|
Опрос
|
реклама
Быстрый переход
У GeForce RTX 5080 тоже обнаружились бракованные чипы с недостачей блоков ROP
24.02.2025 [10:27],
Николай Хижняк
На днях Nvidia подтвердила, что некоторые видеокарты GeForce RTX 5090/RTX 5090D и RTX 5070 Ti получили дефектные графические процессоры, у которых недостаёт блоков растеризации (ROP). Компания заявила, что лишь 0,5 % видеокарт получили дефектные GPU. Как выяснилось, проблема затронула и модели RTX 5080. 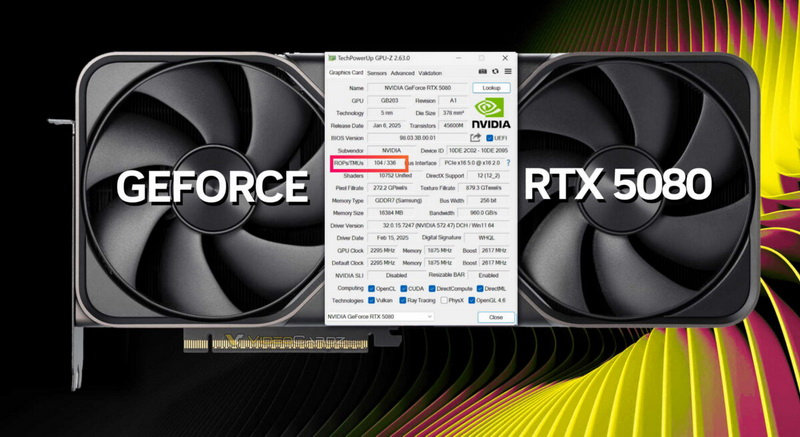
Источник изображения: VideoCardz На форуме Reddit один из пользователей поделился скриншотом утилиты GPU-Z с данными своей видеокарты RTX 5080, у которой не хватает восьми блоков растеризации. Вместо положенных 112 ROP программа показывает, что у GPU имеется только 104 блока растеризации. По словам пользователя, дефектной оказалась эталонная версия RTX 5080 Founders Edition. Любопытно, что у всех бракованных GeForce RTX 5090/RTX 5090D и RTX 5070 Ti также не хватает именно восьми блоков ROP. У GeForce RTX 5090(D) их 168 вместо положенных 176, а у GeForce RTX 5070 Ti — 88 вместо необходимых 96. 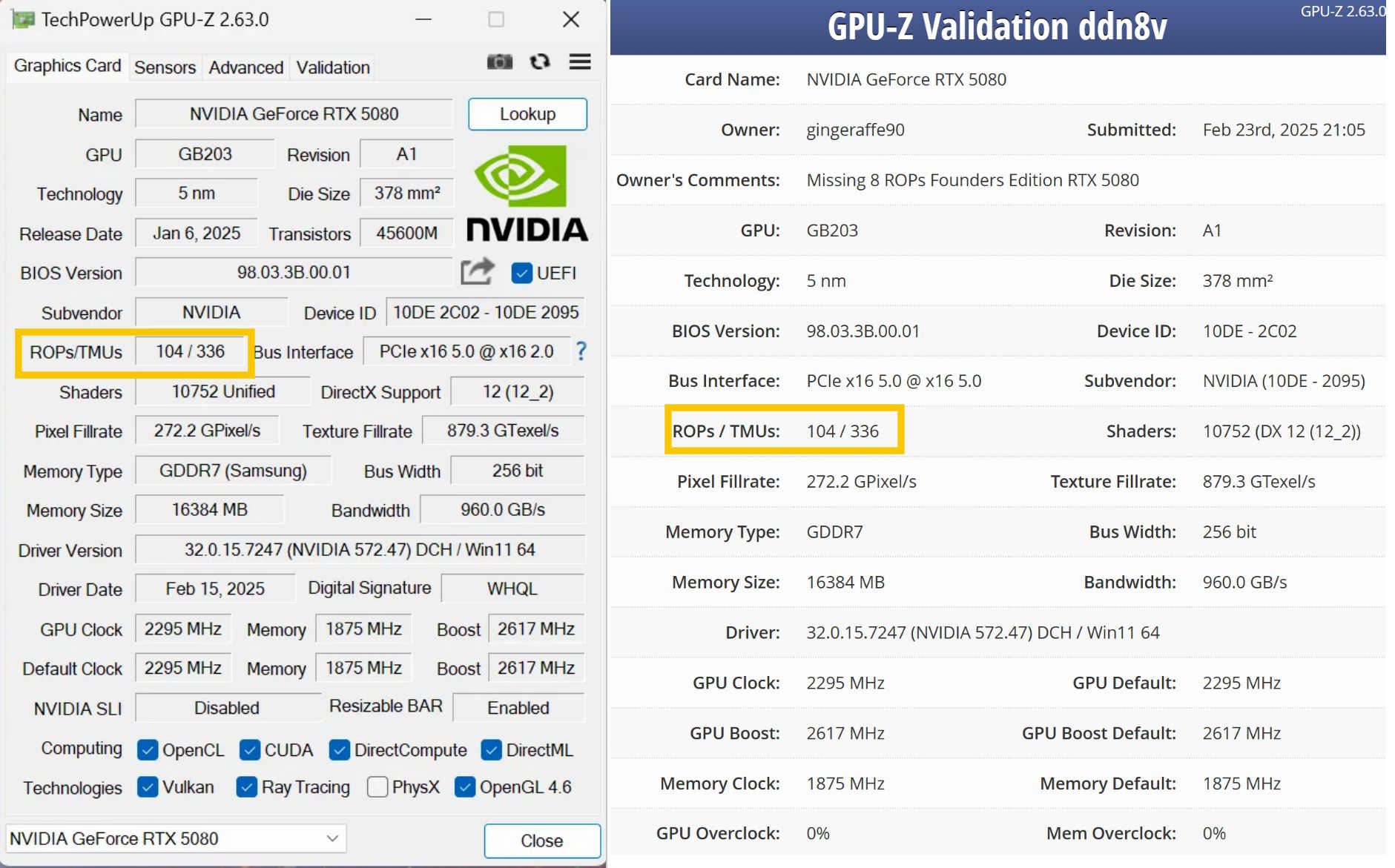
Бракованная RTX 5080. Источник изображения: Reddit / gingeraffe90 Как уже отмечалось, нехватка блоков растеризации напрямую влияет на производительность видеокарт в играх и синтетических бенчмарках. У GeForce RTX 5090/RTX 5090D дефицит ROP приводит к снижению быстродействия на 5–8 %, а у RTX 5070 Ti в синтетических тестах производительность падает до 11 % (игровые тесты пока не проводились). Насколько сильно упала производительность у дефектной RTX 5080 из-за недостатка блоков ROP, пока неизвестно. Следует добавить, что отсутствие 8 блоков ROP у RTX 5080 подтвердилось при валидации данных в GPU-Z. Владелец карты также переустановил графический драйвер, чтобы убедиться в том, что проблема не программная. Nvidia признала «редкую проблему» недостачи вычислительных блоков у GeForce RTX 5090 и RTX 5070 Ti
22.02.2025 [09:48],
Николай Хижняк
Компания Nvidia признала, что некоторые видеокарты GeForce RTX 5090/RTX 5090D, уже поставленные на рынок, оказались оснащены дефектными графическими процессорами GB202, у которых не хватает 8 блоков растеризации (ROP). Компания также сообщила, что проблема затронула и модели RTX 5070 Ti. 
