|
Опрос
|
реклама
Быстрый переход
Быть в тренде: два полезных курса, которые помогут с нуля освоить навыки 1С-разработки и аналитики
03.10.2024 [10:00],
Андрей Крупин
Последние несколько лет спрос на специалистов по 1С на российском рынке остаётся стабильно высоким, даже на стажёров. Это обусловлено тем, что всё больше организаций переходят на отечественную платформу автоматизации бизнеса «1С:Предприятие», отказываясь от западных аналогов из-за санкций и реализуя поддерживаемые государством программы импортозамещения ПО. 
«1С:Предприятие» — один из самых популярных в России и СНГ программных комплексов для автоматизации процессов документооборота, ведения бухгалтерского учёта, управления предприятиями различных сфер деятельности и решения прочих задач в корпоративной среде О востребованности экспертов по 1С говорит рост количества вакансий и предлагаемых зарплат — только на площадке hh.ru насчитывается свыше 11 тысяч для разработчиков. При этом предложения по заработной плате варьируются в зависимости от региона РФ и стартуют с 50 тысяч рублей для начинающих специалистов и с 200 тысяч рублей для профессионалов с опытом работы (согласно данным сервиса «Хабр Карьера»). По данным банка «Точка», за последние два года медианные зарплаты в IT-сегменте выросли на 15 %, и больше всего повысились зарплаты разработчиков 1С — на 46 % относительно 2022 года. Однако вместе с зарплатами растут и требования — для входа в профессию нужны опыт и знания. Одним из вариантов освоить новую профессию могут стать онлайн-курсы. У Яндекс Практикума есть курсы «Разработчик 1C» и «1С‑аналитик». Они ориентированы на тех, кто только начинает свой путь в новой профессии, а также может подойти тем, кто уже начал свой путь в 1С-разработке или аналитике самостоятельно. Для обучения главное — иметь компьютер и достаточно времени для занятий. Первый курс — «Разработчик 1C» — позволяет за 6 месяцев освоить с нуля 1С — один из самых востребованных языков программирования, в котором можно писать код как на английском, так и на русском. Авторы курса — эксперты по 1С из Яндекса и других крупных компаний с опытом 10+ лет. Курс совмещает наглядную теорию с непрерывной практикой и позволяет научиться создавать информационные системы на базе 1С, программировать в среде «1С:Предприятие», разрабатывать собственные конфигурации на платформе 1С, интегрировать 1С со сторонними сервисами, разрабатывать мобильные версии приложений на базе 1С, поддерживать работоспособность готовых информационных систем и решать прочие, отвечающие требованиям рынка и заказчиков задачи. Программа курса одобрена учебным центром 1С и соответствует современным технологиям разработки на 1С. По завершении обучения выпускник получит диплом о профессиональной переподготовке и свидетельство от учебного центра 1С. Также Практикум поможет с трудоустройством: в карьерном центре расскажут, как оформить резюме и портфолио, а также как откликаться на вакансии. 
Курс «Разработчик 1C» Продолжительность второго курса — «1С‑аналитик» — составляет 8 месяцев. За это время студенты научатся анализировать и моделировать бизнес-процессы, а также описывать их с помощью нотаций, взаимодействовать с 1С‑программистами: ставить задачи и контролировать их выполнение, выбирать инструменты и методы интеграции 1С, подбирать оптимальные конфигурации 1С и писать документацию. Студент успеет сделать девять практических работ и четыре проекта для портфолио. На всех этапах обучения студентов ждёт поддержка команды сопровождения, наставники — опытные специалисты — проводят вебинары и отвечают на сложные вопросы по теории и практике; ревьюеры проверяют домашние работы и проекта, а кураторы помогают не потеряться в учебном процессе. Учёбе потребуется уделять от 15 часов в неделю. Заниматься можно в любое время, главное — вовремя сдавать проекты на проверку. 
Курс «1С‑аналитик» Практикум использует технологии для помощи в обучении, поэтому студенты могут пользоваться YandexGPT, чтобы получить быстрый ответ на вопрос или сделать конспект урока. У обоих курсов есть бесплатные части на 2 и 6 часов, которые помогут погрузиться в профессию и понять, подходит ли такой формат обучения и стоит ли развиваться в выбранном направлении. Если решите продолжить, необязательно оплачивать курс целиком — можно частями или в кредит. Желаем успеха в освоении новых специальностей! Крупнейшие сайты интернета запретили Apple собирать их данные для обучения ИИ
29.08.2024 [18:19],
Павел Котов
Одним из источников данных для обучения систем генеративного искусственного интеллекта являются общедоступные веб-ресурсы. Apple предоставила их владельцам возможность отказаться от сбора данных для обучения системы Apple Intelligence, и многие из крупнейших ресурсов этой возможностью воспользовались. Среди них значатся Facebook✴ и Instagram✴, а также крупные новостные и медийные ресурсы, включая New York Times и The Atlantic.  В течение последних лет Apple применяла веб-сканер под названием AppleBot — собранные им данные использовались для обучения Siri и поисковой машины Spotlight. А совсем недавно компания подключила к AppleBot и Apple Intelligence. Это спорная практика, поскольку современный ИИ вольно обходится с защищёнными авторским правом материалами — в узких областях, где материалов вообще не так много, системы почти без изменений цитируют целые абзацы. Apple уверяет, что производит сбор информации с учётом этических норм, отсеивая персональные данные, пользуясь только лицензированными материалами и общедоступными данными, которые поступают от сканера AppleBot. Чтобы дать веб-мастерам возможность отказаться от сбора информации только для обучения ИИ, компания использовала псевдоним Applebot-Extended — стандартная поисковая индексация при запрете этого псевдонима остаётся. Отказ осуществляется внесением соответствующей директивы в общедоступный на веб-ресурсах файл robots.txt, а значит, у любого желающего есть возможность увидеть, кто из издателей заблокировал к себе доступ Apple Intelligence. Это сделали Facebook✴, Instagram✴, Craigslist, Tumblr, New York Times, Financial Times, The Atlantic, Vox Media, сеть USA Today и Condé Nast, установил журнал Wired. Чуть более четверти крупных американских новостных сайтов (294 из 1167) отказались пускать к себе ИИ от Apple, уточнил журналист Бен Уэлш (Ben Welsh). По неподтверждённой информации, Apple заключила с некоторым медиакомпаниями сделки, заплатив им за право использовать их материалы для обучения ИИ. Вероятно, эти соображения сдерживают и остальные ресурсы — они просто ждут денег. Tesla ищет тех, кто готов ходить по полдня с 13-кг грузом за $48 в час — для обучения роботов Optimus
19.08.2024 [21:52],
Владимир Мироненко
В следующем году, как обещает гендиректор Tesla Илон Маск (Elon Musk), компания начнёт использовать человекоподобных роботов Optimus для внутренних операций с последующим запуском массового производства для поставок сторонним компаниям в 2026 году. В связи с этим в течение последнего года Tesla наняла десятки тренеров для обучения роботов, пишет TechSpot. 
