|
Опрос
|
реклама
Быстрый переход
Чат-бот Claude AI станет прекращать «вредоносные или оскорбительные диалоги с пользователями»
18.08.2025 [18:58],
Сергей Сурабекянц
Anthropic научила свой чат-бот Claude AI прекращать общение, которое он сочтёт «вредоносным или оскорбительным». Эта возможность уже доступна в моделях Opus 4 и 4.1. Она позволит чат-боту завершать разговоры в качестве крайней меры после неоднократных попыток пользователя сгенерировать вредоносный или оскорбительный контент. Anthropic хочет добиться «потенциального благополучия» моделей ИИ, прекращая беседы, в которых Claude испытывает «явный дискомфорт». 
Источник изображения: Anthropic После прекращения диалога со стороны Claude, пользователь не сможет отправлять новые сообщения в этом чате, но создание новых чатов будет по-прежнему доступно. Anthropic отметила, что разговоры, вызывающие подобную реакцию, являются «крайними случаями», добавляя, что большинство пользователей не столкнутся с этим препятствием даже при обсуждении спорных тем. В ходе тестирования Claude Opus 4 у чат-бота было отмечено «стойкое и последовательное отвращение к причинению вреда», в том числе к созданию сексуального контента с участием несовершеннолетних, насильственным действиям и терроризму. В этих случаях, по данным Anthropic, Claude демонстрировал «явную тревожность» и «тенденцию прекращать вредоносные разговоры, когда предоставлялась такая возможность». Claude получил прямое указание не завершать разговоры, если пользователь проявляет признаки желания причинить «неминуемый вред» себе или другим. В таких случаях Anthropic привлекает онлайн-сервис кризисной поддержки Throughline, чтобы помочь разработать ответы на запросы, связанные с самоповреждением и психическим здоровьем. На прошлой неделе Anthropic обновила политику использования своего чат-бота, поскольку быстро развивающиеся модели ИИ вызывают всё больше опасений по поводу безопасности. Теперь компания запрещает использовать Claude для разработки биологического, ядерного, химического или радиологического оружия, а также для разработки вредоносного кода или эксплуатации уязвимостей сети. Пока все ждут GPT-5, Anthropic выпустила ИИ-модель Claude Opus 4.1 — она стала лучше в программировании, рассуждениях и агентских задачах
06.08.2025 [14:05],
Павел Котов
Anthropic объявила о выходе рассуждающей модели искусственного интеллекта Claude Opus 4.1, предназначенной для работы в качестве ИИ-агента, средства написания программного кода. 
