко не подбиралась к точности ИИ. А когда LLM специально обучили на базе данных по нейробиологии, точность предсказания повысилась до 86 %. Исследователи говорят, что это открытие прокладывает путь к будущему, в котором эксперты-люди смогут сотрудничать с хорошо откалиброванными моделями. Проделанная работа также показывает, что большинство новых открытий вовсе не новые. ИИ отлично вскрывает эту особенность современной науки. Благодаря новому инструменту учёные, по крайней мере, будут знать, стоит ли заниматься выбранным направлением для исследования или проще поискать его результаты в интернете. Каждый пятый ПК теперь оснащён ИИ-ускорителем, но люди покупают их не из-за этого
15.11.2024 [00:30],
Николай Хижняк
Поставки настольных и мобильных компьютеров с ускорителями для приложений искусственного интеллекта достигли 13,2 млн единиц в третьем квартале 2024 года, что составляет 20 % от всех поставок ПК за указанный период, по подсчётам агентства Canalys. Во втором квартале объём поставок таких компьютеров составлял 8,8 млн единиц. 
Источник изображения: Microsoft Сразу стоит отметить, что к «ИИ-совместимым» персональным компьютерам аналитики Canalys относят все настольные и мобильные компьютеры, оснащённые специализированным ИИ-ускорителем NPU или «его аналогом». Таким образом к данной категории относятся не только системы на Copilot+PC на новейших чипах AMD, Intel и Qualcomm, но и Windows-компьютеры на чипах Intel и AMD прошлого поколения, а также все Apple Mac на процессорах M-серии. 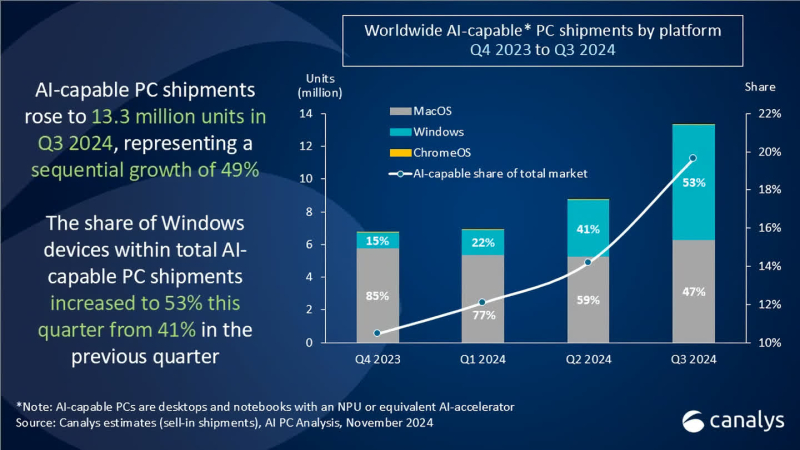
Источник изображения: Canalys Согласно свежему анализу Canalys, на системы с Windows пришлось более половины (53 %) поставок ПК с ИИ в третьем квартале, тогда как доля Apple снизилась до 47 %. Во втором квартале лидером являлась как раз компания Apple с 59 % поставок систем с поддержкой ИИ, тогда как на долю систем с Windows приходилось 41 % поставок. Несмотря на прогресс в развитии ПК с поддержкой ИИ производителям по-прежнему приходится убеждать покупателей в том, что покупка такой системы, а стоят они зачастую дороже, того стоит. Некоторые наблюдатели утверждают, что рост поставок таких компьютеров не обязательно связан с тем, что люди ищут именно ПК с ИИ. Просто многие современные системы изначально оснащены ИИ-ускорителем. 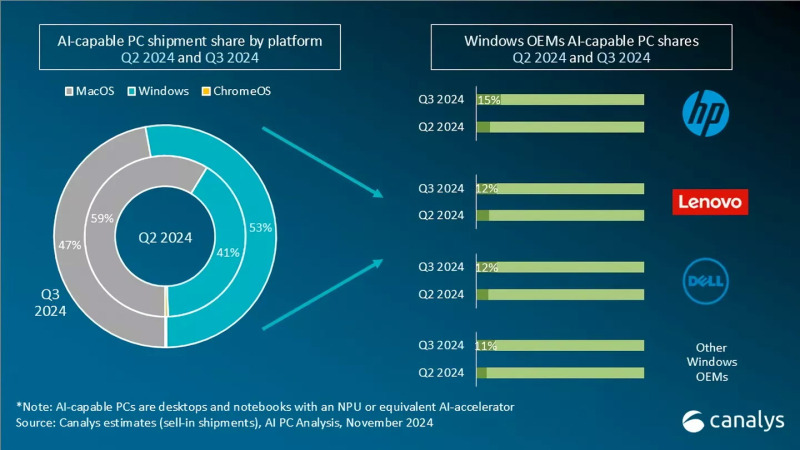
Источник изображения: Canalys Главный аналитик Canalys Ишан Датт (Ishan Dutt) рассказал, что проведённый в ноябре опрос компаний, занимающихся продажами компьютеров, показал, что 31 % не планирует продавать системы Copilot+PC в следующем году, а 34 % респондентов ожидают, что такие устройства составят менее десятой части от общего объёма продаж в 2025 году. Для получения заветного обозначения Copilot+PC компания Microsoft требует от производителей ПК, чтобы система оснащалась ИИ-движком (NPU), производительность которого