|
Опрос
|
реклама
Быстрый переход
ИИ сравняется с людьми в любой задаче через десять лет, уверен глава Google DeepMind
18.03.2025 [18:50],
Сергей Сурабекянц
Генеральный директор Google DeepMind Демис Хассабис (Demis Hassabis) заявил, что сильный ИИ (Artificial General Intelligence, AGI), который ни в чём не уступает человеку или даже превосходит его, будет разработан в ближайшие пять–десять лет. Он абсолютно уверен в реалистичности создания AGI и полагает, что решение этой задачи — всего лишь вопрос времени. Хассабис определяет AGI как «систему, которая способна демонстрировать все сложные возможности, присущие человеку». 
Источник изображения: Pixabay «Я думаю, что сегодняшние системы очень пассивны, есть ещё много вещей, которые они не могут делать. Но я думаю, что в течение следующих пяти–десяти лет многие из этих возможностей начнут выходить на первый план, и мы начнём двигаться к тому, что мы называем искусственным интеллектом общего назначения», — считает Хассабис. Он не одинок в своём мнении — в прошлом году генеральный директор китайского технологического гиганта Baidu Робин Ли (Robin Li) заявил, что AGI появится «более чем через 10 лет». Другие коллеги Хассабиса более оптимистичны. Генеральный директор Anthropic Дарио Амодеи (Dario Amodei) уверен, что модель ИИ, которая «лучше, чем почти все люди, почти во всех задачах», появится в «ближайшие два–три года». Директор по продуктам Cisco Джиту Патель (Jeetu Patel) полагает, что AGI может быть создан уже в этом году. Генеральный директор Tesla Илон Маск (Elon Musk) предсказал, что AGI, скорее всего, станет реальностью к 2026 году, генеральный директор OpenAI Сэм Альтман (Sam Altman) считает, что такая система может быть разработана в «достаточно близком будущем». Хассабис в своих прогнозах пошёл дальше и предположил, что вслед за появлением AGI на сцену выйдет искусственный суперинтеллект (Artificial Super Intelligence, ASI), который превзойдёт человека во всех сферах деятельности. Однако «никто на самом деле не знает», когда произойдёт такой прорыв, признался он. По мнению Хассабиса, главная проблема в создании AGI — это доведение современных систем ИИ до уровня понимания контекста реального мира. «Вопрос в том, как быстро мы сможем обобщить идеи планирования и агентного поведения, планирования и рассуждений, а затем применить их к реальному миру, дополнив такими вещами, как модели мира, которые способны понимать окружающую нас реальность», — пояснил он. По словам Хассабиса, в последнее время внимание разработчиков всё больше привлекают так называемые мультиагентные системы искусственного интеллекта. В качестве примера он привёл исследования DeepMind по обучению агентов ИИ игре в Starcraft: «Мы проделали большую работу над этим, например, в проекте Starcraft, где у нас было сообщество агентов или лига агентов, способных как конкурировать, так и сотрудничать». Высокопоставленные менеджеры и ведущие разработчики ИИ сходятся в одном — они не видят ближайшее будущее человечества без всеведущих, всемогущих и всезнающих систем ИИ, которые, как они уверены, превзойдут человека в любой сфере деятельности. По всей видимости, они думают, что их самих и их близких такое нашествие ИИ-саранчи, «затмившей небо», не коснётся. Google DeepMind дала роботам ИИ, с которым они могут выполнять сложные задания без предварительного обучения
12.03.2025 [20:41],
Сергей Сурабекянц
Лаборатория Google DeepMind представила две новые модели ИИ, которые помогут роботам «выполнять более широкий спектр реальных задач, чем когда-либо прежде». Gemini Robotics — это модель «зрение-язык-действие», способная понимать новые ситуации без предварительного обучения. А Gemini Robotics-ER компания описывает как передовую модель, которая может «понимать наш сложный и динамичный мир» и управлять движениями робота. 
Источник изображений: Google DeepMind Модель Gemini Robotics построена на основе Gemini 2.0, последней версии флагманской модели ИИ от Google. ПО словам руководителя отдела робототехники Google DeepMind Каролины Парада (Carolina Parada), Gemini Robotics «использует мультимодальное понимание мира Gemini и переносит его в реальный мир, добавляя физические действия в качестве новой модальности». Новая модель особенно сильна в трёх ключевых областях, которые, по словам Google DeepMind, необходимы для создания по-настоящему полезных роботов: универсальность, интерактивность и ловкость. Помимо способности обобщать новые сценарии, Gemini Robotics лучше взаимодействует с людьми и их окружением. Модель способна выполнять очень точные физические задачи, такие как складывание листа бумаги или открывание бутылки.  «Хотя в прошлом мы уже достигли прогресса в каждой из этих областей по отдельности, теперь мы приносим [резко] увеличивающуюся производительность во всех трёх областях с помощью одной модели, — заявила Парада. — Это позволяет нам создавать роботов, которые более способны, более отзывчивы и более устойчивы к изменениям в окружающей обстановке». Модель Gemini Robotics-ER разработана специально для робототехников. С её помощью специалисты могут подключаться к существующим контроллерам низкого уровня, управляющим движениями робота. Как объяснила Парада на примере упаковки ланч-бокса — на столе лежат предметы, нужно определить, где что находится, как открыть ланч-бокс, как брать предметы и куда их класть. Именно такой цепочки рассуждений придерживается Gemini Robotics-ER.  Разработчики уделили серьёзное внимание безопасности. Исследователь Google DeepMind Викас Синдхвани (Vikas Sindhwani) рассказал, как лаборатория использует «многоуровневый подход», при котором модели Gemini Robotics-ER «обучаются оценивать, безопасно ли выполнять потенциальное действие в заданном сценарии». Кроме того, Google DeepMind разработала ряд эталонных тестов и фреймворков, чтобы помочь дальнейшим исследованиям безопасности в отрасли ИИ. В частности, в прошлом году лаборатория представила «Конституцию робота» — набор правил, вдохновлённых «Тремя законами робототехники», сформулированными Айзеком Азимовым в рассказе «Хоровод» в 1942 году. В настоящее время Google DeepMind совместно с компанией Apptronik разрабатывает «следующее поколение человекоподобных роботов». Также лаборатория предоставила доступ к своей модели Gemini Robotics-ER «доверенным тестировщикам», среди которых Agile Robots, Agility Robotics, Boston Dynamics и Enchanted Tools. «Мы полностью сосредоточены на создании интеллекта, который сможет понимать физический мир и действовать в этом физическом мире, — сказала Парада. — Мы очень рады использовать это в нескольких воплощениях и во многих приложениях для нас».  Напомним, что в сентябре 2024 года исследователи из Google DeepMind продемонстрировали метод обучения, позволяющий научить робота выполнять некоторые требующие определённой ловкости действия, такие как завязывание шнурков, подвешивание рубашек и даже починка других роботов. Google создала ИИ-лаборанта, который умеет выдвигать гипотезы и ускорять исследования
19.02.2025 [20:56],
Сергей Сурабекянц
Google создала лаборанта на основе искусственного интеллекта, который поможет учёным ускорить биомедицинские исследования и разработать специализированные приложения на основе передовых технологий. Новый ИИ-ассистент (AI Coscientist — «ИИ-соучёный») умеет выявлять пробелы в знаниях исследователей и предлагать новые идеи, способные ускорить процесс научного познания. 
