Архитектура RDNA подарила графическим картам AMD новую жизнь. Ускорители Radeon RX 5000 стали крупным явлением на массовом рынке своего времени и остаются мерилом быстродействия на доллар для новых продуктов. А благодаря следующей, 6000-й серии марка Radeon вновь заняла место на игровом олимпе. Однако у «красных» GPU были и хорошо известные слабости. По скорости трассировки лучей железо AMD могло соревноваться только с GeForce предыдущего поколения, но никак не с актуальными предложениями NVIDIA. Да и возможности быстрых матричных вычислений для масштабирования кадров при помощи ИИ, уже ставшей обязательным атрибутом современных графических процессоров, чипы Navi до сих пор не имели.

В видеокартах Radeon RX 7000 прошлые технические недостатки были устранены или по меньшей мере компенсированы путем глубокой переработки логики GPU. А в ситуации, когда старшие «зеленые» модели, GeForce RTX 4070 Ti и RTX 4080, не блещут производительностью (в пересчете на доллар цены) даже по тем ориентирам, которые раньше установила сама NVIDIA (только RTX 4090 выбивается из общего ряда, но она сама по себе чрезвычайно дорога), многие, как обычно, ждут, что придет AMD и все исправит. Ну что ж, посмотрим, смогла ли компания ответить на чаяния покупателей, недовольных лидером рынка.
А поскольку AMD замыкает годичный цикл релизов, выпустив новинки после того, как это сделали Intel и NVIDIA, мы воспользуемся такой возможностью, чтобы провести детальное сравнение конкурирующих архитектур. Но сначала обсудим главное нововведение, которым чипсет Navi 31 обогатил графические процессоры, ведь от любых предыдущих GPU он отличается тем, что это именно чипсет, который состоит из нескольких отдельных кристаллов.
⇡#Первый чиплетный GPU
AMD не раз становилась лидером в новых методах физической компоновки электронных систем, будь то память HBM или первые чиплетные CPU на массовом рынке. Последняя технология сулит массу преимуществ и графическим процессорам. В отличие от монолитного кристалла, чиплеты упрощают масштабирование и отбраковку отдельных составляющих GPU и позволяют использовать различные нормы фотолитографии для компонентов того или иного типа. Так, плотность логики GPU хорошо отзывается на переход к более тонкой технологической норме, а вот система ввода-вывода и массивный кеш третьего уровня, появившийся в архитектуре RDNA, уплотнить сложнее.
Графический процессор Navi 31, который лежит в основе первых видеокарт Radeon 7000-й серии, разделили на чиплеты по принципу, схожему с тем, как это сделано в десктопных процессорах Ryzen. Кристалл GCD (Graphics Compute Die) объединяет весь вычислительный конвейер и некоторые uncore-компоненты, включая контроллеры дисплея, PCI-Express и шины Infinity Fabric. В свою очередь, каждый из шести мелких кристаллов MCD (Memory Cache Die) содержит 16 Мбайт кеша третьего уровня и четыре 16-битных контроллера внешней памяти GDDR6. Чиплет GCD производится по новому техпроцессу TSMC N5 (разновидность которого под названием 4N также применяет NVIDIA для выпуска графических процессоров Ada Lovelace). В свою очередь, MCD довольствуются нормой N6 — ее AMD использовала ранее в чипах Navi 24 (десктопные видеокарты Radeon RX 6400/6500 XT и мобильные решения 6000-й серии).

Продолжая сравнение с центральными процессорами AMD, заострим внимание на том, что в Ryzen за счет чиплетов превосходно масштабируются именно главные вычислительные компоненты — то есть ядра x86, распределенные по чиплетам CCD (Core Complex Die), — в то время как логика Navi 31 осталась монолитной. Идея разбить «мозг» GPU на чиплеты заманчива и уже реализована в ускорителях вычислений AMD Instinct, но в существующем виде совершенно не подходит потребительским видеокартам, ведь каждый GCD все еще представляет собой независимый вычислительный конвейер со своим front-end’ом, а технологии CrossFire и SLI, которые вновь пришлось бы использовать для объединения GPU на программном уровне, плохо сочетаются с современным подходом к рендерингу, да и вообще официально мертвы.
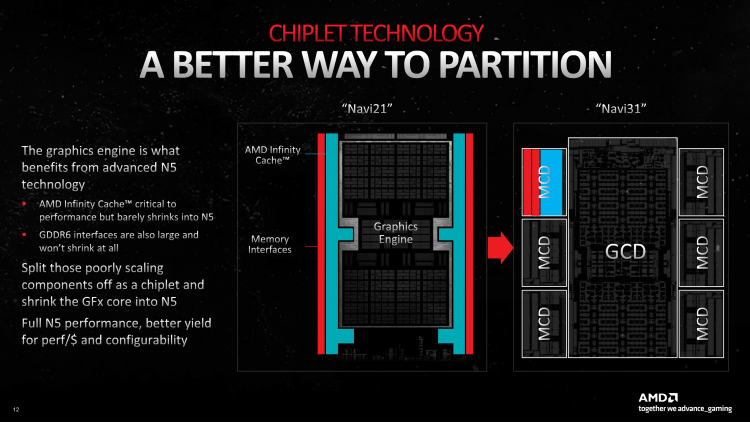
Благодаря тому, что кеш L3 и контроллеры памяти Navi 31 отселили в собственные чиплеты, кристалл GCD получился очень компактным по меркам GPU высшего эшелона: всего 300 мм2. В свою очередь, один чиплет MCD имеет площадь 37 мм2, а в сумме получается 522 мм2 — почти столько же, сколько у флагманского чипа прошлого поколения, Navi 21 (519,8 мм2).
У нас нет информации из первых рук о плотности отдельных чиплетов, но, согласно сторонним источникам, компонентный бюджет GCD равен 45,7 млрд транзисторов, а MCD — 2,05 млрд. В целом Navi 31 содержит 57,7 млрд транзисторов (и это уже официальное число), вдвое больше 26,8 млрд Navi 21. Монолитный кристалл AD102 серии Ada от NVIDIA (GeForce RTX 4090) занимает 608,5 мм2 и состоит из 76,3 млрд транзисторов. Впрочем, более подходящим конкурентом для Navi 31 является AD103, который установлен в GeForce RTX 4080. Его параметры — 378,6 мм2 и 45,9 млрд.
Главной проблемой, которую предстояло устранить инженерам AMD для того, чтобы прийти к чиплетной организации GPU, были чрезвычайно высокие требования к пропускной способности и, как следствие, сложность межчиповых соединений. Стандартный органический субстрат, который чаще всего применяется для корпусировки центральных (включая Ryzen) и графических процессоров, не позволяет достигнуть необходимой плотности проводников. Одним из возможных решений задачи является хорошо знакомый нам по видеокартам Radeon R9 Fury и Radeon RX Vega кремниевый интерпозер — пассивный кристалл, превышающий по площади вместе взятые чиплеты. Либо, как разновидность кремниевого интерпозера, небольшой мостик, соединяющий GPU с памятью HBM в серверных ускорителях AMD Instinct MI200.
Однако кремниевый интерпозер представляет собой, по сути, еще один чип, что значительно удорожает производство. Альтернативной или сопутствующей технологией является многослойная (трехмерная) компоновка чиплетов, которую также активно применяет AMD, но для Navi 31 наиболее подходящим с экономической точки зрения признали третий вариант. Чиплеты GCD и MCD находятся в одной плоскости и связаны fanout-соединениями, которые подразумевают такую форму упаковки микросхем, как FOWFL (Fanout Wafer-Level Packaging). После нарезки из кремниевых пластин чиплеты точно фиксируют в нужном положении эпоксидным компаундом, а затем сверху наращивается слой RDL (Redistribution Layer) при помощи фотолитографических инструментов, что и дает чрезвычайно мелкий шаг проводников, выходящих за пределы площади каждой микросхемы (отсюда термин fanout). У TSMC как раз есть подходящее решение под маркой InFO-R, хотя официального подтверждения тому, что AMD использовала конкретно эту — одну из многих в арсенале TSMC — технологию, нет.

AMD смогла увеличить плотность соединений Navi 31 в 10 раз по сравнению с Ryzen в пересчете на пропускную способность и снизить энергопотребление на 80 % в пересчете на бит шины. По абсолютным оценкам, все каналы Infinity Fabric между чиплетом GCD и окружающими его MCD развивают пропускную способность в 5,3 Тбайт/с. Таких громадных чисел удалось достигнуть в первую очередь за счет широкого интерфейса: cудя по каналам между кешем L2 и L3, 2304 байт за такт. При этом неизвестно, является ли он параллельным на физическом уровне (это означает 18 432 проводника!), или же, что более вероятно, используется определенная форма SerDes (сериализации-десериализации), как в тех же Ryzen. В свою очередь, базовая частота Infinity Fabric возросла на 40 %, а максимальная, если высчитать из приведенных данных, составляет около 2,3 ГГц. Для сравнения: Infinity Fabric предыдущего флагманского GPU, Navi 21, работает на частоте вплоть до 1,94 ГГц и имеет пропускную способность в 1,99 Тбайт/с.

Что касается общей энергоэффективности чипсета Navi 31, то, по испытаниям AMD, он достигает на 30 % большей тактовый частоты, чем Navi 21, при равной мощности либо такой же тактовой частоты, потребляя вдвое меньше энергии. А в целом быстродействие на ватт должно увеличиться на 54 % благодаря еще и массе архитектурных изменений, каждое из которых мы разберем далее.
Front-end и шейдерный домен графического процессора теперь развязаны по тактовым частотам: ориентиром для первого компонента в паспортных характеристиках Radeon RX 7900 XTX является Boost Clock (2,5 ГГц), для второго — Game Clock (2,3 ГГц). Это консервативные значения в свете того, что для чипсета Navi 31, как утверждает AMD, и 3 ГГц — не предел. По слухам, масштабирование тактовой частоты сдерживает дефект первых версий кремния. С другой стороны, AMD таким образом ограничила аппетиты видеокарт: 7900 XTX довольствуется сравнительно низким напряжением питания и полной мощностью в 335 Вт, в то время как NVIDIA уже пробила планку 450 Вт.
⇡#Архитектура RDNA 3 в общих чертах
GCD чипсета Navi 31 структурирован по таким же принципам, как кремний RDNA второго поколения (см. обзор Radeon RX 6800 и RX 6800 XT). Рассмотрим устройство GPU по направлению от front-end’а к back-end’у вычислительного конвейера и выделим первые изменения, которые отличают RDNA 3 от RDNA 2.
В начале цепочки находятся командные процессоры для шейдеров и вычислений общего назначения, аппаратный планировщик и геометрический процессор. Геометрический процессор RDNA 3 модифицировали таким образом, чтобы увеличить в 2,3 раза скорость обработки вызовов Multi-Draw Indirect. Последние представляют собой распространенный метод оптимизации рендеринга, когда вместо отдельных вызовов на отрисовку полигональных сеток приложение отдает лишь один, а такие задачи подготовки сцены, как отсечение невидимых сеток, GPU выполняет вместо центрального процессора.
