|
Опрос
|
реклама
Быстрый переход
OpenAI и Oracle построят дата-центр из 64 000 ускорителей Nvidia GB200 для ИИ-мегапроекта Stargate
07.03.2025 [11:24],
Алексей Разин
Превращение США в сверхдержаву в сфере искусственного интеллекта, помимо прочего, подразумевает создание на территории страны сети центров обработки данных в рамках проекта Stargate, реализуемого при участии OpenAI, SoftBank и Oracle. В Техасе к концу 2026 года будет развёрнут центр обработки данных, который разместит 64 000 ускорителей Nvidia GB200 на миллиарды долларов США.  По информации Bloomberg, на площадке в техасском городе Абилин к концу 2026 года появится специализированный центр обработки данных с 64 000 ускорителями вычислений Nvidia GB200. Вычислительные мощности Stargate в Техасе будут вводиться в строй по фазам, первая из них уже примет 16 000 ускорителей данного типа. Затраты, связанные с реализацией данного проекта, не уточняются, но более старые ускорители B200 руководством Nvidia оценивались в сумму от $30 до $40 тысяч за штуку. Таким образом, на обустройство только одного ЦОД в Техасе будет стоить инвесторам несколько миллиардов долларов США. Напомним, проект Stargate был анонсирован в январе компаниями OpenAI, SoftBank и Oracle при участии Дональда Трампа (Donald Trump). Только на первом этапе на развитие вычислительной инфраструктуры в США планируется потратить $100 млрд, а за последующие четыре года сумма может вырасти до $500 млрд. На территории США планируется построить около десяти центров обработки данных, которые будут обслуживать инфраструктуру Stargate. Помимо Техаса, они могут появиться в Пенсильвании, Висконсине, Орегоне и Юте. К концу 2024 года Meta✴ Platforms планировала увеличить количество эксплуатируемых ускорителей H100 до 600 000 штук. Облачный провайдер CoreWeave располагает более чем 250 000 ускорителей Nvidia, которые распределены по 32 центрам обработки данных. Стартап xAI Илона Маска (Elon Musk) заключил с Dell контракт на поставку серверов для фирменного суперкомпьютера на сумму $5 млрд. Подобная активность участников рынка и обеспечивает крупными заказами и Nvidia, и выпускающую для неё чипы TSMC. OpenAI собралась продавать доступ к ИИ-агентам уровня кандидата наук за $20 000 в месяц
06.03.2025 [14:04],
Павел Котов
OpenAI готовится запустить новую линейку агентов искусственного интеллекта, за доступ к которым будет взиматься плата в размере от $2000 до $20 000, сообщает Information. Эти инструменты смогут писать компьютерный код и проводить исследования на уровне кандидата наук. 
Источник изображения: Growtika / unsplash.com Мощные ИИ-агенты OpenAI предложат сортировку лидов по продажам, разработку ПО и проведение расширенных исследований. Компания планирует ввести три тарифных плана новой линейки. Самый дешёвый с ценником $2000 адресован высокооплачиваемым специалистам, которым необходима помощь ИИ в работе. Более мощный ИИ-агент, способный писать программный код, будет стоить около $10 000 в месяц и подойдёт инженерам и разработчикам. ИИ-агент с «зарплатой» $20 000 в месяц сможет производить исследования на уровне кандидата наук, проводить углублённый анализ и решать сложные задачи. Сейчас руководство OpenAI обсуждает инициативу с инвесторами, позиционируя ИИ-агентов как новый основной источник дохода. В долгосрочной перспективе компания рассчитывает получать от данного направления от 20 % до 25 % выручки. Данная ценовая стратегия OpenAI является сигналом о переходе компании к услугам ИИ повышенного качества — компания стремится стать прямым конкурентом разработчикам систем ИИ для корпоративных клиентов. Разработка трёх тарифных планов указывает, что OpenAI намерена всерьёз заняться монетизацией ИИ вне потребительского сектора. Традиционные сайты массово теряют аудиторию из-за чат-ботов и агентов с ИИ
06.03.2025 [14:00],
Павел Котов
Специализирующиеся на искусственном интеллекте компании обещали владельцам сайтов, что поисковые системы нового поколения обеспечат им приток посетителей через реферальный трафик. Новый доклад платформы лицензирования контента TollBit показал, что в действительности это не так. 