составляет не менее 40 TOPS (триллионов операций в секунду). В любом случае поставки и продажи ИИ-совместимых ПК в ближайшие месяцы должны вырасти, поскольку до даты окончания поддержки Windows 10, не имеющей функции ИИ, осталось меньше года. По данным StatCounter, Windows 10 по-прежнему занимает более 60 % рынка настольных ПК на базе Windows во всём мире. С прекращением поддержки многие потребители перейдут на новые ПК с Windows 11 в 2025 году. Топ-8 курсов для роста в карьере
11.11.2024 [10:00],
3DNews Team
Делимся подборкой коротких курсов, чтобы быстро внедрить в работу новые знания и решать более сложные задачи. Они подойдут руководителям, HR-специалистам, продакт-менеджерам и другим специалистам. А ещё сейчас их можно купить со скидкой 20 %.  Навыки аргументации для руководителей 9 дней живой практики с наставниками, в которой студенты моделируют реальные рабочие ситуации и решают их. Вы освоите алгоритм, который поможет готовиться к важным встречам и аргументировать свою точку зрения. Курс подойдёт руководителям, менеджерам и всем, кто стремится к руководящей позиции. Юнит-экономика За 18 дней курс научит разбираться в экономике продукта и принимать прибыльные бизнес-решения. Подойдёт аналитикам, руководителям отделов, владельцам бизнеса, действующим и начинающим продакт-менеджерам. Инструменты начинающего руководителя За 1 месяц начинающие руководители смогут освоить эффективные фреймворки управления командой и почувствовать себя увереннее в работе. Вы научитесь ставить понятные и измеримые задачи, выстраивать коммуникацию, делегировать и контролировать выполнение задач, а также давать и получать обратную связь. Основы управления проектами 1,5 или 3 месяца обучения в зависимости от выбранного формата. Навыковый курс по запуску и реализации проектов для специалистов с опытом и тех, кто никогда раньше этого не делал. Вы научитесь работать над целями и потребностями заказчиков, ресурсами проекта и команды, а также управлять изменениями и рисками. В курс включены более 20 инструментов и методологий. Навыки критического мышления 2 месяца, за которые вы научитесь избегать логических ловушек и манипуляций, противостоять логическим уловкам, выявлять причинные связи и добывать недостающие данные, точно доносить мысль, находить аргументы, конструктивно критиковать и не только. Курс для продактов и проджектов, руководителей, разработчиков и других специалистов. Основы продакт-менеджмента За 3 месяца курс поможет освоить бизнес-подходы на примере В2В- и В2С-кейсов Яндекса. Вы научитесь всем основам продуктового подхода: как приоритизировать задачи, опираясь на прибыль, как использовать метрики и продуктовые фреймы, как проверять идеи на жизнеспособность и многому-многому другому. HR-аналитика За 3 месяца разовьёте аналитические навыки, которые помогут вам продвигаться в карьере. По данным hh.ru, медианная зарплата