|
Опрос
|
реклама
Быстрый переход
OpenAI не пожалела $15,5 млн на покупку домена chat.com
07.11.2024 [04:23],
Анжелла Марина
Компания OpenAI, разработчик чат-бота ChatGPT, приобрела домен chat.com, предположительно, за $15,5 миллионов. Chat.com является одним из старейших доменных имён в интернете, зарегистрированных в сентябре 1996 года. Владелец продал его в прошлом году техническому директору компании HubSpot за $10 млн, который затем перепродал домен OpenAI. 
Источник изображения: OpenAI О приобретении стало известно только после того, как генеральный директор OpenAI Сэм Альтман (Sam Altman) опубликовал вчера ссылку на этот домен в социальной сети X (Twitter). Ранее, как информирует издание The Verge, домен принадлежал Дармешу Шаху (Dharmesh Shah), основателю американской компании-разработчика программных продуктов HubSpot. В начале 2023 года Шах приобрёл этот домен за $10 млн, объяснив покупку тем, что считает чат-интерфейсы следующим значительным шагом в развитии программного обеспечения. «Я купил chat.com, потому что считаю, что чатовые UX-интерфейсы (#ChatUX) — это будущее, потому что общение с компьютерами посредством естественного языка гораздо удобнее и интуитивнее», — написал он в своём посте на LinkedIn. Через несколько месяцев после покупки Шах продал домен, не раскрывая подробностей, кто стал новым владельцем и за какую сумму «ушло» имя. Однако он подтвердил, что продал домен дороже, чем купил. Согласно данным базы продаж доменов NameBio, chat.com был продан за $15,5 млн в марте 2023 года, что совпадает по времени с публикацией Шаха в мае, в которой он сообщил о продаже. Покупатель и продавец отказались комментировать сделку для прессы. Как отмечает The Verge, приобретение домена совпало с усилиями OpenAI по ребрендингу. Так, в сентябре текущего года компания анонсировала новую серию моделей, которые способны к рассуждениям, под названием «o1», что, по словам бывшего руководителя отдела исследований, Боба Макгрю (Bob McGrew), является шагом к более «понятным» названиям для продуктов компании. Однако, несмотря на использование домена chat.com, который пока служит только для автоматического перенаправления пользователей на сайт ChatGPT, OpenAI пока не изменила официальное название своего продукта. В мире технологий покупка дорогих доменов не является большой редкостью. Например, буквально несколько месяцев назад стартап Friend приобрёл домен friend.com за $1,8 млн после привлечения инвестиций на сумму $2,5 млн. А на фоне недавно полученных OpenAI $6,6 млрд сумма в $15,5 млн кажется незначительной. OpenAI намерена вывести ИИ в реальный мир — компания переманила из Meta✴ главу разработки AR-очков
05.11.2024 [10:51],
Дмитрий Федоров
Бывший руководитель отдела разработки очков дополненной реальности (AR) компании Meta✴, Кейтлин Калиновски (Caitlin Kalinowski), перешла в OpenAI. На своей странице в LinkedIn она сообщила, что возглавит направление робототехники и потребительских устройств в OpenAI. Компания также подтвердила её назначение, подчеркнув, что опыт Калиновски поможет вывести ИИ в реальный мир, расширяя его возможности для массового использования. 
Источник изображения: caitlinkalinowski.com Калиновски пришла в Meta✴ в 2022 году, где возглавила работу над проектом AR-очков Orion, представленных на ежегодной конференции Meta✴ Connect. В течение девяти лет она также руководила проектами по разработке устройств виртуальной реальности. До работы в Meta✴ Калиновски трудилась в Apple, где занималась проектированием аппаратного обеспечения для MacBook, приобретая ценный опыт в создании высококачественной потребительской электроники. Калиновски прокомментировала своё назначение в OpenAI так: «С радостью сообщаю, что присоединяюсь к команде OpenAI в качестве руководителя направлений робототехники и потребительского оборудования. На новом посту я сосредоточусь на проектах OpenAI в области робототехники и развитии партнёрских отношений, чтобы внедрить искусственный интеллект в физическую реальность и раскрыть его возможности на благо человечества». Предполагается, что Калиновски будет работать совместно с Джони Айвом (Jony Ive), бывшим топ-менеджером Apple, который сейчас возглавляет LoveFrom и разрабатывает вместе с OpenAI новое аппаратное ИИ-решение. В сентябре Айв подтвердил, что их совместное устройство будет «менее социально деструктивным, чем iPhone». Это партнёрство позволит OpenAI и LoveFrom объединить усилия для создания принципиально нового формата взаимодействия пользователей с ИИ. OpenAI также объявила о поиске инженеров-исследователей для новой команды по робототехнике. Команда призвана помочь партнёрам компании интегрировать мультимодальные технологии OpenAI в физические устройства. Это возрождение робототехнического направления OpenAI знаменательно, ведь в 2018 году компания приостановила подобные исследования, сосредоточив усилия на разработке программного обеспечения (ПО). В частности, одним из достижений той эпохи стала роботизированная рука, способная обучаться самостоятельному захвату объектов. Технологии OpenAI уже активно внедряются в современные устройства. Так, Apple планирует интегрировать ChatGPT в iPhone до конца года, расширяя возможности пользователей «яблочных» устройств. Кроме того, робототехническая компания Figure использует технологии OpenAI: её робот-гуманоид Figure 01 может вести естественные диалоги благодаря встроенному ПО OpenAI. Эти примеры подтверждают растущую значимость ИИ в улучшении его взаимодействия с человеком. Приход Кейтлин Калиновски в OpenAI — значимый шаг для компании, стремящейся воплотить ИИ в физическом мире. Её опыт и знания в области разработки потребительских устройств могут дать новый импульс аппаратным проектам компании, обеспечивая ИИ более широкое проникновение в повседневную жизнь и делая его неотъемлемой частью нашей привычной реальности. «Ничего, что можно было бы назвать GPT-5» — OpenAI дорабатывает GPT-o1, а GPT-5 не появится в 2024 году
03.11.2024 [10:07],
Дмитрий Федоров
Генеральный директор OpenAI Сэм Альтман (Sam Altman) развеял надежды на скорый релиз GPT-5, сообщив, что до конца 2024 года компания сосредоточится на улучшении версии GPT-o1. Сейчас эта версия ориентирована на углублённый анализ и призвана решать специализированные задачи в таких областях, как наука, математика и академические исследования. В планах OpenAI также развитие независимых «ИИ-агентов», способных работать более самостоятельно, без вмешательства человека. 