Источник изображения: TechSpot Согласно разделу вакансий на сайте Tesla, работа оператора по сбору данных в подразделении компании в Пало-Альто подразумевает использование костюма для захвата движений и гарнитуры виртуальной реальности во время выполнения определённых движений. Также указано, что претенденты на вакансию должны быть в хорошей физической форме, поскольку обязанности тренера предполагают ходьбу более семи часов в день с переноской до 30 фунтов (13,6 кг). Рост претендента должен составлять 170–180 см, чтобы надеть костюм для захвата движения и комфортно работать в среде виртуальной реальности в течение длительного времени, что может вызывать у некоторых людей тошноту. По словам Маска, высота Optimus будет около 173 см, отсюда такие требования к росту. В числе требований к претендентам также указано умение стоять, сидеть, ходить, наклоняться, сгибаться, тянуться, приседать и поворачиваться в течение дня. Тренеры должны будут анализировать собираемую ими информацию и готовить отчёты. Работать они будут по гибкому графику днём/ночью с одним выходным и со сверхурочной работой при необходимости. Оплата составляет от $25 до $48 в час с выплатой премий и предоставлением льгот. По словам Маска, несколько роботов Optimus уже работают на заводе Tesla во Фримонте, где они занимаются переноской аккумуляторных ячеек и укладкой их в транспортные контейнеры. «Яндекс» ищет тренеров для обучения YandexGPT переводу текста с изображений, аудио- и видеофайлов
19.08.2024 [20:24],
Владимир Мироненко
Нейросеть YandexGPT научат распознавать и переводить текст с изображений, аудио- и видеофайлов, пишут «Ведомости» со ссылкой на описание вакансии AI-тренера, опубликованной на сайте компании «Яндекс». По словам источника ресурса, близкого к «Яндексу», предполагается нанять около десятка специалистов такого профиля. 
Источник изображения: geralt/Pixabay Как указано в описании вакансии, в обязанности тренера входит обучение генеративной модели, создавая собственные эталонные примеры, а также оценка качества перевода и обучение нейросети распознаванию и переводу текста с изображений и видео. В начале 2023 года «Яндекс» объявляла набор AI-тренеров для обучения моделей семейства YandexGPT, напомнил представитель компании. Но если тогда принимали на работу специалистов гуманитарного направления, умеющих работать с русскоязычными текстами, то сейчас речь идёт о специалистах, ориентирующихся в узкоспециализированных тематиках, чтобы точечно углубить знания ИИ-модели. Например, они должны разбираться в терминологии самых разных направлений — от физики до юриспруденции, сообщил представитель «Яндекса». Гендиректор Dbrain, автор Telegram-канала AI Happens Алексей Хахунов отметил, что в машинном обучении самыми важными критерии являются чистота и качество данных. По словам Хахунова, для обучения современных моделей нужны два типа специалистов: нейролингвисты, которые знают, как работают нейросети и могут создавать современные алгоритмы — в первую очередь машинных переводов, и специалисты, в совершенстве владеющие несколькими языками, что позволяет создавать пары между различными языками. При этом нужно делать не дословный перевод, а собирать семантически близкие виды переводов. «Одни и те же фразы по смыслу могут звучать по-разному на разных языках, и важно, чтобы переводчик опирался на глубокое понимание языка, а не на дословный перевод», — пояснил эксперт. С ним согласился эксперт Альянса искусственного интеллекта Андрей Комиссаров, по словам которого, проблема в том, что на большом количестве языков нейросети делают дословный перевод, поскольку не ощущают тонкостей языка и не могут работать с фразеологизмами. «В данном случае речь идёт о дообучении модели. Для этого необходимо чутье языка», — отметил он. Сейчас с переводом у нейросетей дела идут по-разному. «Если с английским языком машина более-менее справляется, то в случае с китайским, если перевести текст туда и обратно, он фактически превратится в бессвязный набор слов», — сообщил Комиссаров. У OpenAI почти готов революционный ИИ Strawberry — он умеет планировать и рассуждать
13.07.2024 [12:59],
Павел Котов
OpenAI разрабатывает систему искусственного интеллекта, в которой применяется новый подход — проект носит кодовое название Strawberry. Отличием новой модели является её способность рассуждать. Об этом сообщает Reuters со ссылкой на внутренний документ OpenAI, с которым ещё в мае ознакомились журналисты агентства. 
Источник изображения: Mariia Shalabaieva / unsplash.com Точную дату документа установить не удалось, но в нём подробно изложено, как компания намеревается использовать Strawberry для проведения исследований — сейчас модель находится в процессе разработки, сообщил источник издания. Не удалось также установить, насколько модель Strawberry близка к выходу в общий доступ. Она засекречена, и доступ к ней строго охраняется даже внутри OpenAI. В документе описан проект, в рамках которого Strawberry не просто даёт ответы на вопросы, а составляет план для автономной навигации ИИ в интернете для выполнения некоего «глубокого исследования». В OpenAI отмалчиваться или отрицать существование проекта не стали. «Хотим, чтобы наши модели ИИ видели и понимали мир так же, как мы. Непрерывное исследование новых возможностей ИИ — обычная практика в отрасли, и мы разделяем уверенность, что в будущем эти системы будут совершенствовать свои способности рассуждать», — заявил представитель компании. Работа над проектом велась ещё в прошлом году, но тогда он назывался Q* («Q со звёздочкой»), а инцидент с увольнением Сэма Альтмана (Sam Altman) произошёл вскоре после его запуска и получения первых результатов. Двое сотрудников OpenAI сообщили о том, как в этом году стали свидетелями демонстраций возможностей Q* — модель успешно отвечала на сложные научные вопросы и справлялась с математическими задачами. 
