|
Опрос
|
реклама
Быстрый переход
В Китае квантовый компьютер впервые применили для точной настройки ИИ
09.04.2025 [10:26],
Геннадий Детинич
Китайские учёные первыми в мире использовали квантовый компьютер для точной настройки искусственного интеллекта — большой языковой модели с одним миллиардом параметров. Это стало первым использованием квантовой платформы, имеющим практическую ценность. В этом проявил себя компьютер Wukong китайской компании Origin, основанный на 72 сверхпроводящих кубитах. 
Источник изображения: Origin Система Wukong относится к третьему поколению квантовых компьютеров Origin. В январе 2024 года к ней был открыт облачный доступ со всего мира. Как признаются разработчики, поток учёных возглавили исследователи из США, несмотря на то что китайским учёным доступ к аналогичным ресурсам западных партнёров по-прежнему закрыт. «Это первый случай, когда настоящий квантовый компьютер был использован для точной настройки большой языковой модели в практических условиях. Это демонстрирует, что современное квантовое оборудование может начать поддерживать задачи обучения ИИ в реальном мире», — сказал Чэнь Чжаоюнь (Chen Zhaoyun), исследователь из Института искусственного интеллекта при Национальном научном центре в Хэфэе. По словам учёных, система Origin Wukong на 8,4 % улучшила результаты обучения ИИ при одновременном сокращении количества параметров на 76 %. Обычно для решения подобных задач — специализации ИИ общего назначения — используются суперкомпьютеры, что требует значительных вычислительных и энергетических ресурсов. Квантовый вычислитель, использующий принцип квантовой суперпозиции — множества вероятностных состояний вместо двух классических (0 и 1), способен экспоненциально ускорить расчёты при относительно скромных затратах ресурсов. В частности, учёные продемонстрировали преимущества точной настройки большой языковой модели с помощью квантовой системы для диагностики психических расстройств (число ошибок снижено на 15 %), а также при решении математических задач, где точность выросла с 68 % до 82 %. Для запуска алгоритмов обучения ИИ на квантовой платформе исследователи разработали то, что назвали «квантово-взвешенной тензорной гибридной настройкой параметров». Весовые значения обрабатывала квантовая платформа, в то время как классическая часть готовила большую языковую модель. Благодаря суперпозиции и эффекту квантовой запутанности платформа Origin Wukong смогла одновременно обрабатывать огромное количество комбинаций параметров, что ускорило специализацию модели. Meta✴ лишилась главы фундаментальных ИИ-исследований
02.04.2025 [11:25],
Дмитрий Федоров
Вице-президент Meta✴ по исследованиям в области ИИ Джоэль Пино (Joelle Pineau) объявила о своём уходе из компании. Её последний рабочий день в Meta✴ назначен на 30 мая 2025 года. Отставка происходит на фоне активной инвестиционной стратегии компании в сфере ИИ, направленной на опережение OpenAI и Google. 
Источник изображения: Farhat Altaf / Unsplash О своём уходе Пино сообщила в публикации на LinkedIn, где подтвердила, что покинет Meta✴. Она занимала должность вице-президента компании по исследованиям в области ИИ и с 2023 года возглавляла подразделение Fundamental AI Research (FAIR). FAIR занимается фундаментальными разработками в области ИИ, часть которых впоследствии внедряется в ключевые цифровые продукты Meta✴. Уход Пино совпал с этапом технологического переосмысления внутри компании. Генеральный директор Meta✴ Марк Цукерберг (Mark Zuckerberg) обозначил ИИ как приоритетное направление и инвестировал в него многомиллиардные ресурсы. Согласно его заявлениям, Meta✴ стремится к созданию ИИ-ассистента, которым будут пользоваться более одного миллиарда человек, а также к разработке так называемого сильного ИИ (Artificial General Intelligence — AGI), то есть ИИ-систем, способных мыслить и действовать на уровне человека. В своём заявлении Пино указала, что на фоне глобальных изменений и ускоряющейся гонки в сфере ИИ она считает целесообразным «освободить пространство для других». Она добавила, что будет наблюдать за дальнейшим развитием событий «со стороны», зная, что у команды Meta✴ есть всё необходимое для построения эффективных и этически устойчивых ИИ-систем, способных интегрироваться в повседневную жизнь миллиардов людей. Пино присоединилась к Meta✴ в 2017 году для руководства лабораторией по исследованиям в области ИИ в Монреале. Она также занимает должность профессора информатики в Университете Макгилла (McGill University), где является содиректором лаборатории по обучению и логическому выводу. Среди проектов, курируемых Пино, — семейство открытых языковых моделей LLaMA, а также PyTorch — фреймворк машинного обучения для языка Python для разработчиков ИИ. Разработки под её руководством охватывали передовые направления в области компьютерных наук и впоследствии использовались в технологических решениях Meta✴. Объявление Пино прозвучало за несколько недель до проведения ежегодной конференции LlamaCon, которая состоится 29 апреля. Ожидается, что на мероприятии Meta✴ представит очередную версию большой языковой модели LLaMA. Главный директор по продуктам компании Крис Кокс (Chris Cox) заявил, что LLaMA 4 станет основой для ИИ-агентов нового поколения. По информации издания CNBC, компания также планирует выпустить отдельное приложение для чат-бота Meta✴ AI. На фоне этих разработок отставка Пино приобретает особое значение, учитывая её ключевую роль в формировании научного направления FAIR. Китайская Zhipu AI ворвалась в ИИ-гонку с бесплатным ИИ-агентом AutoGLM Rumination
31.03.2025 [11:49],
Дмитрий Федоров
Китайская компания Zhipu AI, специализирующаяся на разработке систем искусственного интеллекта, представила ИИ-агента под названием AutoGLM Rumination. Новинка стала частью волны аналогичных проектов на фоне нарастающей конкуренции на китайском рынке ИИ. AutoGLM Rumination способен выполнять углублённые исследования, а также справляться с прикладными задачами, включая поиск информации в интернете, планирование путешествий и составление исследовательских отчётов. 
Источник изображения: zhipuai.cn Агент основан на моделях собственной разработки Zhipu AI. В их число входят рассуждающая ИИ-модель GLM-Z1-Air и базовая языковая модель GLM-4-Air-0414. Компания утверждает, что GLM-Z1-Air демонстрирует производительность, сопоставимую с моделью R1 компании DeepSeek, но работает в восемь раз быстрее и требует лишь одну тридцатую вычислительных ресурсов. Такие характеристики указывают на потенциальное снижение затрат на развёртывание и эксплуатацию ИИ-систем, что особенно важно на фоне масштабной интеграции нейросетей в экономику и государственное управление. ИИ-агенты представляют собой автономные программные системы, способные принимать решения и выполнять широкий спектр задач без постоянного вмешательства пользователя. В начале 2025 года компания DeepSeek представила ИИ-модель, работающую при значительно меньших издержках, чем американские аналоги, что вызвало значительный интерес на рынке. На этом фоне китайские разработчики ускорили вывод отечественных решений в области ИИ. Презентация Zhipu AI состоялась спустя несколько недель после заявления конкурирующей компании Manus, представившей своего ИИ-агента как первого в мире универсального ИИ-агента. В отличие от Manus, предлагающей продукт по подписке стоимостью до $199 в месяц, AutoGLM Rumination будет доступен бесплатно. Компания заявляет, что пользователи смогут получить доступ к ИИ-агенту через официальный сайт модели GLM и мобильное приложение. Компания Zhipu AI была основана в 2019 году как самостоятельная организация, выделившаяся из исследовательской лаборатории при Университете Цинхуа (Tsinghua University) с целью коммерциализации разработок в области ИИ. За последние годы она заняла одно из ведущих мест среди китайских ИИ-стартапов. Zhipu AI известна разработкой серии моделей GLM, последняя из которых — GLM4 — по заявлению компании превосходит GPT-4 по ряду бенчмарков. Подробные данные о метриках и условиях тестирования не раскрываются. Ранее в марте Zhipu AI провела три раунда финансирования при участии китайских государственных структур. Последние инвестиции поступили от администрации города Чэнду, которая вложила в компанию 300 млн юаней (около $41,5 млн). Участие региональных властей отражает стратегическую заинтересованность китайских городов в развитии ИИ-решений, особенно в условиях усиливающегося соперничества с иностранными разработками. Ant Group придумала, как эффективно обучать ИИ на китайских чипах вместо Nvidia
24.03.2025 [10:55],
Дмитрий Федоров
Ant Group представила новый метод обучения ИИ-моделей, позволяющий использовать китайские полупроводники, включая чипы Huawei и Alibaba. Компания применила архитектуру Mixture of Experts и уже достигла результатов, сопоставимых с использованием графических процессоров (GPU) Nvidia H800, что укрепляет позиции Китая на фоне ограничений, введённых США. 