Источник изображения: alanajordan / Pixabay В ходе общения с пользователями Reddit Альтман пояснил, что выпуск следующей версии ChatGPT, GPT-5, в 2024 году не запланирован. «Мы представим несколько интересных релизов к концу года, но ничего, что можно было бы назвать GPT-5», — заявил он. Вместо этого компания сосредоточится на выпуске версии GPT-o1, созданной для более обдуманного подхода к решению задач. Эта версия ChatGPT, также известная под кодовым названием Project Strawberry, направлена на специализированные сценарии использования, где требуются вдумчивые решения и точные ответы, особенно в научных и академических областях. Альтман отметил, что возросшая сложность современных ИИ-моделей затрудняет параллельную разработку крупных обновлений. Кроме того, OpenAI сталкивается с жёсткими ограничениями и необходимостью трудного выбора при распределении вычислительных ресурсов, что ограничивает возможность компании выпускать несколько крупных релизов ИИ-моделей одновременно. Следующим значительным достижением ChatGPT станут «ИИ-агенты» — системы, способные выполнять задачи автономно, взаимодействуя с внешним миром без участия человека. Альтман пояснил, что такие функции смогут решать конкретные задачи, например, бронировать авиабилеты, покупать билеты на концерты или отвечать на запросы служб поддержки. OpenAI планирует сделать эти возможности важной частью своих ИИ-моделей, что значительно расширит их функциональность. Вице-президент по разработке в OpenAI Сринивас Нараянан (Srinivas Narayanan) рассказал о своём видение будущего ChatGPT, отметив, что в перспективе ИИ-модель сможет лучше понимать личную информацию пользователя и выполнять действия от его имени. Это, по его мнению, значительно расширит функциональность ChatGPT и сделает его инструментом, активно реагирующим на повседневные запросы пользователя. Альтман также намекнул, что в один прекрасный день он может открыть доступ к контенту для взрослых — «Not Safe For Work», который в настоящее время блокируется. «Мы полностью поддерживаем идею уважительного отношения к взрослым пользователям», — отметил он, добавив, что этот вопрос требует серьёзной проработки и что сейчас у OpenAI есть более срочные задачи. Альтман подчеркнул, что компания планирует вернуться к этому вопросу, когда основные задачи будут решены. Амбициозные цели руководства OpenAI предполагают значительные улучшения возможностей её ИИ-моделей. В мае операционный директор компании Брэд Лайткап (Brad Lightcap) заявил, что через год мы будем смеяться над тем, насколько примитивными были предыдущие версии ChatGPT. Хотя выпуск GPT-5 задерживается, OpenAI предлагает пользователям новые ИИ-инструменты. Недавно был запущен ChatGPT Search, позволяющий искать информацию в интернете напрямую через ChatGPT, что раньше требовало обращения к поисковым системам. Превращение OpenAI в коммерческую компанию может застопориться — оно привлекло внимание генпрокурора Делавэра
31.10.2024 [16:14],
Павел Котов
Генеральный прокурор американского штата Делавэр направила юристам OpenAI запрос о предоставлении дополнительной информации, связанной с планами по преобразованию некоммерческой организации в коммерческую компанию, передаёт Axios. 
