|
Опрос
|
реклама
Быстрый переход
OpenAI задумалась о переезде из Калифорнии, чтобы избавиться от чрезмерной бюрократии
09.09.2025 [14:57],
Алексей Разин
По информации The Wall Street Journal, намеченная реструктуризация OpenAI натыкается на препятствия не только в виде пересмотра договорённостей с Microsoft, но и разного рода бюрократические сложности на уровне властей Калифорнии. Теперь некоторые источники предлагают OpenAI перерегистрироваться в другом штате, чтобы облегчить как реструктуризацию, так и дальнейшее ведение бизнеса. 
Источник изображения: OpenAI Напомним, что преобразование в коммерческую структуру важно для привлечения будущих инвестиций в капитал OpenAI, поскольку действующая организационная форма стартапа подразумевает главенство некоммерческого фонда и ограничение на участие инвесторов в распределении прибыли. При этом амбициозные планы OpenAI предусматривают увеличение расходов на десятки миллиардов долларов в год, и справиться без поддержки инвесторов компания будет просто не в состоянии. В Калифорнии, как поясняет источник, уже находятся активисты, которые пытаются защитить существующую организационную структуру OpenAI, которая управляется некоммерческой организацией. Для этого планируется призвать на помощь законодательство Калифорнии и правозащитников. Власти Калифорнии формально имеют право обязать OpenAI выплатить штраф за отказ от своей формально некоммерческой миссии в случае реструктуризации. Дело усложняется тем, что OpenAI уже начала привлекать средства инвесторов под обещания будущей реструктуризации, и если она не состоится, то компании придётся вернуть до $19 млрд инвесторам, которые ранее ей доверились. Руководство OpenAI изначально не рассчитывало, что заявления о планах по реструктуризации привлекут столько внимания общественности. Расследование со стороны генерального прокурора Калифорнии является источником особого беспокойства для OpenAI. Если прокурор штата будет препятствовать реструктуризации компании, то она может рассмотреть вариант переезда в другой штат для смены юрисдикции. Основная часть исследователей в сфере ИИ у OpenAI сосредоточена в районе Сан-Франциско. Перенос штаб-квартиры в другой штат будет затруднителен по многим причинам. На протяжении всего лета представителям OpenAI приходилось принимать участие в общественных слушаниях, на которых выступали активисты и представители других некоммерческих организаций. В итоге компания взяла на себя обязательства направить $50 млн на поддержку локальных организаций некоммерческого профиля. Именно под давлением противников реструктуризации OpenAI к маю этого года сформировала концепцию преобразований, которая не подразумевала бы полный отказ от главенства некоммерческой организации. Власти штата призывают OpenAI к ответственному развитию искусственного интеллекта, но видят со стороны компании ориентированность на извлечение прибыли в ущерб гуманитарным целям. OpenAI пытается удовлетворить запросы прокуратуры штата компенсирующими мерами, но давление возрастает, и стартап в итоге может решиться на переезд из Калифорнии. Часть оппозиции считает, что OpenAI использует свою некоммерческую структуру для снижения налоговой и регуляторной нагрузки, высказывая опасения, что подобному примеру могут последовать другие компании. Растущее количество противников реструктуризации вынуждает OpenAI задумываться об отчаянных мерах типа смены юрисдикции. В своё время Илон Маск (Elon Musk) перенёс штаб-квартиру Tesla из Калифорнии в Техас, сославшись на свои противоречия с властями первого из штатов. Многие эксперты указывали тогда, что Маск мог руководствоваться банальным стремлением сэкономить на налогах. Соцсети заполонили боты: Сэм Альтман пожаловался, что интернет стал искусственным из-за ИИ
09.09.2025 [13:14],
Павел Котов
Сегодня стало невозможно определить, действительно ли публикации в соцсетях пишут люди, или это делают чат-боты с искусственным интеллектом, пожаловался в соцсети X глава компании OpenAI Сэм Альтман (Sam Altman). 
