|
Опрос
|
реклама
Быстрый переход
Meta✴ в партнёрстве с ЮНЕСКО запускает новую программу сбора данных для улучшения речи и перевода ИИ
07.02.2025 [18:49],
Сергей Сурабекянц
LTPP (Language Technology Partner Program — партнёрская программа по языковым технологиям) — совместная инициатива ЮНЕСКО и Meta✴ по поиску авторов, которые могут предоставить более 10 часов записей речи с транскрипциями, большие объёмы письменного текста и наборы переведённых текстов на разных языках. В дальнейшем эти данные будут интегрированы в ИИ-модели с открытым исходным кодом для распознавания речи и перевода. Усилия LTPP будут сосредоточены на недостаточно обслуживаемых языках для поддержки работы, уже проводимой в этом направлении ЮНЕСКО. «В конечном итоге наша цель — создать интеллектуальные системы, которые могут понимать и реагировать на сложные потребности человека, независимо от языка или культурного происхождения», — заявил представитель Meta✴. В дополнение к новой инициативе Meta✴ опубликовала открытый исходный код программы для оценки производительности моделей языкового перевода. Тест, состоящий из предложений, созданных лингвистами, поддерживает семь языков, и доступен на платформе разработки ИИ Hugging Face. Meta✴ продолжает расширять количество языков, поддерживаемых её ИИ-моделями и развивать функции автоматического перевода для создателей контента. В сентябре прошлого года компания начала тестирование инструмента для перевода голосов в Instagram✴ Reels, который дублирует речь создателя на другом языке с автоматическим липсинком. На сегодняшний день обработка на платформах Meta✴ контента на языках, отличных от английского, далека от совершенства. По некоторым данным, в соцсети Facebook✴ 79 % дезинформации о COVID на итальянском и испанском языках не были распознаны и отмечены системой, по сравнению с 29 % на английском языке. А сообщения на арабском языке, наоборот, часто ошибочно помечаются как разжигающие ненависть. Meta✴ заявила, что принимает меры по улучшению своих технологий перевода и модерации. И, хотя компания позиционирует обе свои языковые инициативы как филантропические, нет никаких сомнений, что главным бенефициаром этих программ станет именно Meta✴, которая сможет существенно улучшить качество распознавания речи и перевода. Опубликовано видео 1983 года, в котором Стив Джобс говорит о будущем компьютеров
18.07.2024 [19:57],
Сергей Сурабекянц
Архив Стива Джобса (Steve Jobs) был запущен в 2022 году Лорен Пауэлл Джобс (Laurene Powell Jobs), Тимом Куком (Tim Cook) и Джони Айвом (Jony Ive). Здесь представлена коллекция цитат, фотографий, видео и электронных писем основателя Apple. Сайт также предлагает стипендии и гранты для молодых творцов, желающих пойти по стопам Джобса. Недавно на сайте появилась страница с ранее не публиковавшимся видео речи Джобса в Аспене в 1983 году. 
Источник изображений: stevejobsarchive.com Видео сопровождается комментариями и воспоминаниями Джони Айва, который более 20 лет руководил дизайном в Apple и является автором многих устройств компании. На протяжении практически всей жизни Джони Айв был близким другом Джобса. Ниже мы приводим цитаты из комментариев Айва. «Стив редко посещал конференции по дизайну. Это был 1983 год, до запуска Mac, относительно ранний период существования Apple. Меня поражает, насколько глубоким было его понимание драматических изменений, которые должны были произойти, когда компьютер стал широко доступным. Конечно, он не только был пророческим, но и сыграл важную роль в определении продуктов, которые навсегда изменят нашу культуру и нашу жизнь».  «Накануне выпуска первого по-настоящему персонального компьютера Стив озабочен не только основополагающими технологиями и функциональностью конструкции продукта. Это чрезвычайно необычно, поскольку на ранних стадиях серьёзных инноваций обычно именно основная технология получает выгоду. Описывая то, что он считает неизбежностью, он просит дизайнеров в аудитории думать в первую очередь о дизайне этих продуктов». «Стив отмечает, что усилия по проектированию в США в то время были сосредоточены на автомобилях, при этом мало внимания и усилий уделялось бытовой электронике. Стив прогнозирует, что к 1986 году продажи ПК превысят продажи автомобилей и что в следующие десять лет люди будут проводить больше времени с ПК, чем в автомобиле. Это были абсурдные заявления для начала 1980-х годов».  «Стив остаётся одним из лучших педагогов, которых я когда-либо встречал в своей жизни. У него была способность объяснять невероятно абстрактные и сложные технологии доступным, осязаемым и актуальным языком. Когда я оглядываюсь назад на нашу работу, больше всего мне вспоминаются не продукты, а процесс. Часть гениальности Стива заключалась в том, что он научился поддерживать творческий процесс, поощряя и развивая идеи даже в больших группах людей. К процессу творчества он относился с редким и удивительным почтением».  «Революция, описанная Стивом более 40 лет назад, конечно же, произошла, отчасти из-за его глубокой приверженности своего рода гражданской ответственности. Он заботился, выходя за рамки любого функционального императива. Это была победа красоты, чистоты и, как он сказал, неравнодушия. Он искренне верил, что, делая что-то полезное, расширяющее возможности и красивое, мы выражаем свою любовь к человечеству». Разработан ИИ, распознающий эмоции человека по голосу — он поможет в работе кризисных линий
01.05.2024 [16:47],
Павел Котов
Модель искусственного интеллекта оказалась эффективным инструментом для выявления таких эмоций как страх и беспокойство в голосах людей, которые звонят на телефонные линии психологическом помощи. Автор проекта надеется, что она окажется полезной для телефонных операторов на линиях по предотвращению самоубийств. 