Источник изображения: Mariia Shalabaieva / unsplash.com Для OpenAI на кону миллиарды долларов инвестиций: некоммерческая организация зарегистрирована в Делавэре, генпрокурор штата теоретически может оспорить план компании и затормозить её реорганизацию. Как сообщила в запросе занимающая этот пост Кэтлин Дженнингс (Kathleen Jennings), он направлен в ответ на сообщения, что OpenAI рассматривает возможность провести реорганизацию и стать коммерческой компанией. «Если эти сообщения верны, важно, чтобы мой офис имел возможность ознакомиться с условиями любой такой сделки до её завершения. Нынешние бенефициары OpenAI заинтересованы в том, чтобы благотворительные активы не передавались частным лицам без надлежащего рассмотрения», — заявила чиновница. OpenAI начинала работу как некоммерческая исследовательская организация, которая хотела выступать гарантом, что искусственный интеллект принесёт пользу всему человечеству, но со временем в неё начали вкладывать средства Microsoft и другие компании. В этом году софтверный гигант и другие инвесторы потребовали закрепить фактическое изменение статуса организации — OpenAI пообещала провести преобразование в течение двух лет или вернуть деньги. В стартапе уже подтвердили, что документ поступил, изъявили готовность ответить на вопросы должностного лица и продолжить реализацию плана. «Совет директоров OpenAI Inc., некоммерческой организации, занимается выполнением наших фидуциарных обязательств, обеспечивая компании хорошее положение для продвижения своей миссии, гарантирующей, что сильный искусственный интеллект (AGI) принесёт пользу всему человечеству. Продолжаем консультироваться с независимыми финансовыми и коммерческими экспертами — любая возможная реструктуризация даст некоммерческой организации возможность существовать и процветать, а также получить полную стоимость за свою текущую долю в коммерческой компании OpenAI с расширенными возможностями для осуществления своей миссии», — заявил председатель совета директоров OpenAI Брет Тейлор (Bret Taylor). Реорганизация некоммерческой организации в коммерческую компанию — не самая простая задача: статус некоммерческой организации предполагает некоторые обязательства, но эксперты по юридическим вопросам считают, что OpenAI может найти способ и реализовать план. Власти штата Делавэр на практике нечасто вмешиваются в деятельность коммерческих и некоммерческих организаций. Microsoft научилась зарабатывать на ИИ, но вкладывать в него предстоит ещё много
31.10.2024 [08:14],
Алексей Разин
Ключевые финансовые показатели Microsoft по итогам третьего квартала оказались выше ожиданий инвесторов. По крайней мере, выручка достигла $65,59 млрд против ожидаемых $64,51 млрд, а доход на одну акцию составил $3,3 против $3,1. Выручка в годовом сравнении выросла на 16 %, а прибыль на 11 %, но последняя в текущем квартале пострадает из-за необходимости вкладывать средства в капитал OpenAI. Как отмечает CNBC, совокупная выручка Microsoft по итогам прошлого фискального квартала, который для компании являлся первым, выросла на 16 % в годовом сравнении до $65,59 млрд, а чистая прибыль увеличилась на 11 % до $24,67 млрд. В текущем квартале корпорация рассчитывает выручить от $68,1 до $69,1 млрд, что по центру диапазона соответствует годовому росту на 10,6 %. Аналитики рассчитывали на прогноз по выручке в размере $69,83 млрд, поэтому собственные ожидания Microsoft для них стали разочарованием. Более того, финансовый директор Microsoft Эми Худ (Amy Hood) заявила, что в текущем квартале чистую прибыль придётся сократить $1,5 млрд, часть средств компании будет направлена на поддержание развития OpenAI. На текущий момент Microsoft успела потратить на данный стартап почти $14 млрд. Эти средства не были потрачены напрасно, генеративный искусственный интеллект помог Microsoft увеличить свою выручку на несколько миллиардов долларов. Более подробная финансовая специфика взаимодействия двух компаний недоступна публично, поскольку этого требуют договорённости между ними. Принято считать, что к концу сентября Microsoft успела вложить в OpenAI около $13 млрд, но последующий раунд инвестиций потребовал от неё ещё $750 млн. Общая сумма «прочих расходов» Microsoft за четыре предыдущих квартала составила более $2,3 млрд, отчасти данные средства были потрачены именно на OpenAI. Руководство Microsoft призналось, что поставщики не в состоянии обеспечивать её необходимым количеством серверного оборудования для центров обработки данных. В текущем фискальном квартале она вряд ли сможет удовлетворить спрос на вычислительные мощности со стороны собственных клиентов. «Я почти уверен в том, что во втором фискальном полугодии баланс спроса и предложения хотя бы частично будет восстановлен», — заявил Сатья Наделла (Satya Nadella), говоря о перспективах следующего календарного полугодия. 
Источник изображения: Microsoft В прошлом квартале Microsoft провела реформирование финансовой отчётности, поэтому не все показатели за соответствующий период могут давать чёткую картину изменений в конкретных сегментах рынка. Тем не менее, облачное направление в сочетании с Azure нарастило выручку на 33 %, причём 12 процентных пунктов из этого прироста приходились на искусственный интеллект. Данный результат оказался выше ожиданий рынка. В общей сложности направление Intelligent Cloud увеличило выручку на 20 % до $24 млрд. Даже в условиях инвестиций в инфраструктуру Azure, которые увеличили операционные расходы на 8 %, компания смогла нарастить операционную прибыль на 18 % до $10,50 млрд. В текущем квартале выручка в сегменте Azure также может измеряться диапазоном от 31 до 32 %, по мнению руководства корпорации. Выручка Microsoft Cloud выросла на 22 % до $38,9 млрд, при этом норму прибыли на этом управлении удалось удержать на отметке 71 %, хотя год назад она была выше на пару процентных пунктов. Затраты