Источник изображения: Mariia Shalabaieva / unsplash.com Альтман обратил на это внимание, когда изучал на платформе Reddit сообщения, посвящённые сервисам написания программного кода при помощи ИИ — Anthropic Claude Code и OpenAI Codex. Пользователи сетевого сообщества создали в нём столько тем о своём переходе с Claude Code на Codex, что Альтман задумался, сколько из этих публикаций создали реальные люди. Он отметил несколько тенденций, из-за которых написанные человеком и ИИ посты становится отличать друг от друга всё труднее. Люди и сами всё чаще начинают копировать языковой стиль ИИ, в результате чего граница между ними размывается в обе стороны. Блогеры и энтузиасты, которые проводят в сети чрезвычайно много времени (Extremely Online), стали действовать сообща, одновременно публикуя схожие материалы, потому что к этому их подталкивают алгоритмы соцсетей. Это проявляется, например, в стандартных циклах трендов: сначала новые продукты встречаются с воодушевлением, которое в одночасье сменяется столь же единодушной критикой; а также в том, что большинство авторов в соцсетях в погоне за монетизацией публикуют эксцентрические посты, за которыми всё меньше просматривается искренность. 
Источник изображения: ilgmyzin / unsplash.com В умелых руках все эти механизмы обращаются в «астротурфинг» — имитацию общественной поддержки того или иного мнения, — и этот эффект со стороны конкурентов OpenAI, отметил господин Альтман, довелось испытать на себе. Одним из его проявлений глава компании назвал шумиху вокруг не самого удачного запуска флагманской большой языковой модели GPT-5. Вскоре после её выхода Альтман провёл на Reddit серию вопросов и ответов, в которой признал наличие некоторых проблем, но не смог восстановить прежний уровень доверия. «В итоге возникает ощущение, что ИИ-Twitter и ИИ-Reddit стали какими-то неестественными, чего год или два назад не было», — пожаловался глава OpenAI. Установить долю написанных ИИ публикаций на Reddit действительно непросто, но она может оказаться значительной: если верить материалам исследования, проведённого специализирующейся на вопросах кибербезопасности компанией Imperva, в 2024 году более половины всего интернет-трафика создал не человек, и дело здесь преимущественно в ИИ-моделях. По одной из версий, Альтман обратился к этому вопросу потому, что OpenAI готовит собственную соцсеть, но едва ли и она сможет гарантировать, что на этой платформе тоже массово не заведутся боты с ИИ. В следующем году выйдет полнометражный мультфильм Critterz, созданный с помощью OpenAI и её ИИ
08.09.2025 [13:21],
Алексей Разин
Генеративный искусственный интеллект получил первую часть своего названия благодаря способности создавать целые произведения искусства, поэтому в кинопроизводстве подобные технологии должны найти своё место. По крайней мере, так считает OpenAI, помогающая создать полнометражную анимационную ленту Critterz, которая выйдет на экраны в следующем году. 
Источник изображения: Critterz.tv По мнению The Wall Street Journal, участие в данном кинопроекте позволит OpenAI показать деятелям кинематографической отрасли, что ИИ позволяет быстрее и дешевле создавать соответствующую продукцию. Принято считать, что персонажи Critterz являются детищами Чэда Нельсона (Chad Nelson), который в OpenAI отвечает за творческие процессы и решения. Эскизы персонажей будущего полнометражного мультфильма Нельсон начал создавать ещё три года назад. Первоначально эти герои потребовались для создания анимированной короткометражки с помощью DALL-E. Сейчас представитель OpenAI скооперировался с компаниями из киноиндустрии, расположенными в Лондоне и Лос-Анджелесе, чтобы к майскому кинофестивалю в Каннах представить полнометражный анимационный фильм. Время работы над картиной сокращено с привычных трёх лет до девяти месяцев, и это является определённым вызовом для участников процесса, которые будут сильно полагаться на генеративный искусственный интеллект. Более того, на создание фильма выделено всего $30 млн, что также определяет выбор инструментария для работы над анимационной картиной. Над созданием детальных эскизов персонажей будут работать профессиональные художники, а голосами с ними поделятся живые актёры, но дальнейшая обработка этих «входных данных» будет поручена нейросетям. Над сценарием фильма также поработали опытные специалисты. В общей сложности над созданием анимационной картины работают около 30 человек, что по меркам отрасли не так много. В случае успеха Critterz компания OpenAI сможет заявить, что ИИ теперь может использоваться киностудиями для создания фильмов, а также открыть дорогу на большие экраны начинающим командам, не располагающим существенными ресурсами и бюджетом. Насколько активно OpenAI будет вовлечена в продвижение фильма в прокате, пока не уточняется. OpenAI после критики GPT-5 реорганизовала команду, отвечающую за поведение ИИ
07.09.2025 [00:29],
Анжелла Марина
OpenAI провела реорганизацию своей команды Model Behavior, отвечающей за поведенческие характеристики ИИ-моделей компании. Команда будет интегрирована в более крупный подраздел Post Training, а её основатель Джоанн Джанг (Joanne Jang) возглавит лабораторию под названием OAI Labs по разработке принципиально новых форматов взаимодействия человека и искусственного интеллекта (ИИ). 