Источник изображения: The_BiG_LeBowsKi / pixabay.com Оценка эмоционального состояния звонящих на кризисные телефонные линии на предмет текущего уровня суицидального риска имеет решающее значение для выявления и предотвращения самоубийств. Речь человека способна при помощи невербальных средств передавать полезную информацию о психическом и эмоциональном состоянии человека, содержа подсказки о том, испытывает он грусть, злобу или страх. Исследования суицидальной речи начались более 30 лет назад — уже удалось выявить в ней объективные звуковые признаки, которые можно использовать для определения различных психических состояний и расстройств, включая депрессию. Но для человека, слушающего собеседника по телефону, оценка риска самоубийства может оказаться сложной задачей, потому что на кризисные линии звонят люди, пребывающие в крайне эмоционально нестабильном состоянии, и характеристики их речи могут быстро меняться. Решение этой задачи предложил Алаа Нфисси (Alaa Nfissi), аспирант университета Конкордия (Канада, г. Монреаль). Он обучил распознаванию речевых эмоций модель ИИ. Обычно такую оценку проводили психологи, из-за чего она требовала значительных временных затрат и опыта, но модель глубокого обучения оказалась способной эффективно распознавать эмоции. Для обучения модели автор проекта использовал базу реальных записей звонков на кризисные линии для предотвращения самоубийств, а также записи актёров, которым было поручено изображать определённые эмоции. Записи были разбиты на сегменты и снабжены аннотациями, отражающими соответствующее состояние психики: злость, грусть, нейтральное состояние, страх или беспокойство. В результате модель научилась достаточно точно распознавать четыре эмоции: страх/беспокойство (правильный ответ в 82 % случаев), грусть (77 %), злость (72 %) и нейтральное состояние (78 %). Особенно хорошо модель справлялась с оценкой фрагментов записей настоящих звонков: грусть (78 %) и злость (100 %). Алаа Нфисси считает, что разработанная им модель ИИ сможет использоваться в качестве вспомогательного инструмента для работы на кризисных линиях, помогая операторам в реальном времени оценивать состояние собеседников и выбирать подходящие стратегии разговора. Возможно, это будет способствовать предотвращению самоубийств. Spotify будет дублировать подкасты на иностранные языки голосами самих авторов с помощью ИИ
25.09.2023 [18:25],
Сергей Сурабекянц
Сотрудничество Spotify с OpenAI позволит подкастерам синтезировать собственный голос для автоматического создания версий своих шоу на иностранных языках. Это основная идея новой функции голосового перевода Spotify на базе ИИ, которая воспроизводит подкасты на других языках, используя синтезированный голос создателя. Теперь подкастеру достаточно просто «щёлкнуть выключателем» и мгновенно заговорить на другом языке. 
Источник изображения: unsplash.com Компания уже заключила договоры с несколькими подкастерами о переводе созданных ими англоязычных эпизодов на испанский с помощью своего нового инструмента, и планирует в ближайшие недели выпустить переводы на французский и немецкий языки. Первыми будут переведены эпизоды подкастеров с такими громкими именами, как Дакс Шепард (Dax Shepard), Моника Пэдман (Monica Padman), Лекс Фридман (Lex Fridman), Билл Симмонс (Bill Simmons) и Стивен Бартлетт (Steven Bartlett). В дальнейшем Spotify планирует расширить эту группу, включив в неё The Rewatchables и предстоящее шоу Тревора Ноа (Trevor Noah). Основой функции перевода является ИИ-инструмент синтезирования голоса OpenAI Whisper, который умеет как транскрибировать английскую речь, так и переводить на английский с других языков. Но инструмент Spotify выходит за рамки простого перевода речи в текст — эта функция переведёт подкаст на другой язык и воспроизведёт его в синтезированной версии голосом подкастера. «Сопоставляя собственный голос создателя, Voice Translation даёт слушателям по всему миру возможность открывать для себя новых подкастеров и вдохновляться ими более аутентично, чем когда-либо прежде», — уверен Зиад Султан (Ziad Sultan), вице-президент Spotify по персонализации. OpenAI сегодня утром объявила о запуске инструмента, который может создавать «человеческий звук из просто текста и нескольких секунд образца речи». Доступность нового инструмента будет существенно ограничена из-за опасений по поводу безопасности и конфиденциальности. Вероятно, это одна из причин, почему технология перевода Spotify пока тестируется только с «избранной группой» подкастеров, а компания не делает прогнозов о массовом внедрении новой функции. Google начала тестирование нового способа поиска песен на YouTube: их достаточно напеть
24.08.2023 [08:22],
Дмитрий Федоров
Google тестирует новый способ поиска песен на YouTube — просто напевая их голосом. Этот инновационный шаг, уже доступный ограниченному числу пользователей Android, может кардинально изменить то, как мы находим музыкальные композиции в интернете. 
