|
Опрос
|
реклама
Быстрый переход
Google создала и показала в деле ИИ, который заставляет роботов сначала думать, а потом делать
27.09.2025 [01:10],
Анжелла Марина
Компания Google DeepMind представила две новые модели искусственного интеллекта (ИИ) для робототехники Gemini Robotics 1.5 и Gemini Robotics-ER 1.5, которые совместно реализуют подход, при котором робот сначала «обдумывает» задачу и только потом выполняет действие. Технология основана на генеративных ИИ-системах и призвана преодолеть ограничения современных роботов, требующих длительной настройки под каждую конкретную задачу. 
Источник изображения: Google Генеративные ИИ-системы, способные создавать текст, изображения, аудио и даже видео, становятся всё более распространёнными. Подобно тому, как такие модели генерируют указанные типы данных, они могут также выдавать последовательности действий для роботов. Именно на этом принципе построен проект Gemini Robotics от Google DeepMind, в рамках которого анонсированы две взаимодополняющие модели, позволяющие роботам «думать» перед тем, как действовать. Хотя традиционные большие языковые модели (LLM) имеют ряд ограничений, внедрение симулированного рассуждения значительно расширило их возможности, и теперь аналогичный прорыв может произойти в робототехнике. Команда Google DeepMind считает, что генеративный ИИ способен кардинально изменить робототехнику, обеспечив роботам универсальную функциональность. В отличие от современных систем, которые требуют месяцев настройки под одну узкоспециализированную задачу и плохо адаптируются к новым условиям, новые ИИ-подходы позволяют роботам работать в незнакомых средах без перепрограммирования. Как отметила Каролина Парада (Carolina Parada), руководитель направления робототехники в DeepMind, роботы на сегодняшний день «чрезвычайно специализированы и сложны в развёртывании». Для реализации концепции DeepMind разработала Gemini Robotics-ER 1.5 и Gemini Robotics 1.5. Первая — это модель «зрение–язык» (VLM) с функцией воплощённого рассуждения (embodied reasoning), которая анализирует визуальные и текстовые данные, формирует пошаговый план выполнения задачи и может подключать внешние инструменты, например, поиск Google для уточнения контекста. Вторая — модель «зрение–язык–действие» (VLA), которая преобразует полученные инструкции в физические действия робота, одновременно корректируя их на основе визуальной обратной связи и собственного процесса «обдумывания» каждого шага. По словам Канишки Рао (Kanishka Rao) из DeepMind, ключевым прорывом стало наделение робота способностью имитировать интуитивные рассуждения человека, то есть думать перед тем, как действовать. Разработчики наглядно продемонстрировали, как работают новые модели — наделённый Gemini Robotics 1.5 человекоподобный робот Apollo на видео упаковывает вещи для поездки, а другой робот Aloha 2, точнее пара роборук — сортирует мусор. Обе модели основаны на фундаментальной архитектуре Gemini, но дополнительно дообучены на данных, отражающих взаимодействие с физическим миром. Это позволяет роботам выполнять сложные многоэтапные задачи, приближая их к уровню автономных агентов. При этом система демонстрирует кроссплатформенную совместимость. В частности, навыки, внедрённые в одного робота, например, на двурукого Aloha 2, могут быть перенесены на другого, включая гуманоида Apollo, без дополнительной настройки под конкретную механику. Несмотря на вероятный технологический прорыв, практическое применение технологии пока ограничено. Модель Gemini Robotics 1.5, отвечающая за управление роботами, доступна только доверенным тестировщикам. В то же время Gemini Robotics-ER 1.5 уже интегрирована в Google AI Studio, что даёт разработчикам возможность генерировать инструкции для собственных экспериментов с физически воплощёнными роботами. Однако, как считает Райан Уитвам (Ryan Whitwam) из Ars Technica, до появления бытовых роботов, способных выполнять повседневные задачи, ещё предстоит пройти значительный путь. ИИ от OpenAI обошёл все команды из людей, а заодно и Google Deepmind, на чемпионате по программированию
18.09.2025 [10:15],
Антон Чивчалов
Искусственный интеллект от OpenAI показал выдающийся результат в финале Международного студенческого чемпионата по программированию ICPC 2025, решив все 12 задач и превзойдя как команды студентов, так и модель Gemini 2.5 от Google Deepmind, передаёт сайт Decoder. 