Источник изображения: Lukas / pixabay.com Во вторник в компании прошло внутреннее общее собрание, на котором был показан некий исследовательский проект — ИИ с новыми навыками рассуждения, подобными человеческим. Представитель OpenAI подтвердил факт проведения встречи, но отказался рассказать, что на ней было; Reuters не удалось установить, шла ли речь о проекте Strawberry. Предполагается, что система нового поколения задаст новую планку в аспекте способности ИИ рассуждать — это стало возможным благодаря новому способу обработки модели, которая была предварительно обучена на очень больших наборах данных. В последние месяцы OpenAI в конфиденциальном порядке давала понять разработчикам и другим сторонним лицам, что находится на пороге выпуска технологии, связанной со значительно более продвинутыми способностями ИИ к рассуждениям, утверждают анонимные источники. Особенностью Strawberry является уникальная методика обработки системы ИИ после процедуры обучения — чаще всего под ней подразумевается «тонкая настройка» модели. В случае Strawberry речь идёт о сходстве с методом StaR (Self-Taught Reasoner), который был разработан в 2022 году в Стэнфордском университете (США): он описывает самообучение ИИ и итеративную подготовку моделью собственных наборов данных для последующего дополнительного обучения — эта схема в теории может использоваться для создания модели ИИ, которая превзойдёт интеллект человеческого уровня. Важнейшей способностью Strawberry является выполнение задач, которые требуют планирования наперёд и выполнения ряда действий в течение длительного периода времени. Для этого в OpenAI проводятся создание, обучение и оценка моделей на данных «глубокого исследования» — состав этого набора данных и продолжительность периода, на который ИИ составляется план, журналистам установить не удалось. Такая модель реализует собственные исследовательские проекты, в автономном режиме осуществляя веб-серфинг при помощи специального агента — пользователя компьютера (Сomputer-Using Agent, CUA). В рамках проверки работы такая модель будет выполнять задачи, которые поручаются инженерам по ПО и машинному обучению. Робоэкскаватор обучили прицельно швырять камни
10.07.2024 [15:44],
Геннадий Детинич
Опытным экскаваторщикам знаком трюк, который позволяет отправлять содержимое ковша за пределы досягаемости стрелы. Наделённый нейросетью робоэкскаватор оказался прилежным учеником, который также смог освоить прицельное метание камней дальше зоны досягаемости стрелы. На очереди швыряние сыпучих материалов и повышение точности для работы ковшом на разных высотах. 
Источник изображения: ETH Zürich О процессе обучения нейросети робоэкскаватора для точного манипулирования содержимым ковша сообщили исследователи из Швейцарии (ETH Zürich). Нейросеть на основе обучения с подкреплением была обучена бросать мяч и камни в указанную точку, которая была дальше досягаемости стрелы (до 9,5 м при дальности захвата стрелой 7,5 м). Подобные операции помогут робототехнике справляться с большим кругом задач с меньшими затратами энергии на перемещения, а также сделают её работу более безопасной. Экскаватор совершал захват и броски ковшом с двумя степенями свободы, который не был жёстко закреплён на стреле. Броски совершались как по прямой, когда в работе была одна только стрела, так и с поворотом кабины. Во втором случае точность была чуть меньше, но в любом случае снаряд отклонялся от точки прицеливания не более чем на 30–40 см. Исследователи обучали нейросеть на базе модернизированного 12-т колёсного экскаватора Menzi Muck M545. Ранее они обучили экскаватор ряду нетривиальных операций, например, научив его строить устойчивую стену из неподготовленных каменных блоков. Экскаватор сам оценивал баланс камней и строил прочное каменное ограждение. Для точных автономных работ на местности экскаватор с помощью установленных на него датчиков строит модель окружающего пространства, в котором выполняет заданные операции. Часть субсидий в США по «Закону о чипах» будет направлена на подготовку кадров для отрасли
05.07.2024 [07:54],
Алексей Разин
На новых предприятиях по выпуску чипов, которые построят в США местные и зарубежные компании при помощи государственных субсидий, появятся многочисленные вакансии, которые нужно будет заполнять местными специалистами. Обеспечить их подготовку в адекватных количествах помогут средства, выделяемые властями в рамках «Закона о чипах», как поясняет Bloomberg. 
Источник изображения: Micron Technology По некоторым оценкам, дефицит специалистов технического профиля в американской полупроводниковой отрасли к 2030 году будет измеряться 90 000 человек, и чтобы покрыть его хотя бы частично, потребуется финансировать их подготовку не только за счёт частных компаний, но и государства. По информации Bloomberg, намеревающиеся построить новые предприятия в США компании Intel, Samsung, TSMC и Micron готовы потратить на соответствующие нужды по $40–50 млн каждая. Дополнительно власти США собираются направить на финансирование десяти образовательных программ для полупроводниковой отрасли от $500 000 до $2 млн в каждом случае. Эти средства будут изысканы из тех $5 млрд, которые власти страны намерены направить на создание и развитие Национального центра полупроводниковых технологий. С момента подписания в 2022 году «Закона о чипах» около 50 муниципальных образовательных учреждений в США ввели в свои учебные планы программы подготовки специалистов для полупроводниковой отрасли. Попутно был объявлен претендент на получение 12-го гранта на строительство предприятия по производству чипов в США. Им оказалась компания Rogue Valley Microdevices из Флориды, которая построит на территории штата предприятие по выпуску чипов, применяемых как в оборонной сфере, так и в сегменте биотехнологий. YouTube пытается договориться со звукозаписывающими лейблами об ИИ-клонировании голосов артистов
27.06.2024 [18:17],
Сергей Сурабекянц
После дебюта в прошлом году инструментов генеративного ИИ, создающих музыку в стиле множества известных исполнителей, YouTube приняла решение платить Universal Music Group (UMG), Sony Music Entertainment и Warner Records паушальные взносы в обмен на лицензирование их песен для легального обучения своих инструментов ИИ. 
Источник изображения: Pixabay YouTube сообщила, что не планирует расширять возможности инструмента Dream Track, который на этапе тестирования поддерживали всего десять артистов, но подтвердила, что «ведёт переговоры с лейблами о других экспериментах». Платформа стремится лицензировать музыку исполнителей для обучения новых инструментов ИИ, которые YouTube планирует запустить позднее в этом году. Суммы, которые YouTube готова платить за лицензии, не разглашаются, но, скорее всего, это будут разовые (паушальные) платежи, а не соглашения, основанные на роялти. Информация о намерениях YouTube появились всего через несколько дней после того, как Ассоциация звукозаписывающей индустрии Америки (RIAA), представляющая такие звукозаписывающие компании, как Sony, Warner и Universal, подала отдельные иски о нарушении авторских прав против Suno и Udio — двух ведущих компаний в области создания музыки с использованием ИИ. По мнению RIAA, их продукция произведена с использованием «нелицензионного копирования звукозаписей в массовом масштабе». Ассоциация требует возмещения ущерба в размере до $150 000 за каждое нарушение. Недавно Sony Music предостерегла компании, занимающиеся ИИ, от «несанкционированного использования» её контента, а UMG была готова временно заблокировать весь свой музыкальный каталог в TikTok. Более 200 музыкантов в открытом письме призвали технологические компании прекратить использовать ИИ для «ущемления и обесценивания прав занимающихся творчеством людей». Reddit введёт жёсткие меры против сборщиков контента для обучения ИИ
26.06.2024 [18:03],
Павел Котов
Администрация платформы Reddit заявила, что обновит исключения для роботов (файл robots.txt), которые сообщают веб-ботам о разрешении или запрете сканировать сайт и его разделы. Ресурс также примет меры для фактического ограничения доступа некоторым ботам. 