HR-специалиста с навыками в аналитике выше на 27%. Поэтому курс полезен специалистам разного уровня: начинающим HR-менеджерам и рекрутерам, HR BP и HR-дpженералистам. Управление командой За 4 месяца вы научитесь управлять большим потоком задач, повышать эффективность команды, сохранять авторитет, разрешать конфликты и внедрять изменения. Курс подходит текущим и будущим руководителям, предпринимателям и продактам. Чёрная пятница Начните любой курс Яндекс Практикума бесплатно: пройдите первую тему и получите скидку 20% на оплату обучения до 30 ноября. The Beatles номинированы на «Грэмми» с песней, восстановленной с помощью искусственного интеллекта
10.11.2024 [05:26],
Анжелла Марина
Легендарные The Beatles вновь номинированы на музыкальную премию «Грэмми» спустя более 50 лет после распада группы. Их последняя песня «Now and Then», отреставрированная в прошлом году с помощью искусственного интеллекта, претендует на звание «Запись года» наряду с песенными хитами Билли Айлиш (Billie Eilish) и Тейлор Свифт (Taylor Swift). 
Источник изображения: Now And Then / YouTube Песня «Now and Then» была выпущена в ноябре 2023 года, но её история началась ещё в конце 1970-х годов. Тогда Джон Леннон (John Lennon) записал демоверсию этой композиции не в студийных условиях. Позднее запись, вместе с другими треками «Free As A Bird» и «Real Love», была передана оставшимся участникам группы в 1990-х годах для включения в проект The Beatles Anthology. Однако «Now and Then» так и не была завершена из-за технических ограничений того времени, которые не позволяли качественно отделить вокал Джона Леннона от инструментального сопровождения. Изменить ситуацию удалось только в 2021 году, когда режиссёр Питер Джексон (Peter Jackson) и его команда, снимавшие документальный фильм о «Битлз», использовали технологию машинного обучения. Это позволило ныне живущим Полу Маккартни (Paul McCartney) и Ринго Старру (Ringo Starr) завершить работу над песней, отделив голос от фортепиано и создав полноценный трек с сопровождением музыкальных инструментов. «Теперь, благодаря ИИ, мы смогли вернуть эту песню к жизни», — отметил Маккартни. Несмотря на то, что «Now and Then» была закончена с использованием искусственного интеллекта, она соответствует правилам «Грэмми» в отношении ИИ. Правила гласят, что «только люди имеют право быть номинированными или выиграть премию Grammy, но работы, содержащие элементы ИИ, имеют право участвовать в соответствующих категориях». Церемония «Грэмми» состоится 2 февраля 2025 года, а песне The Beatles придётся конкурировать с современными хитами известных артистов. Как поддерживать мотивацию для учёбы и развития в профессии
06.11.2024 [10:00],
Владимир Мироненко
Специалисты, стремящиеся к профессиональному росту, постоянно учатся новому. Однако полагаться исключительно на силу воли в процессе учёбы может оказаться неэффективным. 