Источник изображений: Ant Group CO Это достижение знаменует собой важный этап в технологическом противостоянии между китайскими и американскими компаниями, которое резко обострилось после того, как DeepSeek доказала возможность создания современных больших языковых моделей (LLM) без миллиардных вливаний, аналогичных тем, которые делают OpenAI и Google. Хотя Ant Group по-прежнему использует решения Nvidia в ряде проектов, в новых разработках компания отдаёт предпочтение альтернативным поставщикам, включая AMD, а также местным китайским производителям полупроводников, особенно в условиях нарастающего давления со стороны экспортных ограничений США. Это позволяет китайским компаниям сохранять темп технологического прогресса и снижать зависимость от иностранных поставщиков, прежде всего от Nvidia. Согласно опубликованной в марте научной статье, Ant Group утверждает, что её ИИ-модели в отдельных тестах превзошли разработки компании Meta✴. Однако эти заявления пока не получили независимого подтверждения. При этом важно отметить, что модель H800, хотя и не относится к передовому классу ускорителей Nvidia, остаётся мощным инструментом, способным справляться с ресурсоёмкими задачами обучения ИИ. Благодаря собственной оптимизированной стратегии Ant Group удалось сократить расходы на обучение ИИ-модели объёмом в 1 трлн токенов с 6,35 млн юаней ($880 000) до 5,1 млн юаней ($707 000). В данном контексте токены — это минимальные единицы текста, на которых обучаются LLM, чтобы впоследствии генерировать осмысленные ответы на запросы пользователей.  В компании заявили о намерении внедрить свои новые языковые модели — Ling-Plus и Ling-Lite — в решения, ориентированные на промышленное применение, включая здравоохранение и финансовую сферу. Ant Group уже приобрела китайскую платформу Haodf.com, специализирующуюся на медицинских онлайн-сервисах, чтобы расширить возможности своей ИИ-инфраструктуры в области здравоохранения. Кроме того, компания развивает мобильное приложение Zhixiaobao, позиционируемое как ИИ-ассистент для повседневной жизни, а также Maxiaocai — сервис на основе ИИ, предоставляющий финансовые рекомендации. В опубликованной научной работе подчёркивается, что модель Ling-Lite показала лучшие результаты в одном из ключевых англоязычных тестов по сравнению с одной из версий Llama компании Meta✴. При этом обе модели — Ling-Lite и Ling-Plus — превзошли аналоги DeepSeek в бенчмарках на китайском языке. Ling-Lite содержит 16,8 млрд параметров — это настраиваемые элементы модели, определяющие её поведение при генерации текста. Модель Ling-Plus насчитывает 290 млрд параметров и по масштабности относится к категории больших языковых систем. Обе модели были представлены сообществу разработчиков в виде решений с открытым исходным кодом. По оценке MIT Technology Review, GPT-4.5 компании OpenAI содержит около 1,8 трлн параметров, а DeepSeek-R1 — 671 млрд. Архитектура Mixture of Experts, использованная в Ling-моделях, предполагает активацию отдельных подсетей внутри модели в зависимости от типа задачи, тем самым обеспечивая оптимальное распределение вычислительных ресурсов. Эта система напоминает команду специалистов, в которой каждый элемент ИИ-модели отвечает за строго определённую, узкоспециализированную функцию. Однако в процессе обучения возникли сложности: как сообщается в научной статье, даже незначительные изменения в аппаратной конфигурации или в структуре модели приводили к резкому росту числа ошибок. Такая нестабильность делает процесс обучения чувствительным к параметрам окружения и требует дополнительной адаптации на каждом этапе. Apple отстранила главу разработки ИИ из-за «утраты доверия» — за Siri теперь возьмётся идейный создатель Vision Pro
21.03.2025 [06:12],
Дмитрий Федоров
Apple провела перестановки в руководстве подразделений, связанных с ИИ и голосовым ассистентом Siri. Майк Роквелл (Mike Rockwell), руководитель отдела разработки Vision Pro, назначен новым главой подразделения ИИ, сменив Джона Джаннандреа (John Giannandrea), утратившего доверие Тима Кука (Tim Cook). Эти изменения произошли на фоне задержки запуска генеративного ИИ и растущего напряжения внутри компании. 
Источник изображения: Zhiyue / Unsplash Согласно источникам Bloomberg, решение о перестановках было принято после того, как генеральный директор Apple Тим Кук (Tim Cook) утратил уверенность в способности Джаннандреа эффективно управлять разработкой ИИ. Теперь Роквелл будет руководить как Siri, так и разработками в области ИИ в Apple. Одновременно с этим Пол Мид (Paul Meade), ранее отвечавший за разработку аппаратного обеспечения для гарнитуры дополненной реальности Apple Vision Pro под началом Роквелла, займёт пост главы Vision Pro Group. Ранее в этом месяце Apple в заявлении для техноблога Daring Fireball сообщила, что откладывает запуск обновлений генеративного ИИ для Siri до следующего года, поскольку разработка заняла больше времени, чем думали в компании. Позже Bloomberg сообщил о напряжённом совещании команды Siri, на котором старший директор Apple Робби Уокер (Robby Walker) назвал ситуацию с ИИ «уродливой». Сумеет ли Apple восстановить утраченный темп в гонке ИИ — вопрос, который пока остаётся открытым. OpenAI предоставила разработчикам свою самую дорогую ИИ-модель o1-pro
20.03.2025 [15:20],
Дмитрий Федоров
OpenAI выпустила более мощную версию своей ИИ-модели o1, получившую название o1-pro, и добавила её в API для разработчиков. По словам компании, o1-pro задействует больше вычислительных мощностей, чем o1, чтобы стабильно выдавать более качественные ответы. В настоящее время o1-pro доступна только избранным разработчикам — тем, кто уже потратил не менее $5 на услуги API OpenAI. 