Источник изображения: Pixabay В настоящее время технологические компании тратят миллиарды долларов на модели и продукты ИИ, рассчитывая, что эти технологии смогут изменить различные отрасли — от здравоохранения до энергетики и образования. «С помощью нашего проекта мы пытаемся выяснить, могут ли технологии, подобные нашему ИИ-ассистенту, наделить исследователей сверхспособностями», — заявил старший клинический учёный Google Алан Картикесалингам (Alan Karthikesalingam). AI Coscientist работает с использованием нескольких агентов ИИ, которые имитируют научный процесс: один специализируется на генерации идей, другие — на их рассмотрении, критическом анализе и рецензировании. ИИ-модель способна извлекать информацию из научных статей и специализированных баз данных, находящихся в свободном доступе. Затем она анализирует полученные данные и генерирует ранжированный список предложений с пояснениями и ссылками на источники. Ранние испытания нового инструмента Google с экспертами из Стэнфордского университета, Имперского колледжа Лондона и Хьюстонской методистской больницы показали, что он способен генерировать многообещающие научные гипотезы. AI Coscientist смог подобрать препараты, которые можно повторно использовать для лечения фиброза печени — серьёзного заболевания, ведущего к образованию рубцовой ткани. ИИ-ассистент предложил два типа препаратов, которые, как подтвердили учёные, помогли в лечении этой болезни. AI Coscientist также сумел прийти к тем же выводам о новом механизме переноса генов, что и исследователи из лаборатории Imperial в своих закрытых научных работах. Результаты, полученные учёными, не были общедоступными, так как находились на стадии рецензирования в ведущем научном журнале. Инструмент Google затратил на исследование всего несколько дней, в то время как университетская команда учёных работала над ним несколько лет. «Мы думаем, что это инструмент, который может изменить наш подход к науке», — считает профессор кафедры инфекционных заболеваний Хосе Пенадес (José Penadés), один из исследователей механизма переноса генов. Такие инструменты, как новый Google AI Coscientist, могут помочь исследователям оставаться в курсе последних открытий в своих предметных областях, полагает доцент Оксфордского университета Якоб Ферстер (Jakob Foerster). Ранее лаборатория Google DeepMind представила новую версию модели искусственного интеллекта AlphaFold, которая предсказывает форму и поведение белков. OpenAI, Perplexity, немецкий производитель лекарств BioNTech и его лондонское дочернее предприятие InstaDeep также недавно запустили собственные инструменты для ИИ-исследований. Новая ИИ-модель от DeepMind смогла бы получить «золото» на Международной математической олимпиаде
08.02.2025 [19:23],
Владимир Мироненко
DeepMind, дочернее предприятие Google, специализирующееся на исследованиях в сфере искусственного интеллекта (ИИ), сообщило о новых достижениях ИИ-модели AlphaGeometry2 в решении геометрических задач. В недавно опубликованном исследовании DeepMind сообщается, что AlphaGeometry2 успешно решила 84 % задач (42 из 50) Международной математической олимпиады (IMO) с 2000 по 2024 год, набрав средний балл золотого медалиста (40,9). 