Источник изображения: сгенерировано AI Согласно служебной записке, которой ознакомилось издание TechCrunch, главный научный сотрудник OpenAI Марк Чэн (Mark Chen) сообщил, что команда Model Behavior, насчитывающая около 14 исследователей, теперь будет подчиняться руководителю отдела Post Training Максу Шварцеру (Max Schwarzer). Представитель компании подтвердил факт реорганизации. Эта команда отвечала за формирование «личности» моделей и в частности, за снижение подобострастия, когда ИИ безоговорочно поддерживал мнение пользователя, даже если они были потенциально вредны, а также за балансировку политических предубеждений в ответах и участие в формировании позиции компании по вопросам «сознания» моделей. Чэн пояснил, что объединение команд позволит сбаллансировать работу над поведением моделей с ядром их технической разработки. В последние месяцы OpenAI столкнулась с волной критики после обновления GPT-5, так как пользователи сочли его ответы ИИ слишком недружелюбными. В ответ компания вернула доступ к предыдущим версиям, включая GPT-4o, и выпустила обновление, призванное сделать ответы модели «теплее», при этом избежав заискивания и подобстрастия. Серьёзность проблемы подчёркивает и судебный иск от родителей подростка, которые обвинили ChatGPT на базе GPT-4o в том, что тот не смог пресечь суицидальные мысли их 16-летнего сына. Джанг в свою очередь отметила, что на раннем этапе работы OAI Labs будет фокусироваться на исследовании моделей, выходящих за рамки чата с акцентом на агентный ИИ и автономию. Она видит будущие системы как инструменты для мышления, создания, игры, обучения и общения. На вопрос о возможном сотрудничестве с бывшим главным дизайнером Apple Джони Айвом (Jony Ive), который сейчас работает с OpenAI над линейкой аппаратных устройств, Джанг ответила, что открыта к разным идеям, но начнёт с областей, в которых уже имеет опыт. OpenAI в ближайшие несколько лет потратит на свою инфраструктуру $115 млрд
06.09.2025 [07:39],
Алексей Разин
Поскольку OpenAI до сих пор считается стартапом, информацией о предстоящих расходах и доходах компания делится с немногочисленными инвесторами в довольно приватной обстановке. Изданию The Information недавно удалось выяснить, что в период с 2025 по 2029 годы включительно OpenAI намерена потратить $115 млрд вместо первоначально запланированных $35 млрд. 
Источник изображения: Unsplash, Дима Соломин Уже сейчас OpenAI является одним из крупнейших в мире арендаторов облачных вычислительных мощностей, поэтому заметную часть этих расходов составляет плата за аренду ЦОД и счета за электроэнергию. Чтобы снизить расходы в этой сфере, OpenAI как раз собирается наладить выпуск чипов для ускорителей вычислений собственной разработки и заняться строительством ЦОД. В текущем году OpenAI рассчитывает потратить более $8 млрд вместо заложенных в прогноз ранее примерно $6,5 млрд. В следующем году расходы более чем удвоятся до $17 млрд, а относительно прежнего прогноза они вырастут на $10 млрд. В 2027 году расходы компании составят $35 млрд, а в 2028 году увеличатся до $45 млрд. В целом, в период с 2025 до 2030 годы включительно OpenAI собирается направить на поддержание и развитие своей вычислительной инфраструктуры не менее $150 млрд. Более того, она предупредила инвесторов, что стоимость разработки ИИ-моделей оказывается выше ожидаемой. OpenAI хочет создать платформу для поиска работы в сфере ИИ
05.09.2025 [13:07],
Алексей Разин
Искусственный интеллект пригоден для обработки больших массивов информации, и с этой точки зрения витрина маркетплейса или доски объявлений мало чем отличается от сайтов по поиску работы. OpenAI намеревается создать собственную платформу для поиска работы и подбора персонала, задействовав фирменные технологии искусственного интеллекта. 