Турнир ICPC 2025. Источник изображения: worldfinals.icpc.global В OpenAI рассказали, что её система решала задачи в таких же условиях, что и участники-люди, не имея никаких преимуществ. Задания выдавались в стандартном PDF-формате, на решение выдавалось пять часов. Ответы направлялись официальному судье ICPC, который оценивал все работы по одинаковым критериям. «Участник» от OpenAI состоял из двух моделей — GPT-5 и ещё одной, экспериментальной системы. GPT-5 успешно справилась с 11 задачами, а последнюю, самую сложную, решила экспериментальная модель после девяти попыток. Комбинированная система OpenAI превзошла результат Deepmind, который также участвовал в соревновании. Модель от Google решила только 10 задач. При этом ни OpenAI, ни Deepmind не участвовали в турнире официально, поэтому все призовые места были присуждены участникам-людям. Первое место в общем зачёте заняла команда Санкт-Петербургского госуниверситета. Интересно, что только ИИ-модели — от OpenAI и Google — решили одну из задач (Problem C), которую не смогла решить ни одна человеческая команда. В OpenAI подчёркивают, что её модель специально не обучалась для участия в конкурсах, решения генерировались в рамках общего подхода к логическому выводу и анализу. Турнир ICPC 2025 проходил в Баку, столице Азербайджана. Ранее те же модели показали высокие результаты на Международной математической олимпиаде и Международной олимпиаде по информатике. Google научила ИИ создавать живые 3D-миры, которые не рассыпаются за минуту — Genie 3 проложит путь к AGI
05.08.2025 [18:24],
Сергей Сурабекянц
Google DeepMind выпустила новую версию своей ИИ-модели мира — Genie 3, способную генерировать трёхмерные среды, с которыми можно взаимодействовать в реальном времени. Компания утверждает, что пользователи смогут исследовать сгенерированные миры гораздо дольше, чем раньше, а модель будет запоминать расположение предметов, остающихся за пределами кадра. Мировые модели также являются важным шагом на пути к «сильному ИИ», поскольку позволяют обучать ИИ без ограничений в богатой среде. 
Источник изображений: Google Модели мира или мировые модели — это тип систем искусственного интеллекта, которые могут моделировать трёхмерные среды для образовательных, развлекательных и научных целей, а также для обучения роботов или агентов ИИ. В сгенерированном пространстве на основе текстовой подсказки пользователь может перемещаться, как в видеоигре. В это направление ИИ Google вкладывает значительные ресурсы. В декабре компания представила Genie 2, способную создавать интерактивные миры на основе изображений, а сейчас формирует новую команду по созданию моделей миров под руководством бывшего ведущего разработчика генератора видео Sora от OpenAI. У существующих моделей миров пока сохраняется множество недостатков. Например, в сгенерированном Genie 2 мире можно находиться не более одной минуты. По отзывам экспертов, подобные миры больше напоминали «прогулку по размытой версии Google Street View, где всё менялось и трансформировалось неожиданным образом, когда пользователь отводил взгляд». Genie 3, по всей видимости, может стать заметным шагом вперёд. Разработчики утверждают, что пользователи смогут создавать миры, в которых поддерживается «несколько» минут непрерывного взаимодействия. Genie 3 может удерживать в памяти сгенерированные объекты около минуты, что позволит пользователю возвращаться к ним и обнаруживать их на прежнем месте. 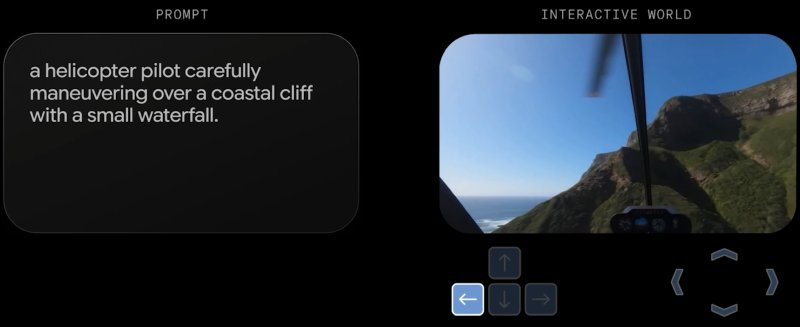 В Genie 3 появились так называемые «подсказываемые мировые события», позволяющие в реальном времени менять погодные условия или добавлять новых персонажей. Google сообщает, что пока количество способов взаимодействия с генерируемыми мирами ограничено, а читаемый текст «часто появляется только при наличии его в исходном описании мира».  На текущем этапе создаваемые модели миров обеспечивают разрешение 720p при частоте 24 кадра в секунду. Genie 3 пока недоступна для широкой аудитории. По словам Google, она существует в виде «ограниченной исследовательской предварительной версии», доступной «небольшой группе учёных и разработчиков» для тщательной оценки возможных рисков и путей их минимизации. Компания заявила, что пока лишь «изучает», как в дальнейшем предоставить доступ к Genie 3 «дополнительным тестировщикам». ИИ от Google самостоятельно обнаружил 20 уязвимостей в открытом ПО
05.08.2025 [00:44],
Анжелла Марина
Искусственный интеллект Google впервые самостоятельно выявил 20 уязвимостей в открытом программном обеспечении (Open Source). Баги были обнаружены с помощью системы Big Sleep в таких проектах, как мультимедийная библиотека FFmpeg и графический редактор ImageMagick. Об этом сообщил TechCrunch со ссылкой на заявление в X вице-президента компании по безопасности Хизер Адкинс (Heather Adkins). 