Источник изображений: TechPowerUp Ранее сообщалось, что некоторые владельцы видеокарт GeForce RTX 5090/RTX 5090D от Zotac, MSI, Gigabyte и Manli пожаловались на то, что в графических процессорах их ускорителей не хватает блоков растеризации. Вместо положенных 176 ROP их карты имеют только 168 этих блоков. Поскольку ROP являются одними из ключевых компонентов видеокарты, их отсутствие негативно сказывается на производительности GPU. Тесты портала TechPowerUp показали, что Zotac GeForce RTX 5090 Solid с недостачей ROP уступает по игровой производительности даже эталонной RTX 5090 Founders Edition. Нехватка блоков ROP не связана с какой-то проблемой в работе BIOS видеокарт — речь идёт об аппаратном дефекте GPU. 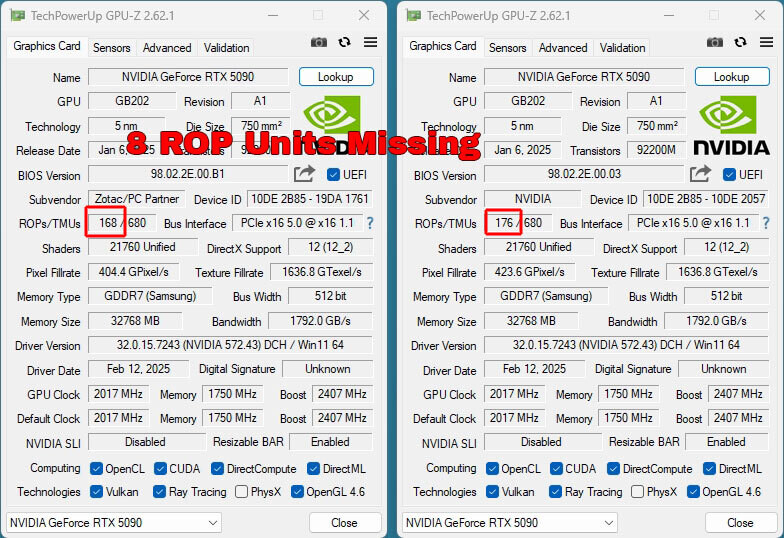 Комментарий Nvidia по поводу ситуации с дефектными GeForce RTX 5090/RTX 5090D и RTX 5070 Ti получил популярный видеоблогер JayzTwoCents: «Мы обнаружили редкую проблему, что менее 0,5 % выпущенных видеокарт GeForce RTX 5090/RTX 5090D и RTX 5070 Ti имеют меньше блоков ROP, чем заявлено в спецификациях этих моделей видеокарт. Средний уровень потери [игровой] производительности от нехватки этих блоков ROP составляет 4 %. Нехватка блоков ROP не влияет на ИИ-производительность и вычислительные возможности видеокарт. Владельцы видеокарт, столкнувшиеся с этой проблемой, должны обратиться к производителю видеокарты для замены. Производственная аномалия была устранена», — цитирует слова представителя Nvidia блогер JayzTwoCents. Компания не пояснила, о каком количестве недостающих ROP идёт речь в случае с моделями RTX 5070 Ti. Напомним, что в составе графического чипа GB203-300, служащего основой для RTX 5070 Ti, имеется 96 блоков ROP. Южная Корея закупит 10 000 ИИ-ускорителей, чтобы не отставать от остального мира
17.02.2025 [12:31],
Алексей Разин
Одним из главных событий в начале второго президентского срока Дональда Трампа (Donald Trump) стал анонс проекта Stargate, который подразумевает рекордные финансовые вливания в создание на территории США мощнейшей вычислительной инфраструктуры для ИИ. Южная Корея старается не отставать от заокеанского партнёра, а потому готова закупить 10 000 ускорителей вычислений в этом году. 
Источник изображения: Nvidia Об этом сообщает агентство Reuters со ссылкой на заявления южнокорейского президента Чхве Сан Мока (Choi Sang-mok): «Поскольку конкуренция за доминирование в отрасли ИИ усиливается, конкурентный ландшафт смещается от противостояний между компаниями к полномасштабному соперничеству между национальными экосистемами инноваций». По словам президента Южной Кореи, власти страны намереваются закупить к сентябрю этого года 10 000 GPU для использования в составе национального вычислительного центра, который будет работать над решением проблем в сфере искусственного интеллекта. Закупка ускорителей будет осуществляться в рамках частно-государственного партнёрства, но кто будет поставщиком этих GPU, не уточняется. Скорее всего, речь идёт о продукции Nvidia, ведь именно она контролирует не менее 80 % рынка данных изделий. Тем более, что Южной Корее посчастливилось оказаться в числе тех 18 стран, которые могут получать из США передовые ускорители вычислений для собственных нужд практически без ограничений. Подробные условия этой закупки будут определены к сентябрю текущего года. Высокий спрос на подобные ускорители заставляет рынок стремительно меняться. На прошлой неделе, например, стало известно о намерениях OpenAI завершить разработку собственного ИИ-чипа через несколько месяцев. Выпускать его по 3-нм технологии со следующего года может начать тайваньская компания TSMC. По меньшей мере, в рамках того же американского проекта Stargate такие ускорители OpenAI точно пригодятся. Moore Threads выпустила профессиональную видеокарту MTT X300 на мощном китайском GPU
30.12.2024 [15:21],
Анжелла Марина
Китайский производитель графических процессоров Moore Threads представил профессиональную видеокарту MTT X300, ориентированную на задачи визуализации, такие как CAD, BIM, GIS и редактирование видео. В основе новинки лежит графический процессор X300 с архитектурой MUSA второго поколения, включающий 4096 ядер MUSA и обеспечивающий вычислительную мощность 14,4 Тфлопс в FP32. 