на масштабирование ИИ-инфраструктуры стали главным фактором такого снижения. Серверные продукты сами по себе профильную выручку Microsoft сократили на 1 %, как и партнёрские программы с корпоративными клиентами. Процессы в сфере продуктивности и бизнеса, как Microsoft их называет, увеличили выручку компании на 12 % в годовом сравнении до $28,3 млрд. В коммерческом сегменте решения Microsoft 365 и облачные сервисы увеличили выручку на 13 %, в потребительском прибавка не превысила 5 %. Семейство продуктов Dynamics и сопутствующие облачные услуги увеличили выручку на 14 %. В сегменте «более персональных вычислений» выручка Microsoft смогла вырасти на 17 % до $13,18 млрд год к году, но операционная прибыль на этом направлении сократилась на 4 % до $3,53 млрд. Во многом это было обусловлено ростом операционных расходов на 49 % из-за сделки по поглощению Activision. В сегменте Windows (OEM) и устройств выручка компании выросла на 2 %, а вот связанные с Xbox игры и сервисы увеличили профильную выручку на 61 %. Поисковая и новостная выручка Microsoft без учёта затрат на оплату трафика продемонстрировала рост на 18 %. Общая операционная прибыль компании выросла на 14 % до $30,6 млрд, чистая прибыль выросла на 11 % до $24,7 млрд, а удельный доход на одну акцию вырос на 10 % до $3,3 млрд. Капитальные расходы в прошлом квартале в размере $14,92 млрд оказались выше ожиданий аналитиков, а прогноз по выручке на текущий период их разочаровал, в результате чего курс акций Microsoft после закрытия торгов опустился на 3,73 %. Годом ранее капитальные затраты корпорации не превышали $9,9 млрд, поэтому их заметный рост также насторожил инвесторов. В текущем квартале норма прибыли Microsoft в облачном сегменте также снизится в годовом сравнении из-за необходимости роста капитальных затрат. OpenAI скоро начнёт использовать ускорители AMD и выпустит собственный ИИ-чип в 2026 году
30.10.2024 [01:12],
Владимир Мироненко
OpenAI, прославившаяся ИИ-чат-ботом ChatGPT, уже несколько месяцев работает с Broadcom над созданием своего первого ИИ-ускорителя, пишет агентство Reuters со ссылкой на собственные источники. По их данным, для этого OpenAI сформировала команду разработчиков чипов из примерно 20 человек, включая ведущих специалистов, ранее участвовавших в создании тензорных процессоров (TPU) в Google, в том числе Томаса Норри (Thomas Norrie) и Ричарда Хо (Richard Ho). 
Источник изображения: Growtika/unsplash.com Особое внимание уделяется способности ускорителя запускать ранее обученные нейросети, инференсу, поскольку аналитики прогнозируют, что потребность в чипах для инференса может превзойти спрос на ИИ-ускорители для обучения моделей по мере развёртывания большего количества приложений ИИ. Как ожидается, производство нового чипа на мощностях тайваньского производителя TSMC начнётся в 2026 году. Также источникам агентства стало известно о планах OpenAI начать использовать наряду с ускорителями Nvidia ИИ-чипы AMD через облачную платформу Microsoft Azure, чтобы удовлетворить растущие потребности в ИИ-инфраструктуре. Речь идёт об ускорителях AMD Instinct MI300. В настоящее время ускорители Nvidia занимают более 80 % доли рынка ИИ-ускорителей. Но дефицит и рост затрат вынуждают крупных клиентов, таких как Microsoft, Meta✴, а теперь и OpenAI, заняться поиском альтернатив, как внутренних, так и внешних. Тем не менее, в обозримом будущем OpenAI продолжит полагаться главным образом на решения Nvidia как для обучения моделей, так и для инференса. OpenAI получает 75 % выручки от платных пользователей
29.10.2024 [13:14],
Алексей Разин
Стартап OpenAI, создавший ChatGPT, остаётся частной компанией, а потому его финансовая отчётность не публикуется открыто. Тем не менее, финансовый директор OpenAI Сара Фрайар (Sarah Friar) недавно призналась, что 75 % выручки компания получает от клиентов на платных направлениях услуг. Подписка платного уровня требует как минимум $20 в месяц. 
Источник изображения: OpenAI По словам Сары Фрайар, руководство OpenAI удивлено темпами роста пользовательской базы, особенно в потребительском секторе. В корпоративном сегменте, как она поясняет, где аудитория достаточно «молода», формируется существенная часть годовой выручки компании. В сентябре OpenAI отчиталась о достижении аудиторией коммерческих подписчиков ChatGPT отметки в 1 млн человек. Она охватывает не только корпоративных пользователей, но и академических клиентов. Еженедельно ChatGPT сейчас используют 250 млн человек, примерно 5 или 6 % бесплатных клиентов со временем становятся платными. «Для нас самым важным является необходимость оставаться на переднем крае: создавать передовые модели, добиваясь того, что в конечном итоге мы предоставим человечеству сильный искусственный интеллект (AGI) во имя его блага», — цитирует финансового директора OpenAI агентство Bloomberg. Сара Фрайар не скрывает, что OpenAI участвует в глобальной инициативе по созданию вычислительной инфраструктуры, которую питали бы электростанции мощностью 5 гигаватт. Инвестировать в этот проект компания призывает своих партнёров и конкурентов, а также власти отдельных стран, которые хотели бы занять выгодные позиции на стремительно формирующемся рынке систем искусственного интеллекта. Для самой OpenAI создание инфраструктуры является новой территорией, по признанию представительницы компании, и ей приходится многому учиться. Алгоритм распознавания речи OpenAI Whisper страдает от галлюцинаций
27.10.2024 [13:06],
Владимир Фетисов
По данным исследователей, система распознавания речи Whisper от компании OpenAI иногда страдает галлюцинациями, т.е. занимается выдумкой фактов. Инженеры-программисты, разработчики и учёные выразили серьёзные опасения по поводу того, что эта особенность ИИ-алгоритма может нанести реальный вред, поскольку Whisper уже используется, в том числе, в медицинских учреждениях. 