Источник изображения: Gabrielle Henderson / Unsplash Как отмечает CNBC, подобная платформа станет конкурентом для социальной сети LinkedIn, которая помогает профессионалам и работодателям взаимодействовать на выгодных условиях. Пока проект носит рабочее название OpenAI Jobs Platform. Реализация данной инициативы позволит OpenAI составить конкуренцию Microsoft ещё на одном направлении деятельности, поскольку LinkedIn принадлежит последней из корпораций. По замыслу представителей OpenAI, новая платформа для работы с вакансиями поможет решить проблему дефицита кадров не только крупным компаниям, но и малому бизнесу. Кроме того, правительственные организации также смогут найти подходящих специалистов в области ИИ с её помощью. Сервис должен быть введён в строй к середине следующего года. Попутно OpenAI запустит фирменную программу обучения и сертификации, которая позволит выпускникам корпоративной академии лучше применять ИИ в своей профессиональной деятельности. В OpenAI Academy свою квалификацию смогут повысить представители самого разного уровня. Чат-бот ChatGPT в режиме обучения будет применяться для взаимодействия со слушателями курсов. До 2030 года OpenAI собирается выдать 10 млн фирменных сертификатов гражданам США. Обе инициативы помогут специалистам лучше адаптироваться к меняющимся из-за распространения ИИ условиям на рынке труда. OpenAI выпустит свой первый ИИ-чип в 2026 году при поддержке Broadcom — последней это сулит $10 млрд
05.09.2025 [05:29],
Алексей Разин
Слухи о намерениях OpenAI представить чип для ускорения вычислений в системах ИИ получили новую жизнь на этой неделе, поскольку компания Broadcom открыто призналась в заключении контракта с таинственным новым клиентом на поставку подобных чипов на общую сумму $10 млрд. Данные чипы выйдут в следующем году. 
Источник изображения: Broadcom Издание Financial Times подтвердило, что Broadcom помогла OpenAI разработать профильный чип, и на рынок он выйдет в 2026 году. Вторая из компаний собирается использовать этот компонент для собственных нужд и не предлагать сторонним клиентам. Сотрудничество с Broadcom в этой сфере началось ещё в прошлом году. До этого момента не было известно, когда начнётся массовое производство данного изделия. Для Broadcom стартап OpenAI станет уже четвёртым по счёту клиентом, для которого она разработала ИИ-чип. Акции Broadcom после этих заявлений в сочетании с в целом позитивной отчётностью выросли в цене на 4,5 %. Компания сотрудничала с Google при разработке специализированных тензорных процессоров последней. По мнению аналитиков HSBC, следующий год будет характеризоваться ростом продаж специализированных ИИ-чипов, тогда как универсальные решения типа предлагаемых Nvidia уже не смогут продемонстрировать высокой динамики роста выручки. Глава OpenAI Сэм Альтман (Sam Altman) в прошлом месяце выразил готовность увеличить вычислительные мощности компании вдвое за ближайшие пять месяцев. Функция Projects в ChatGPT стала доступна бесплатным пользователям
04.09.2025 [12:05],
Антон Чивчалов
Компания OpenAI предоставила бесплатным пользователям ChatGPT доступ к функции Projects, которая раньше предлагалась только платным подписчикам. Projects — «проекты» — позволяют распределять разговоры с ИИ по темам, настраивать запросы, ограничивать доступ к данным, выбирать визуальное оформление и т. д., сообщает Engadget. 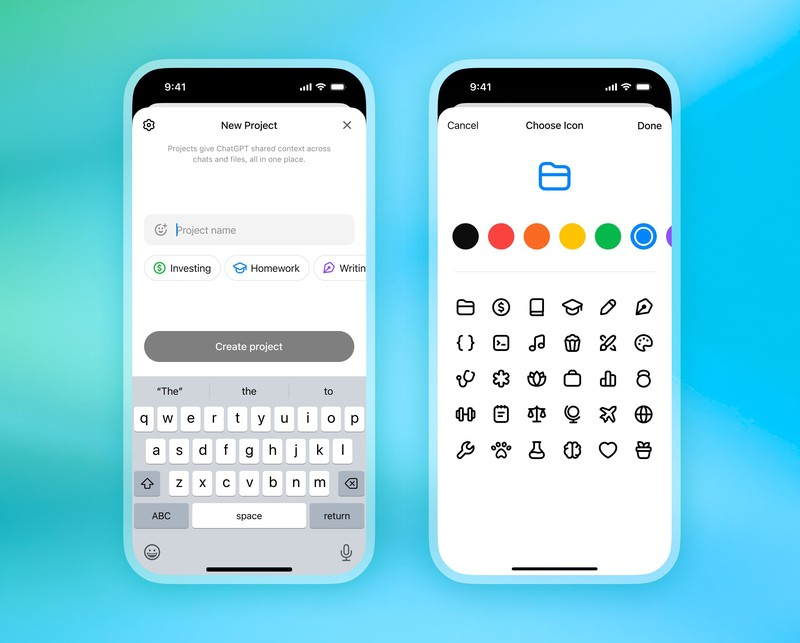
Источник изображения: OpenAI Функция Projects уже доступна в приложении для Android и в браузерной веб-версии. iOS-приложение будет обновлено «в ближайшие дни», говорится в официальном аккаунте OpenAI в X. Projects представляют собой систему проектов-папок, где можно распределять разговоры с ChatGPT в зависимости от темы. У каждого такого проекта может быть собственный цвет и иконка по выбору пользователя, свои настройки и ограничения на информацию, которой может пользоваться ИИ. Эти возможности особенно пригодятся тем, кто работает с нейросетями регулярно и в сложных задачах. Также в Projects повышен лимит на загрузку файлов. На бесплатном тарифе можно прикреплять 5 файлов, на Plus — 25, на Pro — 40. Ранее Projects была доступна только платным подписчикам, но в OpenAI взяли курс на постепенное расширение возможностей для широкого круга пользователей. Раньше точно так же перешли из платной в бесплатную категорию функции Deep Research и ChatGPT Voice. В компании считают, что такие шаги будут стимулировать переход бесплатных пользователей на платные тарифы. ChatGPT получит родительский контроль и научится выявлять психологические проблемы у пользователей