Источник изображения: «Яндекс Практикум» Важно понять, как работает мотивация, и создать благоприятные условия для достижения целей. Такой подход не только облегчит обучение, но и сделает его более продуктивным и осознанным, помогая сохранить интерес и энергию. Причины снижения мотивации
Как поддерживать мотивацию✅Напоминать себе о первоначальной цели. Для чего я решился на обучение, может ли оно изменить мою жизнь в лучшую сторону? Если ответ «да», сразу окажется, что усилия стоят того, чтобы их прикладывать. Следующим шагом будет — изменить инфраструктуру своей жизни, построить удобный график и интегрировать в него обучение. ✅Делегировать другие обязанности. Чтобы интегрировать в график учёбу, иногда стоит делегировать какие-то другие дела. Например, попросить супруга забирать детей из садика, а освободившееся время уделить обучению. ✅Быть готовым отложить какие-то дела на короткое время. Иногда — например, во время сдачи учебного проекта — приходится уделять учёбе больше времени. В такое время, скорее всего, придётся откладывать встречи с друзьями или отказываться от развлечений в пользу обучения. ✅Отказаться от иллюзии, что учиться можно «между делом». Бывает, что мы откладываем выполнение домашнего задания, прохождение учебного тренажёра и т. д. на то время, когда будем ехать в метро на работу, на обеденный перерыв или какой-то другой небольшой промежуток времени. Микролёрнинг — вещь хорошая, но всегда есть риск, что человек не успеет достаточно погрузиться в материал, и учёба не принесёт желаемых результатов. В «Яндекс Практикуме» вы не останетесь один на один с учёбой: вас поддержат куратор, наставник, ревьюер, сообщество сокурсников. Ваша цель — наша цель. Если вы хотите найти новую работу или повысить уровень компетенций, мы вам в этом поможем. Учёные MIT подсмотрели у больших языковых моделей ИИ эффективный метод обучения роботов
03.11.2024 [12:22],
Владимир Фетисов
Исследователи из Массачусетского технологического института (MIT) разработали собственный метод обучения роботов новым навыкам. Вместо стандартного набора сфокусированных данных, которые обычно используются при обучении роботов, они задействовали большие массивы данных, тем самым имитируя процесс обучения больших языковых моделей (LLM). 
Источник изображения: MIT По мнению исследователей из MIT, имитационное обучение, когда робот учится на действиях человека, выполняющего ту или иную задачу, может оказаться неэффективным при несущественном изменение окружающей обстановки. К примеру, у робота могут возникнуть трудности после обучения, если он попадёт в обстановку с другим освещением или предметами. В своей работе исследователи задействовали разные LLM, такие как GPT-4, чтобы повысить качество обучения методом перебора данных. «В области языковых моделей все данные — это просто предложения. В робототехнике, учитывая всю неоднородность данных, если вы хотите проводить предварительное обучение аналогичным образом, то потребуется другая архитектура», — рассказал один из авторов исследования Лируй Ванг (Lirui Wang). Исследователи разработали новую архитектуру под названием Heterogeneous Pretrained Transformers (HPT), которая объединяет информацию, получаемую от разных датчиков и из разных сред. Собираемые таким образом данные объединяются в обучаемые модели с помощью «трансформера». Конечному пользователю нужно лишь указать дизайн робота, его конфигурацию и навык, которому он должен обучиться. «Мы мечтаем о создании универсального мозга робота, который можно было бы загрузить и использовать в своём роботе без какого-либо обучения. Пока мы находимся на ранних стадиях, но мы собираемся продолжать упорно работать и надеемся, что масштабирование приведёт к прорыву в робототехнике, как это было с большими языковыми моделями», — рассказал один из авторов исследования Дэвид Хелд (David Held). Google представила Learn About — инструмент интерактивного обучения на базе искусственного интеллекта
02.11.2024 [17:48],
Владимир Фетисов
Компания Google без лишнего шума представила новый образовательный сервис на основе искусственного интеллекта под названием Learn About, анонс которого состоялся на прошедшей в мае конференции Google I/O. Сервис призван изменить подход к обучению чему-либо, превращая этот процесс в увлекательный диалог вместо стандартного чтения текста и просмотра сопутствующих изображений. 