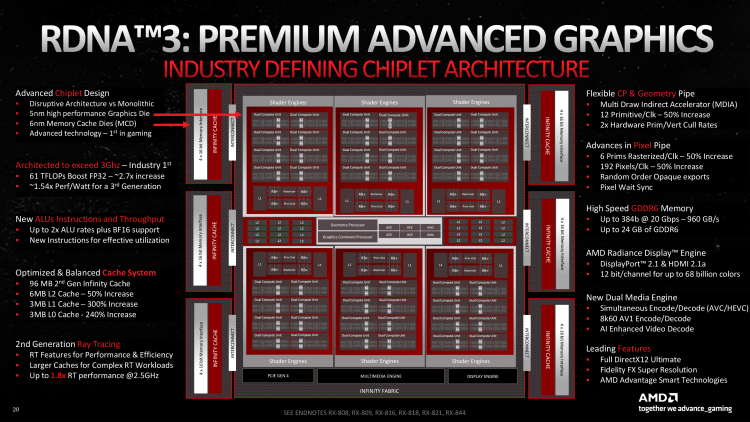
Основной массив вычислительный логики RDNA сформирован несколькими крупными блоками Shader Engine, варьируя число которых AMD сможет получить GPU той или иной категории быстродействия на основе одного архитектурного шаблона. Каждый Shader Engine имеет собственный кеш первого уровня, блок примитивов, (ответственный за сборку треугольников из вершин и тесселяцию), растеризатор (осуществляет переход от операций над геометрическими данными к пиксельным), определенное число Compute Unit’ов и блоков операций растеризации (ROP). Последние замыкают конвейер рендеринга, определяя финальный цвет пикселов в кадровом буфере. Compute Unit, как и в прошлых итерациях RDNA, а до того — архитектуре GCN, несет всю нагрузку по исполнению шейдерных программ и фильтрации текстур.
Navi 31 содержит в общей сложности 96 CU против 80 в Navi 21. Таким образом, формула GPU пришла к 6144 шейдерным ALU (смотря как считать, но об этом позже) и 384 блокам наложения текстур. Но теперь CU распределены по шести SE вместо четырех, что обеспечивает лучший баланс между блоками примитивов и растеризаторами, с одной стороны, и шейдерным ядром, с другой.
| Производитель | |
|---|
| Название |
Navi 21 |
Navi 31 |
| Где используется |
Radeon RX 6800;
Radeon RX 6800 XT;
Radeon RX 6900 XT;
Radeon RX 6950 XT
|
Radeon RX 7900 XT;
Radeon RX 7900 XTX
|
| Микроархитектура |
RDNA 2 |
RDNA 3 |
| Техпроцесс |
TSMC N7 |
TSMC N5/N6 |
| Число транзисторов, млрд |
26,8 |
57,7 |
| Площадь чипа, мм2 |
519,8 |
522 |
| Число CU/WGP/SE |
| Compute Units (CU) |
80 |
96 |
| Workgroup Processors (WGP) |
40 |
48 |
| Shader Arrays (SA) |
Нет |
Нет |
| Shader Engines (SE) |
4 |
6 |
| Конфигурация Compute Unit |
| Векторные ALU |
2 × 32 |
4 × 32 |
| Скалярные ALU |
2 |
2 |
| Тригонометрические ALU |
2 × 8 |
2 × 8 |
| Блоки трассировки лучей (Ray Accelerators) |
1 |
1 |
| Блоки наложения текстур (TMU) |
4 |
4 |
| Векторные/скалярные регистры |
1024/2560 |
1024/3840 |
| Объем кеша L0, Кбайт |
16 |
32 |
| Конфигурация Workgroup Processor (WGP) |
| Объем Local Data Store (LDS), Кбайт |
128 |
128 |
| Объем кеша инструкций, Кбайт |
32 |
32 |
| Объем скалярного кеша, Кбайт |
16 |
16 |
| Программируемые вычислительные блоки |
| Векторные ALU |
5 120 |
12 288 |
| Скалярные ALU |
160 |
192 |
| Блоки трассировки лучей (Ray Accelerators) |
80 |
96 |
| Тригонометрические ALU |
1280 |
1536 |
| Блоки фиксированной функциональности |
| Блоки наложения текстур (TMU) |
320 |
384 |
| Блоки операций растеризации (ROP) |
128 |
192 |
| Блоки трассировки лучей (Ray Accelerators) |
80 |
96 |
| Конфигурация памяти |
| Объем кеша L1, Кбайт |
1 024 |
3072 |
| Объем кеша L2, Кбайт |
4 096 |
6 144 |
| Объем Infinity Cache, Мбайт |
128 |
96 |
| Разрядность шины RAM, бит |
256 |
384 |
| Тип микросхем RAM |
GDDR6 |
GDDR6 |
|
| Интерфейс PCI Express |
4.0 x16 |
4.0 x16 |
Кроме того, блоки примитивов научились отсекать невидимые треугольники вдвое быстрее и в общей сложности могут отдать для растеризации 12 треугольников за такт против 4 в Navi 21, а общий темп растеризации увеличился с 4 до 6 примитивов. Что касается соответствующих параметров «зеленых» графических процессоров, то каждый блок GPC (аналог Shader Engine в RDNA) получает 3 примитива после отсечения невидимых, а растеризатор, принадлежащий GPC, обрабатывает один примитив за такт. Во всяком случае, такова последняя информация со времен GeForce 20-й серии, но, коль скоро NVIDIA не сообщает о каких-либо изменениях в этой области, скорее всего, их и не было. В силу того, что шейдерный домен топовых GPU предшествующего и актуального поколения от NVIDIA состоит из 7 и 12 GPC соответственно, ранние этапы конвейера рендеринга у них сильнее по сравнению с Navi 31. Как бы то ни было, фреймрейт современных игр редко упирается в производительность блоков фиксированной функциональности, связанных с геометрией, поэтому создатели GPU уже перестали обращать на них повышенное внимание.
Наконец, каждый SE в Navi 31 по-прежнему содержит эквивалент 32 ROP (192 на весь GPU), а значит, пиксельный филлрейт увеличился в полтора раза вместе с количеством SE.
RDNA 3 содержит ряд оптимизаций, направленных на исполнение пиксельных шейдеров. Во-первых, OREO (Opaque Random Export Order). Архитектура RDNA 2 умеет исполнять пиксельные шейдеры вне очереди, но одна из финальных стадий рендеринга (Blend, смешивание цветов пикселов) должна происходить в порядке, определенном приложением. Чтобы сохранить очередность, в которой завершаются шейдеры, чипы RDNA 2 пользуются специальным буфером (Re-Order Buffer), в то время как RDNA 3 ведет журнал (scoreboard), позволяющий шейдерам записывать финальный результат вне очереди и без ожидания, когда речь идет о разных или непрозрачных поверхностях.
Во-вторых, RDNA 3 более гибко оперирует зависимостями между различными пиксельными шейдерами и операциями блоков фиксированной функциональности: в случае, когда один пиксельный шейдер или блок фиксированной функциональности ожидает результат другого пиксельного шейдера или блока фиксированной функциональности, работа может быть приостановлена, чтобы переключить логику на другие задачи.
⇡#Вдвое больше шейдерных ALU (или нет?)
В Compute Unit’е RDNA 3 сконцентрированы наиболее существенные (в какой-то мере даже революционные для графических процессоров AMD) изменения архитектуры, но вместе с тем трудные для понимания неискушенной публикой и открытые для ложных интерпретаций — причем как в пользу, так и во вред AMD. Для начала вспомним, каким образом происходят вычисления в предыдущих версиях RDNA, а потом разберемся, что именно поменялось и как в результате чипы Navi третьего поколения соотносятся с актуальной логикой NVIDIA и Intel.
Compute Unit’ы представляют собой основные строительные блоки шейдерного домена и группируются попарно в так называемые WGP (Workgroup Processors) с общим массивом разделяемой памяти (LDS), кешем инструкций и скалярным кешем. В свою очередь, CU делится на две части, каждая из которых содержит следующие компоненты:
- планировщик инструкций;
- векторный блок SIMD32 из 32 ALU;
- SIMD8 — блок из 8 ALU для тригонометрических операций;
- один скалярный блок с собственным ALU (обслуживает операции условного перехода и ветвления);
- два ALU для вычислений двойной точности (FP64).
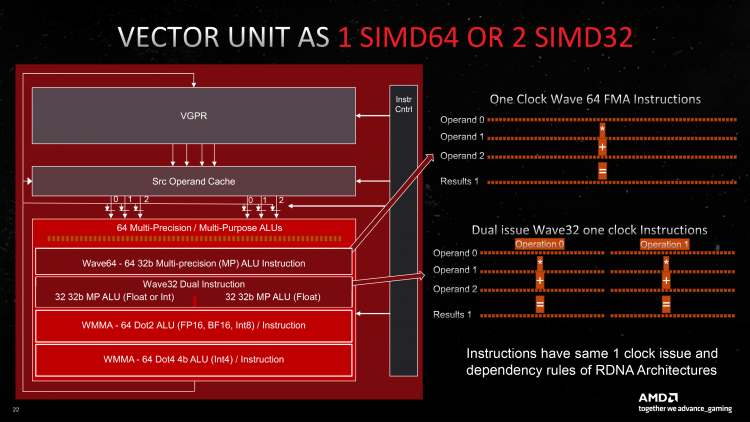
RDNA работает с группами (wavefront’ами) из 32 потоков инструкций (wave32) таким образом, что планировщик отдает одну векторную инструкцию шириной в 32 рабочие единицы за такт, а блок SIMD32 также исполняет ее за один такт. В альтернативном режиме wave64 используется 64-поточный wavefront — такая инструкция как отдается, так и выполняется за два такта.
Тригонометрические инструкции и расчеты двойной точности движутся в сниженном темпе (4 и 16 тактов в формате wave32), но отдаются за один такт и, следовательно, могут происходить параллельно с работой SIMD32.
Отдача и исполнение скалярных инструкций протекает совершенно независимо от векторных в темпе одна инструкция за такт. Одна часть скалярного блока выполняет операции условного ветвления и некоторые типы синхронизации. Другая представляет собой целочисленное ALU, открывающее альтернативный путь исполнения инструкции wavefront’а в том случае, когда все из 32 или 64 рабочие единицы содержат однородные данные, и можно смело заменить их одной. Все эти процессы мы подробно разбирали в обзоре Radeon RX 5700 и RX 5700 XT.
Отдача инструкций в RDNA 1 и 2
Compute Unit архитектуры RDNA 1 или RDNA 2 содержит в общей сложности 64 векторных ALU и обладает пропускной способностью в 2 векторные инструкции wave32 за такт. Титульная особенность RDNA 3 заключается в том, что блок SIMD32 внутри каждой из двух секций CU дублирован, и, как следствие, пропускная способность увеличилась в два раза: либо сразу две инструкции wave32, либо одна wave64 за такт. Чтобы обеспечить новым ALU быстрый доступ к данным, объем векторных регистров (ближайшего к ALU и самого быстрого хранилища) также увеличили на 50 %. При этом один SIMD32 в секции сохранил возможность целочисленных расчетов (над данными INT32). Таким образом, с формальной точки зрения Compute Unit чипов AMD теперь стоит на одном уровне с аналогичным строительным блоком графических процессоров NVIDIA, который прошел такую же трансформацию ранее.
