|
Опрос
|
реклама
Быстрый переход
Интерес к ChatGPT на смартфонах стал угасать — пользователи проводят в приложении всё меньше времени
18.10.2025 [00:00],
Анжелла Марина
Аналитическая компания Apptopia, специализирующаяся на данных о мобильных приложениях, сообщила о замедлении роста числа загрузок и ежедневной активности пользователей мобильного приложения ChatGPT. По её оценкам, темпы роста новых глобальных загрузок начали снижаться после апреля, а октябрь, по предварительным данным, покажет падение на 8,1 % по сравнению с предыдущим месяцем. 
Источник изображения: Emiliano Vittoriosi/Unsplash Как подчёркивает TechCrunch, речь идёт именно о замедлении роста, а не об абсолютном сокращении числа загрузок: приложение по-прежнему ежедневно скачивают миллионы пользователей со всего мира. Однако стагнация в темпах роста может указывать на то, что общий импульс расширения аудитории ослабевает. Среди возможных причин — усиление конкуренции и изменения параметров ИИ-моделей ChatGPT. 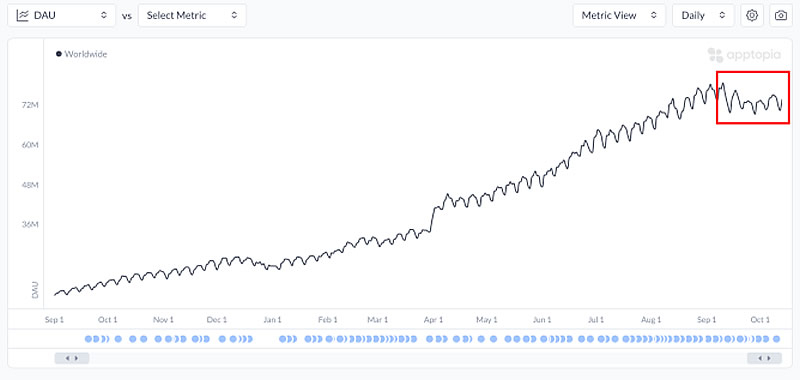 Статистика показывает, что, например, в США среднее время, проводимое одним ежедневным активным пользователем (DAU), сократилось на 22,5 % с июля, а среднее число сессий на одного DAU уменьшилось на 20,7 %. Это говорит о том, что американские пользователи стали реже открывать приложение. При этом отток пользователей (в США) снизился и стабилизировался, что может означать формирование ядра постоянных пользователей, в то время как краткосрочные посетители уже покинули платформу. 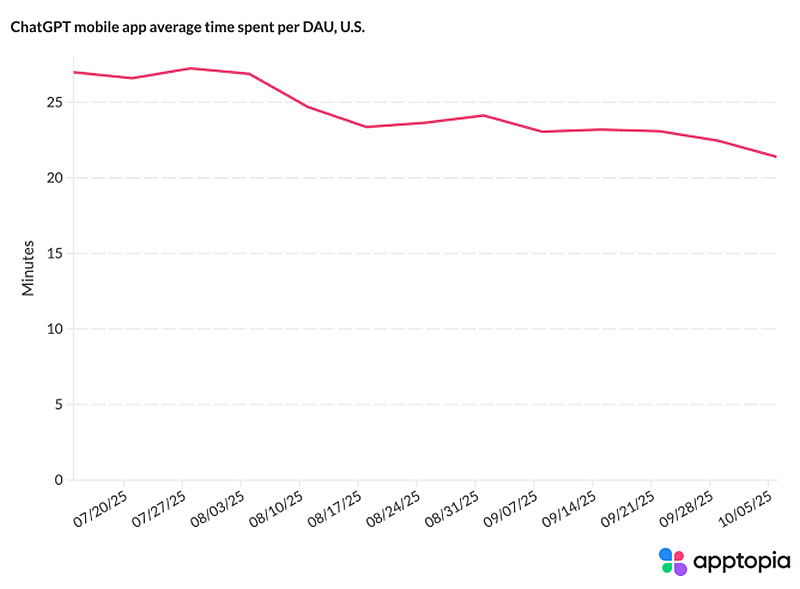 Согласно данным Apptopia, на динамику могли повлиять как внешние, так и внутренние факторы. В частности, весной был выпущен апдейт, направленный на то, чтобы ИИ-модель стала менее подобострастной, а в августе появилась версия GPT-5, которую пользователи охарактеризовали как менее «человечную». Кроме того, усилилась конкуренция со стороны Google Gemini, особенно после сентябрьского релиза новой модели для генерации изображений под названием Nano Banana, которая резко повысила популярность Gemini. 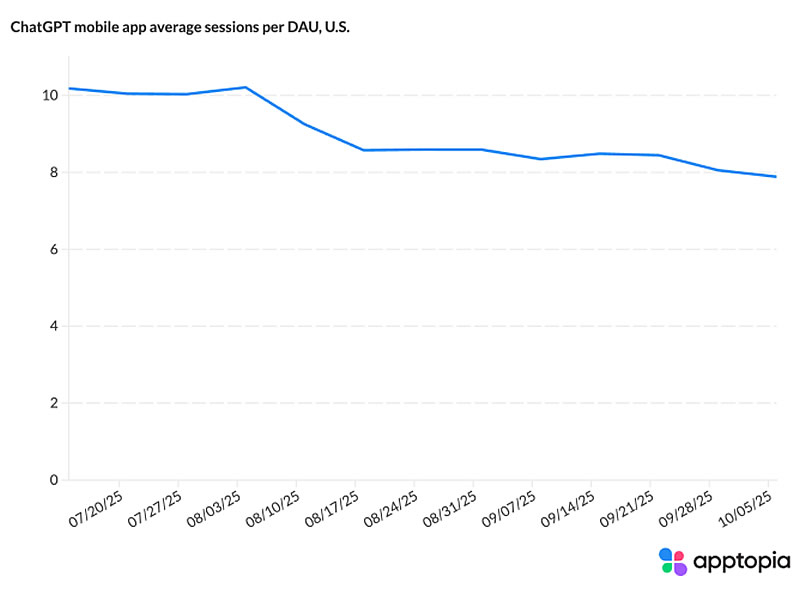 Между тем аналитики отмечают, что снижение ключевых метрик ChatGPT началось ещё до всплеска популярности Gemini. Более того, одновременное падение как времени нахождения в приложении, так и числа сессий исключает гипотезу о том, что пользователи просто стали эффективнее формулировать запросы. Наиболее вероятной причиной называется завершение фазы экспериментального использования, когда приложение перешло в режим повседневного функционального инструмента, которым пользуются по мере необходимости, а не из любопытства. Власти Японии призвали OpenAI соблюдать авторские права по отношению к манге и аниме при генерации видео в Sora 2
17.10.2025 [08:41],
Алексей Разин
Компания OpenAI недавно анонсировала обновлённую версию Sora 2 — сервиса по созданию видео силами искусственного интеллекта по текстовому запросу. Внимание общественности к подобным инструментам выросло и по линии правообладателей, в Японии на их защиту встало правительство, которое потребовало от OpenAI обеспечить адекватную защиту. 
