|
Опрос
|
реклама
Быстрый переход
Китайская Innosilicon представила видеокарту Fenghua 3 — CUDA, DX12, трассировка лучей и более 112 Гбайт HBM
24.09.2025 [15:31],
Николай Хижняк
Компания Innosilicon представила свой графический процессор третьего поколения — Fenghua 3. Компания обещает, что третья версия графического процессора будет значительно превосходить своих предшественников. Компания называет его первым полнофункциональным GPU собственной разработки, которые построен на открытой архитектуре RISC-V и совместим с CUDA. 
Источник изображений: Innosilicon В отличие от предыдущих поколений ускорителей Fenghua, основанных на архитектуре PowerVR от Imagination Technologies, Fenghua 3 использует в качестве основы проект OpenCore RISC-V Nanhu V3. Innosilicon утверждает, что новый GPU способен справиться с широким спектром рабочих нагрузок: от обучения ИИ и масштабных научных вычислений до САПР, медицинской визуализации и облачного гейминга. Для Fenghua 3 заявляется поддержка DirectX 12, Vulkan 1.2 и OpenGL 4.6 с аппаратной трассировкой лучей. Компания продемонстрировала работу GPU в таких играх, как Tomb Raider, Delta Force и Valorant, хотя данные о частоте кадров и настройках не были предоставлены. Fenghua 3 также поддерживает подключение до шести 8K-мониторов с частотой обновления 30 Гц.  Для задач искусственного интеллекта ускоритель на базе Fenghua 3 предлагает более 112 Гбайт высокоскоростной памяти HBM — это самый большой объём памяти среди китайских видеокарт. Один ускоритель может обрабатывать модели с 32 и 72 млрд параметров, а кластер из восьми — поддерживать огромные модели DeepSeek 671B и 685B. Innosilicon также подтвердила совместимость своей новинки с Qwen 2.5, Qwen 3 и семейством ИИ-моделей DeepSeek V3, V3.1 и R1. Innosilicon также похвасталась тем, что Fenghua 3 — первая в Китае видеокарта, поддерживающая формат YUV444, который обеспечивает наилучшую детализацию и точность цветопередачи. Это будет особенно полезно для тех, кто работает с САПР или занимается видеомонтажом. Кроме того, Fenghua 3 — первая в мире видеокарта, которая предлагает встроенную поддержку технологии DICOM (Digital Imaging and Communication in Medicine). Она позволяет точно визуализировать рентгеновские снимки, МРТ, КТ и УЗИ на стандартных мониторах, устраняя необходимость в дорогостоящих специализированных медицинских дисплеях с градациями серого. Ускоритель работает с системами Windows, Android, Tongxin и Kylin Linux. Сделка c Nvidia не повлияет на собственные планы Intel по выпуску процессоров и видеокарт
20.09.2025 [13:34],
Андрей Созинов
Intel чётко заявила — сотрудничество с Nvidia не повлияет на уже свёрстанные её собственные планы выпуска новых процессоров и видеокарт. Компания пояснила, что все новые продукты, которые будут разрабатываться в союзе с Nvidia, должны будут усилить и дополнить линейку продукции, а не перекраивать её. Отдельно Intel подчёркивает, что видеокарты Arc тоже продолжат развиваться. 
Источник изображения: X, Lip-Bu Tan «Хотя на данный момент мы не раскрываем конкретные планы, всё, о чём мы говорим, соответствует существующей стратегии Intel и дополняет её. Сотрудничество с NVIDIA позволит предложить дополнительные решения для ИИ и расширит присутствие в сегментах высокопроизводительных вычислений как в клиентских системах, так и в ЦОД. Мы продолжим придерживаться нашего плана развития GPU. С NVIDIA мы работаем над обслуживанием отдельных сегментов рынка, но также будем следовать собственному курсу», — пояснил представитель Intel в комментарии сайту Tom's Hardware. Напомним, Nvidia инвестировала в Intel $5 млрд и договорилась о поставке чиплетов RTX для интеграции их в процессоры Intel. Это породило два ключевых вопроса. Первый: изменится ли судьба графики Arc — в том числе дискретной и встроенной. И второй: повлияет ли это на планы Intel по мобильным CPU. После того, как в прессе поднялась волна спекуляций, Intel дала развёрнутый официальный комментарий. Из него следует: оснований для беспокойства нет, компания продолжит придерживаться своего плана по GPU, что позволяет рассчитывать на сохранение линейки Arc как минимум в обозримом будущем. Что касается процессоров, здесь Intel ещё более категорична: текущая мобильная дорожная карта остаётся без изменений. Сейчас в процессорных планах значится процессор Panther