Источник изображения: redditinc.com Традиционно файл robots.txt использовался для того, чтобы помочь поисковым системам правильно сканировать сайт. Но с развитием систем искусственного интеллекта появились боты, которые выкачивают контент сайтов целиком для обучения моделей без указания источника этого контента. Поэтому вместе с обновлением файла robots.txt администрация Reddit продолжит ограничивать скорость неизвестных ботов и блокировать их доступ к платформе — меры будут приниматься, если эти системы не будут соблюдать «Политику открытого контента» (Public Content Policy) на сайте. Новый режим работы не должен повлиять на большинство пользователей и добросовестных участников ресурса, включая исследователей и некоммерческие организации вроде Internet Archive, сообщили в администрации Reddit. Меры вводятся лишь для того, чтобы не позволить другим компаниям обучать большие языковые модели ИИ на контенте платформы. Администрация ресурса опубликовала заявление после того, как стало известно, что ИИ-стартап Perplexity занимается сбором контента вопреки директивам robots.txt — гендиректор компании Аравинд Шринивас (Aravind Srinivas) заявил, что эти директивы не являются правовым обязательством. Предстоящие изменения Reddit не затронут партнёров, которые заключили соглашения с платформой: Google и OpenAI обучают свои модели ИИ на контенте ресурса на возмездной основе. В прошлом году Reddit для защиты от неправомерного сбора контента ввела плату за доступ к API, что вызвало массовые протесты среди пользователей. Adobe прописала явный самозапрет обучать ИИ на материалах клиентов, но есть исключение
19.06.2024 [18:26],
Павел Котов
В последние недели Adobe пришлось отбиваться от резко негативной реакции пользователей на новую редакцию условий обслуживания — теперь компания пытается исправить ситуацию. Накануне она опубликовала изменённый вариант своего соглашения об условиях обслуживания, в котором чётко указала, что она не будет обучать искусственный интеллект на контенте пользователя, который хранится локально или в облаке. 
Источник изображения: Rubaitul Azad / unsplash.com Раздел документа, определяющий доступ Adobe к пользовательскому контенту, теперь включает несколько категорий, одна из которых посвящена генеративному ИИ. Теперь в условиях обслуживания прямо говорится, что ПО компании «не будет использовать ваш локальный или облачный контент для обучения генеративного ИИ». За одним исключением: если материал пользователя отправлен на площадку Adobe Stock, то компания сохраняет за собой право использовать его для обучения своей нейросети Firefly. Новая редакция документа, подчёркивает директор Adobe по стратегическим вопросам Скотт Бельски (Scott Belsky), на деле не меняет ничего — ранее позиция компании в отношении обучения ИИ не была чётко изложена ранее, что привело к недопониманию. «Мы прямо заявили, что не будем обучать генеративный ИИ на вашем контенте. Это всегда было политикой нашей компании. Мы всегда заявляли об этом очень ясно, но никогда не говорили об этом явным образом», — заявил господин Бельски ресурсу The Verge. Документ в новой редакции также учитывает обеспокоенность пользователей по поводу сканирования компанией контента, который создавался в соответствии с соглашением о неразглашении (NDA) — компания заверила, что «не сканирует и не просматривает» содержимое материалов, хранящихся локально на компьютере пользователя. Но она производит автоматическое сканирование контента в облаке на предмет незаконных материалов — если система сообщает об обнаружении таких материалов, либо если пользователь участвует в программах тестирования предварительных версий ПО или улучшения продуктов, контент в облаке может просмотреть работник компании. Только европейцы смогут запретить Meta✴ использовать свой контент из соцсетей для обучения ИИ
11.06.2024 [13:43],
Павел Котов
Компания Meta✴, которая владеет Facebook✴, Instagram✴ и WhatsApp, дала себе право обучать модели искусственного интеллекта на публикациях всех пользователей, но только аудитории из Евросоюза предоставлена привилегия отказать компании в доступе к своим материалам. 
Источник изображения: NoName_13 / pixabay.com Гигант соцсетей не стал включать материалы европейских пользователей в массив данных для обучения ИИ, вероятно, чтобы не нарушать действующих в регионе жёстких норм в отношении конфиденциальности граждан. «Чтобы обслуживать наши европейские сообщества должным образом, обеспечивающие работу Meta✴ модели ИИ должны обучаться на актуальной информации, отражающей различные языки, географию и культурные особенности людей в Европе, которые будут ими пользоваться. Для этого мы хотим обучать наши большие языковые модели, которые обеспечивают функции ИИ, с использованием контента, который люди в ЕС решили публично разместить в продуктах и сервисах Meta✴», — заявили в компании. Meta✴ приняла несколько мер, чтобы укрепить свою позицию. Она указала, что для обучения ИИ будет использоваться «публичный контент», то есть публикации, комментарии, фотографии и другие материалы, размещённые на её платформах соцсетей пользователями старше 18 лет — личные сообщения в этот набор не входят. Компания также отметила, что с 22 мая разослала европейским пользователям уведомления о вступлении 26 июня в силу новых условий обслуживания на платформах, предусматривающих использование их материалов для обучения ИИ. При этом любой европейский пользователь может отказаться от этого без объяснения причин, и его данные не будет включаться в массив информации для обучения ИИ ни сейчас, ни в будущем. Жителям других регионов Meta✴ такой возможности не предлагает. Обучение модели LLaMa 3 осуществлялось вообще без согласования с пользователями — теперь же граждан стран за пределами ЕС просто информируют о включении их материалов в обучающие массивы и не дают возможности отказаться от этого. Ранее против этой инициативы выступила европейская правозащитная организация NOYB (None Of Your Business), которая подчеркнула, что пользователи соцсетей должны давать явное согласие на использование их данных для обучения ИИ, а не совершать дополнительные операции, чтобы отказаться от этого. Сейчас отношения Meta✴ и властей ЕС складываются не лучшим образом: платформы Facebook✴ и Instagram✴ ожидают проверки на предмет онлайн-контента, угрожающего безопасности несовершеннолетних. Выявленные правонарушения будут грозить компании гигантскими оборотными штрафами. Ноутбуки на Intel Lunar Lake и AMD Strix Point на старте продаж не получат ИИ-функции Copilot Plus
07.06.2024 [22:20],
Николай Хижняк
Новые ИИ-функции Windows, включая технологию масштабирования Auto SR, не являются эксклюзивными для ПК на базе процессоров Qualcomm Snapdragon X Elite. Чипы Intel Lunar Lake и AMD Strix Point тоже оснащены производительными NPU, необходимыми для их работы. Компьютеры на этих процессорах появятся в продаже осенью и тоже получат маркировку Copilot Plus PC. Однако никто не гарантирует, что они получат поддержку ИИ-функций прямо на старте продаж, в отличие от систем на чипах Qualcomm. 