Источник изображения: OpenAI OpenAI установила тариф в $150 за 1 млн токенов, переданных в ИИ-модель на обработку (примерно 750 000 слов), и $600 за 1 млн токенов, сгенерированных ИИ-моделью. Это в два раза дороже, чем GPT-4.5 при обработке входных данных, и в 10 раз дороже, чем «рассуждающая» ИИ-модель o1 при генерации текста. OpenAI рассчитывает, что повышенная производительность o1-pro убедит разработчиков платить такие внушительные суммы. Компания утверждает, что новинка использует дополнительные вычислительные ресурсы, чтобы «думать усерднее» и давать более точные ответы на сложные вопросы. «O1-pro в API — это версия o1, использующая больше вычислительных ресурсов, чтобы мыслить ещё глубже и давать ещё более точные ответы на самые сложные задачи», — заявил представитель OpenAI. Он добавил, что компания решила включить модель в API после многочисленных запросов от разработчиков. Однако первые отзывы об ИИ-модели o1-pro, которая с декабря 2024 года доступна на платформе ИИ-чат-ботов OpenAI для подписчиков ChatGPT Pro, оказались не слишком положительными. Пользователи обнаружили, что новинка с трудом справляется с головоломками судоку, а простые шутки про оптические иллюзии ставят её в тупик. Более того, некоторые внутренние тесты OpenAI, проведённые в конце 2024 года, показали, что o1-pro лишь незначительно превосходит o1 в задачах программирования и математики, но при этом демонстрирует более стабильные результаты. Meta✴ AI добрался до Европы, но с ограничениями и без обучения на данных пользователей
20.03.2025 [10:29],
Дмитрий Федоров
Meta✴ AI появится в Европе спустя почти год после приостановки его развёртывания в регионе из-за регуляторных ограничений. Начиная с этой недели, ИИ-ассистент компании станет доступен в приложениях WhatsApp, Facebook✴, Instagram✴ и Messenger для пользователей 41 европейской страны и 21 зарубежной территории. Однако функциональность ИИ-чат-бота будет ограничена только текстовым общением. 
Источник изображения: Farhat Altaf / Unsplash Meta✴ AI появился в США ещё в 2023 году, однако выход на европейский рынок пришлось приостановить после вмешательства ирландской Комиссии по защите данных (Data Protection Commission, DPC). Тогда регулятор потребовал от компании отложить обучение ИИ-модели на пользовательском контенте, опубликованном в Facebook✴ и Instagram✴. Помимо этого, Meta✴ приостановила запуск своей флагманской большой языковой модели Llama в Европейском союзе (ЕС) из-за нормативных ограничений. Теперь Meta✴ AI выходит на европейский рынок, но с серьёзными ограничениями. ИИ-чат-бот сможет помогать европейским пользователям в генерации идей, планировании поездок и поиске информации, опираясь на данные из интернета. Европейцы также смогут использовать Meta✴ AI для отображения определенных видов контента в своей ленте Instagram✴. Однако они не смогут использовать ИИ для создания или редактирования изображений, а также задавать вопросы о фотографиях. Meta✴ подчёркивает, что для обучения ИИ-модели не использовались данные пользователей из ЕС. «Этот запуск стал результатом почти года интенсивного взаимодействия с различными европейскими регуляторами, и пока мы предлагаем в регионе только текстовую модель, которая не была обучена на данных, полученных от пользователей из ЕС. Мы продолжим сотрудничать с регулирующими органами, чтобы люди в Европе имели доступ к инновациям Meta✴ в области искусственного интеллекта, которые уже доступны для всего остального мира», — заявила представитель Meta✴ Элли Хитрик (Ellie Heatrick). В ноябре прошлого года компания Meta✴ начала внедрять некоторые ИИ-функции в свои смарт-очки Ray-Ban Meta✴ в ЕС, но в настоящее время эти устройства не поддерживают ИИ-функции, которые позволяют европейцам спрашивать смарт-очки о том, что они видят. Тем не менее компания подчёркивает, что продолжит работать над достижением паритета в функциональности между европейской и американской версиями Meta✴ AI, постепенно расширяя его возможности. AMD похвасталась, что Ryzen AI Max+ 395 до 12 раз быстрее в работе с ИИ, чем прямой конкурент от Intel
17.03.2025 [23:03],
Николай Хижняк