03.09.2025 [11:38],
Антон Чивчалов
В OpenAI сообщили о планах внедрения в ChatGPT новых функций, направленных на улучшение реакций ИИ в ситуациях, когда пользователь испытывает эмоциональное или психологическое напряжение, а также новых средств родительского контроля, пишет Silicon Angle. 
Источник изображения: Nicolò Canu/Unsplash Первое обновление затронет так называемый маршрутизатор в GPT-5 — компонент ИИ, который анализирует запрос пользователя и решает, какая из языковых моделей лучше подходит для его обработки. В новой версии маршрутизатор сможет распознавать признаки острого психологического напряжения, и такие запросы будут направляться модели, «заточенной» для рассуждений и бесед с пользователями. Такая модель способна предоставлять «более полезные ответы», чем другие, говорят в OpenAI. Ещё одно нововведение — система родительского контроля. Родители смогут задавать возрастные ограничения, отключать историю чатов и получать уведомления о потенциально опасных запросах детей. А если система решит, что ребёнок находится в состоянии психологического напряжения, она может послать родителям уведомление. Эти функции заработают уже в течение месяца. В OpenAI говорят, что функции родительского контроля разрабатываются с участием специалистов в области развития подростков и психического здоровья. В частности, компания сотрудничает с международной сетью врачей Global Physician Network, в которую входят свыше 200 специалистов различного профиля. «Их работа напрямую влияет на наши исследования в области безопасности, обучение моделей и другие меры вмешательства», — говорится в заявлении компании. Новые инициативы OpenAI продолжают курс на повышение безопасности искусственного интеллекта, о чём было объявлено в прошлом месяце. Также в компании ведётся работа над улучшением блокировки потенциально опасных ответов ИИ. Meta✴ может начать использовать ИИ-модели Google и OpenAI в своих приложениях
31.08.2025 [10:31],
Владимир Фетисов
Компания Meta✴ Platforms рассматривает возможность партнёрства с конкурентами, такими как Google и OpenAI, с целью расширения возможностей искусственного интеллекта в своих приложениях. Об этом пишет информационное агентство Reuters со ссылкой на собственные осведомлённые источники. 
Источник изображения: Steve Johnson / Unsplash В сообщении сказано, что руководители ИИ-подразделения Meta✴ Superintelligence Labs изучают возможность интеграции ИИ-модели Google Gemini с целью предоставления текстовых ответов на пользовательские запросы, получаемые чат-ботом Meta✴ AI. Вместе с этим они рассмотрели возможность использования ИИ-моделей OpenAI для повышения качества работы Meta✴ AI и других ИИ-функций в приложениях компании. Любые сделки Meta✴ с конкурентами, такими как Google и OpenAI, следует рассматривать как временное явление, необходимое до тех пор, пока компания не завершит разработку собственных алгоритмов. Приоритетной задачей ИИ-подразделения Meta✴ является обеспечение того, чтобы собственная ИИ-модель Llama 5 могла успешно конкурировать с передовыми аналогами других компаний. По данным источника, Meta✴ уже интегрировала ИИ-модели сторонних разработчиков в некоторые внутренние инструменты, предназначенные для сотрудников компании. К примеру, это касается ИИ-помощника по написанию программного кода, которым пользуется персонал Meta✴. Официальные представители OpenAI и Google воздерживаются от комментариев по данному вопросу. Стартап Илона Маска обвинил бывшего сотрудника в краже секретов для OpenAI
30.08.2025 [14:19],
Владимир Мироненко
Стартап Илона Маска (Elon Musk) в области искусственного интеллекта xAI подал в суд на бывшего сотрудника компании, якобы похитившего составляющую коммерческую тайну информацию о чат-боте Grok для передачи конкурирующей компании OpenAI, пишет Reuters. 