Источник изображения: Dima Solomin / unsplash.com Ранее OpenAI и Perplexity делали громкие заявления, что их поисковые системы с ИИ, которые проводят сбор материалов из Сети, обеспечат владельцам сайтов прирост посетителей и новые источники дохода. В действительности поисковые системы с ИИ отправляют на новостные сайты и блоги на 96 % меньше реферального трафика, чем традиционный поиск Google, гласит доклад TollBit, которым компания поделилась с Forbes. При этом за последние месяцы объёмы собираемой ИИ информации с сайтов выросли более чем вдвое. OpenAI, Perplexity, Meta✴ и другие ИИ-компании за IV квартал 2024 года сканировали сайты около 2 млн раз — данные предоставлены на примере 160 сайтов, включая национальные и местные новостные ресурсы, посвящённые потребительским технологиям сайты и посвящённые шопингу блоги. Каждая страница на них подвергалась сканированию в среднем семь раз. TollBit предлагает сайтам средства обнаружения сканирования ИИ — каждый раз, когда это происходит, компания взимает с разработчиков ИИ-платформ плату в пользу ресурсов, зарегистрированных на её аналитической платформе. Это даёт TollBit представление о трафике и активности механизмов сканирования. В OpenAI, Meta✴ и Perplexity представленные в докладе данные комментировать не стали, но в Perplexity отметили, что их система следует директивам в файлах robots.txt — они указывают, к каким разделам сайтов разрешён доступ. В феврале аналитики Gartner опубликовали прогноз, согласно которому к 2026 году трафик с традиционных поисковых систем из-за чат-ботов и агентов с ИИ упадёт на 25 %. Процесс уже пошёл: недавно специализирующаяся на образовательных технологиях компания Chegg решила засудить Google за сводки данных, которые показываются в поисковой выдаче; во II квартале минувшего года, когда они только начали появляться, трафик Chegg просел на 8 %, а в январе этого года он провалился уже на 49 %. По версии истца, ИИ-сводки в поиске включали материалы с сайта Chegg без указания источника. Падение трафика повлияло на Chegg до такой степени, что сейчас компания рассматривает возможность перехода в частное владение или вообще продажи своих активов. В Google иск Chegg назвали «беспочвенным» и заявили, что в поисковой выдаче повысилось разнообразие сайтов. 
Источник изображения: BoliviaInteligente / unsplash.com Ситуация осложняется тем, что при сканировании ресурсов и сборе данных разработчики ИИ указывают в своих системах не соответствующие действительности значения строки «User agent», и это не позволяет владельцам сайтов выявлять сканеры и формировать понимание, как ИИ-компании используют доступ к материалам ресурсов. Google, по одной из версий, использует для разных целей одних и тех же ботов — они и индексируют сайты, и собирают с них данные для ИИ. Действия Perplexity, которая говорит об уважении к директивам robots.txt, ещё более непредсказуемы: даже когда ресурс блокирует доступ средствами веб-сервера, сканирование предположительно не останавливается, потому что реферальный трафик продолжает поступать. Один из ресурсов, если верить официальным показателям, подвергся сканированию 500 раз, после чего от Perplexity на него пришли 10 000 посетителей. Это можно объяснить только работой неопознанного сканирующего бота. В прошлом году Perplexity уличили в копировании и последующем почти дословном цитировании материалов, в том числе платных популярных новостных агентств, включая Forbes, CNBC и Bloomberg, — без ссылки на источник. Сервис компании также часто ссылался на низкокачественные созданные ИИ блоги и сообщения в социальных сетях, содержащие неточную информацию. New York Post и Dow Jones подали на Perplexity в суд, обвинив компанию в нарушении авторских прав. Бесконтрольное сканирование материалов сайтов приводит и к тому, что у их владельцев растут расходы на серверные ресурсы. OpenAI и Perplexity запустили ИИ-агентов, которые самостоятельно ищут необходимую информацию на сайтах и составляют подробные отчёты, что обязательно усугубит проблему. Одним из очевидных способов разрешения конфликта является прямое лицензирование материалов. Associated Press, Axel Springer и Financial Times заключили соответствующие соглашения с OpenAI. Появились и новые компании, которые взимают плату с владельцев систем ИИ каждый раз, когда те копируют материалы с сайтов — по этой модели работает подготовившая доклад TollBit. Инвестиции Microsoft в OpenAI не нарушают конкуренцию, решил антимонопольный орган Великобритании
06.03.2025 [00:34],
Анжелла Марина
Британское Управление по конкуренции и рынкам (CMA) одобрило инвестиционное соглашение между Microsoft и OpenAI на сумму $13 млрд. Решение положило конец 14-месячному периоду неопределённости, связанному с антимонопольной проверкой. Как передаёт Bloomberg, ведомство пришло к выводу, что сделка не подпадает под правила слияний и поглощений, а значит, не требует глубокого расследования. 
Источник изображения: Dima Solomin / Unsplash В ходе проверки регулятор изучал, усиливают ли партнёрские отношения контроль одной компании над другой. Однако по итогам расследования, СМА заявила, что «хотя Microsoft получила значительное влияние на OpenAI ещё в 2019 году, смены контроля не произошло». В то же время в США Федеральная торговая комиссия ранее выразила обеспокоенность тем, что партнёрство с OpenAI может укрепить доминирование Microsoft в области искусственного интеллекта (ИИ). Расследование FTC пока не завершено. По мнению ряда экспертов, сделка с OpenAI дала Microsoft конкурентное преимущество перед другими технологическими гигантами, позволив интегрировать ИИ-разработки во многие ключевые продукты компании. На этом фоне в 2023 году, Microsoft и Apple отказались от мест в совете директоров OpenAI, ответив тем самым на растущее давление со стороны регуляторов. Стоит сказать, что проверка заняла довольно много времени. Исполнительный директор CMA по вопросам слияний Джоэл Бэмфорд (Joel Bamford) признал, что расследование слишком затянулось, но, по его словам, на это повлияли сложность данного партнёрства и постоянные изменения в его структуре. Рассмотрение сделки Microsoft и OpenAI было частью глобальных усилий антимонопольных органов по предотвращению излишней концентрации власти в сфере ИИ. Однако в OpenAI считают, что сосредоточены на разработке безопасного и полезного ИИ, а Microsoft подчеркнула, что партнёрство, напротив, способствует развитию конкуренции на рынке. Также регулятор ранее одобрил сотрудничество Google с ИИ-разработчиком, компанией Anthropic. Судья отклонила требование Маска о запрете перевода OpenAI на коммерческие рельсы
05.03.2025 [10:21],
Алексей Разин
С прошлого года Илон Маск (Elon Musk) пытается через суд предотвратить реструктуризацию стартапа OpenAI, которая позволит ему перейти на коммерческие рельсы и проще привлекать материальные ресурсы, необходимые для развития. Судья на этой неделе отклонила требование Маска о наложении предварительного судебного запрета на реструктуризацию OpenAI. 
