|
Опрос
|
реклама
Быстрый переход
Проблемы Nvidia в Китае стали подарком местным разработчикам GPU — Moore Threads, MetaX и Cambricon
07.10.2025 [18:04],
Павел Котов
Недавно гендиректор Nvidia Дженсен Хуанг (Jensen Huang) отметил, что китайские производители добились значительных успехов в области производства чипов — по его мнению, Китай отстаёт от США уже на «наносекунды». Если четыре года назад доля Nvidia на китайском рынке была 95 %, то к настоящему моменту сократилась до 50 %. Помимо Huawei, руку к этому приложили Moore Threads, MetaX и Cambricon, отмечают аналитики TrendForce. 
Источник изображения: metax-tech.com По типу чипов Moore Threads ближе всего к Nvidia. Cambricon и Huawei HiSilicon специализируются на архитектурах ASIC, а Moore Threads, по её собственному заверению, является единственной китайской компанией, которая сегодня массово производит полнофункциональные графические процессоры. К настоящему моменту она выпустила четыре их поколения: Sudi (2021 год), Chunxiao (2022), Quyuan (2023) и Pinghu (2024). Видеокарты первых двух поколений предназначались для потребительских десктопов и и профессиональных систем, тогда как Quyuan и Pinghu работают и с алгоритмами искусственного интеллекта. Основатель и гендиректор Moore Threads Джеймс Чжан Цзяньчжун (James Zhang Jianzhong) проработал в Nvidia 14 лет, он дослужился до должности вице-президента и гендиректора китайского филиала компании, которую покинул в 2020 году, чтобы основать Moore Threads. В конце сентября компания Цзяньчжуна получила разрешение Шанхайской фондовой биржи выйти на первичное размещение акций — процедура заняла 88 дней, и это один из лучших результатов. Moore Threads намеревается привлечь 8 млрд юаней ($1,12 млрд), чтобы ускорить масштабное производство продукции. 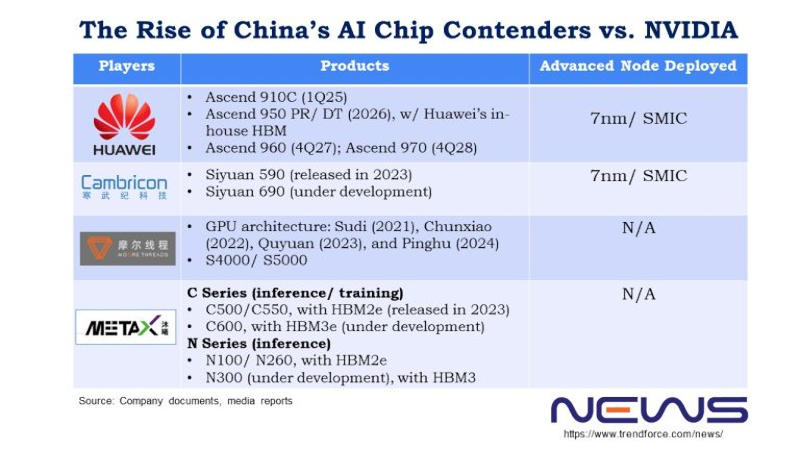
Источник изображения: trendforce.com Выйти на биржу готовится и MetaX. Если в Moore Threads работает много выходцев из Nvidia, то MetaX происходит от AMD. Основатель этой китайской компании Чэнь Вэйлян (Chen Weiliang) в 2007 году начал работу в AMD Shanghai в качестве старшего директора, а в 2020 году ушёл из неё и учредил собственный стартап. Выходцами из AMD являются также оба технических директора MetaX Пэн Ли (Peng Li) и Ян Цзянь (Yang Jian). В 2024 году основным источником дохода компании стали ускорители для обучения и инференса (запуска) ИИ: на платы GPU пришлись 68,99 % от общего объёма выручки, на серверы — 28,29 %. В первом квартале 2025 года на графические процессоры этой серии пришлись 97,55 % от общего объёма продаж. Ни MetaX, ни Moore Threads пока на прибыльность не вышли — но обе уверены, что смогут привлечь капитал, исходя из резкого роста выручки в 2024 году, а также того, как растёт их признание на рынке оборудования для ИИ-вычислений. Cambricon в сентябре получила разрешение на закрытый раунд финансирования на сумму 3,99 млрд юаней ($559,6 млн) — ей необходимы средства на проекты по разработке чипов и ПО для ИИ. По итогам 2025 года компания ожидает роста выручки на величину от 317 % до 483 % — в диапазоне от 5 млрд до 7 млрд юаней. Подчёркивается, что прогноз предварительный и не является твёрдым обязательством. Чистая прибыль за первую половину 2025 года составила 1 млрд юаней ($140,4 млн) — аналогичный период в прошлом году компания завершила убытком в размере 530 млн юаней ($74,1 млн). В отличие от Moore Threads и MetaX компания Cambricon обходится без кадрового ресурса Nvidia и AMD. Cambricon в 2016 году основали братья Чэнь Юньцзи (Chen Yunji) и Чэнь Тяньши (Chen Tianshi). Новый флагман Siyuan 690, как ожидается, по производительности будет сравним с ускорителем Nvidia H100. Его предшественник Siyuan 590, дебютировавший в 2023 году, выпускается с использованием техпроцесса 7 нм и обеспечивает 80 % производительности Nvidia A100. Из всего трио у Cambricon самая высокая выручка; Moore Threads ранее отставала от MetaX, но в первой половине 2025 года вырвалась вперёд. В условиях ограничений на продукты Nvidia в Китае все три производителя показыывают взрывной рост доходов: за первую половину 2025 года они заработали больше, чем за три предыдущих года вместе взятых. При этом доля рынка Nvidia остаётся больше, чем MetaX. Президент OpenAI: человечеству потребуется 10 млрд ИИ-ускорителей — по одному на каждого жителя Земли
30.09.2025 [06:58],
Алексей Разин
Сейчас стартап OpenAI использует любую возможность для привлечения не только финансовых ресурсов, но и заключения контрактов с поставщиками тех же ускорителей вычислений, коим является Nvidia. Президент компании Грег Брокман (Greg Brockman) убеждён, что человечеству потребуется до 10 млрд ускорителей вычислений, и каждого жителя планеты буквально будет обслуживать отдельный ИИ-чип. 
Источник изображения: Nvidia Своими соображениями президент OpenAI поделился в интервью CNBC, в котором также приняли участие генеральный директор компании Сэм Альтман (Sam Altman), а также глава и основатель Nvidia Дженсен Хуанг (Jensen Huang). По мнению Альтмана, масштабы сотрудничества с Nvidia по своей значимости для человечества окажутся важнее программы доставки до Луны американских астронавтов, которую NASA реализовало в прошлом веке. Альтман видит будущее человечества с неразрывным присутствием «супермозга», созданного искусственным интеллектом и активно влияющего на повседневную жизнь людей. Брокман же считает, что ИИ будет действовать в качестве «агента, который работает на опережение, пока вы спите». Каждый работающий житель Земли, по его мнению, будет использовать ресурсы как минимум одного ускорителя вычислений при выполнении своих должностных обязанностей. «Вам действительно захочется, чтобы у каждого человека был свой собственный выделенный GPU», — охарактеризовал свой прогноз Брокман. Сейчас подобное предсказание может казаться нереалистичным, но достаточно вспомнить, что в начале девяностых годов прошлого века один из основателей Microosft Билл Гейтс (Bill Gates) указывал на неизбежность появления компьютера не только в каждом домохозяйстве, но и на каждом рабочем столе. В какой-то мере его предсказание сбылось, пусть даже если вместо компьютеров в их классической форме речь идёт о смартфонах, которые помещаются в карман. Брокман считает, что сейчас отрасль ИИ на три порядка отстаёт от потенциальных потребностей в вычислительных мощностях, и для создания постоянно функционирующей глобальной системы искусственного интеллекта человечеству может потребоваться до 10 млрд ускорителей вычислений. По сути, это даже больше, чем проживает людей на Земле (8,2 млрд человек). Мир, по мнению Брокмана, движется к состоянию, при котором экономику подпитывают вычисления. Вычислительных мощностей сейчас не хватает, как он считает, а наличие достаточно мощных центров обработки данных в будущем станет определять состоятельность экономики целых стран. В какой-то мере они заменят валюту в качестве источника ресурсов для развития экономики. Китайская Innosilicon представила видеокарту Fenghua 3 — CUDA, DX12, трассировка лучей и более 112 Гбайт HBM
24.09.2025 [15:31],
Николай Хижняк
Компания Innosilicon представила свой графический процессор третьего поколения — Fenghua 3. Компания обещает, что третья версия графического процессора будет значительно превосходить своих предшественников. Компания называет его первым полнофункциональным GPU собственной разработки, которые построен на открытой архитектуре RISC-V и совместим с CUDA. 