SM (Streaming Multiprocessor) «зеленой» архитектуры Ampere (серия GeForce 30) или Ada (GeForce 40) разделен на четыре секции. Каждая из них имеет собственный планировщик и два векторных блока SIMD16 по 16 шейдерных ALU каждый (в терминологии NVIDIA это 16 CUDA-ядер). Оба SIMD16 могут обрабатывать вещественночисленные данные (FP32), но только один из них — целочисленные (INT32). GPU от NVIDIA оперируют группами (warp’ами) из 32 потоков, при этом каждая инструкция warp’а отдается за один такт, но исполняется блоком SIMD16 за два, что позволяет инициализировать два SIMD16 по очереди, поддерживая параллелизм вычислений. Секция SM также содержит блок ALU SIMD4 для тригонометрических операций: соответствующие инструкции выполняются за 8 тактов и, следовательно, в параллельном режиме с работой двух SIMD16.
Таким образом, пропускная способность целого SM составляет 128 рабочих единиц FP32 или 64 FP32 + 64 INT32 — в точности как у Compute Unit’а архитектуры RDNA 3. Однако, в отличие от CU, секция SM лишена полноценного скалярного конвейера с независимой отдачей инструкций: такие инструкции исполняет блок специализированных ALU в темпе одна за два такта, но на их инициализацию тоже тратится один такт общего планировщика. За более подробной информацией рекомендуем вернуться к нашему разбору архитектуры Ampere. Следующее поколение чипов NVIDIA, Ada, не внесло в логику шейдерных расчетов никаких принципиальных изменений.
Streaming Multiprocessor в архитектуре NVIDIA Ada Lovelace
Что касается интеловских графических процессоров Arc на базе архитектуры Xe-HPG, то их шейдерное ядро существенно отличается от конкурирующих решений и (по крайней мере, в теории) является самым мощным на потребительском рынке. Xe-core (аналог Compute Unit в чипах AMD и SM в чипах NVIDIA) содержит 16 компонентов Xe Vector Engine. Каждый из них содержит блок SIMD8 для вещественночисленных расчетов и SIMD8 для целочисленных. В отличие от AMD и NVIDIA, Intel предпочитает группировать потоки инструкций в узкие wavefront’ы по восемь штук. При этом оба SIMD8 получают и исполняют инструкции одновременно. Конкуренция за такт планировщика для инициализации существует только между INT32-совместимым SIMD8 и привязанным к нему блоком SIMD2, который выполняет тригонометрические инструкции за четыре такта. Благодаря двум равноправным конвейерам FP32 и INT32 интеловский Xe-core развивает пропускную способность одновременно в 128 рабочих единиц того и другого типа, чем не может похвастаться ни «красный» Compute Unit, ни «зеленый» Streaming Multiprocessor.
Xe Vector Engine в архитектуре Intel Xe-HPG
В результате можно сказать, что по ключевым метрикам теоретического быстродействия шейдеров графический процессор Navi 31 совершенно не отстает от Ampere и Ada от NVIDIA и уступает лишь Intel Arc. Однако на практике все не так радужно, как в теории. Неспроста в паспортных характеристиках Radeon RX 7900 XTX фигурируют 6144, а вовсе не 12 288 шейдерных ALU.
Для того чтобы инициализировать удвоенный массив SIMD32, в RDNA 3 предусмотрен новый тип инструкций VOPD (Vector Operation Dual), который позволяет упаковать вместе две независимые векторные инструкции. Формат VOPD сам по себе накладывает определенные ограничения: не больше двух операндов на каждую инструкцию, что автоматически исключает некоторые из них, включая FMA (умножение-сложение с однократным округлением) без аккумулятора. FMA — та самая инструкция, которую используют все производители GPU для иллюстрации теоретического быстродействия в гигафлопсах, но, к счастью, далеко не единственная из тех, которые находят применение в графических шейдерах и вычислениях общего назначения.
Далее, VOPD лишь в очень немногих ситуациях подходит для вычислений сниженной точности (FP16), которые, помимо рабочих приложений, уже пригодились в играх. Набор команд RDNA 3 содержит лишь две соответствующие инструкции: расчет Dot2 (скалярного произведения и сложения с аккумулятором) FP16 или BF16, но они используются редко, главным образом в задачах машинного обучения. Как следствие, большинство операций половинной точности задействуют лишь один SIMD32. Тем не менее в самом выгодном случае речь идет об удвоенном темпе FP16 — при условии, что векторные SIMD’ы не занимаются никакой другой работой (поправка справедлива и для конкурирующих графических архитектур).
| Compute Unit (AMD RDNA 1/RDNA 2) | Compute Unit (AMD RDNA 3) | Streaming Multiprocessor (NVIDIA Ampere) | Streaming Multiprocessor (NVIDIA Ada Lovelace) | Xe-core (Intel Xe-HPG) |
|---|
| Исполнительные блоки |
2 × векторных SIMD32 (FP32/INT32);
2 × векторных SIMD8 (тригонометрические);
2 × скалярных ALU
|
2 × векторных SIMD32 (FP32/INT32);
2 × векторных SIMD32 (FP32);
2 × векторных SIMD8 (тригонометрические);
2 × скалярных ALU
|
4 × векторных SIMD16 (FP32/INT32);
4 × векторных SIMD16 (FP32);
4 × векторных SIMD4 (тригонометрические);
4 × скалярных ALU;
4 × тензорных ядра
|
4 × векторных SIMD16 (FP32/INT32);
4 × векторных SIMD16 (FP32);
4 × векторных SIMD4 (тригонометрические);
4 × скалярных ALU;
4 × тензорных ядра
|
16 × векторных SIMD8 (FP32);
16 × векторных SIMD8 (INT32);
16 × векторных SIMD2 (тригонометрические);
16 × XMX
|
| Пропускная способность, рабочих единиц за такт |
64 × FP32;
64 × INT32;
128 × FP16;
16 × тригон.
|
128 × FP32;
64 × INT32;
256 × FP16;
16 × тригон.
|
128 × FP32;
64 × INT32;
128 × FP16;
16 × тригон.
|
128 × FP32;
64 × INT32;
128 × FP16;
16 × тригон.
|
128 × FP32;
128 × INT32;
256 × FP16;
32 × тригон.
|
| Пропускная способность матричных операций, FLOP за такт (FP16) |
Н/Д |
512 |
1024 |
2048 |
2048 |
Добавим, что темп расчетов двойной точности (FP64) упал в два раза по сравнению с RDNA 2, т. к. из Compute Unit’a изъяли один FP64-совместимый ALU. Благо для потребительских видеокарт это не имеет ни малейшего значения — в отличие от следующего обстоятельства.
Дело в том, что VOPD представляет собой такую форму кодирования, как VLIW (Very Long Instruction Word) — этот термин узнают читатели, которые помнят архитектуру ATI/AMD до Radeon еще той, старой 7000-й серии — с присущими ей особенностями. Для комбинации в VOPD необходимо взять инструкции из одного и того же wavefront’а, однако не всякий код содержит широкие возможности для внеочередного исполнения. Задача извлечения ILP (параллелизма на уровне инструкций) ложится на компилятор — условие, которое погубило уже немало технических инноваций.
Сама AMD консервативно оценивает влияние архитектурных преобразований RDNA 3 на реальную игровую производительность: всего 17,4 % при сравнении ускорителей на базе Navi 31 и Navi 21 с одинаковой тактовой частотой. Затем AMD добавила, что кодирование VOPD само по себе ответственно лишь за 4-процентный рост фреймрейта в трассировке лучей. Последний результат нельзя слепо проецировать на любые другие задачи, и, разумеется, по мере совершенствования компиляторов графический процессор будет активнее задействовать новые ALU. Самым эффективным решением пока являются шейдеры, доработанные вручную, либо wavefront шириной в 64 потока, который позволяет вообще отказаться от VOPD. Как бы то ни было, итог один: полное «раскрытие потенциала» RDNA 3 займет какое-то время. Но, замечу справедливости ради, и чипы NVIDIA Ampere, в которых норма шейдерных ALU на SM также была удвоена, не стали от этого в два раза быстрее собственных предшественников. А в RDNA 3 дополнительная арифметика решает еще одну очень важную задачу.
⇡#Матричные вычисления
Слабым местом графических процессоров AMD до сих пор было полное отсутствие специализированных механизмов для обработки данных нейросетями, в то время как NVIDIA выпустила на массовый рынок уже третье поколение GPU с тензорными ядрами, и Intel тоже сделала крупную ставку на матричную логику в чипах Arc. Благодаря архитектуре RDNA 3 видеокартам Radeon удалось хотя бы отчасти наверстать упущенное.
64 ALU удвоенного SIMD32 теперь могут быть целиком задействованы для умножения-сложения матриц (WMMA). В таком режиме каждый ALU на самом деле выполняет другие инструкции — Dot2 или Dot4 (скалярное произведение двух или четырех элементов матриц и последующее сложение с аккумулятором). Поддержка Dot2 и Dot4 уже появилась в RDNA второго поколения, но RDNA 3, во-первых, принимает матрицы с размерностью 16 × 16 × 16 непосредственно в качестве операндов, а во-вторых, пользуется двойным массивом шейдерных ALU и увеличенным регистровым файлом. Итоговая пропускная способность CU в инструкциях Dot2 (предназначенных для данных с плавающей запятой FP16, BF16 и целочисленных INT8) равна 128 за такт. В Dot4 (данные INT4) — 256.
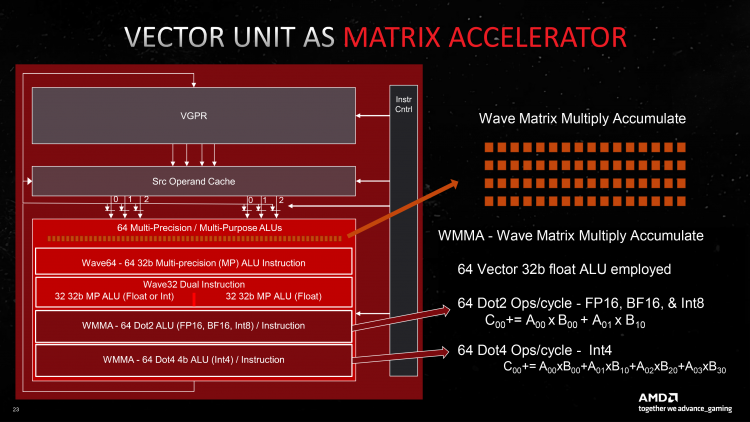
AMD не приводит данных о быстродействии в пересчете на инструкции FMA (только о том, что новый GPU выполняет их в 2,7 раза быстрее, чем Navi 21) для того, чтобы RDNA 3 можно было напрямую сравнить с решениями конкурентов, однако число индивидуальных операций вывести нетрудно: так, функция Dot2 рассчитывается в четыре действия, что дает 512 FLOP на один CU. И разумеется, блоки SIMD32 не могут заниматься никакой другой работой при загрузке матричными вычислениями. Если таким же образом разложить паспортные характеристики тензорных ядер в «зеленых» GPU, то матричная производительность потокового мультипроцессора Turing и Ampere составляет 1024 FLOP, а у Ada — 2048. Интеловский Xe-core не уступает SM чипов Ada по теоретической пропускной способности, однако имеет отдельное преимущество в том, что его матричные блоки инициализируются и параллельно с шейдерными ALU.