Источник изображения: Moore Threads / @Olrak29_ on X MTT X300 использует интерфейс PCIe 5.0 x16 и предлагает достаточно разнообразные возможности подключения дисплеев: имеется три порта DisplayPort 1.4a и один HDMI 2.1, поддерживающие разрешение до 7680 × 4320 пикселей. Новинка обладает энергопотреблением (TGP) 255 Вт. При этом, как отмечает издание TechPowerUp, несмотря на позиционирование X300 в качестве новой модели, эта видеокарта, по сути, является аналогом игровой видеокарты Moore Threads MTT S80, но с изменённой прошивкой и иным набором драйверов. Видеокарта оснащена 16 Гбайт памяти GDDR6 с 256-битной шиной, обеспечивая пропускную способность памяти 448 Гбайт/с, поддерживает аппаратное ускорение декодирования для различных кодеков, включая AV1, H.264, H.265, VP8, VP9, AVS, AVS2, MPEG4 и MPEG2, а также аппаратное кодирование для AV1, H.264 и H.265. Учитывая профессиональное применение, X300 может одновременно обрабатывать до 36 потоков видео при разрешении 1080p и 30 кадрах в секунду (FPS) для операций кодирования и декодирования, а также поддерживает вывод изображения на четыре дисплея с разрешением до 8K. Примечательно, что Moore Threads разработала драйверы для всех основных архитектур, включая x86, Arm и даже LoongArch, стремясь сделать свой продукт универсальным решением для различных профессиональных задач и охватить максимально широкий спектр платформ. Хотя конкретная цена и дата начала продаж MTT X300 ещё не объявлена, её характеристики и возможности указывают на то, что она вполне может стать конкурентоспособным решением для профессионалов, работающих с графикой и видео. Продажи «урезанных» ИИ-ускорителей Nvidia в Китае растут бешеным темпом
29.12.2024 [21:34],
Анжелла Марина
После усиления санкций США компания Nvidia продолжает поставлять в Китай флагманские GPU, но в несколько урезанном виде. Спрос на созданный для Китая ускоритель вычислений HGX H20, возможности которого адаптированы в соответствии с санкционными требованиями США, ежеквартально увеличивается на 50 %, сообщает Tom's Hardware. Ускоритель HGX H20 стал в Китае настоящим хитом. 
Источник изображения: Nvidia В контексте глобального спроса на технологии искусственного интеллекта, Nvidia в последние два года испытывает большой интерес к своей продукции, особенно в США, странах Ближнего Востока и Китае. Однако из-за экспортных ограничений компания не может продавать в Китай свои самые мощные ускорители, такие как Hopper H100 и даже адаптированный прежде для Китая H800, без специальной лицензии. В ответ на эти ограничения Nvidia предложила урезанную версию — HGX H20, которая, несмотря на более скромные характеристики, быстро завоёвывает китайский рынок систем искусственного интеллекта. «Модифицированная система H20, полностью соответствующая правилам экспортного контроля для Китая, показывает невероятные результаты по продажам, подчёркивая, насколько важен для Nvidia китайский рынок, даже с учётом необходимости адаптировать продукцию под действующие ограничения», — пишет в X аналитик в сфере полупроводникового бизнеса Клаус Ошхолм (Claus Aasholm). Развитие искусственного интеллекта в мире стимулирует спрос на все типы оборудования для дата-центров, включая GPU от Nvidia. Ведущие экономики мира, США и Китай, находятся в состоянии гонки за превосходство в области ИИ, и в то время, как США используют свои ресурсы для наращивания ИИ-возможностей, Китай, несмотря на ограничения, продолжает активно развивать собственные аппаратные и программные ИИ-решения. Это подтверждается недавним достижением китайской компании Deepseek, которая успешно обучила свою языковую модель на GPU от Nvidia. В перспективе китайские компании, такие как Biren Technologies и Moore Threads, могут составить конкуренцию Nvidia на внутреннем рынке. Однако аналитики отмечают, что это не произойдёт в ближайшее время, и Nvidia продолжит доминировать в китайских дата-центрах, даже несмотря на урезанные версии своих GPU. У Nvidia нашлась ахиллесова пята — треть выручки зависит от настроения трёх клиентов
22.11.2024 [23:17],
Андрей Созинов
Компания Nvidia сильно зависит от горстки крупнейших заказчиков, которые активно покупают ускорители вычислений для задач ИИ и в совокупности приносят компании более трети дохода. Это ставит Nvidia в уязвимое положение, хотя в ближайшее время компании и её инвесторам вряд ли стоит беспокоиться — спрос на ИИ-ускорители только растёт. 
Источник изображений: Nvidia В квартальном отчёте по форме 10-Q, который компании подают в Комиссию по ценным бумагам и биржам США, Nvidia в очередной раз заявила, что у неё есть ключевые клиенты, которые настолько важны, что заказы каждого из них формируют более 10 % от глобальной выручки Nvidia. При этом компания не раскрывает имена этих клиентов, что логично, поскольку вряд ли бы они хотели, чтобы их инвесторы, сотрудники, критики, активисты и конкуренты узнали, сколько именно денег они тратят на чипы Nvidia. В отчёте за второй квартал Nvidia указала четырёх крупнейших клиентов, а в последнем квартале упоминается три таких «кита», поскольку один из них сократил закупки. Хотя доподлинно неизвестно, что это за клиенты, Мандип Сингх (Mandeep Singh), руководитель глобального отдела технологических исследований Bloomberg Intelligence, считает, что речь идёт о Microsoft, Meta✴ и, возможно, Super Micro.  Сама Nvidia называет их просто «клиент A», «клиент B» и «клиент C». Сообща они приобрели товаров и услуг на общую сумму 12,6 миллиарда долларов в третьем финансовом квартале, завершившемся в конце октября. Это более трети от общей выручки Nvidia, которая составила 35,1 миллиарда долларов. Также отмечается, что каждый из «китов» приобрёл товаров и услуг Nvidia на сумму от 10 до 11 миллиардов долларов за первые девять месяцев текущего финансового года. Примечательно, что вклад «китов» в выручку оказался равнозначным: на каждого пришлось по 12 %, что говорит о том, что они, скорее всего, закупили максимальное количество выделенных им чипов, но не столько, сколько им хотелось бы в идеале. Это согласуется с комментариями генерального директора Дженсена Хуанга (Jensen Huang) о том, что Nvidia ограничена в поставках. Компания не может просто производить больше чипов, поскольку она сама их не выпускает, а заказывает производство у TSMC, мощности которой расписаны на годы вперёд. Поскольку имена крупнейших покупателей чипов Nvidia засекречены, трудно сказать, являются ли они «посредниками», как Super Micro Computer, которая выпускает серверы для центров обработки данных, или конечными пользователями, как Microsoft, Meta✴ или xAI Илона Маска (Elon Musk). Последняя, например, практически из ниоткуда построила мощнейший ИИ-суперкомпьютер всего за три месяца.  Тем не менее полагаться на горстку крупных клиентов весьма рискованно — если кто-то из них, а ещё хуже, все разом, перестанут закупать ИИ-чипы, у Nvidia резко упадёт выручка. К счастью для инвесторов Nvidia, в ближайшее время такое маловероятно. Аналитик Bloomberg Intelligence Мандип Сингх видит лишь несколько долгосрочных рисков для Nvidia. Во-первых, некоторые крупные клиенты, вероятно, со временем сократят заказы в пользу собственных чипов, что приведёт к уменьшению доли компании на рынке. Одним из таких клиентов является Alphabet, у которой есть собственные ИИ-чипы семейства TPU. Во-вторых, Nvidia доминирует в области ускорителей для обучения ИИ, но не может похвастаться тем же в сфере чипов для инференса — запуска уже обученных нейросетей. Для инференса не требуются столь мощные чипы, что означает для Nvidia гораздо большую конкуренцию не только со стороны AMD и других прямых соперников, но и со стороны компаний с собственными чипами, таких как Tesla.  В конечном счёте запуск обученных нейросетей станет гораздо более значимым бизнесом, поскольку всё больше предприятий будут использовать ИИ, считает аналитик. «Многие компании пытаются сфокусироваться на возможностях инференса, потому что для этого не нужен самый мощный GPU-ускоритель», — заявил Сингх. Он также отметил, что в долгосрочной перспективе переход на чипы для инференса является «безусловно» большим риском для Nvidia, чем потеря доли рынка чипов для обучения ИИ. И тем не менее Сингх отмечает, что верит прогнозу Дженсена Хуанга о том, что расходы крупнейших клиентов на ИИ-чипы не прекратятся. Даже если доля Nvidia на рынке ИИ-чипов сократится с нынешних 90 %, компания всё равно сможет ежегодно зарабатывать на этом сотни миллиардов долларов. Gigabyte представила видеокарту для рабочих станций Radeon Pro W7800 AI TOP с 48 Гбайт памяти GDDR6
15.11.2024 [14:29],
Николай Хижняк
Компания Gigabyte анонсировала видеокарту Radeon Pro W7800 AI TOP для рабочих станций. Отличительная особенность новой модели от ранее выпущенной Radeon Pro W7800 заключается в объёме доступной видеопамяти. Новая модель получила 48 Гбайт GDDR6, оригинальная же Pro W7800, выпущенная AMD в прошлом году, выпускается с 32 Гбайт памяти. 
