







 MWC 2018
MWC 2018 2018
2018 Computex
Computex
⇣ Содержание
|
Опрос
|
реклама
Самое интересное в новостях
Обзор видеокарты NVIDIA GeForce RTX 3080, часть 1
⇡#SM в архитектуре AmpereНачиная с чипов Maxwell, инженеры NVIDIA делят Streaming Multiprocessor на четыре секции с различным числом вычислительных блоков внутри (в зависимости от конкретной реализации в том или ином GPU) и в предыдущем поколении архитектуры (Turing) пришли к тому, что секция SM содержит 16 CUDA-ядер, оперирующих форматом данных FP32. Кроме того, в процессорах Volta и Turing, отделили пути данных для операций над целыми числами внутри CUDA-ядер от арифметики с плавающей запятой — таким образом возник блок из 16 целочисленных CUDA-ядер, а общее число ALU, которые могут быть загружены одновременно, эффективно удвоилось. Внутри секции SM находится собственный планировщик, который за такт отправляет на исполнение одну инструкцию warp’a (группы из 32 потоков инструкций — т.н. рабочих единиц), которая позволяет совершить одну и ту же операцию над 32 операндами. Благодаря тому, что блоку из 16 шейдерных ALU требуется два такта, чтобы выполнить инструкцию, во втором такте планировщик остается свободен. Нечетные такты планировщика могут быть заняты отправкой инструкций из другого warp’а на 16 целочисленных ALU (или другие типы исполнительных блоков, которые мы пока не упоминали), поэтому теоретическая пропускная способность Turing при полной загрузке целочисленными расчетами и операциями с плавающей точкой в одно и то же время также увеличилась в два раза по сравнению с исключительно дробной или исключительно целочисленной арифметикой. В комментариях к обзорам ускорителей на Turing неоднократно звучало мнение, что NVIDIA следовало вложиться в большее число CUDA-ядер вместо специализированных блоков трассировки лучей, которые якобы помешали чипмейкеру выпустить GPU, способные сохранить прежние темпы роста производительности. И хотя серия GeForce RTX 20 действительно оказалась не самым удачным примером роста быстродействия по сравнению с ее предшественниками, не говоря уже об удельной стоимости FPS, обвинять в этом рейтрейсинг не совсем корректно. В конце концов, на ALU общего назначения по-прежнему ложится львиная доля нагрузки при пересчете шейдеров во время множественных отражений лучей, а также денойзинг изображения, необходимый при сравнительно низкой плотности последних в рендеринге реального времени. 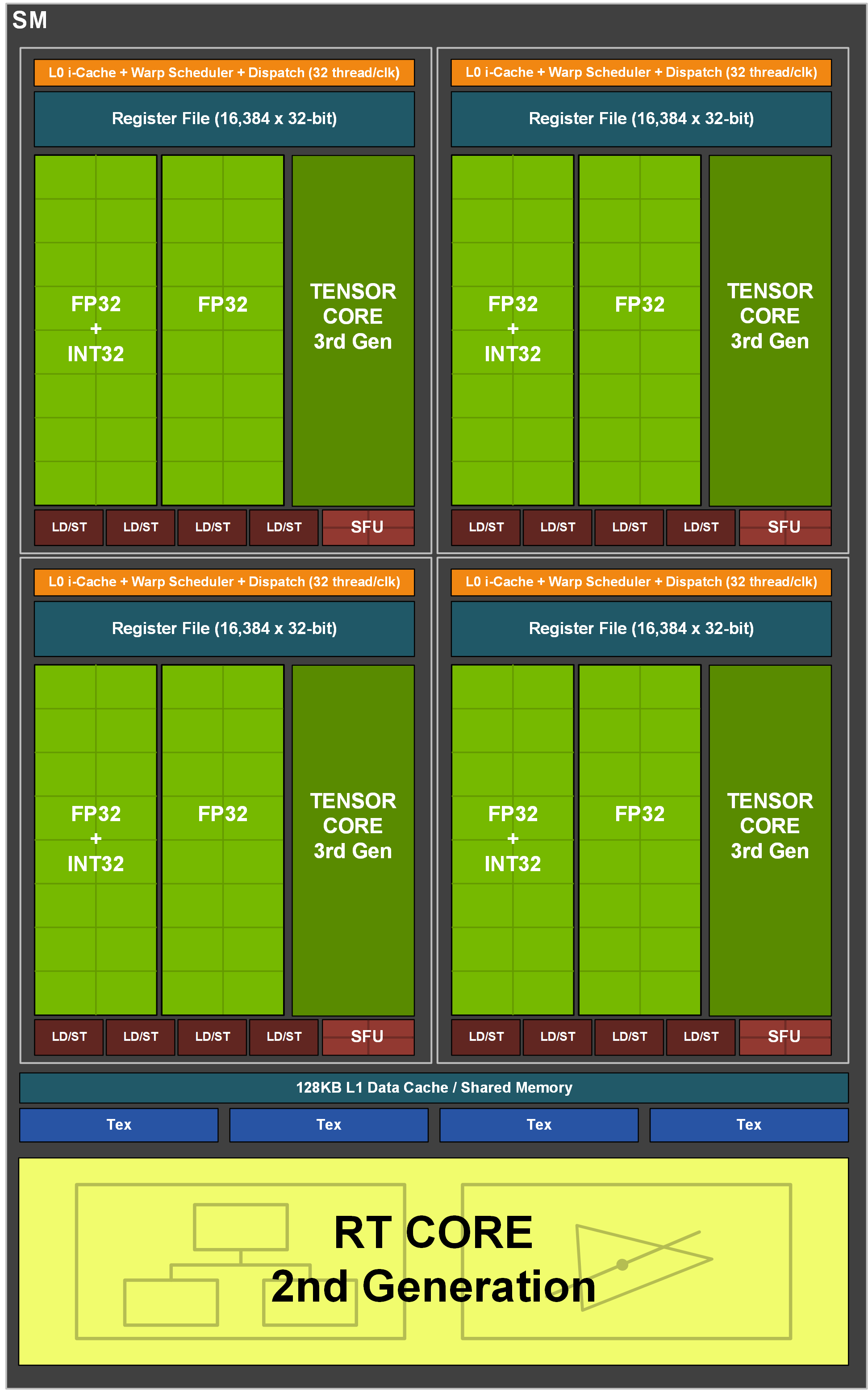 Тем не менее вот ответ NVIDIA всем тем, кому не доложили шейдерных ALU в архитектуре Turing: теперь количество CUDA-ядер FP32 внутри секции SM стало вдвое больше. Ampere вернулся к исходным позициям архитектуры Pascal, когда на одном и том же пути данных лежит массив 16 ALU FP32 и 16 целочисленных ALU INT32, но появилась отдельная ветка из 16 FP32-совместимых CUDA-ядер. Таким образом, при равном количестве SM теоретическая производительность Ampere в операциях над 32-битными вещественными числами увеличилась в два раза по сравнению с Turing. Пожалуй, это главное, что нужно вынести из обзора новых чипов, если нет интереса к более изощренным аспектам новой архитектуры. Польза от реорганизации SM еще и в том, что транзисторный бюджет процессора не так сильно раздулся, как если бы NVIDIA просто нарастила их количество. Чтобы насытить потребности усиленного SM в быстром доступе к данным, объем кеша L1, общий с разделяемой памятью, был увеличин с 96 до 128 Кбайт, а его пропускная