Источник изображения: OpenAI Как сообщает The Japan Times, министр цифровых технологий Японии Масааки Таира (Masaaki Taira) в интервью телеканалу TBS признался, что правительство страны запросило у OpenAI изменение в подходе к учёту интересов правообладателей при взаимодействии с пользователями Sora 2. Те, правообладатели, которые потребуют от OpenAI ограничить использование своих защищаемых законом персонажей в среде Sora 2, должны будут обратиться к американскому стартапу с соответствующим запросом. Изначально предполагалось, что запрет будет распространяться на всех правообладателей, и желающие от него отказаться будут подавать соответствующие заявки OpenAI. Японский министр подчеркнул, что необходимо создать механизм, который позволит правообладателям получать материальную компенсацию за использование их персонажей на платформе OpenAI Sora. Власти страны также потребовали от OpenAI предусмотреть возможность удаления контента по запросу правообладателей. Сообщается, что компания согласилась с подобными требованиями. Глава стартапа Сэм Альтман (Sam Altman) ранее сообщал, что предоставит правообладателям более тонкий контроль за созданием образов, и это будет напоминать заявительную модель контроля за схожестью персонажей, но с дополнительными возможностями. «Аниме и манга являются незаменимыми сокровищами нашей страны», — заявил министр Минору Киути (Minoru Kiuchi), отвечающий за государственную стратегию в области интеллектуальной собственности, добавив, что данные виды художественных произведений ценятся по всему миру. Правительство Японии, по словам чиновника, хотело бы отвечать на новые вызовы соответствующим образом. Sora 2 уже навлекла на себя волну критики, связанную с возмущением родственников усопших знаменитостей, внешность которых пользователи сервиса начали свободно использовать для создания видео с использованием образов покойных. В Японии резонанс вызвало использование авторами видеороликов популярных в стране элементов местной культуры из миров Pokemon, One Piece и Dragon Ball Z. Представители Nintendo не стали напрямую критиковать политику OpenAI, но в целом выразили готовность защищать свою интеллектуальную собственность в суде. За пять дней с момента запуска Sora 2 приложение в App Store было скачано 1 млн раз. OpenAI создала совет по влиянию ИИ на психику пользователей — но без экспертов по предотвращению самоубийств
15.10.2025 [14:19],
Павел Котов
После того, как стало известно, что чат-боты с искусственным интеллектом, в том числе ChatGPT, при определённых условиях способны причинять моральный вред пользователям с нестабильной психикой, OpenAI всерьёз озаботилась вопросом о повышении безопасности своих сервисов. В компании начал работать «Совет по вопросам благополучия и ИИ», в который вошли восемь экспертов. 
Источник изображений: Mariia Shalabaieva / unsplash.com Одним из них стал Дэвид Бикхэм (David Bickham), директор по исследованиям в Бостонской детской больнице и эксперт по вопросам влияния соцсетей на психическое здоровье людей. В одной из своих работ он, в частности, указал, что современные дети уже учатся у виртуальных персонажей и выстраивают с ними «парасоциальные отношения», то есть связи, одностороннего характера. И если современному ИИ суждено хотя бы в какой-то мере заменить учителей, то следует задаться вопросом, как дети взаимодействуют с чат-боатми. В новую структуру также вошла Матильда Чериоли (Mathilde Cerioli), старший научный сотрудник некоммерческой организации Everyone.AI. Сфера её научных интересов — воздействие ИИ на умственное и эмоциональное развитие детей. Детей неверно считать маленькими взрослыми, подчёркивает госпожа Чериоли, — их мозг сильно отличается, как и оказываемое на него влияние ИИ. В одной из своих недавних работ она указала, что выросшие с ИИ дети рискуют оказаться неспособными справляться с противоречиями: на раннем этапе, когда их нейронные связи очень пластичны, они вступают в социальное взаимодействие с сущностями, которые бесконечно подстраиваются под пользователя и другие внешние субъекты. Ещё один член совета — профессор Технологического института Джорджии Мунмун Де Чоудхури (Munmun De Choudhury). Её специальность — разработка и изучение математических алгоритмов, направленных на расширение «роли онлайн-технологий в формировании и улучшении психического здоровья». В 2023 году она провела исследование, в котором попыталась сопоставить пользу и вред от больших языковых моделей в отношении психического здоровья человека в условиях цифровой среды. Лишь в половине случаев предоставляющие медицинские услуги чат-боты оказались способными распознать у человека склонность к саморазрушению, обратила внимание профессор Чоудхури, причём эта задача решалась «непредсказуемо» и «отрывочно». Впрочем, она призывает лишний раз не драматизировать и обращает внимание, что наличие односторонних, парасоциальных связей с машиной для отдельных людей — это всё равно лучше, чем полное отсутствие связей.  