Источник изображения: maginative.com Инструмент Learn About ориентирован на людей, которые регулярно используют поисковые системы для изучения чего-то нового. Однако в данном случае на смену традиционным методам обучения, в которых информация преподносится статично в процессе чтения текста и просмотра изображений, приходит метод, предлагающий персонализированное интерактивное обучение. В некотором смысле новый сервис можно назвать своеобразным виртуальным репетиром, которому можно задавать вопросы или предоставлять собственные материалы. Возможно изучение специально подобранных тем широкого спектра, начиная от повседневных вопросов и заканчивая сложными академическими предметами. Алгоритмы на базе нейросетей генерируют контент, который поможет разобраться в теме, связать основные понятия, углубить понимание вопроса. Learn About объединяется традиционный обучающий контент, такой как видео, статьи и изображения, с возможностями искусственного интеллекта, и позиционируется Google как новый вид цифрового помощника по обучению. Learn About обладает большим потенциалом, но Google даёт понять, что на данном этапе это всё ещё эксперимент, поскольку сервис может предоставлять неточную или вводящую в заблуждение информацию. Пользователям рекомендуется проверять факты и оставлять отзывы по итогам взаимодействия с сервисом. Отмечается, что на данный момент Learn About не сохраняет данные о взаимодействии с пользователями, история чата исчезнет, как только будет закрыта веб-страница. «Больше, чем у кого-либо»: Цукерберг похвастался системой с более чем 100 тыс. Nvidia H100 — на ней обучается Llama 4
31.10.2024 [22:31],
Николай Хижняк
Среди американских IT-гигантов зародилась новая забава — соревнование, у кого больше кластеры и твёрже уверенность в превосходстве своих мощностей для обучения больших языковых моделей ИИ. Лишь недавно глава компании Tesla Илон Маск (Elon Musk) хвастался завершением сборки суперкомпьютера xAI Colossus со 100 тыс. ускорителей Nvidia H100 для обучения ИИ, как об использовании более 100 тыс. таких же ИИ-ускорителей сообщил глава Meta✴ Марк Цукерберг (Mark Zuckerberg). 
Источник изображения: CNET/YouTube Глава Meta✴ отметил, что упомянутая система используется для обучения большой языковой модели нового поколения Llama 4. Эта LLM обучается «на кластере, в котором используется больше 100 000 графических ИИ-процессоров H100, и это больше, чем что-либо, что я видел в отчётах о том, что делают другие», — заявил Цукерберг. Он не поделился деталями о том, что именно уже умеет делать Llama 4. Однако, как пишет издание Wired со ссылкой на заявление главы Meta✴, их ИИ-модель обрела «новые модальности», «стала сильнее в рассуждениях» и «значительно быстрее». Этим комментарием Цукерберг явно хотел уколоть Маска, который ранее заявлял, что в составе его суперкластера xAI Colossus для обучения ИИ-модели Grok используются 100 тыс. ускорителей Nvidia H100. Позже Маск заявил, что количество ускорителей в xAI Colossus в перспективе будет увеличено втрое. Meta✴ также ранее заявила, что планирует получить до конца текущего года ИИ-ускорители, эквивалентные более чем полумиллиону H100. Таким образом, у компании Цукерберга уже имеется значительное количество оборудования для обучения своих ИИ-моделей, и будет ещё больше. Meta✴ использует уникальный подход к распространению своих моделей Llama — она предоставляет их полностью бесплатно, позволяя другим исследователям, компаниям и организациям создавать на их базе новые продукты. Это отличает её от тех же GPT-4o от OpenAI и Gemini от Google, доступных только через API. Однако Meta✴ всё же накладывает некоторые ограничения на лицензию Llama, например, на коммерческое использование. Кроме того, компания не сообщает, как именно обучаются её модели. В остальном модели Llama имеют природу «открытого исходного кода». С учётом заявленного количества используемых