Источник изображений: anthropic.com Поработать с Opus 4.1 уже могут подписчики платных версий Claude и в Claude Code; новая модель также доступна через API, на платформах Amazon Bedrock и Google Cloud Vertex AI. Стоимость доступа к ней такая же, как у оригинальной Opus 4. 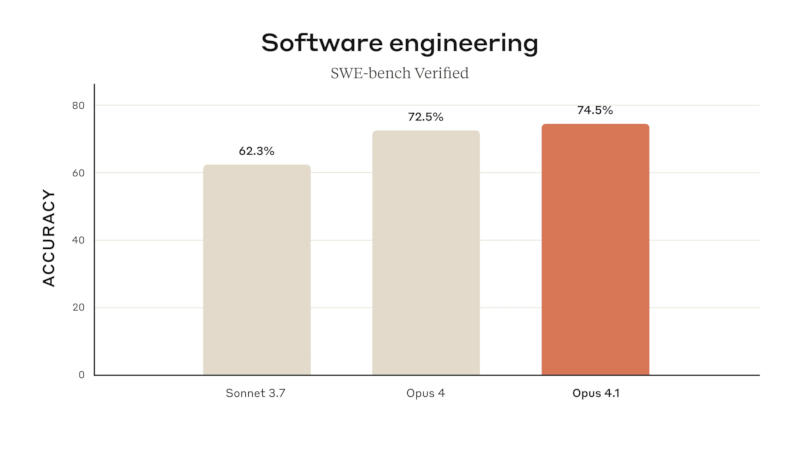 Anthropic Claude Opus 4.1 лучше справляется с задачами на написание программного кода — тест SWE-bench Verified показал результат до 74,5 %. Улучшились навыки чат-бота Claude в области анализа данных и углублённых исследований, особенно при необходимости произвести агентный поиск информации и отследить детали. 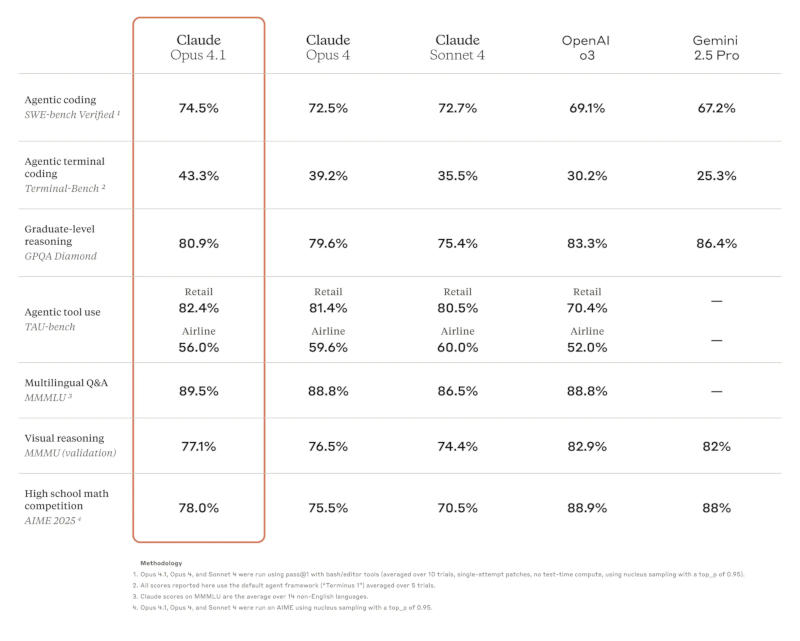 Обновлённая модель Claude Opus 4.1 стала лучше в большинстве функций по сравнению с Opus 4, по версии GitHub. Ещё одна примечательная особенность Opus 4.1 — способность вносить точные изменения в код даже при большом объёме его базы, ограничиваясь только необходимыми модификациями и не создавая новых ошибок, что делает модель эффективным средством для повседневной отладки, отметили в Rakuten Group. В Windsurf прогресс Opus 4.1 по сравнению с Opus 4 оценили в одно стандартное отклонение — таким же он был при переходе от Sonnet 3.7 к Sonnet 4. Anthropic рекомендовала переходить с Opus 4 на Opus 4.1 во всех сценариях работы. При подключении через API разработчикам достаточно выбрать модель claude-opus-4-1-20250805. Пузырь ИИ сдувается, пока OpenAI, Google и Anthropic пытаются создать более продвинутый ИИ
13.11.2024 [19:26],
Сергей Сурабекянц
Три ведущие компании в области искусственного интеллекта столкнулись с ощутимым снижением отдачи от своих дорогостоящих усилий по разработке новых систем ИИ. Новая модель OpenAI, известная как Orion, не достигла желаемой компанией производительности, предстоящая итерация Google Gemini не оправдывает ожиданий, а Anthropic столкнулась с отставанием в графике выпуска своей модели Claude под названием 3.5 Opus. 
Источник изображения: unsplash.com После многих лет стремительного выпуска всё более сложных продуктов ИИ три ведущие в этой сфере компании наблюдают убывающую отдачу от дорогостоящих усилий по созданию новых моделей. Становится все труднее находить свежие, ещё неиспользованные источники высококачественных данных для обучения более продвинутых систем ИИ. А нынешних весьма скромных улучшений недостаточно, чтобы окупить огромные затраты, связанные с созданием и эксплуатацией новых моделей, как и оправдать ожидания от выпуска новых продуктов. Так, OpenAI утверждала, что находится на пороге важной вехи. В сентябре завершился начальный раунд обучения для новой масштабной модели Orion, которая должна была приблизится к созданию мощного ИИ, превосходящего людей. Но ожидания компании, по утверждению осведомлённых источников, не оправдались. Orion не смогла продемонстрировать прорыва, который ранее показала модель GPT-4 по сравнению с GPT-3.5. 