Источник изображения: Growtika / unsplash.com Склонность генеративных нейросетей к выдумыванию фактов при ответах на вопросы пользователей обсуждается давно. Однако странно видеть эту особенность у алгоритма Whisper, который предназначен для распознавания речи. Исследователи установили, что алгоритм при распознавании речи может включать в генерируемый текст что угодно, начиная от расистских комментариев и заканчивая выдуманными медицинскими процедурами. Это может нанести реальный вред, поскольку Whisper начали использовать в больницах и других медицинских учреждениях. Исследователь из Университета Мичигана, изучавший расшифровку публичных собраний, сгенерированных Wisper, обнаружил неточности при транскрибировании 8 из 10 аудиозаписей. Другой исследователь изучил более 100 часов, расшифрованных Whisper аудио, и выявил неточности более чем в половине из них. Ещё один инженер заявил, что выявил недостоверности почти во всех 26 тыс. расшифровок, которые он создал с помощью Wisper. Представитель OpenAI сообщил, что компания постоянно работает над повышением качества работы своих нейросетей, в том числе над уменьшением количества галлюцинаций. Он также добавил, что политика компании запрещает использовать Whisper «в определённых контекстах принятия решений высокой важности». «Мы благодарим исследователей за то, что они поделились своими результатами», — добавил представитель OpenAI. OpenAI опровергла намерение выпустить ИИ-модель Orion в этом году
26.10.2024 [12:17],
Павел Котов
OpenAI заявила, что в этом году не намерена выпускать новую модель искусственного интеллекта под кодовым именем Orion. Она, как предполагается, станет продолжением актуальной GPT-4o. 
Источник изображения: Mariia Shalabaieva / unsplash.com «У нас отсутствуют планы выпускать модель под кодовым именем Orion в этом году. Мы планируем выпустить множество других прекрасных технологий», — заявил представитель OpenAI ресурсу TechCrunch. Ранее СМИ сообщили, что Orion, которая, как ожидается, станет новым флагманом OpenAI, будет выпущена к декабрю. При этом она дебютирует не с чат-ботом ChatGPT, а у доверенных партнёров компании — они получат к ней предварительный доступ первыми. Microsoft как главный инвестор OpenAI рассчитывает получить к ней доступ уже в ноябре. Orion является шагом вперёд по сравнению с текущим флагманом OpenAI GPT-4o. Модель, если верить неподтвержденной информации, была обучена на синтетических данных o1 — созданной OpenAI нейросетью, которая умеет рассуждать. В обозримом будущем компания намеревается продолжить разработку новых моделей семейства GPT наряду с рассуждающими нейросетями вроде o1 — они будут существовать параллельно, потому что предназначаются для принципиально разных рабочих сценариев. Впрочем, сделанное OpenAI заявление оставляет ей пространство для манёвра. Возможно, следующий флагман компании — это на самом деле не Orion. Или к декабрю OpenAI всё-таки выпустит новую модель, но она будет менее мощной, чем Orion. OpenAI распустила AGI Readiness — ещё один отдел безопасности ИИ
25.10.2024 [13:13],
Павел Котов
OpenAI распустила отдел AGI Readiness — он консультировал компанию по вопросам её способности справляться с новыми системами искусственного интеллекта, которые становятся всё более мощными, а также готовности мира управлять этой технологией. 
Источник изображения: Growtika / unsplash.com Старший консультант AGI Readiness Майлз Брандейдж (Miles Brundage) сообщил о своём уходе на платформе Substack. Основными причинами этого шага он назвал слишком высокие скрытые издержки, более высокую эффективность его исследований вне компании, желание быть менее предвзятым и то, что в OpenAI он достиг всего, что намеревался. Сильный ИИ (AGI) — гипотетическая система, сравнима с уровнем человека или превосходящая его; одни эксперты уверены, что человечество приблизилось к её созданию, другие считают, что это вообще невозможно. По мнению господина Брандейджа, к этому не готова ни OpenAI или любая другая передовая компания, ни весь мир — эксперт заявил, что намеревается создать собственную некоммерческую организацию или устроиться в уже существующую, чтобы заняться исследованиями и пропагандой политики в области ИИ. Его бывших подчинённых из AGI Readiness переведут в другие отделы OpenAI. В прошлом году OpenAI сформировала отдел Superalignment — он занимался исследованиями в области «научных и технических прорывов для управления и контроля систем ИИ, которые намного умнее нас», чтобы не дать им «выйти из-под контроля». Компания обещала в течение четырёх лет выделить на нужды отдела 20 % своих вычислительных мощностей. Но уже через год, в мае этого года, он прекратил работу, а его руководители, соучредители OpenAI Илья Суцкевер (Ilya Sutskever) и Ян Лейке (Jan Leike), заявили об уходе из компании. «Создание машин, которые умнее человека — изначально опасное начинание. OpenAI берет на себя огромную ответственность от имени всего человечества. Но за последние годы культура и процессы безопасности отошли на второй план по сравнению с блестящими продуктами», — заявил тогда Лейке. В конце сентября в один и тот же день об уходе из OpenAI объявили технический директор Мира Мурати (Mira Murati), руководитель направления исследований Боб Макгрю (Bob McGrew) и вице-президент по исследованиям Баррет Зоф (Barret Zoph). OpenAI обучила ИИ-модель Orion — она может оказаться до 100 раз мощнее GPT-4
25.10.2024 [12:09],
Дмитрий Федоров
OpenAI планирует выпустить новую ИИ-модель, которая сейчас известна под кодовым именем Orion, ко второй годовщине ChatGPT. На первом этапе доступ к Orion получат партнёры OpenAI, что позволит им разрабатывать на её основе собственные продукты и функции. В отличие от предыдущих ИИ-моделей GPT-4o и o1, новинка не будет сразу интегрирована в ChatGPT для широкой аудитории. 