Источник изображения: Unsplash, Дима Соломин Судья Окружного суда Окленда Ивон Гонзалез Роджерс (Yvonne Gonzalez Rogers) постановила, что Илону Маску не удалось предоставить адекватные по своей значимости доводы для введения предварительного судебного запрета на реструктуризацию OpenAI. При этом рассмотрение дела не прекращается, и новое судебное заседание по этому иску состоится до конца года. Представителей Маска подобное решение отчасти устроило, адвокат Марк Тоберофф (Marc Toberoff) выразил надежду, что суд в дальнейшем докажет неправомерность использования руководителем OpenAI Сэмом Альтманом (Sam Altman) благотворительных взносов Маска для целей личного обогащения, поскольку они предназначались для «общественного блага». Противоречия между Илоном Маском и основателями OpenAI стали причиной ухода первого из них из этого стартапа в 2018 году. Маск пытается внушить суду и общественности мысль о том, что всегда рассчитывал на сохранение некоммерческого статуса OpenAI, а руководство компании с годами всё больше думало о коммерческой деятельности. В прошлом декабре он обратился в суд с требованием заблокировать грядущую реструктуризацию, которая вывела бы на первый план коммерческую деятельность OpenAI. Сейчас стартапом руководит некоммерческий состав совета директоров, это отпугивает инвесторов, а в средствах на развитие OpenAI регулярно нуждается, поэтому реструктуризация должна устранить эту проблему. Представители OpenAI в суде указывали на то, что сам Илон Маск ранее не противился идее перевода стартапа в коммерческое русло, подтверждая это архивной перепиской. Нынешнее поведение Маска в OpenAI объясняют желанием сдержать развитие конкурента, поскольку с 2023 года миллиардер пытается закрепиться на рынке систем генеративного искусственного интеллекта при помощи собственного стартапа xAI. OpenAI добавит генератор реалистичных видео Sora в ChatGPT
01.03.2025 [17:26],
Павел Котов
Компания OpenAI намеревается интегрировать основанный на искусственном интеллекте генератор видео Sora в популярный чат-бот ChatGPT. Об этом сообщило руководство самой компании во время сессии в Discord. 
Источник изображения: Mariia Shalabaieva / unsplash.com Сегодня Sora доступен только через вышедшее в декабре отдельное веб-приложение — в нём можно генерировать видео кинематографического качества продолжительностью до 20 секунд. Однако руководитель проекта Sora в OpenAI Рохан Сахаи (Rohan Sahai) сообщил, что компания планирует расширить присутствие сервиса и возможности генератора видео. Первоначально, когда сервис ещё не был общедоступным, компания продвигала его среди представителей творческих профессий и студий — производителей видеоконтента. Теперь OpenAI прилагает более целенаправленные усилия, чтобы сделать Sora привлекательнее. Компания намерена объединить Sora с ChatGPT, но сроки реализации пока не называются. В новом формате генератор видео будет менее функциональным по сравнению с отдельным веб-приложением, где можно редактировать и монтировать ролики. Тем не менее, это, вероятно, поспособствует росту и без того значительной популярности ChatGPT, а также станет стимулом к оформлению платных подписок, предполагающих более высокие лимиты на генерацию видео. OpenAI изначально запустила Sora как отдельное приложение, чтобы не усложнять работу с ChatGPT. Со временем разработчики предоставили сообществу возможность просматривать видео, созданные другими пользователями; компания также задумалась о выпуске отдельного мобильного приложения Sora и даже начала подыскивать разработчиков для этого проекта. Ещё одно направление развития — использование Sora для генерации не только видео, но и статических изображений. Такой проект также находится в разработке. В ChatGPT уже есть генератор изображений DALL-E 3, но предполагается, что в Sora изображения будут более фотореалистичными. Кроме того, ведётся разработка новой версии модели Sora Turbo, которая лежит в основе приложения Sora. У OpenAI закончились ИИ-ускорители — глава компании объяснил задержку GPT-4.5
28.02.2025 [17:55],
Павел Котов
OpenAI сообщила о выходе модели искусственного интеллекта GPT-4.5, но доступ к ней получили только пользователи подписки ChatGPT Pro, которые платят $200 в месяц. Полномасштабное развёртывание новой модели пришлось отложить, поскольку «мы слишком выросли, и у нас закончились графические процессоры», необходимые для этого, сообщил глава компании Сэм Альтман (Sam Altman). 