Источник изображения: Microsoft Как пишет портал The Verge, поговоривший с представителями компаний Intel, AMD и Nvidia, системы на базе новых процессоров Core Ultra и Ryzen AI потребуют установку программных обновлений для Windows, которые наделят их поддержкой ИИ-функций Copilot Plus от Microsoft. Однако неизвестно, будут ли эти обновления выпущены до конца текущего года. «Системы на базе Intel Lunar Lake и AMD Strix Point соответствуют требованиям Windows 11 AI PC и нашим требованиям аппаратного обеспечения для Copilot Plus PC. Мы тесно сотрудничаем с Intel и AMD для оснащения их систем функциями Copilot Plus через бесплатные программные обновления, когда те станут доступны», — говорится в заявлении менеджера по маркетингу Microsoft Джеймса Хауэлла (James Howell) для The Verge. «Lunar Lake получат поддержку функций Copilot Plus PC через обновления, когда они станут доступным», — сообщил в ответе изданию PR-менеджер Intel Томас Ханнафорд (Thomas Hannaford). Ранее в разговоре с The Verge представители Nvidia сообщили аналогичную информацию: «Эти Windows 11 AI PC получат бесплатные обновления с функциями Copilot Plus, когда эти обновления будут готовы». Представитель AMD Мэтью Гурвиц (Matthew Hurwitz) в разговоре с журналистами не смог подтвердить, что ноутбуки на базе их процессоров получат функции Copilot Plus PC на старте продаж. «Мы ожидаем, что функции Copilot Plus появятся [в составе ноутбуков на базе наших процессоров] к концу 2024 года», — заявил Гурвиц. В Intel и Microsoft тоже не смогли уточнить, появятся ли ИИ-функции в составе ноутбуков на базе Intel до конца текущего года. Microsoft изменила Recall — функция не будет делать скриншоты без разрешения пользователя
07.06.2024 [22:05],
Николай Хижняк
Microsoft внесла изменения в функцию записи действий Recall для Windows 11 после того, как она вызвала жаркие споры на тему конфиденциальности пользователей. Recall постоянно делает скриншоты действий пользователя на ПК, а затем позволяет в любой момент вернуться к той или иной активности. Как пишет The Verge, у Recall можно будет отключить функцию съёмки скриншотов при первоначальной настройке ОС. 
Источник изображений: Microsoft Функция Recall станет доступна с поступлением в продажу ноутбуков Copilot Plus PC. Изначально Microsoft планировала активировать Recall на компьютерах по умолчанию, однако сейчас компания говорит, что предоставит пользователям возможность выбора — включить или оставить выключенной спорную ИИ-функцию. Выбор можно будет сделать во время процесса первоначальной настройки нового Copilot Plus PC. «Если не будет выбран иной вариант, то Recall будет отключена по умолчанию», — говорит глава подразделения Windows Паван Давулури (Pavan Davuluri). 