Источник изображения: SAM-RIZ44 / Pixabay В мире смартфонов поиск песни по звуку используется уже давно. Сервисы вроде Google Assistant и SoundHound позволяют добавлять треки в плейлист Spotify или воспроизводить клипы на YouTube. Однако новый способ поиска песни кажется более удобным, если вы не помните её название или другие детали. Google объявила о том, что экспериментирует с поиском песен на YouTube по напеву голосом. Кроме этого, пользователи могут использовать функцию определения песни, записав её фрагмент, который играет фоном, например, в кафе или на радио. Для активации функции необходимо переключиться из голосового поиска YouTube на поиск песен. После этого пользователь должен напеть или записать фрагмент песни в течение минимум 3 секунд. Затем система перенаправит его к соответствующему контенту на YouTube — официальному клипу, пользовательскому видео или короткому ролику Shorts. На этапе тестирования новый поиск доступен только ограниченному числу пользователей YouTube на Android. Перед тем, как он окажется в широком доступе, его характеристики могут измениться. Многие надеются, что компания добавит его и в YouTube Music. Кроме этого, Google тестирует ещё одну функцию для YouTube — «Полка канала» (Channel Shelf) в ленте подписок. Она позволит объединять несколько свежих публикаций одного автора на одной «полке». Таким образом, подписчикам не придётся переходить на YouTube-канал, чтобы увидеть недавние публикации. Google утверждает, что это нововведение снизит давление на авторов контента в плане частоты его публикаций. Meta✴ представила ИИ-модель Voicebox, которая генерирует и редактирует устную речь
17.06.2023 [10:31],
Павел Котов
Инженеры Meta✴ рассказали о нейросетевой модели Voicebox, которая обладает широкими возможностями по работе с устной речью: генерация, редактирование или стилизация по образцу. Авторы проекта охарактеризовали её как прорыв в моделях речевого ИИ. 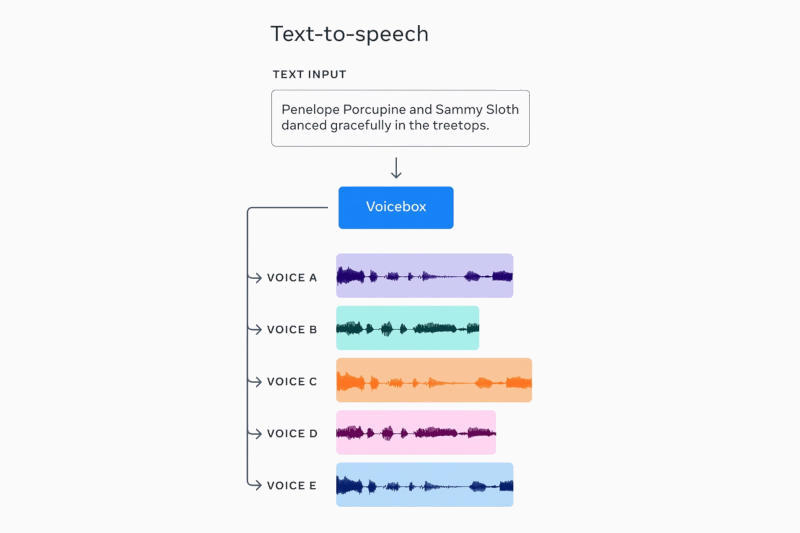
Источник изображения: Meta✴ Voicebox озвучивает заданный текст с высоким качеством или производит обработку уже готовой записи голоса, например, удаляет из него посторонние звуки вроде автомобильных гудков и собачьего лая, сохраняя содержание и стилистику речи. При необходимости можно даже «переиграть» фрагмент записи, точечно исправив, например, неправильно произнесённое слово. Поддерживаются шесть языков: английский, французский, немецкий, испанский, польский и португальский. Voicebox может использоваться в качестве синхронного переводчика, передавая голос и манеру речи собеседника. Модель была обучена на 50 часах аудиокниг, и этого ей хватило, чтобы овладеть навыками устной речи в полной мере: она составляет профиль голоса и манеры речи на основе образца продолжительностью всего две секунды, после чего может воспроизвести её с любым текстом. На практике эти возможности могут оказаться полезными в приложениях метавселенной, обеспечив естественное звучание голосов для виртуальных помощников и неигровых персонажей; или для слабовидящих людей — модель может озвучивать письма голосами их авторов. Meta✴ часто делает свои ИИ-модели общедоступными, но не на сей раз. В компании не раскрыли, на каких материалах производилось обучение Voicebox, и не предложили испытать технологию на практике — опасаются злоупотреблений. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2025 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews. kz
![]()
![]()








 MWC 2018
MWC 2018 2018
2018 Computex
Computex
 Подписаться
Подписаться