способность — с 64 до 128 байт за такт. Кроме того, Ampere допускает более гибкие пропорции между L1 и разделяемой памятью. Раньше можно было выделить только 64 из 96 Кбайт одному типу данных. Теперь разделяемая память может занять вплоть до 100 Кбайт в задачах GP-GPU, хотя полезный объем кеша L1 и текстурного кеша для 3D-рендеринга по-прежнему не превышает 64 Кбайт. Объем регистрового файла — ближайшего к ALU и, соответственно, самого быстрого типа памяти в графическом процессоре — как и прежде составляет 256 Кбайт, а значит при полной загрузке тензорными инструкциями (что означает 64 warp'a в работе) остальным вычислительным блокам приходится бездействовать. Однако тензоры в новой архитектуре мы рассмотрим подробнее чуть позже. Несмотря на всю мощь Ampere, о реальном быстродействии, близком к проектным значениям, может идти речь только при рафинированной вещественночисленной нагрузке, ведь блок INT32-ядер теперь снова висит на одной ветке с одним из двух блоков FP32. Кроме того, на такты диспетчеров команд в SM претендует масса других компонентов.
Прим. Последний пункт относится лишь к серверному чипу AD100. В потребительских версиях Ampere тензорные ядра больше не выполняют команды для обыкновенных расчетов половинной точности. Или, во всяком случае, последние не отправляются диспетчером по той же линии данных. Темп производительности FP16, равный FP32, обеспечивается путем исполнения на 32-битных ALU без «упаковки», то есть лишние биты операндов просто отбрасываются. Наконец, в Turing и Ampere есть скалярные ALU, которые используются операциями условного ветвления, перехода и прочей целочисленной арифметики. В таких случаях все значения операций одной SIMT-инструкции одинаковы и вместо того, чтобы загружать ими INT32-блоки, 32 операции скаляризирутся в одну. Каждая секция SM содержит один скалярный блок, который выполняет свою инструкцию за два такта и также занимает один такт планировщика для инициализации. Таким образом, скалярные операции Ampere не имеют никаких преимуществ в пропускной способности перед векторными, только в энергоэффективности. Хотя диспетчер команд в отдельно взятой секции SM способен отдать лишь одну инструкцию за такт вычислительным блокам того или иного типа, неравная латентность исполнения создает различные комбинации нагрузки и поддерживает параллелизм. Расчеты пропускной способности, которую развивает целый SM графических процессоров Ampere, приведены в таблице для сравнения с архитектурами Turing, Pascal, а также соперничающими «красными» решениями — RDNA и GCN, по-прежнему бодро чувствующими себя в сфере GP-GPU. Заметим, что мы не стремились охватить абсолютно все сочетания инструкций, которые возможны в рассмотренных архитектурах. Пропуск тактов ALU, который в чипах NVIDIA могут вызывать операции load/store, тоже не берется во внимание (GCN и, скорее всего, RDNA обходит последнее ограничение за счет большого числа портов планировщика). Опустим и скалярные операции в Turing и Ampere, поскольку они лишь замещают нагрузку на блоках INT32 в подходящий момент. В GCN и RDNA векторые и скалярные инструкции делаются одновременно. Все, что нам было нужно, это оценить быстродействие при работе с тем или иным форматом данных — FP32, INT32, FP16, а также в тригонометрических операциях. С учетом темпа исполнения медленных инструкций мы взяли за временной интервал пропускной способности восемь тактов GPU — таким образом, в таблице остается меньше дробных чисел.