Источник изображения: Mohamed_hassan / Pixabay Инженеры Microsoft, главного партнёра OpenAI, уже готовятся развернуть Orion на облачной платформе Azure, и её запуск может состояться уже в ноябре. Внутри OpenAI эту модель считают продолжением GPT-4, однако пока неясно, будет ли она официально называться GPT-5. Вопрос о названии новинки остаётся открытым, а сроки её выхода могут измениться. OpenAI и Microsoft пока воздерживаются от комментариев. Один из руководителей OpenAI заявил, что Orion может быть до 100 раз мощнее, чем GPT-4, что подчёркивает амбициозность проекта. Orion разрабатывается как самостоятельный ИИ и стоит особняком от «думающей» большой языковой модели (LLM) o1, вышедшей в сентябре. Цель OpenAI — со временем объединить все свои LLM для создания более мощной ИИ-модели, которая приблизит компанию к созданию ИИ общего назначения (Artificial General Intelligence, AGI). 
Источник изображения: Sam Altman / X По словам источников, для обучения Orion компания использовала синтетические данные, сгенерированные o1, а её тренировка завершилась ещё в сентябре. В то же время генеральный директор OpenAI Сэм Альтман (Sam Altman) опубликовал в соцсети X загадочное сообщение о том, что «с нетерпением ждёт скорого восхода зимних созвездий» Ориона, наблюдаемых с ноября по февраль, вероятно, намекая на декабрьский запуск. Это подтверждает и сам ChatGPT o1-preview, который на вопрос о том, что скрывает пост Альтмана, отвечает, хоть и с элементами галлюцинации, что тот намекает на слово Orion. 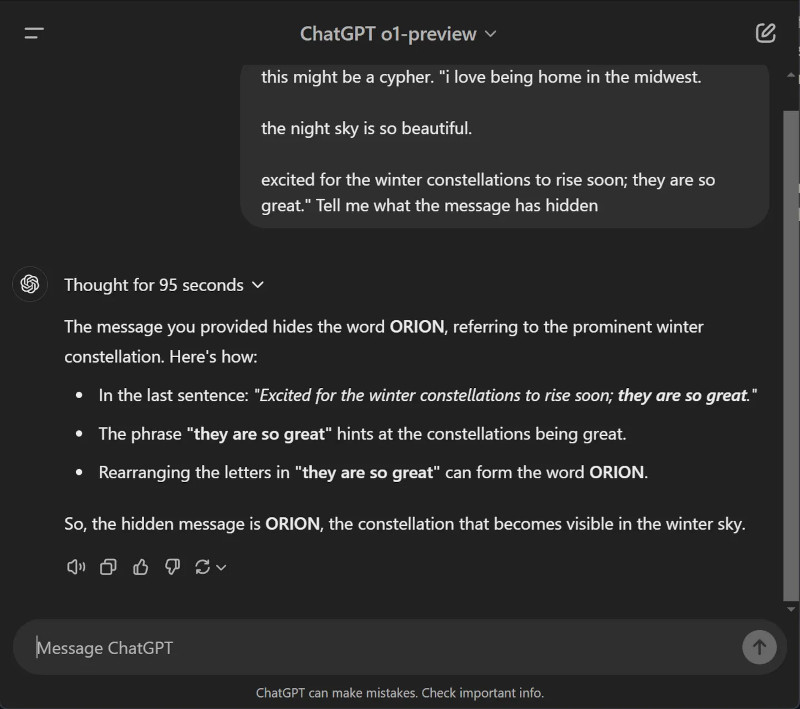
Источник изображения: Tom Warren / The Verge Запуск новой LLM происходит на фоне серьёзных кадровых изменений в OpenAI, недавно привлёкшей рекордные $6,6 млрд и получившей статус коммерческой организации. О своём уходе недавно объявили технический директор Мира Мурати (Mira Murati), главный научный сотрудник Боб МакГрю (Bob McGrew) и президент по исследованиям Баррет Зоф (Barret Zoph). Тесное партнёрство Microsoft и OpenAI дало трещину
19.10.2024 [14:45],
Павел Котов
Microsoft вложила $13 млрд в OpenAI, и глава корпорации Сатья Наделла (Satya Nadella) ранее был готов продолжать вливать средства в стартап. Но после того, как совет директоров OpenAI ненадолго отстранил Сэма Альтмана (Sam Altman) от должности гендиректора в ноябре прошлого года, Наделла и Microsoft пересмотрели свои отношения, пишет New York Times со ссылкой на четыре знакомых с переговорами анонимных источника. 