Источник изображения: xAI Иск xAI был подан в четверг в федеральный суд Калифорнии. В нём сообщается, что бывший сотрудник Сюэчэнь Ли (Xuechen Li) ранее в этом месяце украл конфиденциальную информацию, связанную с «передовыми ИИ-технологиями с функциями, превосходящими те, что предлагает ChatGPT», чтобы использовать секретные данные на своей новой работе в OpenAI. Как уточняет Reuters, OpenAI не является ответчиком в этом деле. Согласно иску, Сюэчэнь Ли приступил к работе в xAI в качестве инженера в прошлом году. Круг его обязанностей включал участие в обучении и разработке Grok. xAI утверждает, что Ли получил доступ к её коммерческим секретам в июле, вскоре после того, как принял предложение о работе в OpenAI и продал акции xAI на $7 млн. Эти сведения, как сообщается в иске, могут помочь OpenAI усилить продукт ChatGPT, добавив «более инновационный ИИ и оригинальные функции xAI». В иске также говорится, что Ли признался в краже файлов компании и «заметании следов» во время встречи 14 августа, и что позже на его устройствах были обнаружены дополнительные похищенные материалы, о которых он умолчал. В иске xAI выдвинуто требование о выплате неуказанной суммы денежной компенсации, а также о вынесении судебного запрета на переход Ли в OpenAI. Этот иск ещё больше ухудшил отношения Маска и OpenAI. В прошлом году он подал в суд на компанию и её гендиректора Сэма Альтмана (Sam Altman) за якобы отказ от первоначальной цели работать на некоммерческом поприще. В апреле OpenAI подала встречный иск против Маска, обвинив его в преследовании. OpenAI решили засудить за самоубийство подростка — компания пообещала изменить ChatGPT
27.08.2025 [12:57],
Павел Котов
Руководство OpenAI подробно рассказало о планах по устранению сбоев, возникающих у ChatGPT при работе с «ситуациями деликатного характера». Компания обратилась к этому вопросу после того, как на неё подала в суд семья подростка, совершившего самоубийство. 
Источник изображения: Mariia Shalabaieva / unsplash.com «Мы продолжим улучшать [ChatGPT], руководствуясь рекомендациями экспертов и ответственностью перед людьми, которые пользуются нашими инструментами, и надеемся, что к нам подключатся остальные, чтобы эта технология защищала людей, когда они наиболее уязвимы», — пообещала компания в корпоративном блоге. Накануне на OpenAI подали в суд родители совершившего суицид 16-летнего Адама Рейна (Adam Raine) — истцы утверждают, что «ChatGPT активно помогал Адаму изучать способы самоубийства». В OpenAI пояснили, что ChatGPT обучен предлагать помощь людям, которые выражают опасные намерения. Но в продолжительной переписке эта функция может начать работать со сбоями, и чат-бот иногда даёт ответы, противоречащие политике безопасности компании. Разработчик рассказал о грядущем обновлении флагманской модели GPT-5, с которым чат-бот научится снижать накал в обсуждении. Более того, компания изучает возможность переключать пользователей на «сертифицированных психотерапевтов до того, как обострится кризис» — не исключается вариант с формированием группы экспертов, с которыми пользователи могли бы связываться напрямую из ChatGPT. OpenAI также пообещала добавить элементы управления, которые помогут родителям лучше понять, как используют ChatGPT их дети. С членами семьи Рейн, по словам её адвоката, компания связаться не пыталась — никто не выразил соболезнования и не изъявлял желания обсудить работу по повышению безопасности продукции компании. Известны и другие случаи самоубийств среди пользователей ChatGPT, пишет CNBC. Популярность сервисов искусственного интеллекта продолжает расти, и всё чаще возникают опасения по поводу их применения для терапии, общения и удовлетворения других социальных потребностей. OpenAI рискует потерять миллиарды инвестиций: переговоры с Microsoft откладывают реструктуризацию
27.08.2025 [09:46],
Алексей Разин
Корпорация Microsoft продолжает оставаться крупнейшим инвестором OpenAI, но некоторые нюансы организационной структуры и условий взаимодействия ограничивают возможность последней привлекать дополнительные средства на своё развитие. При этом обсуждение условий реструктуризации может отсрочить её до следующего года, как сообщает Financial Times. 