Новейший флагманский мобильный процессор AMD Ryzen AI Max+ 395 семейства Strix Halo обеспечивает до 12 раз более высокую производительность в работе с различными большими языковыми моделями ИИ, чем чипы Intel Lunar Lake. Об этом AMD сообщила в своём официальном блоге, поделившись соответствующими диаграммами. 
Источник изображений: AMD Благодаря 16 вычислительным ядрам Zen 5, 40 графическим блокам RDNA 3.5, а также NPU XDNA 2 с производительностью 50 TOPS (триллионов операций в секунду), процессор Ryzen AI Max+ 395 обеспечивает до 12,2 раза более высокое быстродействие в определённых сценариях LLM, чем Intel Core Ultra 258V. Стоит напомнить, что в составе чипа Intel Lunar Lake имеются только четыре P-ядра и четыре E-ядра, что в общей сложности вполовину меньше, чем у Ryzen AI Max+ 395. Однако разница в производительности между платформами выражена гораздо сильнее, чем в два раза. 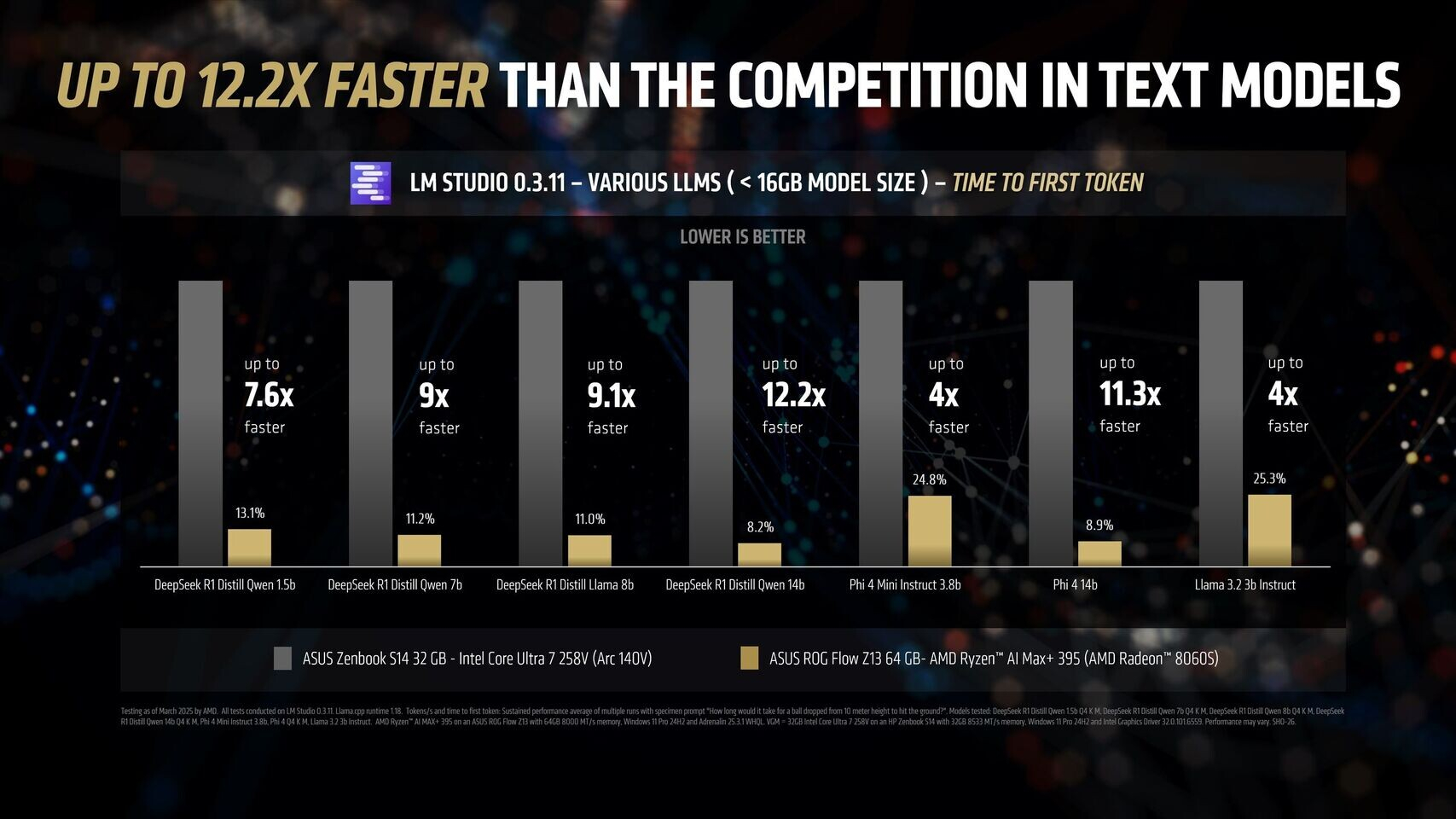 Преимущество чипа Ryzen AI Max+ 395 становится ещё более заметным с повышением сложности языковых моделей. Наибольшая разница в производительности между платформами видна при работе с LLM с 14 млрд параметров, где требуется больше оперативной памяти. Напомним, что Lunar Lake представляет собой гибридные процессоры, оснащённые до 32 Гбайт набортной ОЗУ. 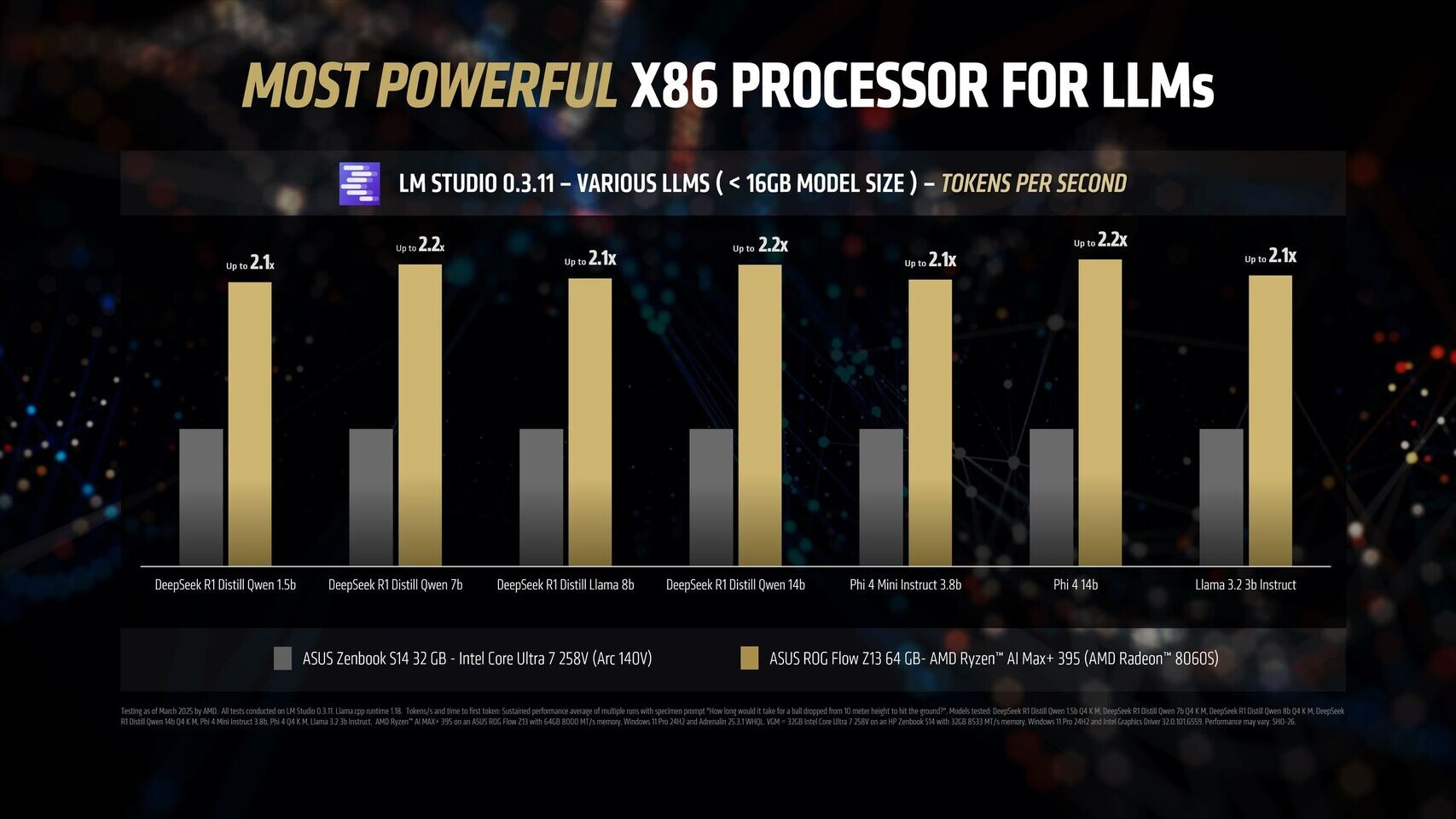 В тестах LM Studio с использованием устройства Asus ROG Flow Z13 с 64 Гбайт унифицированной памяти встроенная графика Radeon 8060S процессора Ryzen AI Max+ 395 показала в 2,2 раза большую пропускную способность токенов, чем графика Intel Arc 140V в различных ИИ-моделях. В тестах Time-to-First-Token (метрика производительности языковых моделей, которая показывает, сколько времени проходит от отправки запроса до генерации первого токена ответа) чип AMD продемонстрировал четырёхкратное преимущество над конкурентом в таких моделях, как Llama 3.2 3B Instruct, и увеличил отрыв до 9,1 раза в моделях, поддерживающих 7–8 млрд параметров, например DeepSeek R1 Distill. 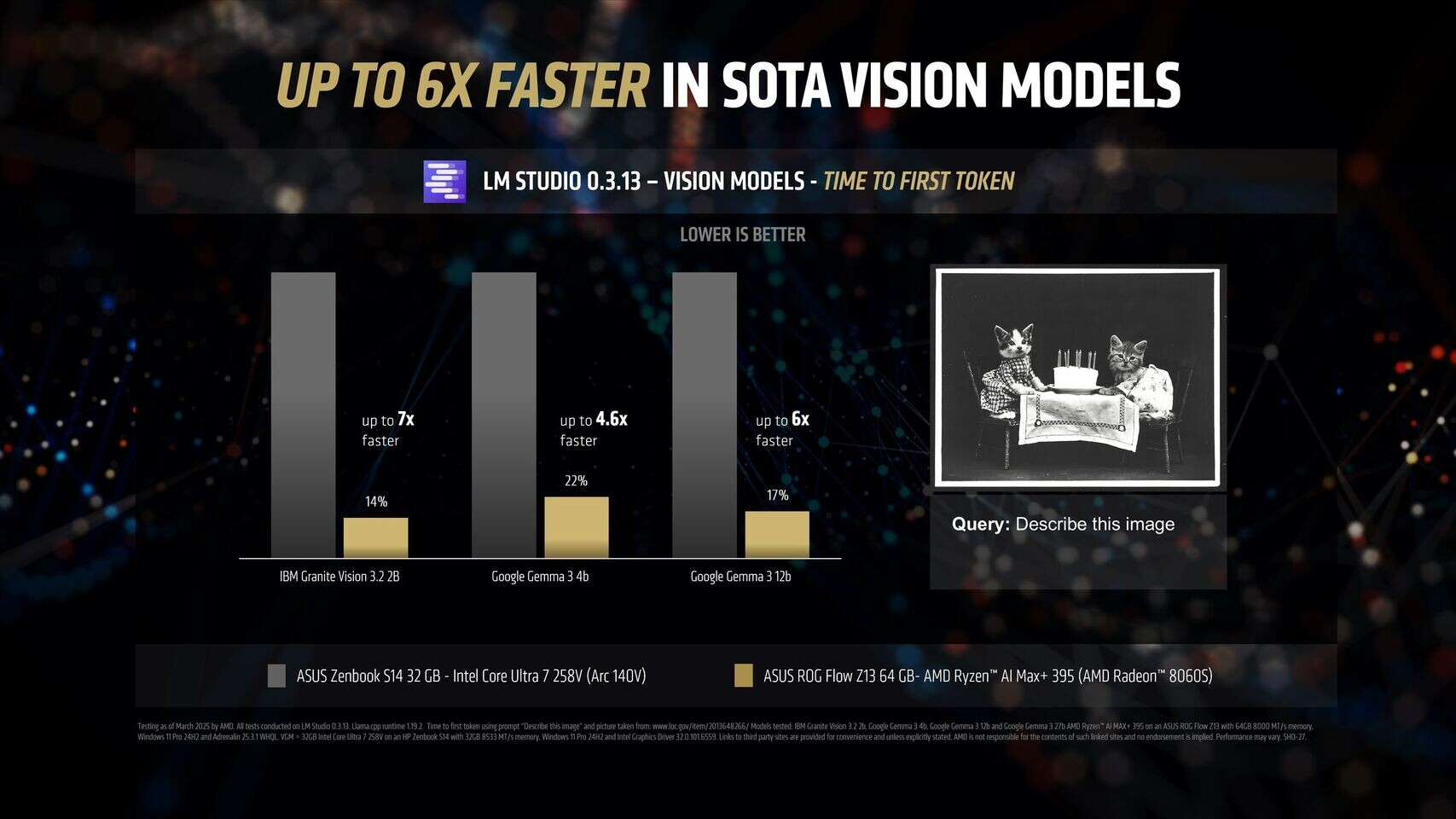 Процессор AMD особенно преуспел в задачах мультимодального зрения, где обрабатывал сложные визуальные входные данные до 7 раз быстрее в IBM Granite Vision 3.2 3B и в 6 раз быстрее в Google Gemma 3 12B по сравнению с чипом Intel. Поддержка платформой AMD технологии Variable Graphics Memory позволяет выделять до 96 Гбайт памяти в качестве VRAM из систем с унифицированной памятью объёмом до 128 Гбайт, что, в свою очередь, позволяет развёртывать современные языковые модели, такие как Google Gemma 3 27B Vision. Преимущества производительности процессора AMD над конкурентом видны и в практических ИИ-приложениях, таких как анализ медицинских изображений и помощь в кодировании с помощью высокоточного 6-битного квантования в модели DeepSeek R1 Distill Qwen 32B. Baidu представила флагманские модели Ernie 4.5 и X1 и готова к соперничеству с DeepSeek и СhatGPT
16.03.2025 [14:09],
Дмитрий Федоров
Китайская технологическая корпорация Baidu Inc. представила новую ИИ-модель Ernie X1, способную объяснять ход своих рассуждений. Стремясь укрепить позиции на фоне растущей конкуренции, особенно со стороны DeepSeek, компания также обновила свою базовую ИИ-модель до Ernie 4.5, заявив о её превосходстве над GPT-4.5. Одновременно Baidu сделала все уровни своего сервиса, включая X1, бесплатными для пользователей ИИ-чат-бота, причём на несколько недель раньше срока. Кроме того, корпорация объявила, что с 30 июня её ИИ-модели Ernie AI станут открытыми. 
Источник изображения: Baidu.com Ernie X1 предназначена для ведения повседневных диалогов, выполнения сложных вычислений и логических рассуждений. Подобную функциональность ранее продемонстрировала думающая ИИ-модель DeepSeek R1, которая потрясла мировую ИИ-индустрию, предложив производительность, сопоставимую с возможностями лучших мировых ИИ-чат-ботов, но при этом потребляющую значительно меньше ресурсов на разработку. Запуск Ernie X1 можно рассматривать как ответ Baidu на усиливающуюся конкуренцию в сфере генеративного ИИ. Одновременно с презентацией Ernie X1 компания Baidu представила обновлённую ИИ-модель — Ernie 4.5. По заявлению разработчиков, эта версия превосходит GPT-4.5 компании OpenAI по ряду отраслевых тестов, в частности в области генерации текстов. Однако конкретные показатели и методология