Источник изображения: nvidia.com «На следующей неделе мы добавим несколько десятков тысяч графических процессоров и выпустим её на тариф Plus», — пообещал гендиректор OpenAI и добавил, что вскоре компания получит ещё сотни тысяч ускорителей. Из-за мирового дефицита вычислительных мощностей компания была вынуждена обратиться к Broadcom с целью совместной разработки собственного ускорителя для ИИ. Однако на это уйдёт не один год, а пока для удовлетворения своих потребностей и потребностей клиентов компании приходится работать с оборудованием Nvidia и других поставщиков. Это в очередной раз подчёркивает, в каком выгодном положении остаётся Nvidia. Недавно компания заявила, что ускорители последнего поколения Blackwell распроданы до октября текущего года. А поскольку мировая отрасль центров обработки данных планирует крупномасштабное расширение существующих и строительство новых объектов, успех будет сопутствовать «зелёным» ещё несколько лет. Только OpenAI и Microsoft работают над суперкомпьютером, который обойдётся в $100 млрд, а Илон Маск (Elon Musk) намеревается расширить свой суперкомпьютер Colossus в Мемфисе (штат Теннесси, США) до более чем миллиона ускорителей. В Южной Корее одобрение получил объект мощностью 3 ГВт, а ЦОД планируют запустить даже на Луне. Глава Microsoft Сатья Наделла (Satya Nadella) выразил опасение, что мощности объектов для ИИ окажутся чрезмерными, хотя новые модели становятся всё более требовательными к вычислительным ресурсам. Яркий тому пример — новая OpenAI GPT-4.5. Это «гигантская, дорогая модель», как охарактеризовал её Сэм Альтман. Стоимость подключения к ней составит $75 за 1 млн входных токенов и $150 за 1 млн выходных — для сравнения, у GPT-4o эти тарифы составляют $2,50 и $10 соответственно. Несмотря на цену, это «не рассуждающая модель, и [она] не побьёт эталонных показателей», признался гендиректор OpenAI, но, по его словам, «это другой вид интеллекта, [у него] есть волшебство, которого я прежде не ощущал». OpenAI представила GPT-4.5 — самую большую и осведомлённую ИИ-модель для ChatGPT без поддержки размышлений
28.02.2025 [00:31],
Андрей Созинов
OpenAI выпустила GPT-4.5 — свою самую передовую и крупную большую языковую модель (LLM) искусственного интеллекта. Разработчик называет этот релиз своей «самой осведомлённой моделью», но предупреждает, что GPT-4.5 не является прорывной моделью и может не демонстрировать таких высоких результатов, как o1 или o3-mini, обладающие способностями к рассуждению. 
Источник изображений: OpenAI GPT-4.5 предлагает улучшенные навыки написания текстов, более качественные знания о мире и то, что OpenAI называет «усовершенствованной индивидуальностью по сравнению с предыдущими моделями». Компания утверждает, что взаимодействие с GPT-4.5 будет более «естественным» и отмечает, что модель лучше распознаёт паттерны и определяет взаимосвязи, что делает её идеальной для написания текстов, программирования и «решения практических задач». 