ускорителей для обучения ИИ-моделей возникает вопрос — сколько электричества всё это требует? Один специализированный ускоритель может съедать до 3,7 МВт·ч энергии в год. Это означает, что 100 тыс. таких ускорителей будут потреблять как минимум 370 ГВт·ч электроэнергии — как отмечается, достаточно для того, чтобы обеспечить энергией свыше 34 млн среднестатистических американских домохозяйств. Каким образом компании добывают всю эту энергию? По признанию самого Цукерберга, со временем сфера ИИ столкнётся с ограничением доступных энергетических мощностей. Компания Илона Маска, например, использует несколько огромных мобильных генераторов для питания суперкластера из 100 тыс. ускорителей, расположенных в здании площадью более 7000 м2 в Мемфисе, штат Теннесси. Та же Google может не достичь своих целевых показателей по выбросам углерода, поскольку с 2019 года увеличила выбросы парниковых газов своими дата-центрами на 48 %. На этом фоне бывший генеральный директор Google даже предложил США отказаться от поставленных климатических целей, позволив компаниям, занимающимся ИИ, работать на полную мощность, а затем использовать разработанные технологии ИИ для решения климатического кризиса. Meta✴ увильнула от ответа на вопрос о том, как компании удалось запитать такой гигантский вычислительный кластер. Необходимость в обеспечении растущего объёма используемой энергии для ИИ вынудила те же технологические гиганты Amazon, Oracle, Microsoft и Google обратиться к атомной энергетике. Одни инвестируют в разработку малых ядерных реакторов, другие подписали контракты на перезапуск старых атомных электростанций для обеспечения растущих энергетических потребностей. Что читают DevOps-инженеры
30.10.2024 [10:00],
Владимир Мироненко
Рекомендации книг для начинающих и продолжающих DevOps-инженеров. Помогут понять базовые принципы и узнать о различных концепциях, без привязки к конкретным инструментам и без готовых решений. 
Источник изображения: «Яндекс Практикум» «Руководство по DevOps. Как добиться гибкости, надежности и безопасности мирового уровня в технологических компаниях» Ким, Дебуа, Уиллис, Хамбл Наиболее полное и исчерпывающее руководство по DevOps, написанное ведущими мировыми специалистами. Книга будет полезна абсолютно всем, кто прямо или косвенно связан с IT и управлением. «Site Reliability Engineering. Надёжность и безотказность как в Google» Бейер, Джоунс, Петофф, Мёрфи Систематизированный перечень подходов Google для обеспечения надёжности сервисов, где DevOps — лишь один из инструментов. Книга организована как сборник статей от разных авторов. Полезна всем, кто занимается организацией надёжности высоконагруженных сервисов. «Программирование инфраструктуры. Как создаются адаптивные облачные системы» Моррис В книге рассказывается, как эффективно использовать принципы, паттерны и практики DevOps, чтобы успешно обслуживать инфраструктуры облачного века. Будет полезна системным администраторам, разработчикам, архитекторам, тимлидам и DevOps-специалистам. «Безопасность контейнеров. Фундаментальный подход к защите контейнеризированных приложений» Райс В этой книге, предназначенной для специалистов-практиков, изучаются ключевые технологии, с помощью которых разработчики и специалисты по защите данных могут оценить риски для безопасности и выбрать подходящие решения. «Ускоряйся! Наука DevOps. Как создавать и масштабировать высокопроизводительные цифровые организации» Форсгрен, Хамбл, Ким Основу книги составляют исследования с использованием строгих статистических методов, включая данные, собранные из отчетов о состоянии DevOps. В этой книге представлены как результаты, так и научные подходы, которые стоят за этими исследованиями, чтобы вы могли применять всё это на практике. В «Яндекс Практикуме» есть курсы для тех, кто уже имеет опыт в разработке и хочет расширить свои компетенции и перейти на новый уровень. Практика с