сравнений не раскрываются. Также Baidu предоставила бесплатный доступ ко всем уровням сервиса, включая X1, причём на несколько недель раньше срока. Одним из наиболее значительных шагов компании стало объявление о переходе с 30 июня 2025 года к модели с открытым исходным кодом, что представляет собой серьёзное стратегическое изменение. Это решение можно рассматривать как реакцию на растущую популярность DeepSeek, чьи модели с открытым кодом получили широкое признание среди разработчиков по всему миру. Открытие исходного кода Ernie AI может позволить Baidu привлечь больше специалистов к совершенствованию своих технологий и усилить влияние на международном рынке ИИ. Помимо выпуска новых моделей, Baidu интегрировала конкурирующую DeepSeek R1 в свою поисковую систему, которая остаётся ключевым направлением её бизнеса. Этот шаг позволяет повысить точность поиска и улучшить качество ответов, генерируемых системой. По итогам IV квартала 2024 года выручка Baidu от облачных сервисов выросла на 26 %, что объясняется увеличением спроса на вычислительные мощности, необходимые для работы с ИИ. Однако этот успех был частично нивелирован слабой динамикой рекламных продаж, обусловленной экономической ситуацией в Китае. В феврале этого года Baidu завершила сделку по приобретению платформы потокового вещания YY Live у Joyy Inc. Сумма сделки составила $2,1 млрд, из которых $1,6 млрд находились в условном депозите. Теперь эти средства могут быть направлены на развитие ИИ и облачных технологий. DeepSeek похвасталась расчётной рентабельностью своих ИИ-сервисов на уровне 545 %
02.03.2025 [06:51],
Алексей Разин
Китайские разработчики языковых моделей DeepSeek на этой неделе опубликовали интересные данные о расчётной рентабельности своих языковых моделей V3 и R1 в течение условного 24-часового периода. По данным авторов расчётов, эти модели позволяют заработать в шесть с половиной раз больше, чем расходуют на аренду вычислительных мощностей. 
Источник изображения: Unsplash, Solen Feyissa По сути, если опираться на опубликованную представителями DeepSeek на страницах GitHub информацию, за произвольно выбранные сутки компания потратила на аренду ускорителей вычислений $87 072, тогда как потенциальная монетизация её моделей V3 и R1 могла бы принести ей $562 027 за тот же период. Соотнеся эти величины, авторы расчётов и получили условную рентабельность в размере 545 %. Впрочем, важно понимать, что расчёты по этой методике подразумевают ряд допущений. Прежде всего, потенциальные доходы рассчитывались без учёта скидок, а за основу бралась ценовая политика в отношении более дорогой модели R1. Во-вторых, далеко не все публично доступные сервисы DeepSeek монетизированы и являются платными для пользователей. Если бы плата за доступ к ним взималась по коммерческой стоимости, количество пользователей могли бы сократиться, а это уменьшило бы получаемую выручку. Наконец, расчёты в этом примере никак не учитывают расходы DeepSeek на электроэнергию и аренду хранилищ для данных, а также на исследования и разработки как таковые. В любом случае, данная попытка продемонстрировать потенциальным инвесторам свою перспективность и состоятельность должна вдохновить представителей других стартапов на публикацию подобных расчётов. Пока сфера искусственного интеллекта требует от инвесторов огромных затрат, а финансовая отдача весьма эфемерна и отдалена во времени. DeepSeek поясняет, что высокой эффективности своих сервисов компания добилась за счёт ряда оптимизаций. Во-первых, трафик распределяется между несколькими центрами обработки данных максимально равномерно. Во-вторых, гибко регулируется время обработки запроса пользователя. В-третьих, обрабатываемые данные сортируются по партиям для оптимальной нагрузки на инфраструктуру. ИИ Gemini пропал из приложения Google для iOS
19.02.2025 [17:01],
Дмитрий Федоров
Компания Google завершила процесс переноса ИИ Gemini в отдельное приложение для iOS и официально отключила поддержку ассистента в основном приложении Google для iPhone. Теперь для работы с ИИ необходимо установить приложение Gemini из Apple App Store, которое обеспечивает доступ ко всем функциям ИИ, включая поддержку Gemini Live и генерацию изображений с помощью Imagen 3. 