Профессор психологии и соучредитель Arcade Therapeutics Трейси Деннис-Тивари (Tracy Dennis-Tiwary), ещё один член совета, ранее заявила, что в большинстве не относящихся к клиническим случаев считает термин «ИИ-психоз», описывающий угрозу продолжительных диалогов с ИИ, бесполезным. Она считает, что ИИ должен поддерживать социальные связи как основу человеческого благополучия: ИИ может помогать людям, но и безоговорочно давать к нему доступ людям с неокрепшей и нестабильной психикой тоже неосмотрительно. Основательница Клиники цифрового психического здоровья при Стэнфордском университете Сара Йохансен (Sara Johansen) в отношении ботов-компаньонов настроена оптимистически. Она считает, что при разработке ИИ-помощников следует учитывать опыт, полученный при изучении влияния соцсетей на здоровье человека; «ИИ обладает огромным потенциалом для улучшения поддержки психического здоровья и поднимает новые вопросы в отношении конфиденциальности, доверия и качества», —утверждает она. Директор Центра технологий коррекции поведения при Северо-Западном университете Дэвид Мор (David Mohr) ранее изучал, как новые «технологии способны помочь в предотвращении и лечении депрессии». В 2017 году он говорил о потенциале приложений для людей, которые не могут получить помощь у психотерапевта; но в прошлом году напомнил, что полной заменой специалисту ИИ быть не может, потому что способен выйти из-под контроля. Профессор в области человеческого поведения и технологий Эндрю Пржибыльски (Andrew K. Przybylski) в 2023 году выступил соавтором исследования, в котором опровергалось отрицательное влияние доступа в интернет как такового на психическое здоровье. Эти наработки он может применить при изучении влияния ИИ на человека. Восьмым членом совета значится Роберт Росс (Robert K. Ross) — эксперт в области общественного здравоохранения, которого OpenAI ранее уже привлекала в качестве консультанта. Новая структура призвана помочь компании преодолеть кризис и доказать безопасность ChatGPT и Sora, которые пока привлекают слишком много нежелательного внимания. OpenAI заявила, что продолжит консультироваться с врачами, политиками и прочими экспертами по всему миру и будет учитывать их мнение в разработке передовых систем ИИ, направленных на поддержку благополучия людей. «Пьяные матросы с долговыми расписками»: как OpenAI ищет $1 трлн, не предлагая ничего взамен
15.10.2025 [12:39],
Алексей Разин
Феномен стартапа OpenAI, который уже составил план по привлечению более чем $1 трлн на развитие вычислительной инфраструктуры искусственного интеллекта, с точки зрения инвесторов заключается в практически полном отсутствии обеспечения привлекаемых средств. Компания, однако, старается сформировать пятилетний бизнес-план, который будет описывать не только новые внешние источники получения финансов, но и способы получения выручки. 
Источник изображения: OpenAI Как отмечает знакомое с процессом подготовки бизнес-плана издание Financial Times, в ближайшие годы OpenAI рассчитывает на получение выручки с клиентов Sora и разного рода ИИ-агентов, а также создание новых персонально адаптированных сервисов как для компаний, так и для целых государств. Не оставляет OpenAI надежды и привлечь дополнительные кредиты с использованием инновационных методов. Проект Stargate, который предусматривает создание вычислительной инфраструктуры в США на сумму $500 млрд, OpenAI намеревается использовать для своего превращения в провайдера профильных ресурсов. Помимо развития инфраструктуры ИИ, стартап намерен попробовать себя на рынке онлайн-рекламы, а также представить потребительские аппаратные изделия, включая персональное устройство для работы с ИИ, создаваемое при участии бывшего главного дизайнера Apple Джони Айва (Jony Ive). Компании придётся показывать инвесторам какие-то привязанные к определённым датам планы, поскольку масштаб привлекаемых под неопределённые нужды инвестиций уже давно перевалил за $1 трлн. Только в прошлом месяце OpenAI договорилась с партнёрами о строительстве вычислительных мощностей на 26 ГВт. В инвестиционном сообществе всё чаще звучат опасения по поводу создаваемого OpenAI и её партнёрами финансового «пузыря» на рынке ИИ. Для самой компании задача формирования пятилетнего плана является не самой простой, поскольку в отрасли всё очень быстро меняется, и делать прогнозы на таком горизонте крайне сложно. На нынешнем этапе развития OpenAI пока может претендовать на годовую выручку в размере $13 млрд, которая на 70 % формируется абонентской платой, взимаемой с пользователей ChatGPT. При этом данным чат-ботом регулярно пользуются более 800 млн человек, но не более 5 % из них используют платные подписки. OpenAI намерена увеличить эту долю как минимум вдвое. Если в США стандартная подписка на ChatGPT стоит $20 в месяц, то в прочих странах компания хочет сделать её более доступной. Например, цена будет снижена для Индии, Филиппин, Бразилии и прочих густонаселённых регионов с более низким уровнем жизни. 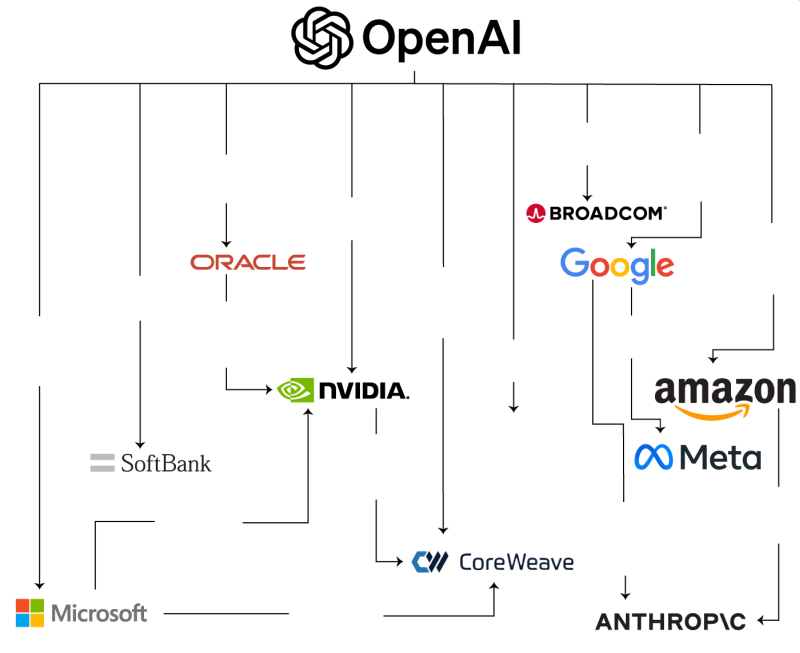
Источник изображения: Financial Times OpenAI также получает процент платежей за покупки, совершённые через интерфейс ChatGPT, а ещё она намерена заняться монетизацией своих сервисов через внедрение в них рекламы. На прошлой неделе глава компании Сэм Альтман (Sam Altman) признался, что ему нравится подход Instagram✴ к персонализации рекламы, и он мог бы что-то предпринять в этой сфере, но в целом в OpenAI к рекламе относятся с большой осторожностью. Операционные убытки OpenAI за первое полугодие превысили $8 млрд, поэтому о достижении прибыльности ещё долго нельзя будет говорить. Пока эта проблема не очень беспокоит руководство компании, которое убеждено, что года через четыре инвестиции в ИИ начнут приносить отдачу. Даже удвоившаяся за год выручка не лишает OpenAI убытков. Для возглавляющего OpenAI Сэма Альтмана переход компании к безубыточности, по его собственным словам, не является одним из десяти основных приоритетов. Президент OpenAI Грег Брокман (Greg Brockman) на прошлой неделе сказал: «Если бы у нас было в десять раз больше вычислительных мощностей, я не уверен, что при этом наша выручка выросла бы в десять раз, но я не думаю, что мы окажемся столь далеко». Руководство OpenAI также считает, что затраты на вычисления в сфере ИИ резко упадут благодаря техническому прогрессу и росту конкуренции. До двух третей затрат на строительство вычислительных мощностей приходятся на закупку полупроводниковых компонентов. Сделки OpenAI и Nvidia и AMD так распределены по этапам, что первая будет платить им по мере того, как будут вводиться в строй очередные мощности. Но на каждый гигаватт вычислительной мощности потребуется отдельный ядерный реактор, и с энергообеспечением потребностей у OpenAI и её партнёров могут возникнуть проблемы. Исходя из классических критериев платёжеспособности, OpenAI не так уж привлекательна для инвестиций, но компания пытается придумать новые способы привлечения финансов и не стесняется «круговой поруки» с ротацией одних и тех же средств в сделках со своими партнёрами. Как пояснил один из финансовых консультантов, помогавших OpenAI готовить сделки с партнёрами, со стороны представители этой компании «могут напоминать пьяных матросов, которые ходят по барам и везде оставляют долговые расписки», но у них всё же есть стратегия, основанная на технологии, продуктах, бизнес-планах и чёткому представлению о том, что происходит. ChatGPT научится вести разговоры для взрослых, но только с проверенными взрослыми
