|
Опрос
|
реклама
Быстрый переход
В Китае подоспела замена ИИ-чипам Nvidia: Huawei начнёт отгрузки Ascend 910C в мае
22.04.2025 [00:44],
Анжелла Марина
Компания Huawei Technologies планирует уже в следующем месяце начать массовые поставки своего усовершенствованного ИИ-ускорителя Ascend 910C на внутренний рынок китайским клиентам. Единичные отгрузки чипов уже состоялись и, как отмечает Reuters, планы компании совпадают с ключевым моментом — китайские разработчики остались без доступа к современным чипам Nvidia из-за новых экспортных ограничений США. 
Источник изображения: Huawei Technologies С начала апреля администрация президента США Дональда Трампа (Donald Trump) потребовала, чтобы Nvidia получила экспортную лицензию на поставки в Китай своего чипа H20, который был одним из немногих, разрешённых к свободной продаже в Поднебесной. Теперь китайские компании вынуждены искать внутренние альтернативы, и Huawei со своим новым чипом может занять освободившуюся нишу. Huawei Ascend 910C представляет собой графический процессор (GPU), который, по словам экспертов, достигает уровня производительности, сопоставимого с Nvidia H100. Это стало возможным благодаря объединению двух чипов 910B в одном корпусе с использованием современных технологий интеграции. Уточняется, что новинка обладает вдвое большей вычислительной мощностью и объёмом памяти по сравнению с предыдущей моделью, а также улучшенной поддержкой различных типов нагрузок, связанных с работой искусственного интеллекта (ИИ). Хотя Huawei официально отказывается комментировать планы по поставкам и не раскрывает технические характеристики 910C, эксперты считают, что чип может стать основным выбором китайских разработчиков ИИ-моделей в условиях усилившегося технологического давления со стороны США. Как стало известно Reuters, Huawei ещё в конце прошлого года разослала тестовые образцы Ascend 910C технологическим компаниям и начала принимать заказы. Однако какие именно предприятия производят новый чип, пока неизвестно. По данным источников, часть компонентов изготавливает китайская SMIC по 7-нанометровой технологии, но с низким процентом выхода годных чипов. Также выяснилось, что некоторые GPU 910C содержат полупроводники, произведённые тайваньской компанией TSMC для китайской Sophgo. В связи с этим Министерство торговли США начало расследование, поскольку TSMC с 2020 года официально не сотрудничает с Huawei. По данным исследователя из Центра технологий, безопасности и политики RAND в Арлингтоне (США) Леннарта Хайма (Lennart Heim), TSMC выпустила всего около трёх миллионов чипов по заказу Sophgo. Huawei отрицает использование чипов TSMC в своих процессорах. Sophgo не прокомментировала ситуацию, а TSMC заявила о полном соблюдении экспортных ограничений. AMD анонсировала мероприятие Advancing AI, на котором представит ИИ-ускорители Instinct MI355X
10.04.2025 [13:24],
Николай Хижняк
Компания AMD запланировала проведение мероприятия Advancing AI на 12 июня. На нём будут представлены специализированные ускорители Instinct нового поколения. Компания также пообещала обновления для своей платформы Radeon Open Compute Platform (ROCm), предназначенной для высокопроизводительных вычислений (HPC) и задач искусственного интеллекта. 
Источник изображения: AMD От AMD ожидается анонс ИИ-ускорителей Instinct MI355X. Ранее компания заявляла, что этот продукт будет выпущен во второй половине 2025 года. В составе ускорителей будут использоваться графические процессоры на архитектуре CDNA 4, производимые по 3-нм техпроцессу, а также до 288 Гбайт памяти HBM3e. Возможно, компания также поделится свежими подробностями об ускорителях Instinct MI400, выход которых намечен на 2026 год. Они станут первыми ИИ-ускорителями AMD, использующими память HBM4. AMD проведёт прямую трансляцию мероприятия Advancing AI 12 июня в 9:30 по тихоокеанскому времени (19:30 мск). Вести мероприятие будет глава компании AMD Лиза Су (Lisa Su). Китай ударит по Nvidia новыми экологическими нормами — компания потеряет до $17 млрд выручки в год
26.03.2025 [12:42],
Павел Котов
Китайские власти ввели новые нормы энергоэффективности при использовании передовых чипов — из-за них китайские компании могут лишиться возможности покупать самые продаваемые в Китае ускорители Nvidia. Самой компании эти правила грозят потерей выручки в размере $17 млрд в год, пишет Financial Times. 
Источник изображения: nvidia.com Государственный комитет по развитию и реформам КНР рекомендует использовать в новых центрах обработки данных и при расширении существующих объектов чипы, отвечающие строгим требованиям, и ускорители Nvidia H20, которые производятся специально для Китая в соответствии с американскими санкциями, этим требованиям не соответствуют. В последние месяцы китайские власти негласно отговаривали местных технологических гигантов, в том числе Alibaba, ByteDance и Tencent от закупки H20; сейчас эти нормы не соблюдаются по всей строгости и пока не повлияли на продажи ускорителей данной модели. Но если ведомство решит ужесточить запрет, это создаст угрозу для бизнеса Nvidia в стране, где годовой оборот компании составляет $17 млрд. Китай активно строит новые ЦОД, и американский производитель рискует растерять заказы, которые уйдут местным конкурентам, в том числе Huawei, чья продукция в большей мере соответствует повестке Пекина. В попытке избежать реализации неблагоприятного сценария руководство Nvidia стремится в ближайшие месяцы провести встречу с главой комитета Чжэном Шаньцзе (Zheng Shanjie). Новые нормы были введены ещё в прошлом году, ранее о них не сообщалось — они возникли на фоне торговой напряжённости между США и Китаем, соревнующихся в разработке передового искусственного интеллекта. Пекин пытается снизить зависимость местных компаний от продукции зарубежных игроков вроде Nvidia, чья продукция оказалась критически важной при разработке передовых моделей ИИ. Несоблюдение требований грозит компаниям проверками на местах и штрафами — всего этого они стремятся избежать. Чтобы преодолеть угрозу, Nvidia подготовила решение для внесения корректировок в ускорители H20, но они могут снизить эффективность компонента и сделать его менее конкурентоспособным на китайском рынке. Технологические гиганты, в том числе Alibaba и Tencent, в этом году активно нарастили заказы на H20 после выхода эффективной рассуждающей модели ИИ DeepSeek R1. Nvidia тем временем всё чаще попадает в поле зрения китайских регуляторов: Государственное управление рыночного регулирования (SAMR) в декабре инициировало проверку, чтобы выяснить, не ограничивала ли Nvidia поставки ускорителей в Китай в 2022 году ещё до введения американских санкций. По итогам 2025 финансового года доход компании в стране составил $17,1 млрд — это 13 % от общего объёма продаж. Новым экологическим требованиям не соответствуют также чипы Intel HL328 и HL388, но из-за их незначительного присутствия на рынке масштабных последствий от возможных мер в отношении этой продукции не предвидится. Nvidia представила видеокарты с 96 Гбайт GDDR7 — профессиональные RTX Pro Blackwell для серверов, ПК и ноутбуков
18.03.2025 [23:16],
Николай Хижняк
Компания Nvidia представила новые профессиональные настольные и мобильные видеокарты серии Nvidia RTX Pro на архитектуре Blackwell для рабочих станций и серверов. Эти решения предназначены для различных задач, включая работу с агентными ИИ, моделированием, дополненной реальностью, 3D-дизайном, сложными визуальными эффектами, а также разработку ИИ для робототехники и транспортных средств. 
Источник изображений: Nvidia Для дата-центров компания подготовила ускоритель Nvidia RTX Pro 6000 Blackwell Server Edition, построенный на чипе GB202 в полной конфигурации с 24 064 ядрами CUDA, который дополняют 96 Гбайт памяти GDDR7.  Nvidia RTX Pro 6000 Blackwell Server Edition Для настольных систем представлены модели Nvidia RTX Pro 6000 Blackwell Workstation Edition, Nvidia RTX Pro 6000 Blackwell Max-Q Workstation Edition, Nvidia RTX Pro 5000 Blackwell, Nvidia RTX Pro 4500 Blackwell и Nvidia RTX Pro 4000 Blackwell. Видеокарты RTX Pro 6000 предлагают те же характеристики, что и серверная версия, а версия Max-Q отличается от обычной вдвое меньшим энергопотреблением. Остальные карты предлагают более скромные характеристики, от 8960 CUDA и 24 Гбайт памяти до 14 080 CUDA и 48 Гбайт памяти. 