Источник изображений: Google Ещё в ноябре 2024 года компания представила самостоятельное приложение Gemini для iOS. Несмотря на это, до настоящего момента пользователи могли продолжать работать с Gemini через приложение Google. После отключения поддержки Gemini в приложении Google при попытке воспользоваться сервисом пользователи видят сообщение, призывающее установить основную программу. Самостоятельное приложение Gemini для iOS предлагает весь спектр знакомых функций, а также ряд новых возможностей. Важным нововведением стала поддержка генератора изображений с искусственным интеллектом Imagen 3, позволяющего пользователям создавать изображения высокого качества за считанные секунды. Кроме того, голосовой помощник Gemini Live теперь доступен на нескольких языках, что расширяет его возможности общения с человеком.  Последнее обновление Gemini для iOS — версия 1.2025.0570102 — добавило расширенные функции интеграции с сервисами Google. Теперь пользователи могут, не выходя из приложения, прокладывать маршруты в Google Maps, просматривать рекомендованные видео в YouTube и работать с письмами в Gmail. Такой подход делает ИИ более универсальным инструментом, глубже интегрированным в экосистему Google. Отказ от поддержки Gemini в приложении Google для iOS обусловлен стремлением компании централизовать доступ к своему ИИ-ассистенту. Разделение функциональности позволяет Google гибко развивать продукт, оперативно выпускать обновления и внедрять новые технологии без ограничений, связанных с интеграцией в сторонние сервисы. Кроме того, отдельное приложение открывает перспективы монетизации ИИ, включая возможное введение подписочных моделей для расширенной функциональности. Этот шаг Google следует рассматривать в контексте растущей конкуренции на рынке ИИ. Компания активно развивает свои технологии, соперничая с Apple, Microsoft и OpenAI. Перенос Gemini в отдельное приложение может упростить дальнейшие обновления, ускорить внедрение новых функций и повысить конкурентоспособность продукта, особенно в сравнении с ChatGPT компании OpenAI и возможными будущими ИИ-решениями Apple для Siri. Google Meet с ИИ Gemini научился назначать исполнителей и заменил ручное ведение заметок
19.02.2025 [06:28],
Дмитрий Федоров
Google Meet, являясь одним из ключевых инструментов для корпоративных пользователей Google Workspace, продолжил интеграцию ИИ в процесс видеоконференций. Новая функциональность на базе ИИ Gemini способна анализировать разговор в режиме реального времени, фиксировать ключевые тезисы и автоматически формировать чек-лист последующих действий. Более того, ИИ не просто фиксирует важные моменты, но и прикрепляет к задаче основную заинтересованную сторону, а также определяет дедлайны, что минимизирует вероятность потери критически важной информации. 
Источник изображений: Google Функция ведения заметок впервые была представлена в августе 2024 года. Её основная цель — автоматическое создание структурированных отчётов по итогам встреч. Редакция издания The Verge тестировала этот инструмент с момента запуска и отметила, что он не допускает критических ошибок. Теперь технология голосовой транскрипции на базе Gemini не только фиксирует сказанное, но и различает голоса участников, хотя и не всегда безупречно. После завершения встречи ИИ обобщает её результаты с удивительно последовательной структурой в документе Google Docs и автоматически рассылает его всем участникам. Эта функция будет особенно полезна командам, которым важно оперативно фиксировать принятые решения и снижать нагрузку на сотрудников, вручную записывающих ключевые моменты. 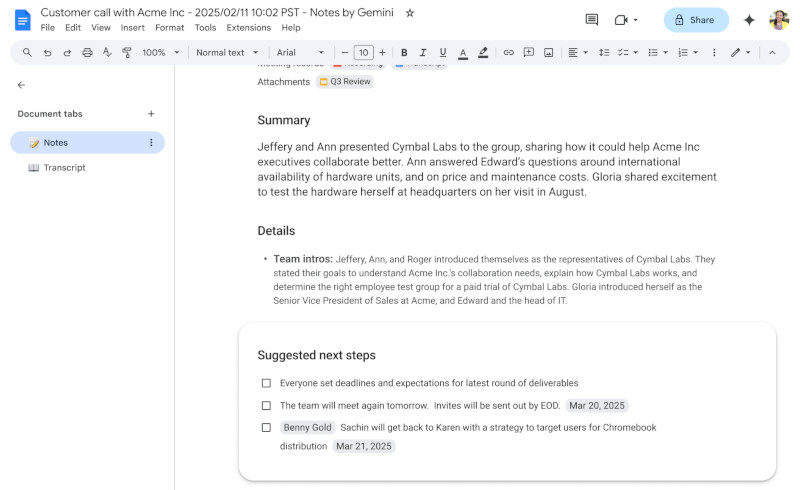 Google подчёркивает, что внедрение новой функции будет проходить «значительно медленнее обычного», поскольку компания тщательно отслеживает её качество и производительность. Хотя ИИ-заметки и автоматическое создание списка действий значительно упрощают работу пользователей, вопрос конфиденциальности остаётся актуальным. Многие компании обсуждают чувствительные данные во время встреч, и автоматический анализ речи может вызывать опасения, что конфиденциальная информация попадёт в большую языковую модель Gemini. Функция начала внедряться сегодня, однако организациям следует учитывать потенциальные риски, связанные с использованием ИИ в корпоративной среде. Современную ИИ-модель запустили на крошечном компьютере Raspberry Pi Zero — непрактично, но работает
18.02.2025 [17:01],
Павел Котов
Энтузиаст Бинь Фам (Binh Pham) создал USB-устройство на основе одноплатного компьютера Raspberry Pi Zero, на котором локально запускается большая языковая модель искусственного интеллекта, генерирующая художественные тексты. 
Источник изображения: youtube.com/@build_with_binh Программную часть проекта автор разработал с помощью библиотеки llama.cpp и утилиты llamafile — они предназначены для вывода больших языковых моделей ИИ. Это оказалось непростой задачей, поскольку у Raspberry Pi Zero всего 512 Мбайт оперативной памяти и процессор с устаревшей архитектурой ARMv6, что помешало компиляции проекта в исходном варианте. Чтобы обойти эти ограничения, энтузиасту пришлось преобразовать оптимизированный для ARMv8 набор инструкций в llama.cpp и удалить оттуда все нотации и механизмы оптимизации, предназначенные для современного оборудования. Сам одноплатный компьютер Raspberry Pi Zero и плату расширения с разъёмом USB для подключения к современным компьютерам Бинь Фам поместил в распечатанный на 3D-принтере корпус. Из-за скромных вычислительных ресурсов пришлось ограничить контекст 64 токенами и использовать модели, содержащие от 15 млн до 136 млн параметров. Самая маленькая — Tiny15M — показала максимальную скорость среди всех протестированных моделей: 223 мс на токен. Для Lamini-T5-Flan-77M этот показатель составил 2,5 с на токен, а для SmolLM2-136M — 2,2 с на токен. При такой скорости работы устройство трудно назвать практичным, но автор проекта решил не останавливаться на достигнутом. Он посчитал, что управлять ИИ через интерфейс командной строки недостаточно удобно, и предложил более комфортный способ. Чтобы отправить запрос, пользователю необходимо создать в указанном расположении пустой текстовый файл, имя которого служит запросом к модели. Обнаружив файл, система отправляет запрос к ИИ и записывает его ответ в содержимое того же файла. Своим проектом Бинь Фам решил показать, каким может стать взаимодействие с локальными моделями ИИ в будущем. «Максимально правдивый ИИ»: xAI Илона Маска выпустила флагманскую ИИ-модель Grok 3
18.02.2025 [11:42],
Дмитрий Федоров
Компания xAI, основанная Илоном Маском (Elon Musk), представила флагманскую ИИ-модель Grok 3, а также обновления для iOS-приложения Grok и веб-версии. Разработка Grok 3 велась несколько месяцев, а её запуск, первоначально запланированный на 2024 год, был отложен. Для обучения Grok 3 были использованы вычислительные мощности, в 10 раз превышающие ресурсы его предшественника, что позволило существенно повысить точность и глубину анализа данных новой ИИ-моделью. 