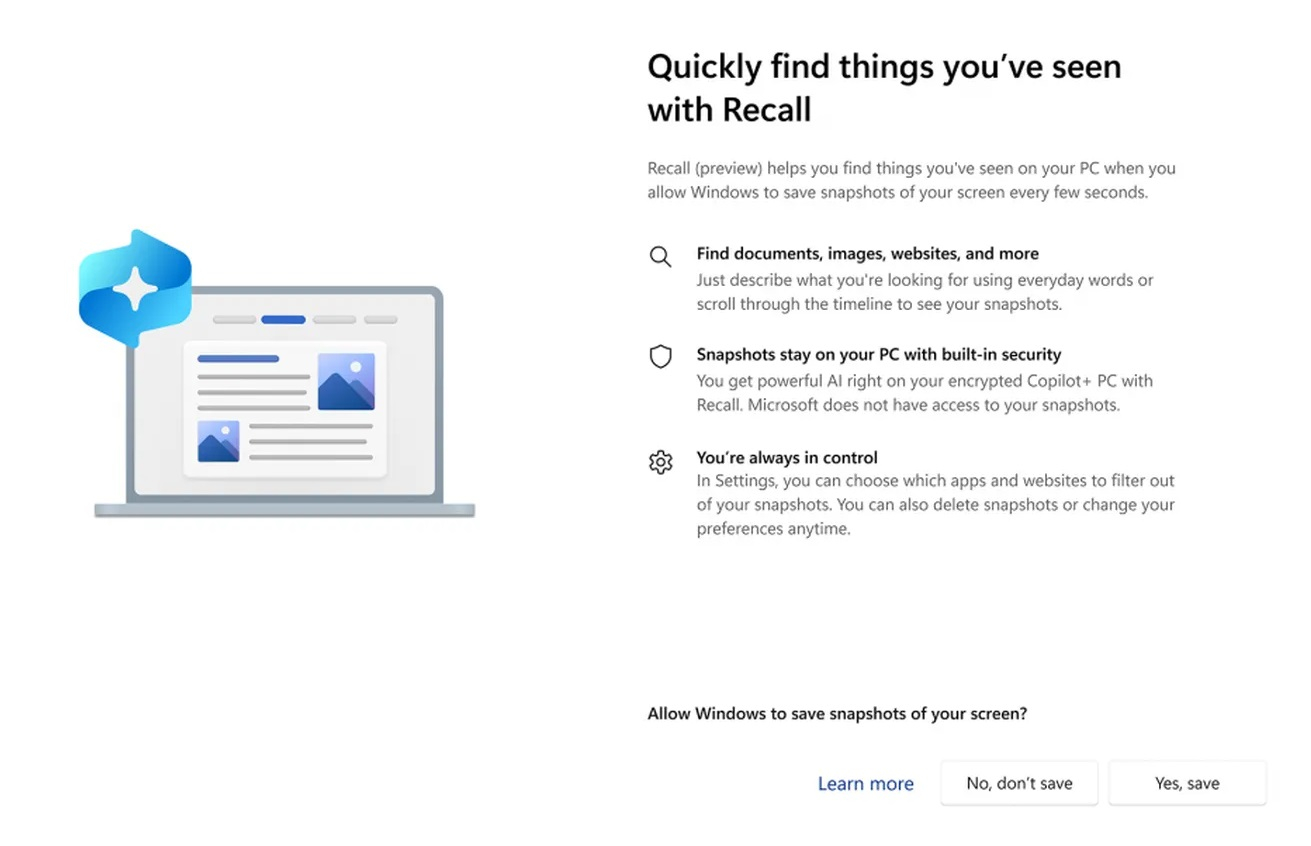 Перед использованием Recall компания также потребует авторизацию через Windows Hello. Таким образом, пользователю придётся предоставить изображение своего лица, отпечаток пальца или использовать PIN-код перед обращением к Recall. «Кроме того, для просмотра вашей хроники и поиска в Recall потребуется подтверждение присутствия [владельца ПК]», — говорит Давулури, отмечая, что посторонний не сможет использовать поиск в Recall без предварительной аутентификации. 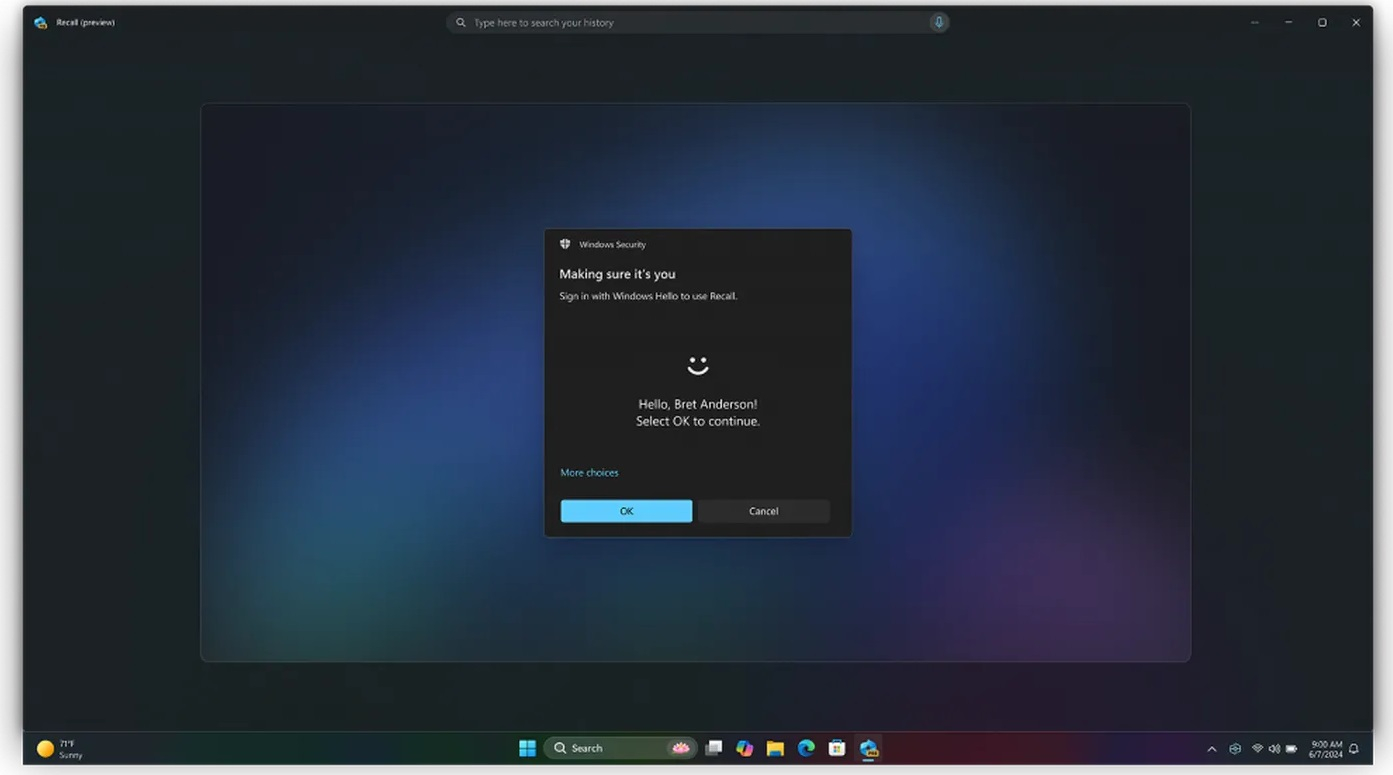 Эта аутентификация также будет применяться к защите скриншотов, создаваемых Recall. «Мы добавляем дополнительные уровни защиты данных, включая дешифровку по методу «точно в срок», защищенную системой безопасного входа Windows Hello Enhanced Sign-in Security (ESS). Таким образом, снимки Recall будут расшифрованы и доступны только после аутентификации пользователя», — объясняет Давулури, добавляя, что база данных поисковых индексов также будет зашифрована. Ранее сообщалось, что Recall при поддержке ИИ-алгоритмов будет делать скриншоты того, что происходит на ПК, и сохранять эту информацию локально, то есть на компьютере пользователя. Эта информация не попадёт в облако и не будет использоваться Microsoft для обучения своих ИИ-моделей. Поисковая строка Recall позволит просматривать разные временные отрезки активности в форме созданных скриншотов (открытые страницы веб-браузера, программы и т.д.). При желании пользователь сможет вернуться в ту или иную временную точку активности с помощью всего пары движений мыши. 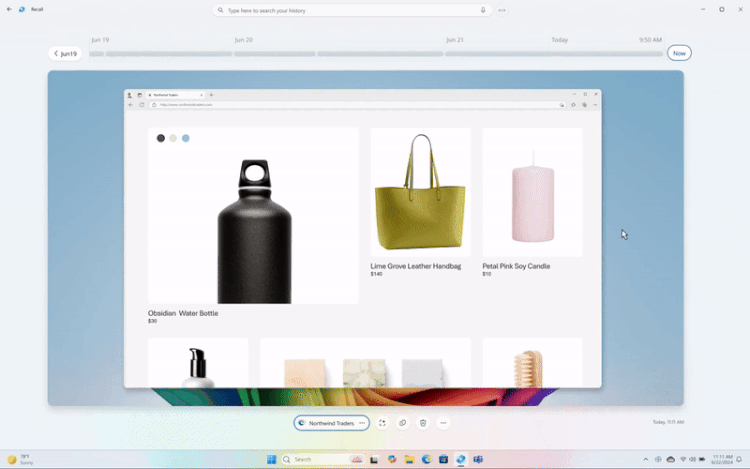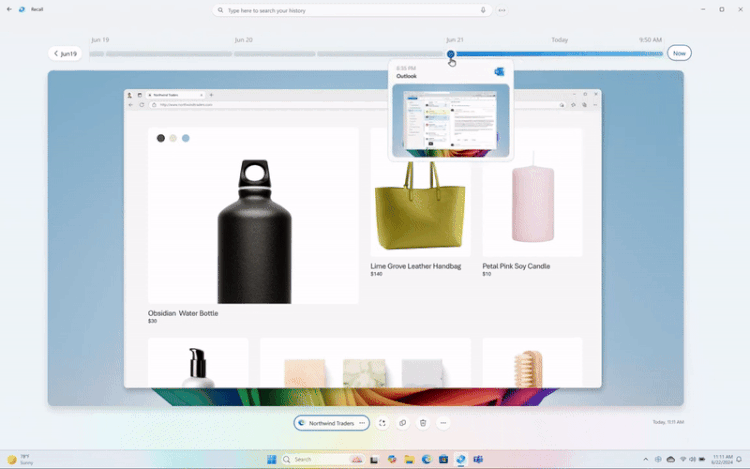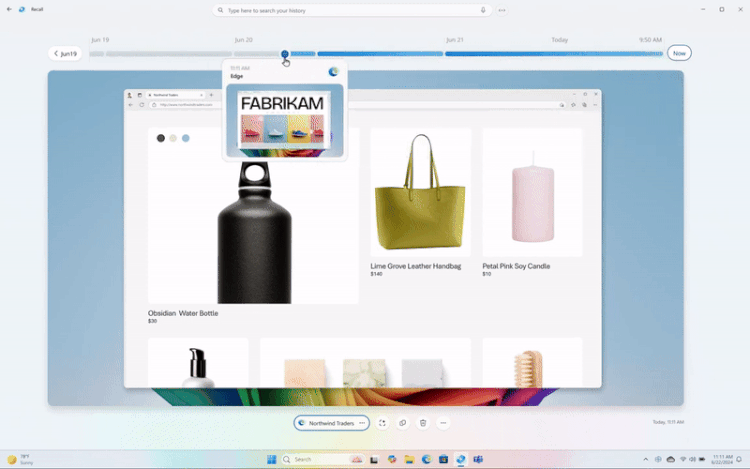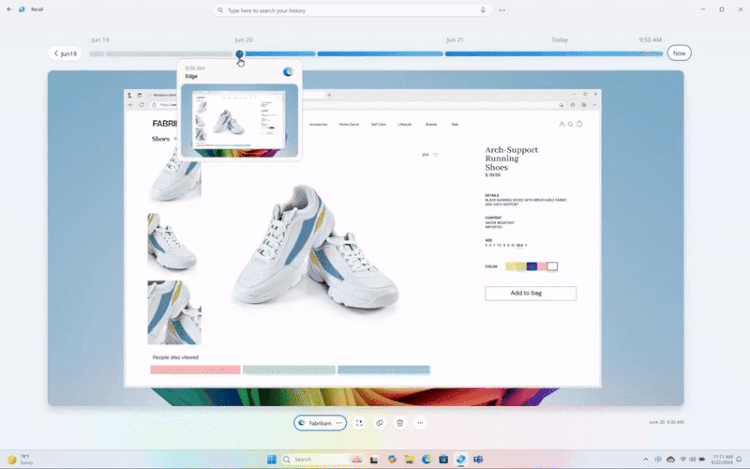 Microsoft внесла изменения в способы хранения базы данных Recall и доступа к ней после того, как эксперт по кибербезопасности Кевин Бомонт (Kevin Beaumont) обнаружил, что функция хранит информацию в виде обычного текста, что значительно упрощало авторам вредоносных программ создание инструментов для извлечения базы данных и её содержимого. Хотя Recall пока доступна лишь в тестовых сборках Windows, некоторые умельцы уже успели воспользоваться этим недостатком и создали ряд программных инструментов, позволяющих получить доступ к хранящимся в ней данным пользователей. Например, приложение TotalRecall извлекает базу данных Recall и позволяет легко просматривать сохранённый текст и снимки экрана, созданные функцией Microsoft. А сетевой инструмент NetExec, похоже, скоро получит собственный модуль Recall, который сможет получать доступ к папкам Recall на ПК и создавать их дамп для дальнейшего просмотра созданных снимков экрана. Появление подобных инструментов стало возможным только потому, что база данных Recall не наделена системой полного шифрования. Как сообщается, Microsoft разработала Recall в рамках инициативы Secure Future Initiative (SFI), призванной повысить безопасность её программных продуктов после крупных атак на облачный сервис Azure. Портал The Verge пишет, что глава Microsoft Сатья Наделла (Satya Nadella) ставит во главу угла безопасность над всеми остальным при разработке новых