|
Опрос
|
реклама
Быстрый переход
Исследование Apple показало, что ИИ-модели не думают, а лишь имитируют мышление
13.10.2024 [19:36],
Анжелла Марина
Исследователи Apple обнаружили, что большие языковые модели, такие как ChatGPT, не способны к логическому мышлению и их легко сбить с толку, если добавить несущественные детали к поставленной задаче, сообщает издание TechCrunch. 
Источник изображения: D koi/Unsplash Опубликованная статья «Понимание ограничений математического мышления в больших языковых моделях» поднимает вопрос о способности искусственного интеллекта к логическому мышлению. Исследование показало, что большие языковые модели (LLM) могут решать простые математические задачи, но добавление малозначимой информации приводит к ошибкам. Например, модель вполне может решить такую задачу: «Оливер собрал 44 киви в пятницу. Затем он собрал 58 киви в субботу. В воскресенье он собрал вдвое больше киви, чем в пятницу. Сколько киви у Оливера?». Однако, если при этом в условие задачи добавить фразу «в воскресенье 5 из этих киви были немного меньше среднего размера», модель скорее всего вычтет эти 5 киви из общего числа, несмотря на то, что размер киви не влияет на их количество. 
Источник изображения: Copilot Мехрдад Фараджтабар (Mehrdad Farajtabar), один из соавторов исследования, объясняет, что такие ошибки указывают на то, что LLM не понимают сути задачи, а просто воспроизводят шаблоны из обучающих данных. «Мы предполагаем, что это снижение [эффективности] связано с тем фактом, что современные LLM не способны к подлинному логическому рассуждению; вместо этого они пытаются воспроизвести шаги рассуждения, наблюдаемые в их обучающих данных», — говорится в статье. Другой специалист из OpenAI возразил, что правильные результаты можно получить с помощью техники формулировки запросов (prompt engineering). Однако Фараджтабар отметил, что для сложных задач может потребоваться экспоненциально больше контекстных данных, чтобы нейтрализовать отвлекающие факторы, которые, например, ребёнок легко бы проигнорировал. Означает ли это, что LLM не могут рассуждать? Возможно. Никто пока не даёт точного ответа, так как нет чёткого понимания происходящего. Возможно, LLM «рассуждают», но способом, который мы пока не распознаём или не можем контролировать. В любом случае эта тема открывает захватывающие перспективы для дальнейших исследований. Китайские хакеры пытались взломать OpenAI, используя её же ChatGPT
09.10.2024 [18:29],
Сергей Сурабекянц
OpenAI подверглась нападению китайских киберпреступников, которые отправляли вредоносное ПО сотрудникам OpenAI в архивных файлах. «Мы пресекли деятельность предполагаемого китайского злоумышленника SweetSpecter, который безуспешно занимался фишинговыми атаками на личные и корпоративные адреса электронной почты сотрудников OpenAI», — заявили в OpenAI. Примечательно, что хакеры из группы SweetSpecter использовали инструменты OpenAI для проведения своих операций. 
Источник изображения: pexels.com OpenAI заблокировала неуказанное количество учётных записей, которые, по её мнению, связаны с хакерской группой SweetSpecter. Сообщается, что киберпреступники используют инструменты OpenAI для таких целей, как «разведка, исследование уязвимостей, поддержка сценариев, уклонение от обнаружения аномалий и разработка». В процессе фишинговой атаки хакеры отправляли сотрудникам OpenAI официальные письма об обнаруженных недостатках в работе ChatGPT с вложениями в виде zip-файлов, в которых якобы находилось подробное описание «проблемы» отправителя. При открытии zip-файла появлялся документ с фальшивым списком сообщений об ошибках ChatGPT, а в это время в фоновом режиме вредоносная программа SugarGh0st RAT захватывала контроль над ПК, позволяя хакерам похищать данные и получать доступ к компьютеру. По данным OpenAI, эти атаки были безуспешными — письма блокировались внутренними системами безопасности OpenAI и не попадали в корпоративные почтовые ящики. Компания особо отметила, что эти атаки не имеют отношения к успешному взлому учётной записи OpenAI Newsroom X в прошлом месяце, когда хакерам удалось запустить криптофишинговую аферу, которая опустошала кошельки жертв. Фишинговые электронные письма — настоящая проблема как для обычных потребителей, так и для сотрудников технологических компаний. Фишинговые атаки могут привести к масштабным утечкам корпоративных данных или потере средств и могут осуществляться по электронной почте, телефону или при помощи текстовых сообщений. Противостоять им помогает изучение наиболее распространённых методов и типов атак и элементарная цифровая гигиена. Согласно данным американской компании по кибербезопасности Palo Alto Networks, ранее группа SweetSpecter в интересах китайского правительства атаковала посольства, министерства, правительственных чиновников и другие политические организации. Главный разработчик ИИ-видеогенератора Sora сбежал из OpenAI в Google DeepMind
04.10.2024 [19:19],
Сергей Сурабекянц
Тим Брукс (Tim Brooks), возглавлявший вместе с Уильямом Пиблзом (William Peebles) в OpenAI разработку ИИ-генератора видео Sora, сообщил о своём переходе в ИИ-лабораторию Google DeepMind. Там он займётся исследованиями в области создания видео при помощи ИИ и «симуляторами мира». По слухам, уход Брукса вызван техническими проблемами Sora и отставанием в производительности от конкурирующих систем Luma, Runway и других. 