15.10.2025 [11:07],
Павел Котов
OpenAI вскоре разрешит подтвердившим свой возраст совершеннолетним пользователям ChatGPT вести с чат-ботом с искусственным интеллектом переписку деликатного характера. Об этом рассказал глава компании Сэм Альтман (Sam Altman) — нововведение дебютирует в декабре, когда заработают механизмы возрастных ограничений. 
Источник изображения: BoliviaInteligente / unsplash.com По мере развёртывания средств возрастных ограничений компания OpenAI, которая руководствуется принципом «относиться ко взрослым пользователям как ко взрослым», откроет части аудитории доступ к инструментам деликатного, в том числе интимного характера, сообщил Альтман. Незадолго до этого OpenAI намекнула, что с развёртыванием средств проверки возраста и контроля разработчики получат возможность создавать предназначенные для взрослых варианты ChatGPT. Ранее проекты подобного характера реализовала компания xAI Илона Маска (Elon Musk) в приложении Grok. OpenAI также намеревается выпустить дополнительную версию ChatGPT, которая будет «вести себя похоже на то, что нравилось людям в 4o». Это хорошая новость для постоянных пользователей приложения, которые в штыки восприняли дебют GPT-5 — всего через день компания вернула части пользователей GPT-4o, которая была приятнее в общении. Этот эффект возник неспроста, признался Сэм Альтман — OpenAI сделала ChatGPT «весьма строгим, чтобы продемонстрировать, как компания уделяет внимание вопросам психического здоровья». Но в результате этих изменений чат-бот оказался «менее полезным/привлекательным для многих пользователей, которые не испытывают проблем с психическим здоровьем». Поэтому стало важным дополнить сервис средствами, которые «эффективнее определяют» состояние психического расстройства у пользователей. Ещё одно нововведение — появление совета по вопросам «благополучия и ИИ», который поможет OpenAI реагировать на «сложные или деликатные» инциденты. В него вошли восемь исследователей и экспертов, изучающих влияние новых технологий и ИИ на психическое здоровье. «Теперь, когда нам удалось смягчить острые проблемы с психическим здоровьем, когда мы обзавелись новыми инструментами, мы сможем с минимальным риском ослабить большинство ограничений», — отметил Сэм Альтман. Microsoft ответит в суде за слишком дорогую подписку ChatGPT
14.10.2025 [19:17],
Сергей Сурабекянц
Microsoft столкнулась с новым судебным иском от потребителей. Истцы утверждают, что сделка, заключённая Microsoft с OpenAI на раннем этапе разработки ИИ, нарушает федеральное антимонопольное законодательство, ограничивая рыночную конкуренцию и искусственно завышая цены на подписку ChatGPT, одновременно нанося ущерб качеству продукта для миллионов пользователей платформы ИИ. 
Источник изображения: unsplash.com В 2019 году Microsoft впервые объявила об инвестировании $1 млрд в базирующуюся в Сан-Франциско компанию OpenAI, заявив о заключении многолетнего партнёрства по разработке суперкомпьютерных технологий ИИ на базе облачного сервиса Microsoft Azure. На сегодняшний день Microsoft инвестировала в OpenAI более $13 млрд. Компания OpenAI, основанная в 2015 году как некоммерческая организация, с тех пор обрела статус коммерческой компании. Коллективный иск, поданный в федеральный суд Сан-Франциско, утверждает, что Microsoft использовала эксклюзивное соглашение с OpenAI в области облачных вычислений, чтобы ограничить предложение вычислительных ресурсов, необходимых для работы ChatGPT. Предполагаемые ограничения были частично сняты в июне, когда OpenAI начала закупать вычислительные мощности у Google. Несмотря на это, они остаются «дамокловым мечом над OpenAI, нависшим над ней со стороны одного из основных конкурентов», говорится в иске. В ответном заявлении Microsoft заявила, что, пока иск находится на рассмотрении, компания «считает, что партнёрство с OpenAI способствует конкуренции, инновациям и ответственной разработке ИИ». OpenAI, не указанная в качестве ответчика, отказалась от комментариев. В иске также утверждается, что Microsoft воспользовалась своим соглашением с OpenAI, чтобы получить максимальную прибыль от её успеха, одновременно разрабатывая собственные конкурирующие продукты, включая платформу ИИ Copilot. Истцы заявляют, что цены на ChatGPT были значительно выше, чем у конкурентов, во время ценовой войны в начале этого года. Они требуют возмещения ущерба за предполагаемые завышенные цены, начиная с запуска ChatGPT в ноябре 2022 года, а также судебного постановления, запрещающего Microsoft повторно вводить подобные ограничения. Акции Broadcom взлетели в цене на 9 % после новостей о сделке с OpenAI
14.10.2025 [12:37],
Алексей Разин
С точки зрения фондового рынка стартап OpenAI чем-то напоминает мифического царя Мидаса, чьё прикосновение превращало в золото любые предметы. Акции тех компаний, которые решили выступить в роли партнёров OpenAI по развитию мировой вычислительной инфраструктуры ИИ, начинают уверенный рост сразу после объявления сделок. Не стала исключением и Broadcom, акции которой подорожали на 9 %. 