Источник изображения: Unsplash, Levart_Photographer Соглашение между Microsoft и OpenAI действует до 2030 года, что даёт возможность первой рассчитывать на доступ к технологиям второй в течение этого срока. Однако, в договоре имеется пункт, который позволяет OpenAI избавиться от назойливой опеки со стороны Microsoft раньше — для этого стартапу будет достаточно разработать так называемый сильный искусственный интеллект (AGI). Совету директоров OpenAI для этого нужно будет всего лишь заявить, что соответствующая цель достигнута. Как отмечает Financial Times, противоречия между OpenAI и Microsoft могут отложить реструктуризацию на следующий год, а это навредит планам прочих инвесторов. Например, SoftBank может отказаться от намерений вложить в капитал OpenAI около $2 млрд. Затягивание переговоров с Microsoft также навредит и прочим потенциальным инвесторам OpenAI. Без реструктуризации стартап не сможет активно привлекать средства инвесторов, рассчитывающих на какую-нибудь финансовую отдачу, а не абстрактные заверения в духе «работы на благо всего человечества». В перспективе OpenAI после реструктуризации сможет выйти и на IPO. Одним из спорных моментов остаётся доступ клиентов OpenAI к программному интерфейсу API, которым сейчас через свою облачную инфраструктуру Azure распоряжается Microsoft. Стартап хотел бы привлечь к работе по такой схеме конкурентов Microsoft типа Google, ей это очевидным образом не нравятся, поэтому переговоры сопровождаются напряжением. Не исключено, что компромиссом станет доступ к API через альтернативные облачные площадки только для правительственных организаций, имеющих соглашения с OpenAI. Тот самый пункт о разработке AGI продолжает смущать Microsoft, ведь если ИИ подобного уровня будет создан, она утратит доступ к будущим продуктам OpenAI, разработанным после соответствующего момента. Поскольку конкуренты Microsoft при этом смогут пользоваться более новыми разработками OpenAI, саму корпорацию это поставит в уязвимое положение. Руководство Microsoft данный пункт соглашения с OpenAI хотело бы исключить вовсе. Вторая из сторон на это пока пойти не готова, но время работает против OpenAI в этом вопросе. В сфере будущей структуры капитала OpenAI у Microsoft тоже есть свои предпочтения. Она хотела бы владеть от 30 до 35 % акций стартапа после его реструктуризации. На данный момент Microsoft уже вложила в капитал OpenAI более $13 млрд. Даже если стороны достигнут взаимовыгодного соглашения, на преодоление всех формальностей уйдёт какое-то время, и это также с высокой вероятностью отодвигает заключение сделки на следующий год. Некоторые из крупных инвесторов OpenAI уже имеют право потребовать часть своих денег назад, если стартап не завершит реструктуризацию к определённому сроку. В случае с SoftBank этот рубеж соответствует концу 2025 года, например. OpenAI рассчитывает получить от SoftBank все причитающиеся инвестиции, даже если реструктуризация не будет завершена в указанные сроки. Стартап рассматривает возможность размещения акций и на первичном, и на вторичном рынке. Желающих вложиться в него сейчас предостаточно, и упускать выгодный момент из-за затягивающихся переговоров с Microsoft компания вряд ли захочет. OpenAI переманила топ-менеджеров Instagram✴ и Doximity для запуска ИИ-проектов в сфере здравоохранения
26.08.2025 [16:12],
Владимир Мироненко
У компании OpenAI серьёзные виды на рынок медицинских услуг, для выхода на который он наняла соучредителя Doximity и топ-менеджера Instagram✴ в свою команду в сфере здравоохранения, пишет Business Insider. 