Ampere удвоил пиковую производительность в операциях над числами FP32, свойственную Turing. Но по таблице хорошо видно, что то же можно сказать, если взять за точку отсчета конкурирующую архитектуру RNDA. Кроме того, присутствие в шейдерном коде тригонометрических операций сильнее бьет по общей пропускной способности RDNA, нежели Ampere. Никуда не делась и возможность исполнять INT32- и FP32-расчеты одновременно, которой RDNA не обладает. Впрочем, сравнивая Ampere и RDNA, не следует фокусироваться на удельной производительности основного строительного блока той и другой архитектуры — SM у NVIDIA и Compute Unit у AMD. В том виде, как RDNA представлена чипами Navi, один CU слабее амперовского SM, но он, очевидно, и дешевле по транзисторному бюджету. Который из двух подходов окажется выигрышным на следующем витке противостояния между двумя чипмейкерами, мы сможем выяснить на практике уже в следующем месяце, когда будут представлены продукты на основе большого Navi и RDNA второго поколения. ⇡#Усиленные блоки трассировки лучейКаждый SM в архитектуре Turing содержит RT-ядро, выполняющее поиск пересечений между лучом и полигонами сцены. В простейшем случае такая задача крайне неэффективно и ресурсоемко решается путем перебора всех геометрических примитивов, но RT-движок Turing использует распространенный метод оптимизации под названием Bounding Volume Hierarchy. Алгоритм BVH заранее сортирует полигоны объектов по вложенным друг в друга боксам. Таким образом, чтобы быстро определить точку пересечения луча с поверхностью примитива, сперва программе нужно рекурсивным образом пройти сквозь древовидную структуру BVH. RT-ядра, представленные в чипах Turing, разделены на два механизма, один из которых отвечает за поиск полигона внутри BVH, а другой — за определение барицентрических координат пересечения с лучом на плоскости самого полигона. И хотя появление RT-ядер само по себе помогло Turing выйти на уровень быстродействия, недостижимый в рамках программного рейтрейсинга, первая итерация данной архитектуры имеет свои ограничения. А именно, два компонента RT-ядра работают строго в последовательном порядке. В Ampere это изменилось: блок пересечения с полигоном может заниматься одним лучом одновременно с тем, как блок BVH отслеживает второй. Кроме того, первый блок работает вдвое быстрее, чем раньше. 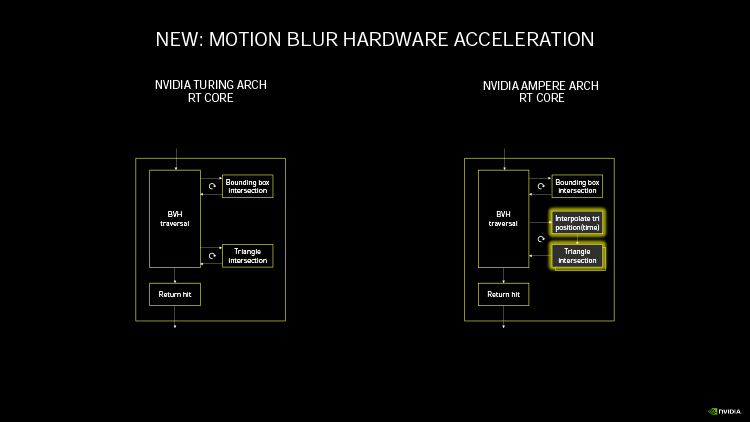 Наконец, в аппаратном рейтрейсинге на чипах Ampere есть одно функциональное нововведение — трассированный motion blur. Информация о положении геометрического примитива в кадре теперь может храниться не только в виде неизменных координат, но еще и в виде функции, описывающей его движение. Таким образом, для того, чтобы обнаружить полигон внутри BVH, нужно задать вопрос: «Где он находится в данный момент времени?». Затем каждый из множества лучей, отслеживаемых RT-ядром в пределах одного кадра, несколько раз пересекает поверхностью полигона в интерполированных координатах, соответствующих меняющемуся положению вершин вдоль заданного вектора, и получается размытие в движении. Благодаря специализированному железу трассированный motion blur на чипах Ampere выполняется в восемь раз быстрее по сравнению с теоретической скоростью на Turing. Также заметим, что движение полигона не обязано быть линейным и может, к примеру, быть круговым, как у лопастей пропеллера. В любом случае результатом становится более качественный эффект размытия по сравнению с иными, порой более изощренными, но не столь элегантными методами. Технология уже поддерживается пакетами оффлайновой трассировки лучей, совместимыми с интерфейсом NVIDIA OptiX 7.0, — такими как Blender 2.90, Chaos V-Ray 5.0, Autodesk Arnold и Redshift Renderer 3. А вот в компьютерных играх она появится не так скоро: как ни крути, она многократно увеличивает нагрузку не только на RT-ядра, но и на массив шейдерных ALU. 