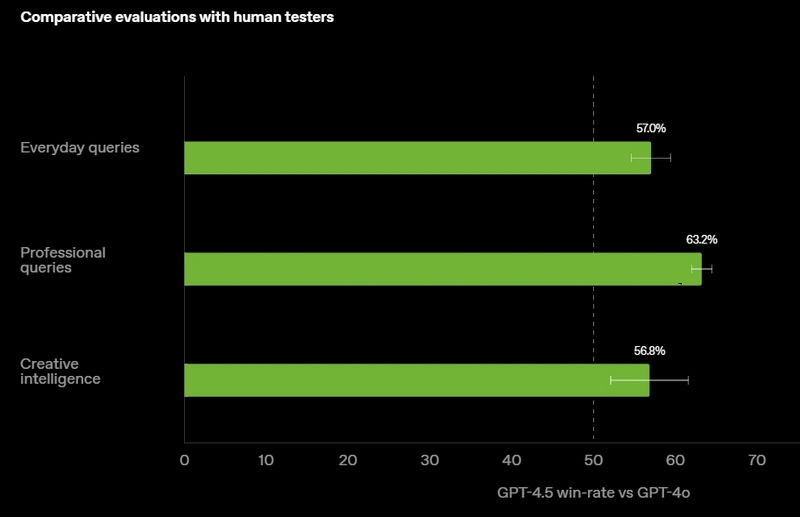 При этом OpenAI предупредила, что в GPT-4.5 недостаточно новых возможностей, чтобы считать её передовой моделью. «GPT-4.5 не является прорывной моделью, но это самая большая LLM OpenAI, превосходящая вычислительную эффективность GPT-4 более чем в 10 раз, — говорится в документе OpenAI, который просочился в Сеть до анонса. — Она не представляет семь новых возможностей по сравнению с предыдущими версиями со способностью к рассуждениям, и её производительность ниже, чем у o1, o3-mini и Deep Research в большинстве тестов». 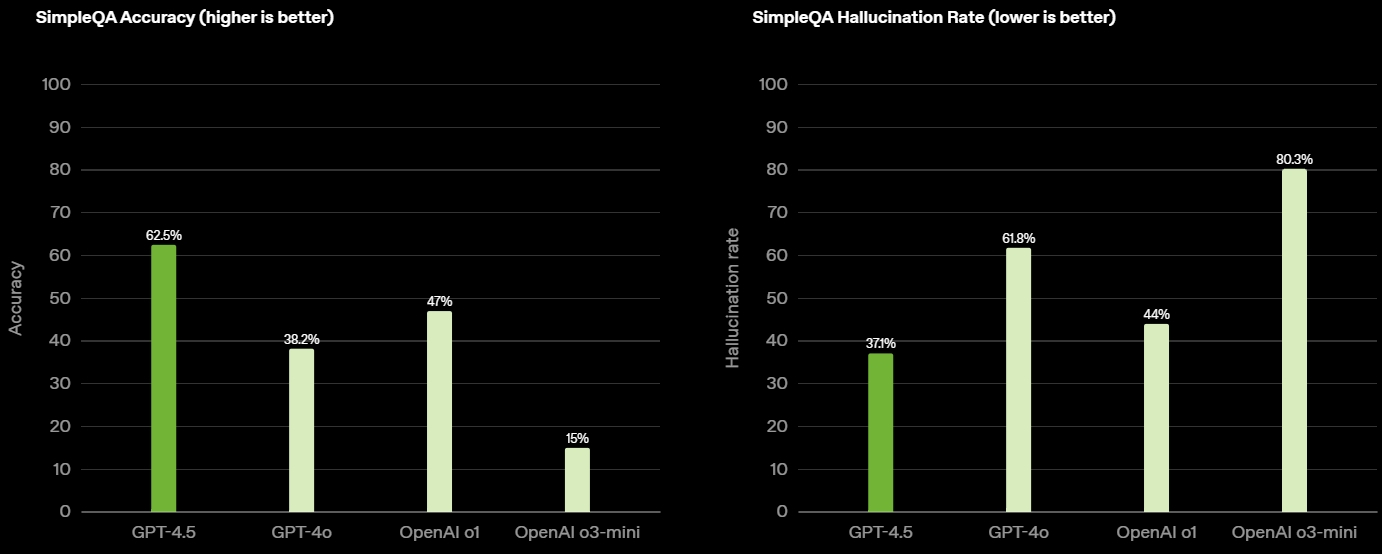 Ранее сообщалось, что OpenAI использует свою модель с возможностью рассуждений o1 для обучения GPT-4.5 на синтетических данных. Сама OpenAI заявила, что обучила GPT-4.5 «с помощью новых методов контроля в сочетании с традиционными методами, такими как контролируемая тонкая настройка (SFT) и обучение с подкреплением на основе человеческой обратной связи (RLHF), аналогичными тем, что использовались для GPT-4o». «Мы адаптировали GPT-4.5 так, чтобы он лучше сотрудничал, делая разговоры более тёплыми, интуитивными и эмоционально насыщенными, — сказал Рафаэль Гонтихо Лопес (Raphael Gontijo Lopes), исследователь из OpenAI. — Чтобы оценить это, мы попросили тестировщиков сравнить её [новую модель] с GPT-4o, и GPT-4.5 оказалась впереди практически по всем категориям». 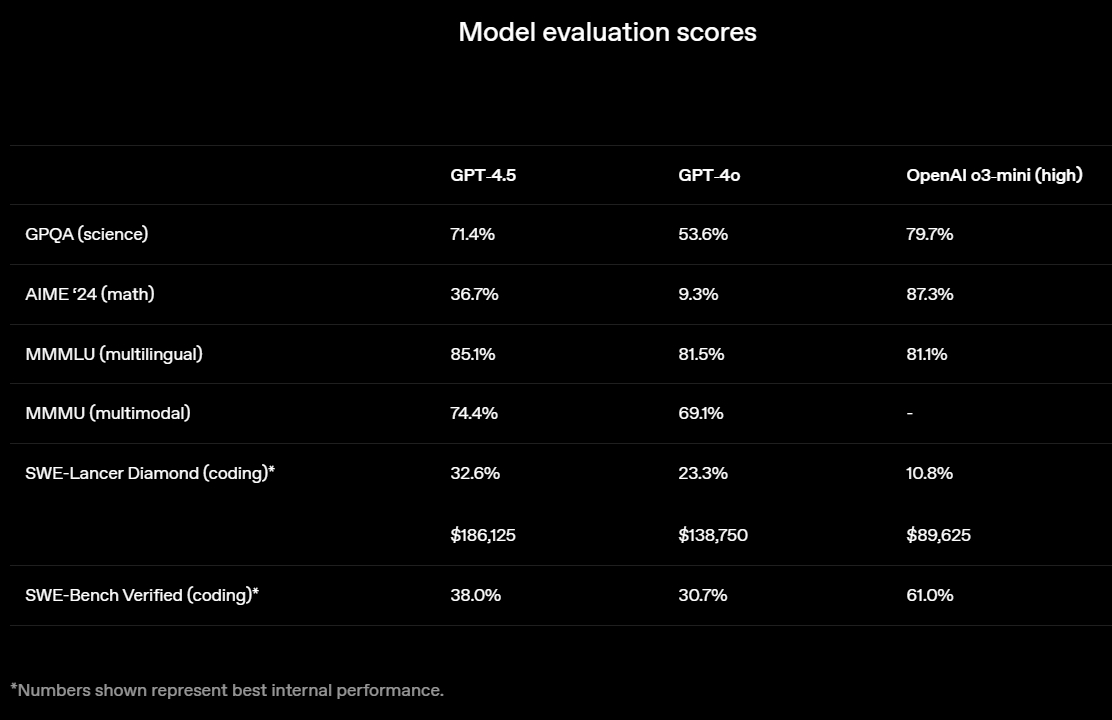 Несмотря на некоторые ограничения, GPT-4.5 галлюцинирует значительно меньше, чем GPT-4o, и немного меньше, чем модель o1, заявила OpenAI. Также новинка демонстрирует более развитую интуицию и творческие способности, лучше понимает, что имеют в виду пользователи, и «интерпретирует тонкие сигналы или неявные ожидания с большим количеством нюансов». GPT-4.5 с сегодняшнего дня доступна пользователям с подпиской ChatGPT Pro за $200 в месяц, а также исследователям. Сейчас модель находится на стадии предварительного исследовательского тестирования. Решение выпустить её в таком виде обусловлено желанием «лучше понять её сильные стороны и ограничения». «Мы всё ещё изучаем её возможности и с нетерпением ждём, когда люди начнут использовать её так, как мы, возможно, не ожидали», — подытожили в OpenAI. В компании не сообщили, когда сделают новинку доступной более широкой публике. На прошлой неделе сообщалось, что OpenAI планирует запустить GPT-4.5 к концу февраля, а GPT-5 — уже в конце мая. Генеральный директор OpenAI Сэм Альтман (Sam Altman) назвал GPT-5 «системой, объединяющей множество наших технологий», отметив, что она будет включать модель OpenAI o3. В прошлом месяце OpenAI выпустила o3-mini, но полноценная o3 появится только как часть GPT-5. Компания таким образом намерена объединить свои большие языковые модели, чтобы в итоге создать одну более мощную систему, способную самостоятельно определять, какие ресурсы необходимо задействовать для решения той или иной задачи. ИИ-агент OpenAI для написания рефератов стал доступен всем платным пользователям ChatGPT
26.02.2025 [10:32],
Павел Котов
Компания OpenAI накануне объявила, что инструмент Deep Research — ИИ-агент для комплексного сбора и анализа информации с помощью ChatGPT и интернет-поиска — теперь доступен для пользователей всех платных тарифов ChatGPT. 