Источник изображения: Google AlphaGeometry2 является улучшенной версией ИИ-системы AlphaGeometry, вышедшей в январе прошлого года. В июле прошлого года DeepMind продемонстрировала возможности системы, объединившей ИИ-модели AlphaProof и AlphaGeometry2, которой удалось решить 4 из 6 задач IMO. AlphaGeometry2, используя лингвистическую модель на основе архитектуры Gemini и усовершенствованный механизм символической дедукции способна определять стратегии решения задач с точностью, превосходящей возможности большинства экспертов-людей. Принятый подход объединяет два основных компонента: лингвистическую модель, способную генерировать предложения на основе подробного геометрического описания, и символический механизм DDAR (Deductive Database Arithmetic Reasoning), который проверяет логическую связность предлагаемых решений, создавая дедуктивное замыкание на основе доступной информации. Проще говоря, модель Gemini AlphaGeometry2 предлагает символическому механизму шаги и конструкции на формальном математическом языке, и механизм, следуя определённым правилам, проверяет эти шаги на логическую согласованность. Ключевым элементом, который позволил AlphaGeometry2 превзойти по скорости предшественника AlphaGeometry, является алгоритм SKEST (Shared Knowledge Ensemble of Search Trees), который реализует итеративную стратегию поиска, основанную на обмене знаниями между несколькими параллельными деревьями поиска. Это позволяет одновременно исследовать несколько путей решения, увеличивая скорость обработки и улучшая качество сгенерированных доказательств. Эффективность системы удалось значительно повысить с новой реализацией DDAR на C++, что в 300 раз увеличило её скорость по сравнению с версией, написанной на Python. Вместе с тем из-за технических особенностей AlphaGeometry2 пока ограничена в возможности решать задачи с переменным числом точек, нелинейными уравнениями или неравенствами. Поэтому DeepMind изучает новые стратегии, такие как разбиение сложных задач на подзадачи и применение обучения с подкреплением для выхода ИИ на новый уровень в решении сложных математических задач. Как сообщается, AlphaGeometry2 технически не является первой ИИ-системой, достигшей уровня золотого медалиста по геометрии, но она первая, достигшая этого с набором задач такого размера. При этом AlphaGeometry2 использует гибридный подход, поскольку модель Gemini имеет архитектуру нейронной сети, в то время как её символический механизм основан на правилах. Сторонники использования нейронных сетей утверждают, что интеллектуальных действий, от распознавания речи до генерации изображений, можно добиться только благодаря использованию огромных объёмов данных и вычислений. В отличие от символических систем ИИ, которые решают задачи, определяя наборы правил манипуляции символами, предназначенных для определённых задач, нейронные сети пытаются решать задачи посредством статистической аппроксимации (замены одних результатов другими, близкими к исходным) и обучения на примерах. В свою очередь, сторонники символического ИИ считают, что он более подходит для эффективного кодирования глобальных знаний. В DeepMind считают, что поиск новых способов решения сложных геометрических задач, особенно в евклидовой геометрии, может стать ключом к расширению возможностей ИИ. Решение задач требует логического рассуждения и способности выбирать правильный шаг из нескольких возможных. По мнению DeepMind, эти способности будут иметь решающее значение для будущего универсальных моделей ИИ. Google отказалась от обещания не использовать ИИ в военных и шпионских целях
05.02.2025 [09:39],
Анжелла Марина
Компания Google пересмотрела свою позицию в области безопасности искусственного интеллекта (ИИ), убрав обещание не применять ИИ для военных и разведывательных целей. Прежние правила, введённые в 2018 году, были обновлены и опубликованы в официальном блоге компании, сообщает The Washington Post. 
Источник изображения: Copilot Ранее компания заявляла, что не будет заниматься четырьмя категориями применения ИИ: оружием, слежкой, технологиями, «способными нанести вред», и проектами, нарушающими международное право и права человека. Эти ограничения делали Google исключением среди лидеров рынка ИИ. Например, Microsoft и Amazon давно сотрудничают с Пентагоном. Их примеру последовали OpenAI и Anthropic, которые сотрудничают с оборонными подрядчиками США, такими как Anduril и Palantir. По словам экспертов, решение Google отражает растущее значение ИИ для национальной обороны США. Профессор политологии Майкл Горовиц (Michael Horowitz) из Пенсильванского университета отметил, что это логичный шаг, поскольку технологии ИИ становятся всё более важными для американской армии. «Заявление Google является ещё одним доказательством того, что отношения между технологическим сектором США и Министерством обороны продолжают становиться всё теснее, включая ведущие компании в области ИИ», — сказал Горовиц. Однако критики, такие как Лилли Ирани (Lilly Irani), бывший сотрудник Google и профессор Калифорнийского университета в Сан-Диего, считают, что «обещания компании соблюдать международные законы и права человека часто оказываются пустыми словами». Напомним, Google впервые ввела этические принципы после протестов сотрудников против контракта с Пентагоном, известного как Project Maven. Этот проект предполагал использование алгоритмов компьютерного зрения для анализа данных с дронов. Тогда тысячи работников подписали петицию, требуя прекратить участие компании в военных проектах, что Google и сделала, отказавшись не только от контракта, но и пообещав не участвовать в разработке оружия. Однако новое изменение политики свидетельствует о том, что приоритеты компании изменились. Бывший руководитель Google DeepMind переманивает таланты в Microsoft для работы над ИИ
05.02.2025 [05:17],
Анжелла Марина
Глава подразделения искусственного интеллекта в Microsoft Мустафа Сулейман (Mustafa Suleyman) в стремлении укрепить позиции компании в разработке интерактивных ИИ-агентов расширяет команду Microsoft, переманивает ключевых специалистов из Google, включая создателей технологии «Audio Overviews». Бывшие коллеги Сулеймана из DeepMind, откуда он ушёл в 2022 году, будут привлечены для работы над проектом по созданию мультимодальных моделей для обработки текста, звука и видео. 
Источник изображения: Copilot Как сообщает Financial Times, в числе новых сотрудников Microsoft оказались Марко Тальясаччи (Marco Tagliasacchi) и Залан Боршош (Zalán Borsos), создатели функции «Audio Overviews», позволяющей преобразовывать текст в аудио в стиле увлекательного подкаста. Эти исследователи также участвовали в разработке Astra — перспективного ИИ-агента DeepMind, способного отвечать на вопросы в режиме реального времени с использованием видео, аудио и текста. К команде также присоединился Маттиас Миндерер (Matthias Minderer). Он займётся развитием возможностей ИИ для анализа изображений. Все трое будут работать в новом исследовательском центре Microsoft в Цюрихе и, по словам источника, знакомого с ситуацией, сыграют ключевую роль в разработке следующего поколения Copilot, на основе которого будут создаваться интерактивные ИИ-агенты, способные к выполнению широкого спектра задач. Относительно кадровых потерь такого уровня Google DeepMind комментарии не дал. Однако отмечается, что переход этих специалистов из Google DeepMind в Microsoft является частью ожесточённой борьбы за таланты в сфере ИИ. При этом, обе компании остаются ключевыми игроками в разработке мультимодальных ИИ-моделей, которые способны анализировать и понимать контент на основе аудио, видео или изображений. На фоне этой конкурентной гонки другие компании также не отстают — OpenAI представила голосовой режим для ChatGPT, Amazon внедряет ИИ в свой голосовой помощник Alexa. Google также готовится к выпуску голосового агента Astra в 2025 году. Google формирует команду для «моделирования мира» на основе ИИ для игр и обучения роботов
08.01.2025 [06:06],
Анжелла Марина
Google DeepMind формирует новую исследовательскую группу по искусственному интеллекту (ИИ), которая займётся разработкой ИИ-моделей, способных имитировать физические среды для обучения роботов и создания реалистичных игровых вселенных. Сообщается, что возглавит инициативу Тим Брукс (Tim Brooks), бывший соруководитель проекта Sora в OpenAI, который присоединился к DeepMind ещё в октябре. 