Источник изображений: Innosilicon В отличие от предыдущих поколений ускорителей Fenghua, основанных на архитектуре PowerVR от Imagination Technologies, Fenghua 3 использует в качестве основы проект OpenCore RISC-V Nanhu V3. Innosilicon утверждает, что новый GPU способен справиться с широким спектром рабочих нагрузок: от обучения ИИ и масштабных научных вычислений до САПР, медицинской визуализации и облачного гейминга. Для Fenghua 3 заявляется поддержка DirectX 12, Vulkan 1.2 и OpenGL 4.6 с аппаратной трассировкой лучей. Компания продемонстрировала работу GPU в таких играх, как Tomb Raider, Delta Force и Valorant, хотя данные о частоте кадров и настройках не были предоставлены. Fenghua 3 также поддерживает подключение до шести 8K-мониторов с частотой обновления 30 Гц. 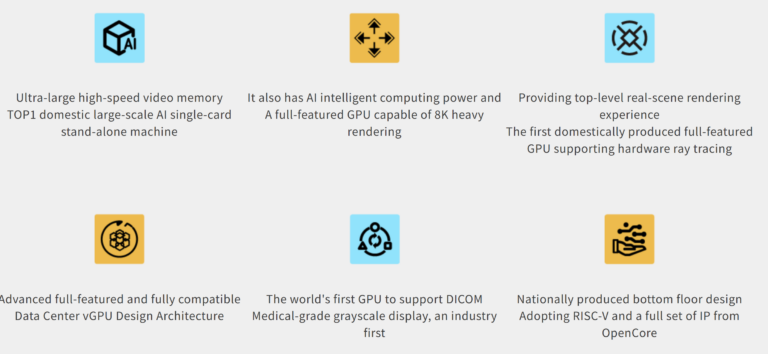 Для задач искусственного интеллекта ускоритель на базе Fenghua 3 предлагает более 112 Гбайт высокоскоростной памяти HBM — это самый большой объём памяти среди китайских видеокарт. Один ускоритель может обрабатывать модели с 32 и 72 млрд параметров, а кластер из восьми — поддерживать огромные модели DeepSeek 671B и 685B. Innosilicon также подтвердила совместимость своей новинки с Qwen 2.5, Qwen 3 и семейством ИИ-моделей DeepSeek V3, V3.1 и R1. Innosilicon также похвасталась тем, что Fenghua 3 — первая в Китае видеокарта, поддерживающая формат YUV444, который обеспечивает наилучшую детализацию и точность цветопередачи. Это будет особенно полезно для тех, кто работает с САПР или занимается видеомонтажом. Кроме того, Fenghua 3 — первая в мире видеокарта, которая предлагает встроенную поддержку технологии DICOM (Digital Imaging and Communication in Medicine). Она позволяет точно визуализировать рентгеновские снимки, МРТ, КТ и УЗИ на стандартных мониторах, устраняя необходимость в дорогостоящих специализированных медицинских дисплеях с градациями серого. Ускоритель работает с системами Windows, Android, Tongxin и Kylin Linux. Huawei пообещала создать «самый мощный в мире» ИИ-кластер, который в разы превзойдёт решения Nvidia
18.09.2025 [20:36],
Сергей Сурабекянц
Huawei наращивает мощности своих вычислительных систем для ИИ на фоне трудностей Nvidia в Китае. Компания заявила, что её новые кластеры из ИИ-ускорителей Ascend 950 на базе чипов собственной разработки станут самыми мощными в мире. Эксперты полагают, что Huawei может преувеличивать свои технические возможности, но признают, что её амбиции стать мировым лидером в области искусственного интеллекта «нельзя недооценивать».  Китайский телекоммуникационный гигант Huawei сегодня анонсировал новые вычислительные системы для искусственного интеллекта на базе собственных чипов Ascend, усиливая давление на американского конкурента Nvidia. Компания заявила, что планирует запустить свой новый суперкластер на базе Atlas 950 уже в следующем году. До конца 2028 года Huawei намерена выпустить три новых поколения чипов Ascend, удваивая их мощность с каждым годом. Эти чипы составляют основу вычислительной инфраструктуры Huawei для искусственного интеллекта, в которой суперкластер объединяет несколько супермодулей, которые, в свою очередь, построены из суперузлов. В основе каждого суперузла лежат чипы Ascend. Huawei утверждает, что её новый суперузел будет поддерживать 8192 чипа Ascend 950, а суперкластер будет использовать более 500 000 таких чипов. Когда у Huawei появится более продвинутая версия ускорителя, Atlas 960, запуск которой запланирован на 2027 год, в один узел можно будет объединить 15 488 чипов, а полный суперкластер благодаря этому будет содержать более одного миллиона чипов Ascend. Пока неясно, как эти кластеры будут соотноситься с системами на базе чипов Nvidia. В пресс-релизе Huawei заявлено, что новые суперузлы станут самыми мощными в мире по вычислительной мощности в течение нескольких лет. Председатель совета директоров Huawei Эрик Сюй (Eric Xu), заявил, что суперузел на базе Atlas 950 обеспечит в 6,7 раза большую вычислительную мощность, чем система Nvidia NVL144, запуск которой также запланирован на следующий год. Сюй также пообещал, что суперкластер Atlas 950 будет обладать в 1,3 раза большей вычислительной мощностью, чем суперкомпьютер xAI Colossus Илона Маска (Elon Musk). 
Источник изображения: Huawei В апреле 2025 года исследовательская компания SemiAnalysis сообщила, что разработанная Huawei система CloudMatrix оказалась производительнее, чем Nvidia GB200 NVL72, несмотря на то, что каждый чип Ascend обеспечивал лишь около трети производительности процессора Nvidia. Huawei добилась преимущества благодаря пятикратному увеличению числа чипов. Два года назад Huawei анонсировала свой суперкластер Atlas 900. Компания развернула более 300 таких суперузлов для более чем двадцати крупных клиентов в телекоммуникационной, производственной и других отраслях. США стремятся отрезать Китай от самых передовых технологий для обучения моделей искусственного интеллекта. Чтобы справиться с этой проблемой, китайские компании стали чаще объединять большое количество менее эффективных, часто отечественных, чипов для достижения схожих вычислительных возможностей. Объявление Huawei было сделано на фоне продвижения Китаем собственных альтернатив чипам Nvidia. На днях китайский регулятор объявил о продлении расследования в отношении Nvidia в связи с предполагаемой монополистической практикой. Ранее правительство Китая настоятельно рекомендовало местным технологическим гигантам прекратить испытания и заказы на чип Nvidia RTX Pro 6000D, разработанный специально для Китая. Генеральный директор Nvidia Дженсен Хуанг (Jensen Huang) заявил, что он «разочарован» новостью об этом запрете. Ранее он называл Huawei «грозным» конкурентом. Дженсен Хуанг «разочарован», но «понимает» решение Китая о запрете импорта ускорителей Nvidia
17.09.2025 [19:30],
Сергей Сурабекянц
В августе администрация США заключила соглашение с Nvidia — компания получала лицензии на экспорт в Китай своих ИИ-чипов H20 в обмен на отчисления в размере 15 % от продаж в Китае. Однако сегодня китайские регуляторы запретили своим ведущим технологическим компаниям использовать ускорители ИИ от Nvidia. Глава компании Дженсен Хуанг (Jensen Huang) рассказал о возникших трудностях и заявил, что он «разочарован». 
Источник изображений: Nvidia Сегодня Financial Times сообщила, что «Администрация киберпространства Китая» (Cyberspace Administration of China, CAC) запретила компаниям, включая ByteDance и Alibaba, покупать видеокарты Nvidia RTX Pro 6000D, разработанные специально для этой страны. Это произошло после нескольких бурных лет для бизнеса Nvidia в Китае, который Хуанг назвал «своего рода американскими горками». Новость о запрете он прокомментировал словами «мы можем обслуживать рынок, только если страна этого хочет». Последние новости стали очередным серьёзным ударом по китайскому бизнесу Nvidia. Ранее на этой неделе Государственное управление по регулированию рынка Китая (State Administration for Market Regulation, SAMR) начало антимонопольное расследование в отношении Nvidia в связи с приобретением ею Mellanox, израильской технологической компании, разрабатывающей сетевые решения для центров обработки данных и серверов. «Мы, вероятно, внесли больший вклад в китайский рынок, чем большинство стран. И я разочарован тем, что вижу, — заявил Хуанг. — Но у них есть более глобальные вопросы взаимодействия между Китаем и США, и я их понимаю». Он подчеркнул, что ранее Nvidia рекомендовала всем финансовым аналитикам не включать Китай в финансовые прогнозы из-за сложных отношений между странами и запланированных переговоров.  Независимо от текущей геополитической ситуации, Хуанг подчеркнул важность китайского сектора искусственного интеллекта: «Китайский рынок важен. Он обширен. Технологическая индустрия динамично развивается. Мы работаем в ней уже 30 лет». Он добавил, что Nvidia «продолжит поддерживать китайское правительство и китайские компании, если они того пожелают, и мы, конечно же, продолжим поддерживать правительство США в их геополитической политике». Хуанг сопровождает президента США Дональда Трампа (Donald Trump) в его государственном визите в Великобританию на этой неделе. Вчера Nvidia объявила об инвестициях в размере £11 млрд ($15 млрд) в британскую инфраструктуру искусственного интеллекта. И она не одинока — ряд других американских технологических гигантов, включая Microsoft, Google и Salesforce, также объявили о многомиллиардном финансировании в развитие ИИ в этой стране. Alibaba разработала собственный ИИ-ускоритель — альтернатива Nvidia, но не для обучения
29.08.2025 [17:09],
Павел Котов
Китайские производители чипов и разработчики систем искусственного интеллекта при поддержке Пекина продолжают наращивать арсенал собственных технологий. Собственный ИИ-ускоритель теперь разработала Alibaba, но для обучения ИИ он не подойдёт. 