Lake, который должен дебютировать этой осенью с началом массовых поставок в 2026 году. Следом идёт Nova Lake, запланированный на конец 2026-го с фактическим выходом в 2027 году. Согласно утечкам, в том же году может появиться и Wildcat Lake. Всё, что родится в результате партнёрства с Nvidia, будет дополнением к этом списку. По сути, это могут быть премиальные версии уже существующих CPU, ориентированные на игровые или творческие сценарии. Технически у Intel уже есть опыт работы с GPU-тайлами в имеющихся процессорах. Поэтому логично предположить, что в будущем компания сможет выпускать процессоры либо с графикой Arc, либо с чиплетами Nvidia RTX на выбор. По словам Дженсена Хуанга, Intel и Nvidia работают над партнёрством около года. Но деталей о конкретных продуктах ждать в ближайшее время не стоит. Для того, чтобы обширные планы компаний воплотились в жизнь, может потребоваться ещё 2-3 года. AMD готовит ответ ИИ-серверам Nvidia — система MegaPod объединит 256 ускорителей Instinct MI500 и 64 процессора EPYC Verano
05.09.2025 [01:17],
Анжелла Марина
AMD намерена представить в 2027 году масштабную вычислительную платформу для искусственного интеллекта под кодовым названием MI500 Scale Up MegaPod, которая будет включать 256 ускорителей серии Instinct MI500 и 64 центральных процессора EPYC Verano. Данная система сможет предложить лучшую масштабируемость по сравнению с Nvidia NVL576 и станет развитием анонсированной ранее платформы Helios 2026 года, которая будет содержать более 72 GPU. 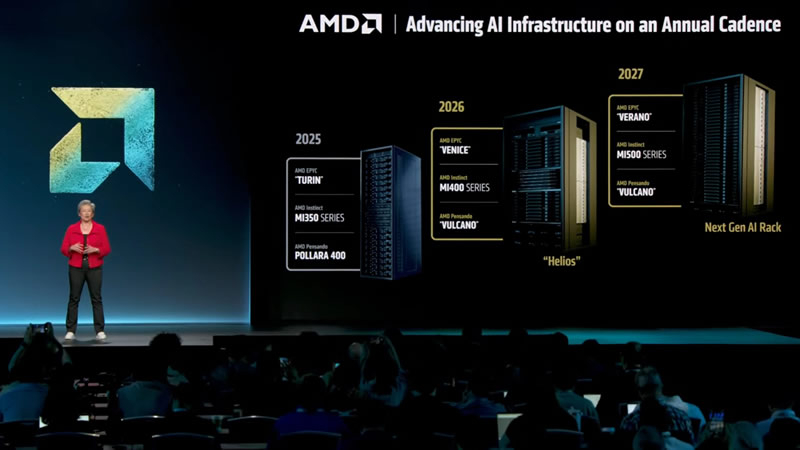
Источник изображения: AMD По сообщению Tom's Hardware, информация о деталях проекта, получившего предварительное название MI500 UAL256, была опубликована аналитическим изданием SemiAnalysis в официальном аккаунте X. В конфигурации задействованы три связанные стойки: в двух боковых разместят по 32 вычислительных модуля, каждый из которых включает один процессор EPYC Verano и четыре ускорителя Instinct MI500, а центральная стойка будет отведена под 18 модулей с коммутаторами UALink. Всего в системе используется 64 вычислительных модуля и 256 GPU-ускорителей. По сравнению с NVL576 от Nvidia, в котором используется 144 ускорителя Rubin Ultra (каждый содержит четыре вычислительных чиплета), платформа AMD предлагает примерно на 78 % больше GPU-ускорителей на одну систему. Однако аналитики отмечают, что прямое сравнение производительности затруднено, так как у NVL576 будет 147 Тбайт памяти HBM4 и суммарная производительность 14 400 PFLOPS в формате FP4, что делает её крайне производительной и конкурентной системой. Учитывая растущее энергопотребление и тепловыделение графических процессоров для искусственного интеллекта, платформа MI500 UAL256 будет использовать единую систему жидкостного охлаждения как для вычислительных модулей, так и для сетевых коммутаторов. Ожидается, что AMD представит свою разработку в конце 2027 года, примерно в тот же период, когда Nvidia планирует дебют своих машин на архитектуре Kyber. Если это произойдёт, то обе компании в 2028 году увеличат производство стоечных решений на базе Instinct MI500 и Rubin Ultra. Nvidia захватила почти четверть рынка GPU для ПК — лидирует Intel, а доля AMD сжалась до 14 %
30.08.2025 [16:18],
Николай Хижняк
Nvidia продолжила стремительно наращивать свою долю на рынке видеокарт во втором квартале 2025 года. По данным исследовательской компании Jon Peddie Research, мировые поставки графических процессоров для ПК, куда входят как дискретные GPU, так и встроенные, достигли 74,7 млн единиц, а поставки центральных процессоров для ПК — 66,9 млн единиц. 
Источник изображения: Wccftech Согласно прогнозу JPR, с 2025-го по 2028-й год среднегодовой темп сокращения рынка графических процессоров для ПК составит 2,9 %, а к концу обозначенного периода количество использующихся по всему миру графических процессоров для ПК достигнет почти 3 млрд единиц. Доля дискретных видеокарт на рынке в течение следующих пяти лет достигнет 23 % — большинство систем по-прежнему будут ограничиваться встроенной графикой. 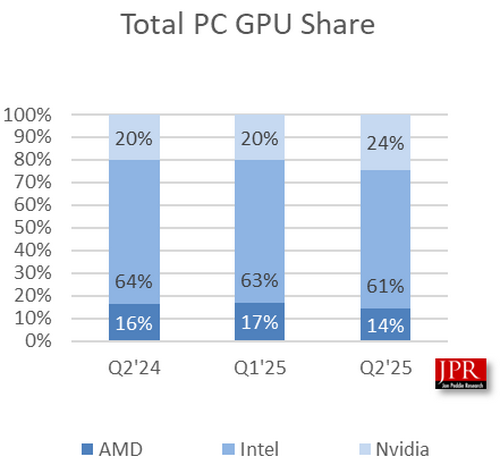