первого дня обучения, поддержка наставников и кураторов, обратная связь от экспертов, интерактивный учебник, возможность начать учиться бесплатно — переходите по ссылкам, чтобы узнать о всех преимуществах каждого курса. «Эксплуатация и разработка в Kubernetes» — за 3 месяца освоите и примените на практике технологии оркестрации контейнеров. Программу составляли инженеры и тимлиды, которые давно работают с Kubernetes. Благодаря этому, вы будете учиться только тому, что на самом деле пригодится в работе. Ближайший старт — 14 ноября. «Apache Kafka для разработки и архитектуры» — 3-месячный курс для тех, кто хочет влиять на масштабируемость и надёжность систем. С этой технологией вы будете работать с более сложными продуктами и сможете повысить грейд. Есть бесплатная вводная часть. Ближайший старт — 21 ноября. «Архитектура программного обеспечения» — за 6 месяцев освоите лучшие практики архитектуры и научитесь решать сложные архитектурные задачи. Есть бесплатная вводная часть. Ближайший старт — 24 октября, 28 ноября и 12 декабря. Бесплатно начните любой курс «Яндекс Практикума», пройдите первую тему и получите скидку 20 % на оплату обучения до 30 ноября. OSI ввела строгие стандарты открытости для Meta✴ Llama и других ИИ-моделей
29.10.2024 [07:19],
Дмитрий Федоров
Open Source Initiative (OSI), десятилетиями определяющая стандарты открытого программного обеспечения (ПО), ввела определение для понятия «открытый ИИ». Теперь, чтобы модель ИИ считалась действительно открытой, OSI требует предоставления доступа к данным, использованным для её обучения, полному исходному коду, а также ко всем параметрам и весам, определяющим её поведение. Эти новые условия могут существенно повлиять на технологическую индустрию, поскольку такие ИИ-модели, как Llama компании Meta✴ не соответствуют этим стандартам. 
Источник изображения: BrianPenny / Pixabay Неудивительно, что Meta✴ придерживается иной точки зрения, считая, что подход OSI не учитывает особенностей современных ИИ-систем. Представитель компании Фейт Айшен (Faith Eischen) подчеркнула, что Meta✴, хотя и поддерживает многие инициативы OSI, не согласна с предложенным определением, поскольку, по её словам, «единого стандарта для открытого ИИ не существует». Она также добавила, что Meta✴ продолжит работать с OSI и другими организациями, чтобы обеспечить «ответственное расширение доступа к ИИ» вне зависимости от формальных критериев. При этом Meta✴ подчёркивает, что её модель Llama ограничена в коммерческом применении в приложениях с аудиторией более 700 млн пользователей, что противоречит стандартам OSI, подразумевающим полную свободу её использования и модификации. Принципы OSI, определяющие стандарты открытого ПО, на протяжении 25 лет признаются сообществом разработчиков и активно им используются. Благодаря этим принципам разработчики могут свободно использовать чужие наработки, не опасаясь юридических претензий. Новое определение OSI для ИИ-моделей предполагает аналогичное применение принципов открытости, однако для техногигантов, таких как Meta✴, это может стать серьёзным вызовом. Недавно некоммерческая организация Linux Foundation также вступила в обсуждение, предложив свою трактовку «открытого ИИ», что подчёркивает возрастающую значимость данной темы для всей ИТ-индустрии. Исполнительный директор OSI Стефано Маффулли (Stefano Maffulli) отметил, что разработка нового определения «открытого ИИ» заняла два года и включала консультации с экспертами в области машинного обучения (ML) и обработки естественного языка (NLP), философами, представителями Creative Commons и другими специалистами. Этот процесс позволил OSI создать определение, которое может стать основой для борьбы с так называемым «open washing», когда компании заявляют о своей открытости, но фактически ограничивают возможности использования и модификации своих продуктов. Meta✴ объясняет своё нежелание раскрывать