Источник изображений: alibabagroup.com Alibaba долгое время была одним из крупнейших в стране клиентов Nvidia — теперь гиганту электронной коммерции приходится заполнять пустоту, образовавшуюся с уходом американского партнёра из-за проявившегося редкого единодушия Вашингтона и Пекина. Китай пока далёк от возможности производить чипы, способные конкурировать с передовыми американскими продуктами, поставки которых власти США запретили. Китайские компании вынуждены самостоятельно разрабатывать альтернативы ускорителю Nvidia H20, самому мощному из разрешённых к экспорту. Трамп разрешил поставлять его в Китай, но уже Пекин запретил использование этих чипов, сославшись на угрозы безопасности, которых, по словам производителя, не существует. Alibaba иногда сравнивают с Amazon: китайский гигант электронной коммерции предоставляет услуги облачного провайдера, выступая конкурентом Amazon Web Services, Microsoft Azure и Google Cloud. Сейчас это направление деятельности, включая инфраструктуру для ИИ, для компании столь же важно, как и электронная коммерция. В ближайшие три года она намерена вложить в эту область не менее $53 млрд. В арсенале Alibaba значится и одно из наиболее популярных семейств моделей ИИ в мире — Qwen. Быстрое внедрение ИИ в китайскую экономику порождает высокий спрос на услуги инференса — запуска передовых моделей в облачных ресурсах. Для этой задачи, как правило, самые современные ИИ-ускорители не требуются.  Ранее Alibaba использовала для вывода ИИ чипы, разработанные для конкретных приложений. Новый ускоритель, который сейчас проходит испытания, предназначен для более широкого спектра задач в области ИИ, сообщает The Wall Street Journal со ссылкой на собственные источники. Чипы предыдущих версий для Alibaba выпускала TSMC, но Вашингтон запретил тайваньскому подрядчику производить чипы для Китая с использованием передовых технологий, поэтому новый ускоритель изготавливается китайской компанией. Местное производство передовых чипов — тоже актуальная для Пекина задача из-за американских санкций, и местные власти активно инвестируют в этом направление в стремлении сформировать самодостаточную цепочку поставок для ИИ-решений. Китайским лидером в этой области является Huawei с её ускорителями Ascend — они объединяются в вычислительные системы, превосходящие по производительности стойки с 72 ускорителями семейства Nvidia Blackwell. При этом оборудование Huawei совместимо только с собственной программной средой компании, тогда как Alibaba при разработке собственного ускорителя стремилась обеспечить совместимость с экосистемой Nvidia, и клиенты смогут использовать на новых ускорителях ПО, написанное для работы в среде американской компании. Единственный недостаток — ускорители Alibaba предназначаются для вывода, а не обучения ИИ. Nvidia представила GB300 Blackwell Ultra — мощнейший ИИ-ускоритель с 20 480 CUDA, 288 Гбайт HBM3E и PCIe 6.0
26.08.2025 [14:45],
Павел Котов
Nvidia опубликовала подробную информацию об ускорителе искусственного интеллекта GB300 Blackwell Ultra. От предшественника в лице GB200 его отличают увеличенные число ядер и объём памяти, более быстрый интерфейс и более высокая мощность. В основе Nvidia GB300 лежат два кристалла с суммарным числом 208 млрд транзисторов — они производятся по технологии TSMC 4NP и работают как единый графический процессор (GPU) за счёт интерконнекта NV-HBI со скоростью 10 Тбайт/с. 
Источник изображений: nvidia.com GPU содержит 160 потоковых мультипроцессоров (Streaming Multiprocessors), на каждый из которых приходится по 128 ядер CUDA — всего 20 480 ядер, а также тензорные ядра пятого поколения с поддержкой вычислений на числах FP8, FP6 и нового формата NVFP4. Каждый потоковый мультипроцессор располагает 256 Кбайт тензорной памяти (TMEM) — всего 40 Мбайт. Предусмотрены также дополнительные аппаратные блоки для проведения трансцендентных вычислений и операций, оптимизированных для вычислительных ядер.  Память организована в восемь 12-слойных стеков HBM3E общим объёмом 288 Гбайт. Пропускная способность памяти у Nvidia GB300 в сравнении с GB200 не изменилась — она составляет 8 Тбайт/с, будучи организованной в 16 каналов по 512 бит (8192-битный интерфейс). Увеличенный объём памяти позволяет размещать на чипе ИИ-модель целиком, а также хранить большие объёмы кеша ключей и значений без выгрузки во внешние ресурсы. Показатель TGP вырос до 1400 Вт.  За связь между графическими процессорами отвечает интерфейс NVLink 5 с двунаправленной скоростью передачи данных 1,8 Тбайт/с на каждый GPU. Связь между GPU и центральным процессором Grace реализована через интерфейс NVLink-C2C со скоростью 900 Гбайт/с и поддержкой единого адресного пространства. Для подключения к хосту используется шина PCIe 6.0 x16 с двунаправленной полосой пропускания 256 Гбайт/с — этот интерфейс Nvidia применила впервые. Ускорители могут устанавливаться в стойку GB300 NVL72 с 72 графическими процессорами, до 20,7 Тбайт памяти HBM3E и общей полосой пропускания HBM 576 Тбайт/с. На стойку также приходится 72 Arm-ядра Grace Superchip и до 480 Гбайт LPDDR5X с полосой пропускания 512 Гбайт/с. NVFP4 — это новый формат данных с низкой точностью, реализованный в тензорных ядрах. Он обеспечивает точность, сравнимую с FP8, но позволяет использовать в 1,8 раза меньше памяти. Массовое производство ускорителей Nvidia GB300 уже стартовало, и первые клиенты их получили. Мобильная графика Arm станет производительнее — в GPU встроят нейронные ускорители
12.08.2025 [17:58],
Сергей Сурабекянц
Arm сообщила, что следующее поколение её мобильных графических процессоров, которое выйдет в 2026 году, будет использовать нейронные технологии, обеспечивающие более высокое качество изображения и повышенную производительность. Компания также представила программный интерфейс (API) для разработчиков, чтобы они могли начать работу с ним уже сегодня, не дожидаясь появления нового оборудования. 
Источник изображений: Arm В первую очередь Arm рассматривает использование нейронного ускорения для масштабирования графики до более высокого разрешения без ущерба для производительности. Среди других предполагаемых сценариев — удвоение частоты кадров с помощью интерполяции и повышение качества изображения за счёт трассировки пути в реальном времени на мобильных устройствах с меньшим количеством лучей на пиксель. «Поскольку ИИ всё больше сливается с графикой реального времени, нам необходим ИИ на базе графических процессоров, который был бы интегрированным, производительным и, что особенно важно, энергоэффективным. Упрощение разработки ИИ на графических процессорах для разработчиков стало движущей силой технических инноваций, о которых мы здесь говорим», — заявил научный сотрудник Arm в области ИИ и платформ для разработчиков Герайнт Норт (Geraint North). Arm отказалась раскрывать подробную техническую информацию о нейронных ускорителях до анонса следующего поколения графических процессоров Mali. Известно лишь, что они будут размещаться в шейдерных ядрах, а производительность нейросетей будет масштабироваться в зависимости от их количества в конкретной реализации GPU. Архитектура Arm пятого поколения предусматривает конфигурации вплоть до 16 ядер. В прошлом году Arm анонсировала технологию масштабирования Arm Accuracy Super Resolution (Arm ASR), позволяющую игре рендерить изображение с более низким разрешением и применять алгоритм масштабирования, снижая затраты на обработку кадра при сохранении качества. Новая технология Neural Super Sampling (NSS) на базе аппаратного нейронного ускорителя способна масштабировать картинку с 540p до 1080p за 4 мс на кадр и снижать нагрузку на графический процессор на 50 %.  «Рендеринг в реальном времени с использованием искусственного интеллекта быстрее, чётче и энергоэффективнее. Таким образом, NSS может создавать выходные данные того же качества с использованием входных данных более низкого качества или даже более высокого качества с теми же входными данными», — заявил Норт. Arm также представила технологии Neural Frame Rate Upscaling (NFRU) и Neural Super Sampling and Denoising (NSSD). NFRU повышает частоту кадров путём создания промежуточного кадра из двух последовательных кадров. «Нейронная сеть также тесно связана с новым оборудованием, которое мы добавим к нашим графическим процессорам для ускорения генерации векторов движения, отслеживающих перемещение пикселей между кадрами. Это позволит очень дёшево масштабировать контент, работающий с частотой 30 кадров в секунду, до 60 кадров в секунду», — пояснил Норт. Технология NSSD предназначена для обеспечения качества изображения трассировки пути, которая, по словам Норта, слишком затратна с точки зрения вычислительных ресурсов даже на настольных системах: «Когда вы объединяете трассировку пути с нейронной сетью, вы фактически можете проецировать лишь небольшое количество лучей на пиксель в сцену, и вы можете использовать нейронную технологию для добавления недостающих деталей. Таким образом, нейронная сеть может экстраполировать данные не только из соседних пикселей, но и из предыдущих кадров». Все эти новшества доступны разработчикам уже сегодня благодаря набору инструментов для разработки нейронной графики. В комплект входят плагины для Unreal Engine, позволяющие интегрировать нейронный суперсэмплинг в игру «всего за несколько кликов». Модели доступны в открытых форматах на GitHub и Hugging Face. Также доступна полная эмуляция расширений Arm ML Vulkan для ПК, что позволяет программистам использовать весь стек приложений, не дожидаясь выпуска мобильных чипов.  Arm — не первая компания, внедряющая нейронные технологии в чипы смартфонов. В частности, ИИ уже широко используется для управления функциями камеры. Компания Qualcomm, лицензиат Arm, расширяет возможности искусственного интеллекта своих смартфонных платформ благодаря нейронным процессорам (NPU). На прошлогодней выставке MWC компания Qualcomm продемонстрировала большую языковую модель с 7 млрд параметров, работающую на Android-смартфоне, и представила свой AI Hub для разработчиков. Nvidia представила крошечные видеокарты RTX Pro 4000 SFF и RTX Pro 2000 для профессионалов
11.08.2025 [19:35],
Николай Хижняк
Nvidia расширила ассортимент профессиональных видеокарт поколения Blackwell, представив модели RTX Pro 4000 SFF и RTX Pro 2000 на конференции SIGGRAPH 2025. Эти видеокарты дополняют линейку решений Nvidia для рабочих станций. Помимо повышенной производительности по сравнению с моделями предыдущего поколения, новинки также оптимизированы для ускорения задач ИИ, что делает их актуальными для различных рабочих процессов в самых разных отраслях. 