Источник изображения здесь и ниже: Jon Peddie Research Во втором квартале поставки GPU для ПК выросли на 4,9 % по сравнению с тем же периодом прошлого года. Поставки видеокарт для настольных ПК увеличились на 11 %, а мобильных GPU для ноутбуков — на 2,5 %. В этом году Nvidia и AMD выпустили новые серии видеокарт — GeForce RTX 5000 и Radeon RX 9000. Благодаря этому поставки видеокарт начали расти по сравнению с предыдущими месяцами. Цены на новые модели графических ускорителей всё ещё находятся на высоком уровне, но они постепенно нормализуются, и многие модели уже доступны по ценам, близким к рекомендованным. Общая доля GPU компаний AMD и Intel на рынке снизилась: у AMD падение составило 2,4 % по сравнению с предыдущим кварталом, а у Intel — 1,9 %. В то же время доля Nvidia увеличилась до 24 %, что на 4,3 % больше, чем кварталом ранее. Благодаря тому, что встроенная графика присутствует в большинстве процессоров Intel, компания занимает большую часть рынка. 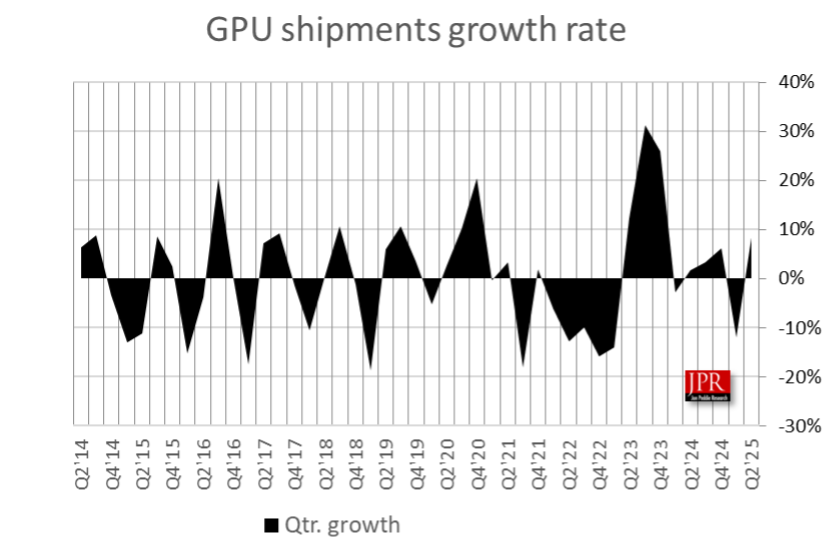 Учитывая, что дискретные видеокарты продемонстрировали наибольший рост во II квартале 2025 года, можно ожидать, что доля Nvidia на рынке дискретной графики поднимется на новый уровень. Согласно отчёту за I квартал 2025 года, доля Nvidia на рынке дискретной графики составляла 92 %. AMD же сократила свою долю с 15 % до 8 %. Доля Intel, по данным Jon Peddie Research, упала с одного процента до нуля. 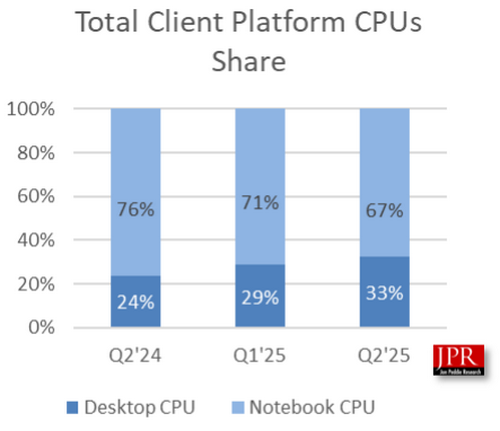 Отчёт по поставкам процессоров для ПК показывает, что AMD удалось увеличить отгрузки в штучном выражении на 27 %. У Intel прирост составил всего 2 %. Совокупно поставки процессоров во II квартале этого года выросли на 8 %. Сегмент процессоров для ПК увеличился на 12,9 % по сравнению с прошлым годом и на 7,9 % по сравнению с предыдущим кварталом. По состоянию на I квартал 2025 года доля настольных процессоров на рынке составила 33 %. В IV квартале 2024 года этот показатель составлял 29 %, а по итогам второго квартала прошлого года — 24 %. Доля процессоров для ноутбуков в I квартале 2025 года составила 67 %, что ниже 71 % кварталом ранее и 76 % годом ранее. AMD призналась, что готова быстро создавать дискретные нейронные процессоры для ИИ
02.08.2025 [07:05],
Алексей Разин
Очевидно, что Intel и AMD сложно смириться с тем, как Nvidia практически единолично пожинает плоды своих многолетних усилий по продвижению так называемых GPU в сфере ускорения вычислений. В свою очередь, AMD готова не только создавать конкурентоспособные GPU, но и присматривается к сегменту более специализированных нейронных процессоров (NPU), которые также могут быть востребованы в эпоху ИИ. 
Источник изображения: AMD Руководитель направления клиентских центральных процессоров AMD Рахул Тику (Rahul Tikoo) подтвердил изданию CRN, что эта компания ведёт переговоры с клиентами на тему возможного применения специализированных чипов, ускоряющих работу инфраструктуры ИИ, при этом не являющихся GPU. Подчёркивается, что крупные производители ПК типа Lenovo, Dell и HP Inc. интересуются возможностью использования различных ускорителей для работы с искусственным интеллектом. В частности, Dell уже выразила готовность использовать дискретный ускоритель Qualcomm для соответствующих нужд. Как пояснил представитель AMD, компания внимательно присматривается к этой сфере применения, и у неё есть решения, которые она может предложить при наличии спроса. Когда такие продукты появятся на рынке, Рахул Тику пояснить отказался, сославшись на необходимость сохранения коммерческой тайны. При этом он подчеркнул, что AMD подобные предложения может вывести на рынок достаточно быстро. Ранее технический директор одного из системных интеграторов заявил CRN, что AMD, на его взгляд, может предложить NPU, созданные с использованием разработок Xilinx. Соответствующий блок уже появился в составе процессоров Ryzen, в дальнейшем он может трансформироваться в обособленное дискретное решение с более высокой производительностью. Ценность подобных компонентов должна заключаться в том, что при адекватном уровне быстродействия они будут потреблять существенно меньше электроэнергии, чем GPU. Китайская Lisuan Technology представила видеокарту на собственном GPU, и она тянет Black Myth: Wukong в 4K
26.07.2025 [15:14],
Николай Хижняк
Китайский стартап Lisuan Technology представил на мероприятии в Шанхае свой первый графический процессор 7G106 собственной разработки, изготовленный с применением 6-нм техпроцесса TSMC N6. Работу чипа показали в составе референсной видеокарты. GPU предназначен для игровых видеокарт массового сегмента. 