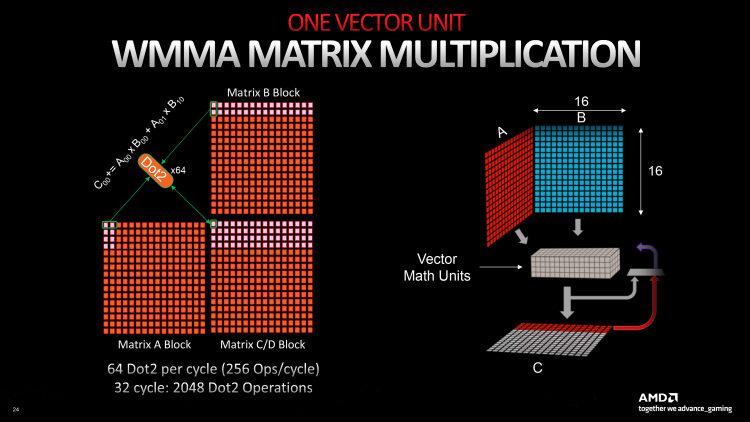
Как видите, AMD пока не удалось повторить достижения NVIDIA хотя бы четырехлетней давности, однако и то, что есть, — уже большой шаг вперед. Жаль только, что программная инфраструктура «красных» снова отстает от железа. Даже скромная матричная производительность, которой обладают Radeon RX 7000-й серии, могла бы существенно ускорить игровой рендеринг благодаря апскейлингу кадров на основе ИИ. Скорее всего, именно это произойдет в следующей, третьей версии алгоритма FSR, хотя AMD пока не признается, что FSR 3.0 задействует матричную логику RDNA 3.
⇡#Трассировка лучей
Рейтрейсинг — другая сфера, в которой ускорители Radeon 6000-й серии не могли похвастаться высоким быстродействием, ведь логика фиксированной функциональности, необходимая для трассировки лучей в реальном времени, слабо развита у «красных» графических процессоров по сравнению с продуктами NVIDIA и Intel. Так, RT-блок в потоковом мультипроцессоре Ampere выполняет два пересечения луча с треугольником и одновременно — определенное число пересечений луча с боксом BVH, которое NVIDIA не разглашает, а в архитектуре Ada первое значение еще и удвоили. В свою очередь, интеловский Xe-core достигает результатов в 1 или 12 пересечений соответственно, также в параллельном режиме. Пропускная способность Compute Unit архитектуры RDNA 2 составляет одно пересечение луча с треугольником либо четыре пересечения с боксом BVH за такт. Наконец, чипы NVIDIA и Intel обсчитывают прохождение структуры BVH в железе, в то время как RDNA 2 полагается на шейдерные ALU.

Эта характеристика справедлива и для третьей версии RDNA. Но пусть чип Navi 31 не нарастил мускулов для трассировки лучей, имеющиеся ресурсы он расходует более экономно. Так, благодаря дополнительной контрольной логике AMD задает оптимальный порядок прохождения структуры для той или иной задачи: рендеринга теней, отражений и т. д.
В контексте интерфейса DXR графический процессор теперь поддерживает флаги индивидуальных лучей, которые позволяют форсировать ряд параметров (переопределять прозрачность, отбрасывать примитивы по их ориентации и т. д.), и аналогичные по назначению флаги узлов BVH, связанные с прозрачностью, чтобы избежать лишней работы. Кроме того, в наборе команд появились специальные инструкции, при помощи которых реализован стек указателей на узлы BVH в разделяемой памяти CU. Наконец, прямое влияние на скорость рейтрейсинга оказывает увеличенный в 1,5 раза объем векторных регистров CU.
RDNA 3 также пользуется неким двухступенчатым планировщиком, чтобы избежать хаотичных обращений к памяти при шейдинге разнородных материалов. Но описание этой технологии туманно, так что здесь мы не можем поделиться какими-либо подробностями.
Если верить оценкам AMD, тонкая настройка алгоритмов рейтрейсинга в сумме с сырой вычислительной мощностью GPU дала богатые плоды: по сравнению с Radeon RX 6950 XT быстродействие Radeon RX 7900 XTX в трассированных играх увеличилось на 80 %.
⇡#Усиленный стек памяти
Апгрейд исполнительной логики RDNA повлек за собой изменения в объеме и пропускной способности, которые не обошли стороной ни один из уровней внутричиповой и внешней памяти GPU. Так, помимо дополнительных векторных регистров, принадлежащий каждому CU кеш нулевого уровня был увеличен с 16 до 32 Кбайт. В свою очередь, и объем кеша L1, к которому имеют равный доступ все CU в пределах Shader Engine, возрос с 256 до 512 Кбайт. Скорость каналов между хранилищами индивидуального CU и кешем первого уровня осталась прежней, но благодаря тому, что каждый Shader Engine содержит 16 вместо 20 CU, их общая пропускная способность в пределах GPU увеличилась с 4096 до 6144 байт за такт. Наконец, крупнейшим кешем чиплета GCD, L2, пользуются сами блоки Shader Engine. Его объем теперь составляет 6 Мбайт вместо 4 Мбайт в Navi 21, а общая пропускная способность (опять-таки вслед за количеством Shader Engine) стала в 1,5 раза выше.
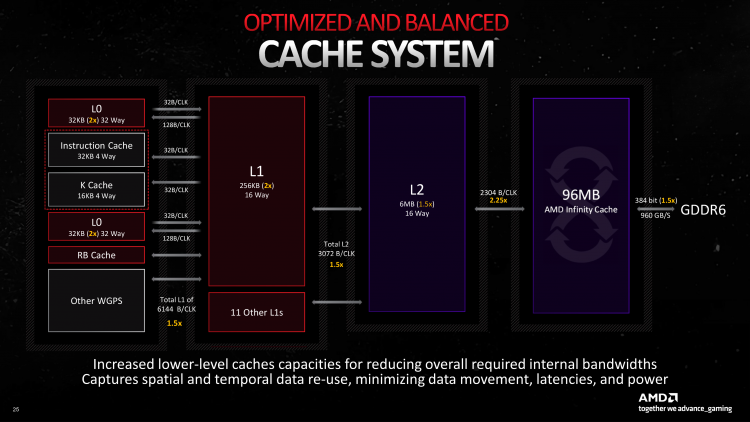
Любопытно, что, несмотря на высокие аппетиты исполнительной логики, общий объем Infinity Cache, который теперь распределен по внешним чиплетам MCD, уменьшился с 128 Мбайт в Navi 21 до 96 Мбайт. Но этот факт уравновешивает более широкий канал между L2 и L3 — 2304 вместо 1024 байт за такт, — и сумасшедшие 5,3 Тбайт/с пропускной способности межчиплетного интерфейса Infinity Fabric. К тому же флагманский ускоритель AMD вновь использует широкий 384-битный интерфейс внешней памяти. Комбинированная пропускная способность GDDR6 с номиналом 20 Гбит/с на контакт шины и Infinity Cache у топовой модели Radeon RX 7900 XTX составляет 3,5 Тбайт/с. По этому поводу может возникнуть непонимание, ведь число 3,5 Тбайт/с значительно меньше физической скорости Infinity Fabric, но здесь принимается поправка на долю попаданий в кеш: исходя из приведенных чисел, расчеты дают 58–59 % — в точности как у Navi 21 при игре в 4К согласно прошлым испытаниям AMD. То есть меньший объем L3 дополнительно компенсируют еще и отточенные алгоритмы кеширования.
Ускорители Radeon вслед за решениями нового поколения от NVIDIA и Intel продолжают использовать PCI Express 4.0. Хотя десктопные центральные процессоры уже поддерживают пятое поколение системной шины, подходящих видеокарт мы не увидим до следующего обновления архитектуры.
⇡#Контроллеры дисплея и видеокодек
Среди графических процессоров нового поколения только Navi 31 может похвастаться нативной совместимостью с последними версиями обоих интерфейсов вывода изображения: DisplayPort 2.1 и HDMI 2.1. Первый благодаря втрое большей скорости передачи данных по сравнению с DisplayPort 1.4a рассчитан на громадные разрешения вплоть до 16К. Navi 31 использует только 54 Гбит/с из теоретически возможных 77,37, а максимальными параметрами одного дисплея является разрешение 8К и частота 165 Гц (с компрессией DSC). Для домашних мониторов и это, разумеется, дело будущего, однако современные экраны с вполне осязаемыми параметрами тоже могут воспользоваться пропускной способностью DisplayPort 2.1. К примеру, режим 4К с частотой обновления 120 Гц и HDR уже лежит за пределами возможностей DisplayPort 1.4a без применения DSC или цветовой субдискретизации.
В то же время ускорители GeForce 40-й серии по-прежнему оснащаются контроллерами DisplayPort 1.4a. Видеокарты Intel Arc, с другой стороны, поддерживают DisplayPort 2.1, но HDMI в них ограничен спецификацией 2.0, а совместимость с HDMI 2.1 реализована при помощи дискретного конвертера.
AMD также подтянула скромные на фоне конкурентов возможности интегрированного ASIC для обработки видео: появилась функция кодирования AV1 с производительностью вплоть до 60 FPS при разрешении 8К, а пиковая скорость декодирования AV1 и кодирования либо декодирования двух других форматов — H.264 и HEVC — увеличилась сразу в 2–3 раза. Кроме того, H.264 и HEVC теперь можно кодировать или декодировать двумя независимыми потоками.
⇡#Технические характеристики, цены
Чипсет Navi 31 представляет революционный для графических процессоров физический дизайн и массу внутренних усовершенствований по сравнению с кремнием Navi второго поколения — в сумме это наиболее масштабные изменения, которые претерпели «красные» GPU с основания архитектуры RDNA. Но если копнуть глубже, AMD еще не удалось до конца преодолеть отставание от чипов NVIDIA в таких ключевых аспектах, как эффективность шейдерного ядра, логики матричных вычислений и рейтрейсинга. Да и по формальным количественным признакам Navi 31 уступает AD102 — топовому GPU семейства Ada. Впрочем, очередной претендент на статус самого производительного графического процессора — это совсем не то, чего сейчас требуют покупатели видеокарт. Что нужно геймерам, так это достаточно быстрый ускоритель, который обеспечит уверенный рост игрового фреймрейта на единицу стоимости без скрытой наценки за новые функции.