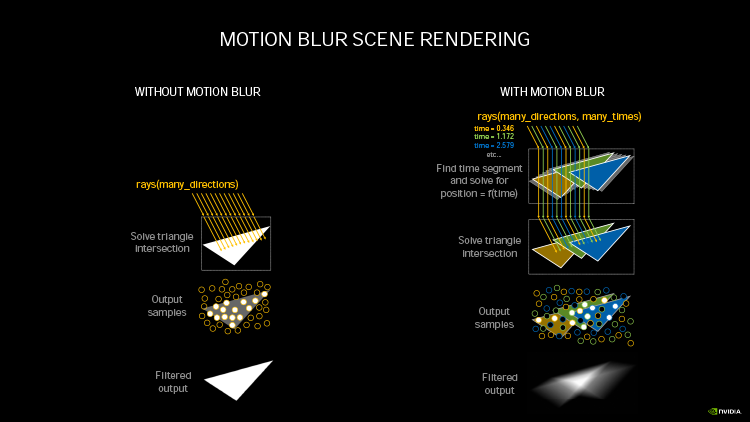 ⇡#Тензорные ядра нового поколенияСпециализированным исполнительным блоком секции SM в процессорах Turing являются два тензорных ядра, которые рассчитаны на единственный тип операций — FMA (Fused Multiply Add), а в качестве операндов принимают матрицы чисел с плавающей запятой. Подобные вычисления используются при обработке данных нейросетями (inference) как в профессиональной, так и в игровой сфере — к примеру, на них опирается фирменный алгоритм масштабирования кадров DLSS. В чипах Volta и Turing тензорное ядро перемножает две матрицы чисел половинной точности (FP16) размером 4 × 4 и складывает результат с третьей матрицей 4 × 4 (FP16 или FP32), чтобы получить финальную матрицу FP32. Таким образом, одно тензорное ядро за такт процессора выполняет 64 инструкции FMA. Что же изменилось в следующей итерации микроархитектуры? Во-первых, тензорное ядро Ampere обладает вдвое большей пропускной способностью за счет того, что размерность одной из перемножаемых матриц увеличилась с 4 × 4 до 4 × 8. Впрочем, каждая секция SM потребительских чипов Ampere теперь содержит лишь одно тензорное ядро, так что удельная производительность на такт осталась прежней. В серверном GA100 она удвоена, поскольку каждое тензорное ядро выполняет умножение матриц размером 8 × 4 и 8 × 8, но реализовывать подобную вычислительную мощность в потребительских продуктах NVIDIA пока не считает целесообразной инвестицией транзисторного бюджета. 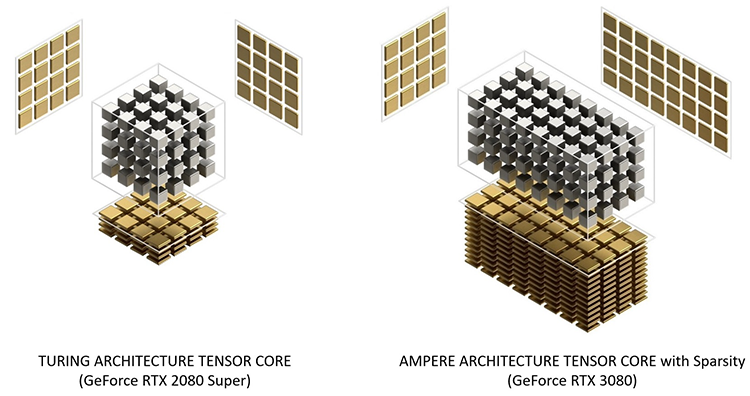 Общим нововведением для GA100 и геймерских разновидностей Ampere является поддержка структурно-разреженных матриц, которые позволяют существенно увеличить пропускную способность тензорных ядер. Давайте разберемся, о чем идет речь. Глубинное обучение нейросети начинается с того, что каждый узел определенного слоя соединен со всеми узлами следующего, а в процессе тренировки соединения приобретают веса, которые определяют «перемещение» данных, обрабатываемых нейросетью на практике. При этом обязательно возникают соединения, не оказывающие значимого влияния на точность результатов. Такие соединения, узлы или целые сегменты принято устранять для экономии вычислительных мощностей тем или иным способом, и получается, собственно говоря, разреженная сеть. К примеру, веса соединений, близкие к нулю, обнуляются, после чего проводится повторная тренировка сети — метод т. н. Fine-Grained Sparsity. В ином случае (Coarse-Grained Sparsity) изымаются целые сегменты сети. Первый подход позволяет сохранить высокую точность, но страдает от низкой оптимизации под массивно-параллельную архитектуру исполнительных блоков и памяти GPU. Так, для того, чтобы получить данные на выходе узлов в условиях Fine-Grained Sparsity, требуется различный объем вычислений, что вызывает проблемы с балансировкой нагрузки и неравномерный доступ к памяти. А вот структурная разреженность (Fine-Grained Structured Sparsity) также допускает присутствие в сети нулевых весов, но вместе с тем накладывает такие ограничения, что каждый узел определенного ряда должен иметь фиксированное число деактивированных соединений. В результате на каждый узел приходится одинаковый объем вычислений и запросов к данным. Тензорные ядра Ampere оптимизированы под обработку структурно-разреженных нейросетей таким образом, что в расчетных матрицах возможно наличие двух ненулевых значений в ряду из четырех чисел, а общая производительность также увеличивается в два раза за счет пропуска нулей. Кроме того, матрицы, разреженные в соотношении 2:4, допускают двукратную компрессию, которая экономит объем и пропускную способность различных эшелонов памяти GPU. Заметим, что Ampere не выполняет разрежение матриц на лету, но NVIDIA предоставила для этого простой алгоритм. Сначала разработчик должен выполнить тренировку нейросети с результатом в виде плотной матрицы, затем последняя конвертируется в разреженную, и наконец происходит тонкая настройка оставшихся весов. Как утверждает чипмейкер, метод не приводит к значимому падению точности обработки данных нейросетью (inference) в таких задачах, как компьютерное зрение, распознавание объектов, моделирование естественных языков и т. д. 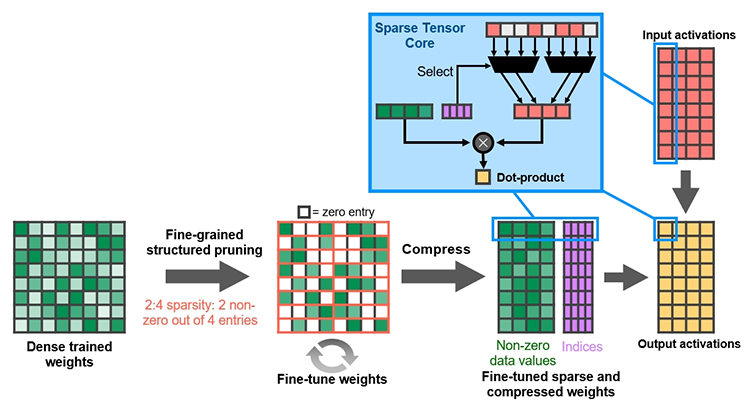 В дополнение к поддержке структурно-разреженных нейросетей, архитектура Ampere содержит иные нововведения, направленные на то, чтобы ускорить и сделать более гибкой тренировку нейросетей за счет ряда новых форматов данных. Тензорные ядра, впервые представленные чипом Volta, оперируют данными в формате FP16 и аккумулируют результат операции FMA в формате FP16 для inference-вычислений и в FP32 для тренировки. Следующая архитектура Turing принесла поддержку целочисленных форматов INT8, INT4, а также бинарных данных, которые находят применение в процедурах inference, не требующих повышенной точности. В свою очередь, Ampere располагает тем же репертуаром форматов для