Источник изображений: Lisuan Technology / TechPowerUp Графический процессор 7G106 от компании Lisuan Technology использует проприетарную архитектуру TrueGPU с поддержкой различных API, включая DirectX 12 (без поддержки трассировки лучей), Vulkan 1.3, OpenGL 4.6 и OpenCL 3.0. Несмотря на отсутствие поддержки трассировки лучей, 7G106 позиционируется как решение для широкого круга пользователей, ищущих достойную игровую производительность без наценки, характерной для продукции топовых мировых брендов.  В составе графического процессора 7G106 присутствуют 192 текстурных блока (TMU) и 96 блоков растеризации (ROP). Чип поддерживает до 12 Гбайт памяти GDDR6 с 192-битной шиной. Для GPU заявляется поддержка вычислений FP32 и INT8 с теоретической производительностью FP32 на уровне 24 Тфлопс. Графический чип также поддерживает аппаратное ускорение декодирования AV1 и HEVC до 8K60FPS, а также кодирование AV1 с разрешением 4K30FPS и HEVC с разрешением 8K30FPS. Он поддерживает интерфейс PCIe 4.0 x16 и предлагает поддержку четырёх видеовыходов DisplayPort 1.4 с компрессией DSC 1.2b. Поддержка HDMI не заявлена, вероятно, ввиду высокой стоимости лицензии.  Характеристики энергопотребления представленного решения пока неокончательные. Референсная видеокарта на базе 7G106 оснащена одним 8-контактным разъёмом PCIe, что подразумевает максимальную потребляемую мощность 225 Вт. Карта также предлагает функцию виртуального GPU (vGPU), поддерживающую до 16 контейнеров через SR-IOV, что говорит о её направленности не только на игровой сегмент, но и на корпоративные решения и виртуализацию. Компания подчеркнула эту универсальность во время анонса, выделив варианты использования ускорителя для рабочих станций, создания контента и даже метавселенной. Lisuan Technology также анонсировала профессиональный вариант ускорителя, оснащённый 24 Гбайт памяти. Характеристики в целом аналогичные игровой карте, но все данные производитель не привёл. Сравнить обе карты можно в таблице ниже. 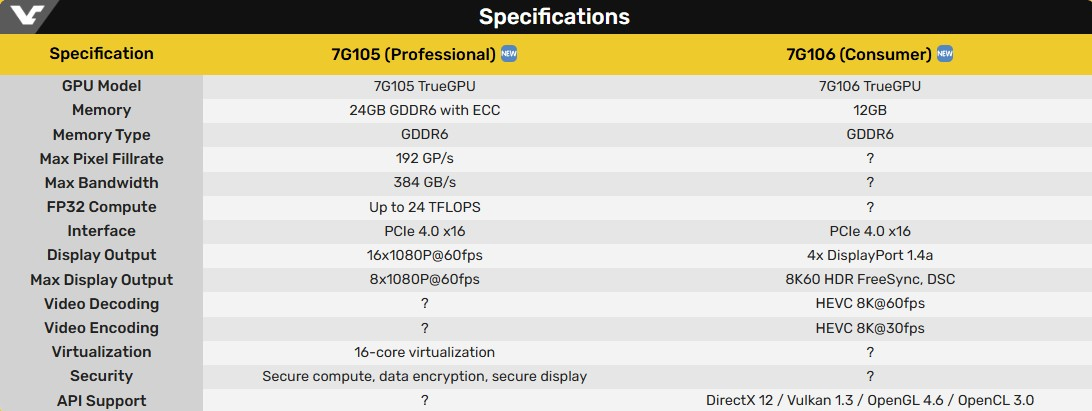 На мероприятии также было продемонстрировано, что видеокарта на базе графического процессора 7G106 способна обеспечить приемлемый уровень производительности в игре Black Myth: Wukong в разрешении 4K и при высоких настройках графики. Согласно данным портала ITHome, карта показала более 70 кадров в секунду в этой игре. В синтетических бенчмарках 7G106 показал результат 26 800 в 3DMark Fire Strike и 111 290 баллов в тесте Geekbench 6.4.0 OpenCL. Во втором случае китайское решение оказалось примерно на 10 % быстрее GeForce RTX 4060. Однако в тесте Fire Strike китайский GPU оказался заметно медленнее моделей Nvidia GeForce RTX 5060, RTX 5050, а также AMD Radeon RX 9060, все из которых показали результат около 29 000 баллов. 
Источник изображений: ITHome  Согласно имеющейся информации, образцы графического процессора 7G106 начнут рассылать заинтересованным сторонам в августе. А начало массового производства 7G106 запланировано на сентябрь этого года. Однако информации о тактовых частотах графического процессора, а также данных о том, когда видеокарты на его основе появятся в продаже, пока нет. Lisuan Tech 7G106

Смотреть все изображения (16)



Смотреть все изображения (16) Представители портала TechPowerUp побывали на презентации Lisuan Technology. С фотографиями этого мероприятия можно ознакомиться в галерее выше. Китайцы выпустили первую видеокарту на суверенном 6-нм GPU — Lisuan G100, которую сравнивают с RTX 4060
30.05.2025 [16:29],
Николай Хижняк
Китайская компания Lisuan Technology заявила, что успешно запустила первый образец будущей видеокарты G100, в основе которой используется первый для Китая полностью суверенный графический процессор, произведённый с использованием 6-нм техпроцесса. 