Компания представила два продукта на основе Navi 31. Топовая модель, Radeon RX 7900 XTX, комплектуется полностью функциональным GPU со следующей формулой исполнительных блоков: 6 144 (или 12 288, если считать удвоенные SIMD32) FP32-совместимых шейдерных ALU, 384 блока наложения текстур и 192 ROP. Ориентировочная тактовая частота в играх (Game Clock), равная 2 269 МГц, относится к шейдерному домену GPU, в то время как оппортунистическая частота шейдеров (Boost Clock) в 2 499 МГц является нормой для front-end’a Navi 31. Устройство комплектуется 24 Гбайт памяти GDDR6 с пропускной способностью 20 Гбит/с на контакт 384-битной шины. Полностью разблокированный чипсет Navi 31 также имеет 96 Мбайт внутреннего кеша третьего уровня. Резерв потребляемой мощности Radeon RX 7900 XTX составляет 335 Вт.
В свою очередь, конфигурация Radeon RX 7900 XT лишилась 12 из 96 CU и, как следствие, включает 5 376 (10 752) шейдерных ALU, 336 блоков наложения текстур, но по-прежнему 192 ROP. Один из шести чиплетов MCD вместе со своими контроллерами памяти и сегментом Infinity Cache у младшей модели не активен. Как следствие, объем L3 составляет 80 Мбайт, а разрядность шины VRAM — 320 бит. Radeon RX 7900 XT имеет 20 Гбайт памяти GDDR6 того же номинала, что и флагман, — 20 Гбит/с. Game Clock и Boost Clock графического процессора установлены на уровне 2 025 и 2 394 МГц, а потребляемая мощность не превышает 315 Вт.
| Производитель | AMD |
|---|
| Модель |
Radeon RX 6800 |
Radeon RX 6800 XT |
Radeon RX 6900 XT |
Radeon RX 6950 XT |
Radeon RX 7900 XT |
Radeon RX 7900 XTX |
| Графический процессор |
| Название |
Navi 21 XL |
Navi 21 XT |
Navi 21 XTX |
Navi 21 KXTX |
Navi 31 XT |
Navi 31 XTX |
| Микроархитектура |
RDNA 2 |
RDNA 2 |
RDNA 2 |
RDNA 2 |
RDNA 3 |
RDNA 3 |
| Техпроцесс, нм |
TSMC N7 |
TSMC N7 |
TSMC N7 |
TSMC N7 |
TSMC N5/N6 |
TSMC N5/N6 |
| Число транзисторов, млрд |
26,8 |
26,8 |
26,8 |
26,8 |
57,7 |
57,7 |
| Тактовая частота, МГц: Base Clock / Game Clock / Boost Clock |
1 700/1 815/2 105 |
1 825 /2 015/2 250 |
1 825 /2 015/2 250 |
1925 /2 100/2 310 |
1 500 /2 025/2 394 |
1 855 /2 269/2 499 |
| Шейдерные ALU FP32 |
3 840 |
4 608 |
5 120 |
5 120 |
5 376 (10 752) |
6 144 (12 288) |
| Блоки наложения текстур (TMU) |
240 |
288 |
320 |
320 |
326 |
384 |
| Блоки операций растеризации (ROP) |
96 |
128 |
128 |
128 |
192 |
192 |
| Оперативная память |
| Разрядность шины, бит |
256 |
256 |
256 |
256 |
320 |
384 |
| Тип микросхем |
GDDR6 SGRAM |
GDDR6 SGRAM |
GDDR6 SGRAM |
GDDR6 SGRAM |
GDDR6 SGRAM |
GDDR6 SGRAM |
| Тактовая частота, МГц (пропускная способность на контакт, Мбит/с) |
2 000 (16 000) |
2 000 (16 000) |
2 000 (16 000) |
2 250 (18 000) |
2 500 (20 000) |
2 500 (20 000) |
| Объем, Мбайт |
16 192 |
16 192 |
16 192 |
16 192 |
20 480 |
24 576 |
| Объем Infinity Cache, Мбайт |
128 |
128 |
128 |
128 |
80 |
96 |
| Шина ввода/вывода |
PCI Express 4.0 x16 |
PCI Express 4.0 x16 |
PCI Express 4.0 x16 |
PCI Express 4.0 x16 |
PCI Express 4.0 x16 |
PCI Express 4.0 x16 |
| Производительность |
| Пиковая производительность FP32, GFLOPS (из расчета максимальной указанной частоты) |
16 166 |
20 736 |
23 040 |
23 654 |
25 740 (51 481) |
30 708 (61 116) |
| Производительность FP64/FP32 |
1/16 |
1/16 |
1/16 |
1/16 |
1/32 (1/64) |
1/32 (1/64) |
| Производительность FP16/FP32 |
2/1 |
2/1 |
2/1 |
2/1 |
2/1 |
2/1 |
| Пропускная способность оперативной памяти, Гбайт/с |
512 |
512 |
512 |
576 |
800 |
960 |
| Вывод изображения |
| Интерфейсы вывода изображения |
DisplayPort 1.4, HDMI 2.1 |
DisplayPort 1.4, HDMI 2.1 |
DisplayPort 1.4, HDMI 2.1 |
DisplayPort 1.4, HDMI 2.1 |
DisplayPort 2.1, HDMI 2.1a |
DisplayPort 2.1, HDMI 2.1a |
| TBP/TDP, Вт |
250 |
300 |
300 |
335 |
315 |
335 |
| Розничная цена (США, без налога), $ |
579 (рекоменд. на дату выхода) |
649 (рекоменд. на дату выхода) |
999 (рекоменд. на дату выхода) |
1 099 (рекоменд. на дату выхода) |
899 (рекоменд. на дату выхода) |
999 (рекоменд. на дату выхода) |
| Розничная цена (Россия), руб. |
Н/Д |
Н/Д |
Н/Д |
Н/Д |
Н/Д |
Н/Д |
Основного конкурента Radeon RX 7900 XTX компания видит в GeForce RTX 4080. RX 7900 XTX сулит лучшие результаты в играх без рейтрейсинга, хотя его рекомендованная стоимость ниже: $999 против $1 199. В свою очередь, Radeon RX 7900 XT поступил в продажу по MSRP в $899 и должен занять промежуточное положение между GeForce RTX 4070 Ti ($799) и RTX 4080, ближе к последнему. Что касается трассировки лучей, то AMD не претендует на равенство с NVIDIA в этой дисциплине, но отставание уже не должно быть настолько катастрофическим, как раньше.
Заметим, что Radeon RX 7900 XTX не стал дороже, чем старшая модель, которая открыла 6000-ю серию, Radeon RX 6900 XT, и стоит меньше Radeon RX 6950 XT ($1 099). Что ж, AMD удалось повысить быстродействие на доллар хотя бы по формальным характеристикам GPU и результатам собственных бенчмарков. А вот к позиционированию Radeon RX 7900 XT есть вопросы. В прошлом поколении рекомендованные цены топовой (RX 6900 XT) и предтоповой (RX 6800 XT) видеокарты различались на $350. Теперь за сумму в $799, то есть почти 90 % стоимости флагмана, RX 7900 XT располагает лишь 84 % его теоретического быстродействия, не говоря уже об урезанном объеме VRAM.
Рынок еще плохо насыщен новыми видеокартами AMD, а российский — тем более. Radeon RX 7900 XTX при минимальной стоимости 114 010 руб. (в период работы над обзором) сейчас дороже GeForce RTX 4080 (от 100 990 руб.). В свою очередь, Radeon RX 7900 XT стоит как минимум 99 736 руб., а GeForce RTX 4070 Ti — 80 008. Важно и то, что речь идет о референсных моделях в упаковке тех или иных вендоров. Но со времен релиза 7000-й серии уже поступило немало сообщений о дефекте референсной системы охлаждения, который вызывает перегрев GPU при эксплуатации в типичном горизонтальном положении. Никто не знает, как много бракованных устройств попало в розницу, и все же, пока AMD не устранит проблему, более надежным выбором станет какая-либо из партнерских версий. Две такие видеокарты, от SAPPHIRE, мы и рассмотрим в обзоре.
⇡#SAPPHIRE NITRO+ Radeon RX 7900 XT/XTX: конструкция
Новые решения AMD в обзоре представляют устройства SAPPHIRE серии NITRO+. Видеокарты разогнаны относительно референсных спецификаций: параметры Game Clock и Boost Clock у Radeon RX 7900 XT повышены с 2 025 и 2 394 до 2 220 и 2 560 МГц соответственно, а у Radeon RX 7900 XTX — с 2 269 и 2 499 до 2 510 и 2 680 МГц. Впрочем, обе новинки имеют резервную копию BIOS, которая задает почти референсные частоты, — ее мы впоследствии и будем использовать в тестах производительности. Видеопамять ускорителей всегда работает на скорости, предусмотренной спецификациями AMD, — 20 Гбит/с.
Львиную долю предложений 7000-й серии на рынке пока занимают референсные модели, а вот NITRO+ — редкий зверь. В российских интернет-магазинах мы вовсе не нашли этих видеокарт, да и, к примеру, на американской площадке Newegg всё уже выкуплено. Цены последней партии были, разумеется, намного выше MSRP: $1 049 за Radeon RX 7900 XT и $1 199 за XTX. Не удивительно, ведь NITRO+, как мы сейчас убедимся, представляет собой продукт высшей категории без попыток сэкономить на каких-либо компонентах.
Устройства исполнены в освежающем и одновременно строгом стиле. Кожух системы охлаждения с гнездами под три 95-мм вентилятора выглядит как темная металлическая пластина. Сверху по всей длине проходит диффузор RGB-подсветки, но точно такая же панель есть и с обратной стороны! В стандартных корпусах она обращена к материнской плате, а производитель явно рассчитывал на дизайнерские системы, где видеокарта установлена вертикально на собственной полке.
Еще один сегмент RGB-подсветки находится под логотипом SAPPHIRE, вырезанным в металлическом бэкплейте. Защитную пластину сделали покороче, чтобы хвост радиатора, который выходит за пределы площади PCB, продувался насквозь. В отличие от референса, пластина с видеовыходами в NITRO+ перфорированная, а значит, часть нагретого воздуха сразу покидает корпус ПК.
У NITRO+ есть разъем для подключения внешнего корпусного вентилятора с автоматической регулировкой скорости вращения и контакты для синхронизации RGB-подсветки с материнской платой. Питание поступает через старые добрые восьмиконтактные разъемы — целых три штуки, которые вместе с линиями питания PCI Express обеспечивают резерв мощности в 525 Вт.
Radeon RX 7900 XTX развивает энергопотребление в 335 Вт даже по референсным спецификациям, не принимая во внимание заводской разгон NITRO+. Младшей модели хватает 315 Вт, но ускорители комплектуются одинаково мощной системой охлаждения. Любая из двух видеокарт занимает в корпусе четыре слота расширения, а другие габариты составляют 320 × 136 мм. Весят устройства по 1,9 кг.
В основании кулера лежит испарительная камера, которая снимает тепло не только с чиплетов GPU, но и со всех микросхем видеопамяти и отдает его семи тепловым трубкам. В свою очередь, компоненты VRM накрыты литой рамой из магниево-алюминиевого сплава, которая также придает всей конструкции механическую прочность.