Источник изображения: Pixabay Генеральный директор Google DeepMind Демис Хассабис (Demis Hassabis) уверен, что приход Брукса поможет «сделать реальностью давнюю мечту о симуляторе мира». Под этим термином подразумеваются такие модели ИИ, как недавно выпущенная Genie, которая может генерировать играбельные, управляемые виртуальные миры из синтезированных изображений, реальных фотографий и даже эскизов. В OpenAI Брукс был одним из первых исследователей, работавших над моделью ИИ Sora, представленной в январе 2023 года. Осведомлённые источники связывают его уход с техническими проблемами, от которых, как утверждается, страдает система — ей требовалось более 10 минут для создания 1-минутного видеоклипа. Сообщается, что OpenAI находится в процессе обучения улучшенной модели Sora, которая сможет генерировать видео гораздо быстрее. Весной 2024 года Google представила собственную модель генерации видео под названием Veo. Ожидается, что Veo скоро станет доступна создателям контента в сервисе коротких видео YouTube Shorts. Похоже, что OpenAI пока уступает конкурентам в продвижении разработок по созданию видеоконтента. В начале прошлого месяца Runway подписала соглашение со студией Lionsgate на обучение пользовательской модели видео на основе каталога фильмов Lionsgate. В это же время Stability, которая разрабатывает собственный набор моделей генерации видео, ввела в совет директоров режиссёра «Аватара», «Терминатора» и «Титаника» Джеймса Кэмерона (James Cameron). В начале этого года OpenAI демонстрировала Sora кинематографистам и представителям голливудских студий, но о заключении долгосрочных партнёрских соглашений объявлено не было. Любопытно, что Брукс фактически возвращается в Google, ведь ранее он занимался разработкой телефонов Pixel. Нужно отметить, что он пополнил череду уволившихся из OpenAI высокопоставленных сотрудников и учредителей:
OpenAI запустил новый интерфейс «Canvas» для работы с большими проектами и кодом
04.10.2024 [06:25],
Анжелла Марина
OpenAI добавила в ChatGPT новый инструмент Canvas, который позволяет редактировать текст и код, сгенерированный ИИ, не создавая новых запросов. Пользователи могут легко вносить изменения, добавлять комментарии и переводить текст на другой язык. Новый интерфейс позволяет взаимодействовать с ChatGPT на более интуитивном уровне. 
Источник изображения: Levart_Photographer/Unsplash Решение OpenAI ввести редактируемое рабочее пространство вписывается в тенденцию того, что уже делают другие разработчики искусственного интеллекта. Например, Anthropic выпустила в июне инструмент Artifacts с аналогичной функцией, а компания Anysphere ИИ-помощника Cursor, который представляет из себя альтернативу Visual Studio Code и уже успел приобрести большую популярность у программистов. В настоящее время чат-боты не способны выполнять масштабные проекты по одному единственному запросу, требуется множество запросов и часто с многократным повторением одного и того же кода. Редактируемое рабочее пространство Canvas позволит корректировать ошибки в результатах работы ИИ без необходимости заново генерировать весь текст или код. «Это более естественный интерфейс для сотрудничества с ChatGPT», — отметил менеджер по продукту OpenAI Дэниел Левайн (Daniel Levine). 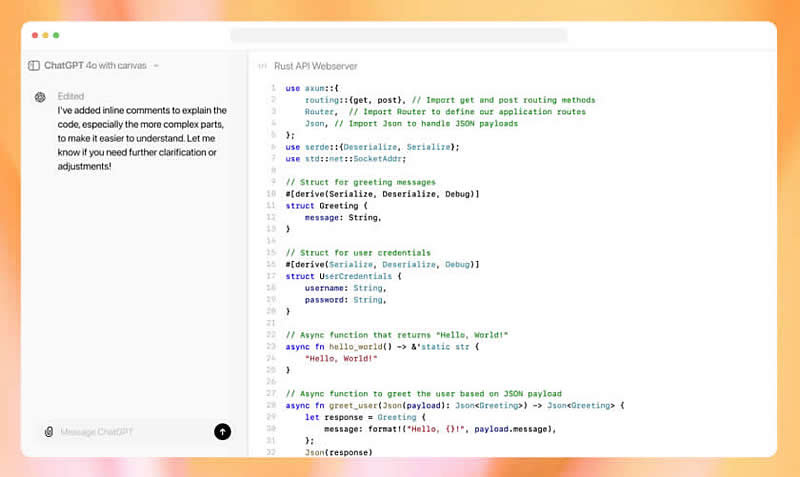