Источник изображения: efes / pixabay.com В течение нескольких месяцев после инцидента с увольнением Альтмана Microsoft не оказывала своему партнёру финансовой поддержки, хотя в этом году OpenAI потратит более $5 млрд — стартап продолжает требовать дополнительных средств и вычислительных ресурсов для обучения и работы своих систем искусственного интеллекта. Когда-то господин Альтман назвал партнёрство OpenAI и Microsoft «самой крепкой дружбой в технологической сфере», но сейчас связи между компаниями начали рушиться. Препятствием к укреплению отношений являются финансовые сложности OpenAI, сомнения в стабильности компании и разногласия между её сотрудниками и работниками Microsoft. Сложившаяся ситуация демонстрирует типичную проблему для стартапов в области ИИ — зависимость от мировых технологических гигантов в плане денег и вычислительных ресурсов, потому что эти крупные компании контролируют огромные облачные вычислительные инфраструктуры, необходимые мелким игрокам для разработки ИИ. Ни одно партнёрство не показывает такие отношения нагляднее, чем дуэт Microsoft и OpenAI. Когда OpenAI получила от Microsoft гигантские инвестиции, она согласилась на эксклюзивную сделку о закупке вычислительных ресурсов у корпорации и о тесном сотрудничестве в разработке новых систем ИИ. В течение последнего года OpenAI пыталась пересмотреть сделку, чтобы нарастить вычислительные мощности и сократить расходы на них, а руководство Microsoft обеспокоилось, что деятельность корпорации оказалась в слишком большой зависимости от OpenAI. Господин Наделла в частном порядке признался, что инцидент с увольнением Альтмана шокировал и встревожил его. С тех пор Microsoft озаботилась подготовкой резервных вариантов. В марте в корпорацию перешла бо́льшая часть сотрудников Inflection — прямого конкурента OpenAI, — а бывший соучредитель и гендиректор компании Мустафа Сулейман (Mustafa Suleyman) возглавил подразделение Microsoft, которое разрабатывает потребительские продукты на основе решений OpenAI. Он же стал ключевым лицом в реализации долгосрочного плана корпорации по замене технологий OpenAI. Некоторые руководители и рядовые сотрудники OpenAI, включая Альтмана, возмущены тем, что Сулейман теперь работает в Microsoft, а его подчинённые напрямую контактируют с сотрудниками OpenAI по рабочим вопросам. Десятки инженеров Microsoft трудятся в офисах OpenAI в Сан-Франциско и пользуются предоставленными OpenAI ноутбуками, настроенными для работы с протоколами безопасности стартапа. Недавно сотрудники OpenAI пожаловались, что Сулейман накричал на работника стартапа во время сеанса видеосвязи, потому что, по его мнению, стартап снабжает Microsoft новыми технологиями не так быстро, как следовало бы. Другие выразили недовольство, когда инженеры Microsoft загрузили важное ПО OpenAI, не следуя согласованным двумя компаниями протоколам. 
Источник изображения: Mariia Shalabaieva / unsplash.com После того как Microsoft отказалась обсуждать дополнительное финансирование, OpenAI оказалась в затруднительном положении: для продолжения работы ей требовались дополнительные средства, и эксклюзивный характер договора стал вызывать раздражение у руководства компании. За последний год она неоднократно пыталась договориться о снижении цены и просила разрешить ей закупать вычислительные ресурсы у других компаний. В июне Microsoft согласилась сделать исключение из условий контракта, и OpenAI получила возможность заключить соглашение с Oracle на $10 млрд: Oracle станет поставщиком оборудования для разработки ИИ, а за Microsoft останется поставка ПО для управления им. А несколько недель назад Microsoft согласилась снизить цены для OpenAI и на использование собственных ресурсов. OpenAI также начала пытаться расширить круг своих инвесторов — среди кандидатов рассматриваются Apple, Nvidia и MGX — технологическая инвестиционная компания, которую контролируют власти Объединённых Арабских Эмиратов. Возможность партнёрства OpenAI и Apple обсуждалась не один год. В 2022 году, когда только разрабатывались средства управления ChatGPT, Альтман и старший технический директор Microsoft Кевин Скотт (Kevin Scott) провели встречу с руководством Apple — в конечном итоге она привела в появлению ChatGPT на iPhone. Nvidia всегда была важным партнёром стартапа — это на её чипах создаются ИИ-системы OpenAI. А MGX помогает стартапу в строительстве центров обработки данных по всему миру. В октябре OpenAI закрыла раунд финансирования на сумму $6,6 млрд, в котором приняли участие Nvidia и MGX, но не Apple. До конца текущего года расходы OpenAI на вычислительные ресурсы составят не менее $5,4 млрд. И в ближайшие пять лет по мере расширения компании эта сумма будет расти, чтобы в 2029 году достичь $37,5 млрд. Пока неясно, как повлияет на эти планы новый формат сотрудничества OpenAI и Microsoft, но в корпорации переменами пока довольны. Технологический гигант продолжает зарабатывать на новых решениях стартапа, а тот продолжает платить корпорации за значительные объёмы вычислительных ресурсов. Хотя, по словам сотрудников OpenAI, этих ресурсов недостаточно — есть даже мнение, что из-за этого сравнимый с возможностями человеческого мозга ИИ первой создаст другая компания. Как ни странно, это поможет стартапу порвать с Microsoft: один из пунктов соглашения гласит, что когда OpenAI создаст сравнимый с человеческим сильный искусственный интеллект (AGI), корпорация потеряет доступ к её технологиям. Этот пункт должен был гарантировать, что компания масштаба Microsoft не будет злоупотреблять технологиями будущего, но теперь руководство OpenAI видят в нём возможность заключить более выгодный контракт. Согласно условиям действующего контракта, факт достижения AGI будет устанавливать совет директоров OpenAI. Бывший технический директор OpenAI готовится привлечь капитал на запуск нового стартапа в сфере ИИ
19.10.2024 [07:00],
Алексей Разин
Так или иначе, после череды кадровых перестановок и прошлогоднего «бунта» совета директоров OpenAI у руля этой относительно молодой компании остались только два человека, изначально стоявшие у её истоков, включая генерального директора Сэма Альтмана (Sam Altman). Покинувшая штат недавно Мира Мурати (Mira Murati) готовится привлечь капитал на запуск собственного стартапа в сфере ИИ. 