Nvidia RTX Pro 6000 Blackwell Workstation Edition
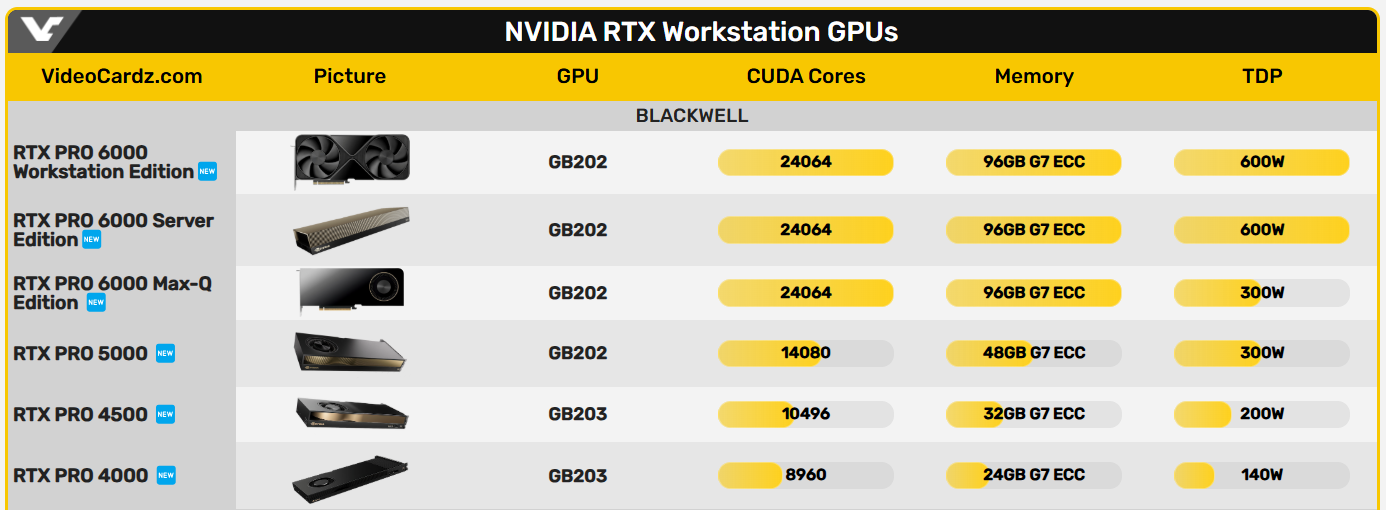 Для мобильных рабочих станций анонсированы видеокарты Nvidia RTX Pro 5000 Blackwell, Nvidia RTX Pro 4000 Blackwell, Nvidia RTX Pro 3000 Blackwell, Nvidia RTX Pro 2000 Blackwell, Nvidia RTX Pro 1000 Blackwell и Nvidia RTX Pro 500 Blackwell. Они предлагают от 6 до 24 Гбайт памяти GDDR7 и графические процессоры поколения Blackwell, которые насчитывают от 1792 до 10 496 ядеро CUDA. 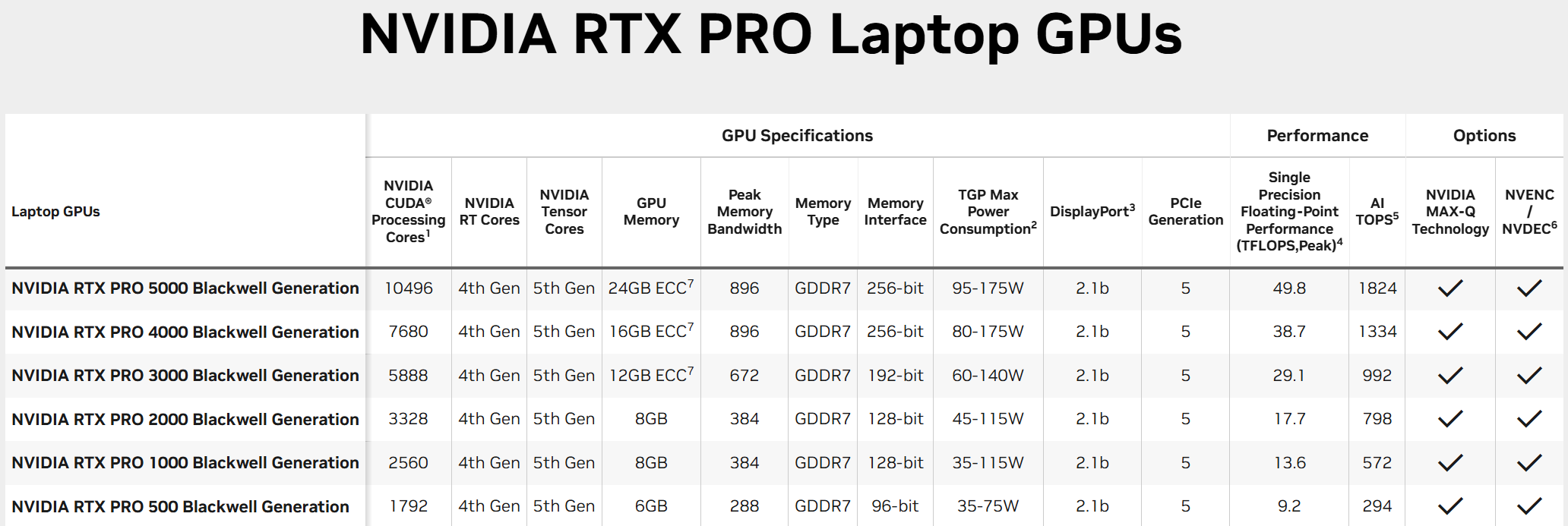 Новые ускорители Nvidia RTX Pro Blackwell обладают рядом преимуществ. Потоковые мультипроцессоры Nvidia обеспечивают до 1,5 раза более высокую пропускную способность и включают новые нейронные шейдеры. Четвёртое поколение RT-ядер обеспечивает двукратный прирост производительности при рендеринге фотореалистичных сцен и сложных 3D-проектов, оптимизированных под Nvidia RTX Mega Geometry. Четвёртое поколение тензорных ядер выполняет до 4000 триллионов ИИ-операций в секунду, поддерживает вычисления FP4 и работу технологии Nvidia DLSS 4 Multi Frame Generation. Ускорители оснащены аппаратным многопоточным кодировщиком Nvidia NVENC девятого поколения с поддержкой кодирования 4:2:2, а также кодировщиком шестого поколения для декодирования 4:2:2 H.264 и HEVC.  Все модели поддерживают интерфейс PCIe 5.0, DisplayPort 2.1 с разрешением до 4K@180 Гц или 8K@165 Гц, а также технологию Multi-Instance GPU (MIG), позволяющую разделять один GPU на четыре независимых виртуальных графических процессора, что вдвое больше по сравнению с предыдущими моделями.  Первые тестирования показали высокую эффективность новинок. Компания Foster + Partners отметила пятикратный рост производительности в среде проектирования Cyclops по сравнению с Nvidia RTX A6000. GE HealthCare зафиксировала двукратный прирост эффективности в обработке алгоритмов реконструкции. SoftServe заявила, что 96 Гбайт памяти у Nvidia RTX Pro Workstation Edition увеличивают продуктивность при работе с Llama 3.3-70B, Mistral 8x7b и платформой Nvidia Omniverse в три раза. 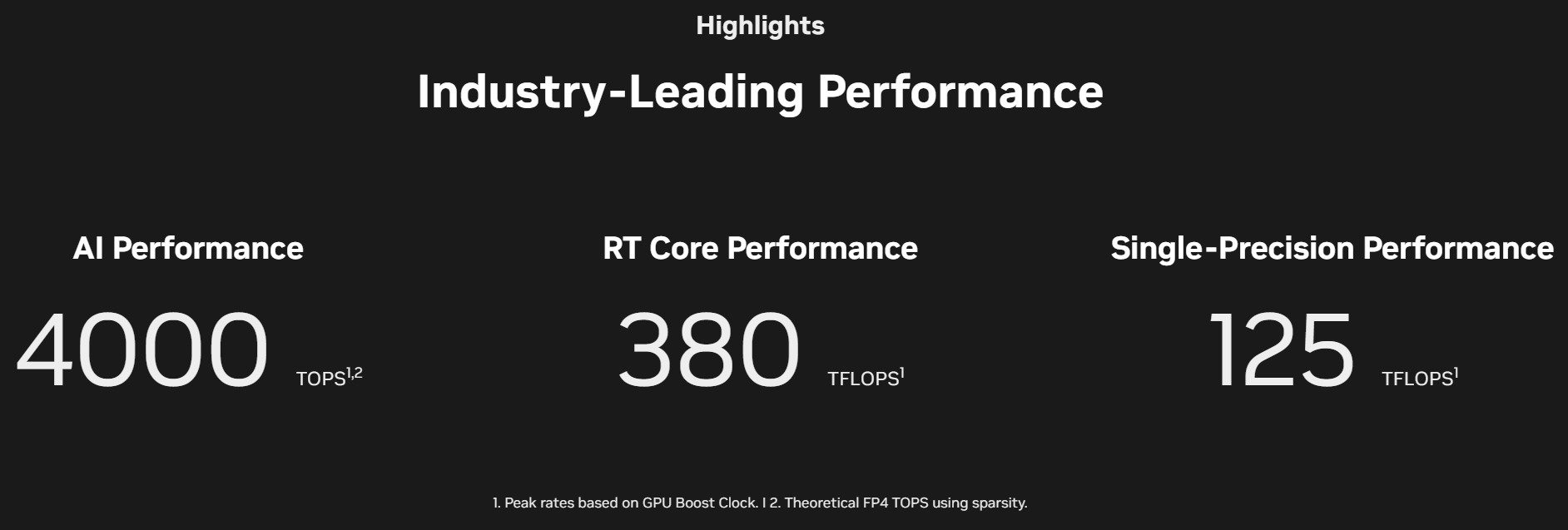 Профессиональные ускорители Nvidia RTX Pro 6000 Blackwell Workstation Edition и Nvidia RTX Pro 6000 Blackwell Max-Q Workstation Edition поступят в продажу через глобальных партнёров-дистрибьюторов, таких как PNY и TD SYNNEX, в апреле. В мае они появятся у BOXX, Dell, HP Inc., Lambda и Lenovo. Модели Nvidia RTX Pro 5000, RTX Pro 4500 и RTX Pro 4000 Blackwell поступят в продажу летом в магазинах BOXX, Dell, HP и Lenovo, а также через глобальных партнеров-дистрибьюторов. Профессиональные ускорители Nvidia RTX Pro для ноутбуков ожидаются в ассортименте компаний Dell, HP, Lenovo и Razer позже в этом году. У OpenAI закончились ИИ-ускорители — глава компании объяснил задержку GPT-4.5
28.02.2025 [17:55],
Павел Котов
OpenAI сообщила о выходе модели искусственного интеллекта GPT-4.5, но доступ к ней получили только пользователи подписки ChatGPT Pro, которые платят $200 в месяц. Полномасштабное развёртывание новой модели пришлось отложить, поскольку «мы слишком выросли, и у нас закончились графические процессоры», необходимые для этого, сообщил глава компании Сэм Альтман (Sam Altman). 