программных продуктов, о чём он сообщил во внутреннем письме для сотрудников компании и призвал их последовать его примеру, даже если это будет означать отказ от каких-то новых функций. «Если вы столкнулись с выбором между безопасностью и другим приоритетом, ваш ответ ясен: занимайтесь безопасностью. В некоторых случаях это означает, что безопасность имеет более высокий приоритет над другими задачами, которыми мы занимаемся, такими как разработка новых функций или обеспечение постоянной поддержки устаревших систем», — сообщил Наделла сотрудникам Microsoft. Глава подразделения Windows Паван Давулури в своих комментариях тоже ссылается на новую инициативу SFI по повышению безопасности программных продуктов Microsoft и отмечает, что компания принимает меры по повышению защиты Recall. Однако, похоже, эти вносимые изменения во многом опираются на отзывы сторонних исследователей цифровой безопасности, а не на собственные принципы безопасности Microsoft. В противном случае спорные моменты, связанные с Recall, были бы выявлены ещё на стадии её разработки и компания приняла бы соответствующие меры для их исправления или изменения ещё до запуска этой функции. Microsoft подчеркивает, что Recall будет доступна только на новых ПК Copilot Plus PC. Эти системы разработаны с учётом повышенных требований к программной и аппаратной безопасности и оснащены криптографическим процессором Pluton, разработанным для защиты персональных данных пользователей от кражи. AMD представила мощнейший ИИ-ускоритель MI325X с 288 Гбайт HBM3e и рассказала про MI350X на архитектуре CDNA4
03.06.2024 [12:22],
Николай Хижняк
Компания AMD представила на выставке Computex 2024 обновлённые планы по выпуску ускорителей вычислений Instinct, а также анонсировала новый флагманский ИИ-ускоритель Instinct MI325X. 
Источник изображений: AMD Ранее компания выпустила ускорители MI300A и MI300X с памятью HBM3, а также несколько их вариаций для определённых регионов. Новый MI325X основан на той же архитектуре CDNA 3 и использует ту же комбинацию из 5- и 6-нм чипов, но тем не менее представляет собой существенное обновление для семейства Instinct. Дело в том, что в данном ускорителе применена более производительная память HBM3e.  Instinct MI325X предложит 288 Гбайт памяти, что на 96 Гбайт больше, чем у MI300X. Что ещё важнее, использование новой памяти HBM3e обеспечило повышение пропускной способности до 6,0 Тбайт/с — на 700 Гбайт/с больше, чем у MI300X с HBM3. AMD отмечает, что переход на новую память обеспечит MI325X в 1,3 раза более высокую производительность инференса (работа уже обученной нейросети) и генерации токенов по сравнению с Nvidia H200.  Компания AMD также предварительно анонсировала ускоритель Instinct MI350X, который будет построен на чипе с новой архитектурой CDNA 4. Переход на эту архитектуру обещает примерно 35-кратный прирост производительности в работе обученной нейросети по сравнению с актуальной CDNA 3. 