Источник изображений: Nvidia Модель RTX Pro 4000 Blackwell SFF — это уменьшенная версия уже доступной видеокарты RTX 4000 Blackwell. Компания утверждает, что новинка обеспечивает более чем двукратный прирост производительности в задачах ИИ по сравнению с RTX A4000 SFF предыдущего поколения, предлагая при этом улучшенные возможности трассировки лучей и на 50 % увеличенную пропускную способность. При этом уровень энергопотребления остался на прежнем уровне — 70 Вт. Благодаря 24 Гбайт памяти ECC GDDR7 и заявленной производительности 770 TOPS в задачах ИИ, эта видеокарта может стать отличным выбором для профессионалов, которым требуется высокая вычислительная мощность в составе компактной рабочей станции.  Новая модель RTX Pro 2000 оснащена 16 Гбайт памяти ECC GDDR7 и предлагает производительность до 545 TOPS в задачах ИИ при том же уровне энергопотребления — 70 Вт. По заявлению Nvidia, карта разработана для массового дизайна и рабочих процессов с применением искусственного интеллекта. Новинка примерно в 1,5 раза быстрее модели Nvidia RTX A2000 в задачах 3D-моделирования, автоматизированного проектирования и рендеринга. Кроме того, она обеспечивает более высокую эффективность при генерации изображений и текста с помощью ИИ. Точные характеристики и стоимость моделей RTX Pro 4000 SFF и RTX Pro 2000 в рамках презентации Nvidia не раскрыла. Ожидается, что видеокарты поступят в продажу в конце текущего года. RTX Pro 2000 будет доступна у компаний PNY и TD Synnex как отдельное решение, а также появится у системных интеграторов Boxx, Dell, HP и Lenovo в составе готовых рабочих станций. RTX Pro 4000 SFF будет предлагаться в системах от партнёров Nvidia, включая Dell, HP и Lenovo. AMD по примеру Nvidia возобновит поставки своих ИИ-ускорителей Instinct в Китай
15.07.2025 [21:05],
Николай Хижняк
Представитель AMD в разговоре с порталом Tom’s Hardware подтвердил, что компания возобновит поставки ИИ-ускорителей MI308 в Китай. Это специализированная модификация ускорителей серии Instinct MI300, разработанная специально для соответствия экспортным правилам, установленным Министерством торговли США. 
Источник изображения: AMD Ранее сегодня глава Nvidia Дженсен Хуанг (Jensen Huang) публично подтвердил, что компания немедленно приступает к подготовке возобновления продаж своих ИИ-ускорителей Hopper H20 в Китае. Nvidia рассчитывает получить разрешение на продажу этих специализированных GPU, изготовленных по индивидуальному заказу, после того как в апреле они были запрещены к продаже в Китае обновлёнными экспортными правилами США. AMD и Nvidia ясно дали понять, что китайский рынок критически важен для их бизнеса, поскольку они разрабатывают специализированные GPU для центров обработки данных с учётом ограничений правительства США. Однако проектирование и выпуск таких вариантов графических чипов — процесс небыстрый: их разработка, производство, сборка и настройка занимают месяцы. После завершения разработки и установки необходимой прошивки устройства фактически становятся программно заблокированными в соответствии с экспортными ограничениями, что часто затрудняет их продажу за пределами рынков, для которых эти ограничения были введены. «Мы планируем возобновить поставки, как только получим одобрение по лицензии. Министерство торговли недавно сообщило нам, что заявки на получение лицензий на экспорт продукции MI308 в Китай будут переданы на рассмотрение», — заявил представитель AMD в разговоре с Tom’s Hardware. Обе компании оказались под давлением в связи с масштабным экспортным контролем на поставки технологий, связанных с ИИ, введённым ещё предыдущей администрацией президента США Джо Байдена и продолженным нынешней администрацией президента Дональда Трампа. Последняя, хоть и сузила ограничения, всё же включила в список запрещённых к поставке чипов такие модели, как H20 и MI308. Согласно оценке AMD, экспортные ограничения могут обойтись ей примерно в $800 млн в виде нераспроданных запасов, невыполненных обязательств по заказам и оставшихся резервов. Хотя это значительно меньше, чем масштабное списание Nvidia в размере $5,5 млрд, потери всё же заметно ударят по чистой прибыли AMD. После сегодняшнего объявления акции AMD подскочили на 5,7 % вслед за аналогичным ростом акций Nvidia. Один сбитый бит — и всё пропало: атака GPUHammer на ускорители Nvidia ломает ИИ с минимальными усилиями
15.07.2025 [00:07],
Николай Хижняк
Команда исследователей из Университета Торонто обнаружила новую атаку под названием GPUHammer, которая может инвертировать биты в памяти графических процессоров Nvidia, незаметно повреждая модели ИИ и нанося серьёзный ущерб, не затрагивая при этом сам код или входные данные. К счастью, Nvidia уже опередила потенциальных злоумышленников, которые могли бы воспользоваться этой уязвимостью, и выпустила рекомендации по снижению риска, связанного с этой проблемой. 
Источник изображения: Nvidia Исследователи продемонстрировали, как GPUHammer может снизить точность модели ИИ с 80 % до менее 1 % — всего лишь инвертируя один бит в памяти. Они протестировали уязвимость на реальной профессиональной видеокарте Nvidia RTX A6000, используя технику многократного инжектирования ячеек памяти до тех пор, пока одна из соседних ячеек не инвертируется, что нарушает целостность хранящихся в ней данных. GPUHammer — это версия известной аппаратной уязвимости Rowhammer, ориентированная на графические процессоры. Это явление уже давно существует в мире процессоров и оперативной памяти. Современные микросхемы памяти настолько плотно упакованы, что многократное чтение или запись одной строки может вызвать электрические помехи, которые переворачивают (инвертируют) биты в соседних строках. Этим перевернутым битом может быть что угодно — число, команда или часть веса нейронной сети. До сих пор эта уязвимость в основном касалась системной памяти DDR4, но GPUHammer продемонстрировала свою эффективность с видеопамятью GDDR6, которая используется во многих современных видеокартах Nvidia. Это серьёзная причина для беспокойства, по крайней мере, в определённых ситуациях. Исследователи показали, что даже при наличии некоторых мер защиты они могут вызывать множественные перевороты битов в нескольких банках памяти. В одном случае это полностью сломало обученную модель ИИ, сделав её практически бесполезной. Примечательно, что для этого даже не требуется доступ к данным. Злоумышленнику достаточно просто использовать тот же графический процессор в облачной среде или на сервере, и он потенциально может вмешиваться в вашу рабочую нагрузку по своему усмотрению. Исследователи протестировали метод атаки на карте RTX A6000, но риску подвержен широкий спектр графических процессоров Ampere, Ada, Hopper и Turing, особенно тех, что используются в рабочих станциях и серверах. Nvidia опубликовала полный список уязвимых моделей ускорителей и рекомендует использовать функцию коррекции ошибок ECC для решения большинства из них. При этом новые графические процессоры, такие как RTX 5090 и серверные H100, имеют встроенную ECC непосредственно на GPU, и она работает автоматически — настройка пользователем не требуется. Данная уязвимость не затрагивает обычных пользователей домашних ПК. Она актуальна для общих сред графических процессоров, таких как облачные игровые серверы, кластеры обучения ИИ или конфигурации VDI, где несколько пользователей запускают рабочие нагрузки на одном оборудовании. Тем не менее угроза реальна и должна быть серьезно воспринята всей индустрией, особенно с учётом того, что всё больше игр, приложений и сервисов начинают в той или иной мере использовать ИИ. Рекомендация Nvidia сводится к использованию функции ECC. Её можно включить с помощью командной строки Nvidia, введя команду Атаки, подобные GPUHammer, не просто приводят к сбоям в работе систем или вызывают сбои. Они нарушают целостность самого ИИ, влияя на поведение моделей или принятие решений. И поскольку всё это происходит на аппаратном уровне, эти изменения практически незаметны, особенно если не знать, что именно и где искать. В регулируемых отраслях, таких как здравоохранение, финансы или автономный транспорт, это может привести к серьёзным проблемам — неверным решениям, нарушениям безопасности и даже юридическим последствиям. Nvidia выпустит ИИ-ускоритель B30 специально для Китая взамен запрещённого H20
02.06.2025 [16:52],
Дмитрий Федоров
Nvidia разрабатывает специализированный ИИ-ускоритель B30, соответствующий требованиям экспортного контроля США и предназначенный для поставок в Китай. Новый графический ускоритель (GPU) построен на архитектуре Blackwell и, вероятно, получит поддержку NVLink для объединения нескольких GPU в вычислительные кластеры. Эта разработка стала прямым ответом Nvidia на запрет, введённый правительством США на экспорт в КНР чипов линейки H20 на архитектуре Hopper. 