Источник изображения: Mariia Shalabaieva / unsplash.com Вместо короткого ответа на вопрос Deep Research выдаёт подробную и структурированную информацию, собранную из нескольких источников с полными ссылками и объяснением логики рассуждений. Сбор и систематизация информации занимает от 5 до 30 минут. Deep Research базируется на специальной версии рассуждающей модели OpenAI o3, обученной по методике Reinforcement Learning (обучения с подкреплением), которая совмещена с поиском в интернете. Подписчики тарифных планов ChatGPT Plus, Team, Enterprise и Edu могут задавать десять исследовательских запросов в месяц. Ранее услуга OpenAI Deep Research была доступна только пользователям ChatGPT Pro, которые платят по $200 в месяц — на момент выхода ИИ-агента они могли создавать 100 запросов в месяц, теперь это количество увеличено до 120. Инструменты для проведения глубокого исследования в веб-поиске уже предложили конкуренты OpenAI — Google и Perplexity — эти сервисы имеют то же название и также генерируют длинные отчёты, но доступны они для более широкого круга пользователей. На минувшей неделе Google открыла исследовательский ИИ-агент для всех пользователей Gemini Advanced — оформить эту подписку можно за $19,99 в месяц, как и ChatGPT Plus. Технологические компании рассчитывают, что инструменты глубокого исследования окажутся для потребителей стимулом оформлять дорогие подписки на системы ИИ. В OpenAI, однако, уже решили изучить вопрос, какую угрозу Deep Research может представлять для общественности, если инструментом станут злоупотреблять для распространения дезинформации. Microsoft сняла ограничения на болтовню с Copilot и ИИ-рассуждения для бесплатных пользователей
25.02.2025 [22:00],
Андрей Созинов
В прошлом месяце Microsoft сделала ИИ-модель OpenAI o1 со способностью к рассуждению бесплатной для всех пользователей Copilot. Однако для бесплатных пользователей имелись ограничения на количество сообщений. Теперь эти ограничения в функции Think Deeper сняты, равно как и временны́е ограничения на голосовое общение с Copilot через функцию Voice in Copilot. 
Источник изображения: Microsoft «Мы прилагаем все усилия, чтобы как можно быстрее предоставить неограниченный доступ к расширенным функциям как можно большему числу людей, начиная с Voice и Think Deeper, — говорит команда Copilot. — Стоит отметить, что вы можете столкнуться с задержками или перебоями в работе в периоды высокого спроса или в случае обнаружения проблем с безопасностью, неправильного использования или других нарушений "Условий использования Copilot"». Неограниченное использование Copilot Voice и Think Deeper появилось спустя два года после того, как Microsoft впервые запустила Copilot в поисковой системе Bing, и всего через месяц после того, как компания изменила подписку Copilot Pro, включив в неё ИИ-функции Office AI в Microsoft 365. Microsoft продолжает предлагать пользователям подписку Copilot Pro за $20 в месяц. Компания обещает, что платные пользователи «сохранят привилегированный доступ к нашим новейшим моделям во время пиковых нагрузок, ранний доступ к экспериментальным функциям искусственного интеллекта, а также дополнительное использование Copilot в избранных приложениях Microsoft 365, таких как Word, Excel и PowerPoint». Компания отметила, что «в ближайшее время» расскажет об упомянутых экспериментальных функциях, к которым платные подписчики получат ранний доступ. Весьма вероятно, что речь об GPT-4.5 — недавно инсайдер из Microsoft намекнул, что выход новой продвинутой модели состоится уже на этой неделе. Да и выход GPT-5 не за горами. OpenAI провела зачистку ChatGPT от аккаунтов из Китая и Северной Кореи, подозреваемых во вредоносной деятельности
22.02.2025 [13:47],
Владимир Фетисов
OpenAI заблокировала аккаунты пользователей из Китая и Северной Кореи, которые, якобы, использовали технологии компании в злонамеренных целях, включая слежку и кампании по влиянию на общественное мнение. В заявлении OpenAI говорится, что авторитарные режимы могут применять искусственный интеллект во вред США и собственным гражданам. Отмечается, что для выявления подозрительной активности был задействован специальный ИИ-алгоритм. 