Источник изображения: Lisuan Technology Китай стремится к технологической независимости от западных компаний. На этом фоне к китайским компаниям присоединилось множество опытных разработчиков и инженеров. Lisuan Technology, основанная в 2021 году, является одним из самых молодых стартапов в сегменте разработки и производства видеокарт. Другими аналогичными стартапами являются Moore Threads (основана в 2020 году) и Biren (создана в 2019 году). В числе основателей Lisuan Technology — ветераны индустрии, проработавшие в Кремниевой долине более 25 лет. То же самое можно сказать и о Moore Threads, которая была основана Чжан Цзяньчжуном (Zhang Jianzhong), бывшим вице-президентом и директором китайского подразделения Nvidia. О видеокарте G100 пока мало информации. Известно, что в её основе используется проприетарная архитектура TrueGPU, разработанная Lisuan Technology. В отличие от некоторых других китайских производителей, которые нередко лицензируют технологии таких компаний, как Imagination, для разработки на их основе собственных продуктов, TrueGPU является действительно суверенной архитектурой, разработанной с нуля. Lisuan Technology не сообщает, на мощностях какого производителя выпущен 6-нм графический процессор, используемый в основе G100. Из-за американских санкций Китай не имеет доступа к иностранным 6-нм техпроцессам, что исключает Samsung и TSMC в качестве возможных производителей этого чипа. Весьма вероятно, что за выпуск GPU отвечает китайский производитель полупроводников SMIC, который также занимается выпуском графических процессоров Ascend 920 AI для компании Huawei. Слухи приписывают G100 производительность на уровне GeForce RTX 4060, хотя сама компания Lisuan Technology эту информацию не подтверждала. Также ускорителю приписывают поддержку графических API DirectX 12, Vulkan 1.3, OpenGL 4.6 и OpenGL 3.0. Это может говорить о том, что G100 можно будет использовать не только для профессиональных задач, но и для игр. Разработка G100 началась в 2021 году. Изначально компания планировала выпустить этот ускоритель в 2023 году, однако финансовые трудности (дело чуть не дошло до банкротства), с которыми столкнулся разработчик, сдвинули срок выпуска на 2024 год. В конечном итоге родительская компания Dongxin Semiconductor поддержала стартап и выделила ему финансирование в размере $27,7 млн, что позволило продолжить разработку G100. Lisuan Technology успешно произвела первые чипы G100, они работают и, судя по всему, результаты соответствуют ожиданиям разработчика. Сейчас компания занимается разработкой программного обеспечения, проверками аппаратной части, а также оптимизацией графического драйвера. Lisuan Technology рассчитывает выпустить небольшое количество видеокарт G100 в третьем квартале этого года, однако массовое производство ускорителя, вероятно, стартует не раньше 2026 года. Разработка видеокарты с нуля требует больших усилий и времени. Опыт той же Moore Threads показал, что разработка программного обеспечения так же важна, как и разработка «железа», поскольку правильно оптимизированные драйверы способны значительно повысить производительность GPU. AMD столкнулась со слабым спросом на ИИ-ускорители Instinct MI325X
14.05.2025 [09:27],
Вячеслав Ким
Ускорители AMD Instinct MI325X, запущенные во втором квартале 2025 года, не смогли привлечь крупных клиентов, уступив по популярности решениям от Nvidia. По данным аналитиков SemiAnalysis, покупатели предпочли графические процессоры Blackwell от Nvidia из-за более выгодного соотношения производительности и стоимости.  Одним из ключевых факторов низкого спроса стал предел масштабируемости MI325X — до восьми GPU на систему. Для сравнения, конкурирующий продукт Nvidia GB200 NVL72 объединяет до 72 графических процессоров в едином кластере, что критически важно при выполнении масштабных задач в области искусственного интеллекта. Ранний интерес к MI325X проявила компания Microsoft в 2024 году, однако после первых закупок корпорация не разместила повторных заказов. AMD попыталась исправить ситуацию, снизив цены для привлечения новых клиентов. Oracle и ещё несколько крупных операторов дата-центров заинтересовались предложением, но объёмы их закупок остаются незначительными по сравнению с поставками Nvidia. Тем не менее у AMD Instinct MI325X сохраняются перспективы в сегменте, где не требуется большое количество объединённых GPU. Компания намерена улучшить экосистему программного обеспечения и сохранить конкурентные цены для привлечения разработчиков моделей ИИ с небольшим числом параметров. AMD выпустила Instinct MI325X одновременно с Nvidia H200 и платформой Blackwell, что существенно осложнило конкуренцию на рынке высокопроизводительных вычислений. В последние годы Nvidia занимает лидирующие позиции благодаря более гибким решениям и высокой производительности в задачах искусственного интеллекта и глубокого обучения. Nvidia придумала, как законно обойти антикитайские санкции, и продолжит поставки ИИ-ускорителей в Китай
02.05.2025 [22:24],
Анжелла Марина
После ужесточения санкций со стороны США и запрета на поставку в Китай ИИ-ускорителя H20, Nvidia оказалась в сложной ситуации и вынуждена пересмотреть стратегию работы с ключевым китайским рынком, чтобы избежать нарушений экспортных ограничений. Компания ведёт переговоры с Alibaba, ByteDance и Tencent о поставках адаптированных чипов. 
Источник изображения: Mariia Shalabaieva / Unsplash По сообщению Reuters, генеральный директор компании Дженсен Хуан (Jensen Huang) лично проинформировал партнёров о новых разработках во время своего визита в Пекин в середине апреля. Эта поездка состоялась вскоре после того, как США ограничили экспорт в Китай чипов H20 (специализированный вариант H100) для задач искусственного интеллекта. По оценкам самой Nvidia, новые экспортные ограничения могут лишить компанию $5,5 млрд выручки, и чтобы минимизировать потери, разрабатываются чипы, которые формально соответствовали бы американским требованиям, но при этом сохраняли бы высокую производительность. Параллельно ведётся работа над «китайской» версией новейшего процессора Blackwell. Китайский рынок остаётся критически важным для Nvidia, поэтому компания ищет любые способы сохранить там своё присутствие. Ранее она уже выпускала «урезанные» версии чипов для этого региона, но новые санкции требуют более сложных технических решений, над чем сейчас и трудятся инженеры. Сообщается, что первые образцы ИИ-ускорителей поступят китайским клиентам уже в июне, а китайская версия Blackwell — немного позже. Представители Nvidia отказались комментировать эту информацию. Компании ByteDance, Alibaba и Tencent, а также Министерство торговли США не ответили на запросы Reuters. Anthropic раскрыла схему контрабанды ИИ-чипов вперемешку с живыми лобстерами — в Nvidia лишь посмеялись
02.05.2025 [15:58],
Павел Котов
На этой неделе события в технологической войне США и Китая приобрели несколько курьёзный оборот. Специализирующаяся на искусственном интеллекте компания Anthropic заявила, что контрабандисты ввозят чипы Nvidia в Китай, спрятав их вместе с живыми лобстерами. 