Источник изображения: AI Система Big Sleep была разработана совместно подразделением DeepMind и командой экспертов по кибербезопасности Project Zero. Google пока не раскрывает деталей найденных уязвимостей, так как они ещё не устранены. Однако сам факт успешной работы Big Sleep подтверждает, что ИИ-инструменты начинают приносить реальные результаты. По словам представителя компании Кимберли Самры (Kimberly Samra), каждый баг был найден и воспроизведён ИИ без участия человека, хотя перед отправкой отчётов эксперты, конечно же, перепроверили все данные. Вице-президент Google по инженерии Роял Хансен (Royal Hansen) назвал это прорывом в автоматизированном поиске уязвимостей. При этом Big Sleep — не единственный подобный инструмент: на рынке уже действуют и другие ИИ-системы, такие как RunSybil и XBOW. Последний, в частности, занимает верхние позиции в рейтинге платформы HackerOne, специализирующейся на поиске уязвимостей. Сооснователь и технический директор RunSybil Влад Ионеску (Vlad Ionescu) оценил Big Sleep как серьёзный и продуманный проект, подчеркнув, что за ним стоят опытнейшие специалисты. При этом он отметил растущую проблему: некоторые ИИ-системы генерируют ложные отчёты, имитируя реальные уязвимости. По его словам, разработчики всё чаще получают сообщения, которые выглядят убедительно, но на деле не содержат настоящих ошибок. Это явление он назвал цифровым «мусором» в сфере Bug Bounty — программы вознаграждений разработчикам за найденные ошибки. Google DeepMind назвал переманивание Meta✴ талантов из других компаний вполне оправданным
25.07.2025 [18:55],
Владимир Мироненко
Глава подразделения Google DeepMind Демис Хассабис (Demis Hassabis) заявил, что переманивание компанией Meta✴ квалифицированных специалистов в области ИИ вполне оправдано, поскольку ей необходимо получить конкурентное преимущество на ИИ-рынке, пишет Business Insider. Сейчас Meta✴ активно переманивает талантливых специалистов из других компаний, предлагая оклады, которые не снились даже главе Apple. 
Источник изображения: TheStandingDesk/unsplash.com «Сейчас Meta✴ не на переднем крае, возможно, им удастся вернуться туда, — сказал Хассабис в выпуске подкаста Lex Fridman, опубликованном в четверг. — С их точки зрения, их действия, вероятно, рациональны, поскольку они отстают, и им нужно что-то делать». Сейчас Meta✴ комплектует новое подразделение по созданию суперинтеллекта Superintelligence Labs, предлагая за работу в нём исследователям из передовых лабораторий, таких как OpenAI, зарплату до $100 млн. В числе перешедших в компанию за последнее время — бывший руководитель GitHub Нат Фридман (Nat Friedman), бывший генеральный директор Scale AI Александр Ван (Alexandr Wang) и бывшие исследователи OpenAI Шэнцзя Чжао (Shengjia Zhao), Шучао Би (Shuchao Bi), Цзяхуэй Юй (Jiahui Yu) и Хунъюй Жэнь (Hongyu Ren). Хассабис заявил, что, хотя Meta✴ делает такие предложения «рационально», многие специалисты в сфере ИИ считают приоритетной задачей «безопасное управление этой технологией». «Есть вещи важнее, чем просто деньги», — говорит глава Google DeepMind, вместе с тем признавая, что люди должны получать зарплату по рыночным ставкам. Впрочем, не все придерживаются мнения Хассабиса по поводу рациональности переманивания кадров. Генеральный директор OpenAI Сэм Альтман (Sam Altman) назвал такую практику отвратительной. Стёртые временем письмена прочитает «Эней» — ИИ от Google DeepMind для восстановления древних текстов и их истории
24.07.2025 [11:32],
Геннадий Детинич
Команда Google DeepMind представила новую генеративную модель — «Эней» (Aeneas). Это невероятный по возможностям инструмент для историков и археологов. Обученный на сотнях тысяч латинских текстов, «Эней» не просто восстановит утраченные фрагменты обнаруженных надписей — он расскажет их историю и происхождение, а также примерную датировку. 
Источник изображения: DeepMind Граждане римской империи умели и любили писать. Это нашло отражение даже в сериале «Рим» HBO, где граффити на стенах сооружений древнего Рима было нормой. Кое-что из подобных надписей дошло до современности, хотя и в сильно повреждённом виде. Также остаются нерасшифрованными множество обрывков текстов на памятниках, папирусах и других осколках прошлой цивилизации. Чтобы восстановить, датировать и вплести в контекст обнаруженные фрагменты, историкам приходится годами корпеть над каждым из них, опираясь исключительно на свой опыт и помощь коллег. ИИ «Эней» в корне изменит подход к этой работе. Подчеркнём, «Эней» — это не только восстановление сильно фрагментированных текстов. Модель помогает даже определить географическое происхождение повреждённой надписи — она с высокой точностью укажет на одну из 62 провинций древнеримской империи, где эта надпись была сделана. Кроме датирования надписи важным будет контекст, который ИИ разъяснит в понятной форме, что со временем наверняка найдёт своё выражение в исторических чат-ботах для любителей истории и обычных граждан. В общем случае «Эней» — это мультимодальная генеративная нейронная сеть, которая обрабатывает как текст, так и изображения надписей. Для обучения модели был создан обширный набор данных — Latin Epigraphic Dataset (LED), включающий более 176 000 латинских надписей из подборки наиболее полных научных источников. Для обработки текстового ввода модель использует трансформерный декодер, а также специализированные сети для восстановления утраченных символов и датировки текстов. Географическое определение происхождения надписей осуществляется с учётом как текста, так и визуальной информации. «Эней» способен за секунды находить текстовые и контекстные параллели среди тысяч надписей, что значительно ускоряет работу историков. Проверка модели на практике показала, что «Эней» восстанавливает повреждённые надписи с точностью 73 %, если промежутки не превышают десяти потерянных символов. Этот показатель снижается до 58 % только в том случае, если длина восстановления неизвестна, что само по себе невероятно сложная задача. Благодаря использованию визуальных данных модель может отнести одну из древнеримских надписей к 62 провинциям с точностью 72 %. Для датировки «Эней» помещает текст с интервалом в 13 лет от предоставленных историками дат. К ключевым возможностям модели можно отнести поиск параллелей, что выражается в анализе огромного корпуса латинских надписей, что позволяет выявлять тексты с похожими формулировками, синтаксисом, стандартизированными формулами или происхождением (это помогает историкам помещать надписи в более широкий исторический контекст); одновременный анализ текстовой и визуальной информации и их комбинацию; восстановление пробелов неизвестной длины, что делает его уникальным инструментом для работы с сильно повреждёнными артефактами. Наконец, модель «Эней» может работать с любыми другими письменами и носителями, достаточно обучить её новым языкам. Разработчик обещает свободно распространять «Энея», который основан на открытом коде. В доказательство этого компания разместила ссылки на все необходимые файлы и базы, включая обучающие материалы. Отметим, «Эней» был разработан в сотрудничестве с Университетом Ноттингема (University of Nottingham), а также с исследователями из университетов Уорика (Universities of Warwick), Оксфорда (Oxford) и Афинского университета экономики и бизнеса (Athens University of Economics and Business). Тестирование модели проводилось с участием 23 историков, которые анализировали датированные надписи с использованием «Энея» и без него. Результаты показали, что в 90 % случаев модель способствовала появлению новых идей для исследований и повышала точность определения происхождения и датировки текстов. Например, «Эней» уточнил датировку текста «Res Gestae Divi Augusti», приписываемого римскому императору Августу, предложив два вероятных диапазона, о которых спорят историки. Причём ИИ сделал это количественно, что демонстрирует наглядность научного поиска. Безусловно, «Эней» не заменяет историков, а выступает как инструмент, интегрирующийся в их рабочий процесс, предоставляя гипотезы и параллели для дальнейшего анализа. Модель демонстрирует потенциал для расширения на другие древние языки, такие как греческий или египетские иероглифы, что может обогатить глобальную историографию. Интерактивная версия «Энея» доступна бесплатно на сайте predictingthepast.com, а код и набор данных открыты для исследователей, что способствует дальнейшему совершенствованию модели. Microsoft переманила десятки талантливых сотрудников Google DeepMind для превосходства в ИИ
23.07.2025 [14:11],
Владимир Фетисов
Компания Microsoft за последние месяцы наняла более 20 сотрудников исследовательского подразделения Google DeepMind, работающего в сфере искусственного интеллекта. Переманивая талантливых разработчиков из других компаний, софтверный гигант не только ослабляет конкурентов, но также стремится получить преимущество в быстро развивающемся сегменте искусственного интеллекта. 
Источник изображения: Steve Johnson / Unsplash Последним теперь уже бывшим сотрудником DeepMind, который перешёл в Microsoft, стал Амар Субраманья (Amar Subramanya), возглавлявший инженерный отдел чат-бота Google Gemini. На смену места работы указывает информация в профиле разработчика на портале LinkedIn. «Здешняя культура отличается поразительно низким уровнем самомнения, но при этом переполнена амбициями», — написал Субраманья, подтверждая своё назначение корпоративным вице-президентом по ИИ в Microsoft. По данным источника, Субраманья присоединился к другим бывшим сотрудникам DeepMind, включая ведущего инженера Сонала Гупта (Sonal Gupta), инженера-программиста Адама Садовски (Adam Sadovsky) и менеджера по продуктам Тима Фрэнка (Tim Frank). В сообщении отмечается, что за последние шесть месяцев Microsoft переманила к себе по меньшей мере 24 сотрудника DeepMind. Активность Microsoft в сфере найма сотрудников ИИ-подразделений связана с тем, что в последние месяцы разные компании активизировали усилия по переманиванию к себе талантливых инженеров конкурентов. Это привело к резкому росту зарплат в сфере ИИ. Глава OpenAI Сэм Альтман (Sam Altman) даже раскритиковал Марка Цукерберга (Mark Zuckerberg) за то, что он, переманивая ведущих специалистов в Meta✴, предлагал существенные бонусы, вплоть до выплаты $100 млн. Проблема подбора персонала между Microsoft и Google стоит особо остро. Так, соучредитель и бывший глава DeepMind Мустафа Сулейман (Mustafa Suleyman) в настоящее время руководит ИИ-подразделением Microsoft и отвечает за стратегию компании в области потребительского ИИ. Это приводит к разногласиям между Сулейманом и Демисом Хассабисом (Demis Hassabis), его бывшим партнёром и нынешним главой DeepMind. В конце прошлого года Сулейман переманил из DeepMind Доминика Кинга (Dominic King) и Кристофера Келли (Cristopher Kelly), которые возглавили новое медицинское ИИ-подразделение. По словам Сулеймана, разработчикам уже удалось создать систему на базе нейросетей, которая в четыре раза успешнее диагностирует сложные заболевания, чем обычные врачи. Хассабис был в числе первопроходцев в сфере использования ИИ-технологий в здравоохранении. В прошлом году он получил Нобелевскую премию по химии за создание технологии прогнозирования сложной структуры белков. Сулейман присоединился к Microsoft в марте, когда софтверный гигант нанял большую часть персонала его ИИ-стартапа Inflection и заплатил $650 млн за лицензирование технологий компании. Субраманья и его коллега из DeepMind Мэт Веллозо (Mat Velloso) покинули Google в прошлом месяце, что привело к ряду перестановок в ИИ-подразделении Google, стремящемся успешно конкурировать с OpenAI, Anthropic и другими ИИ-компаниями. Веллозо в конечном счёте присоединился к Meta✴, которая собирает новую команду инженеров для создания так называемого суперинтеллекта. В прошлом месяце Meta✴ объявила о вложении $15 млрд в стартап Scale AI, занимающийся маркировкой данных. По данным источника, созданный в OpenAI сервис ChatGPT ежемесячно используют 600 млн человек, тогда как у аналога Google Gemini этот показатель составляет 400 млн пользователей. Отмечается, что показатель выбытия сотрудников DeepMind находится ниже среднеотраслевых значений. Компания сумела заместить ушедших специалистов, переманивая сотрудников из Microsoft. «Мы рады, что нам удалось привлечь ведущих мировых исследователей в области искусственного интеллекта, включая исследователей и инженеров из конкурирующих компаний», — прокомментировал данный вопрос представитель Google. Поглощение ИИ-стартапа Windsurf компанией OpenAI сорвалось и специалистов тут же переманила Google