Источник изображения: Techcrunch.com В ходе демонстрации интерфейса Левайн выбрал модель «GPT-4o с Canvas» из выпадающего списка в ChatGPT. Однако в будущем окно Canvas будет появляться автоматически, если система определит, что для выполнения задачи, например для написания длинного текста или сложного кода, потребуется отдельное рабочее пространство. Пользователи также смогут просто ввести команду «use canvas», чтобы открыть окно проекта. ChatGPT может помочь и в написании письма. Пользователь просто вводит запрос на его создание и готовый текст появится в окне Canvas. Затем можно использовать ползунок для изменения длины текста, а также выделить отдельные предложения, чтобы попросить ChatGPT внести изменения, например, сделать текст дружелюбнее или добавить эмодзи. Кроме того, есть возможность попросить ИИ переписать письмо на другом языке. Аналогично происходит и с программным кодом. Пользователи могут выделять его фрагменты и задавать дополнительные вопросы ИИ. Отметим, что функции для работы с кодом в Canvas несколько отличаются от обычного рабочего окна ChatGPT. Например, появится новая кнопка «Проверить код», после нажатия на которую ChatGPT проанализирует данные и предложит конкретные правки, вне зависимости от того, сгенерирован ли этот код ИИ или написан человеком. Canvas с 3 октября уже доступна в бета-версии для пользователей ChatGPT Plus и Teams, а на следующей неделе будет запущена и для пользователей Enterprise и Edu, сообщает ресурс TechCrunch. С началом учебного года аудитория ChatGPT выросла на четверть — это 50 млн новых пользователей
03.10.2024 [21:02],
Анжелла Марина
OpenAI продолжает удерживать лидерство на рынке чат-ботов на основе искусственного интеллекта. Компания отчиталась о невероятном росте аудитории ChatGPT. За два месяца число пользователей выросло на 50 миллионов, достигнув 250 миллионов. 
Источник изображения: Kandinsky Несмотря на то, что сегодня на рынке представлены такие мощные ИИ-инструменты, как Gemini, Grok, Claude, Perplexity и другие, ChatGPT становится нарицательным именем для всего многообразия чат-ботов. Когда люди говорят о том, чтобы попросить чат-бот что-то сделать, они говорят «спросить у ChatGPT», что сравнимо с выражением «погуглить», которое давно стало синонимом поиска информации в интернете. По информации издания Android Headlines, каждую неделю более 250 миллионов человек по всему миру используют ChatGPT для разных целей. Однако впечатляют не только цифры, но и то, с какой скоростью этот показатель растёт. Если в августе ChatGPT пользовались 200 миллионов человек, то менее, чем за два месяца еженедельная аудитория выросла на 50 миллионов пользователей. Высказывается мнение, что такой скачок обусловлен началом нового учебного года. Не исключено, что школьники и студенты обращаются к ChatGPT за «помощью» в выполнении домашних заданий. Если это действительно так, то навряд ли можно рассчитывать, что в долгосрочной перспективе их успеваемость повысится. В целом успех ChatGPT показывает, что, несмотря на довольно большой выбор чат-ботов на рынке, именно продукт OpenAI пока остаётся ИИ-помощником номер один для большинства пользователей, несмотря на сильных конкурентов в лице Microsoft, Google и Meta✴. При этом, хотя Microsoft и использует модели OpenAI, она предлагает пользователям собственный уникальный ИИ-продукт Copilot. На OpenAI обрушился денежный дождь: компании дали кредит на $4 млрд
03.10.2024 [19:45],
Сергей Сурабекянц
Вчера OpenAI закрыла очередной раунд финансирования, в процессе которого компания привлекла $6,6 млрд от инвесторов, среди которых Thrive Capital, Microsoft, Nvidia и SoftBank. В дополнение к этому сегодня компания получила возобновляемую кредитную линию на $4 млрд с овердрафтом ещё в $2 млрд, что повысило её общую ликвидность до более чем $10 млрд. Биржевая оценка стоимости компании достигла $157 млрд. 