 Для производства ускорителей вычислений MI350X будет использоваться передовой 3-нм техпроцесс. Instinct MI350X тоже получат до 288 Гбайт памяти HBM3e. Для них также заявляется поддержка типов данных FP4/FP6, что принесёт пользу в работе с алгоритмами машинного обучения. Дополнительные детали об Instinct MI350X компания не сообщила, но отметила, что они будут выпускаться в формфакторе Open Accelerator Module (OAM). 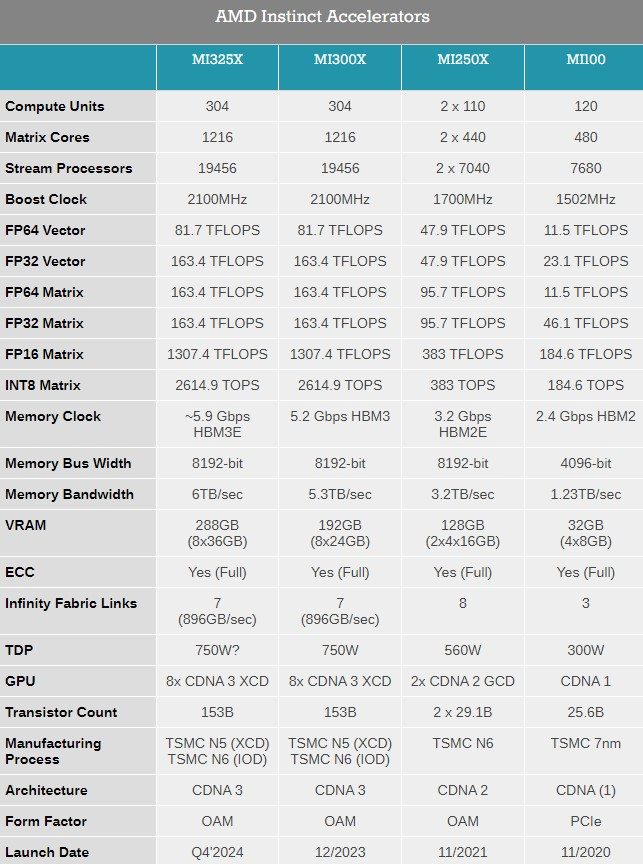
Источник изображения: AnandTech ИИ-ускорители Instinct MI325X начнут продаваться в четвёртом квартале этого года. Выход MI350X ожидается в 2025 году. Кроме того, AMD сообщила, что ускорители вычислений серии MI400 на архитектуре CDNA-Next будут представлены в 2026 году. ChatGPT обретёт тело: OpenAI возродила разработку роботов
31.05.2024 [18:44],
Сергей Сурабекянц
Компания OpenAI заморозила разработку собственного робота общего назначения ещё в 2020 году. Теперь гигант искусственного интеллекта собирается поставлять свои технологии машинного обучения другим разработчикам и производителям роботов. По сообщению Forbes, в связи с ростом инвестиций в роботов с ИИ компания OpenAI перезапускает свое ранее закрытое подразделение по робототехнике. 
Источник изображения: unsplash.com По данным трёх независимых источников, в настоящее время OpenAI нанимает инженеров-исследователей для восстановления команды, которую она закрыла в 2020 году. Новая команда существует менее двух месяцев и в списке вакансий поясняется, что новые сотрудники станут «одними из первых её членов». За последний год OpenAI инвестировала в несколько компаний, занимающихся разработкой человекоподобных роботов, включая Fig AI (привлечено $745 млн), 1X Technologies (125 $млн) и Physical Intelligence ($70 млн). Первые намёки на возвращение интереса OpenAI к робототехнике появились в февральском пресс-релизе, посвящённом сбору средств для компании Fig. Месяц спустя компания Fig представила робота, демонстрирующего элементарные навыки речи и мышления на основе большой мультимодальной модели, обученной OpenAI. 
Источник изображения: pexels.com Источники сообщают, что OpenAI намерена сосуществовать, а не конкурировать с разработчиками роботов, создавая технологии, которые производители роботов будут интегрировать в свои собственные системы. Инженеры компании будут сотрудничать с внешними партнёрами и заниматься обучением моделей ИИ. Даже такая, более узкая направленность команды робототехники OpenAI, может пересекаться с другими компаниями. Например, Covariant, основанная бывшими членами команды OpenAI по робототехнике, занимаются обучением собственных моделей, а количество талантливых специалистов весьма ограничено. 
Источник изображения: pexels.com Робототехника была одним из основных направлений OpenAI с первых дней её существования. Команда специалистов под руководством соучредителя OpenAI Войцеха Зарембы (Wojciech Zaremba) стремилась создать «робота общего назначения». В 2019 году исследователи OpenAI обучили нейросеть собирать кубик Рубика с помощью роботизированной руки. Но в октябре 2020 года команда была распущена из-за «нехватки данных для обучения», по словам Зарембы. 
Источник изображения: Mitsubishi В конечном итоге OpenAI направила усилия команды по робототехнике на другие проекты. «Благодаря быстрому прогрессу в области искусственного интеллекта и его возможностей мы обнаружили, что другие подходы, такие как обучение с подкреплением и обратной связью с человеком, приводят к более быстрому прогрессу», — говорится в заявлении компании. В конечном итоге, достижения в обучении с подкреплением стимулировали бум ИИ, который произошёл после выпуска компанией ChatGPT. Некоторые из бывших сотрудников OpenAI в области робототехники остаются в компании на других должностях. Например, Заремба помогает руководить разработкой флагманских моделей GPT, Питер Велиндер (Peter Welinder) руководит продуктами и партнёрскими отношениями, Боб МакГрю (Bob McGrew) является вице-президентом по исследованиям, а Лилиан Венг (Lilian Weng) возглавляет отдел систем безопасности и является членом недавно созданного комитета по безопасности OpenAI. 
Источник изображения: pexels.com Пока нет точной информации, планирует ли OpenAI разрабатывать своё робототехническое оборудование, что она пыталась сделать несколько лет назад. Растущие амбиции компании в последнее время были отмечены некоторой турбулентностью, в том числе серией увольнений высокопоставленных специалистов. После публикации Forbes от 30 мая, OpenAI официально подтвердила набор специалистов в возрождённую команду по робототехнике. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2025 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews. kz
![]()
![]()








 MWC 2018
MWC 2018 2018
2018 Computex
Computex