Источник изображения: Pixabay Anthropic, как и её конкуренты, столкнулась с трудностями в процессе разработки и обучения 3.5 Opus. По словам инсайдеров, модель 3.5 Opus показала себя лучше, чем старая версия, но не так значительно, как ожидалось, учитывая размер модели и затраты на её создание и запуск. Эти проблемы бросают вызов утвердившемуся в Кремниевой долине мнению о масштабируемости ИИ. Приверженцам глобального внедрения ИИ приходится признать, что бо́льшая вычислительная мощность, увеличенный объём данных и более крупные модели пока не прокладывают путь к технологическому прорыву в области ИИ. 
Источник изображения: Nvidia Эксперты высказывают обоснованные сомнения в окупаемости крупных инвестиций в ИИ и достижимости всеобъемлющей цели, к которой стремятся разработчики ИИ-моделей, — создания общего искусственного интеллекта (AGI). Этот термин обычно применяется к гипотетическим ИИ-системам, способным соответствовать или превосходить человека в большинстве интеллектуальных задач. Руководители OpenAI и Anthropic ранее заявляли, что AGI может появиться уже через несколько лет. Технология, лежащая в основе ChatGPT и конкурирующих ИИ-чат-ботов, была создана на основе данных из социальных сетей, онлайн-комментариев, книг и других источников из интернета. Этих данных хватило для создания продуктов, генерирующих суррогатные эссе и поэмы, но для разработки систем ИИ, которые превзойдут интеллектом лауреатов Нобелевской премии — как надеются некоторые компании, — могут потребоваться другие источники данных, помимо сообщений в Википедии и субтитров YouTube. 
Источник изображения: unsplash.com OpenAI была вынуждена заключить соглашения с издателями, чтобы удовлетворить хотя бы часть потребности в высококачественных данных, а также адаптироваться к растущему юридическому давлению со стороны правообладателей контента, используемого для обучения ИИ. Отмечается высокий спрос на рынке труда на специалистов с высшим образованием, которые могут маркировать данные, связанные с их областью компетенции. Это помогает сделать обученные ИИ-системы более эффективными в ответах на запросы. Подобные усилия обходятся дороже и требуют на порядок больше времени, чем простое индексирование интернета. Поэтому технологические компании обращаются к синтетическим данным, таким как сгенерированные компьютером изображения или текст, имитирующие контент, созданный людьми. Однако у такого подхода есть свои ограничения, так как трудно добиться качественного улучшения при использовании подобных данных для обучения ИИ. Тем не менее компании ИИ продолжают следовать принципу «чем больше, тем лучше». В стремлении создавать продукты, приближающиеся к уровню человеческого интеллекта, технологические компании увеличивают объём вычислительной мощности, данных и времени, затрачиваемых на обучение новых моделей, что приводит к росту расходов. Генеральный директор Anthropic Дарио Амодеи (Dario Amodei) заявил, что в этом году компании потратят $100 млн на обучение новейших моделей, а в ближайшие годы эта сумма может достичь $100 млрд. 
Источник изображения: unsplash.com Безусловно, потенциал для улучшения моделей ИИ, помимо масштабирования, существует. Например, для своей новой модели Orion OpenAI применяет многомесячный процесс пост-обучения. Эта процедура включает использование обратной связи от людей для улучшения ответов и уточнения «эмоциональной окраски» взаимодействия с пользователями. Разработчики ИИ-моделей оказываются перед выбором: либо предлагать старые модели с дополнительными улучшениями, либо запускать чрезвычайно дорогие новые версии, которые могут работать ненамного лучше. По мере роста затрат растут и ожидания — стремительное развитие ИИ на начальном этапе создало завышенные ожидания как у специалистов, так и у инвесторов. |
© 1997—2025 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews. kz
![]()
![]()








 MWC 2018
MWC 2018 2018
2018 Computex
Computex