Источник изображения: unsplash.com «Теперь у нас есть доступ к более чем 10 миллиардам долларов ликвидности, что даёт нам гибкость для инвестирования в новые инициативы и широкие возможности масштабирования, — сообщила сегодня OpenAI. — Это также подтверждает наше партнёрство с исключительной группой финансовых учреждений, многие из которых также являются клиентами OpenAI». Компания планирует использовать эти средства для вложений в исследования и продукты, расширение инфраструктуры и привлечение талантов. Последний раунд финансирования OpenAI включал обширный список инвестиционных фирм и крупных технологических компаний во главе с фондом Thrive Capital, который планировал вложить $1 млрд. Столь же крупные инвестиции были получены от Microsoft и Nvidia. По словам осведомлённых источников, в проекте приняли также участие SoftBank, Khosla Ventures, Altimeter Capital, Fidelity Management & Research Company, MGX, Tiger Global и другие фонды. Открытый сегодня для OpenAI кредит на $4 млрд (плюс $2 млрд овердрафта) — необеспеченный. Его предоставляет группа ведущих банков, в числе которых JPMorgan Chase, Citigroup, Goldman Sachs, Morgan Stanley и другие. Средства могут использоваться в течение трёх лет. Процентная ставка для OpenAI установлена на уровне около 6 % годовых. Стремительный подъем OpenAI, начавшийся с запуска ChatGPT в конце 2022 года, стал самой громкой историей в технологической отрасли за последние пару лет, сделав концепцию генеративного ИИ мейнстримом и проложив путь для десятков миллиардов инвестиций в инфраструктуру ИИ. Биржевая оценка стоимости компании достигла $157 млрд. Ранее в этом году OpenAI оценивалась в $80 млрд, по сравнению с $29 млрд в 2023 году. Выручка OpenAI в сентябре 2024 года составила $300 млн, что на 1700 % больше, чем в начале прошлого года. В следующем году компания рассчитывает заработать $11,6 млрд по сравнению с $3,7 млрд в 2024. Но до выхода на окупаемость ещё очень далеко, так как OpenAI вынуждена постоянно наращивать закупки ускорителей для обучения и запуска своих больших языковых моделей. Осведомлённые источники утверждают, что компания ожидает в этом году убытки в размере около $5 млрд. OpenAI также пережила множество трудностей роста в последние месяцы, включая серьёзные кадровые потери. На прошлой неделе компанию покинули технический директор Мира Мурати (Mira Murati), главный научный сотрудник Боб МакГрю (Bob McGrew) и вице-президент по исследованиям Баррет Зоф (Barret Zoph). Уход ключевых специалистов произошёл на фоне реструктуризации OpenAI из некоммерческой организации в коммерческую, что вызвало волну слухов о получении Сэмом Альтманом (Sam Altman) пакета акций, которые он опроверг, назвав эту информацию «просто неправдой». Председатель OpenAI Брет Тейлор (Bret Taylor) сообщил что «совет директоров обсуждал, будет ли выгодно для компании и нашей миссии, если Сэм получит компенсацию в виде акций, но конкретные цифры не обсуждались и никаких решений не принималось». Google надеется догнать OpenAI, создав собственный рассуждающий ИИ
03.10.2024 [10:13],
Владимир Фетисов
Компания Google работает над созданием модели искусственного интеллекта, способной рассуждать подобно человеку. За счёт этого IT-гигант намерен усилить конкуренцию с OpenAI, которая уже представила аналогичный продукт под названием o1. Об этом пишет Bloomberg со ссылкой на собственные осведомлённые источники. 
Источник изображения: geralt/Pixabay В сообщении сказано, что за последние месяцы Google добилась значительного прогресса в разработке моделей искусственного интеллекта, способных справляться с решением многоэтапных задач в таких областях, как математика и программирование. По данным источника, как и OpenAI, Google пытается создать рассуждающий ИИ-алгоритм с помощью техники, называемой «цепочка мыслей». Она подразумевает, что прежде чем дать ответ на письменный запрос ИИ-алгоритм на несколько секунд берёт паузу, чтобы проанализировать связанные с запросом тематики и затем дать обобщённый ответ на поставленный вопрос. Официальные представители Google отказались от комментариев по данному вопросу. Google и OpenAI ведут напряжённую борьбу за доминирование в сфере искусственного интеллекта. Противостояние обострилось с появлением ИИ-бота ChatGPT, который, как считают некоторые инвесторы, со временем способен устранить необходимость в поисковике Google. IT-гигант всячески стремится избежать этого, для чего ведущие исследовательские команды разработчиков компании были объединены в подразделение DeepMind. Несмотря на это, Google продолжает двигаться медленнее, когда дело доходит да запуска новых ИИ-продуктов, делая паузу, чтобы рассмотреть этические проблемы, необходимость оправдать ожидания общественности в отношении доверия к бренду компании и др. Анонимный источник издания сообщил, что после того, как в середине сентября OpenAI представила алгоритм o1, некоторые сотрудники DeepMind были разочарованы отставанием Google в гонке за лидерство в сфере ИИ. Однако сотрудники уже не так обеспокоены, как после запуска ChatGPT, поскольку сейчас Google успела выпустить некоторые из своих собственных разработок. OpenAI запретила своим спонсорам поддерживать её конкурентов и Илона Маска
03.10.2024 [08:29],
Алексей Разин
Изданию Financial Times удалось разведать интересные подробности заключённой на этой неделе сделки по новому раунду финансирования OpenAI на сумму $6,6 млрд, которая оценила капитализацию компании в $157 млрд. На этапе переговоров OpenAI настаивала на том, чтобы инвесторы отказались от намерений вкладывать средства в капитал конкурирующих стартапов в области искусственного интеллекта. 