inference, но освоил два новых формата — TF32 и BF16 — предназначенных для тренировки. TF32 (аббревиатура для Tensor Float 32) представляет собой формат сниженной точности, который содержит 8-битную экспоненту подобно FP32, но сокращает мантиссу с 24 до 10 бит — как в FP16. Таким образом, данные, представленные в формате TF32, обладают тем же диапазоном величин, как в FP32, но точностью, свойственной FP16. Преобладающим форматом данных в машинном обучении сегодня является FP32, однако им не могут оперировать тензорные ядра, и вся работа ложится на стандартные 32-битные ALU (CUDA-ядра). Имплементация TF32 в чипах Ampere такова, что она дает возможность привлечь тензорные ядра для тренировки нейросети прозрачным образом без дополнительных усилий со стороны пользователя. Программа просто отправляет на GPU вещественночисленные данные стандартной точности, и в результате операции, не содержащие тензорной математики, по-прежнему обслуживаются CUDA-ядрами, но в ином случае тензорные ядра считывают FP32, обрабатывают его в качестве TF32 и возвращают результат опять в виде FP32. Пропускная способность таких операций на тензорных ядрах составляет ½ от FP16, тем не менее TF32 обеспечивает двукратное ускорение по сравнению с работой в чистом FP32 на CUDA-ядрах. 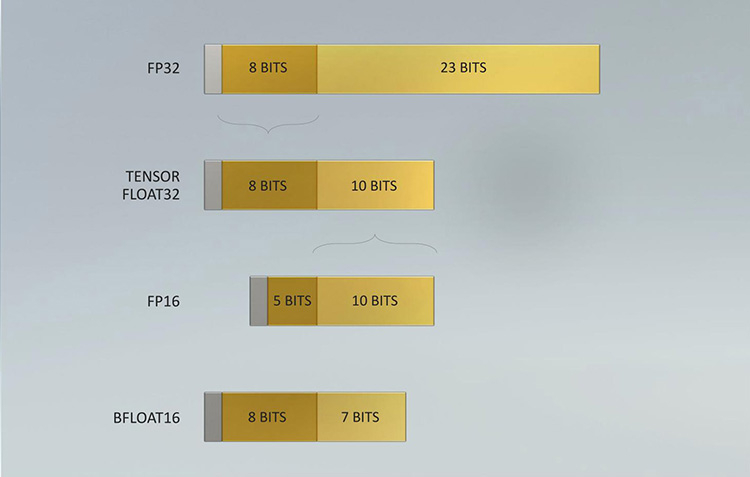 В качестве альтернативы FP16 разработчики теперь могут использовать — причем как на тензорных, так и на CUDA-ядрах — формат BF16 (bfloat16), популяризированный интеловскими продуктами для машинного обучения. В структуру FP16 заложены те же принципы, по которым построен формат TF32: вместо 5 бит экспоненты и 10 бит мантиссы, характерных для FP16, здесь используются 8 и 7 бит соответственно. Оба формата — FP16 и BF16 — доказали свою жизнеспособность в задачах тренировки нейросетей и позволяют достигнуть результатов, сравнимых с эталонным уровнем FP32. Пропускная способность чипов GA100 и GA102 в работе с FP16 и BF16 одинакова и в четыре раза превосходит таковую с использованием FP32. Наконец, архитектура Ampere позволяет выполнять на тензорных ядрах расчеты двойной точности (FP64), но эта функция зарезервирована за серверным процессором GA100 и не поддерживается чипами нижних эшелонов — GA102 и GA104. Вместе с тем, все упомянутые форматы данных за исключением бинарного и FP64 могут использоваться в структурно-разреженных матрицах и, соответственно, получают двукратное увеличение пропускной способности.  Однако и это еще не все. Следующее нововведение Ampere, связанное с тензорными ядрами, напрямую касается производительности в играх. Дело в том, что Turing не позволяет одновременно нагружать блоки трассировки лучей и тензорные ядра. Как следствие, графические шейдеры могут обрабатываться непрерывно по мере рендеринга кадра, но параллельно им в отдельный момент времени действует только один тип расчетной (compute) нагрузки — рейтрейсинг или тензорные операции DLSS. Теперь трассировка лучей, графические шейдеры и DLSS внутри SM выполняются одновременно, что дополнительно сокращает время рендеринга. Может возникнуть вопрос, каким образом DLSS находит работу, пока кадр еще не готов. Ответ в том, что DLSS имеет временную компоненту и привлекает данные предшествующих кадров. ⇡#Оперативная память GDDR6XКолоссальный потенциал вычислительной мощности старших чипов Ampere нуждается в соответствующей пропускной способности набортной памяти видеокарты. В то же время скорость переключения ячеек DRAM увеличить нелегко, а пропускную способность в последние годы удавалось наращивать главным образом за счет параллелизма. Так, например, в стандартах GDDR5X и GDDR6 ввели режим QDR, который путем фазового сдвига четырех копий сигнала (частоты WCK, Word Clock) обеспечивает двойную пропускную способность по сравнению с чипами GDDR5, передающими информацию в режиме DDR. Но при этом «реальная» частота WCK первоначально была такой же, как в рамках GDDR5. Потребительские видеокарты сегодня оснащаются памятью GDDR6 с номинальной скоростью передачи данных вплоть до 16 Гбит/с на контакт, но похоже, что таким процессорам, как GA102, требуется очередной качественный скачок. NVIDIA могла пойти путем увеличения разрядности шины памяти GPU — либо за счет перехода на HBM2, как сделано в топовых устройствах AMD и «зеленых» серверных ускорителях, включая GA100, либо за счет подключения чипов GDDR6 к широкой 512-битной шине. Но