Основной и вспомогательный радиаторы демонтируются вместе, что изрядно упрощает обслуживание. А для того, чтобы заменить или почистить вентиляторы СО, как и в прошлых изделиях SAPPHIRE, вообще не обязательно разбирать видеокарту: каждый запитан через разъем с «нулевым» усилием монтажа и держится единственным винтом.
Заметим, что в референсной версии Radeon RX 7900 XTX (но не XT) появился датчик температуры окружающего воздуха, расположенный между центральным вентилятором и радиатором СО. У SAPPHIRE NITRO+ такой функции нет.
Бэкплейт на видеокарте тоже не просто для красоты: пластина участвует в охлаждении платы благодаря термопрокладкам в зоне чипов GDDR6.
К каждой из двух моделей NITRO+ прилагается простой кронштейн, фиксирующий свободный угол конструкции при горизонтальной установке, и кабель синхронизации RGB-подсветки.
⇡#SAPPHIRE NITRO+ Radeon RX 7900 XT/XTX: печатная плата
Видеокарты SAPPHIRE собраны на кастомной печатной плате, но с таким же устройством системы питания, как у референсных образцов. Для графического процессора Navi 31 предусмотрена сложная схема VRM, которая опирается на двухлинейный ШИМ-контроллер Monolithic Power Systems MP2857 и пару MP2856. Согласно анализу Igor’s Lab, 12 фазами первой линии MP2857 сформировано питание ядра GPU, двумя фазами второй линии — питание микросхем GDDR6. MP2856 обслуживают прочие участки кристалла GPU (это еще пять фаз) и напряжение шины видеопамяти.
В общей сложности на главные компоненты видеокарты приходится 20 фаз, все они укомплектованы мощными силовыми каскадами MP87997 того же производителя, MPS, с током вплоть до 70 А.
|
|
|
|
SAPPHIRE NITRO+ Radeon RX 7900 XTX
|
Как ни странно, у младшей модели абсолютно такой же 20-фазный VRM, в то время как референс Radeon RX 7900 XT довольствуется 17 фазами.
Все фильтры на выходе регуляторов напряжения представлены плоскими полимерными конденсаторами. Кроме того, в отличие от референсной платы, у NITRO+ есть такая полезная особенность, как предохранители на силовых линиях восьмиконтактных разъемов и слота PCI Express.
|
|
|
|
SAPPHIRE NITRO+ Radeon RX 7900 XTX
|
Видеопамять Radeon RX 7900 XTX набрана двенадцатью микросхемами Hynix H56G42AS8DX-014, которые работают на своей номинальной скорости 20 Гбит/с. В силу того, что Radeon RX 7900 XT пользуется урезанной до 320 бит шиной VRAM, два чипа GDDR6 отсутствуют на его печатной плате.
Чипсет Navi 31 в Radeon RX 7900 XT и XTX выглядит одинаково. Один из шести кристаллов MCD версии XT просто деактивирован или заменен «болванкой» подходящего размера. Промежутки между чиплетами заполнены компаундом, который не только защищает субстрат GPU, но и помогает распределению термопасты.
У NITRO+ также есть трехпозиционный переключатель BIOS. В исходном положении прошивка передает управление режимами мощности фирменной утилите SAPPHIRE TriXX. Два других положения позволяют выбрать между тактовыми частотами, близкими к референсу, и заводским разгоном.
Вслед за старшими моделями 6000-й серии референсные версии нового поколения имеют два выхода DisplayPort, единственный HDMI и разъем USB Type-C, который облегчает подключение шлемов VR и некоторых мониторов. Однако инженеры SAPPHIRE приняли более практичное решение заменить USB дополнительным HDMI.
⇡#Тестовый стенд, методика тестирования
| Тестовый стенд |
|---|
| CPU |
AMD Ryzen 9 5950X (4,4 ГГц, фиксированная тактовая частота всех ядер) |
| Материнская плата |
ASUS ROG Strix X570-E Gaming (Resizable BAR вкл.) |
| Оперативная память |
G.Skill Trident Z RGB F4-3200C14D-16GTZR, 4 × 8 Гбайт (3 600 МТ/с, CL16) |
| ПЗУ |
Intel SSD 760p, 2048 Гбайт |
| Блок питания |
Corsair AX1200i, 1200 Вт |
| Система охлаждения CPU |
Corsair iCUE H115i RGB PRO XT |
| Корпус |
Открытый стенд |
| Операционная система |
Windows 10 Pro x64 |
| ПО для GPU AMD |
| Radeon RX 7900 XT/XTX |
AMD Software Adrenalin Edition 23.1.1 |
| Остальные видеокарты |
AMD Software Adrenalin Edition 22.11.2 |
| ПО для GPU NVIDIA |
| GeForce RTX 4070 Ti |
NVIDIA GeForce Game Ready Driver 527.62 |
| Остальные видеокарты |
NVIDIA GeForce Game Ready Driver 527.37 |
| Игры без трассировки лучей |
|---|
| Игра |
API |
Метод тестирования |
Настройки графики |
Полноэкранное сглаживание |
| Assassin's Creed Valhalla |
DirectX 12 |
Встроенный бенчмарк |
Макс. качество графики |
TAA High |
| Borderlands 3 |
DirectX 12 |
Встроенный бенчмарк |
Макс. качество графики |
TAA |
| Cyberpunk 2077 |
DirectX 12 |
Встроенный бенчмарк |
Макс. качество графики; Screen Space Reflections: Ultra |
TAA |
| DOOM Eternal |
Vulkan |
OCAT, начало миссии Mars Core |
Макс. качество графики |
TSSAA |
| Far Cry 6 |
DirectX 12 |
Встроенный бенчмарк |
Макс. качество графики |
TAA |
| Metro Exodus |
DirectX 12 |
Встроенный бенчмарк |
Макс. качество графики; Shading Rate: 100% |
TAA |
| Red Dead Redemption 2 |
Vulkan |
Встроенный бенчмарк |
Макс. качество графики |
TAA High |
| Total War: WARHAMMER III |
DirectX 11 |
Встроенный бенчмарк (Battle Benchmark) |
Макс. качество графики |
TAA High |
| Watch Dogs: Legion |
DirectX 12 |
Встроенный бенчмарк |
Макс. качество графики |
TAA |
| Игры с трассировкой лучей |
|---|
| Игра |
API |
Метод тестирования |
Настройки графики |
Масштабирование |
| Cyberpunk 2077 |
DirectX 12 |
Встроенный бенчмарк |
Макс. качество графики; Screen Space Reflections: Ultra |
DLSS Balanced/FSR Balanced |
| DOOM Eternal |
Vulkan |
OCAT, начало миссии Mars Core |
Макс. качество графики |
DLSS Balanced |
| Far Cry 6 |
DirectX 12 |
Встроенный бенчмарк |
Макс. качество графики |
FSR Balanced |
| Metro Exodus Enchanced Edition |
DirectX 12 |
Встроенный бенчмарк |
Макс. качество графики; Ray Tracing: Ultra; Reflections: Raytaced; VRS: 1x |
DLSS Balanced |
| Minecraft with RTX Beta |
DirectX 12 |
OCAT, бенчмарк в мире Portal Pioneers |
Макс. дальность рендеринга |
DLSS (коэффициент масштабирования зависит от целевого разрешения) |
| Quake II RTX |
Vulkan (расширения VK_KHR) |
Timedemo, demo1.dm2 |
Макс. качество графики |
FSR Balanced |
| Watch Dogs: Legion |
DirectX 12 |
Встроенный бенчмарк |
Макс. качество графики |
DLSS Balanced |
В большинстве тестовых игр показатели средней и минимальной кадровых частот выводятся из массива времени рендеринга индивидуальных кадров, который записывает встроенный бенчмарк (или утилита OCAT, если бенчмарка нет).
Средняя частота смены кадров на диаграммах является величиной, обратной среднему времени кадра. Для оценки минимальной кадровой частоты вычисляется количество кадров, сформированных в каждую секунду теста. Из этого массива чисел берется значение, соответствующее 1-му процентилю распределения. Red Dead Redemption 2 является исключением: ее встроенный бенчмарк самостоятельно регистрирует 1-й процентиль времени рендеринга кадра, из которого выводится соответствующая кадровая частота. В Assassin’s Creed Valhalla мы вынуждены ориентироваться на минимальный фреймрейт по данным интегрированного бенчмарка.
| Кодирование/декодирование видео (ffmpeg 5.x) |
|---|
| Задача |
Настройки |
API |
| AMD |
Intel |
NVIDIA |
AMD |
Intel |
NVIDIA |
| Декодирование |
H.264 |
1920 × 1080 (High Profile, L4.1); 3840 × 2160 (High Profile, L5.1) |
D3D11VA |
| HEVC |
1920 × 1080 (Main Profile, L4.0); 3840 × 2160 (Main Profile, L5.0); 7680 × 4320 (Main Profile, L6.0) |
| VP9 |
1920 × 1080; 3840 × 2160; 7680 × 4320 |
| AV1 |
| Кодирование H.264 |
1920 × 1080 |
-c:v h264_amf -quality speed -coder cabac -level 4.1 -refs 1 -b:v 3M |
-c:v h264_qsv -preset veryfast -cavlc 0 -level 4.1 -b:v 3M |
-c:v h264_nvenc -preset fast -coder cabac -level 4.1 -refs 1 -b:v 3M |
AMF |
Intel Media SDK |
NVENC |
| 3840 × 2160 |
-c:v h264_amf -quality speed -coder cabac -level 5.1 -refs 1 -b:v 7.5M |
-c:v h264_qsv -preset veryfast -cavlc 0 -level 5.1 -b:v 7.5M |
-c:v h264_nvenc -preset fast -coder cabac -level 5.1 -refs 1 -b:v 7.5M |
| Кодирование HEVC |
1920 × 1080 |
-c:v hevc_amf -quality speed -level 4 -b:v 3M |
-c:v hevc_qsv -preset veryfast -b:v 3M |
-c:v hevc_nvenc -preset fast -level 4 -b:v 3M |
| 3840 × 2160 |
-c:v hevc_amf -quality speed -level 5 -b:v 7.5M |
-c:v hevc_qsv -preset veryfast -b:v 7.5M |
-c:v hevc_nvenc -preset fast -level 5 -b:v 7.5M |
| 7680 × 4320 |
-c:v hevc_amf -quality speed -level 6 -b:v 20M |
-c:v hevc_qsv -preset veryfast -b:v 20M |
-c:v hevc_nvenc -preset fast -level 6 -refs 1 -b:v 20M |
Мощность видеокарт регистрируется отдельно от CPU и прочих компонентов ПК с помощью устройства NVIDIA PCAT. В качестве тестовой нагрузки для тестов мощности и уровня шума используется игра Cyberpunk 2077 при разрешении 3840 × 2160 и максимальных параметрах качества графики (без трассировки лучей), а также стресс-тест FurMark с наиболее агрессивными настройками (разрешение 3840 × 2160, MSAA 8x). Замеры всех параметров выполняются после прогрева видеокарты, когда температура GPU и тактовые частоты стабилизируются.