Источник изображения: OpenAI Подобное требование довольно редко встречается, как отметили венчурные инвесторы, что позволяет многим из них диверсифицировать риски, вкладывая деньги в различные компании одного сектора. Sequoia Capital и Andreessen Horowitz, например, одновременно поддерживают как OpenAI, так и xAI. Специфика этого раунда финансирования OpenAI, однако, заключалась в наличии большого количества желающих принять участие, а потому стартап мог устанавливать нетипичные для подобных сделок условия, не желая способствовать развитию бизнеса конкурентов. Помимо основанного Илоном Маском xAI, в перечень запрещённых к поддержке OpenAI стартапов попал Safe Superintelligence, основанный покинувшим OpenAI Ильёй Суцкевером. Anthropic, Perplexity и Glean также оказались в "чёрном списке" OpenAI для своих инвесторов. Один из участников переговоров напомнил, что Uber в своё время диктовала подобные условия, поскольку считала себя доминирующей в своём сегменте компанией. Крупнейшим участником данного раунда финансирования стал венчурный фонд Thrive Capital, который вложил $750 млн собственных средств и привлёк около $550 млн у более мелких инвесторов через проектную компанию. Этот фонд также договорился инвестировать ещё $1 млрд до конца следующего года, но исходя из текущей оценки капитализации OpenAI в $150 млрд до последнего раунда финансирования. Фонд Khosla Ventures вложил $500 млн, по данным источника. Менее года назад капитализация OpenAI не превышала $87 млрд, а в апреле прошлого года была в пять раз ниже текущего уровня. Подобная динамика показывает, что инвесторы верят в потенциал стартапа на рынке систем искусственного интеллекта, поскольку считают его одним из первопроходцев в сфере создания чат-ботов, работающих с генеративными технологиями. Сообщается, что глава компании Сэм Альтман (Sam Altman) принял участие в обсуждении вопроса о выделении ему пакета акций в случае реструктуризации OpenAI и превращении стартапа в коммерческую организацию, хотя ранее сам он отрицал проведение подобных переговоров. Новый раунд финансирования превратил OpenAI в крупнейший стартап Кремниевой долины, но ByteDance и SpaceX превосходят его по этому критерию в целом. OpenAI собрала с инвесторов $6,6 млрд, теперь её стоимость — $157 млрд
03.10.2024 [04:55],
Алексей Разин
Долго обсуждаемая сделка по привлечению в капитал OpenAI дополнительных средств, по данным Bloomberg, была заключена на этой неделе, позволив этому стартапу получить $6,6 млрд и оценить свою капитализацию в $157 млрд. Обе суммы оказались выше ожидаемых, а среди участников этого раунда инвестирования оказались Microsoft и Nvidia. 
Источник изображения: Unsplash, Andrew Neel Вообще, как поясняют источники, решающую роль в этом раунде финансирования играл венчурный инвестиционный фонд Thrive Capital, который вложил в OpenAI около $1,3 млрд. Корпорация Microsoft отделалась $750 млн, и на фоне уже инвестированных ею ранее $13 млрд это не такая большая сумма. Так или иначе, новый раунд позволил OpenAI войти в число трёх стартапов, максимально поддерживаемых венчурными капиталистами. Этого статуса также в своё время удостоились SpaceX Илона Маска (Elon Musk) и социальная сеть TikTok китайской компании ByteDance. Tiger Global Management вложила в OpenAI свои $350 млн, Altimeter Capital довольствовалась $250 млн, согласно неофициальным данным. OpenAI удалось привлечь и внимание международных инвесторов. Владеющая Arm японская корпорация SoftBank вложила $500 млн, какие-то суммы внесли MGX и Coatue. Из сообщений OpenAI становится известно, что полученные средства она направит на дальнейшие исследования в сфере искусственного интеллекта, а также расширение своих вычислительных мощностей. Представители Altimeter Capital заявили, что следующим логическим шагом для OpenAI мог бы стать выход на IPO, этот стартап они назвали важнейшей в США компанией в сфере ИИ после Nvidia. В сделке не участвовала Apple, хотя ранее участвовала в переговорах, как подчёркивает Bloomberg. Часть средств в капитал OpenAI была привлечена через специально созданные проектные компании, которые позволяют собирать средства более мелких инвесторов для финансирования определённого проекта. По крайней мере Thrive Capital не ограничилась собственными средствами, а привлекла дополнительные ресурсы как раз по такой схеме. Будут ли реализованы структурные преобразования в OpenAI, которые до этого активно обсуждались с потенциальными инвесторами, не уточняется. Компания располагает 11 млн подписчиков сервиса ChatGPT Plus, корпоративных подписчиков при этом насчитывается более 1 млн. В следующем году компания рассчитывает выручить более $10 млрд, но пока она остаётся убыточной. В ходе переговоров со своими инвесторами, как сообщается, OpenAI рекомендовала им воздержаться от финансирования деятельности конкурирующих компаний типа Anthropic и xAI. OpenAI открыла речевой ИИ из ChatGPT для сторонних разработчиков — ждём вала говорящих приложений
02.10.2024 [17:53],
Владимир Фетисов
Компания OpenAI представила новые возможности для упрощения процесса создания приложений на основе искусственного интеллекта. Теперь разработчики могут задействовать работающий в режиме онлайн инструмент для создания голосовых программных решений на базе ИИ, используя единый набор инструкций. 