Источник изображения: nvidia.com «На следующей неделе мы добавим несколько десятков тысяч графических процессоров и выпустим её на тариф Plus», — пообещал гендиректор OpenAI и добавил, что вскоре компания получит ещё сотни тысяч ускорителей. Из-за мирового дефицита вычислительных мощностей компания была вынуждена обратиться к Broadcom с целью совместной разработки собственного ускорителя для ИИ. Однако на это уйдёт не один год, а пока для удовлетворения своих потребностей и потребностей клиентов компании приходится работать с оборудованием Nvidia и других поставщиков. Это в очередной раз подчёркивает, в каком выгодном положении остаётся Nvidia. Недавно компания заявила, что ускорители последнего поколения Blackwell распроданы до октября текущего года. А поскольку мировая отрасль центров обработки данных планирует крупномасштабное расширение существующих и строительство новых объектов, успех будет сопутствовать «зелёным» ещё несколько лет. Только OpenAI и Microsoft работают над суперкомпьютером, который обойдётся в $100 млрд, а Илон Маск (Elon Musk) намеревается расширить свой суперкомпьютер Colossus в Мемфисе (штат Теннесси, США) до более чем миллиона ускорителей. В Южной Корее одобрение получил объект мощностью 3 ГВт, а ЦОД планируют запустить даже на Луне. Глава Microsoft Сатья Наделла (Satya Nadella) выразил опасение, что мощности объектов для ИИ окажутся чрезмерными, хотя новые модели становятся всё более требовательными к вычислительным ресурсам. Яркий тому пример — новая OpenAI GPT-4.5. Это «гигантская, дорогая модель», как охарактеризовал её Сэм Альтман. Стоимость подключения к ней составит $75 за 1 млн входных токенов и $150 за 1 млн выходных — для сравнения, у GPT-4o эти тарифы составляют $2,50 и $10 соответственно. Несмотря на цену, это «не рассуждающая модель, и [она] не побьёт эталонных показателей», признался гендиректор OpenAI, но, по его словам, «это другой вид интеллекта, [у него] есть волшебство, которого я прежде не ощущал». Nvidia выпустит 77 % всех чипов для ИИ в мире в 2025 году
19.02.2025 [19:05],
Павел Котов
Переживающий небывалый подъём рынок искусственного интеллекта можно оценивать по разным критериям. Наиболее очевидными представляются производительность и потребление энергии, но аналитики Morgan Stanley решили обратиться к потреблению кремниевых пластин для ИИ-процессоров. Как выяснилось, в 2025 году Nvidia претендует на 77 % мирового рынка этой продукции. 
Источник изображения: Nvidia Nvidia продолжает работать в беспрецедентных масштабах и резко наращивать производство, тогда как доля AMD в разрезе использования пластин за год обещает снизиться. В доклад также включены данные по AWS, Google, Tesla, Microsoft и китайским поставщикам. По итогам 2025 года на Nvidia придётся до 535 000 300-мм пластин для ИИ-чипов, что составит 77 % мирового рынка. Для сравнения: в 2024 году доля компании составляла 51 %, указывают аналитики Morgan Stanley. Активно набирают обороты альтернативные чипы, в том числе Google TPU v6 и AWS Trainium, но они сильно уступают темпам Nvidia. Доля AWS в течение года снизится с 10 % до 7 %, а доля Google — с 19 % до 10 %. Google потребуется 85 000 пластин для TPU v6; AWS — 30 000 для Trainium 2 и 16 000 для Trainium 3. 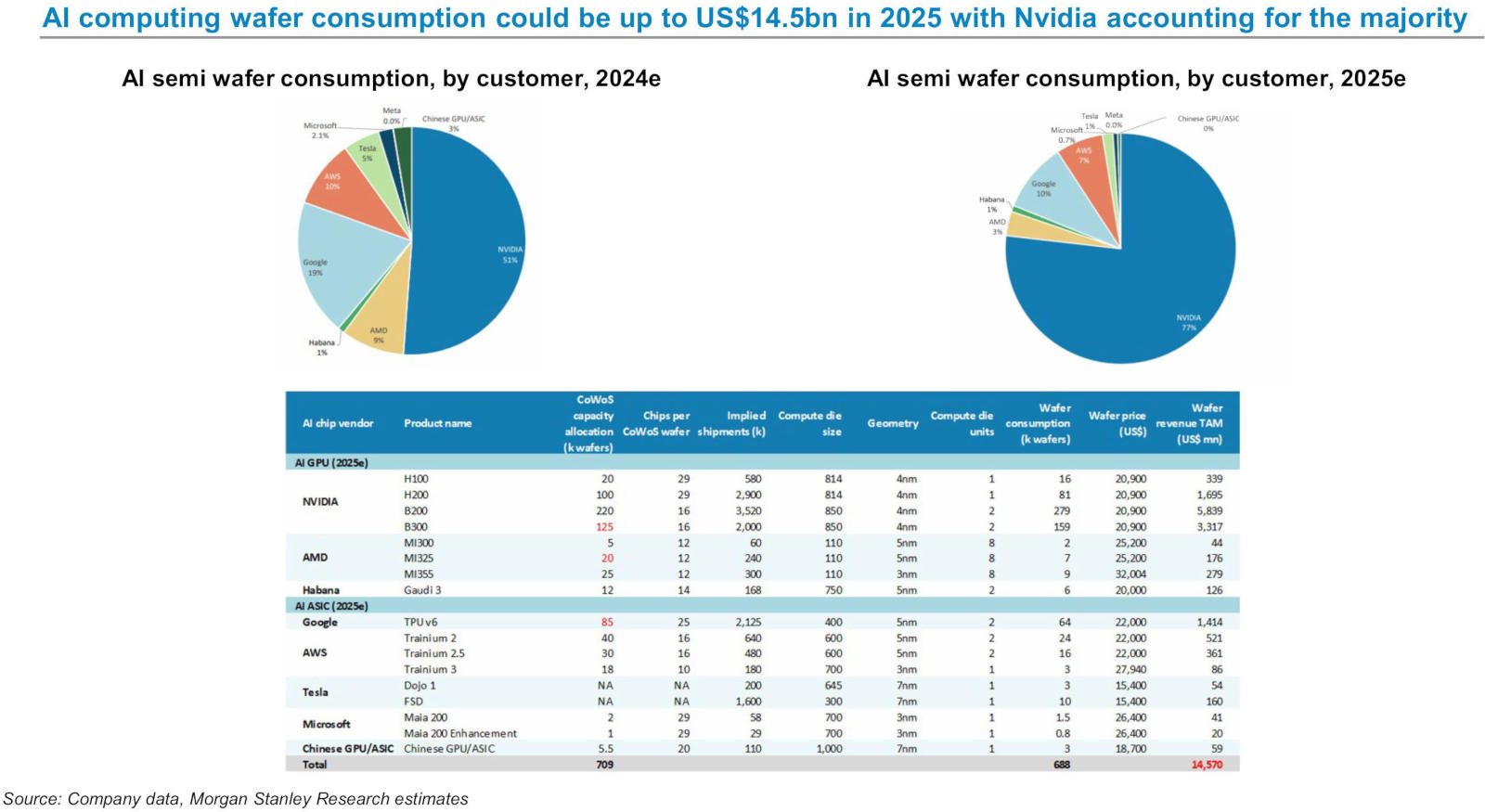
Источник изображения: x.com/Jukanlosreve Доля AMD снизится с 9 % до 3 %. Для её ИИ-ускорителей Instinct MI300, MI325 и MI355 понадобятся от 5000 до 25 000 пластин в зависимости от модели. В абсолютных показателях AMD не намерена сокращать потребление пластин, но её доля на рынке уменьшится. Процессоры Intel Gaudi 3 (Habana) займут всего 1 %; незначительны также доли Tesla, Microsoft и китайских поставщиков. Доля чипов Tesla Dojo и FSD остаётся невеликой, поскольку компания является нишевым игроком на рынке ИИ. Потребности Microsoft в кремниевых пластинах также скромны: её ускоритель Maia 200 и его улучшенная версия используются в ограниченных масштабах, поскольку корпорация продолжает применять решения Nvidia как для обучения, так и для запуска моделей ИИ. В докладе не уточняется, чем обусловлено доминирование Nvidia в этом году — спросом или объёмом зарезервированных мощностей у TSMC. Рынок ИИ-чипов в 2025 году, как ожидается, потребует 688 000 пластин, что в денежном выражении составит $14,57 млрд. Однако этот показатель может оказаться заниженным, поскольку в 2024 году TSMC заработала $64,93 млрд, из которых 51 % (более $32 млрд) пришлось на сегменты высокопроизводительных вычислений (HPC). Технически это направление включает в себя не только ИИ-ускорители, но и процессоры для потребительских ПК, а также чипы для игровых приставок. Однако значительная часть доходов связана именно с графическими и центральными процессорами для центров обработки данных. Наибольший вклад в показатели Nvidia вносит модель B200: для её производства потребуется 220 000 пластин, что эквивалентно $5,84 млрд дохода. Компания укрепит свои позиции за счёт ускорителей H100, H200 и B300. Все они производятся по техпроцессу TSMC 4 нм, а размеры вычислительных кристаллов варьируются от 814 до 850 мм², что объясняет высокий спрос на кремниевые пластины. OpenAI завершит разработку и запустит производство своего ИИ-чипа уже в 2025 году — это первый шаг к снижению зависимости от Nvidia
10.02.2025 [17:54],
Сергей Сурабекянц
Признанный лидер в сфере ИИ, компания OpenAI, прикладывает серьёзные усилия по снижению зависимости от ускорителей ИИ производства Nvidia. В ближайшие несколько месяцев OpenAI планирует завершить разработку собственного чипа и начать его производство на фабриках TSMC с использованием самых передовых техпроцессов. 