12.07.2025 [11:52],
Владимир Мироненко
Сделка по покупке OpenAI ИИ-стартапа Windsurf за $3 млрд, о которой сообщалось ранее, в итоге не состоялась, сообщил в пятницу ресурс The Verge. Представитель OpenAI подтвердил, что срок предложения истёк, и Windsurf вправе рассматривать другие варианты. В тот же день Google и Windsurf объявили, что генеральный директор Windsurf и ещё ряд сотрудников переходят в подразделение Google DeepMind. 
Источник изображения: Growtika/unsplash.com Сообщается, что бывший генеральный директор Windsurf Варун Мохан (Varun Mohan), соучредитель стартапа Дуглас Чен (Douglas Chen) и ещё несколько сотрудников отдела исследований и разработок продолжат работу в Google DeepMind над проектами в области агентного кодирования, преимущественно сосредоточившись на развитии нейросети Gemini. Google не будет контролировать Windsurf и не получит долю в его капитале, но получит неисключительную лицензию на использование некоторых технологий стартапа. Компании не раскрывают финансовые подробности сделки. По данным Bloomberg, она обошлась Google в $2,4 млрд.Временно исполняющим обязанности генерального директора Windsurf назначен Джефф Ван (Jeff Wang), ранее руководивший бизнес-операциями стартапа. Новым президентом Windsurf станет Грэм Морено (Graham Moreno), вице-президент по глобальным продажам. Как утверждают источники Bloomberg, сделка по поглощению OpenAI ИИ-стартапа Windsurf сорвалась из-за позиции Microsoft — крупнейшего инвестора OpenAI. В Windsurf не хотели, чтобы Microsoft получила доступ к их интеллектуальной собственности, но OpenAI не удалось добиться согласия Microsoft по этому вопросу. Согласно действующему соглашению между Microsoft и OpenAI, софтверный гигант имеет право на доступ к технологиям, разрабатываемым стартапом. Google представила ИИ для роботов, который сможет работать без интернета и завязывать шнурки
24.06.2025 [20:57],
Владимир Мироненко
Google DeepMind выпустила новую версию ИИ-модели Gemini Robotics для роботов без подключения к интернету — Gemini Robotics On-Device. Это модель типа «зрение — язык — действие» (VLA), обладающая такими же возможностями, как и представленная в марте, но, как заявляет Google, «достаточно компактная и эффективная, чтобы работать непосредственно на роботе». 
Источник изображения: Google DeepMind Робототехника представляет собой уникальную проблему для ИИ, поскольку робот не только существует в физическом мире, но и изменяет свое окружение. Независимо от того, перемещает ли он блоки или завязывает вам шнурки, трудно предсказать все возможные ситуации, с которыми может столкнуться робот. Традиционный подход к обучению робота действиям с помощью подкрепления был очень медленным, но генеративный ИИ позволяет добиться гораздо большей обобщенности. Флагманская ИИ-модель Gemini Robotics On-Device помогает роботам выполнять широкий спектр физических задач даже без предварительного специального обучения. В частности, она позволяет обобщать новые сценарии, понимать и выполнять голосовые команды, а также справляться с задачами, требующими мелкой моторики. Руководитель отдела робототехники Google DeepMind Каролина Парада (Carolina Parada) сообщила изданию The Verge, что оригинальная модель Gemini Robotics использует гибридный подход, позволяющий ей работать как на устройстве, так и в облаке. Новая модель, доступная исключительно для работы на устройстве, обеспечивает почти тот же спектр функций без подключения к интернету. Парада утверждает, что Gemini Robotics On-Device способна выполнять множество задач «из коробки», а также адаптироваться к новым сценариям всего за 50–100 демонстраций в физическом симуляторе MuJoCo. Изначально модель обучалась только для роботов Google ALOHA, однако позже её адаптировали для других типов, включая гуманоидного робота Apollo от Apptronik и двурукого Franka FR3. По данным Google, Franka FR3 успешно справился с новыми задачами и объектами, с которыми ранее не сталкивался — например, при сборке на промышленном конвейере. «Гибридная модель Gemini Robotics всё ещё мощнее, но мы были приятно удивлены тем, насколько сильна модель On-Device, — говорит Парада. — Я бы рассматривала её как базовую модель или решение для приложений, в которых отсутствует стабильное подключение к интернету». Также она может быть полезна компаниям с жёсткими требованиями к безопасности. Google выпустила первый комплект средств разработки Gemini Robotics SDK для модели On-Device. Этот SDK позволяет разработчикам тестировать модель и производить её тонкую настройку. Это первый подобный инструмент, выпущенный для VLA-моделей Google DeepMind. Конец немого ИИ-видео: Google представила Veo 3 — первый генератор видео со звуком
21.05.2025 [02:47],
Анжелла Марина
Google представила на конференции I/O 2025 новейшую ИИ-модель для генерации видео по текстовым описаниям Veo 3, которая создаёт не только картинку, но и звуковое сопровождение. В отличие от аналогов, алгоритм понимает содержание кадров и создаёт аудио без дополнительных подсказок. А для защиты от дипфейков все ролики будут помечаться невидимым водяным знаком. 