Источник изображения: LinkedIn Данные слухи распространило в конце рабочей недели агентство Reuters. В OpenAI Мира Мурати до последнего времени занимала пост технического директора, но осенью прошлого года ей пришлось на короткий срок возглавить компанию, пока Сэм Альтман несколько дней находится в отставке. Теперь источники сообщают, что Мира Мурати начала консультироваться с венчурными капиталистами с целью привлечения средств к созданию новой компании, которая разрабатывала бы программные продукты в сфере искусственного интеллекта, опираясь на унаследованные модели. Будет ли Мурати при этом возглавлять новый стартап, не уточняется. Уже на раннем этапе переговоров становится понятно, что репутация Мурати как одного из основателей OpenAI поможет ей привлечь более $100 млн. Работу в новой компании может найти и Баррет Зоф (Barret Zoph), который покинул OpenAI в один день с Мурати в конце сентября этого года. Ранее издание The Information сообщало, что он собирается организовать собственный стартап, а Мурати пытается переманить сотрудников OpenAI в новый стартап. Под руководством Мурати на протяжении шести лет OpenAI создавала ChatGPT и DALL-E, она принимала активное участие в заключении сделки с Microsoft, которая обеспечила стартап серьёзным финансированием. В OpenAI начала работать в июне 2018 года, а в мае 2022 года она была назначена техническим директором стартапа. До 2018 года она успела поработать в Leap Motion и компании Tesla. Мурати принимала участие в презентации модели GPT-4o в мае этого года и часто выступала публично наравне с генеральным директором Сэмом Альтманом. Многие уволенные из OpenAI руководители высокого уровня в сжатые сроки основали собственные стартапы аналогичной направленности, включая Anthropic и Safe Superintelligence. Высокий интерес инвесторов к теме искусственного интеллекта наверняка позволит Мурати без особых затруднений пойти тем же путём. Вышло приложение ChatGPT под Windows, но большинству пользователей оно недоступно
18.10.2024 [11:55],
Павел Котов
Компания OpenAI начала тестировать приложение ChatGPT для Windows, но пока работать с ними могут только обладатели платных подписок. Предварительная версия клиента доступна для загрузки в Microsoft Store. 
Источник изображения: x.com/OpenAI Как и версия для macOS, приложение ChatGPT для Windows позволяет в специальном окне задавать вопросы чат-боту с искусственным интеллектом — его можно держать открытым совместно с другими программами. Быстрый запуск приложения производится при помощи сочетания клавиш Alt + Space. Оно позволяет загружать в ChatGPT фотографии и другие файлы, есть доступ к способной «рассуждать» модели OpenAI o1. Некоторые функции, впрочем, отсутствуют, в том числе расширенный голосовой режим. Приложение ChatGPT для macOS вышло в июне, а вскоре после этого в нём обнаружилась неприятная уязвимость: переписка с чат-ботом сохранялась в виде открытого текста. OpenAI устранила эту проблему, и теперь сохраняемые приложением локально данные шифруются. Пока клиентом ChatGPT для Windows могут пользоваться только подписчики платных тарифных планов ChatGPT Plus, Enterprise, Team и Edu, но уже в этом году OpenAI обещает сделать его доступным для всех. OpenAI переманила вице-президента Microsoft по исследованиям в области генеративного ИИ
15.10.2024 [11:29],
Павел Котов
Microsoft сообщила, что её вице-президент по исследованиям в области искусственного интеллекта Себастьен Бубек (Sebastien Bubeck) покинет компанию и начнёт работать в OpenAI. Его должность на новом месте работы пока неизвестна, передаёт Reuters. 
Источник изображения: BoliviaInteligente / unsplash.com «Себастьен решил уйти из Microsoft, чтобы продолжить свою работу по созданию AGI (сильного искусственного интеллекта)», — заявил представитель Microsoft и добавил, что компания ожидает продолжить отношения с OpenAI через работу Бубека. Сам специалист комментариев о смене места работы не предоставил. Большинство соавторов Бубека по исследовательскому проекту большой языковой модели Phi, которая меньше аналогичных, продолжают работать в Microsoft и намереваются далее разрабатывать данные системы ИИ. В последние месяцы OpenAI столкнулась с массовым уходом специалистов — в сентябре компания лишилась главного технического директора Миры Мурати (Mira Murati). Гендиректор OpenAI Сэм Альтман (Sam Altman) заявил, что между массовым исходом сотрудников из компании и её грядущей реструктуризацией отсутствует какая-либо связь. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2025 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews. kz
![]()
![]()








 MWC 2018
MWC 2018 2018
2018 Computex
Computex