оказалось, что есть и другой выход. По заказу NVIDIA компания Micron создала для ускорителей GeForce RTX 30 новые микросхемы памяти GDDR6X. Название вызывает ассоциации с GDDR5X, и неспроста. Последний тип SGRAM был разработан специально под нужды передовых предложений NVIDIA своего времени — GeForce GTX 1080 Ti и ускорителей Quadro на том же чипе GP102. Впоследствии стандарт был кодифицирован JEDEC, но ни один другой производитель, кроме NVIDIA и Micron, не воспользовался этой возможностью. GDDR6X пока тоже не является достоянием всей индустрии, хотя наработки Micron еще могут найти применение в грядущих версиях памяти GDDR. Речь идет о коренном изменении принципов кодирования сигнала WCK. Сегодня, в памяти типа GDDR6, один такт сигнала кодирует один бит информации, соответствующий высокому и низкому напряжению проводника. В GDDR6X, напротив, применяется амплитудно-импульсная модуляция, когда амплитуда сигнала может принимать четыре различных значения (PAM4) и, соответственно, в одном такте сигнала закодированы два бита данных. В рамках PAM4 можно вдвое снизить частоту WCK, сохранив прежнюю пропускную способность, а затем постепенно наращивать и то и другое. 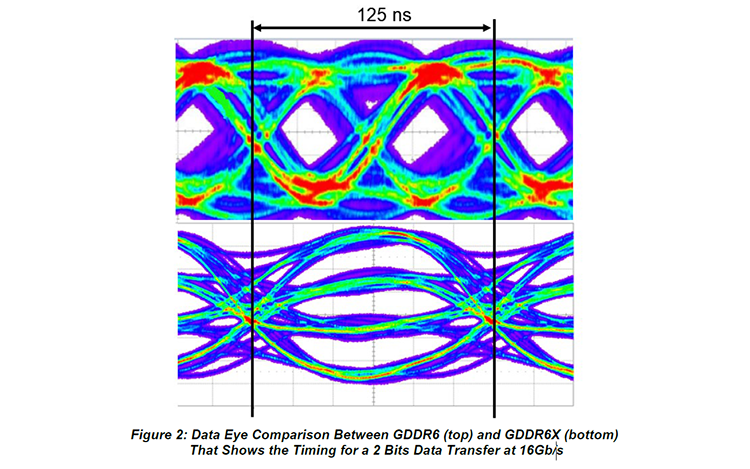 Для начала Micron наладила выпуск микросхем с номиналом 19 и 21 Гбит/с на контакт шины. 19 Гбит/с в GeForce RTX 3080 обеспечивает пропускную способность на уровне 760 Гбайт/с при шине RAM, урезанной с 384 до 320 бит. Среди современных потребительских видеокарт более высокой ПСП может похвастаться лишь Radeon VII (1 Тбайт/с), но GeForce RTX 3090 даже при том, что NVIDIA ограничилась скоростью 19,5 Гбит/с на контакт, уже приближается к показателям HBM2 благодаря полностью активной 384-битной шине памяти — 936 Гбайт/с. Сравнительно низкие «реальные» частоты благотворно влияют и на энергоэффективность чипов — по данным Micron, она увеличилась на 15 %, что совсем не повредит чрезвычайно прожорливым новинкам. Наконец, NVIDIA отмечает, что каждый чип GDDR6X теперь сопряжен с GPU двумя псевдонезависимыми каналами. В действительности и обычная память GDDR6 устроена так, что половинки микросхемы имеют собственные шины передачи команд, адресов и отдельные 16-битные шины передачи данных. Общей является лишь тактовая частота — отсюда приставка псевдо-. По всей видимости, в данном случае речь идет о более гибком управлении кристаллами DRAM, которое помогает ускорить операции прохождения структур BVH при трассировке лучей. Как бы то ни было, переход от GDDR6 к GDDR6X не прошел бесплатно: PAM4 увеличивает производительность RAM ценой повышенных требований к соотношению «сигнал — шум». И, следовательно, для того, чтобы обслуживать память с такими характеристиками, требуются изощренные контроллеры. В частности, NVIDIA использует в памяти прием, который распространен в телекоммуникационных стандартах, опирающихся на амплитудно-импульсную модуляцию, — перекодирование потока данных для предотвращения максимальных колебаний амплитуды, — а кроме того, алгоритмы динамической подстройки сигнала. Отдельную линию питания для подсистемы памяти графического процессора, которую мы упомянули в начале статьи, решили проложить не в последнюю очередь для того, чтобы опять-таки улучшить соотношение «сигнал — шум» в условиях PAM4. 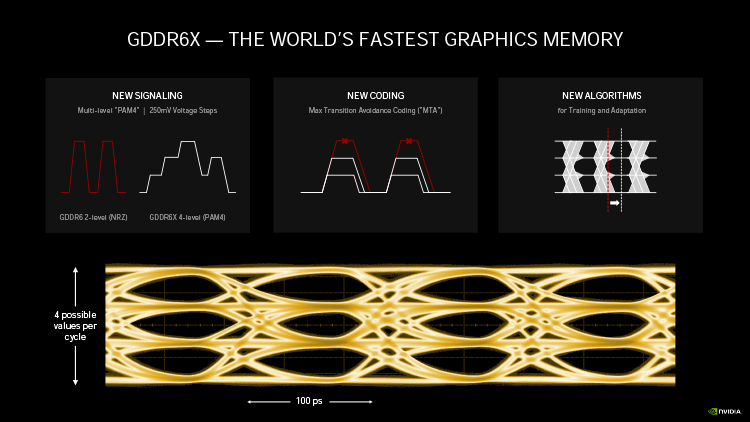 Наконец, производителям печатных плат для GeForce RTX 3080 и RTX 3090 теперь тоже придется иметь дело с более жесткими требованиями к схемотехнике, нежели когда-либо прежде. Не зря чипы RAM в референсной версии RTX 3080 распаяны так близко к подложке GPU. Отметим, что микросхемы GDDR6X выпускаются в таких же корпусах, как у GDDR6, и обладают таким же набором контактов для тех или иных сигналов. У нас нет подтверждения тому, что старый и новый тип памяти электрически совместимы между собой, но вполне возможно, что так оно и есть, а партнеры NVIDIA смогут использовать один и тот же дизайн печатной платы для GeForce RTX 3080 и RTX 3070, хотя последний рассчитан именно на GDDR6.  