Источник изображения: Google Алгоритм умеет создавать звуковые эффекты, фоновые шумы и даже диалоги, синхронизируя их с изображением. По словам главы подразделения Google DeepMind Демиса Хассабиса (Demis Hassabis), пользователи могут задать описание персонажей, окружения и даже указать, как должны звучать реплики. Компания не раскрывает, на каких данных обучали Veo 3, но, скорее всего, как пишет TechCrunch, использовались материалы YouTube, так как Google, владеющая этой платформой, ранее подтверждала, что её контент «может» применяться для тренировки моделей. Рынок генеративного видео уже перенасыщен: Runway, OpenAI, Alibaba и десятки стартапов выпускают похожие модели. Однако Google пошла дальше, внедрив полноценное звуковое сопровождение. Ранее DeepMind разрабатывала технологию «видео-в-аудио» (video-to-audio), что, вероятно, и стало основой для новой системы, которая анализирует пиксели видео и автоматически подбирает соответствующее аудио. Чтобы противостоять распространению дезинформации и дипфейков, все ролики Veo 3 помечаются невидимым встроенным водяным знаком SynthID. Одновременно с этим многие художники и мультипликаторы выражают обеспокоенность происходящим. По данным исследования, заказанного Гильдией аниматоров Голливуда (Animation Guild), к 2026 году около 100 тысяч рабочих мест в киноиндустрии, на телевидении и в анимации в США могут быть потеряны из-за ИИ. Эксперты отмечают, что Veo 3 может стать серьёзным конкурентом на перегруженном рынке генеративного видео — при условии, что Google сдержит обещания по качеству звука. Модель уже доступна в приложении Gemini для подписчиков тарифа AI Ultra стоимостью $249 в месяц. Google представила ИИ-систему AlphaEvolve, которая отлично создаёт и оптимизирует алгоритмы — она ускорит обучение других ИИ
14.05.2025 [23:50],
Владимир Фетисов
Подразделение Google DeepMind, занимающееся разработками в сфере искусственного интеллекта, заявило о создании новой ИИ-системы под названием AlphaEvolve, ориентированной на разбор задач с поддающимися машинной обработке решениями. Разработчики уверены, что этот алгоритм поможет оптимизировать инфраструктуру, которую Google использует для обучения больших языковых моделей (LLM). 
Источник изображений: DeepMind В сообщении говорится, что в настоящее время DeepMind работает над созданием пользовательского интерфейса для AlphaEvolve. После завершения этого процесса доступ к ИИ-алгоритму получит ограниченное число исследователей, а позже — более широкая аудитория. Большинство ИИ-моделей периодически галлюцинируют, что обусловлено их вероятностной архитектурой: они иногда выдумывают факты. Любопытно, что новые ИИ-алгоритмы, такие как o3 от OpenAI, галлюцинируют чаще, чем их предшественники. Это свидетельствует о сложности самой проблемы. Для борьбы с галлюцинациями в AlphaEvolve реализован специальный механизм — автоматическая система оценок. Она задействует ИИ-модели для генерации, критики и формирования пула возможных ответов на поставленный вопрос, а также автоматически оценивает точность этих ответов. AlphaEvolve — не первая система, использующая подобный подход. Разные исследователи, включая команду DeepMind, уже несколько лет применяют схожие методы в различных математических областях. Однако сейчас DeepMind утверждает, что использование в AlphaEvolve «самых современных» моделей, таких как Gemini, делает систему значительно более мощной по сравнению с предыдущими аналогами. 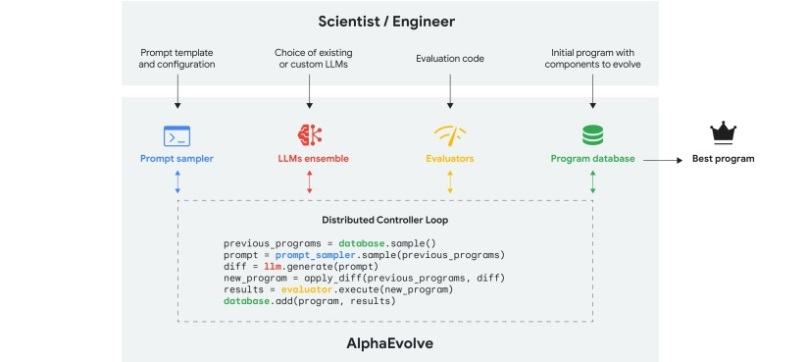 Процесс взаимодействия пользователя с AlphaEvolve начинается с постановки задачи. При желании пользователь может добавить больше деталей, включая инструкции, уравнения, фрагменты кода и соответствующую литературу. Также необходимо предоставить механизм для автоматической оценки ответов в виде формулы. Поскольку AlphaEvolve может решать только те задачи, точность решений которых она способна самостоятельно оценить, система работает лишь с определёнными типами задач — в частности, в областях информатики и оптимизации систем. Ещё одно существенное ограничение заключается в том, что ИИ-система способна описывать решения только в виде алгоритмов, что делает её малопригодной для решения нечисловых задач. В ходе тестирования AlphaEvolve решала около 50 математических задач, охватывающих различные области — от геометрии до комбинаторики. В итоге ИИ-система смогла «воспроизвести» уже известные решения в 75 % случаев и найти улучшенные варианты решений в 20 % случаев. DeepMind также протестировала систему на практических задачах, таких как повышение эффективности работы центров обработки данных Google и ускорение обучения ИИ-моделей. По данным разработчиков, AlphaEvolve создала алгоритм, который позволил вернуть в оборот 0,7 % вычислительных ресурсов Google по всему миру. Система также предложила вариант оптимизации, позволивший сократить общее время обучения моделей семейства Gemini на 1 %. Следует отметить, что пока AlphaEvolve не совершила прорывных открытий. В одном из экспериментов система предложила вариант улучшения дизайна ИИ-ускорителя Google TPU, который ранее уже был найден с помощью других алгоритмов. Однако DeepMind приводит те же аргументы, что и многие другие разработчики в сфере ИИ: AlphaEvolve способна экономить время, позволяя специалистам сосредоточиться на решении других задач. Исследовательскую лабораторию ИИ в Meta✴ возглавил выходец из Google DeepMind