Источник изображения: Samsung По мнению аналитиков, «OpenAI находится на пути к достижению своей амбициозной цели массового производства на мощностях TSMC в 2026 году». Наиболее ответственным этапом на пути от дизайна к выпуску готовых чипов является Tape-out («тейпаут») — процесс переноса цифрового проекта чипа на фотошаблон для последующего производства. Обычно этот этап обходится в несколько десятков миллионов долларов, а до выпуска первого чипа проходит до шести месяцев. В случае сбоя требуется диагностировать проблему и повторить процесс. OpenAI рассматривает свой будущий ускоритель ИИ как стратегический инструмент для укрепления переговорных позиций с другими поставщиками чипов. Если первоначальный выпуск пройдёт удачно, OpenAI уже в этом году представит альтернативу чипам Nvidia, которые сейчас занимают более80 % рынка ИИ-ускорителей. В случае успеха первого чипа инженеры OpenAI планируют разрабатывать все более продвинутые процессоры с более широкими возможностями с каждой новой итерацией. Компания уже стала участником инфраструктурной программы Stargate стоимостью $500 млрд, объявленной президентом США Дональдом Трампом (Donald Trump) в прошлом месяце. Чип разрабатывается внутренней командой OpenAI во главе с Ричардом Хо (Richard Ho) в сотрудничестве с Broadcom. Хо более года назад перешёл в OpenAI из Google, где руководил программой по созданию специализированных чипов ИИ. Хотя команда Хо за последние месяцы выросла до 40 сотрудников, это количество по прежнему на порядок меньше, чем в масштабных проектах таких технологических гигантов, как Google или Amazon. Аналитики полагают, что на первом этапе новый ускоритель ИИ от OpenAI будет играть ограниченную роль в инфраструктуре компании. Чтобы создать столь же всеобъемлющую программу по проектированию чипов ИИ, как у Google или Amazon, OpenAI придётся нанять сотни инженеров. Согласно отраслевым источникам, новый дизайн чипа для амбициозной масштабной программы может обойтись в $500 млн. Эти расходы могут удвоиться, если учитывать необходимость создания программного обеспечения и периферийных устройств. Для сравнения: в 2025 году Meta✴ планирует потратить $60 млрд на ИИ-инфраструктуру, а годовые инвестиции Microsoft в этом направлении составят $80 млрд. Акции AMD пошли на снижение из-за недостаточного внимания компании к ИИ
08.02.2025 [15:04],
Павел Котов
Компания AMD считается крупнейшим конкурентом Nvidia на рынке ускорителей, которые используются для обучения систем искусственного интеллекта, но как показывает динамика акций «красных», инвесторы не уверены, что компания способна справиться с этой ролью, пишет Bloomberg. 
Источник изображения: amd.com Сейчас ценные бумаги AMD находятся на самом низком уровне с ноября 2023 года — по сравнению с концом 2023 года они подешевели на 25 %. Для сравнения, показатель Philadelphia Stock Exchange Semiconductor Index за то же время вырос более чем на 20 %, а акции Nvidia подорожали на 160 %. Только накануне, 7 февраля 2025 года, акции AMD потеряли в цене 0,9 %. Причиной тому стала излишняя осторожность гендиректора компании Лизы Су (Lisa Su) — в ходе квартального отчёта она воздержалась от отдельного годового прогноза по ИИ-ускорителям, которые считаются ключевым продуктом. Тем самым она не дала катализатора финансового развития на ближайшие полгода и перевела вложения в AMD в категорию «мёртвых денег», пожаловались инвесторы. Усугубил ситуацию тот факт, что ранее компания подробно рассказывала о доходах в секторе ИИ, так что загадочное молчание на сей раз вызвало опасения, что Nvidia слишком сильно опередила всех конкурентов, и у AMD могут возникнуть сложности с реализацией своих чипов для ИИ. 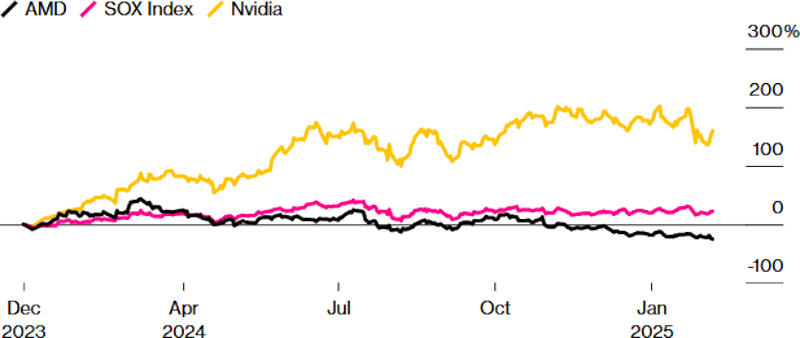
Источник изображения: bloomberg.com В остальном квартальный отчёт оценивается как положительный: компания показала выручку выше ожидаемой и дала оптимистичный общий прогноз. Доктор Су отметила, что продажи ИИ-ускорителей в первой половине 2025 года останутся примерно на уровне второй половины 2024 года. Ситуация может измениться к лучшему в середине года, когда AMD выпустит ускоритель нового поколения — это привлекло внимание инвесторов, ожидающих линейного роста компании, который, по версии руководства AMD, в ближайшие годы будет продолжаться. Но Citi понизил рейтинг AMD и был в этом не одинок: Bank of America, HSBC Holdings и Melius Research указали на сложный характер конкуренции с Nvidia. «Зелёным», по версии IDC, в III квартале принадлежали 89 % мирового рынка серверной графики, тогда как AMD достались лишь 10,3 %, а Intel — всего 1,1 %. Ситуацию не спасла даже сенсация китайской DeepSeek, которая добилась значительных результатов при минимальных затратах: крупные компании всё равно решили удвоить затраты на ИИ — одна только Alphabet подготовила $75 млрд. Но и безнадёжным положение AMD инвесторы пока не считают. Nvidia и Broadcom едва ли смогут удовлетворить спрос всего рынка, и если AMD нарастит долю хотя бы до 15 %, её доходы будут значительными, рассуждают они. Но после публикации квартального отчёта аналитики снизили прогнозируемые показатели AMD: на 15 % по чистой прибыли и на 0,4 % по выручке. В этом году, как ожидается, доходы компании вырастут на 24 %, а чистая прибыль — более чем в три раза. В следующем году рост замедлится: выручка увеличится на 21 %, чистая прибыль — на 46 %. Это значит, что акции торгуются по цене менее 23-кратной предполагаемой прибыли — на 35 % ниже указанной аналитиками средней целевой цены. То есть худшее для AMD на фондовом рынке, вероятно, уже позади. Для мелких производителей ИИ-чипов DeepSeek оказалась не угрозой, а шансом
07.02.2025 [18:35],
Павел Котов
DeepSeek потрясла мировой рынок искусственного интеллекта во главе с американскими компаниями — один только производитель ИИ-ускорителей Nvidia потерял несколько сотен миллиардов долларов капитализации. И пока лидеры рынка пытаются преодолеть последствия, мелкие производители видят в случившемся шанс нарастить масштабы деятельности, пишет CNBC. 
Источник изображения: Solen Feyissa / unsplash.com «Разработчики очень хотят заменить дорогие и закрытые модели OpenAI моделями с открытым исходным кодом, такими как DeepSeek R1», — считает Эндрю Фельдман (Andrew Feldman), гендиректор стартапа Cerebras Systems, выпускающего чипы для ИИ. Компания выступает конкурентом Nvidia и предлагает облачные сервисы в собственных кластерах. Выход DeepSeek R1 спровоцировал один из крупнейших всплесков спроса на услуги компании за всю её историю, и по словам её главы, показал, что рост рынка ИИ не будет связан с доминированием всего одной компании, потому что открытые модели не привязаны к определённым оборудованию или ПО. DeepSeek утверждает, что её рассуждающая модель потребляет меньше вычислительных ресурсов, чем американские аналоги, и обучается без передовых ускорителей. Китайский стартап способен ускорить процесс развёртывания новых технологий в области ИИ-ускорителей, охватив и обучение моделей, и их запуск. Nvidia занимает доминирующее положение на рынке оборудования для обучения ИИ, и многие её конкуренты считают, что у них есть возможность расширить своё присутствие в области запуска уже обученных моделей, обещая клиентам более высокую эффективность за меньшие деньги. Обучение ИИ требует значительных вычислительных ресурсов, но для работы уже обученной системы достаточно и менее мощного оборудования, ограниченного более узким кругом задач. И здесь разработчики альтернативных ускорителей отмечают рост спроса, потому что многие клиенты готовы решать свои задачи на основе уже обученных моделей DeepSeek. Аналитики и отраслевые эксперты уверены, что китайская лаборатория, которая понизила планку на обучение и запуск систем ИИ, окажет влияние на развитие всей отрасли: если услуги запуска уже обученных моделей станут дешевле, технологии ИИ начнут внедряться активнее, потому что снижение затрат приводит к повышению спроса — это явление называется парадоксом Джевона. Рост спроса подтвердили представители специализирующихся на разработке ускорителей стартапов d-Matrix и Etched. «Благодаря широкой доступности моделей малого размера они послужили катализатором эпохи вывода [ИИ]», — рассказали в d-Matrix. «Компании переводят свои затраты с обучающих кластеров на кластеры вывода», — добавили в Etched, к которой с момента выхода DeepSeek R1 обратились уже десятки корпоративных клиентов. Наконец, следует помнить, что небезграничны и ресурсы Nvidia — даже технологический гигант её масштаба физически не сможет удовлетворить весь мировой спрос на ИИ-ускорители. А значит, у мелких игроков действительно есть шанс. Низкопробный софт AMD не даёт раскрыть потенциал ИИ-ускорителей Instinct MI300X и обойти Nvidia, выяснили эксперты
23.12.2024 [23:11],
Николай Хижняк
Пятимесячное расследование компании SemiAnalysis показало, что специализированные ИИ-ускорители серии AMD MI300X не раскрывают свой потенциал из-за серьёзных проблем в работе программного обеспечения. Этот факт делает все усилия компании по навязыванию жёсткой конкуренции Nvidia, доминирующей на рынке аппаратного обеспечения для ИИ, бессмысленными. 