Источник изображений: xAI Grok 3 представляет собой третье поколение семейства ИИ-моделей xAI, созданного в противовес таким разработкам, как GPT-4o компании OpenAI и Gemini корпорации Google. Новая ИИ-модель — серьёзный технологический шаг вперёд: усовершенствованные алгоритмы, увеличенные объёмы обучающих данных, возможность анализа изображений и даже интеграция ряда функций в социальной сети X. «Grok 3 на порядок мощнее Grok 2. Это максимально правдивый ИИ, даже если эта правда иногда расходится с политически корректной», — заявил Маск во время презентации. Для обучения Grok 3 xAI использовала один из крупнейших в мире дата-центров, расположенный в Мемфисе. В нём задействованы около 200 000 графических процессоров (GPU), что позволило обрабатывать более сложные массивы данных и выполнять вычисления с беспрецедентной скоростью. По словам Маска, ресурсы, использованные при обучении Grok 3, оказались в 10 раз больше, чем потребовалось для Grok 2. Кроме того, в обучающую выборку вошли не только общедоступные данные, но и материалы судебных дел, что потенциально расширяет возможности новой ИИ-модели в области анализа юридических документов. 
Дата-центр xAI, где обучался Grok 3, оснащён 200 000 GPU, причём расширение с 100 000 до 200 000 GPU заняло 92 дня
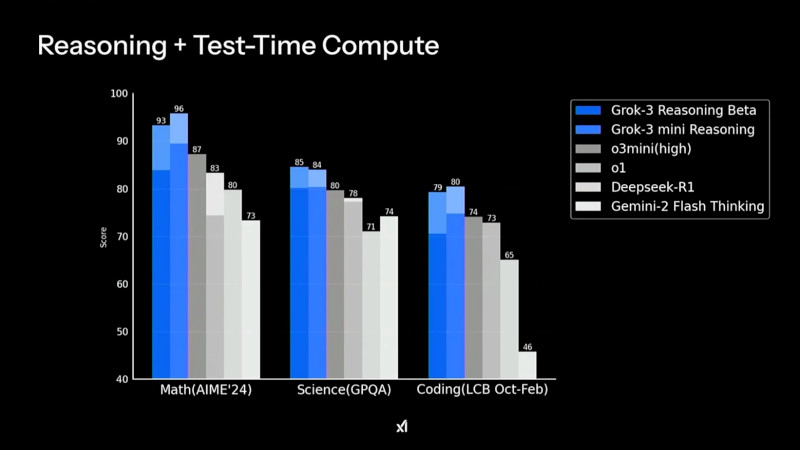
Grok 3 демонстрирует высокие результаты в тестах на математические, научные и задачи программирования, значительно опережая конкурентов в AIME'24, GPQA и LCB Компания xAI утверждает, что Grok 3 показывает превосходные результаты в тестах, в частности, опережая GPT-4o. В бенчмарке AIME, оценивающем математические способности, и GPQA, измеряющем уровень знаний в области физики, биологии и химии на уровне доктора наук, новинка демонстрирует выдающиеся показатели. Более того, ранняя версия Grok 3 заняла высокие позиции в Chatbot Arena (LMSYS) — платформе, где пользователи сравнивают ответы различных ИИ-моделей и голосуют за наиболее качественные. 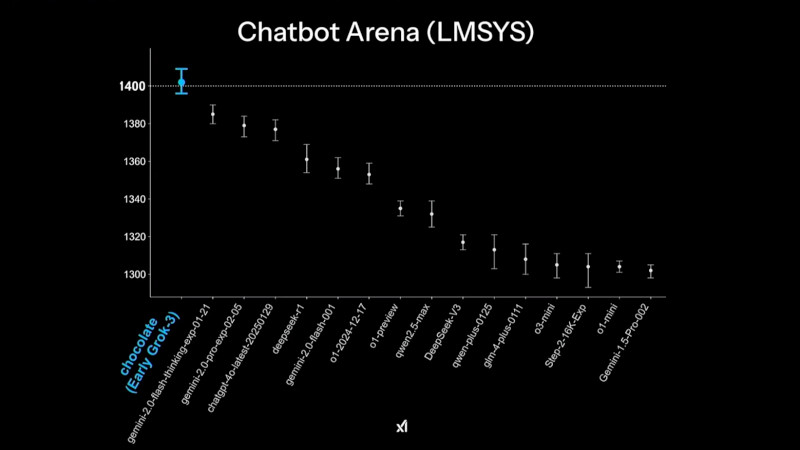
В рейтинге Chatbot Arena ранняя версия Grok 3 под кодовым названием Chocolate показала наивысший результат среди множества больших языковых ИИ-моделей Одним из ключевых нововведений стало появление Grok-3 Reasoning и Grok-3 mini Reasoning — специализированных ИИ-моделей, способных глубоко анализировать проблемы, подобно «рассуждающим» моделям, таким как o3-mini компании OpenAI и R1 китайской компании DeepSeek. Эти нейросети не просто дают ответы, но и тщательно проверяют факты перед их формулировкой, что позволяет значительно снизить вероятность ошибок. По данным xAI, Grok-3 Reasoning превзошёл o3-mini-high в ряде популярных бенчмарков, включая AIME 2025 Performance. 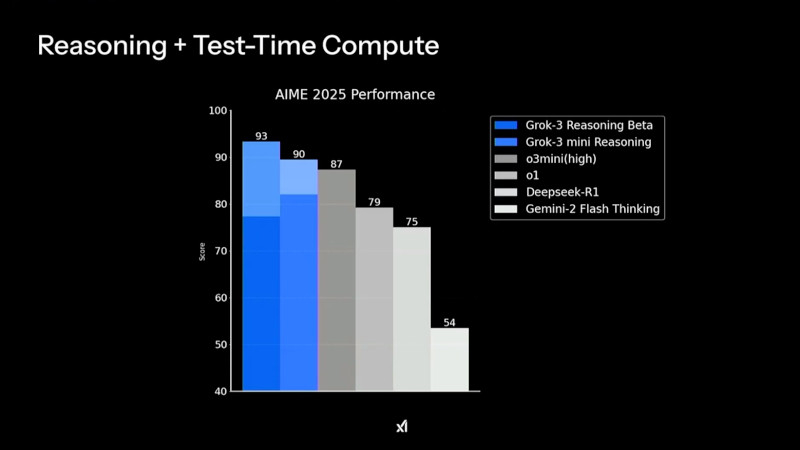
Производительность Grok 3 в тестах AIME 2025 показывает, что версия Grok-3 Reasoning Beta превосходит конкурентов, включая o3-mini-high и Deepseek-R1 Пользователи могут работать с Grok 3 через приложение Grok, в котором доступны два режима работы: Think — для стандартных запросов, и Big Brain — для сложных вычислений и логических задач. Режим Big Brain использует расширенные вычислительные мощности, что позволяет добиться более высокой точности ответов. Он оптимален для научных исследований, математического моделирования и программирования. По словам Маска, в приложении Grok некоторые «мысли» ИИ скрываются в процессе рассуждения, чтобы предотвратить дистилляцию — метод, используемый разработчиками конкурирующих ИИ-моделей для извлечения знаний из других нейросетей. 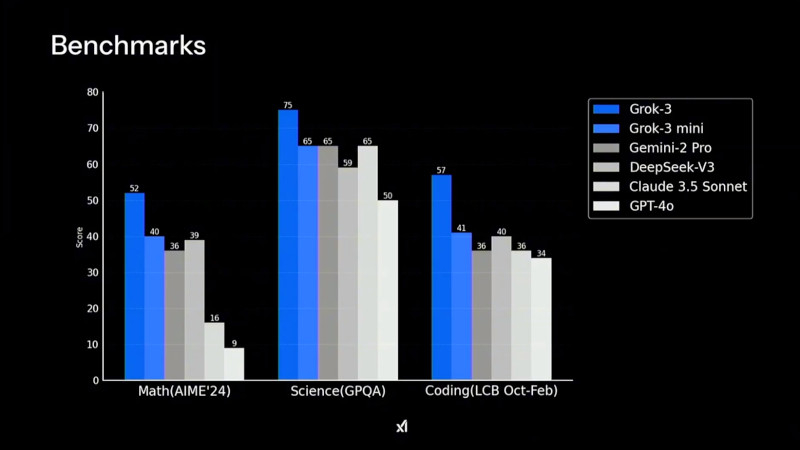
Grok 3 и его мини-версия превзошли конкурентов в тестах на математику, естественные науки и программирование, обогнав GPT-4o, Gemini-2 Pro и DeepSeek-V3 Ещё одной важной новацией стало появление DeepSearch — инструмента, построенного на базе «думающих» ИИ-моделей. Он выполняет интеллектуальный поиск по открытым источникам в интернете и данным социальной сети X, анализируя массивы информации и формируя сжатые аналитические сводки. Эта функциональность делает DeepSearch аналогом OpenAI Deep Research, но с более интегрированным подходом к обработке данных. На данный момент доступ к Grok 3 предоставляется подписчикам X Premium+, стоимость подписки составляет $22 в месяц. Дополнительно компания xAI запустила новый тариф SuperGrok, который стоит $30 в месяц или $300 в год. В него входят расширенные возможности reasoning-запросов, более глубокий анализ через DeepSearch и неограниченная генерация изображений. 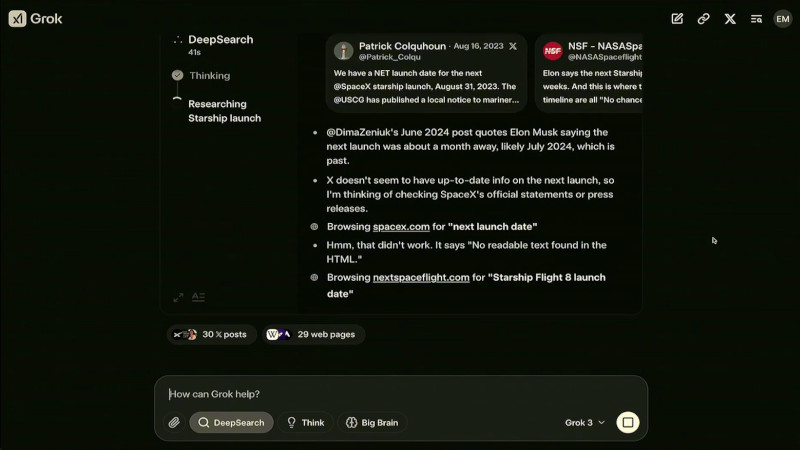