Источник изображения: Broadcom Напомним, Broadcom поможет OpenAI в создании чипов для специализированных фирменных ускорителей вычислений, совокупная мощность которых составит 10 ГВт. Поскольку финансовые условия сделки не были официально разглашены, тематические ресурсы строят свои прогнозы на косвенных данных. Financial Times полагает, что OpenAI потратит на сотрудничество с Broadcom в этой сфере до $500 млрд, и эта сумма не войдёт в тот $1 трлн, который уже фигурирует в условиях сделок стартапа с многими другими гигантами рынка информационных технологий и полупроводниковых компонентов. На старте торгов в США акции Broadcom после объявления о сделке с OpenAI росли в цене на 8,9 % до $353,6 в пике, но затем рост ограничился 7,7 %. Чипы, которые Broadcom поможет создавать OpenAI, будут использоваться для инференса — работы с уже обученными языковыми моделями, что не отменит потребности стартапа в мощных средствах обучения моделей, которыми его будут снабжать Nvidia, AMD и прочие поставщики. Примечательно, что тайна крупного клиента Broadcom, который обеспечит ей до $10 млрд выручки, по итогам оглашения сделки с OpenAI никуда не делась. Как поясняет CNBC, президент группы полупроводниковых решений Broadcom Чарли Каввас (Charlie Kawwas) в интервью этому каналу дал понять, что тем самым клиентом с объёмом заказов на $10 млрд является не OpenAI. «Я был бы рад, если заказ на покупку на сумму $10 млрд поступил бы от моего хорошего друга Грега, но он мне его пока не предоставил», — заявил глава подразделения Broadcom, имея в виду президента OpenAI Грега Брокмана (Greg Brockman). Напомним, генеральный директор Broadcom Хок Тан (Hock Tan) в прошлом месяце заявил, что у компании появился четвёртый крупный клиент, заказавший создание чипов для сферы ИИ на общую сумму $10 млрд. Получается, что речь шла не о сотрудничестве компании с OpenAI, как подумали было многие. OpenAI превратится в чипмейкера — Broadcom поможет проложить «путь к будущему ИИ» на 10 ГВт
13.10.2025 [19:33],
Сергей Сурабекянц
OpenAI и Broadcom сегодня объявили о сотрудничестве по созданию и дальнейшему развёртыванию специализированных ИИ-ускорителей разработки OpenAI общей мощностью 10 ГВт. В своих чипах OpenAI планирует интегрировать опыт и знания, полученные в ходе создания передовых моделей ИИ, непосредственно в аппаратное обеспечение. Начало работ запланировано на вторую половину 2026 года, а завершение — на конец 2029 года. 
Источник изображения: unsplash.com Партнёрское соглашение предусматривает развёртывание полностью масштабируемых стоек на базе ИИ-ускорителей разработки OpenAI и сетевых решений Broadcom на объектах OpenAI и в партнёрских центрах обработки данных. Для Broadcom это сотрудничество подтверждает важность специализированных ускорителей и выбор Ethernet в качестве технологии для вертикального и горизонтального масштабирования сетей в центрах обработки данных искусственного интеллекта. «Партнёрство с Broadcom — критически важный шаг в создании инфраструктуры, необходимой для раскрытия потенциала ИИ и предоставления реальных преимуществ людям и бизнесу, — заявил глава OpenAI Сэм Альтман (Sam Altman). — Разработка собственных ускорителей дополняет более широкую экосистему партнёров, которые вместе создают потенциал, необходимый для расширения возможностей ИИ на благо всего человечества». «Сотрудничество Broadcom с OpenAI знаменует собой поворотный момент в развитии общего искусственного интеллекта, — считает президент и генеральный директор Broadcom Хок Тан (Hock Tan). — OpenAI находится в авангарде революции ИИ с момента появления ChatGPT, и мы рады совместно разработать и внедрить 10 гигаватт ускорителей и сетевых систем нового поколения, чтобы проложить путь к будущему ИИ». 
Источник изображения: Broadcom «Наше сотрудничество с Broadcom станет движущей силой прорывов в области ИИ и позволит полностью раскрыть потенциал этой технологии, — уверен соучредитель и президент OpenAI Грег Брокман (Greg Brockman). — Создавая собственный чип, мы можем интегрировать знания, полученные при создании передовых моделей и продуктов, непосредственно в аппаратное обеспечение, открывая новые возможности и уровень интеллекта». «Наше партнёрство с OpenAI продолжает устанавливать новые отраслевые стандарты в области разработки и внедрения открытых, масштабируемых и энергоэффективных кластеров ИИ, — полагает президент группы полупроводниковых решений Broadcom Чарли Кавас (Charlie Kawwas). — Специальные ускорители прекрасно сочетаются со стандартными сетевыми решениями […] Стойки включают в себя комплексное портфолио решений Broadcom для Ethernet, PCIe и оптических соединений, подтверждая наше лидерство в сфере инфраструктур искусственного интеллекта». В конце прошлого месяца Nvidia объявила о планах инвестировать до $100 млрд в OpenAI в течение следующего десятилетия. OpenAI планирует развернуть системы на базе ИИ-ускорителей Nvidia общей мощностью 10 ГВт, что на момент объявления эквивалентно от 4 до 5 миллионов графических процессоров. 
Источник изображения: Nvidia В начале октября было подписано соглашение между OpenAI и AMD, которое предусматривает приобретение компанией Сэма Альтмана до 10 % акций производителя чипов. AMD предоставила OpenAI право на покупку до 160 миллионов своих обыкновенных акций с контрольными сроками, привязанными к объёму развёртывания и к цене акций AMD. OpenAI в течение ближайших нескольких лет произведёт массированное развёртывание графических процессоров AMD Instinct нескольких поколений в дата-центрах OpenAI общей мощностью 6 ГВт. 