Источник изображения: The Decoder Исследование показало, что программное обеспечение AMD изобилует ошибками, которые делают обучение моделей ИИ практически невозможным без значительной отладки. Таким образом, пока AMD работает над обеспечением качества и простоты использования своих ускорителей, Nvidia продолжает увеличивать разрыв, развёртывая новые функции, библиотеки и повышая производительность своих решений. По итогам обширных тестов, включая тесты GEMM и одноузловое обучение, исследователи пришли к выводу, что AMD не в состоянии преодолеть то, что они называют «неприступным рвом CUDA» — сильное преимущество в виде программного обеспечения, которым обладают ускорители Nvidia. 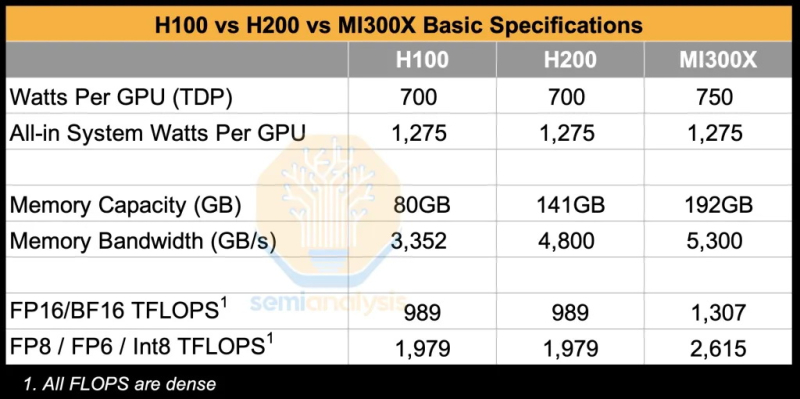
Источник изображения: SemiAnalysis AMD MI300X «на бумаге» выглядят впечатляюще: 1307 Тфлопс в вычислениях FP16 и 192 Гбайт памяти HBM3. Для сравнения, ускорители Nvidia H100 обладают производительностью 989 Тфлопс и имеют только 80 Гбайт памяти. Однако новое поколение ИИ-ускорителей Nvidia H200 с конфигурациями до 141 Гбайт памяти сокращает разрыв в объёме доступного буфера памяти. Кроме того, системы на базе ускорителей AMD также предлагают более низкую общую стоимость владения благодаря более низким ценам на такие системы и более доступной поддержке сетевой инфраструктуры. 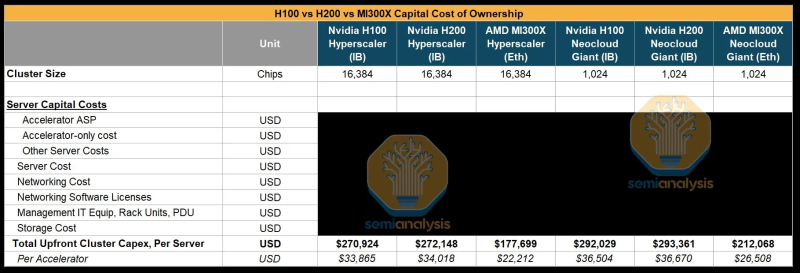
Источник изображения: SemiAnalysis Однако эти преимущества мало что значат на практике. По данным SemiAnalysis, сравнение «голых» спецификаций похоже на «сравнение камер, когда просто проверяешь количество мегапикселей у одной и другой». AMD, отмечают аналитики, таким образом «просто играет с цифрами», но её решения не обеспечивают достаточный уровень производительности в реальных задачах. 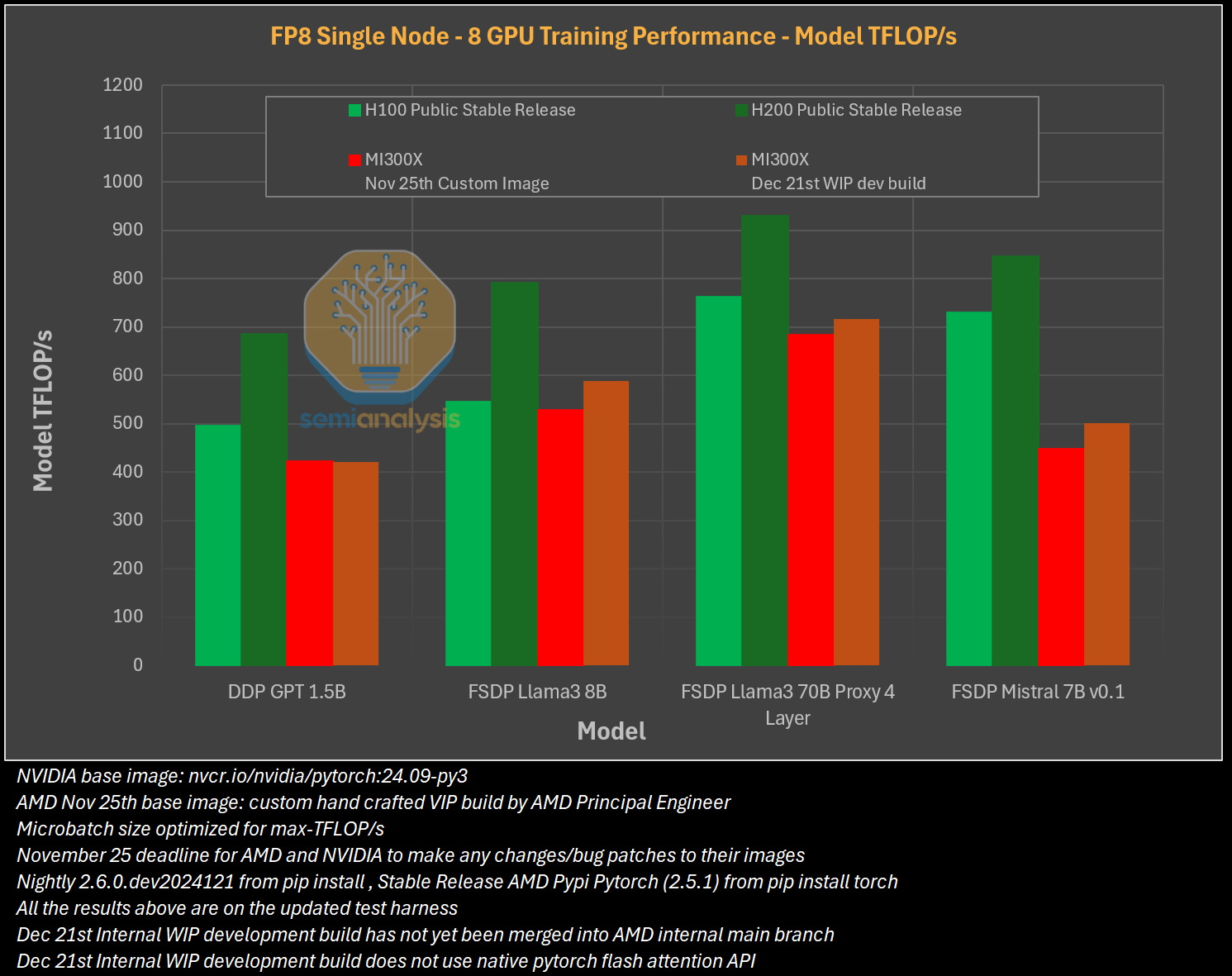
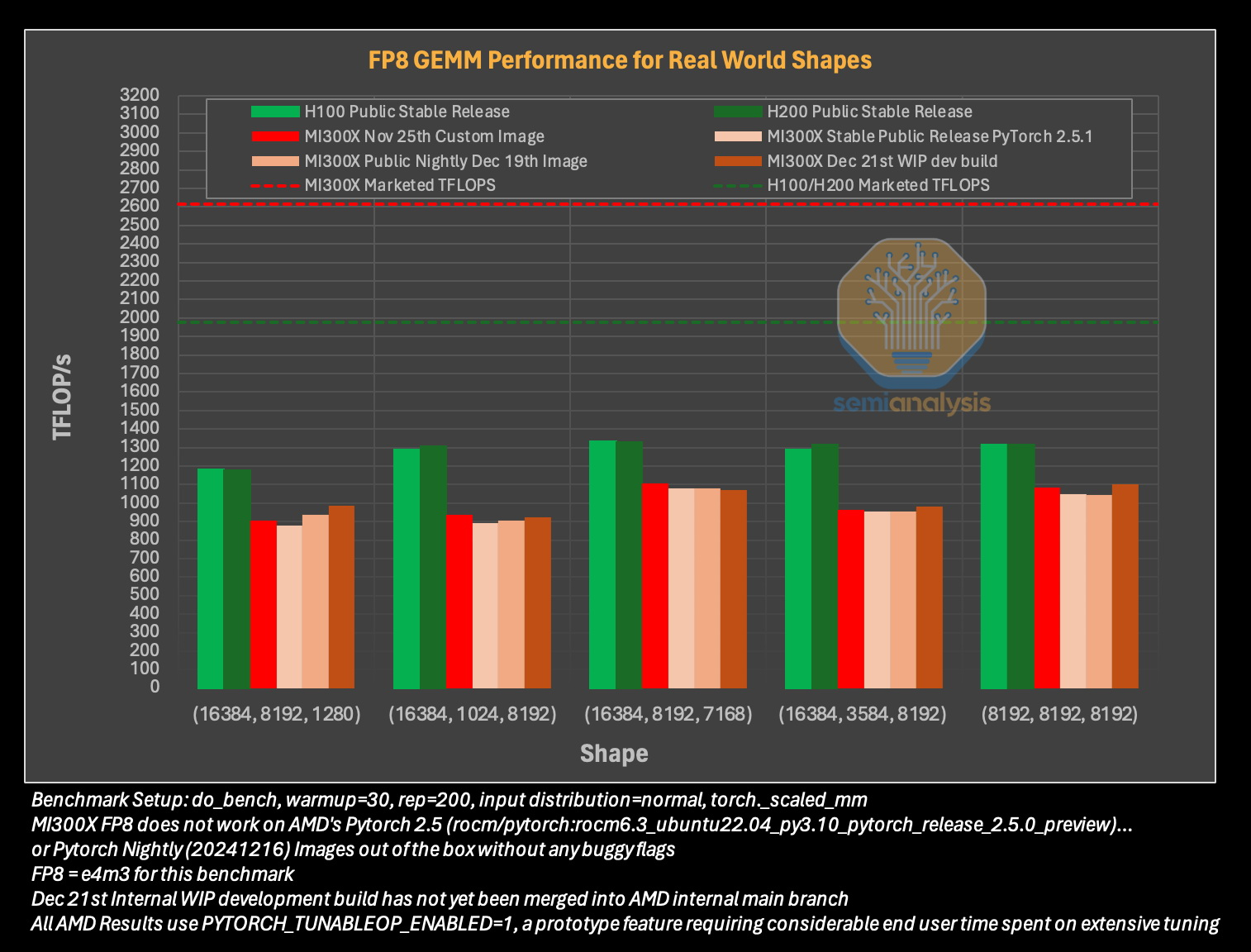 Исследователи отмечают, что им пришлось напрямую работать с инженерами AMD, чтобы исправить многочисленные ошибки в ПО для получения пригодных для оценки результатов тестов. В то же время системы на базе ускорителей Nvidia работали гладко и без каких-либо дополнительных настроек. «С OOBE от AMD (опыт, который пользователь получает при получении продукта после распаковки или при запуске установщика и подготовке к первому использованию, так называемый "опыт из коробки" — прим. ред.) очень сложно работать. И для перехода к пригодному к использованию состоянию [оборудования] может потребоваться немало терпения и усилий», — пишут эксперты. 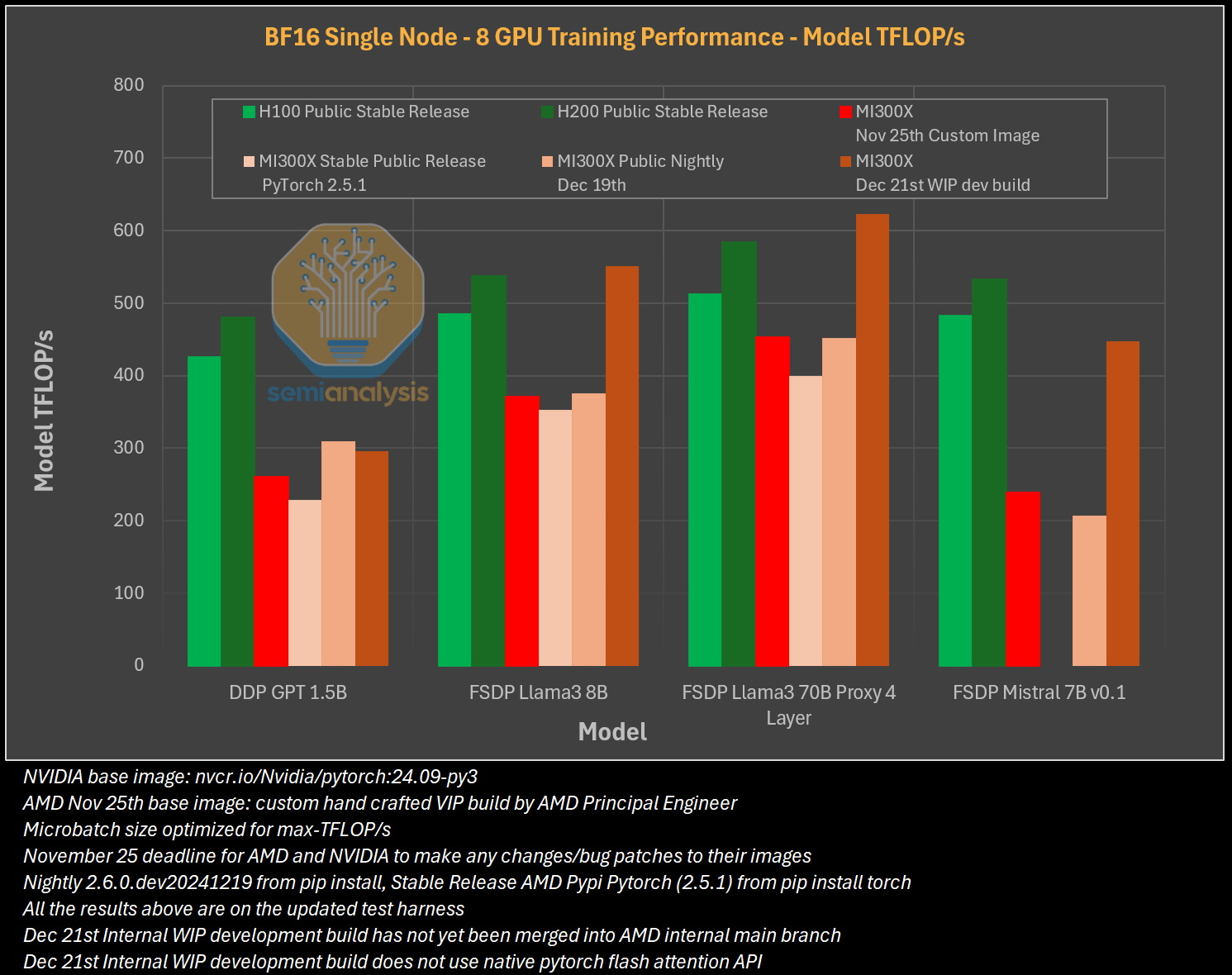