Источник изображения: Levart_Photographer/unsplash.com До этого OpenAI в основном разрабатывала продукты для организаций в сфере здравоохранения и участвовала в совместных исследованиях в области медицинского ИИ. Но в последнее время компания не скрывает своих амбиций в освоении рынка медицинских услуг на базе ИИ. В этом месяце, представляя GPT-5, гендиректор OpenAI Сэм Альтман (Sam Altman) подчеркнул широкие возможности ChatGPT в сфере здравоохранения, назвав ИИ-модель «настоящим экспертом в области медицины», достойным учёной степени. Немногим ранее в OpenAI приступила к работе Эшли Александер (Ashley Alexander), бывшая соруководитель отдела продуктов Instagram✴. Она назначена вице-президентом по продуктам в подразделении в области здравоохранения. До этого, в июне, компания наняла Нейта Гросса (Nate Gross), соучредителя и бывшего директора по стратегии Doximity, выпустившей нейросеть Doximity GPT, основанную на технологиях OpenAI, для помощи врачам в решении административных задач. Гросс также является соучредителем Rock Health, инвестиционной и исследовательской компании в сфере цифрового здравоохранения. По словам представителя OpenAI, Гросс возглавит программы по реализации стратегии вывода OpenAI на рынок здравоохранения, среди первоначальных целей — создание новых медицинских технологий в сотрудничестве с врачами и исследователями. OpenAI планирует не только разрабатывать ИИ-модели для медицинских сервисов других компаний, но и иметь свою инфраструктуру в сфере здравоохранения, а также ИИ-приложения, созданные на их основе, фактически становясь конкурентом своим клиентам из этой отрасли. Исследованиями OpenAI в области ИИ-технологий для здравоохранения руководит Каран Сингал (Karan Singal), бывший эксперт Google, который участвовал в разработке медицинской программы магистратуры Med-PaLM. Как сообщил представитель OpenAI, Сингал и дальше будет заниматься этим направлением. Круг интересов OpenAI весьма обширен. В прошлом месяце компания запустила Study Mode, версию ChatGPT для студентов, чтобы конкурировать с Gemini for Education от Google в сфере образования. В феврале она представила агента по продажам на базе ИИ, а в июле анонсировала агентский инструмент для бронирования билетов и покупок для пользователей. Илон Маск подал иск против Apple и OpenAI — обвиняет в сговоре и захвате рынка ИИ
25.08.2025 [21:41],
Андрей Созинов
Компания xAI Илона Маска (Elon Musk) и входящая в её состав соцсеть X подали в понедельник коллективный иск против Apple и OpenAI, обвинив их в «антиконкурентном сговоре» и создании барьеров для конкурентов. Предметом разбирательства стал эксклюзивный альянс Apple и OpenAI по интеграции ChatGPT в экосистему iPhone в целом и сервис Apple Intelligence в частности. 
Источник изображения: SpaceX В иске утверждается, что Apple навязывает пользователям iPhone использование ChatGPT в качестве чат-бота по умолчанию при активации Apple Intelligence, лишая тем самым смысла скачивание сторонних ИИ-приложений. Маск считает, что «Apple и OpenAI закрыли рынок, чтобы сохранить свои монополии и не допустить конкурентов вроде X и xAI». Также компании Маска обвиняют Apple в сознательном занижении позиций конкурирующих приложений в App Store: по их словам, X и Grok, несмотря на высокие рейтинги, не попадают в подборку «Обязательных приложений» (Must-Have Apps), тогда как ChatGPT там оказался единственным ИИ-чат-ботом по состоянию на 24 августа 2025 года. «В отчаянной попытке защитить свою монополию на рынке смартфонов Apple объединилась с компанией, которая более всех заинтересована в сдерживании конкуренции и инноваций в ИИ — с OpenAI, монополистом на рынке генеративных чат-ботов», — говорится в тексте иска. В документе также утверждается, что интеграция ChatGPT в iPhone даёт OpenAI доступ к «миллиардам пользовательских запросов», что ещё больше укрепляет её доминирование за счёт «монополии Apple на рынке смартфонов». Илон Маск уже публично угрожал Apple судебными исками ранее в этом месяце, указывая на нарушения антимонопольного законодательства: «Apple ведёт себя так, что ни одной ИИ-компании, кроме OpenAI, невозможно выйти на первое место в App Store — это прямое нарушение антимонопольных норм». В OpenAI уже прокомментировали ситуацию. «Этот иск полностью укладывается в привычную для господина Маска стратегию публичного давления», — заявила представитель компании Кайла Вуд (Kayla Wood) в комментарии The Verge. В Apple настаивают, что App Store «создан для честной конкуренции и не содержит предвзятого отношения», отметив это ещё в начале месяца. Новых комментариев от компании не поступало. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2025 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews. kz
![]()
![]()








 MWC 2018
MWC 2018 2018
2018 Computex
Computex