Источник изображения: Google DeepMind / Unsplash «Моделирование мира» — это относительно новая область ИИ, которая может найти применение в различных сферах. Направление может быть использовано для создания интерактивных медиасред в реальном времени для видеоигр и кино, а также для разработки реалистичных сценариев обучения роботов и других систем ИИ. В настоящее время DeepMind активно ищет инженеров-исследователей и учёных для работы в своей лаборатории, разместив вакансии на сайте Greenhouse. Основные задачи команды будут включать обучение моделей в больших масштабах, курирование данных обучения и изучение способов интеграции моделей с мультимодальными языковыми моделями. «Мы считаем, что масштабирование предварительного обучения на видео и мультимодальных данных является критически важным шагом на пути к искусственному общему интеллекту» — говорится в описании вакансий. Несмотря на амбициозные планы, у DeepMind есть несколько конкурентов, которые уже имеют преимущество в разработке технологии по «моделированию мира». Среди них платформа Nvidia Cosmos для развития физического ИИ и стартап World Labs, созданный Фей-Фей Ли (Fei-Fei Li), которую называют «крёстной матерью ИИ». Новая команда DeepMind будет работать вместе с существующими проектами Google, включая флагманские ИИ-модели Gemini, генератор видео Veo и Genie — ранее разработанную модель мира для имитации игровых 3D-сред в реальном времени. Стоит сказать, что Google стремится достичь AGI раньше своих конкурентов и гонка за первенство в достижении использования возможностей сверхинтеллекта набирает обороты. Так, генеральный директор OpenAI Сэм Альтман (Sam Altman) недавно заявил, что компания близка к достижению AGI, и что автономные ИИ-агенты могут начать активно включаться в рабочие процессы уже в наступившем году. Google DeepMind представила ИИ-генератор видео Veo 2, который создаёт двухминутные ролики в 4K
17.12.2024 [11:42],
Павел Котов
Подразделение Google DeepMind представило Veo 2 — основанный на искусственном интеллекте генератор видео нового поколения. Он создаёт видеоролики в разрешении 4K (4096 × 2160 пикселей) продолжительностью до двух минут. Таким образом, он в 4 раза превосходит OpenAI Sora по разрешению и в 6 раз — по продолжительности видео. 
Источник изображений: Google DeepMind На данный момент это преимущество, однако, носит лишь теоретический характер: испробовать Veo 2 можно лишь на экспериментальной площадке VideoFX, где разрешение ограничено 720p, а длина видео — 8 секундами. Для сравнения, доступная для пользователей версия генератора OpenAI Sora предлагает 1080p и 20 секунд. Чтобы начать работу с VideoFX, придётся записаться в список ожидания, хотя Google пообещала на этой неделе расширить аудиторию. В перспективе Veo 2 появится на платформе для бизнес-пользователей Vertex AI, но точные сроки в Google не указали. Veo 2, как и её предшественница, генерирует видео по текстовым подсказкам, которые можно сопровождать изображениями. По сравнению с Veo первого поколения, новая модель лучше «понимает» физику, изображение отличается повышенной чёткостью, усовершенствованы механизмы движения виртуальной камеры. Veo 2 более реалистично моделирует движение (например, изображает наливаемый в кружку кофе) и свойства света (тени и отражения); правдоподобно имитируются разные линзы на виртуальной камере и кинематографические эффекты. Разработчик также уверяет, что у новой модели с меньшей вероятностью проявляются галлюцинации: дополнительные пальцы или «неожиданные объекты»; при этом, как показала практика, от эффекта «зловещей долины» избавиться не удалось. А на видео с движущимся автомобилем дорога при ближайшем рассмотрении оказывается чрезвычайно гладкой, пешеходы сливаются друг с другом, а некоторые фасады домов имеют вид, который противоречит законам физики. Новый генератор видео был обучен на большом числе роликов; в DeepMind не уточнили, какие источники для этого использовались, но одним из них, вероятно, является принадлежащая Google платформа YouTube. Чтобы снизить риск возникновения дипфейков, в Veo 2 встроили систему SynthID — невидимую маркировку генерируемых моделью видео.  В DeepMind также сообщили, что улучшили работу генератора статических изображений Imagen 3 — созданные с его помощью картинки стали более яркими, детализированными, а сама модель теперь более точно следует запросам пользователя. В пользовательском интерфейсе ImageFX, где доступен генератор изображений, появились выпадающие списки, которые появляются прямо в поле запроса и помогают добиться более точного результата. Google представила Mariner — прототип ИИ-агента для Chrome, которому можно давать сложные поручения
12.12.2024 [00:19],
Николай Хижняк
Google представила исследовательский прототип ИИ-агента под названием Project Mariner, который способен выполнять действия в интернете за человека. За разработку отвечает подразделение Google — DeepMind. ИИ-агент на базе Gemini берет под контроль браузер Chrome, перемещает курсор на экране, нажимает кнопки и заполняет формы, что позволяет ему использовать веб-сайты и перемещаться по ним так же, как это делает человек. 