Источник изображения: Dima Solomin / unsplash.com Компания не сообщила, сколько аккаунтов было заблокировано, а также не уточнила, как давно ведётся поиск учётных записей, владельцы которых потенциально занимаются злонамеренной деятельностью. В заявлении сказано, что в одном из таких случаев пользователь ChatGPT генерировал новостные статьи на испанском языке с целью очернить США. Эти материалы впоследствии публиковались новостными изданиями в Латинской Америке от имени китайской компании. Во втором случае злоумышленники, предположительно связанные с Северной Кореей, использовали искусственный интеллект для создания резюме и онлайн-профилей фиктивных соискателей с целью трудоустройства в западные компании. Также была выявлена группа аккаунтов, принадлежащих пользователям из Камбоджи и связанных с финансовым мошенничеством. Они использовались для перевода и публикации комментариев в разных соцсетях, включая X и Facebook✴. Правительство США выразило обеспокоенность тем, что Китай якобы использует искусственный интеллект для контроля над общественным мнением в стране, а также распространения дезинформации и подрыва безопасности США и их союзников. Напомним, ChatGPT от OpenAI является самым популярным ИИ-ботом с 400 млн еженедельно активных пользователей. Компания ведёт переговоры о привлечении инвестиций в размере до $40 млрд при оценке OpenAI в $300 млрд, что может стать рекордным раундом финансирования для частной компании. «Нам просто нужно больше мощностей»: OpenAI постепенно поборет зависимость от Microsoft
22.02.2025 [13:32],
Владимир Мироненко
OpenAI в разработке новых ИИ-моделей и предоставлении ИИ-услуг компаниям и пользователям сейчас в значительной степени полагается на вычислительные мощности своего главного акционера Microsoft. Однако в ближайшие пять лет ожидаются значительные изменения в этом вопросе, сообщило в пятницу издание The Information. 
Источник изображения: Growtika/unsplash.com По данным The Information, к 2030 году OpenAI рассчитывает получать три четверти вычислительных мощностей ЦОД от проекта Stargate, который будет в значительной степени финансироваться конгломератом SoftBank — одним из новых инвесторов OpenAI. Это означает существенное изменение во взаимоотношениях OpenAI с Microsoft, инвестировавшей в компанию с 2019 года почти $14 млрд. Изменение не произойдёт мгновенно, пишет The Information. В ближайшие несколько лет OpenAI продолжит увеличивать расходы на оплату вычислительных мощностей ЦОД, принадлежащих Microsoft. По данным The Information, в 2027 году OpenAI планирует потратить на свои разработки $20 млрд. Для сравнения, расходы компании в 2024 году составили $5 млрд. Согласно прогнозам OpenAI, к 2030 году её затраты на работу уже обученных моделей (инференс) моделей ИИ превысят расходы на их обучение. Когда был анонсирован проект Stargate, один из пользователей соцсети X отметил, что дружбе между OpenAI и Microsoft пришёл конец. В ответ глава OpenAI Сэм Альтман (Sam Altman) заявил: «Вовсе нет! Это очень важное и крупное партнёрство на длительное время». Он также добавил: «Нам просто нужно больше вычислительных мощностей». Microsoft, в свою очередь, утверждает, что отношения между двумя компаниями остаются прочными. Она продолжит размещать сервисы OpenAI на своей платформе облачных вычислений Azure. Вместе с тем Microsoft инвестировала в её французского конкурента Mistral AI и предлагает модели Meta✴ Llama на платформе Azure. В прошлом году Microsoft добавила поддержку модели Anthropic — конкурента OpenAI — своему ИИ-ассистенту GitHub Copilot для помощи программистам в написании кода. Инсайдер из Microsoft намекнул на релиз GPT-4.5 на следующей неделе и GPT-5 в мае
20.02.2025 [22:31],
Анжелла Марина
Microsoft подготавливает серверные мощности для предстоящего запуска моделей GPT-4.5 и GPT-5. Генеральный директор OpenAI Сэм Альтман (Sam Altman) недавно объявил, что GPT-4.5 будет запущен в течение нескольких недель. Теперь же стало известно, что Microsoft планирует разместить новую ИИ-модель на своих серверах уже на следующей неделе. 