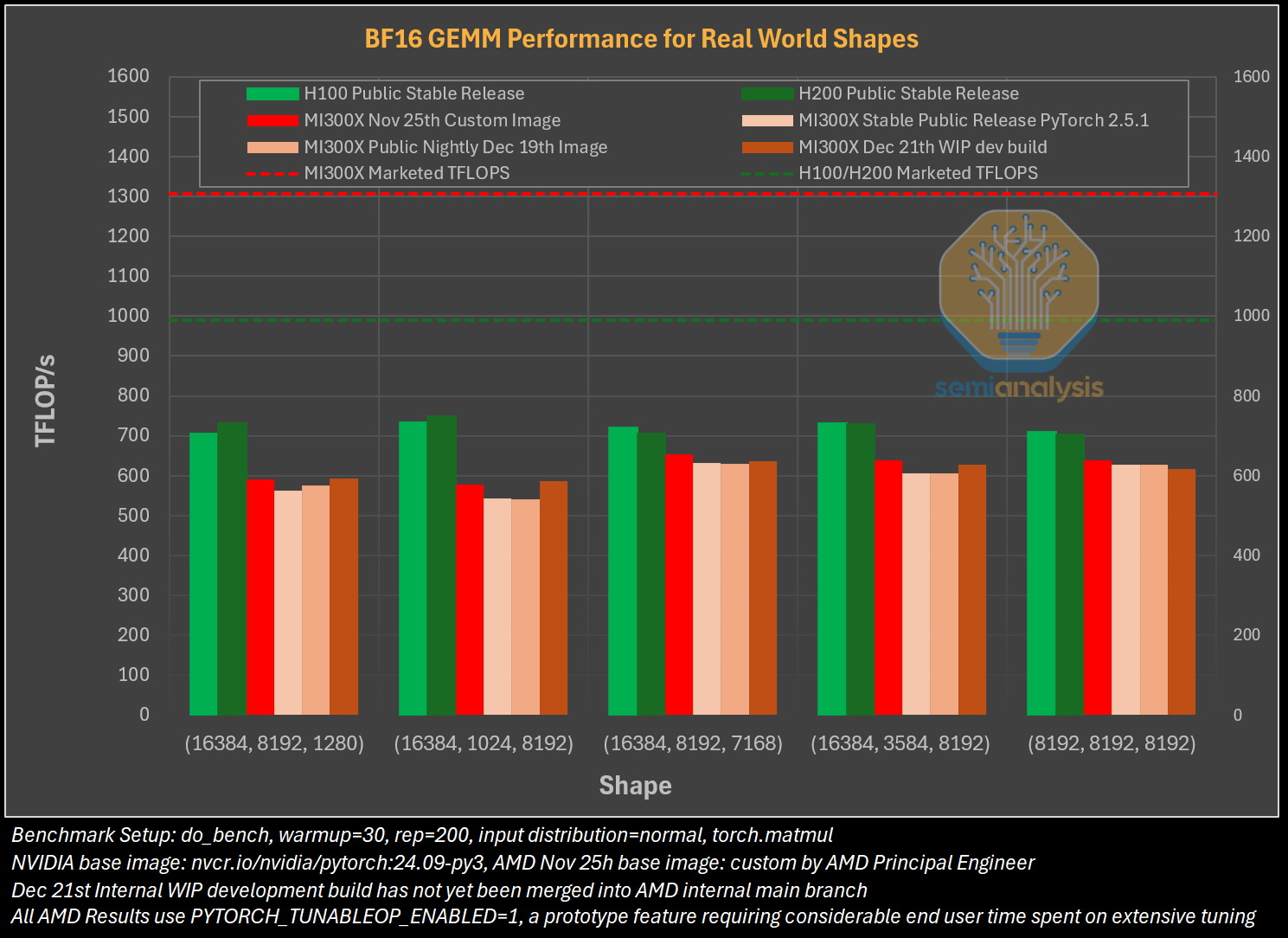 Особенно показательным для SemiAnalysis оказался случай, когда компания TensorWave, крупнейший поставщик облачных решений на базе графических процессоров AMD, была вынуждена предоставить команде инженеров AMD бесплатный доступ к своим графическим процессорам — тому же оборудованию, которое TensorWave приобрела у AMD — только для устранения проблем с программным обеспечением. Для решения проблем эксперты SemiAnalysis рекомендуют генеральному директору AMD Лизе Су (Lisa Su) более активно инвестировать в разработку и тестирование программного обеспечения. В частности, они предлагают выделить тысячи чипов MI300X для автоматизированного тестирования (аналогичному подходу следует Nvidia для своих ускорителей), упростить сложные переменные среды, одновременно внедрив более эффективные настройки для ускорителей по умолчанию. «Сделайте готовый опыт пригодным к использованию!» — призывают специалисты. Представители SemiAnalysis в своём отчёте признаются, что желают успеха компании AMD в конкуренции с Nvidia, но отмечают, что «к сожалению, для этого ещё многое предстоит сделать». Без существенных улучшений программного обеспечения AMD рискует ещё больше отстать, поскольку Nvidia готовится к массовому выпуску ускорителей нового поколения Blackwell. Хотя, по сообщениям, этот процесс у Nvidia также проходит не совсем гладко. Временная глава Intel не верит в успех ИИ-ускорителей Falcon Shores, но это «первый шаг в верном направлении»
13.12.2024 [17:48],
Николай Хижняк
Руководство компании Intel не верит, что компания сможет в скором времени составить достойную конкуренцию Nvidia и AMD в сфере ИИ-ускорителей. Во всяком случае, такое впечатление сложилось после недавних комментариев одной из временно исполняющей обязанности руководителя компании Мишель Джонстон Холтхаус (Michell Johnston Holthaus) на 22-й ежегодной глобальной технологической конференции Barclays. 