Источник изображений: Google Компания сообщила, что в настоящий момент Project Mariner проходит стадию тестирования группой предварительно отобранных пользователей. В разговоре с порталом TechCrunch директор Google Labs Жаклин Конзельманн (Jaclyn Konzelmann) заявила, что Project Mariner представляет собой принципиально новый подход в пользовательском интерфейсе. Проект предлагает отказаться от прямого взаимодействия пользователей с веб-сайтами, возложив эти задачи на генеративную систему ИИ. По её словам, такие изменения могут затронуть миллионы предприятий — от веб-изданий до ритейла — которые традиционно полагались на Google как отправную точку для привлечения пользователей на свои веб-сайты. После установки и настройки Project Mariner в качестве расширения для браузера Chrome у последнего появится специальное окно чата. В нём можно поручить ИИ-агенту выполнение различных задач. Например, его можно попросить создать корзину покупок в продуктовом магазине на основе заданного списка. После этого ИИ-агент самостоятельно перейдёт на страницу указанного магазина (в демонстрации использовался магазин Safeway), выполнит поиск нужных товаров и добавит их в корзину. Журналисты отмечают, что система работает не так быстро, как хотелось бы: между каждым движением курсора проходит примерно 5 секунд. Иногда ИИ-агент прерывает выполнение задачи и возвращается к окну чата, запрашивая уточнения, например, о весе или количестве товаров. 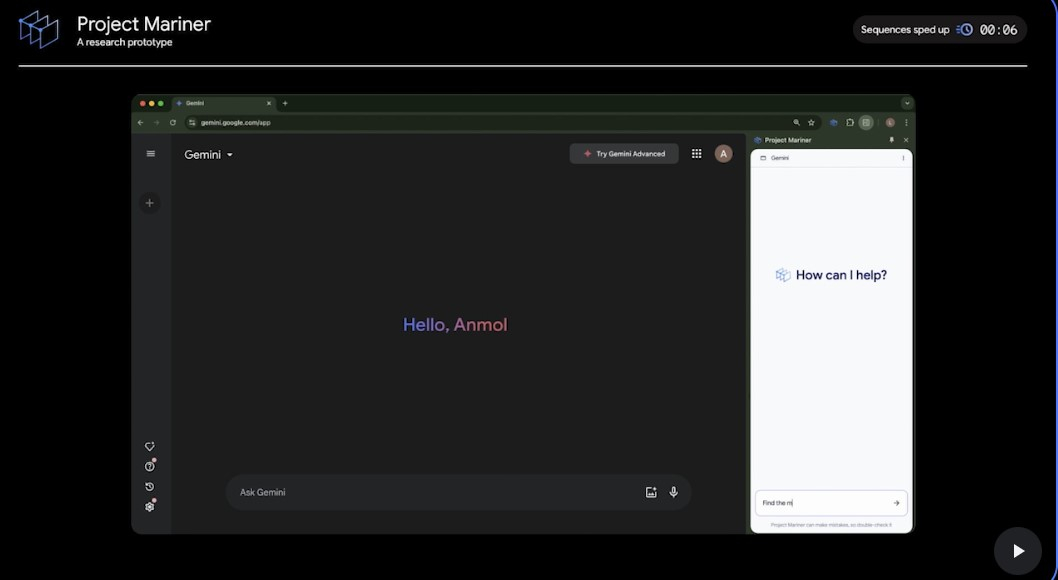 ИИ-агент от Google не может оформить заказ, так как в его алгоритм не включены функции заполнения номеров кредитных карт и другой платёжной информации. Project Mariner также не принимает файлы cookie и не подписывает соглашения об условиях использования от имени пользователей. Google подчёркивает, что это сделано намеренно, чтобы предоставить пользователям больше контроля. Кроме того, ИИ-агент делает снимки экрана окна браузера, с чем пользователи должны согласиться перед его использованием. Эти изображения отправляются для обработки в облачный сервис Gemini, который затем передаёт инструкции обратно на устройство пользователя для навигации по веб-странице. Project Mariner можно использовать для поиска рейсов и отелей, покупок товаров для дома, поиска рецептов и других задач, которые сейчас требуют самостоятельной навигации по сайтам. Одно из основных ограничений Project Mariner заключается в том, что он работает только на активной вкладке браузера Chrome. Иными словами, веб-страница, на которой действует ИИ-агент, должна быть постоянно открыта на экране монитора. Пользователям придётся наблюдать за каждым шагом бота. По словам главного технического директора Google DeepMind Корая Кавукчуоглу (Koray Kavukcuoglu), это сделано специально, чтобы пользователи знали, что именно делает ИИ-агент. 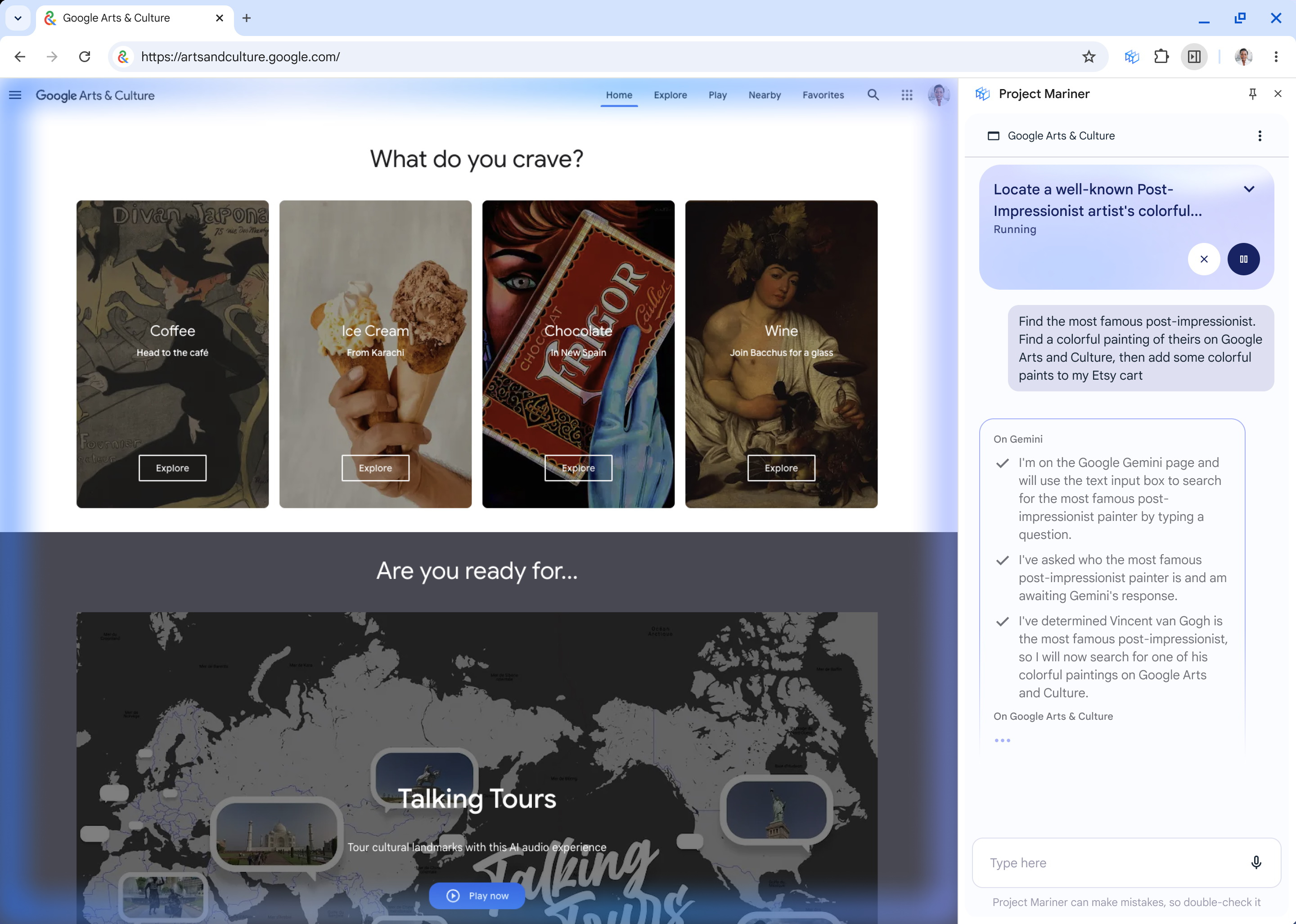 «Поскольку [Gemini] теперь выполняет действия от имени пользователя, важно делать это шаг за шагом. Это дополнительная функция. Вы, как человек, можете использовать веб-сайты, и теперь ваш агент может делать всё, что вы делаете на веб-сайте», — отметил Кавукчуоглу в интервью TechCrunch. С одной стороны, пользователям всё равно придётся видеть страницу сайта, что выгодно для владельцев ресурсов. Однако использование Project Mariner снижает уровень непосредственного взаимодействия пользователей с функциями сайта и в перспективе может вообще исключить необходимость самостоятельного посещения веб-сайтов. «Project Mariner — это принципиально новый сдвиг в парадигме UX, который мы наблюдаем прямо сейчас. Нам нужно понять, как правильно всё это настроить, чтобы изменить принципы взаимодействия пользователей с интернетом, а также найти способы, которыми издатели смогут создавать собственные решения для пользователей на базе ИИ-агентов в будущем», — добавила Конзельманн. Помимо Project Mariner, Google представила несколько других ИИ-агентов для специализированных задач. Например, инструмент Deep Research для глубокого поиска и исследования в интернете. Также был представлен ИИ-агент Jules, предназначенный для помощи разработчикам в написании кода. Он интегрируется в рабочие процессы GitHub, анализирует текущий уровень разработки и может вносить изменения прямо в репозитории. Jules проходит тестирование и станет доступен в 2025 году. Google DeepMind также разрабатывает ИИ-агента для помощи пользователям в видеоиграх. Для этого компания сотрудничает с разработчиком игр, студией Supercell, чтобы проверить способности Gemini интерпретировать игровые миры на примере Clash of Clans. Сроки запуска прототипа этого ИИ-агента пока неизвестны, но Google подчёркивает, что эта разработка помогает в создании ИИ-агентов для навигации как в реальном, так и в виртуальных мирах. Google запустила «всеобъемлющую» ИИ-модель Gemini 2.0, которая может заменить человека