Источник изображения: OpenAI Большую часть дохода OpenAI получает от предприятий, которые используют нейросети компании для создания собственных ИИ-приложений. Поэтому расширение возможностей по созданию таких продуктов является вполне оправданным шагом на фоне обостряющейся борьбы в сфере ИИ с такими компаниями, как Google, которая внедряет в свои продукты алгоритмы, способные обрабатывать разные типы информации, включая текст, изображения и видео. Процесс создания голосовых помощников требует от разработчиков прохождения как минимум трёх этапов: преобразование аудио в текст, обработка запроса и генерация текстового ответа на него, а также преобразование полученного ответа в аудио. В рамках внедрения новых возможностей по созданию голосовых ИИ-приложений OpenAI представила инструмент тонкой настройки больших языковых моделей после завершения этапа обучения. Такой подход позволит повысить качество ответов, которые генерируют создаваемые разработчиками алгоритмы в ответы на запросы в текстовом формате и с использованием изображений. Этап точной настройки может сопровождаться обратной связью от людей, которые проводят оценку того, насколько качественные ответы даёт алгоритм. В OpenAI считают, что использование изображений для точной настройки моделей даст разработчикам более широкие возможности для повышения качества понимания ИИ-алгоритмами того, что демонстрируется на изображениях. Созданные таким образом приложения могут выступать, например, в качестве расширенного поиска по визуальным элементам. В дополнение к этому OpenAI представила инструмент, который позволит меньшим ИИ-моделям учиться на более крупных моделях, а также «Быстрое кэширование», которое существенно сократит затраты на разработку благодаря повторному использованию фрагментов текста, ранее уже обработанных алгоритмом. Все представленные нововведения уже тестируются с привлечением ограниченного числа клиентов OpenAI. Сбежавшую от Сэма Альтмана Миру Мурати осаждают венчурные инвесторы с деньгами
01.10.2024 [22:33],
Сергей Сурабекянц
Технический директор OpenAI Мира Мурати (Mira Murati) объявила о своём уходе из компании на прошлой неделе. По её словам, она решила «освободить время и пространство для собственных исследований». Сразу после увольнения Мурати несколько крупных венчурных компаний объявили о желании профинансировать её следующий проект. Интрига заключается в том, что Мурати пока не делала никаких заявлений о своих дальнейших планах и отказалась комментировать возникшие слухи. 
Источник изображения: Pixabay «Мои шесть с половиной лет в команде OpenAI были исключительной привилегией… Никогда не бывает идеального времени, чтобы уйти из места, которое ты лелеешь, но этот момент кажется правильным» — написала Мурати в своём аккаунте в соцсети X. Генеральный директор OpenAI Сэм Альтман (Sam Altman) прокомментировал внезапный уход Мурати в X: «Я, конечно, не буду притворяться, что такая внезапность [увольнения] естественна, но мы не обычная компания, и я думаю, что причины, которые мне объяснила Мира, имеют смысл». Мурати присоединилась к OpenAI в 2018 году. До этого она занималась проектированием электромобиля Model X в Tesla. В OpenAI Мурати возглавила разработку двух флагманских продуктов компании — ChatGPT и Dall-E. Уход Мурати произошёл на фоне реструктуризации OpenAI из некоммерческой организации в коммерческую, что даст Альтману возможность получить пакет акций. Очередной недавний сбор средств принёс OpenAI инвестиции в размере $6,5 млрд от таких компаний, как Thrive Capital, SoftBank, Coatue и Microsoft. Венчурные капиталисты конкурируют за право быть первыми инвесторами стартапов, основанных выходцами из OpenAI, так как все эти проекты выглядят очень многообещающе. Десятки бывших сотрудников OpenAI, включая уволившихся соучредителей стартапа, за последние несколько лет основали свои компании, к примеру:
Одновременно с Мурати о своём уходе из OpenAI заявили ещё два технических специалиста — главный научный сотрудник Боб МакГрю (Bob McGrew) и вице-президент по исследованиям Барретт Зоф (Barret Zoph). Теперь Альтман и Войцех Заремба (Wojciech Zaremba) — единственные оставшиеся учредители из одиннадцати основателей компании. «Их уход заставил меня задуматься о трудностях, с которыми сталкивались родители в Средние века, когда 6 из 8 детей умирали преждевременно, — написал Заремба в сообщении в соцсети X, ставшем вирусным. — Несмотря на тяжёлую утрату, родителям пришлось смириться с ней и найти глубокую радость и удовлетворение в тех двоих, кто выжил». SoftBank вызвалась заменить Apple в списке ключевых инвесторов OpenAI
30.09.2024 [23:12],
Анжелла Марина
Японская инвестиционная холдинговая компания SoftBank планирует вложить $500 млн в OpenAI, разработчика чат-бота ChatGPT, сообщает Bloomberg. Инвестирование станет частью более крупного раунда финансирования, в ходе которого OpenAI рассчитывает привлечь $6,5 млрд при оценке компании в $150 млрд. 