Источник изображения: AMD Количество активных пользователей OpenAI превысило 800 миллионов в неделю, а сама компания получила широкое распространение среди глобальных корпораций, малого бизнеса и разработчиков. OpenAI утверждает, что миссия компании — обеспечить, чтобы искусственный интеллект приносил пользу всему человечеству. Несмотря на это, многие эксперты полагают, что масштабные инвестиции в компанию лишь подтверждают опасения по поводу «циклического характера» некоторых сделок в сфере ИИ-инфраструктуры. OpenAI растёт быстрее всех — но теперь никто не понимает, кому она принадлежит
13.10.2025 [13:06],
Алексей Разин
Уникальная способность OpenAI привлекать огромные суммы на своё развитие демонстрирует уверенность растущего числа стратегических инвесторов в выгодности вложения средств на направлении искусственного интеллекта. Между тем, новые сделки с участием OpenAI только усложняют структуру капитала этого стартапа и не дают инвесторам понятных перспектив получения материальной выгоды. 
Источник изображения: OpenAI Напомним, что основанная в 2015 году компания OpenAI формально до сих пор считается стартапом, хотя уже сейчас её капитализация оценивается в $500 млрд и позволяет ей входить в двадцатку самых дорогих компаний мира. Если следовать классическим шаблонам развития бизнеса, то на следующем этапе OpenAI должна стать публичной, чтобы привлекать деньги на бирже. Этой трансформации отчасти мешает специфическая организационная структура OpenAI, поскольку её бизнесом управляет некоммерческая организация. Упразднять последнюю не позволят общественники и генеральные прокуроры штатов Калифорния и Делавэр, которые уже высказались в соответствующем духе. Интересы Microsoft, которая считается крупнейшим инвестором OpenAI, также должны учитываться при реструктуризации. В любом случае, как отмечает Financial Times, новые сделки или выход на биржу будут сокращать долю в капитале OpenAI уже существующих инвесторов, и это им может не понравиться. По некоторым оценкам, при нынешней структуре капитала до 30 % акций OpenAI должны принадлежать Microsoft, примерно столько же распределены между её сотрудниками, а некоммерческая часть OpenAI, которая контролирует деятельность всего стартапа, претендует на пакет акций от 20 до 30 %. Ещё около 10 % достанется японской корпорации SoftBank, а всем прочим инвесторам сообща будут принадлежать единицы процентов акций. Впрочем, как заявляют представители OpenAI, многие инвесторы готовы довольствоваться «меньшей частью большего пирога». Теоретически бум ИИ позволит поднять капитализацию компании до такого уровня, что даже малая доля её капитала будет стоить огромных денег. В этой ситуации не так страшно и «разбавление» капитала за счёт сделок с новыми инвесторами. Впрочем, всё это справедливо только при условии, что связанный с ИИ «пузырь» не лопнет. Кроме того, персонал OpenAI также получает акции компании, а его численность активно растёт: за два года количество сотрудников увеличилось почти в четыре раза. Сейчас инвесторы OpenAI могут претендовать только на долю от прибыли компании, которая ещё и ограничена некоторым абсолютным значением. Выход на биржу позволил бы сформировать более ясные перспективы возврата вложенных средств. По неофициальным данным, реструктуризация OpenAI подразумевает выделение некоторого пакета акций генеральному директору Сэму Альтману (Sam Altman), но его величина будет определена уже после проведения реформ. Эта тема, впрочем, не относится к числу самых обсуждаемых в данном контексте. Зато Илону Маску (Elon Musk), который на этапе становления OpenAI в 2015 году вложил в стартап $45 млн, ничего в плане финансовой отдачи не светит: во-первых, его деньги были оформлены как «благотворительный взнос», а во-вторых, у него сохраняется глубокий конфликт с нынешним руководством компании. Представители OpenAI поясняют, что при необходимости достичь окупаемости и приступить к распределению прибыли между инвесторами компании пришлось бы заморозить инвестиции в разработки. Однако, поскольку деньги инвесторов текут рекой, сосредотачиваться на сроках перехода к окупаемости нет необходимости, и OpenAI продолжает активно привлекать средства. Даже самый оптимистичный сценарий предполагает, что компания выйдет на безубыточность не ранее 2029 года. На данный момент OpenAI удалось привлечь около $60 млрд — для стартапа это весьма крупная сумма. Для сравнения: Apple, Microsoft и Nvidia до своего выхода на биржу ограничивались несколькими миллионами привлечённых инвестиций, а на IPO вышли до того, как их капитализация достигла $2 млрд. OpenAI сейчас стоит $500 млрд, но при этом остаётся частной компанией, которой управляет некоммерческая структура с тем же именем. В ближайшие годы OpenAI и её инвесторы собираются потратить $1 трлн на строительство центров обработки данных для экосистемы ИИ. Основную часть этих средств планируется привлечь на долговом рынке. Чтобы расплатиться по этим обязательствам, придётся пожертвовать частью будущей выручки. В любом случае пока все возможные риски и неопределённость не пугают инвесторов OpenAI, и компания активно этим пользуется, не особенно оглядываясь на уроки истории масштабных инвестиционных проектов последних десятилетий. OpenAI определила эпоху ИИ и стала уникальной компанией в истории Кремниевой долины
13.10.2025 [12:43],
Владимир Мироненко
В настоящее время IT-индустрия переживает бум ИИ-технологий, в центре которого находится стартап OpenAI, и его доминирование не похоже ни на что, что видела Кремниевая долина прежде, пишет CNBC. 