Источник изображений: Gigabyte В основе Gigabyte Radeon Pro W7800 AI TOP используется всё тот же графический чип Navi 31 на архитектуре RDNA 3 с 4480 потоковыми процессорами. Разрядность шины памяти новой модели составляет 384 бит, т.е. как у Pro W7900, которая также имеет на борту 48 Гбайт GDDR6. Пропускная способность памяти Radeon Pro W7800 AI TOP составляет 864 Гбайт/с.  Gigabyte Radeon Pro W7800 AI TOP занимает два слота расширения. Она оснащена системой охлаждения в состав которой входит центробежный вентилятор. Длина видеокарты — 29,3 см.  Gigabyte отмечает, что Pro W7800 с 48 Гбайт памяти имеет увеличенный показатель энергопотребления, составляющий 281 Вт. Это на 21 Вт больше, чем у версии с 32 Гбайт памяти и на 14 Вт меньше, чем у старшей модели Pro W7900. Для дополнительного питания новинка использует два 8-контактных разъёма. Аналогично предыдущим моделям ускорителей серии Pro W7000 карта получила три порта DisplayPort 2.1 и один mini-DisplayPort 2.1.  Предполагается, что AMD официально представит Radeon Pro W7800 с 48 Гбайт памяти в ближайшее время. Мировые продажи GPU достигнут $100 млрд в этом году — львиную долю принесут чипы, не связанные с графикой
13.11.2024 [17:25],
Владимир Мироненко
Согласно прогнозу аналитиков Jon Peddie Research, глобальный рынок графических процессоров превысит $98,5 млрд по итогам 2024 года, пишет ресурс Tom's Hardware. 
Источник изображения: Nvidia По данным JPR, на рынке сейчас присутствует семь разработчиков архитектур GPU, а также 20 компаний, занятых созданием дискретных, интегрированных и встраиваемых графических процессоров. Большинство этих решений представляют собой интегрированные GPU начального уровня, и лишь несколько компаний разрабатывают дискретные GPU для игровых видеокарт и ускорителей вычислений. Большую часть дохода на мировом рынке GPU приносят решения, которые не используются для обработки графики: в количественном выражении продажи GPU для задач ИИ и высокопроизводительных вычислений (HPC) составляют всего несколько миллионов единиц в год, но поскольку их цена составляет десятки тысяч долларов за единицу, реализация таких продуктов приносит Nvidia десятки миллиардов долларов, а AMD — миллиарды. 
Источник изображения: AMD Всего за два квартала текущего финансового года доход Nvidia от поставок GPU для ИИ и HPC составил $42 млрд, а за весь год эти цифры могут увеличиться до $90 млрд. AMD ожидает, что выручка от продажи её ИИ-ускорителей превысит $3 млрд. Если говорить о других участниках рынка, как, например, Biren или MetaX, то они пока значительно отстают по доходам от лидеров. «GPU стали повсеместными и их можно найти практически в каждом промышленном, научном, коммерческом и потребительском продукте, производимом сегодня, — сообщил доктор Джон Педди (Jon Peddie), президент Jon Peddie Research. — Некоторые сегменты рынка, такие как ИИ, попали в заголовки из-за своего быстрого роста и высокой средней цены продажи (ASP), но они имеют небольшой объём по сравнению с другими сегментами рынка». Tom's Hardware отметил, что хотя рынок GPU для ИИ имеет небольшой объём по сравнению с другими сегментами, все новички на рынке графических процессоров — особенно из Китая — сосредоточены на решениях для ЦОД, а не для игр. Конечно, эти компании сталкиваются с ограничениями со стороны правительства США, стремящегося перекрыть Китаю доступ к передовым технологиям ИИ, но, по-видимому, они готовы пойти на риск, поскольку потенциал рынка ИИ очень высок. Дорогущие ИИ-чипы страдают от быстрого износа — GPU от AMD и Nvidia выдерживают всего 1–3 года
31.10.2024 [12:57],
Алексей Разин
Пока стремящиеся активно развивать сферу искусственного интеллекта разработчики озабочены преимущественно нехваткой компонентов, некоторые из них высказываются на тему ограниченности эксплуатационного ресурса тех самых дорогих и дефицитных чипов. По расчётам специалистов Alphabet, серверные GPU при уровне загрузки 70 % живут от одного до двух лет, в крайнем случае — три. 
Источник изображения: Nvidia На это мнение ссылается Tech Fund, поясняя, что высказывание принадлежит некоему высокопоставленному разработчику систем генеративного искусственного интеллекта Alphabet, который знаком с их спецификой эксплуатации. Даже если подходить к анализу проблемы с обывательской точки зрения, логика в таких заявлениях есть. Выделяя до 700 Вт, графические процессоры Nvidia, AMD и любого другого производителя для современных ускорителей вычислений имеют довольно скромную площадь кристалла, поэтому постоянное воздействие высоких температур способно достаточно быстро приводить к их физическому износу. Продлить срок службы ускорителей вычислений можно, снизив их степень загрузки от типичных 60 или 70 %, но подобные меры натыкаются на экономические соображения разработчиков систем искусственного интеллекта. Недешёвые ускорители в условиях бурного развития отрасли должны максимально быстро приносить финансовую отдачу, а если недогружать их работой, то период амортизации затянется, а это уже не понравится инвесторам. Израильские специалисты недавно предположили, что к концу десятилетия отрасль ИИ будет ежегодно генерировать до 5 млн тонн электронных отходов. Не все из них могут быть переработаны для повторного использования, поэтому проблема воздействия отрасли искусственного интеллекта на окружающую среду становится острее. Соответственно, быстрая выработка ресурса серверных GPU тоже усугубит ситуацию с утилизацией отходов. Рынок видеокарт растёт, но без Intel — компанию полностью вытеснили AMD и Nvidia
25.09.2024 [20:12],
Анжелла Марина
Intel полностью лишилась своих позиций на рынке дискретных видеокарт, уступив свою долю Nvidia и AMD. Несмотря на общий рост рынка, продажи видеокарт Arc Alchemist оказались настолько низкими, что компания не попала в мировую отчётную статистику Jon Peddie Research. 