Источник изображения: OpenAI Лидером раунда предположительно выступит Thrive Capital при участии Microsoft, крупнейшего инвестора OpenAI, а также других инвесторов. В частности, компания обсуждала инвестиции с Nvidia и Apple. Однако последняя больше не участвует в переговорах об участии в раунде, зато в списке инвесторов возможно будет фигурировать SoftBank через свой фонд Vision Fund. Если сделка состоится, OpenAI закрепит за собой статус одного из самых дорогих стартапов в мире. Официальные представители OpenAI и SoftBank пока не дали комментариев по этому поводу. В то же время компания переживает не самый простой период. На прошлой неделе о своём уходе объявила технический директор и ключевой сотрудник OpenAI Мира Мурати (Mira Murati), что стало ещё одним звеном в цепи увольнений топ-менеджеров компании в этом году. Кроме того, по данным Bloomberg, OpenAI рассматривает возможность реструктуризации, чтобы стать полностью коммерческой организацией. Напомним, ранее основатели OpenAI позиционировали свою компанию как некоммерческую организацию, сосредоточившись на исследованиях в «создании положительного долгосрочного воздействия на человека». Отметим, что SoftBank ранее не проявлял инвестиционного интереса к OpenAI, однако поддерживал одного из его конкурентов. В частности, в июне Vision Fund, управляемый SoftBank Investment Advisers, дочерней компанией SoftBank, вложился в Perplexity AI — стартап, занимающийся поиском на основе искусственного интеллекта, оценив его в $3 млрд. Сэм Альтман опроверг слухи о намерениях OpenAI выделить ему крупный пакет акций
30.09.2024 [07:17],
Алексей Разин
На прошлой неделе появилась информация о том, что после предлагаемой реструктуризации OpenAI и юридического перевода стартапа на коммерческие рельсы, глава и основатель Сэм Альтман (Sam Altman) получит крупный пакет акций компании в виде вознаграждения за свой труд. На собрании сотрудников OpenAI в четверг сам Альтман опроверг эти слухи, как поясняет CNBC. 
Источник изображения: OpenAI С другой стороны, по данным источника, в ходе видеотрансляции с собрания сотрудников OpenAI перед аудиторией выступили как генеральный директор Сэм Альтман, так и финансовый директор Сара Фрайар (Sarah Friar). Оба сообщили, что инвесторы выражали обеспокоенность отсутствием в руках Альтмана акций OpenAI — компании, которую он вместе с единомышленниками основал почти девять лет назад. При этом Альтман подчеркнул, что все слухи о намерениях OpenAI выдать ему крупный пакет акций не имеют ничего общего с реальностью, и подобных планов в настоящий момент просто не существует. Председатель совета директоров OpenAI Брет Тейлор (Bret Taylor) в интервью CNBC пояснил, что хотя этот орган правления обсуждал возможность поощрения Альтмана акциями компании, никаких решений не было принято. Из сторонних источников известно, что в четверг собрание сотрудников OpenAI было организовано для обсуждения возможного сценария реструктуризации, по которому коммерческое подразделение компании будет главенствовать, а некоммерческая часть сохранится, но без прежней степени влияния. Сэм Альтман в интервью на прошлой неделе подчеркнул, что недавний уход трёх высокопоставленных руководителей из OpenAI, включая технического директора Миру Мурати (Mira Murati), не имеет ничего общего с подготовкой к реструктуризации, и обсуждался уже на протяжении года. Ушедшие руководители просто готовятся к новому этапу своей карьеры, а OpenAI намерена сделать свой следующий шаг в развитии. OpenAI увеличит стоимость подписки на ChatGPT до $44 в течение пяти лет
28.09.2024 [12:33],
Владимир Мироненко
Компания OpenAI планирует провести на следующей неделе раунд финансирования с целью привлечь $7 млрд, в результате чего оценка её рыночной стоимости может вырасти до $150 млрд, пишет The New York Times. 