Источник изображения: ChatGPT «Китай наладил сложные контрабандные схемы, и подтверждены инциденты, связанные с чипами на сотни миллионов долларов. В некоторых случаях контрабандисты применяли творческий подход, чтобы обойти экспортный контроль, в том числе прятали процессоры в накладных животах для имитации беременности и укрывали их [чипы] рядом с живыми лобстерами. Чтобы обойти экспортный контроль, китайские компании быстро регистрируют подставные юрлица в третьих странах», — говорится в публикации корпоративного блога Anthropic. Nvidia отреагировала на это заявление с сарказмом. «Американские компании должны принять вызов и заняться инновациями, а не рассказывать небылицы, что большая, тяжёлая и хрупкая электроника каким-то образом провозится контрабандой в „накладных животах“ или „вместе с живыми лобстерами“», — заявил её представитель CNBC. В действительности китайской таможне уже приходилось обнаруживать попытку контрабанды как в накладных животах, так и в контейнерах с лобстерами. Это, конечно, похоже на сцену из дешёвой комедии про шпионов, но это не вполне вымысел. Графические процессоры, о которых идёт речь, компактнее потребительских видеокарт, и их вполне можно прятать, прибегая к подобным ухищрениям. Правда, гарантия при этом аннулируется. ИИ с помощью мощных GPU научился взламывать пароли быстрее, чем их успевают менять
30.04.2025 [22:48],
Анжелла Марина
Современные хакеры с помощью искусственного интеллекта и мощных видеокарт (GPU) могут взламывать даже сложные пароли за считанные дни, а в некоторых случаях — мгновенно. Новое исследование по кибербезопасности, о котором сообщил HotHardware, показало, что традиционные комбинации символов больше не обеспечивают надёжной защиты. 
Источник изображения: AI Системы безопасности давно используют метод хеширования — преобразование пароля в случайную последовательность символов. Например, пароль «Hot2025hard@» может храниться в базе данных сайта как зашифрованная строка вида «M176рге8739sheb647398nsjfetwuha63». Однако злоумышленники научились обходить эту защиту, создавая огромные списки возможных комбинаций и сравнивая их с утёкшими в сеть хешами. Согласно исследованию Hive Systems, такие нейросети, как ChatGPT-3, в сочетании с 10 000 видеокарт Nvidia A100 способны за короткое время подобрать 8-символьный пароль, состоящий из цифр, заглавных и строчных букв. Если же пароль ранее уже утёк в сеть, содержит словарные слова или повторяется на разных сайтах, взлом происходит ещё быстрее. Особую угрозу представляют мощные GPU-кластеры. Так, получив доступ, например, к 20 000 чипов Nvidia A100, хакеры могут взламывать даже длинные пароли. При этом исследователи подчёркивают, что речь идёт о случайно сгенерированных комбинациях, а простые пароли вроде «123456» или «qwerty» взламываются моментально. Вывод исследования очевиден: привычные способы защиты становятся неэффективными. Некоторые крупные компании, такие как Microsoft, уже переходят на passkey — более безопасную форму аутентификации без использования паролей. Она представляет собой защищённый цифровой ключ, хранящийся в специальном аппаратном или программном модуле непосредственно на устройстве пользователя, например, в Trusted Platform Module (TPM) или в облаке Microsoft с шифрованием. Тем не менее большинство пользователей всё ещё полагаются на устаревшую систему паролей. Пока же эксперты советуют использовать пароли длиной не менее 12 символов, включающие цифры, спецсимволы (например, «@» или «~») и буквы разного регистра. Также важно не применять один и тот же пароль на разных сайтах и, по возможности, активировать двухфакторную аутентификацию. Nvidia выпустила ещё одно экстренное обновление драйвера для устранения массы проблем у GeForce RTX 5000
29.04.2025 [14:09],
Дмитрий Федоров
Текущее поколение графических карт Nvidia уже успело пройти через немало испытаний. Проблемы на старте продаж, запредельные цены, недовольство покупателей из-за недостаточного объёма видеопамяти — и это лишь малая часть трудностей. Более того, ситуацию усугубляли многочисленные проблемы с драйверами, включая проблемы с отображением температуры, нестабильную работу, появление чёрных экранов и ряд других сбоев. 
Источник изображения: Nvidia Пользователи графических ускорителей (GPU) компании Nvidia стали свидетелями целой серии крупных обновлений драйверов, включая несколько экстренных исправлений, и сейчас Nvidia выпустила ещё одно — нацеленное в основном на решение проблем в линейке RTX 50-й серии. Теперь доступна для загрузки версия драйвера GeForce Hotfix Display Driver 576.26. Вот список исправлений, включённых в это обновление:
Кроме того, Nvidia сообщает, что драйвер версии 576.26 включает следующие семь исправлений из предыдущего экстренного обновления GeForce Hotfix 576.15:
Драйвер доступен для загрузки на официальном сайте по ссылке. Что касается других проблем, например нехватки видеопамяти, то ходят слухи, что грядущие модели Nvidia серии SUPER могут принести столь ожидаемое увеличение объёма памяти для нескольких графических карт этой линейки. Рынок видеокарт показал рост в прошлом квартале, но долгосрочный прогноз слабый
07.03.2025 [04:33],
Анжелла Марина
Согласно новому отчёту аналитической компании Jon Peddie Research, мировой рынок дискретных видеокарт для ПК в исполнении партнёров AIB продемонстрировал рост в четвёртом квартале 2024 года (Q4 2024). Объём поставок AIB достиг 8,4 миллиона единиц, а поставки процессоров для настольных ПК увеличились до 22,5 миллиона. Общий рост GPU поставок составил 6,2 %, превысив средний показатель за последние 10 лет. 