Источник изображений: Nvidia Главная особенность будущего B30 — поддержка масштабирования через объединение нескольких GPU. Эта функция, по мнению аналитиков, может быть реализована либо с применением технологии NVLink, либо посредством сетевых адаптеров ConnectX-8 SuperNIC с поддержкой PCIe 6.0. Несмотря на то, что Nvidia официально исключила NVLink из потребительских GPU начиная с предыдущего поколения, существует вероятность, что компания модифицировала кристаллы GB202, используемые в RTX 5090, и повторно активировала NVLink в их серверной конфигурации. Изначально будущий GPU фигурировал под различными названиями — от RTX Pro 6000D до B40, а теперь B30. Это, вероятно, указывает на наличие нескольких вариантов в рамках новой серии BXX, различающихся по уровню производительности и соответствию требованиям экспортного регулирования. Все модификации предполагается строить на чипах GB20X с использованием памяти GDDR7. Примечательно, что GB20X — это те же кристаллы, которые лежат в основе потребительских видеокарт линейки RTX 50. Таким образом, Nvidia не создаёт принципиально новый чип, а адаптирует уже существующую архитектуру для обхода ограничений. 
Nvidia RTX PRO 6000 Blackwell Workstation Edition На выставке Computex в Тайбэе Nvidia представила серверные системы RTX Pro Blackwell, рассчитанные на установку до восьми GPU RTX Pro 6000. Эти ускорители соединяются между собой через сетевые адаптеры ConnectX-8 SuperNIC, оснащённые встроенными PCIe 6.0-коммутаторами, обеспечивающими прямое взаимодействие между GPU. Та же схема коммуникации применяется при объединении двух суперчипов DGX Spark, которые служат основой для корпоративных и облачных ИИ-решений. Вероятнее всего, аналогичная архитектура будет использована и в B30. Комментируя запрет на экспорт H20, бессменный руководитель Nvidia Дженсен Хуанг (Jensen Huang) подчеркнул, что компания прекращает разработку альтернатив на архитектуре Hopper и сосредотачивается на Blackwell. Правительство США, в свою очередь, заявило, что у H20 — слишком высокая пропускная способность памяти и интерфейсных соединений, что делает чип неприемлемым для свободного экспорта. Эти параметры, по мнению регуляторов, создают риск использования ускорителей в составе китайских суперкомпьютеров, способных обслуживать оборонные и военные программы. 