11.12.2024 [20:03],
Сергей Сурабекянц
Представлена новая модель ИИ Gemini 2.0 от Google, которая стала предельно универсальной — она генерирует текст, звук и изображения, а также предлагает новые мультимодальные возможности, которые закладывают основу для следующего большого этапа в развитии ИИ: агентов, которые в буквальном смысле могут заменить пользователя в рутинных операциях. Новая модель также стала заметно производительнее и энергоэффективнее. 
Источник изображения: techspot.com Как и любая другая компания, участвующая в гонке ИИ, Google лихорадочно встраивает ИИ во всё, до чего может дотянуться, пытаясь создать коммерчески успешные продукты. Одновременно требуется так настроить всю инфраструктуру, чтобы дорогостоящие ИИ-решения не разорили компанию. Тем временем Amazon, Microsoft, Anthropic и OpenAI вливают свои собственные миллиарды в практически тот же самый набор проблем. Gemini 2.0 представлена примерно через 10 месяцев после выпуска версии 1.5. Генеральный директор Google DeepMind Демис Хассабис (Demis Hassabis) очень высоко оценивает новую модель, называя её «всеобъемлющей», хотя Gemini 2.0 все ещё находится в стадии «экспериментального предварительного просмотра», по терминологии Google. Тем не менее Хассабис уверен, что новая модель предоставит совершенно другой уровень возможностей, в первую очередь в области агентского ИИ. Агентским ИИ называют ИИ-ботов, которые могут полноценно выполнять действия от имени пользователя. Например, Project Astra от Google — это визуальная система, которая может распознавать объекты, помогает ориентироваться в мире и находить утерянные предметы. По словам Хассабиса, возможности Astra в версии Gemini 2.0 многократно возросли. Другой пример — Google Project Mariner — экспериментальное расширение для браузера Chrome, которое может буквально подменять пользователя при веб-серфинге. Агент Jules, в свою очередь, помогает разработчикам в поиске и исправлении плохого программного кода. Выпущен даже агент, который помогает лучше играть в видеоигры. Хассабис приводит его в пример в качестве по-настоящему мультимодальной модели ИИ. «Мы действительно считаем 2025 год настоящим началом эры на основе агентов, — заявил Хассабис, — Gemini 2.0 является её основой». Он также отметил возросшую производительность и энергоэффективность новой модели, особенно на фоне общего замедления прогресса в отрасли ИИ. План Google относительно Gemini 2.0 заключается в том, чтобы использовать её абсолютно везде. Google ставила своей целью внедрить как можно больше функций в единую модель, а не запускать множество отдельных разрозненных продуктов. «Мультимодальность, различные виды выходных данных, функции — цель состоит в том, чтобы включить все это в основополагающую модель Gemini. Мы пытаемся построить максимально общую модель», — говорит Хассабис. По словам Хассабиса, с началом агентской эры ИИ потребуется решать как новые, так и старые проблемы. Старые вечны, они касаются производительности, эффективности и стоимости вывода. Новые во многом связаны с рисками в сфере безопасности и конфиденциальности. Gemini 2.0 на данный момент находится на экспериментальной стадии, причём только в облегчённой версии Gemini 2.0 Flash. Выход окончательной версии запланирован на начало следующего года. Google DeepMind создала ИИ, который предсказывает погоду быстрее и точнее существующих систем
05.12.2024 [13:45],
Владимир Мироненко
Google DeepMind разработала новую модель прогнозирования погоды с помощью искусственного интеллекта (ИИ) GenCast, которая превосходит традиционные метеорологические методы по прогнозированию погоды на срок до 15 дней и, к тому же, точнее предсказывает экстремальные погодные явления. 