Источник изображения: Nvidia Несмотря на квартальный рост, прогноз на ближайшие годы остаётся отрицательным. Ожидается, что совокупный темп падения рынка AIB составит 4,3 % в период с 2024 по 2028 годы. К концу прогнозируемого периода общий объём установленных видеокарт достигнет 119 миллионов единиц, а уровень использования дискретных графических ускорителей в настольных ПК составит 81 %. 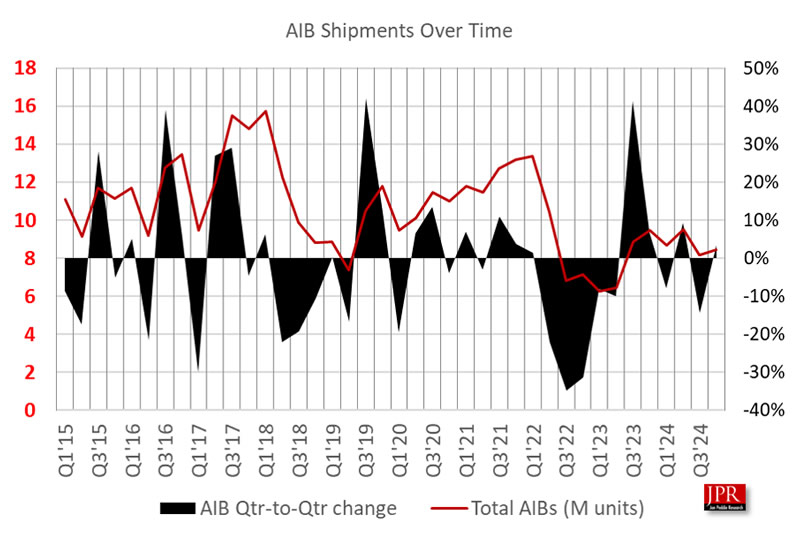
Источник изображения: jonpeddie.com Анализ рыночных долей также показывает изменения в расстановке сил между основными игроками. Доля AMD увеличилась на 5 процентных пунктов по сравнению с предыдущим кварталом, Intel нарастила свою долю на 1,2 п.п., в то время как доля Nvidia снизилась на 6,3 п.п. Отмечается, что такая динамика может быть связана с рядом факторов, включая производственные ограничения и перераспределение ресурсов в пользу графических процессоров для задач искусственного интеллекта (ИИ). 
Источник изображения: jonpeddie.com Из-за высокого спроса производители завершили последний квартал 2024 года с большим объёмом невыполненных заказов, что, по мнению аналитиков, приведёт к аномально высоким поставкам в первом квартале 2025 года. Однако во втором квартале ожидается спад, отчасти из-за введения новых тарифов. «Мы по-прежнему далеки от нормального сезонного цикла, а тарифы окажут дополнительное давление на рынок», — заявил президент Jon Peddie Research Джон Педди (Jon Peddie). 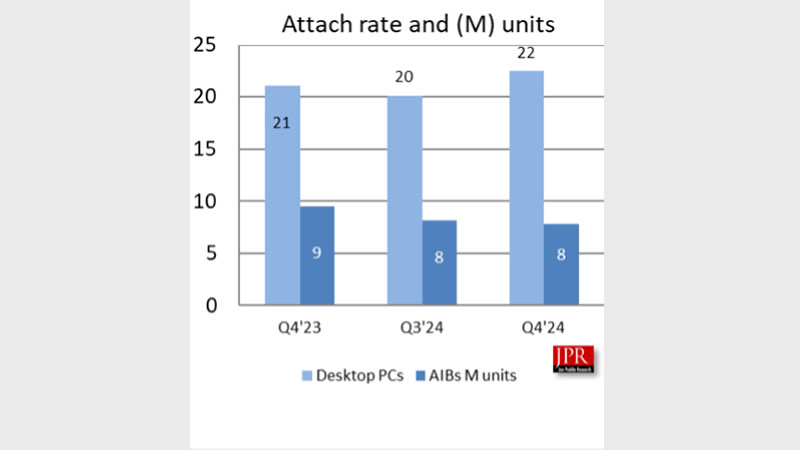
Источник изображения: jonpeddie.com Общий же индекс использования дискретных видеокарт в настольных ПК снизился до 138 %, что на 7 п.п. ниже, чем в предыдущем квартале. Рынок процессоров для настольных ПК сократился на 7,8 % в годовом исчислении, но вырос на 11,6 % по сравнению с предыдущим кварталом. Стоит сказать, что так как AMD и Nvidia планируют представить в первом квартале 2025 года (Q1 2025) новые модели видеокарт, это может в целом оказать положительное влияние на рынок, дополнительно его простимулировав. AMD обогнала Nvidia по плотности транзисторов — даже чип GeForce RTX 5090 проиграл
28.02.2025 [22:37],
Николай Хижняк
Компания AMD представила сегодня графическую архитектуру RDNA 4 и две видеокарты на её основе — Radeon RX 9070 XT и RX 9070. Обе новинки основаны на разных модификациях графического процессора Navi 48. В старшей модели используется Navi 48 XTX, а младшая получила Navi 48 XT. Как пишет портал Tom’s Hardware, эти чипы обладают одной из самых высоких плотностей транзисторов на квадратный миллиметр среди GPU. 