Работа DeepSearch в интерфейсе Grok 3, где система выполняет анализ и поиск актуальной информации о предстоящем запуске Starship от SpaceX В течение ближайшей недели приложение Grok получит обновление, которое добавит голосовой режим, позволяющий Grok общаться с пользователями синтезированным голосом. В дальнейшем, через несколько недель, Grok 3 станет доступен через корпоративный API xAI, что позволит компаниям интегрировать DeepSearch в свои бизнес-процессы. По словам Маска, его компания планирует открыть исходный код Grok 2: «Наш подход заключается в том, что мы выкладываем последнюю версию [Grok] в открытый доступ, когда следующая версия полностью готова. Когда Grok 3 станет зрелой и стабильной, что, вероятно, произойдёт в течение нескольких месяцев, тогда мы откроем исходный код Grok 2». Это означает, что после окончательной стабилизации работы Grok 3 разработчики смогут изучать исходный код его предшественника.  Первоначально Grok позиционировался как передовой и альтернативный ИИ, способный свободно обсуждать темы, которых избегают другие нейросети. Проведённые исследования показали, что до выхода Grok 3 ИИ-модель демонстрировала политический уклон, особенно в вопросах разнообразия и неравенства. Маск объяснил это тем, что обучающие данные включали общедоступные веб-страницы, отражающие определённые идеологические позиции. Маск пообещал, что Grok 3 будет более политически нейтральным, однако пока неясно, удалось ли xAI достичь этой цели. ИИ научился распознавать эмоции животных по выражению морды
17.02.2025 [04:29],
Дмитрий Федоров
Учёные разработали ИИ-системы, способные выявлять боль, стресс и заболевания у животных посредством анализа фотографий их морды. Британский ИИ Intellipig распознаёт дискомфорт у свиней, а ИИ-алгоритмы Израильского университета в Хайфе (UH) обучены определять стресс у собак. В эксперименте, проведённом в Университете Сан-Паулу (USP), ИИ продемонстрировал точность до 88 % при выявлении болевых реакций у лошадей. Эти технологии могут преобразить ветеринарную диагностику и значительно повысить уровень благополучия животных. 
Источник изображения: Virginia Marinova / Unsplash Система Intellipig, разработанная английскими учёными из Университета Западной Англии в Бристоле (UWE Bristol) совместно с шотландскими исследователями из Шотландского сельскохозяйственного колледжа (SRUC), предназначена для мониторинга состояния свиней на фермах. ИИ анализирует фотографии морды животных, выявляя три ключевых маркера: боль, недомогание и эмоциональное расстройство. Фермеры получают автоматические уведомления, что позволяет оперативно реагировать на ухудшение состояния животных и повышать эффективность сельскохозяйственного производства. Параллельно исследовательская группа из UH адаптирует технологии машинного обучения для работы с собаками. Ранее учёные разработали ИИ-алгоритмы, используемые в системах распознавания лиц, для поиска потерявшихся питомцев. Теперь эти алгоритмы применяются для анализа мимики животных с целью выявления признаков дискомфорта. Выяснилось, что 38 % мимических движений у собак совпадает с человеческими, что открывает новые возможности для изучения их эмоционального состояния. Традиционно подобные ИИ-системы полагаются на человека, который выполняет предварительную работу по определению значений различных форм поведения животных, основываясь на длительных наблюдениях за ними в различных ситуациях. Однако недавно в USP был проведён эксперимент, в котором ИИ самостоятельно анализировал фотографии лошадей, сделанные до и после хирургического вмешательства, а также до и после приёма обезболивающих препаратов. ИИ изучал глаза, уши и рот лошадей, определяя наличие болевого синдрома. Согласно результатам исследования, ИИ сумел выявить признаки, указывающие на боль, с точностью 88 %, что подтверждает эффективность такого подхода и открывает перспективы для дальнейших исследований. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2025 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews. kz
![]()
![]()








 MWC 2018
MWC 2018 2018
2018 Computex
Computex Подписаться
Подписаться