Источник изображения: Intel По данным JPR, продажи дискретных настольных GPU значительно выросли во втором квартале 2024 года у всех основных производителей, кроме Intel, продажи которой остались на уровне прошлого квартала. Правда, после выхода на рынок дискретных видеокарт с серией Arc Alchemist в 2022 году, компания ненадолго достигла 4-% доли рынка к концу того же года, но к началу 2024 года полностью потеряла свою долю. 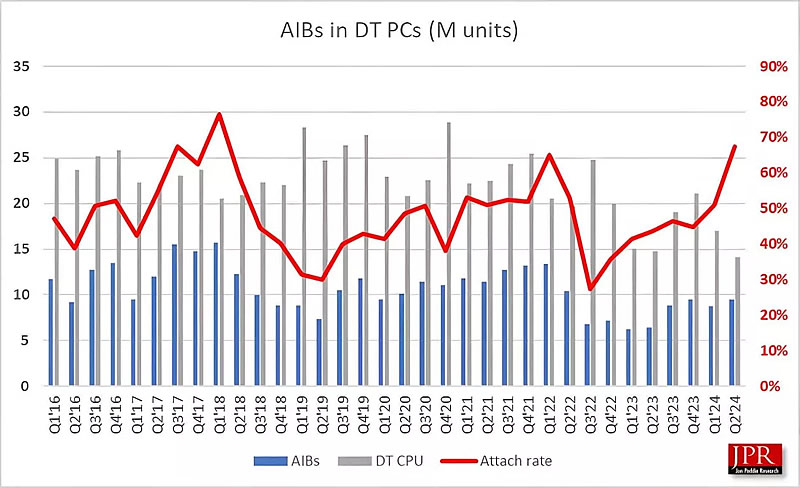
Источник изображения: techspot.com Глобальные поставки видеокарт достигли приблизительно 9,5 млн единиц, что на 9,4 % больше, чем в первом квартале 2024 года, и на 48 % больше, чем во втором квартале 2023 года. При этом король рынка Nvidia выиграл больше всех, показав квартальный рост на 9,7 % и годовой рост на 61,9 %. Что касается AMD, то её поставки хоть и увеличились всего на три процента в годовом исчислении, однако квартальный результат сравним с Nvidia. Team Red также сохранила свою 12-процентную долю рынка с первого квартала. Между тем, процессоры Intel Arc (кодовое название Alchemist) должны были стать альтернативой конкурирующим видеокартам среднего уровня. Однако задержки поставок привели к тому, что компания отстала по соотношению цены и производительности от чипов Nvidia Ampere, Ada Lovelace и AMD RDNA 3. Все три производителя GPU для дискретных видеокарт готовят новые поколения графических процессоров. Ожидается, что архитектура Blackwell от Nvidia, которая, скорее всего, будет называться RTX 5000, дебютирует на выставке CES в январе 2025 года и, вероятно, будет стоить не менее $1000. AMD может представить RDNA 4 (Radeon RX 8000) примерно в то же время, сосредоточив внимание на компонентах, которые могут значительно улучшить графические процессоры среднего уровня. Несмотря на проблемы с Alchemist, Intel, похоже, не отказывается от своих планов в отношении видеокарт Arc Battlemage. Последние новости указывают на то, что компания по-прежнему нацелена на поставки к концу 2024 года. Пока неясно, попытается ли Intel потягаться с Nvidia в сегменте high-end, где у последней сейчас нет конкурентов, или же выпустит ещё одну серию видеокарт среднего уровня. По мнению экспертов, если Intel удастся избежать задержек, которые были с Alchemist, её новые чипы могут стать одними из лучших на рынке, пусть даже и ненадолго. GPU ограничивают свободу программирования, поэтому в сфере ИИ появятся и другие чипы — Лиза Су
23.09.2024 [11:48],
Алексей Разин
Графические процессоры, первоначально созданные для построения трёхмерных изображений, неплохо проявили себя в сфере ускорения параллельных вычислений. В эпоху бурного развития систем искусственного интеллекта они оказались очень востребованы. Глава AMD Лиза Су (Lisa Su) ожидает, что лет через пять ситуация начнёт меняться, и достойное применение в сфере ИИ найдут не только GPU. 
Источник изображения: AMD Своими соображениями она поделилась с изданием The Wall Street Journal. «Сейчас GPU являются архитектурой выбора для больших языковых моделей, поскольку они весьма эффективны в параллельных вычислениях, но при этом они дают лишь ограниченную свободу программирования. Верю ли я, что они останутся предпочтительной архитектурой через пять с лишним лет? Думаю, что всё изменится», — заявила генеральный директор AMD. По её мнению, лет через пять от GPU никто отказываться не будет, но растущую популярность обретут компоненты для систем ИИ другого рода. Более узконаправленные чипы окажутся меньше, дешевле и продемонстрируют более высокую энергетическую эффективность. Примеры подобных чипов существуют уже сейчас. Облачные гиганты типа AWS (Amazon) и Google разрабатывают их для собственных нужд, используя в типовых сферах применения. GPU остаются более универсальными вычислительными средствами, но оптимизировать их энергопотребление и снизить себестоимость из-за постоянной необходимости увеличения производительности проблематично. Broadcom уже помогает Google создавать специализированные чипы, и таких примеров будет становиться только больше. Для разработчиков профильных ускорителей важно чувствовать конъюнктуру рынка и находить нужный баланс между гибкостью программирования и эффективностью работы чипов, а также обеспечивать совместимость с используемой программной экосистемой. Если специализация чипов станет узконаправленной преждевременно, это может принести разработчику большие убытки. Лиза Су добавила, что для вычислений нет универсальных решений, которые подошли бы всем. По её словам, с GPU в будущем станут соседствовать и другие архитектуры, всё просто будет зависеть от эволюции моделей. GeForce RTX 4070 с памятью GDDR6 продаётся в Европе дороже версии с GDDR6X
15.09.2024 [21:05],
Анжелла Марина
Nvidia в прошлом месяце представила видеокарту GeForce RTX 4070 с памятью GDDR6 вместо GDDR6X. Многие думали, что новинка будет слегка дешевле оригинальной модели. Но старт продаж показал ровно противоположную картину — вопреки ожиданиям GeForce RTX 4070 GDDR6 продаётся по более высокой цене, чем версия с GDDR6X, по крайней мере, в некоторых европейских странах. 