Источник изображения: Growtika/unsplash.com В связи с этим OpenAI распространяет среди потенциальных инвесторов отчёт о финансовых показателях, в котором также изложены планы на ближайшее будущее. Согласно данным OpenAI, её выручка в августе выросла год к году более чем в три раза. По состоянию на июнь её услугами пользовалось около 350 млн человек, что в 3,5 раза больше, чем в марте. Рост в основном был достигнут благодаря популярности ChatGPT. Всплеск роста был зафиксирован после того, как появилась возможность использования чат-бота без создания учётной записи или входа в систему. Компания ожидает, что в этом году ChatGPT принесёт $2,7 млрд дохода, что гораздо больше, чем $700 млн в 2023 году. Ещё $1 млрд поступит от компаний, использующих её технологию. Вместе с тем OpenAI по-прежнему убыточна — в этом году она потеряет $5 млрд. Согласно предоставленным документам, около 10 млн пользователей ChatGPT ежемесячно платят компании по $20. OpenAI планирует повысить стоимость подписки к концу года до $22, а в течение следующих пяти лет до $44, говорится в документах. Как сообщается, более миллиона сторонних разработчиков используют технологию OpenAI для поддержки собственных сервисов. Согласно прогнозу OpenAI, в 2029 году её доход достигнет $100 млрд, что примерно соответствует текущим годовым продажам транснациональной корпораций Nestlé или крупного американского ретейлера Target. В документе также указано, что OpenAI находится в процессе перехода от некоммерческой к коммерческой модели бизнеса, что позволит снять любые ограничения на доходность инвесторов. Это откроет OpenAI больше возможностей для переговоров с новыми инвесторами с предложением более высоких ставок доходности. Apple не будет инвестировать в OpenAI
28.09.2024 [08:10],
Алексей Разин
Агентство Reuters со ссылкой на The New York Times поделилось очередными слухами о готовящемся новом раунде финансирования OpenAI инвесторами, среди которых Thrive Capital будет играть ключевую роль, вложив по $1 млрд в этом году и в следующем, а вот Apple из этой гонки предпочла выбыть ещё на этапе переговоров. 
Источник изображения: OpenAI Как известно, в ближайшее время OpenAI рассчитывает привлечь около $6,5 млрд от инвесторов, и переговоры с основными из них должны завершиться на следующей неделе. Издание The Wall Street Journal выяснило, что компания Apple участвовать в этом раунде финансирования стартапа OpenAI отказалась. Зато с дистанции не сошли Nvidia и Microsoft, причём последняя может раскошелиться на дополнительный $1 млрд, хотя до этого уже вложила в капитал OpenAI около $13 млрд. В целом, новый раунд финансирования должен поднять капитализацию OpenAI до уровня более $100 млрд. Если же вернуться к переговорам OpenAI и Thrive Capital, то первая обещает второй утроить свою выручку за год с нынешних $3,7 до $11,6 млрд, призывая указанный инвестиционный фонд потратить более $1 млрд на своё развитие в текущем году и почти такую же сумму в следующем. Правда, Thrive Capital готова будет вложить второй миллиард долларов только в том случае, если выручка OpenAI преодолеет рубеж в $11,6 млрд в следующем году. К слову, в текущем году OpenAI рассчитывает получить убытки в размере $5 млрд, поскольку расходы на развитие вычислительной инфраструктуры очень высоки. OpenAI собирается к концу следующей недели определиться с параметрами очередного раунда финансирования, который подразумевает привлечение средств инвесторов в форме конвертируемых облигаций и оценивает капитализацию стартапа в $150 млрд. При этом инвесторы настаивают на реструктуризации OpenAI и превращении стартапа в коммерческую компанию без доминирования некоммерческой составляющей. Сейчас инвесторы OpenAI ограничены в величине передаваемой им доли прибыли, и это их явно не устраивает. Примечательно, что лишь Thrive Capital договорилась с OpenAI о возможности покупки облигаций в следующем году по текущей цене. Если капитализация OpenAI будет стремительно расти, это позволит Thrive Capital увеличить свою долю в следующем году без увеличения затрат в денежной форме. Только на подписках коммерческих пользователей ChatGPT стартап OpenAI в этом году может выручить $2,7 млрд, почти в четыре раза больше, чем годом ранее. Сейчас чат-бот насчитывает около 10 млн коммерческих пользователей, которые выкладывают по $20 в месяц за доступ к сервису. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2025 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews. kz
![]()
![]()








 MWC 2018
MWC 2018 2018
2018 Computex
Computex