Источник изображения: NOAA/unsplash.com ИИ-модель GenCast рассматривает вероятность реализации нескольких сценариев для точной оценки тенденций — от выработки энергии ветра до перемещения тропических циклонов. Вероятностный метод GenCast является новым рубежом в использовании ИИ для обеспечения более качественных и быстрых ежедневных прогнозов погоды. Этот подход всё чаще используют крупные метеослужбы, пишет Financial Times. «Это знаменует собой своего рода переломный момент в развитии ИИ для прогнозирования погоды, поскольку современные необработанные прогнозы теперь поступают из моделей машинного обучения», — отметил Илан Прайс (Ilan Price), научный сотрудник Google DeepMind. Он добавил, что GenCast может быть включен в оперативные системы прогнозирования погоды, что позволит метеорологам лучше понимать тенденции и готовиться к предстоящим погодным явлениям. Новизна подхода GenCast в сравнении с предыдущими моделями машинного обучения заключается в использовании так называемых ансамблевых прогнозов, представляющих различные результаты, — метода, применяемого в современном традиционном прогнозировании погоды. Для обучения GenCast использовалась накапливавшаяся в течение четырёх десятилетий база данных Европейского центра среднесрочного прогнозирования погоды (ECMWF). Согласно публикации в Nature, модель GenCast превзошла 15-дневный прогноз ECMWF по 97,2 % из 1320 переменных, таких как температура, скорость ветра и влажность. Таким образом она превзошла по точности и охвату ИИ-модель GraphCast от Google DeepMind, представленную в прошлом году. GraphCast превзошла прогнозы ECMWF на 3–10 дней вперед примерно по 90 % показателей. Модели прогнозирования погоды на основе ИИ работают гораздо быстрее стандартных методов прогнозирования, которые полагаются на огромную вычислительную мощность для обработки данных. GenCast может сгенерировать свой прогноз всего за восемь минут, тогда как на составление прогноза с помощью традиционных методов уходят часы. По словам исследователей, ИИ-модель GenCast может быть дополнительно улучшена в части способности предсказания интенсивности крупных штормов. Также может быть увеличено разрешение её данных, чтобы соответствовать обновлениям, сделанным в этом году ECMWF. ECMWF назвал разработку GenCast «важной вехой в развитии прогнозирования погоды». Центр также сообщил, что интегрировал «ключевые компоненты» подхода GenCast в версию своей собственной системы прогнозирования ИИ с ансамблевыми прогнозами, доступную с июня. Google DeepMind представила ИИ-модель Genie 2, которая может превращать тексты в трёхмерные игры
05.12.2024 [10:24],
Дмитрий Рудь
Команда Google DeepMind представила Genie 2 — вторую версию фундаментальной модели ИИ, способной на лету генерировать новые интерактивные цифровые окружения, или игровые миры. 
Источник изображений: Google Напомним, оригинальная Genie была выпущена в феврале и могла генерировать виртуальные 2D-миры из синтезированных изображений. Genie 2 способна делать это в 3D и на основе текстовых команд. Пользователь может описать желаемый мир, выбрать подходящий рендеринг и ступить в новое окружение. На каждом шагу человек/агент совершает действие (движение мыши, нажатие клавиши на клавиатуре), а Genie 2 имитирует его последствия. 
В основе каждого примера — изображение, сгенерированное ИИ-моделью Imagen 3 на основе текстовой подсказки По словам Google DeepMind, Genie 2 может генерировать последовательные интерактивные миры продолжительностью около минуты, хотя большинство показанных (см. видео ниже) примеров длятся 10−20 секунд. По сравнению с первой версией Genie 2:
По мнению Google DeepMind, Genie 2 демонстрирует потенциал фундаментальных моделей мира для создания разнообразных трёхмерных окружений и ускорения тренировок/тестирования ИИ-агентов (вроде того же SIMA). Google DeepMind уточняет, что исследование находится на ранней стадии и требует значительных улучшений в областях возможностей агентов и генерации среды, но уже видит в Genie 2 решение структурной проблемы безопасной тренировки ИИ-агентов. Waymo и Gemini научат роботакси справляться со сложными дорожными ситуациями
31.10.2024 [03:57],
Анжелла Марина
Waymo, дочерняя компания Alphabet, представила новый подход к обучению своих беспилотных транспортных средств, используя модель Gemini — большую мультимодальную языковую модель (MLLM) от Google. Модель улучшит навигацию автономных автомобилей и позволит лучше справляться со сложными дорожными ситуациями. 