Nvidia H200 Tensor Core GPU Ситуация с экспортными ограничениями не ограничивается только Nvidia. Американские регуляторы оказывают серьёзное влияние на весь рынок высокопроизводительных ИИ-решений. Компания AMD, например, оценивает потенциальные убытки от запрета на экспорт ускорителей MI308 в размере до $800 млн. Эта оценка была представлена сразу после вступления в силу новых ограничений. На протяжении последних лет Nvidia ведёт постоянную борьбу с регуляторами, сталкиваясь с чередой запретов и требований, где каждое новое поколение чипов, от A100 до H100 и H20, подвергается новым формам контроля. Хуанг, критикуя действующую экспортную политику США, назвал её «провалом» и предупредил о рисках стратегического отставания. По его мнению, такие меры лишь подталкивают китайские технологические компании, включая Huawei, к активному развитию собственных ИИ-решений. В результате они могут не только догнать, но и перегнать американских техногигантов, сформировав собственные стандарты, которые в будущем могут стать основой глобальной ИИ-инфраструктуры. Это создаёт угрозу потери влияния США не только в технологической, но и в военно-стратегической сфере. Intel представила профессиональные видеокарты Arc Pro B60 и Arc Pro B50, и возможно двухчиповую версию B60
19.05.2025 [16:32],
Николай Хижняк
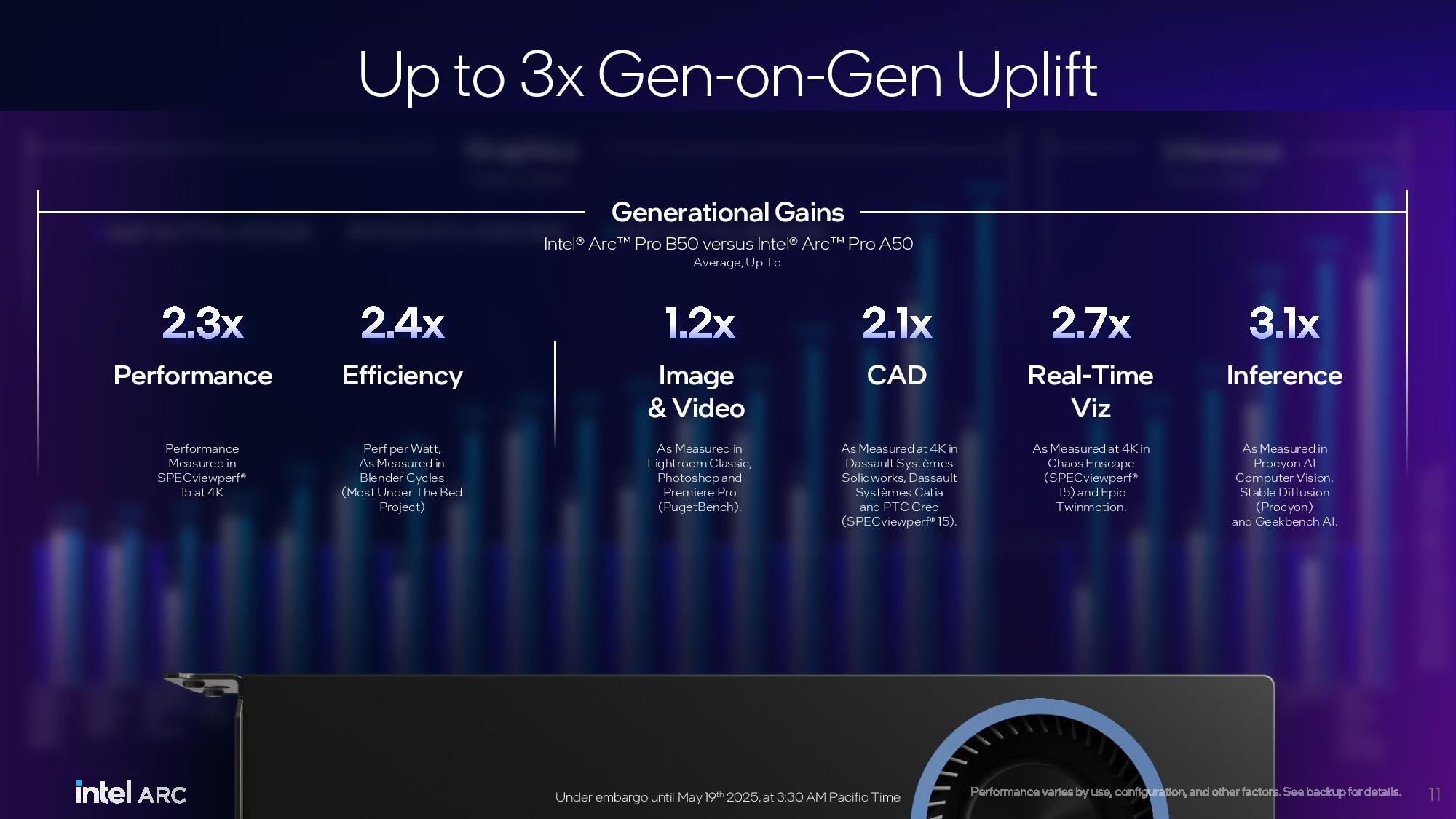
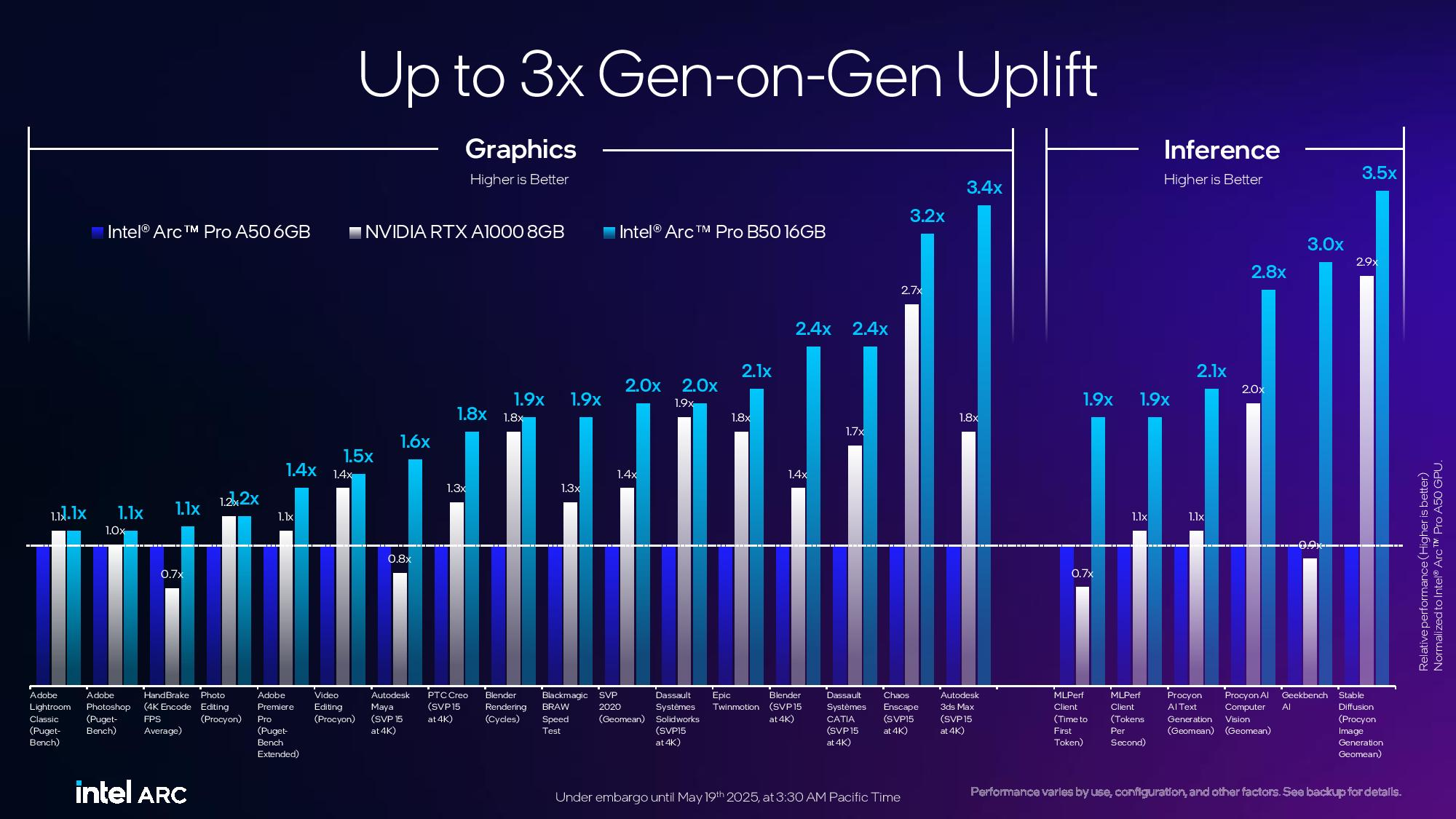
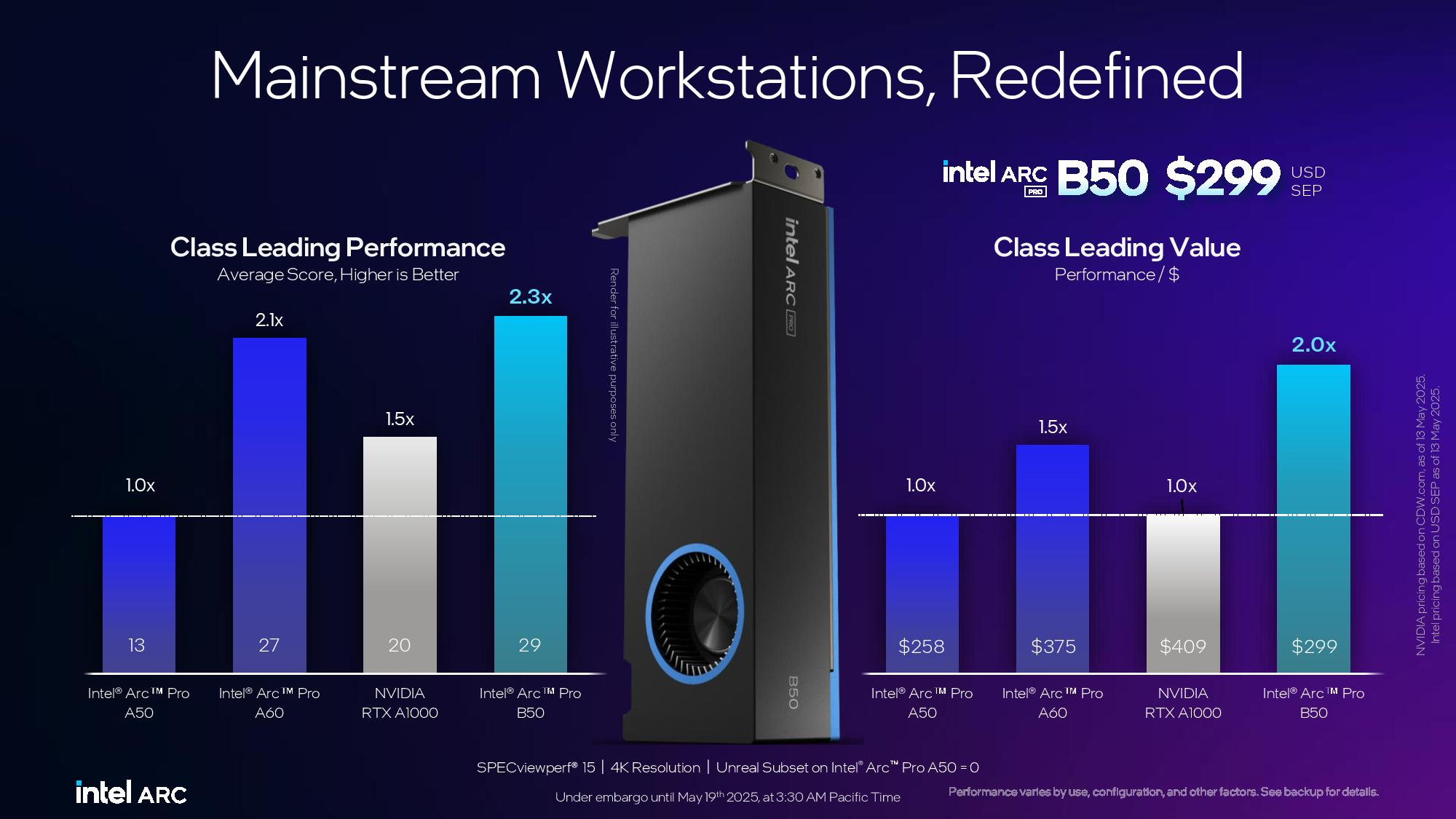
Компания Intel представила профессиональные видеокарты Arc Pro B50 и Arc Pro B60 для рабочих станций. Старшая модель оснащена 24 Гбайт памяти, младшая — 16 Гбайт. Производитель также анонсировал рабочую станцию под названием Battlematrix, которая соединит в себе до восьми графических процессоров Arc Pro B60 — вероятно, в двухчиповой конфигурации. 
Источник изображений: Tom's Hardware / Intel В основе Arc Pro B60 используется полноценный графический чип BGM-G21 с 20 ядрами Xe2-HPG, 20 блоками трассировки лучей и 160 матричными движками (XMX). Карта получила 24 Гбайт памяти GDDR6 со скоростью 19 Гбит/с на контакт, 192-битной шиной и пропускной способностью 456 Гбайт/с.  Для работы новинка использует восемь линий PCIe 5.0. Набор внешних видеоразъёмов будет варьироваться в зависимости от производителя. Производительность Inel Arc Pro B60 в разных нагрузках
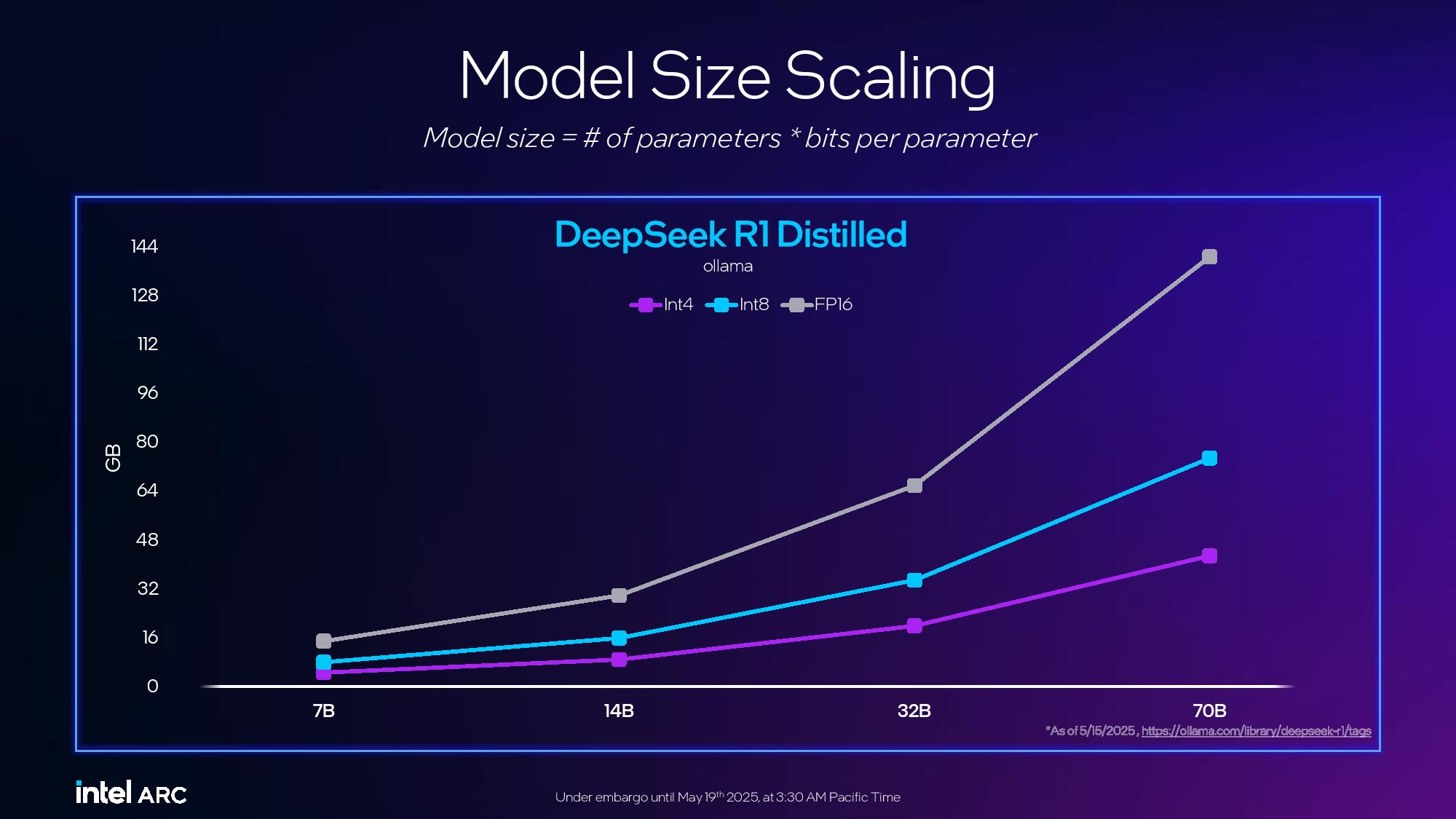
Смотреть все изображения (3)
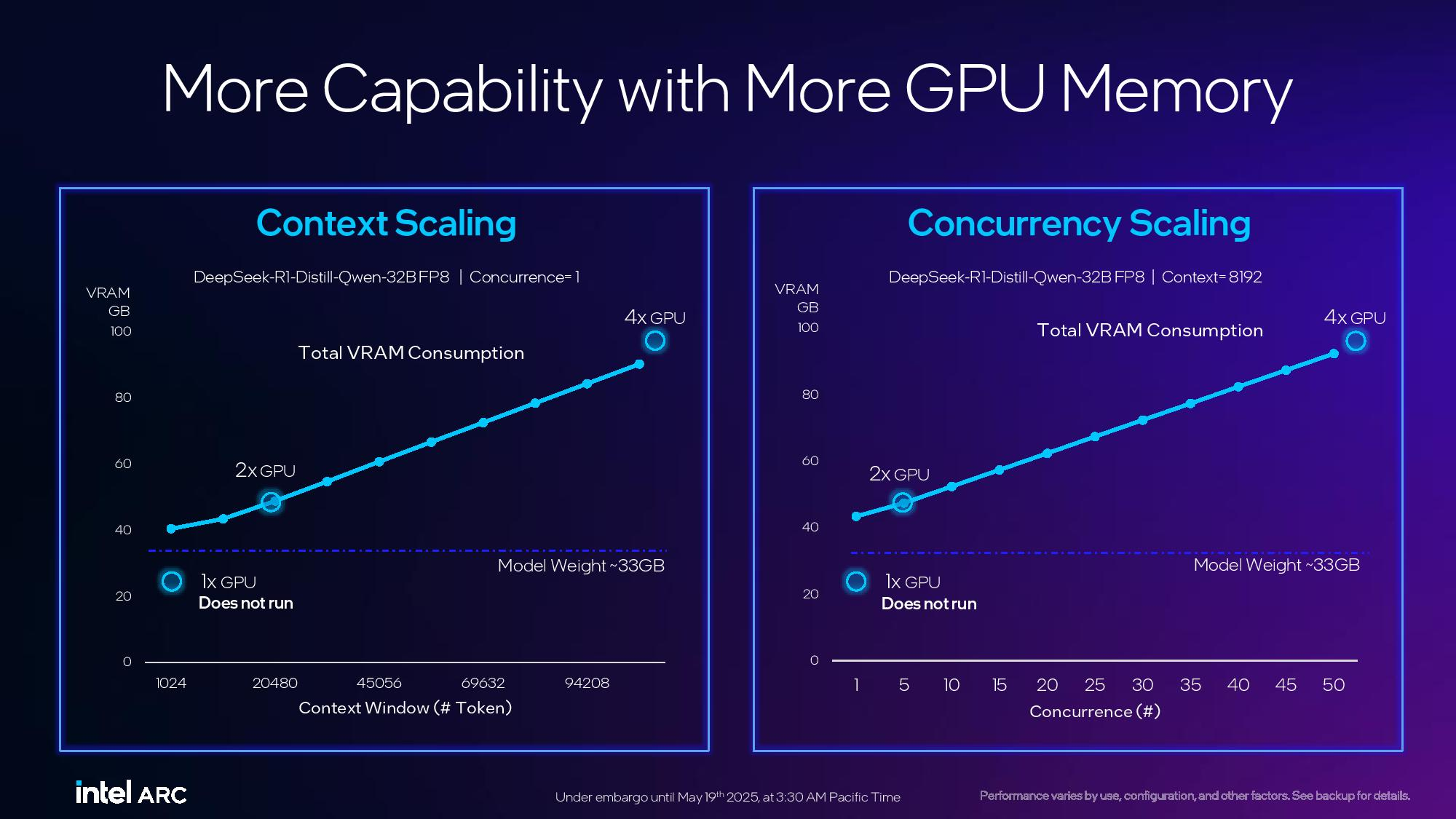
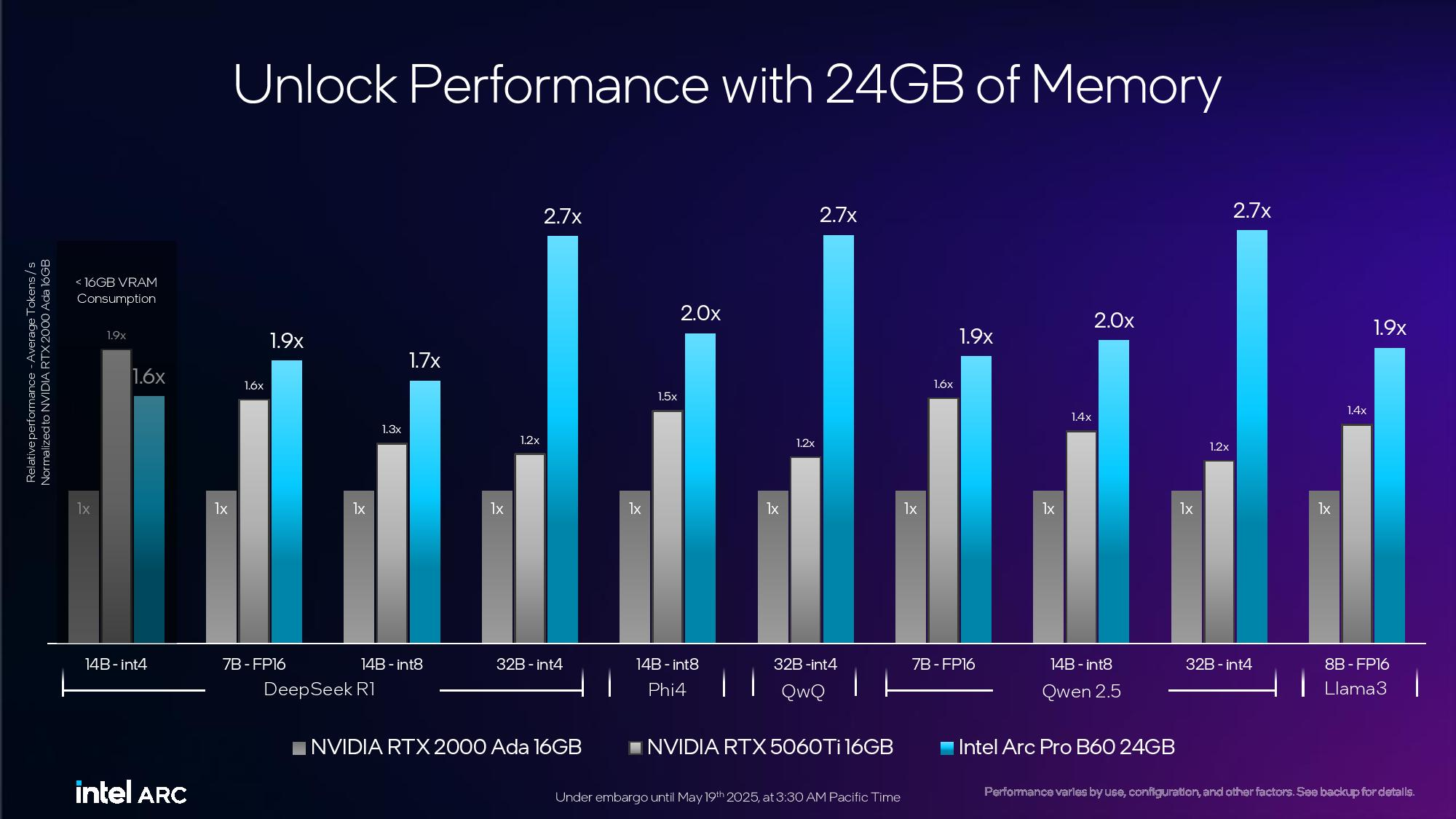