⇡#Участники тестирования
В тестировании производительности приняли участие следующие видеокарты:
- AMD Radeon RX 7900 XTX (1720/2499 МГц, 20 Гбит/с, 24 Гбайт);
- AMD Radeon RX 7900 XT (1387/2394 МГц, 20 Гбит/с, 20 Гбайт);
- AMD Radeon RX 6900 XT (1825/2250 МГц, 16 Гбит/с, 16 Гбайт);
- AMD Radeon RX 6800 XT (1825/2250 МГц, 16 Гбит/с, 16 Гбайт);
- AMD Radeon RX 6800 (1700/2105 МГц, 16 Гбит/с, 16 Гбайт);
- NVIDIA GeForce RTX 4090 (2235/2535 МГц, 21 Гбит/с, 24 Гбайт);
- NVIDIA GeForce RTX 4080 (2205/2505 МГц, 22,4 Гбит/с, 16 Гбайт);
- NVIDIA GeForce RTX 3090 (1395/1695 МГц, 19,5 Гбит/с, 24 Гбайт);
- NVIDIA GeForce RTX 3080 Ti (1365/1665 МГц, 19 Гбит/с, 12 Гбайт);
- NVIDIA GeForce RTX 3080 (1440/1710 МГц, 19 Гбит/с, 10 Гбайт).
Прим. В скобках после названий видеокарт указаны базовая и boost-частота согласно спецификациям каждого устройства. Видеокарты с заводским разгоном приведены в соответствие с референсными параметрами (или приближены к последним) при условии, что это можно сделать без ручной правки кривой тактовых частот. В противном случае используются настройки производителя.
⇡#Тактовые частоты, энергопотребление, температура, уровень шума и разгон
Благодаря тому, что у видеокарт NITRO+ есть двойной BIOS, мы рассмотрим их рабочие характеристики как при настройках, приближенных к настройкам референсных устройств, так и при заводском разгоне. Резервная прошивка Radeon RX 7900 XT задает эталонные Game Clock и Boost Clock, хотя снижает базовую частоту GPU c 2 025 до 1 387 МГц — благо последняя не имеет никакого значения в реальных условиях. В свою очередь, базовая частота Radeon RX 7900 XTX в экономичном режиме также оказалась ниже нормы (1 720 против 1 855 МГц), а Boost Clock —выше (2 304 против 2 269).
На практике обе видеокарты превзошли референсные ориентиры под сложной игровой нагрузкой: у Radeon RX 7900 XT тактовая частота шейдерного домена стабилизировалась на уровне 2 579 МГц, у XTX — 2 545. Заметим, что именно этот параметр отслеживает интерфейс драйвера AMD и такие программы, как MSI Afterburner. Независимую тактовую частоту front-end’a можно увидеть при помощи HWiNFO64: она составляет в среднем 2 773 МГц у TX и 2 753 у XTX.
Чипсет Navi 31 довольствуется низким напряжением питания — около 0,9 В, а полное энергопотребление NITRO+ Radeon RX 7900 XT и XTX составляет 330 и 365 Вт в играх, а в стресс-тесте — 335 и 372 Вт соответственно.
Заводской разгон младшей модели полностью соответствует спецификациям SAPPHIRE (частоты Game и Boost равны 2 219 и 2 599 МГц), а старшая, как выяснилось, работает при чуть большем значении Game Clock (2 526 вместо паспортных 2 510 МГц). В обоих случаях фактические тактовые частоты шейдерного домена возросли умеренно: до 2 731 МГц у XT и 2 706 у XTX. Средняя частота front-end’a при заводском разгоне составляет 2 953 и 2 974 МГц соответственно. Игровое энергопотребление увеличилось до 376 и 428 Вт, а полный резерв мощности составляет 382 и 441 Вт.
| Рабочие параметры под нагрузкой (Cyberpunk 2077) |
|---|
| Видеокарта |
Настройки |
Тактовая частота GPU, МГц (шейдерный домен) |
Тактовая частота GPU, МГц (front-end) |
Напряжение питания GPU, В |
Частота вращения вентиляторов, об/мин (% от макс.) |
Частота вращения вентиляторов 2, об/мин (% от макс.) |
| Средн. |
Макс. |
Средн. |
Макс. |
Средн. |
Макс. |
Средн. |
Средн. |
| SAPPHIRE NITRO+ Radeon RX 7900 XT (1387/2394 МГц, 20 Гбит/с, 20 Гбайт) |
Secondary BIOS |
2579 |
2610 |
2773 |
2807 |
0,89 |
0,90 |
1324 (32%) |
Н/Д |
| SAPPHIRE NITRO+ Radeon RX 7900 XT (1806/2559 МГц, 20 Гбит/с, 20 Гбайт) |
Primary BIOS |
2731 |
2772 |
2953 |
2971 |
0,95 |
0,97 |
1468 (36%) |
Н/Д |
| SAPPHIRE NITRO+ Radeon RX 7900 XT (≤3170 МГц, 22 Гбит/с, 20 Гбайт) |
Primary BIOS |
3029 |
3060 |
3114 |
3327 |
0,99 |
1,00 |
3118 (95%) |
Н/Д |
| SAPPHIRE NITRO+ Radeon RX 7900 XTX (1720/2499 МГц, 20 Гбит/с, 24 Гбайт) |
Secondary BIOS |
2545 |
2585 |
2753 |
2785 |
0,91 |
0,93 |
1412 (34%) |
Н/Д |
| SAPPHIRE NITRO+ Radeon RX 7900 XTX (1960/2679 МГц, 20 Гбит/с, 24 Гбайт) |
Primary BIOS |
2706 |
2735 |
2974 |
3031 |
0,97 |
0,98 |
1473 (36%) |
Н/Д |
| SAPPHIRE NITRO+ Radeon RX 7900 XTX (≤3160 МГц, 21 Гбит/с, 24 Гбайт) |
Primary BIOS |
2927 |
2962 |
3288 |
3302 |
1,04 |
1,05 |
3096 (100%) |
Н/Д |
| AMD Radeon RX 6800 (1700/2105 МГц, 16 Гбит/с, 16 Гбайт) |
|
2202 |
2206 |
Н/Д |
Н/Д |
1,02 |
1,03 |
1658 (50%) |
Н/Д |
| AMD Radeon RX 6800 XT (1825/2250 МГц, 16 Гбит/с, 16 Гбайт) |
|
2216 |
2233 |
Н/Д |
Н/Д |
1,06 |
1,11 |
1125 (34%) |
Н/Д |
| AMD Radeon RX 6900 XT (1825/2250 МГц, 16 Гбит/с, 16 Гбайт) |
|
2267 |
2282 |
Н/Д |
Н/Д |
1,02 |
1,04 |
1331 (40%) |
Н/Д |
| NVIDIA GeForce RTX 3080 Ti FE (1365/1665 МГц, 19 Гбит/с, 12 Гбайт) |
Термопрокладки GELID GP-Extreme |
1726 |
1740 |
Н/Д |
Н/Д |
0,89 |
0,91 |
2108 (58%) |
2108 (62%) |
| NVIDIA GeForce RTX 3090 FE (1395/1695 МГц, 19,5 Гбит/с, 24 Гбайт) |
|
1817 |
1830 |
Н/Д |
Н/Д |
0,90 |
0,91 |
1141 (43%) |
1141 (43%) |
| Palit GeForce RTX 4070 Ti GameRock OC Classic (2310/2610 МГц, 21 Гбит/с, 12 Гбайт), Silent BIOS |
Silent BIOS |
2805 |
2805 |
Н/Д |
Н/Д |
1,10 |
1,10 |
1516 (39%) |
1516 (39%) |
| NVIDIA GeForce RTX 4080 FE (2205/2505 МГц, 22,4 Гбит/с, 16 Гбайт) |
|
2775 |
2775 |
Н/Д |
Н/Д |
1,08 |
1,08 |
1383 (43%) |
1299 (39%) |
| MSI GeForce RTX 4090 SUPRIM X (2235/2625 МГц, 21 Гбит/с, 24 Гбайт), Silent BIOS |
Silent BIOS |
2760 |
2760 |
Н/Д |
Н/Д |
1,05 |
1,05 |
1153 (39%) |
1153 (39%) |
Прим. Измерение всех параметров выполняется после прогрева GPU и стабилизации тактовых частот.
Благодаря массивному кулеру видеокарт SAPPHIRE температура горячей точки GPU ограничена 81 °C как в играх, так и в стресс-тесте. Жаль, что чипы памяти охлаждаются не настолько эффективно, разогреваясь до 92 °С. Однако такие условия можно создать лишь стрессовой нагрузкой при заводском разгоне Radeon RX 7900 XTX, в то время как в играх мы зарегистрировали лишь 88 °C. А главное, оба устройства отличились чрезвычайно низким уровнем шума как при условно референсных тактовых частотах, так и в режиме фабричного оверклокинга. Писк дросселей присутствует, но очень тихий.
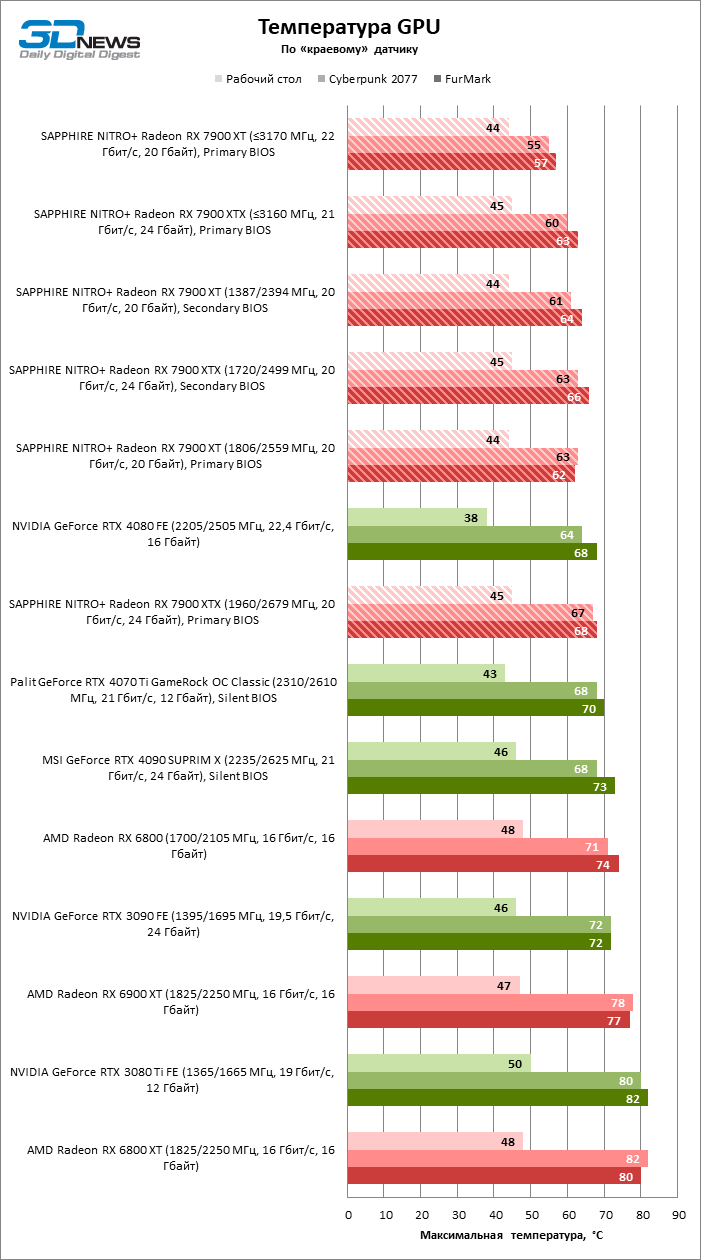
Разогнать любую из новинок вручную очень просто: по большому счету, нужно лишь двигать вперед указатель максимальной тактовой частоты в интерфейсе драйвера, пока масштабирование не упрется в резерв мощности. У NITRO+ Radeon RX 7900 XT с заводским разгоном частота шейдерного домена GPU по умолчанию ограничена 2 870 МГц, но, как выяснилось, это очень консервативное значение для Navi 31. Наша видеокарта не утратила стабильности даже при 3 170 МГц — и это вполне реалистичный ориентир в легких играх! Главным ограничителем разгона является именно потребляемая мощность: да, резерв можно увеличить на 15% от номинала программным способом, но этого все еще недостаточно. В таких условиях тактовой частоте GPU вредит повышенный вольтаж: мы достигли лучших результатов при напряжении не больше 1 В. На резерв мощности, помимо GPU, претендует и видеопамять. Чипы GDDR6, которые использовала SAPPHIRE, успешно работают на скорости 22 Гбит/с вместо исходных 20, но при этом частота графического ядра падает на пару десятков мегагерц. Тем не менее для Radeon RX 7900 XT разгон памяти все-таки важнее в силу изначально урезанной шины и меньшего объема Infinity Cache.