Главным практическим возражением при выборе памяти для GeForce 30-й серии является цена решения. GDDR6X значительно дешевле в производстве и сборке по сравнению с HBM2, но все-таки дороже GDDR6 и нуждается в более сложных печатных платах. Все эти обстоятельства дают новую пищу для сомнений в том, что производители видеокарт оригинального дизайна сумеют удержать приятные розничные цены, рекомендованные NVIDIA. И разумеется, не идет никакой речи о том, чтобы дешево стоили «Амперы» с удвоенным объемом VRAM. Micron еще не выпускает чипов емкостью больше 8 Гбит, а значит, в гипотетические 20-гигабайтные разновидности GeForce RTX 3080 и 16-гигабайтные RTX 3070 придется закладывать вдвое больше микросхем для работы в clamshell-режиме, не считая еще более сложной схемотехники печатных плат. А профессиональные ускорители на базе GA102, возможно, будут на первых порах ограничены «старой» памятью GDDR6, если NVIDIA нацелилась на отметку 48 Гбайт. ⇡#RTX IOЕще один важный аспект быстродействия GPU, над которым поработали создатели Ampere, связан с пропускной способностью соединения между графическим процессором и остальными компонентами системы. Да, все видеокарты серии GeForce RTX 30 используют интерфейс PCI Express четвертого поколения, но это лишь временное решение сложностей, возникающих при передаче данных между ПЗУ компьютера, центральным процессором и локальной памятью графической карты — в частности, в таких сценариях, как предварительная загрузка ресурсов игры или стриминг последних в реальном времени, который широко используется для преодоления ограничений емкости VRAM. Тем более, как мы уже заметили, сам объем оперативной памяти может создать трудности для GeForce RTX 3080 в не столь отдаленном будущем, а референсные спецификации GeForce RTX 3070 уже выглядят проблематично. Некоторые современные игры занимают на жестком диске или SSD свыше 200 Гбайт места, и значительная часть этих данных так или иначе должна попасть в оперативную память GPU. В традиционной логике ввода-вывода это выполняется неуклюжим способом, когда ресурсы сперва копируются в системную память, а затем в VRAM, дважды проходя через интерфейс PCI Express. Кроме того, быстрый SSD не всегда подключен напрямую к центральному процессору: к примеру, свои ограничения на пропускную способность может накладывать шина DMI между CPU и PCH в архитектуре Intel. Наконец, преобладающие в десктопах файловые системы не тоже рассчитаны на эффективную обработку такого количества запросов ввода-вывода. 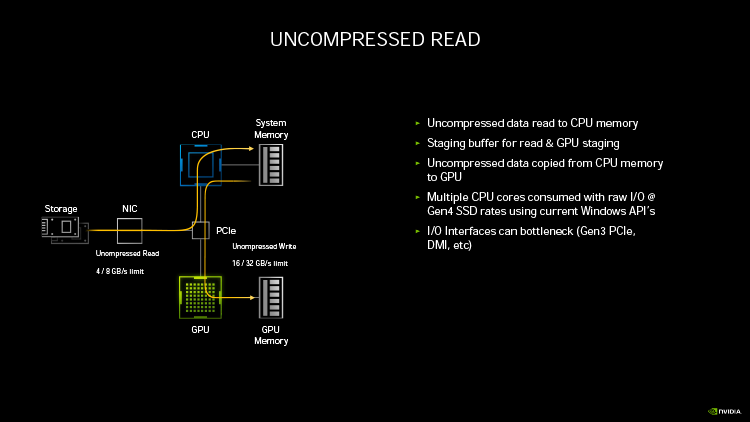 Чтобы обойти все перечисленные ограничения, разработчики игр применяют компрессию данных без потерь, но у нее есть собственные издержки: распаковка данных занимает такты процессора. В патологических случаях, которые симулировала NVIDIA, декомпрессия потока данных с твердотельного накопителя, способного выдать 7 Гбайт/с по шине PCI Express 4.0, полностью поглощает 24 ядра Ryzen Threadripper 3960X! Современные игры, очевидно, не могут создать настолько узкое бутылочное горлышко, но, судя по тому, какими темпами нарастает объем графических ресурсов, это лишь вопрос времени. 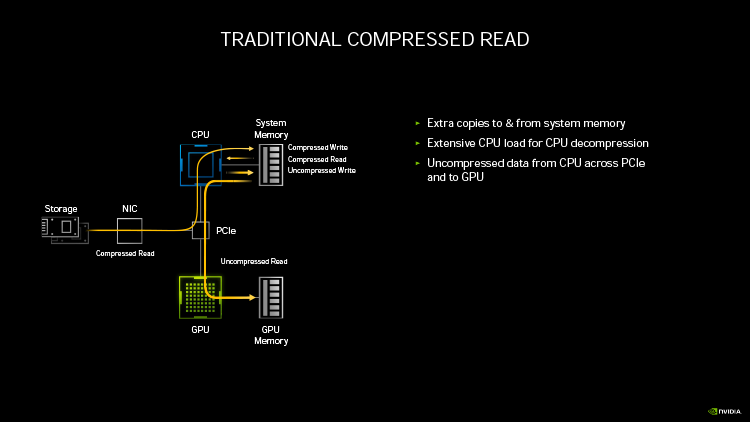 В корне решить проблему загрузки данных в память GPU может только совершенно иная архитектура ввода-вывода. Такие решения уже существуют. К примеру, в консоли нового поколения Xbox Series X применяется специальный SSD, блок аппаратной декомпрессии, а также интерфейс программирования DirectStorage. Microsoft намерена портировать DirectStorage на PC, и, если учесть будущие кросс-платформенные проекты, внедрение нового API в передовые игры для персоналок не за горами. Тем не менее для работы DirectStorage требуется не только SSD, но и средства ускоренной декомпрессии данных, снимающие нагрузку с центрального процессора. Именно эту функцию берет на себя технология RTX IO, которая вносит два ключевых изменения в способ передачи данных. Во-первых, при помощи DMA-блоков Turing и Ampere (да-да, это не эксклюзивная особенность RTX 30-й серии) графические ресурсы копируются напрямую в VRAM, минуя системную память. Во-вторых, на пути от SSD к видеокарте данные остаются сжатыми, а декомпрессию выполняет сам графический процессор путем асинхронных вычислений на шейдерных ALU. Таким образом загрузка из ПЗУ может происходить на полной скорости PCI Express 4.0, но при этом давление на CPU уменьшается в десятки раз. RTX IO под управлением DirectStorage даст разработчикам игр возможность более агрессивно использовать компрессию данных, что в итоге радикально уменьшит время первоначальной загрузки игр. С другой стороны, благодаря скоростной потоковой передаче GPU сможет на лету получать ресурсы из ПЗУ — как для того, чтобы в играх в принципе было меньше периодов загрузки, так и для экономии объема VRAM. 