Источник изображения: Copilot Модель GPT-4.5, известная под кодовым названием Orion, станет следующим этапом развития технологий OpenAI и последней моделью, не использующей цепочку рассуждений (chain-of-thought) для ответа на запросы. OpenAI уже намекнула, что GPT-4.5 будет значительно мощнее, чем GPT-4, однако основное внимание компании будет сосредоточено на разработке GPT-5, которая принесёт более существенные изменения, сообщает издание The Verge. Microsoft ожидает появления GPT-5 в конце мая, что в целом соответствует обещанию Альтмана запустить эту модель в течение нескольких месяцев. Однако дата релиза может измениться, если планы будут скорректированы, как например, это произошло в октябре, когда OpenAI планировала выпустить GPT-4.5 до конца 2024 года, но запуск был отложен на начало 2025 года. Стоит сказать, что GPT-5 станет более значимым релизом по сравнению с GPT-4.5. Альтман назвал её «системой, которая объединяет множество технологий», включая модель o3 со способностью к рассуждению. Хотя в прошлом месяце OpenAI выпустила o3-mini, компания больше не планирует выпускать o3 как отдельную модель и интегрирует её в GPT-5. Новая модель также улучшит взаимодействие пользователей с ChatGPT, объединив модели серий OpenAI o и GPT, чтобы устранить путаницу при выборе подходящей модели для конкретных задач или запросов. «Нам не нравится слишком большой выбор моделей так же, как и вам, и мы хотим вернуться к единому ИИ», — написал Альтман в недавнем посте на платформе X. Если OpenAI удастся выпустить GPT-5 к концу мая, это совпадёт с конференцией для разработчиков Microsoft Build, которая начнётся 19 мая и будет во многом конкурировать с Google I/O. Напомним, в прошлом году Альтман выступил на Microsoft Build всего через несколько дней после релиза GPT-4o — более быстрой модели, ставшей бесплатной для всех пользователей ChatGPT. Однако релиз GPT-4o стал неожиданностью для Microsoft, поскольку подорвал позиции платных ИИ-сервисов на Azure, включая функции речи и перевода. Ожидается, что релизы GPT-4.5 и GPT-5 на этот раз не принесут неприятных впечатлений Microsoft, которая готовится обновить Copilot после запуска новых моделей OpenAI. Microsoft также работает над улучшением Copilot, пытаясь сделать взаимодействие с ИИ-ассистентом более интуитивным. Ранее предлагались опции «креативный», «сбалансированный» и «точный» для контроля результатов модели, но в рамках масштабного обновления Copilot в прошлом году было решено от этих опций отказаться. Кроме того, Microsoft разрабатывает собственную версию агента Operator от OpenAI, способного взаимодействовать с веб-интерфейсами и автоматически выполнять задачи, аналогично макросам или автопилоту в авиации. Ожидается, что в ближайшие месяцы компания представит свои наработки, сосредоточив внимание на возможностях ИИ-агентов и снижении затрат для бизнеса. Аудитория ChatGPT удвоилась с августа до 400 млн еженедельных пользователей, и это не предел
20.02.2025 [18:53],
Сергей Сурабекянц
OpenAI всё больше становится похожей на коммерческую компанию — сегодня она сообщила, что её аудитория достигла 400 млн активных пользователей в неделю. Судя по всему, темпы рост лишь ускоряется, ведь в декабре 2024 года у компании было «всего» 300 млн пользователей, а в конце августа — 200 млн. 
Источник изображения: unsplash.com OpenAI не раскрыла число платных клиентов с активной подпиской на ChatGPT Plus или ChatGPT Pro. Но точно можно сказать, что в сфере B2B дела у OpenAI идут неплохо — компания сообщила о 2 млн платных корпоративных пользователей, что вдвое больше, чем в сентябре 2024 года. Число обращений разработчиков к API также удвоилось за последние шесть месяцев. Стоит отметить, что OpenAI опубликовала эти показатели всего через несколько недель после того, как китайская DeepSeek представила свою конкурирующую технологию. Похоже, что OpenAI стремится продемонстрировать, что её бизнес процветает, несмотря на давление конкурентов. Бывший техдиректор OpenAI Мира Мурати запустила стартап Thinking Machines Lab, который создаст простой ИИ для людей
19.02.2025 [07:04],
Анжелла Марина
Бывший технический директор компании OpenAI Мира Мурати (Mira Murati), неожиданно покинувшая компанию прошлой осенью, открыла свой собственный стартап в области искусственного интеллекта (ИИ). Новая компания получила название Thinking Machines Lab, и хотя конкретные детали о продуктах и возможностях проекта пока не разглашаются, Мурати готова поделиться первой информацией. 
Источник изображения: Copilot Thinking Machines Lab позиционирует себя как компанию, которая стремится сделать искусственный интеллект более понятным и доступным. В официальном заявлении говорится, что целью компании является создание такой ИИ-системы, которая будет широко понятна, настраиваема, универсальна и функциональна. Для достижения этой цели стартап обещает регулярно публиковать технические исследования и код, обеспечивая определённый уровень прозрачности. Как отмечает The Verge, это будет отличать проект Мурати от многих других игроков на рынке, где закрытость часто становится нормой. В пресс-релизе Thinking Machines Lab подчёркивается, что компания сфокусируется не на создании полностью автономных систем, а на продуктах, которые помогут людям взаимодействовать с искусственным интеллектом. «Мы строим будущее, где каждый сможет получить доступ к знаниям и инструментам, чтобы адаптировать ИИ под свои уникальные потребности и цели», — говорится в заявлении компании. Таким образом, можно сделать вывод, что стартап будет ориентирован на пользовательский опыт и персонализацию технологий. Для реализации своих амбициозных планов Мурати собрала команду экспертов мирового уровня. Она привлекла к проекту несколько ключевых специалистов из ведущих ИИ-лабораторий. Среди них — сооснователь OpenAI Джон Шульман (John Schulman), который занял пост главы исследований, а также Барретт Зоф (Barrett Zoph), бывший лидер OpenAI, ставший техническим директором стартапа. По данным The Verge, Шульман активно участвует в наборе команды, проводя встречи с исследователями буквально в нескольких кварталах от штаб-квартиры OpenAI. К проекту также присоединился Джонатан Лахман (Jonathan Lachman), ранее возглавлявший отдел специальных проектов в OpenAI. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2025 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews. kz
![]()
![]()








 MWC 2018
MWC 2018 2018
2018 Computex
Computex