Источник изображений: Intel Напомним, Intel разрабатывает ускорители вычислений Falcon Shores, в основу которого будет положен графический процессор, заточенный под высокопроизводительные вычислений и задачи ЦОД, а дополнят GPU элементы актуальных ИИ-ускорителей Gaudi. Проект по разработке данного решения получил неожиданную оценку от Холтхаус: «Нам действительно нужно подумать о том, как перейти от Gaudi к нашему первому поколению GPU Falcon Shores. Будет ли новый продукт удивительным? Нет, не будет. Но он станет первым шагом в верном направлении». Хольтхаус ещё раз подчеркнула новый прагматичный подход Intel к вопросам разработки аппаратных решений для ускорения ИИ, когда затронула тему стратегии развития продуктов: «Если всё бросить и начать создать новый продукт, то его разработка займёт очень много времени. Прежде чем что-то появится потребуется два–три года. Вместо этого я предпочла бы создать что-то в меньших объёмах, научиться чему-то новому, последовательно совершенствуясь, чтобы в конечном итоге добиться поставленных целей». Врио главы Intel признала устойчивый характер возможностей рынка ИИ, акцентировав текущий интерес индустрии к обучению ИИ-моделей. Однако Хольтхаус также подчеркнула потенциал широких возможностей в других областях: «Очевидно, что ИИ никуда не денется. Очевидно, что обучение [ИИ] сегодня находится центре внимания, но есть возможности развития и на других направлениях, где также отмечаются потребности с точки зрения нового аппаратного обеспечения». По всей видимости она подразумевала инференс — запуск уже обученных нейросетей. 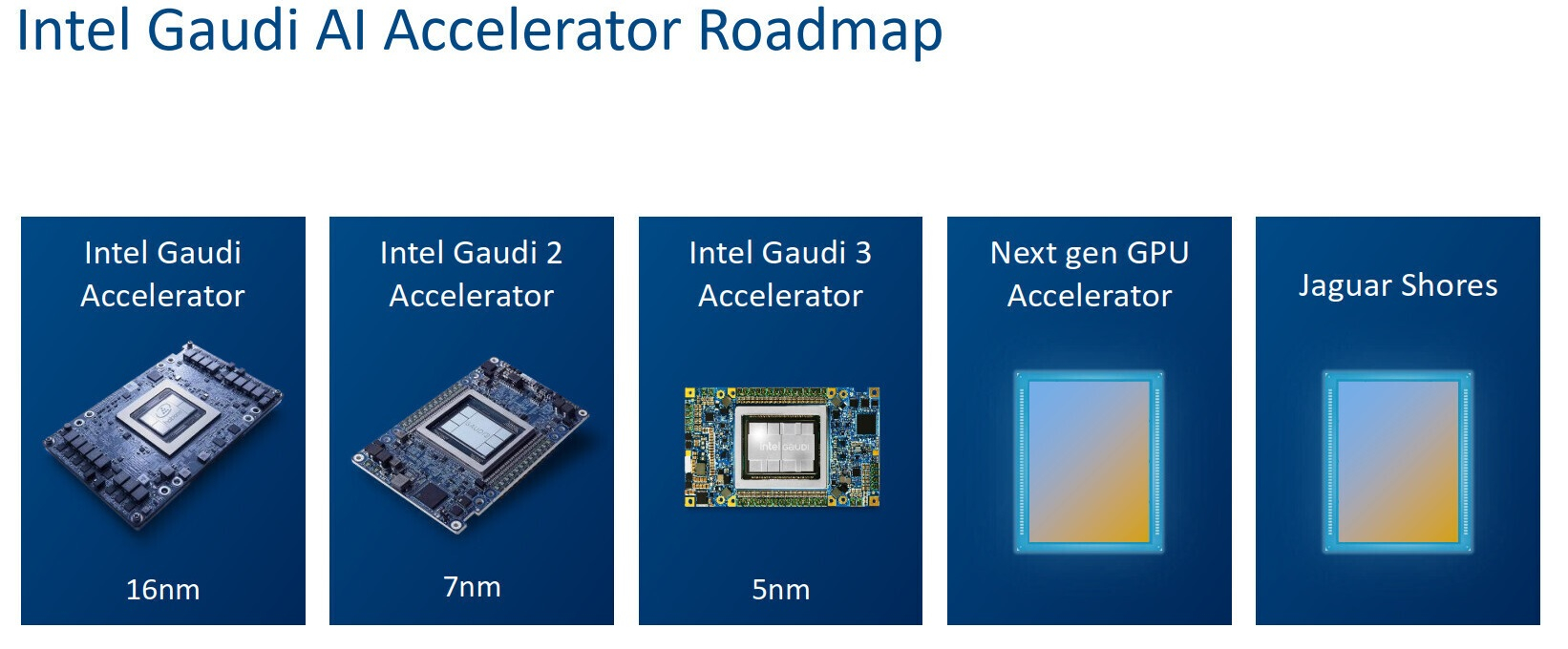 Из сказанного можно сделать вывод, что Falcon Shores не станет для Intel чудесным спасательным кругом, который позволит ей наверстать отставание от Nvidia на рынке GPU-ускорителей. Это в большей степени первая ступень к разработке первоклассного продукта в перспективе. Следующим проектом Intel после Falcon Shores должен стать Jaguar Shores. Его выход ожидается в конце 2025 или начале 2026 года в виде ускорителей ИИ и HPC для центров обработки данных. Однако до его появления компании предстоит проделать немало работы по усовершенствованию не только своего аппаратного, но и программного обеспечения. Доминирующе положение Nvidia на рынке ИИ во многом обязано её программно-аппаратной архитектуре CUDA, поскольку конкуренты, например, AMD, предлагают сопоставимую аппаратную производительность. Перед Intel стоит очень непростая задача. Ей предстоит обеспечить разработку экосистемного программного обеспечения и «бесшовную» интеграцию своих ускорителей следующего поколения, чтобы Jaguar Shores имел шансы догнать остальную часть рынка. У Nvidia появились сильные конкуренты в сфере ИИ-ускорителей, но её ещё рано списывать со счетов
06.12.2024 [16:24],
Павел Котов
Amazon, AMD и целый ряд стартапов всё активнее предлагают альтернативы ускорителям искусственного интеллекта Nvidia, но списывать лидера рынка со счетов пока рано — он предлагает пока неоспоримые преимущества в производительности и программной части, пишет The New York Times. 
Источник изображения: nvidia.com Год назад AMD представила ИИ-ускорители Instinct MI300, объем продаж которых, по предварительным оценкам, к настоящему моменту достиг $5 млрд. Amazon на этой неделе представила второе поколение собственных ускорителей Trainium, которые помогут компании усилить позиции в области обучения и запуска систем ИИ. Судя по реакции клиентов на эти решения, у Nvidia появились достойные альтернативы. Компания долгое время доминировала на этом рынке, и это помогло ей увеличить свою стоимость до $3 трлн, но теперь её конкуренты показывают, что способны обеспечить более высокую скорость по более скромным ценам. Это происходит потому, что ряд технологических компаний, включая не только гигантов масштаба AMD и Amazon, но и небольшие стартапы, начали адаптировать чипы для запуска уже обученных моделей ИИ (инференса). «Настоящая коммерческая ценность появляется с инференсом, и инференс начинает набирать масштаб. Мы начинаем наблюдать изменения», — заявил гендиректор Qualcomm Криштиану Амон (Cristiano Amon); производитель мобильных чипов также собирается использовать для задач с ИИ ускорители Amazon. Конкуренты Nvidia решили последовать её примеру и в другом — они начали предлагать не просто ускорители, а предназначенные для работы с ИИ готовые компьютеры. Усилившаяся конкуренция в области оборудования для ИИ стала очевидной, когда Amazon предложила клиентам аренду ресурсов на базе новых ускорителей Trainium2 — положительные отзывы оставила в том числе Apple. Amazon также представила серверы на 16 и 64 ускорителя с высокоскоростными соединениями, которые способствуют росту производительности при запуске систем ИИ. Amazon также строит гигантский кластер ИИ для своего партнёра Anthropic, который сможет обучать свои модели на сотнях тысяч ускорителей Trainium2. Расходы операторов центров обработки данных на системы ИИ без чипов Nvidia в этом году вырастут на 49 % и достигнут $126 млрд, подсчитали аналитики Omdia. 