Источник изображения: Wccftech.com На данный момент самый дешёвый вариант RTX 4070 GDDR6 — Palit GeForce RTX 4070 White OC 12 Гбайт — продаётся в австрийском магазине BA-Computer за €562. Другие версии от Gigabyte, MSI и ASUS предлагаются по цене от €569 до €614. Самая дорогая Gigabyte GeForce RTX 4070 Windforce OC V2 12 Гбайт GDDR6 с тремя вентиляторами обойдётся в €614. В то же время, оригинальную RTX 4070 GDDR6X можно найти по цене от €536 (Asus Dual GeForce RTX 4070 EVO OC), а многие другие модели с GDDR6X продаются дешевле €560, что делает их явно привлекательнее новинки. 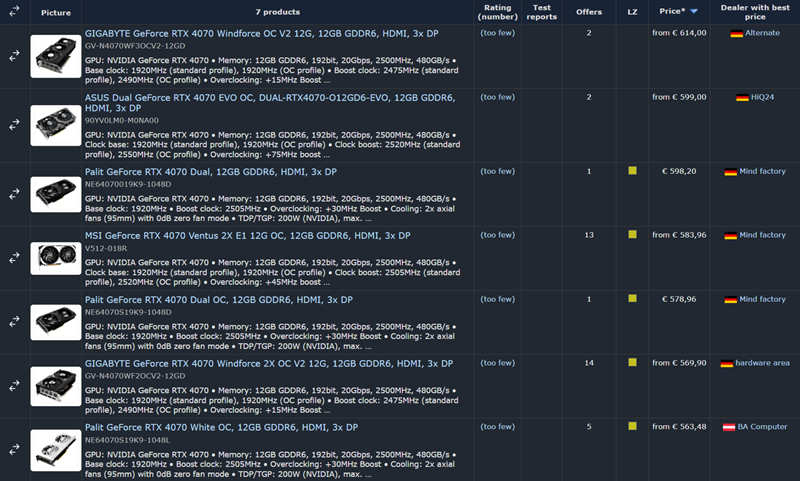
Источник изображения: Geizhals.de Отметим, что согласно первым тестам разница в производительности между двумя версиями RTX 4070 незначительна в разрешениях 1080p и 1440p, а при разрешении 4K оригинальная GeForce RTX 4070 GDDR6X оказывается быстрее примерно на 2 %, что обусловлено более высокой пропускной способностью оперативной памяти — 21 Гбит/с против 20 Гбит/с у GDDR6. 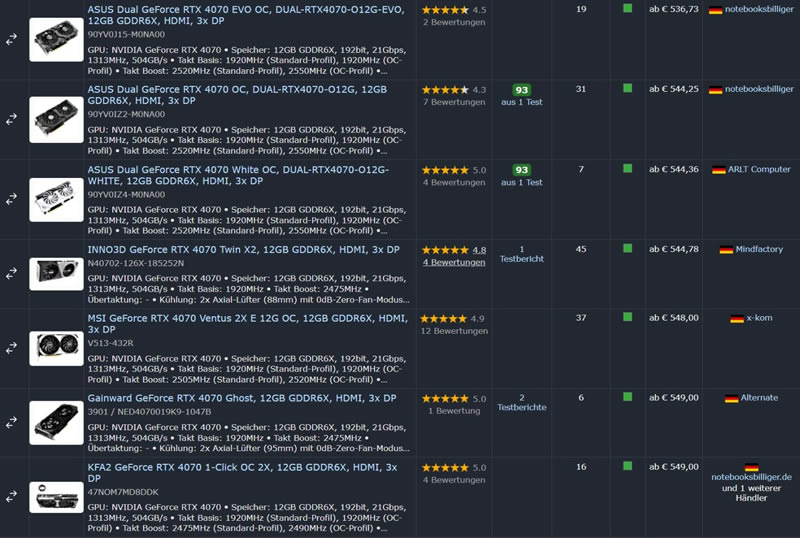
Источник изображения: Geizhals.de Вполне возможно, что в ближайшее время цены на RTX 4070 GDDR6 снизятся и сравняются с RTX 4070 GDDR6X. Однако на данный момент покупка новой версии, как пишет Wccftech, не имеет смысла, так как за те же или даже меньшие деньги можно приобрести оригинальную модель с более высокой производительностью. Кроме того, у Nvidia ещё есть версия RTX 4070 Super, которая оказывается не намного дороже, и это делает видеокарту RTX 4070 GDDR6 ещё менее привлекательной. AMD анонсировала видеокарту Radeon RX 7800M с производительностью уровня мобильной RTX 4070
11.09.2024 [11:40],
Анжелла Марина
Компания AMD опубликовала на своём сайте характеристики видеокарты Radeon RX 7800M, при этом никаких официальных заявлений или пресс-релизов AMD пока не выпустила. Новинка, оснащённая 3840 потоковыми процессорами, является одной из самых мощных мобильных видеокарт AMD и обещает производительность на уровне мобильной GeForce RTX 4070. 
Источник изображения: AMD/Videocardz.com Radeon RX 7800M основана на графическом процессоре Navi 32 с архитектурой RDNA 3 и оснащена 60 вычислительными блоками (CU), что эквивалентно 3840 потоковым процессорам. Для сравнения, старшая модель в линейке, Radeon RX 7900M, использует Navi 31 с 72 CU, а младшие модели на Navi 33 (RX 7700-7600) имеют всего 32 CU. Таким образом, новая видеокарта может заполнить пробел в производительности между существующими моделями. 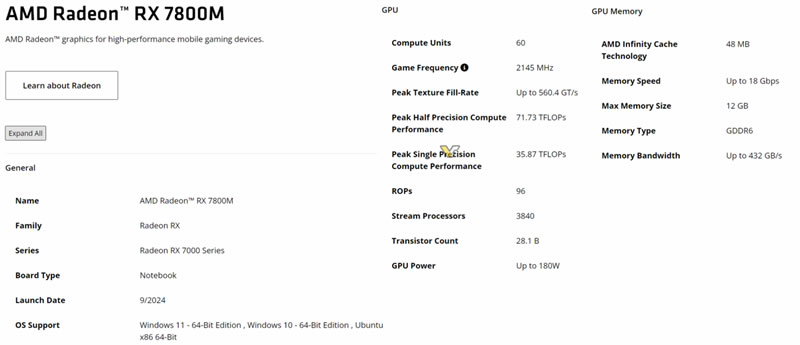
Источник изображения: AMD/Videocardz.com По конфигурации Radeon RX 7800M напоминает десктопную видеокарту RX 7800 XT, используя тот же графический процессор с 60 вычислительными блоками (CU). Однако мобильная версия получила урезанную шину памяти — 192-бит против 256-бит у десктопного варианта. Объём видеопамяти GDDR6 составляет 12 Гбайт, использованы чипы со скоростью 18 Гбит/с, обеспечивающие пропускную способность до 432 Гбайт/с. Объём кэша Infinity Cache также уменьшен с 64 Мбайт до 48 Мбайт. 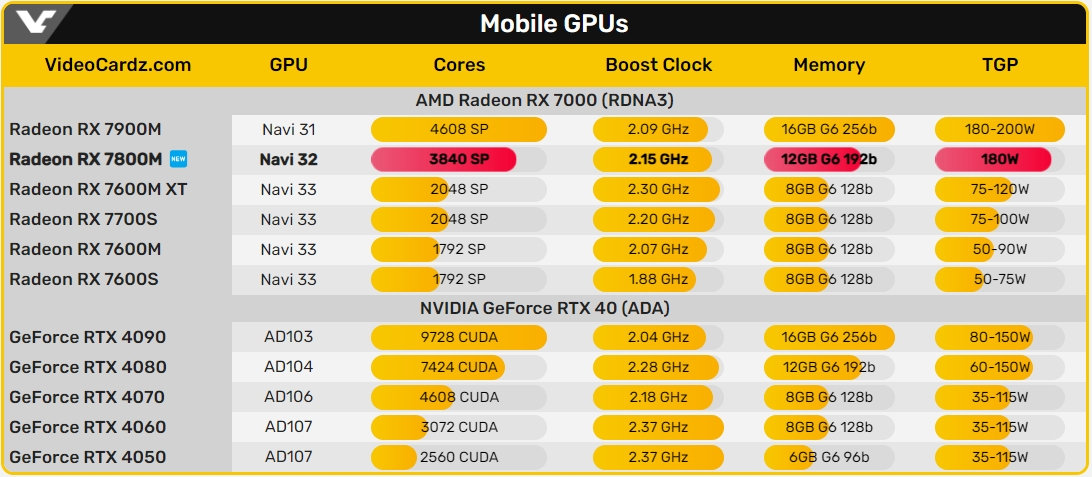 Согласно информации AMD, базовая частота графического процессора Radeon RX 7800M составляет 2145 МГц, а уровень TDP — 180 Вт, что сопоставимо с флагманской моделью Radeon RX 7900M, которая может потреблять до 200 Вт в режиме Boost. Судя по ранним утечкам, RX 7800M способна превзойти по производительности даже мобильную видеокарту NVIDIA GeForce RTX 4070, однако уступает мобильной RTX 4080. Предположительно, «тихий» запуск Radeon RX 7800M может означать ограниченную доступность видеокарты, как это было с RX 7900M, которая выпускалась очень ограниченным тиражом для определённых устройств. На данный момент известно лишь об одной модели, использующей RX 7900M — это внешняя видеокарта OneXGPU 2. Остаётся надеяться, что RX 7800M получит более широкое распространение. AMD отказалась от погони за Nvidia и сделала ставку на массовый рынок GPU
09.09.2024 [07:04],
Дмитрий Федоров
AMD изменила свою стратегию, сместив акцент с ограниченного сегмента флагманских видеокарт для энтузиастов на расширение присутствия на рынке GPU. Новая цель компании — увеличить рыночную долю с текущих 10 % до амбициозных 40–50 %. Для этого в следующей серии видеокарт AMD намерена сосредоточиться на массовом сегменте, охватывающем 80 % рынка, вместо того, чтобы конкурировать в узкой нише высокопроизводительных GPU. 