Источник изображения: waymo.com В новом исследовательском докладе Waymo дала определение своей разработке как «сквозной мультимодальной модели для автономного вождения» (EMMA), которая обрабатывает данные с сенсоров и помогает роботакси принимать решения о направлении движения, избегая препятствий. Как пишет The Verge, Waymo давно подчёркивала своё стратегическое преимущество благодаря доступу к научным исследованиям в области искусственного интеллекта (ИИ) Google DeepMind, ранее принадлежавшей британской компании DeepMind Technologies. Новая система EMMA представляет собой принципиально иной подход к обучению автономных транспортных средств. Вместо традиционных модульных систем, которые разделяют функции на восприятие, планирование маршрута и другие задачи, EMMA предлагает единый подход, который позволит обрабатывать данные комплексно, поможет избежать ошибок, возникающих при передаче данных между модулями, и улучшит адаптацию к новым, незнакомым условиям на дороге в реальном масштабе времени. Одним из ключевых преимуществ использования моделей MLLM, в частности Gemini, является их способность к обобщению знаний, почерпнутых из огромных объёмов данных, полученных из интернета. Это позволяет моделям лучше адаптироваться к нестандартным ситуациям на дороге, таким как неожиданное появление животных или ремонтные работы. Кроме того, модели, обученные на основе Gemini, способны к «цепочке рассуждений». Это метод, который помогает разбивать сложные задачи на последовательные логические шаги, улучшая процесс принятия решений. Несмотря на успехи, Waymo признает, что EMMA имеет свои ограничения. Например, модель пока не поддерживает обработку 3D-данных с таких сенсоров, как лидар или радар, из-за высокой вычислительной сложности. Кроме того, EMMA способна обрабатывать лишь ограниченное количество кадров изображений одновременно. Подчёркивается, что потребуется дальнейшее исследование для преодоления всех этих ограничений перед полноценным внедрением модели в реальных условиях. Waymo также осознает и риски, связанные с использованием MLLM в управлении автономными транспортными средствами. Модели, подобные Gemini, могут допускать ошибки или «галлюцинировать» в простых задачах, что конечно недопустимо на дороге. Тем не менее, есть надежда, что дальнейшие исследования и улучшения архитектуры ИИ-моделей для автономного вождения преодолеют эти проблемы. Главный разработчик ИИ-видеогенератора Sora сбежал из OpenAI в Google DeepMind
04.10.2024 [19:19],
Сергей Сурабекянц
Тим Брукс (Tim Brooks), возглавлявший вместе с Уильямом Пиблзом (William Peebles) в OpenAI разработку ИИ-генератора видео Sora, сообщил о своём переходе в ИИ-лабораторию Google DeepMind. Там он займётся исследованиями в области создания видео при помощи ИИ и «симуляторами мира». По слухам, уход Брукса вызван техническими проблемами Sora и отставанием в производительности от конкурирующих систем Luma, Runway и других. 
Источник изображения: Pixabay Генеральный директор Google DeepMind Демис Хассабис (Demis Hassabis) уверен, что приход Брукса поможет «сделать реальностью давнюю мечту о симуляторе мира». Под этим термином подразумеваются такие модели ИИ, как недавно выпущенная Genie, которая может генерировать играбельные, управляемые виртуальные миры из синтезированных изображений, реальных фотографий и даже эскизов. В OpenAI Брукс был одним из первых исследователей, работавших над моделью ИИ Sora, представленной в январе 2023 года. Осведомлённые источники связывают его уход с техническими проблемами, от которых, как утверждается, страдает система — ей требовалось более 10 минут для создания 1-минутного видеоклипа. Сообщается, что OpenAI находится в процессе обучения улучшенной модели Sora, которая сможет генерировать видео гораздо быстрее. Весной 2024 года Google представила собственную модель генерации видео под названием Veo. Ожидается, что Veo скоро станет доступна создателям контента в сервисе коротких видео YouTube Shorts. Похоже, что OpenAI пока уступает конкурентам в продвижении разработок по созданию видеоконтента. В начале прошлого месяца Runway подписала соглашение со студией Lionsgate на обучение пользовательской модели видео на основе каталога фильмов Lionsgate. В это же время Stability, которая разрабатывает собственный набор моделей генерации видео, ввела в совет директоров режиссёра «Аватара», «Терминатора» и «Титаника» Джеймса Кэмерона (James Cameron). В начале этого года OpenAI демонстрировала Sora кинематографистам и представителям голливудских студий, но о заключении долгосрочных партнёрских соглашений объявлено не было. Любопытно, что Брукс фактически возвращается в Google, ведь ранее он занимался разработкой телефонов Pixel. Нужно отметить, что он пополнил череду уволившихся из OpenAI высокопоставленных сотрудников и учредителей:
В Google DeepMind научили робота завязывать шнурки и чинить других роботов
12.09.2024 [23:05],
Владимир Фетисов
Дети обычно учатся завязывать шнурки к 5–6 годам. В это же время роботы пытаются освоить выполнение данной задачи уже несколько десятилетий. Похоже, что разработчикам из Google DeepMind удалось продвинуться в этом. А кроме того они преуспели в обучении робота выполнению некоторых других действий, требующих ловкости. 
Источник изображения: Google DeepMind Исследователи из Google DeepMind продемонстрировали метод обучения, позволяющий научить робота выполнять некоторые требующие определённой ловкости действия, такие как завязывание шнурков, подвешивание рубашек и даже починка других роботов. Достигнуть определённых успехов в этом направлении удалось благодаря новой обучающей платформе ALOHA Unleashed и собственной программе моделирования DemoStart, которая позволяет роботам обучаться в процессе наблюдения за людьми. Исследование команды DeepMind в первую очередь демонстрирует, как роботизированные системы могут научиться выполнять достаточно сложные задачи, обучаясь на визуальных демонстрациях. Однако эта работа имеет также важное практическое значение, поскольку такие роботы могут оказаться полезны, особенно для оказания помощи людям с ограниченными возможностями. |
© 1997—2025 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews. kz
![]()
![]()








 MWC 2018
MWC 2018 2018
2018 Computex
Computex