Источник изображения: AMD Площадь чипа Navi 48 составляет 357 мм². Это меньше, чем у чипа GB203 (375 мм²), использующегося в составе видеокарт GeForce RTX 5080 и RTX 5070 Ti. Однако плотность транзисторов у нового GPU от AMD выше. В целом в составе Navi 48 содержится 53,9 млрд транзисторов, а у GB203 их 45,6 млрд. У Navi 48 плотность транзисторов составляет около 151 млн/мм², а у GB203 — 120,6 млн/мм². У чипа AMD этот показатель на 25 % выше, чем у конкурента. Более того, плотность транзисторов у Navi 48 выше, чем у графического процессора GB202 (123 млн/мм²), использующегося в основе флагманской видеокарты GeForce RTX 5090. Очевидно, что это не совсем корректное сравнение, поскольку та же RTX 5090 в любом случае окажется значительно быстрее представленных сегодня видеокарт Radeon. Тем не менее любопытно отметить, что Nvidia, похоже, не придавала столь большого приоритета плотности транзисторов при разработке Ada Lovelace, как AMD для своего графического процессора на RDNA 4. И, конечно, нужно учитывать, что количество транзисторов, как правило, считается приблизительным и существуют разные способы их подсчёта. AMD решила отказаться в новом поколении графической архитектуры от чиплетного дизайна, который применялся для GPU на архитектуре RDNA 3, и вернулась обратно к монолитному. Это означает, что вся кеш-память, которая ранее располагалась на отдельных чиплетах графического процессора, теперь содержится в составе одного кристалла вместе с графическими ядрами. И хотя плотность транзисторов у того же Navi 31 (с чиплетным дизайном) тоже составляла порядка 150 млн/мм², этот показатель рассчитывался без учёта совместного использования пространства с кеш-памятью на том же кристалле. AMD следует отдать должное хотя бы за то, что ей удалось вернуться к монолитному дизайну GPU, сохранить прежний уровень плотности транзисторов, а также встроить 64 Мбайт Infinity Cache, не жертвуя при этом эффективностью. Imagination представила графический процессор DXTP, который хорош и в графике, и в ИИ-вычислениях
25.02.2025 [16:43],
Павел Котов
Компания Imagination Technologies представила графический процессор DXTP, предназначенный как для обработки графики, так и для вычислений общего назначения на смартфонах и других устройствах с ограниченным ресурсом питания. 
Источник изображений: imaginationtech.com Благодаря ряду нововведений на уровне микроархитектуры Imagination DXTP предлагает в среднем 20-процентный прирост энергоэффективности — количества кадров в секунду на ватт — в наиболее распространённых нагрузках по сравнению с актуальными графическими процессорами DXT. 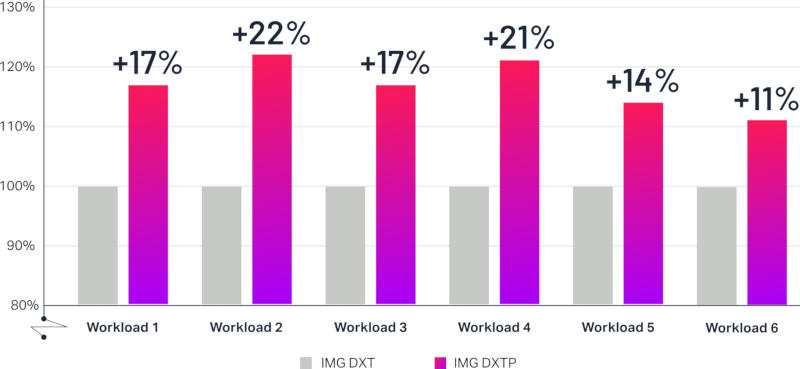 Проекты Imagination востребованы, как указывает сам разработчик, на рынках от мобильных устройств до беспилотных автомобилей. В минувшем году компания освоила технологию аппаратного ускорения трассировки лучей, которая ещё недавно была прерогативой передовых видеокарт для ПК и игровых консолей, но в последние годы всё активнее проникает в мобильные чипы. Вычислительный движок DXTP доступен в двух конфигурациях: для мобильных устройств и автомобилей. Он поддерживает отрисовку до 64 гигапикселей в секунду, производительность составляет 2 Тфлопс в вычислениях FP32 и 8 TOPS в INT8 при тактовой частоте 1 ГГц. Архитектура DXTP также отличается высокой гибкостью — благодаря аппаратной технологии виртуализации многозадачный графический процессор может одновременно обрабатывать графику и выполнять вычисления общего назначения. 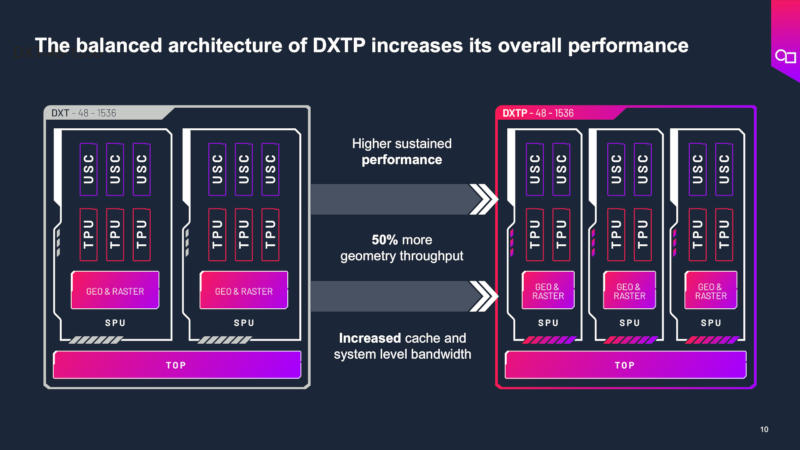 Imagination DXTP предлагает экосистему программного обеспечения, включая SDK и все необходимые инструменты. Доступны высокооптимизированные библиотеки вычислений OpenCL, которые позволяют использовать графический процессор в задачах, связанных с искусственным интеллектом, а также типовые решения для oneAPI и TensorGraph, упрощающие перенос существующего кода на архитектуру Imagination. Графические процессоры Imagination поддерживают среду LiteRT, что обеспечивает выполнение высокопроизводительных задач ИИ под Android. Для разработчиков приложений доступны инструменты PowerVR для анализа производительности на низком уровне, отладки, записи трассировки лучей; также можно задать вопросы на форуме разработчиков Imagination. Добавим, что в 2019 году лондонская Imagination анонсировала серию графики AXT, в 2020 и 2021 годах последовали соответственно BXT и CXT, а в 2023 году вышла IMG DTX. Графические процессоры Imagination появляются на рынке в составе различных однокристальных платформ примерно спустя 18 месяцев с момента анонса. |
© 1997—2025 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews. kz
![]()
![]()








 MWC 2018
MWC 2018 2018
2018 Computex
Computex


