09.05.2025 [10:55],
Павел Котов
На должность руководителя лаборатории фундаментальных исследований в области искусственного интеллекта (Fundamental AI Research — FAIR) в компании Meta✴ назначен Роберт Фергюс (Robert Fergus), выходец из Google DeepMind, узнал Bloomberg. 
Источник изображения: Israel Andrade / unsplash.com Около пяти лет Роберт Фергюс проработал директором по исследованиям в подразделении Google DeepMind, а до Google числился научным сотрудником в самой Meta✴ (тогда Facebook✴). Лаборатория Meta✴ FAIR была основана в 2013 году, в последние годы она столкнулось с некоторыми трудностями, стало известно ранее. Это подразделение руководило исследованиями ранних моделей ИИ, выпущенных компанией, в том числе Llama 1 и Llama 2. Но впоследствии научные сотрудники стали массово его покидать: одни перешли в стартапы, другие перевелись в новое подразделение Meta✴, специализирующееся на генеративном искусственном интеллекте — разработкой Llama 4 руководило уже оно. Предшественницей Фергюса значилась бывший вице-президент Meta✴ по исследованиями в области ИИ Джоэль Пино (Joelle Pineau) — чуть более месяца назад она объявила об отставке и уходе из компании в связи с появлением некой новой возможности. Гендир Google DeepMind рассказал о будущем ИИ и появлении у него самосознания
21.04.2025 [19:27],
Сергей Сурабекянц
Генеральный директор Google DeepMind Демис Хассабис (Demis Hassabis) в течение часа рассказывал журналистам о перспективах Gemini, темпах разработки сильного ИИ (Artificial General Intelligence, AGI) и общем росте самосознания нейросетей. Он уделил много внимания модели Project Astra, которая сейчас находится в стадии предварительного тестирования. Astra узнаёт пользователей и помнит историю общения с ними, — скоро эти возможности появятся в Gemini Live. 
Источник изображения: 9to5Google Хассабис отметил, что перспективная модель Project Astra отличается, прежде всего, увеличенным количеством памяти. В частности, она запоминает ключевые детали из предыдущих разговоров для лучшего контекста и персонализации. Также имеется отдельная «10-минутная память» текущего диалога. Эти возможности, предположительно, скоро появятся в Gemini Live. Хассабис подчеркнул, что Google DeepMind «обучает свою модель ИИ под названием Gemini не просто показывать мир, но и совершать действия в нём, такие как бронирование билетов и покупки онлайн». По мнению Хассабиса, реальный срок появления AGI — 5-10 лет, причём это будет «система, которая действительно понимает все вокруг вас очень тонким и глубоким образом и как бы встроена в вашу повседневную жизнь». На вопрос, «работает ли Google DeepMind сегодня над системой, которая будет осознавать себя», Хассабис заявил, что теоретически это возможно, но он не воспринимает какую-либо из сегодняшних систем как осознающую себя. Он полагает, что «каждый должен принимать собственные решения, взаимодействуя с этими чат-ботами». На вопрос, «является ли самосознание вашей целью» (при разработке ИИ), он ответил, что это может произойти неявно: «Эти системы могут обрести некоторое чувство самосознания. Это возможно. Я думаю, что для этих систем важно понимать вас, себя и других. И это, вероятно, начало чего-то вроде самосознания». «Я думаю, есть две причины, по которым мы считаем друг друга сознательными. Одна из них заключается в том, что вы демонстрируете поведение сознательного существа, очень похожее на моё поведение. Но вторая причина в том, что вы работаете на одном и том же субстрате. Мы сделаны из одного и того же углеродного вещества с нашими мягкими мозгами. Очевидно, что машины работают на кремнии. Так что даже если они демонстрируют одинаковое поведение, и даже если они говорят одно и то же, это не обязательно означает, что это ощущение сознания, которое есть у нас, будет тем же самым, что будет у них», — пояснил Хассабис в заключение. Google платит сотрудникам отделов ИИ за ничегонеделание — лишь бы они не ушли к конкурентам
08.04.2025 [11:10],
Павел Котов
В условиях жёсткой конкуренции Google вынуждена целый год выплачивать некоторым специалистам по искусственному интеллекту средства за то, чтобы они ничего не делали — лишь бы удержать их от перехода в другие компании, сообщил Business Insider. 