Источник изображений: AMD Пока AMD официально не подтвердила слухи об отмене разработки графического процессора Navi 41/4C, флагманского чипсета с архитектурой RDNA 4. Изначально AMD планировала бросить вызов Nvidia в высокопроизводительном сегменте, но затем, руководствуясь неназванными причинами, отказалась от этих планов. Вместо этого компания, по-видимому, сосредоточилась на разработке GPU Navi 48 и Navi 44, ориентированных на более массовый рынок. Примечательно, что названия этих GPU уже были подтверждены AMD в патчах драйверов с открытым исходным кодом и документах по отгрузке. Отвечая на вопросы журналиста Tom's Hardware на выставке IFA 2024 в Берлине, старший вице-президент и генеральный менеджер графического подразделения AMD Джек Гуинь (Jack Huynh) подчеркнул, что AMD приняла новую стратегию, радикально отличающуюся от предыдущей, и будет наращивать своё присутствие в более доступных ценовых категориях. Вероятно, это окажет влияние на архитектуру и позиционирование новой серии видеокарт Radeon RX 8000. Важно отметить, что разворот AMD в сторону массового сегмента не является беспрецедентным. Ранее компания уже дважды использовала подобный подход: сначала с серией Polaris 10/20/30, а затем с чипами первого поколения RDNA. Хотя параллельно разрабатывались и дополнительные высокопроизводительные решения, такие как RX Vega (2017 год) и Radeon VII (2019 год), лишь RX Vega смогла достичь некоторого успеха в высокопроизводительном сегменте. AMD предприняла очередную попытку вернуться в сегмент для энтузиастов с выпуском серии Radeon RX 6900, а затем и RX 7900. Обе линейки предложили конкурентоспособное соотношение цены и производительности по сравнению с сериями Nvidia GeForce RTX 30 и 40.  В ходе интервью журналист Tom's Hardware спросил Гуиня о перспективах конкуренции с Nvidia на рынке высокопроизводительных GPU. Тот подчеркнул, что AMD сейчас находится в иной рыночной позиции и активно обсуждает изменение стратегии. Он привёл в пример PlayStation 5 стоимостью $499, задаваясь вопросом о разумности быть «царём горы», если основная доля рынка лежит в другом ценовом сегменте. Гуинь сообщил, что главной задачей AMD сейчас является расширение присутствия на рынке. Он пояснил, что увеличение доли до 40–50 % позволит привлечь больше разработчиков, которые будут оптимизировать свои продукты под технологии AMD. Топ-менеджер также подчеркнул, что компания не стремится стать брендом, доступным лишь владельцам Porsche и Ferrari, а хочет создавать игровые системы для миллионов пользователей по всему миру. Гуинь заверил, что AMD продолжит разрабатывать передовые технологии и выпускать высококачественные продукты. Однако он отметил, что стратегия «царя горы», применявшаяся ещё во времена ATI (которую AMD купила в 2006 году), не принесла компании значительного роста. Теперь новый подход компании заключается в создании лучших продуктов по правильной цене, что должно обеспечить её технологическое лидерство в наиболее массовых сегментах.  На вопрос о планах выпуска флагманских GPU Гуинь не исключил возможности появления таких продуктов в будущем, но подчеркнул, что приоритетом остаётся увеличение рыночной доли AMD. Без этого привлечь разработчиков к оптимизации их продуктов под технологии AMD будет затруднительно. Гуинь отметил, что если заявить о намерении захватить лишь 10 % рынка, это не вызовет энтузиазма у разработчиков. Однако стратегия, нацеленная на достижение 40 % доли, вызывает гораздо больший интерес и готовность к сотрудничеству. Только после достижения такого масштаба AMD сможет серьёзно задуматься о конкуренции в высокопроизводительном сегменте. Несмотря на смещение фокуса, Гуинь не лишил энтузиастов надежды. Он подтвердил, что AMD продолжает работать над высокопроизводительными решениями с использованием чиплетной технологии, хотя и не назвал конкретных сроков их выхода. Напомним, что AMD уже успешно применяет чиплетную архитектуру в текущем поколении графических процессоров RDNA 3, разделяя графический процессор и кэш-память на отдельные чипы. Однако, по слухам, компания работает ещё и над разделением вычислительных блоков на отдельные чиплеты, что представляет собой чрезвычайно сложную инженерную задачу для графических процессоров из-за необходимости обеспечения сверхвысокой пропускной способности и минимальных задержек при обмене данными между чиплетами. Компания уже удивила индустрию, выпустив процессоры Ryzen с инновационным чиплетным дизайном, что позволило ей укрепить позиции на рынке CPU. Если AMD удастся повторить этот успех в сегменте графических решений, это может существенно повлиять на всю индустрию. Nvidia, долгое время доминировавшая на рынке высокопроизводительных GPU, может столкнуться с серьёзным вызовом, если стратегия AMD окажется успешной. Nvidia укрепила лидерство на рынке GPU, Intel потеряла позиции, а AMD — немного отыграла
06.09.2024 [18:49],
Дмитрий Федоров
Согласно последнему квартальному отчёту исследовательской компании Jon Peddie Research (JPR), касающемуся поставок графических процессоров (GPU), во II квартале 2024 года мировой рынок показал рост на 1,8 %. Nvidia укрепила позиции, увеличив свою долю на 2 %. Несмотря на глобальные экономические трудности, рынок графических процессоров остаётся устойчивым и даже демонстрирует потенциал для дальнейшего роста, что подтверждается прогнозами аналитиков на ближайшие годы. 