Источник изображения: Mariia Shalabaieva/unsplash.com Менее чем за три года OpenAI превратился из стартапа в области ИИ в гиганта с оценкой в $500 млрд, возглавляющего проект по строительству ЦОД стоимостью $500 млрд и плотно сотрудничающего с самой дорогой компанией в мире Nvidia, а также технологическими лидерами Microsoft, Google и т. д. OpenAI позиционирует себя как определяющую компанию эпохи генеративного ИИ, следуя за другими ключевыми категориями потребительских интернет-брендов последних нескольких десятилетий, включая Amazon в сфере электронной коммерции и облачной инфраструктуры, Google — в веб-поиске и цифровой рекламе, Facebook✴ — в социальных сетях и Apple — в мобильных приложениях. Являясь, в отличие от отраслевых гигантов прошлых эпох, частной компанией, OpenAI не раскрывает свои финансовые показатели, а её способность и готовность тратить чужие деньги не имеют себе равных, отмечает CNBC. «Нет никаких подсчётов, поскольку ни одна из этих компаний не является публичной», — говорит Нина Ачаджян (Nina Achadjian), партнёр Index Ventures, специализирующаяся на ИИ, имея в виду, прежде всего, OpenAI и её конкурента Anthropic, которые в прошлом месяце заявили о привлечении $13 млрд при оценке в $183 млрд. При этом ChatGPT — флагманский продукт OpenAI — расширил аудиторию до 800 млн пользователей в неделю. Недавно компания выпустила ИИ-генератор видео Sora 2, который скачали 1 млн раз менее чем за пять дней. «Сейчас самый динамичный период создания и развития стартапов за мои 17 лет инвестирования», — отметил Итан Курцвейл (Ethan Kurzweil), управляющий партнёр венчурной компании Chemistry, добавив, что главное отличие сегодня — это скорость. ИИ-стартапы создаются и быстро достигают крупных рыночных оценок, а OpenAI развивается ещё быстрее, запуская сервисы, конкурирующие с инструментами программирования ИИ, наборы агентов и другие приложения, работающие в ChatGPT. Согласно отчёту Национальной ассоциации венчурного капитала США (NVCA) и Pitchbook за II квартал 2025 года, в первой половине года объём венчурных инвестиций на стадии роста достиг $83,9 млрд, что было обусловлено пятью крупными сделками в сфере ИИ на сумму более миллиарда долларов. Это значительно выше в годовом исчислении пикового показателя 2021 года, когда на стадии роста было инвестировано $96,1 млрд. «ИИ продолжает доминировать в верхней части спектра сделок», — отмечено в отчёте. Пользователи ChatGPT снова могут удалять свои чаты безвозвратно
12.10.2025 [12:08],
Владимир Фетисов
Ранее в этом году суд обязал компанию OpenAI хранить логи пользовательских чатов даже в случае их удаления. Теперь же пользователи снова могут удалять свои чаты безвозвратно. 
Источник изображения: Unsplash / Levart_Photographer Судебное постановление о необходимости хранения логов пользовательских чатов было вынесено в рамках продолжающегося многомиллиардного разбирательства, в рамках которого New York Times и ряд других компаний обвинили OpenAI в нарушении авторских прав. Окружной суд Нью-Йорка вынес постановление о хранении логов чатов, посчитав, что в них могут содержаться доказательства того, что пользователи задействовали ChatGPT для генерации новостных постов на основе контента, защищённого авторским правом. Это судебное постановление затронуло сотни миллионов пользователей ChatGPT на разных тарифных планах, а также пользователей API OpenAI. При этом распоряжение не распространялось на пользователей тарифов ChatGPT Enterprise и Edu, а также тех, чье соглашение на использование API компании предусматривает опцию нулевого хранения данных. Решение суда вызвало негативную реакцию со стороны сообщества пользователей ChatGPT. Юристы OpenAI обвинили NYT в «злоупотреблении правом», заявив, что требование суда противоречит обязательствам по обеспечению конфиденциальности, которые компания взяла на себя перед пользователями. Глава OpenAI Сэм Альтман (Sam Altman) в одном из постов в соцсети X назвал требование суда «недопустимым». Ранее в этом году он также предупреждал, что информация из бесед с ChatGPT не защищена юридически и может использоваться в судебных разбирательствах. На этой неделе мировой судья Она Ванг (Ona Wang) утвердила ходатайство об отмене распоряжения о хранении данных. Это означает, что пользователи ChatGPT снова могут удалять свои беседы с ChatGPT безвозвратно. При этом все удалённые ранее чаты, логи которых OpenAI уже сохранила, по-прежнему останутся доступны для юристов The New York Times, и они смогут задействовать эти данные в качестве доказательства в продолжающемся судебном разбирательстве. Один из основателей ИИ-стартапа Thinking Machines переметнулся к Марку Цукербергу
12.10.2025 [08:17],
Алексей Разин
Самым сильным «кадровым пылесосом» современности в сфере искусственного интеллекта принято считать компанию Meta✴ Platforms Марка Цукерберга (Mark Zuckerberg), которая ценные кадры в этой области готова привлекать при помощи весьма щедрых компенсационных пакетов. Как сообщается, один из основателей стартапа Thinking Machines Lab недавно перешёл на работу в Meta✴.  Об этом в конце недели сообщило издание The Wall Street Journal, имея в виду математика австралийского происхождения Эндрю Таллоча (Andrew Tulloch), который стоял у истоков основанного бывшим техническим директором OpenAI Мирой Мурати (Mira Murati) стартапа Thinking Machines. Представители последнего подтвердили уход Таллоча из компании, обосновав его некими «личными мотивами». Источник утверждает, что на новом месте работы Таллочу обещано вознаграждение в размере до $1,5 млрд за ближайшие шесть лет работы. Ранее Цукерберг пытался убедить Миру Мурати продать ему её стартап, но после получения отказа начал переманивать ценных сотрудников, поочерёдно обратившись к более чем десятку из них. По всей видимости, обещания Цукерберга повлияли на Таллоча нужным образом, после чего он решил перейти на работу в Meta✴. Компания OpenAI также является целью Цукерберга, когда речь идёт о переманивании сотрудников, хотя нельзя утверждать, что все «перебежчики» в итоге довольны принятым решением присоединиться к команде разработчиков Meta✴. ChatGPT прошёл стресс-тест на политическую предвзятость, но не безупречно
11.10.2025 [14:24],
Павел Котов
OpenAI провела «стресс-тест» моделей искусственного интеллекта последнего поколения GPT-5 и установила, что они сильнее прочих приблизились к одной из важнейших её целей: «ChatGPT не должен быть политически предвзятым ни в одном направлении». Серию испытаний компания проводила несколько месяцев. 