Смотреть все изображения (3) По словам Intel, Arc Pro B60 обеспечивает до 197 TOPS производительности в 8-битных целочисленных операциях (INT8). Энергопотребление карты заявлено в диапазоне от 120 до 200 Вт (в зависимости от конкретной модели партнёра). В своих внутренних тестах компания подчёркивает преимущество 24 Гбайт памяти у Arc Pro B60 по сравнению с конкурентами — RTX 200 Ada 16 Гбайт и RTX 5060 Ti 16 Гбайт от Nvidia, утверждая, что это обеспечивает превосходство до 2,7 раза при работе с различными ИИ-моделями. Также подчёркиваются преимущества большей ёмкости памяти с учётом объёма моделей, сценариев использования и масштабирования параллелизма. Модель Arc Pro B50 включает графический процессор BGM-G21 с 16 ядрами Xe2-HPG, 16 блоками трассировки лучей и 128 матричными движками (XMX).  Карта оснащена 16 Гбайт памяти GDDR6 со скоростью 19 Гбит/с на контакт, 128-битной шиной и пропускной способностью 224 Гбайт/с. В задачах INT8 она обеспечивает производительность до 170 TOPS. Энергопотребление карты составляет 70 Вт. Набор внешних видеоразъёмов включает четыре mini-DisplayPort 2.1. Для подключения используется 8 линий PCIe 5.0. Производительность Intel Arc Pro B50 в разных нагрузках
Компания заявляет, что Arc Pro B50 демонстрирует в графических задачах до 3,4 раза более высокую производительность по сравнению с предшественником A50. В качестве основного конкурента Intel выделяет Nvidia RTX 1000.  Что касается проекта Battlematrix, то судя по иллюстрации, а также анонсу китайской компании MaxSun, в системах будут использованы карты с двумя графическими процессорами Arc Pro B60 и 48 Гбайт памяти. Это даст до 192 Гбайт видеопамяти на одну машину. Также в этих системах будут использоваться процессоры Intel Xeon. О проекте Intel Battlematrix
Стоимость подобных рабочих станций будет варьироваться от $5000 до $10 000. Компания отмечает, что рабочие станции Battlematrix предназначены для работы с ИИ-моделями с более чем 70 млрд параметров. Примеры рабочих станций Intel Battlematrix от партнёров
Arc Pro B50 компания Intel оценила в $299, тогда как Arc Pro B60 будет стоит около $500. Оба ускорителя станут доступны в третьем квартале текущего года в составе готовых рабочих станций. Однако в четвёртом квартале года карты также ожидаются в виде самостоятельных продуктов. Профессиональная видеокарта Nvidia RTX Pro 6000 Blackwell Workstation Edition с 96 Гбайт GDDR7 поступила в продажу за €9000
05.05.2025 [16:36],
Николай Хижняк
Компания Nvidia пока официально не объявляла о старте продаж профессиональной видеокарты RTX Pro 6000 Blackwell Workstation Edition, однако, как сообщает VideoCardz, она уже появилась у некоторых ритейлеров. В марте компания представила новинку вместе с моделью RTX Pro 6000 Blackwell Server Edition с 96 Гбайт памяти GDDR7 — специализированной версией для серверов. 