Источник изображения: LauraTara / Pixabay Так, во II квартале 2024 года было отгружено около 70 млн GPU, что говорит о заметном оживлении рынка. Особенно впечатляет рост поставок процессоров для настольных компьютеров (ПК) — +11 % в годовом исчислении. Прогнозируется, что в период с 2024 по 2026 годы совокупный среднегодовой темп прироста составит 4,2 %, а к концу 2026 года общее количество используемых GPU может достичь внушительных 3,3 млрд единиц. Важным моментом остаётся прогнозируемое JPR сохранение значительной доли дискретных графических карт в ПК. По их оценкам, в течение следующих пяти лет около 23 % ПК будут оснащены дискретными видеокартами. Годовой рост поставок GPU, охватывающий все платформы и типы процессоров, оказался на уровне 16 %. При этом наблюдается разная динамика в различных сегментах рынка: так, поставки GPU для ПК увеличились на 21 %, тогда как для ноутбуков — всего на 13 %. 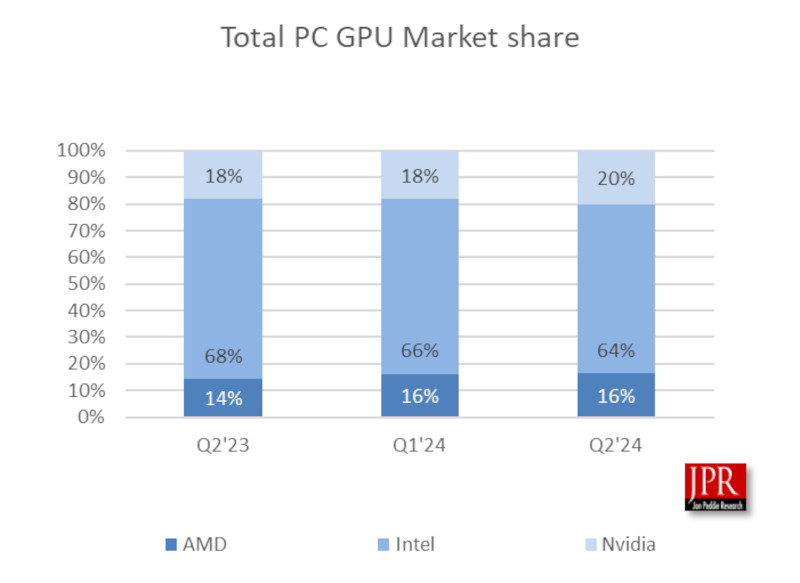
Распределение долей рынка GPU для ПК: AMD, Intel и Nvidia во II квартале 2024 года (источник: JPR, TweakTown) Доктор Джон Педди (Jon Peddie), президент JPR, в своём комментарии отметил: «Скачок поставок во II квартале стал для нас приятным сюрпризом. Рынок уже несколько лет испытывает колебания, стремясь обрести ритмичность и стабильность. Учитывая все текущие потрясения — от торговых войн до пандемии и политических кризисов — ожидать так называемую нормальность в ближайшем будущем маловероятно». Распределение долей рынка GPU между основными игроками также претерпело некоторые изменения. За три месяца AMD удалось незначительно увеличить свою долю на 0,2 %. На этом фоне Nvidia укрепила свои позиции, добавив 2 %, тогда как доля Intel уменьшилась на 2,1 %. Важно отметить, что эти данные учитывают как дискретные, так и интегрированные GPU, что и объясняет стабильные позиции Intel на рынке в целом. 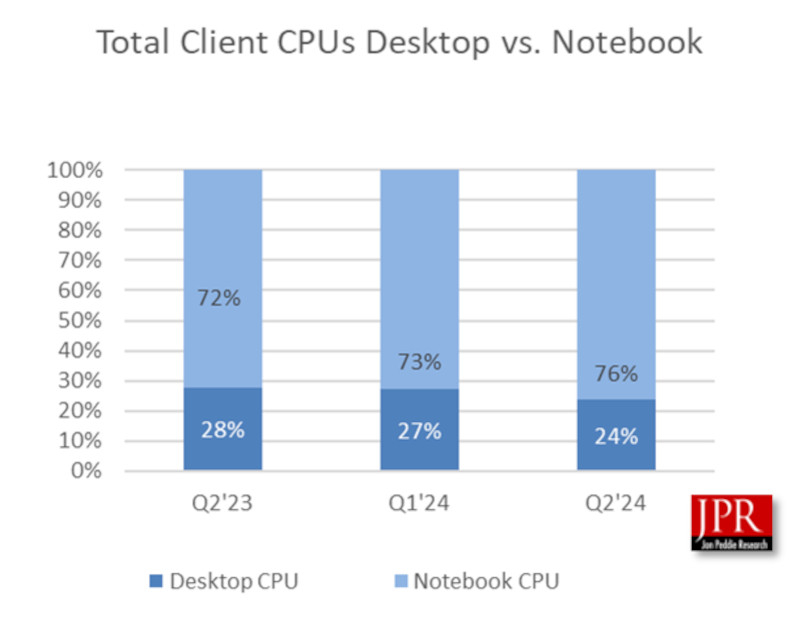
Доля процессоров для ПК и ноутбуков: динамика изменений с II квартала 2023 года по II квартал 2024 год (источник: JPR, TweakTown) JPR также представила ряд интересных статистических данных, характеризующих текущее состояние отрасли:
Эти данные подчёркивают сложную и неоднозначную динамику рынка, где квартальные колебания переплетаются с общей тенденцией к росту. Краткосрочные экономические трудности могут объяснить снижение поставок в квартальном измерении, однако годовой рост показывает более долгосрочную положительную тенденцию в индустрии GPU. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2025 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews. kz
![]()
![]()








 MWC 2018
MWC 2018 2018
2018 Computex
Computex