данные обучения ИИ вопросами безопасности, однако критики указывают на иные мотивы, среди которых минимизация юридических рисков и сохранение конкурентного преимущества. Многие ИИ-модели, вероятно, обучены на материалах, защищённых авторским правом. Так, весной The New York Times сообщила, что Meta✴ признала наличие такого контента в своих данных для обучения, поскольку его фильтрация практически невозможна. В то время как Meta✴ и другие компании, включая OpenAI и Perplexity, сталкиваются с судебными исками за возможное нарушение авторских прав, ИИ-модель Stable Diffusion остаётся одним из немногих примеров открытого доступа к данным обучения ИИ. Маффулли видит в действиях Meta✴ параллели с позицией Microsoft 1990-х годов, когда та рассматривала открытое ПО как угрозу своему бизнесу. Meta✴, по словам Маффулли, подчёркивает объём своих инвестиций в модель Llama, предполагая, что такие ресурсоёмкие разработки по силам немногим. Использование Meta✴ данных обучения в закрытом формате, по мнению Маффулли, стало своего рода «секретным ингредиентом», который позволяет корпорации удерживать конкурентное преимущество и защищать свою интеллектуальную собственность. Начните сегодня или когда угодно: бесплатные курсы для IT-специалистов
23.10.2024 [10:00],
Владимир Мироненко
Собрали курсы для специалистов с опытом, которые можно пройти в любое удобное время в своём темпе. Курсы охватывают разные темы: от облачных сервисов и алгоритмов до основ Go и навыков наставничества. 
Источник изображения: «Яндекс Практикум» «Инженер облачных сервисов» — научитесь использовать облачные сервисы и познакомитесь с возможностями платформы Yandex Cloud. Курс для системных администраторов, разработчиков и инженеров данных, а также всех, кто интересуется облачными технологиями. Программа рассчитана примерно на 70 часов. Вы выполните 60 практических работ в своём облаке в Yandex Cloud и сможете получить сертификат о прохождении курса. «Подготовка к алгоритмическому собеседованию» — узнаете, как проходят алгоритмические собеседования и как к ним подготовиться. Курс для разработчиков, которые ещё не изучали алгоритмы, и для тех, кто хочет оценить уровень своей подготовки к алгоритмическому интервью. Для изучения теоретического материала понадобится 10 часов. Время прохождения практики зависит от вашей подготовки. «Основы Go» — обучитесь основам Go на реальном коде и задачах, получите навыки тестирования и исправления ошибок. Курс для тех, у кого есть опыт в программировании на других языках. Программа рассчитана примерно на 30 часов. «Наставник в IT» — за 4 часа узнаете, как давать обратную связь, мотивировать команду и решать конфликты. Курс для тимлидов (настоящих и будущих), а также менеджеров и всех тех, кто хочет лучше работать с командой. Практикум знает, как сделать учебу интересной. Для этого у нас над курсами работает большая команда, авторы и методисты, которые знают, где лучше поставить теорию на паузу и попробовать применить знания на практике. Бесплатно начните любой курс Яндекс Практикума, пройдите первую тему и получите скидку 20% на оплату обучения до 30 ноября. Мы снизили цену, но оставили в курсах всё то, что помогает добиваться цели, какой бы она ни была: Вебинары и живые лекции Чтобы вы не оставались с теорией один на один. Практика на реальных задачах Во время которой вы соберёте портфолио и подготовитесь к будущей работе. Поддержка YaGPT и наставников Команда сопровождения поможет не сдаться на полпути, а технологии Яндекса упростят учёбу. Помощь с трудоустройством Если в целях была новая работа, то мы поможем добиться желаемого. А ещё скидку можно применить на курсы английского — для этого вам нужно просто записаться на консультацию. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2025 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews. kz
![]()
![]()








 MWC 2018
MWC 2018 2018
2018 Computex
Computex