Источник изображения: aws.amazon.com Но рост конкуренции пока не означает, что Nvidia утратит лидерство. Гендиректор компании Дженсен Хуанг (Jensen Huang) указал, что у неё есть преимущества в области ПО для ИИ, а также в возможностях запуска моделей. Новым чипам семейства Blackwell требуется больше мощности для работы, но их производительность из расчёта на ватт выше, чем у конкурентов. Актуальные ускорители Nvidia стоят до $15 000 за штуку, а цены на Blackwell, как ожидается, будут исчисляться несколькими десятками тысяч. Тем временем поднимаются стартапы, которым удалось привлечь инвестиции, — SambaNova Systems, Groq и Cerebras Systems уверяют, что при запуске ИИ им удалось добиться преимущества как в производительности, так и в цене. Некоторые клиенты уже начали менять рабочие схемы. Исполнительный директор «Техасского центра передовых вычислений» (Texas Advanced Computing Center) Дэн Станционе (Dan Stanzione) рассказал, что организация планирует купить в следующем году суперкомпьютер на базе Blackwell, но для задач по запуску ИИ будет использовать ускорители SambaNova, у которых более низкие потребление энергии и цена. Meta✴ также сообщила, что обучала модель Llama 3.1 405B на чипах Nvidia, но для её работы использует ускорители AMD MI300s. Amazon, Google, Microsoft и Meta✴ продолжают возводить большие кластеры на ускорителях Nvidia, но разрабатывают и свои собственные чипы для ускорения определённых вычислительных задач с целью снижения затрат. Google до конца года намерена начать сдавать в аренду ресурсы на своих ускорителях Trillium шестого поколения, которые почти впятеро быстрее предшественников. Amazon, которая считается отстающей в области ИИ, в этом году выделила на ИИ-ускорители и другое вычислительное оборудование $75 млрд. Ускорители Trainium первого поколения не получили большого признания на рынке, но в отношении Trainium2 компания настроена более оптимистически, а через год ожидается выпуск ещё более мощных Trainium3. По оценкам экспертов, Trainium2 предложат на 40-% прирост производительности на доллар по сравнению с оборудованием на базе Nvidia. Broadcom придумала, как укладывать кристаллы на чипах так, чтобы они работали быстрее
06.12.2024 [16:09],
Павел Котов
Компания Broadcom сообщила, что ее подразделение по производству заказных чипов, выпускающее решения для систем искусственного интеллекта для облачных провайдеров, разработало новую технологию для повышения скорости работы полупроводников. Это особенно актуально на фоне высокого спроса на инфраструктуру для ИИ. 
Источник изображения: broadcom.com Компания Broadcom является одним из крупнейших бенефициаров высокого спроса на аппаратное обеспечение для искусственного интеллекта, поскольку так называемые гиперскейлеры, то есть особенно крупные облачные провайдеры, обращаются к ее заказным чипам для построения своей ИИ-инфраструктуры. Теперь же Broadcom представила технологию 3.5D eXtreme Dimension System in Package (XDSiP), позволяющую создавать ускорители вычислений нового поколения. 3.5D XDSiP позволяет собрать на одной подложки кристаллы с общей площадью более 6000 мм2 и до 12 стеков памяти HBM. Это позволяет создавать ещё более сложные, производительные и в то же время более энергоэффективные ускорители. Компания Broadcom отмечает, что её технология первой в отрасли позволяет соединять кристаллы «лицом к лицу» (Face-to-Face или F2F), то есть передними частями, тогда как прежде было доступно лишь соединение «лицом к спине» Face-to-Back или F2B). Платформа Broadcom 3.5D XDSiP обеспечивает значительное повышение плотности межсоединений и энергоэффективности по сравнению с подходом F2B. Инновационная укладка F2F напрямую соединяет верхние металлические слои верхней и нижней матриц, что обеспечивает плотное и надежное соединение с минимальными электрическими помехами и исключительной механической прочностью. Платформа Broadcom 3.5D XDSiP включает в себя как готовые решения для внедрения в чипы, так и системы для проектирования кастомных решений. Технология, получившая название 3.5D XDSiP, позволит заказчикам чипов Broadcom увеличить объем памяти внутри каждого упакованного чипа и ускорить его работу за счет прямого соединения критически важных компонентов. Выпускать чипы с компоновкой 3.5D XDSiP будет компания TSMC. Сейчас в разработке значатся пять продуктов с новой технологией Broadcom, а их поставки начнутся в феврале 2026 года. Компания не уточнила, для каких облачных провайдеров разрабатывает чипы по индивидуальному заказу, но, указывают аналитики, среди её клиентов значатся Google и Meta✴. «Наши клиенты — гиперскейлеры продолжают масштабировать свои кластеры ИИ», — сообщил гендиректор Broadcom Хок Тань (Hock Tan) в сентябре, когда компания повысила свой прогноз выручки от деятельности в области ИИ за 2024 финансовый год с $11 млрд до $12 млрд. У компании есть три крупных клиента на разработку чипов по индивидуальному заказу, добавил он. Крупнейшим конкурентом Broadcom в этой области является компания Marvell, которая также предлагает передовые решения для соединения чипов. Рынок кастомных чипов к 2028 году может вырасти до $45 млрд — две компании его поделят, заявил недавно гендиректор Marvell Крис Купманс (Chris Koopmans). У Intel уже «почти готова» графика Xe3, хотя только вчера вышли первые видеокарты на Xe2
04.12.2024 [23:48],
Николай Хижняк
Заслуженный исследователь Intel Том Петерсен (Tom Petersen), фактически ставший лицом графического направления компании, принял участие в подкасте The Full Nerd, где рассказал о запуске новой серии настольных видеокарт Battlemage на архитектуре Xe2. В состав серии пока входят только две модели ускорителей — Arc B580 и Arc B570. Не вдаваясь в детали, Петерсен не исключил возможности появления ещё более скоростной графики на базе архитектуры Xe2 в будущем. 
Источник изображения: VideoCardz В настоящее время компания сосредоточена на предстоящем старте продаж первой модели серии Battlemage — Arc B580, которая станет доступна с 13 декабря. Младшая модель Arc B570 поступит в продажу 16 января 2025 года. В более широком плане Петерсен дал понять, что Intel не намерена сворачивать развитие направления Arc Graphics. По его словам, компания почти завершила разработку архитектуры Xe3 и уже приступила к работе над её преемником. Он отметил, что Xe3 находится на последней стадии разработки — её сейчас тестируют команды по программному обеспечению Intel, в то время как аппаратные инженеры сосредоточены на следующем поколении графической архитектуры. «Я хотел бы сообщить, что наша следующая разработка называется Xe3. Она придёт на смену Xe2. И, да, всё верно, она практически завершена. Теперь командам по программному обеспечению предстоит много работы над Xe3. А командам по аппаратному обеспечению нужно заняться следующим проектом. Это наш ритм работы, и мы должны ему следовать», — заявил Том Петерсен в ходе подкаста The Full Nerd.  Разумеется, Петерсен несколько упростил текущее положение дел, так как командам по программному и аппаратному обеспечению ещё предстоит много работы над устранением возможных ошибок в архитектурах Xe2 и Xe3 соответственно после выпуска серии видеокарт Battlemage и начала производства чипов на базе Xe3. Однако главный вывод заключается в том, что Intel не намерена снижать темп и продолжит развивать направление по производству видеокарт. В рамках подкаста Петерсен напомнил, что новые видеокарты Intel запускаются с интервалом более одного года. Учитывая запланированный выход первой видеокарты серии Battlemage в декабре, первых решений на базе Xe3 стоит ожидать не ранее 2026 года. 
Источник изображения: Intel Ещё до выпуска первого поколения графики Arc (Alchemist на архитектуре Xe) Intel объявила о масштабных планах развития своего графического направления. Компания заявила, что в перспективе выпустит графику Arc Battlemage (Xe2), затем Arc Celestial (Xe3) и Arc Druid (предположительно Xe4). Intel также обещала выйти в сегмент видеокарт «ультра-энтузиаст» (самые производительные игровые решения), однако серия Battlemage пока не дотягивает даже до сегмента «энтузиаст», находясь ступенью ниже. В лучшем случае Arc B580 сможет предложить производительность немного выше GeForce RTX 4060 от Nvidia. ИИ обойдётся без Nvidia: Amazon выпустила системы на чипах Trainium2, а через год выйдут Trainium3
04.12.2024 [18:46],
Павел Котов
Подразделение Amazon Web Services (AWS) компании Amazon объявило на проводимой им конференции re:Invent, что клиенты её облачной платформы теперь могут пользоваться системами с ускорителями Trainium2, предназначенными для обучения и запуска больших языковых моделей искусственного интеллекта. 
Источник изображения: aws.amazon.com Представленные в прошлом году чипы работают в четыре раза быстрее предшественников: один инстанс EC2 с 16 ускорителями Trainium2 предлагает производительность до 20,8 Пфлопс. Это значит, что при развёртывании масштабной модели Meta✴ Llama 405B на платформе Amazon Bedrock клиент получит «трёхкратный прирост скорости генерации токенов по сравнению с другими доступными предложениями крупных облачных провайдеров». Можно будет также выбрать систему EC2 Trn2 UltraServer с 64 ускорителями Trainium2 и производительностью 83,2 Пфлопс. Отмечается, что показатель 20,8 Пфлопс относится к плотным моделям и точности FP8, а 83,2 Пфлопс — к разреженным моделям и FP8. Для связи между ускорителями в системах UltraServer используется интерконнект NeuronLink. Совместно со своим партнёром в лице Anthropic, основным конкурентов OpenAI в области больших языковых моделей, AWS намеревается построить крупный кластер систем UltraServer с «сотнями тысяч чипов Trainium2», где стартап сможет обучать свои модели. Он будет в пять раз мощнее кластера, на котором Anthropic обучала модели текущего поколения — по оценке AWS, он «станет крупнейшим в мире вычислительным кластером для ИИ, о котором сообщалось до настоящего времени». Проект поможет компании превзойти показатели, которые обеспечиваются актуальными ускорителями Nvidia, которые по-прежнему пользуются высоким спросом и остаются в дефиците. Хотя в начале следующего года Nvidia готовится запустить ускорители нового поколения Blackwell, которые при 72 чипах на стойку предложат до 720 Пфлопс для FP8. Возможно, поэтому AWS уже сейчас анонсировала ускорители нового поколения Trainium3, которые предлагают ещё один четырёхкратный прирост производительности для систем UltraServer — ускорители будут производиться с использованием техпроцесса 3 нм, а их развёртывание начнётся в конце 2025 года. Потребность в системах нового поколения в компании обосновали тем, что современные модели ИИ по масштабам подходят к триллионам параметров. Инстансы Trn2 пока доступны только в регионе US East инфраструктуры AWS, но скоро появятся и в других; системы UltraServer в настоящее время работают в режиме предварительного доступа. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2025 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews. kz
![]()
![]()








 MWC 2018
MWC 2018 2018
2018 Computex
Computex