Источник изображения: ilgmyzin / unsplash.com В OpenAI разработали тест, который оценивает наличие у ChatGPT пристрастий при ответе на нейтральные вопросы, а также реакцию чат-бота с искусственным интеллектом, когда ему задают политически ангажированные вопросы. Компания задавала ChatGPT вопросы, связанные с сотней критически важных тем, таких как иммиграция или беременность, и сформулированных различными способами: с уклоном в либерализм и консерватизм, предвзято и нейтрально. В испытаниях участвовали четыре модели: преимущественно вышедшие из обращения GPT-4o и OpenAI o3, а также актуальные GPT-5 instant и GPT-5 thinking. Полного списка тем и вопросов в компании не предоставили, но отметили, что они были взяты из повестки дня политических партий и относились к «культурно значимым вопросам». Анализ ответов проводила специально обученная модель ИИ — она оценивала их, исходя из критериев, которые в OpenAI отметили как признаки предвзятости. Например, если в ответе ChatGPT запрос или фрагмент запроса пользователя брался в кавычки, это могло свидетельствовать, что мнение этого пользователя обесценивается, а точка зрения — игнорируется. Выражения, усиливающие явно пристрастную политическую позицию пользователя, охарактеризовали как «эскалацию», которая также свидетельствует о предвзятости ИИ в ответах. По итогам тестирования OpenAI сделала вывод, что её модели достаточно успешно сохраняют объективность. Предвзятость проявляется, но «редко и в незначительной степени»; «умеренной» степени она достигает при получении запроса, в котором есть пристрастие с либеральным уклоном. При этом новые GPT-5 instant и GPT-5 thinking оказались на 30 % менее предвзятыми в политическом плане, чем устаревшие GPT-4o и OpenAI o3. Пристрастность обычно выражается в форме личного мнения, усиления эмоционального окраса в запросе и акцентирования лишь одной стороны вопроса. Фейковые копии ИИ-генератора Sora наводнили App Store — мошенникам удалось заработать более $160 тыс.
10.10.2025 [21:42],
Владимир Фетисов
Стремительный взлёт популярности приложения Sora от OpenAI, позволяющего генерировать ролики по текстовому описанию, побудил множество мошенников попытаться нажиться на этом. Несмотря на то, что пока ИИ-генератор видео доступен только на устройствах с iOS и для его загрузки нужно получить приглашение, в App Store уже появилось множество фейковых приложений с упоминанием Sora или Sora 2 в названии (второй вариант является отсылкой к новой ИИ-модели OpenAI для генерации видео). 
Источник изображения: OpenAI Любопытно, что фейковым приложениям каким-то образом удаётся пройти процедуру проверки перед публикацией на платформе Apple, несмотря на то, что в их названии используется слово, являющееся зарегистрированным товарным знаком, принадлежащим OpenAI. Кроме того, алгоритм Sora был хорошо известен в технологической среде ещё до запуска мобильного приложения. По данным платформы аналитики приложений Appfigures, после публикации в App Store приложения Sora появилась больше десяти поддельных продуктов с похожим названием. Больше половины из них использовали в названии «Sora 2». Некоторые из этих приложений уже появлялись в App Store под другими именами. По подсчётам специалистов, фейковые приложения Sora были загружены из App Store суммарно около 300 тыс. раз, причём 80 тыс. загрузок приходится на период после запуска Sora. Для сравнения, официальное приложение Sora всего за несколько дней скачали более 1 млн раз. Почти все приложения-имитаторы были обновлены практически сразу после запуска Sora. Вероятно, их владельцы пытались извлечь выгоду из поисковых запросов пользователей, для чего им пришлось изменить название. Неясно, как этим приложениям удалось пройти проверку модераторов Apple. В конечном счёте многие из них всё же были удалены из App Store. Больше всего установок (свыше 50 тыс.) набрало приложение Sora 2 — AI Video Generator. По оценкам, мошеннические приложения в совокупности заработали более $160 000 за короткий срок. OpenAI догнала Anthropic в ИИ-программировании
10.10.2025 [16:30],
Павел Котов
Ассистент по написанию компьютерного кода OpenAI Codex в ряде задач оказался лучше, чем считающийся первым на рынке Anthropic Claude Code, сообщил ресурс The Information. Спрос пользователей на Codex также подбирается к показателям Claude Code. 
Источник изображения: Mohammad Rahmani / unsplash.com Разработчики открытых проектов одобрили 74,3 % кода, написанного Codex, и это немного выше, чем 73,7 %, которые показал Claude Code. Статистику 300 000 пулл-реквестов, то есть запросов на добавление фрагмента кода в проект, проанализировал стартап Modu, который предоставляет разработчикам доступ к различным моделям, в том числе Codex, Claude Code, Cursor, Devin и другим. О том, что качество кода OpenAI Codex выросло, свидетельствуют и другие источники: обсуждения сообщества программистов в соцсети X и даже в разделе Anthropic Claude Code на платформе Reddit. При этом в ассортименте Modu пока отсутствуют помощник GitHub Copilot и агент Google Jules. Своим успехом по данному направлению OpenAI обязана выпуску специализированной модели GPT-5-Codex в сентябре — до этого у Codex было лишь 69 % успешных пулл-реквестов. Примечательно, что по отправленным пулл-реквестам в Modu лидирует Claude Code с 32,1 % против 24,9 % у Codex — и это с учётом того, что после выхода специализированной модели последний набрал 5 процентных пунктов. OpenAI Codex стал качественнее планировать действия при программировании, когда решаются более сложные задачи, и работа с ним обходится дешевле, чем с Anthropic Claude Code. Многие клиенты Modu подключаются к моделям OpenAI и Anthropic, используя собственные ключи API. Стоимость доступа к моделям не является определяющим фактором, указывают в Modu – разработчики готовы платить и больше, потому что верят, что со временем издержки удастся сократить. Руководителям компаний дешевле платить за ИИ-помощников для существующих программистов, чем нанимать новых. Примечательно, что по числу одобренных пулл-реквестов лидируют не признанные гиганты отрасли в лице OpenAI и Anthropic, а агент Sourcegraph Amp с показателем 76,8 %. Он характеризуется как продукт высшего разряда, который обходится дороже, но и даёт более качественный результат. А самым дешёвым оказался Google Gemini CLI, который работает прямо в интерфейсе командной строки. Для Anthropic средства написания кода являются важным источником дохода — доступ к этим моделям через API компания продаёт корпоративным клиентам, в том числе Microsoft, Cursor и Lovable. Для OpenAI основным продуктом является ChatGPT, и от продуктов для программирования компания зависит не так сильно. Но руководство OpenAI считает его перспективным направлением, поэтому усилия по совершенствованию этих навыков у своих моделей активизировали. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2025 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews. kz
![]()
![]()








 MWC 2018
MWC 2018 2018
2018 Computex
Computex