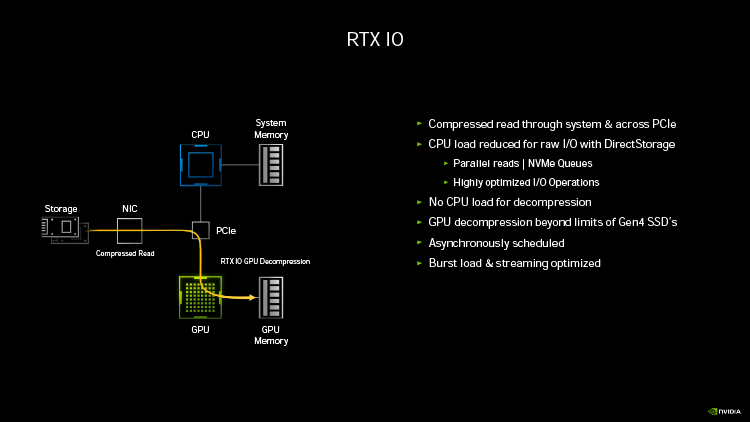 ⇡#Аппаратное декодирование AV1 и выход HDMI 2.1Чипы Ampere стали первыми графическими процессорами с блоками фиксированной функциональности для быстрого декодирования AV1 — нового, высокоэффективного формата сжатия видеозаписей, который предназначен главным образом для трансляции видео по сети. AV1 обеспечивает более высокую степень компрессии, повышенное качество изображения по сравнению с распространенными кодеками HEVC (H.265) и VP9 и в то же время свободен от лицензионных отчислений. AV1 идеально соответствует требованиям 8К-видео, но декомпрессия формата оказывает чрезвычайно сильную нагрузку на процессоры общего назначения. Так, даже современный восьмиядерный CPU не гарантирует больше 30 кадров/с при воспроизведении записей 8К с высоким динамическим диапазоном. Новая версия декодера NVDEC целиком берет эту задачу на себя. Вместе с тем на этот раз NVIDIA ничего не говорит о скорости декодирования прежних форматов H.264, HEVC и VP9. Благо чипы Turing уже достигли в ней чрезвычайно высоких показателей. Кодировщик NVENC также достался в наследство новым GPU без всяких изменений. 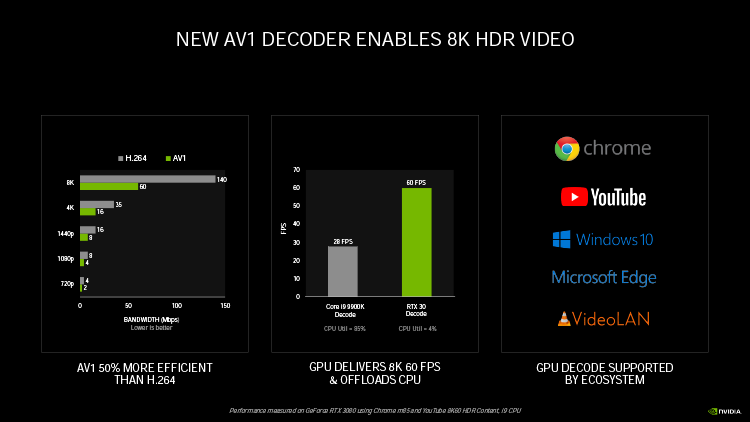 Коль скоро GeForce RTX 3090 объявлен видеокартой для игры в разрешении 8К, справедливо, что флагманский Ampere и два младших ускорителя обзавелись интерфейсом HDMI версии 2.1 с максимальной пропускную способностью, описанной стандартом (48 Гбит/с), которая как раз обеспечивает передачу 8К-сигнала с частотой обновления 60 Гц, а благодаря компрессии (DSC) — еще и HDR. ⇡#ВыводыЕсли ускорители семейства Turing стали в истории графических процессоров NVIDIA таким же поворотным моментом, как появление программируемых шейдеров в GeForce 256, а затем унифицированной шейдерной архитектуры и вычислений общего назначения в GeForce GTX 8800, Ampere вызывает ассоциации с такими славными продуктами, как Kepler и Pascal. Тогда NVIDIA сосредоточилась на росте чистой производительности, опираясь на преимущества передового техпроцесса, а пользователи наслаждались колоссальной прибавкой игровой производительности. C видеокартами GeForce RTX 30 произошло примерно то же самое. Конечно, инженеры NVIDIA не упустили возможности расширить функциональность GPU. В частности, такое нововведение, как RTX IO, выглядит весьма перспективно и имеет все шансы найти практическое применение в играх. Но RTX IO не привязана к чипам Ampere, совместима с Turing, да и в целом предыдущее поколение «зеленых» GPU уже заложило основы архитектуры, стоящей на трех китах: эффективной организации шейдерных ALU, тензорных вычислениях и аппаратно ускоренной трассировке лучей. От следующей итерации кремния требовалось только нарастить производительность (теперь уже за два поколения сразу), и, судя по тому, что мы знаем про Ampere, видеокарты RTX 30 справились с этой задачей. А главное, NVIDIA прислушалась к мнению покупателей и вернулась к правилу «больше FPS за те же деньги». Осталось убедиться в величине прибавки, но это мы выясним в ближайшие дни, когда в нашем распоряжении появятся долгожданные тестовые образцы GeForce RTX 3080 и RTX 3090. Вместе с тем должны признаться, что нас кое-что тревожит в характеристиках новинок. Да, NVIDIA установила на видеокарты 30-й серии такие же цены, как у предшественников, а если сравнивать GeForce RTX 3090 со старым «Титаном», то первая стоит даже меньше. Но все, что мы узнали об Ampere, — высокая потребляемая мощность, требующая соответствующего охлаждения, дорогие чипы памяти и сложные печатные платы — говорит о том, что эти устройства не созданы дешевыми. Так что цены партнерских продуктов в итоге могут сильно разминуться с официальными цифрами. Кроме того, пока нельзя быть уверенным в существовании альтернативных разновидностей GeForce RTX 3080 и, что особенно важно, RTX 3070 с удвоенным объемом VRAM, но их вы точно не сможете купить по рекомендованной стоимости. Наше мнение об ускорителях GeForce RTX 30 и результат надвигающейся битвы между Ampere и большими чипами AMD Navi определят не только и не столько тесты быстродействия, сколько ситуация на рынке через месяц-другой после появления в продаже.
⇣ Содержание
Если Вы заметили ошибку — выделите ее мышью и нажмите CTRL+ENTER.
Материалы по теме
|
© 1997—2025 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews. kz
![]()
![]()






 Подписаться
Подписаться