Источник изображения: Silicon Valley, HBO Специализирующееся на ИИ подразделение Google DeepMind заключает с некоторыми своими сотрудниками в Великобритании «жёсткие» соглашения о неконкуренции, которые не позволяют им в течение года переходить на работу в компании того же профиля. Некоторым из них в течение указанного времени производят выплаты, что равнозначно длительному неоплачиваемому отпуску. Но в результате этих действий исследователи рискуют утратить актуальные знания, умения и навыки, поскольку прогресс в отрасли ИИ отличается быстрыми темпами. В прошлом году Федеральная торговая комиссия (FTC) США запретила заключать большинство соглашений о неконкуренции, но к лондонской штаб-квартире DeepMind это не относится. В марте вице-президент Microsoft по ИИ Нандо де Фрейтас (Nando de Freitas) рассказал, что некоторые сотрудники DeepMind «в отчаянии» обращаются к нему, потому что не могут преодолеть силу соглашений о неконкуренции, и призвал не заключать их. Такая практика применяется «избирательно», уточнили в Google. Nvidia показала настоящего робота из «Звёздных войн»
19.03.2025 [15:08],
Павел Котов
Nvidia при поддержке Google DeepMind и Disney Research ведёт разработку Newton — движка, просчитывающего физику для моделирования движений роботов в реальных условиях. Об этом на мероприятии GTC 2025 рассказал глава Nvidia Дженсен Хуанг (Jensen Huang). 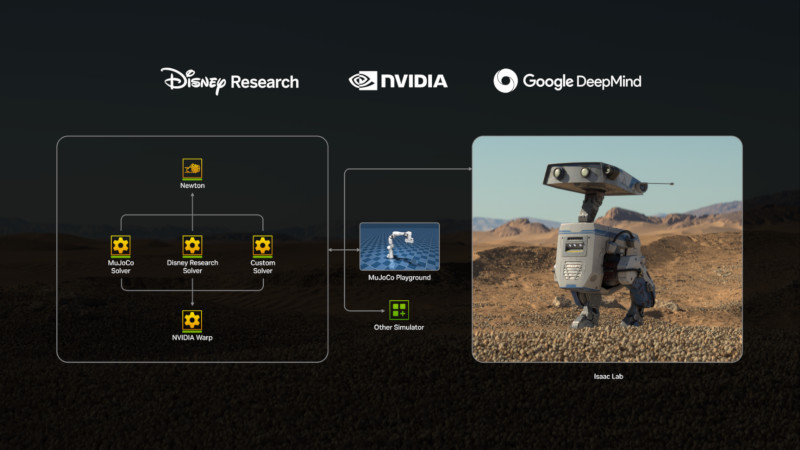
Источник изображения: nvidia.com Одной из первых Newton развернёт компания Disney — платформа будет использоваться в создании, например, роботов BDX по мотивам «Звёздных войн», один из которых появился на сцене вместе с господином Хуангом во время его выступления. Предварительная версия Newton с открытым исходным кодом выйдет уже в этом году. Disney уже не первый год занимается проектом, посвящённым появлению роботов из киновселенной «Звёздных войн» в развлекательных парках компании. Newton станет одной из технологий, которые помогут таким машинам появиться в тематических парках Disney уже в следующем году — старший вице-президент Disney Imagineering Кайл Лафлин (Kyle Laughlin) отметил заслуги Nvidia и Google DeepMind в реализации проекта. Newton поможет роботам стать более «выразительными» и «научиться справляться со сложными задачами с большей точностью», рассказали в Nvidia. Физический движок станет для разработчиков подспорьем в моделировании взаимодействия роботов с объектами внешнего мира — это одна из наиболее сложных задач в робототехнике. Newton легко настраивается, заверили в Nvidia. С его помощью можно запрограммировать сценарии взаимодействия машин с продуктами питания, тканью, песком и другими деформируемыми объектами. Newton также получит совместимость с экосистемой проектирования роботов Google DeepMind, в том числе с физическим движком MuJoCo, имитирующим многосуставные движения механизмов. На GTC 2025 компания Nvidia также представила GR00T N1 — базовую модель искусственного интеллекта, которая поможет роботам эффективнее воспринимать среду и рассуждать о ней. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2025 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews. kz
![]()
![]()








 MWC 2018
MWC 2018 2018
2018 Computex
Computex