Источник изображений: Reddit Как и ожидалось, RTX Pro 6000 Blackwell Workstation Edition оказалась очень дорогой. Новинку удалось найти по цене €8982 (включая НДС 21 %). Карта появилась в базах данных многих европейских и канадских ритейлеров, что может свидетельствовать о её поставках в эти регионы в преддверии официального запуска продаж. 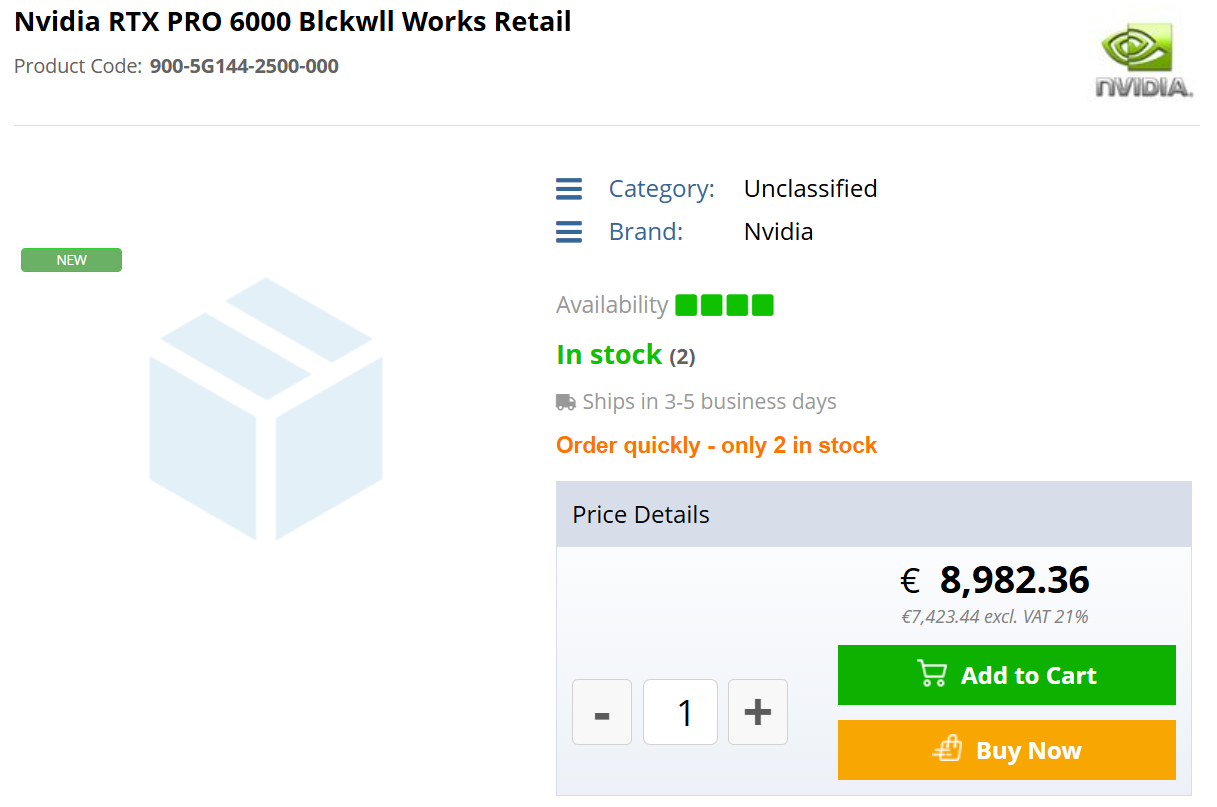
RTX Pro 6000 Blackwell Workstation Edition у ретейлеров в Европе  Один из пользователей Reddit приобрёл RTX Pro 6000 Blackwell Workstation Edition и опубликовал её фотографии. По его словам, видеокарта была куплена с использованием гранта в размере $5000. Однако даже с учётом этого её стоимость оказалась выше, чем у игрового флагмана RTX 5090, который в настоящий момент продаётся примерно за $3000.  В основе RTX Pro 6000 Blackwell Workstation Edition используется графический процессор GB202 с 24 064 ядрами CUDA и 96 Гбайт памяти GDDR7 с поддержкой ECC. Энергопотребление заявлено на уровне 600 Вт. Помимо RTX Pro 6000 Blackwell Workstation Edition и RTX Pro 6000 Blackwell Server Edition, компания Nvidia также выпустит модель RTX Pro 6000 Blackwell Max-Q Edition с энергопотреблением 300 Вт. 
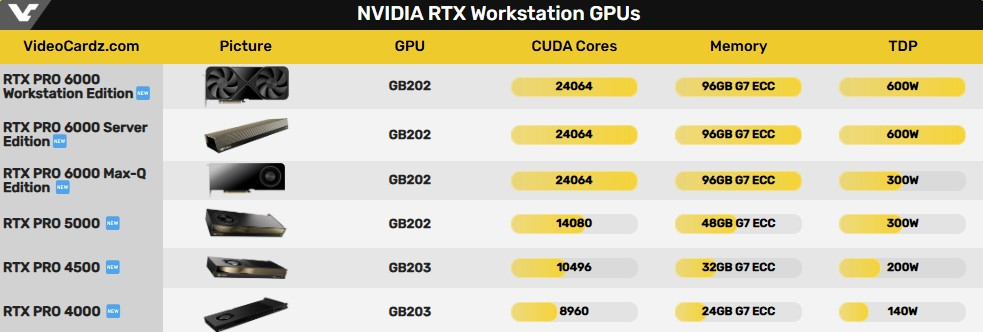 У AMD пока нет альтернатив этим картам. Кроме того, не поступало сообщений о планах компании выпустить профессиональный ускоритель с 96 Гбайт памяти. Архитектура Navi 4 поддерживает шину памяти шириной до 256 бит и не была замечена в конфигурациях с памятью GDDR7. На рынке также отсутствуют 3-Гбайт чипы памяти GDDR6, что делает аналогичную конфигурацию маловероятной в текущем поколении ускорителей AMD. Другими словами, серия RTX Pro 6000 остаётся единственным настольным GPU с таким объёмом памяти. Nvidia придумала, как законно обойти антикитайские санкции, и продолжит поставки ИИ-ускорителей в Китай
02.05.2025 [22:24],
Анжелла Марина
После ужесточения санкций со стороны США и запрета на поставку в Китай ИИ-ускорителя H20, Nvidia оказалась в сложной ситуации и вынуждена пересмотреть стратегию работы с ключевым китайским рынком, чтобы избежать нарушений экспортных ограничений. Компания ведёт переговоры с Alibaba, ByteDance и Tencent о поставках адаптированных чипов. 
Источник изображения: Mariia Shalabaieva / Unsplash По сообщению Reuters, генеральный директор компании Дженсен Хуан (Jensen Huang) лично проинформировал партнёров о новых разработках во время своего визита в Пекин в середине апреля. Эта поездка состоялась вскоре после того, как США ограничили экспорт в Китай чипов H20 (специализированный вариант H100) для задач искусственного интеллекта. По оценкам самой Nvidia, новые экспортные ограничения могут лишить компанию $5,5 млрд выручки, и чтобы минимизировать потери, разрабатываются чипы, которые формально соответствовали бы американским требованиям, но при этом сохраняли бы высокую производительность. Параллельно ведётся работа над «китайской» версией новейшего процессора Blackwell. Китайский рынок остаётся критически важным для Nvidia, поэтому компания ищет любые способы сохранить там своё присутствие. Ранее она уже выпускала «урезанные» версии чипов для этого региона, но новые санкции требуют более сложных технических решений, над чем сейчас и трудятся инженеры. Сообщается, что первые образцы ИИ-ускорителей поступят китайским клиентам уже в июне, а китайская версия Blackwell — немного позже. Представители Nvidia отказались комментировать эту информацию. Компании ByteDance, Alibaba и Tencent, а также Министерство торговли США не ответили на запросы Reuters. |
© 1997—2025 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews. kz
![]()
![]()








 MWC 2018
MWC 2018 2018
2018 Computex
Computex