Если сравнить полученные тактовые частоты NITRO+ Radeon RX 7900 XT с заводскими, видеокарта разгоняется просто замечательно: частота шейдерного домена увеличилась на 298 МГц, а front-end’a — на 161. А если отталкиваться от референсного режима, то мы получили просто колоссальный результат в 450 и 341 МГц соответственно.
Флагманская модель, как и следовало ожидать, хуже поддается оверклокингу. При 15 % добавочной мощности нам удалось довести максимальную тактовую частоту GPU до практически такой же величины, как у Radeon RX 7900 XT: с 2 960 МГц до 3 160 МГц. Но для этого пришлось согласиться на напряжение питания 1,1 В. Кроме того, видеопамять не вполне стабильна на скорости в 22 Гбит/с, но XTX сам по себе меньше зависит от этого параметра — достаточно и 21 Гбит/с.
Как бы то ни было, на результаты разгона Radeon RX 7900 XTX тоже грех жаловаться. Тактовая частота шейдерного домена возросла до 2 927, а частота front-end’a GPU — до 3 288 МГц, то есть на 221 и 314 МГц выше по сравнению с фабричными параметрами NITRO+, а по сравнению с референсом речь идет о прибавке в 382 и 535 МГц соответственно.
Как мы увидим в дальнейшем, игровое быстродействие видеокарт тоже превосходно реагирует на разгон, и напрашивается вопрос, по каким причинам AMD заложила в них такой огромный «резерв прочности». От новинок наверняка можно было бы добиться и лучших результатов, если бы AMD не удалила в 7000-й серии поддержку софтверных таблиц PowerPlay, которые открывают доступ к массе дополнительных настроек видеокарты, включая диапазон регулировки мощности.
Впрочем, полное энергопотребление разогнанного NITRO+ Radeon RX 7900 XT и без того достигает 525 Вт под стрессовой нагрузкой, что в точности соответствует совокупному номиналу трех восьмиконтактных разъемов питания и силовых линий слота PCI Express, да и в играх ускоритель достигает нешуточной мощности в 507 Вт. У Radeon RX 7900 XT эти показатели составляют 460 и 439 Вт соответственно.
Также заметим, что агрессивный оверклокинг любого из двух ускорителей вызывает неприятный побочный эффект: под нагрузкой вентиляторы СО начинают вращаться на максимальных оборотах, хотя на первый взгляд в этом нет ни малейшей необходимости, ведь температура компонентов в результате стала даже ниже, чем без разгона. Будь то недоработка SAPPHIRE или самой AMD, пользователям, которые настроились на серьезный разгон, придется самостоятельно отрегулировать кривую скорости вентиляторов.
⇡#Игровые тесты (1920 × 1080)
Для игр без рейтрейсинга при разрешении 1080p возможности Radeon RX 7900 XTX избыточны, а кадровая частота существенно ограничена производительностью центрального процессора, и, как следствие, процентное соотношение между результатами соперничающих GPU компрессируется. Так, флагман 7000-й линейки опережает своего предшественника, Radeon RX 6900 XT, лишь на 25 % FPS, а GeForce RTX 3090 — на 21. Между GeForce RTX 4080 и Radeon RX 7900 XTX с практической точки зрения нет никакой разницы (хотя последний на 3 % быстрее), да и GeForce RTX 4090 отделяют от RX 7900 XTX скромные 7 % FPS.
Если фреймрейт свыше 120 FPS в режиме 1080p — это все, что вам нужно, Radeon RX 7900 XT справится с этой задачей не хуже флагмана при средних результатах лишь на 6 % ниже. Предтоповый ускоритель 7000-й серии развивает на 19 и 14 % FPS большую производительность, чем старшие модели прошлого поколения — Radeon RX 6900 XT и GeForce RTX 3090, и на 8 % опережает GeForce RTX 4070 Ti.
⇡#Игровые тесты (2560 × 1440)
В режиме 1440p Radeon RX 7900 XTX превосходит Radeon RX 6900 XT и GeForce RTX 3090 на 37 и 29 % кадровой частоты, GeForce RTX 4080 — на 5 %, а преимущество GeForce RTX 4090 перед новинкой AMD составляет 13 % фреймрейта.
В свою очередь, Radeon RX 7900 XT отстает от версии XTX на 8 %, зато на 26 и 18 % соответственно опережает Radeon RX 6900 XT и GeForce RTX 3090. Производительность Radeon RX 7900 XT и GeForce RTX 4070 Ti также существенно различается при разрешении 1440p — в среднем на 13 % в пользу AMD.
⇡#Игровые тесты (3840 × 2160)
Radeon RX 7900 XTX избавился от типичного недостатка всех прошлых образцов архитектуры RDNA: он больше не теряет позиции по сравнению со своими ближайшими конкурентами по мере того, как возрастает разрешение экрана. Наоборот, разрыв между Radeon RX 7900 XTX с одной стороны и Radeon RX 6900 XT и GeForce RTX 3090 с другой увеличился до 54 и 33 % среднего фреймрейта. GeForce RTX 4080 держится лучше, но все же пропустил Radeon RX 7900 XTX вперед на заметную величину — 8 % FPS. Впрочем, быстродействие GeForce RTX 4090 масштабируется еще лучше по причине огромных требований этой видеокарты к ресурсам центрального процессора: теперь она уже на 23 % быстрее Radeon RX 7900 XTX.
Radeon RX 7900 XT стал на 33 % быстрее Radeon RX 6900 XT, но дистанция между младшей из новинок и GeForce RTX 3090 сократилась до 15 % — похоже, на быстродействии XT сказывается урезанная шина памяти и потеря 16 Мбайт кеш-памяти L3. Тем не менее Radeon RX 7900 XT именно в 4К достиг своего максимального преимущества перед GeForce RTX 4070 Ti — 18 % средней кадровой частоты.
⇡#Игровые тесты с трассировкой лучей
Приступим к самому важному соревнованию для новых ускорителей AMD. Ну что ж, архитектура RDNA 3 действительно лучше справляется с рейтрейсингом, чем прошлая итерации. Если сравнить результаты Radeon RX 7900 XTX и Radeon RX 6900 XT, то новый флагман, в зависимости от разрешения, развивает усредненный фреймрейт на 37–63 % выше при гибридном рендеринге и на 65–66 % выше в полностью трассированных бенчмарках. А по совокупным данным всех тестов налицо рост быстродействия на 44–64 %, хотя в играх без трассировки лучей дистанция между Radeon RX 7900 XTX и Radeon RX 6900 XT колеблется от 25 до 54 % FPS.
Цена рейтрейсинга для Radeon RX 7900 XTX составляет 41–55 % кадровой частоты при том, что RX 6900 XT теряет около 51–58 % фреймрейта, стоит включить трассировку лучей на максималках. Выходит, что новый кремний AMD вполне эффективно действует в гибридных играх даже по сравнению с продуктами NVIDIA. К примеру, быстродействие GeForce RTX 3090 снижается на 35–42 % FPS, а RTX 4080 — на 31–41 %.
Radeon RX 7900 XTX поддерживает среднюю кадровую частоту не меньше 60 FPS во всех играх с гибридной моделью рендеринга (кроме Cyberpunk 2077) при разрешении вплоть до 1440p. Флагманская видеокарта меняется местами с GeForce RTX 4070 Ti в тех или иных проектах и даже выходит вперед по общему счету в режиме 4К. Но со старшими представителями 40-й серии Radeon RX 7900 XTX уже не может соревноваться на равных: преимущество RTX 4080 составляет 12–18 %, а RTX 4090 — 28–62 % в зависимости от разрешения.
Как и прежде, чем активнее игра задействует рейтрейсинг, тем сложнее приходится чипам AMD с их довольно слабой логикой фиксированной функциональности. В двух полностью трассированных бенчмарках (Minecraft и Quake II RTX) даже GeForce RTX 3080 Ti опережает Radeon RX 7900 XTX на величину от 20 до 23 % FPS, а RTX 4070 Ti — на 31–34 %. Что и говорить про RTX 4080 и RTX 4090, которые ушли вперед на 66–69 или 78–140 % FPS.
Тем не менее, по обобщенным результатам всех тестов, среди которых есть образцы щадящего рейтрейсинга (как, например, Far Cry 6), Radeon RX 7900 XTX не уступает GeForce RTX 3080 Ti и все еще находится в одной категории с GeForce RTX 4070 Ti: последний быстрее лишь на 4–9 %.
Что касается Radeon RX 7900 XT, то быстродействие младшей модели в целом на 8–13 % ниже, чем у флагмана, но его по-прежнему хватает для того, чтобы достигнуть комфортного фреймрейта в большинстве гибридных игр при разрешении 1440p без помощи апскейлинга. По сравнению с Radeon RX 6900 XT общая производительность RX 7900 XT выше на 33–43 %. В гибридном рендеринге видеокарта AMD является эквивалентом GeForce RTX 3080 Ti с преимуществом в 1–4 % FPS в пользу одного или другого устройства, а RTX 4070 Ti лидирует с отрывом в 7–8 %. Если добавить к расчетам полностью трассированные бенчмарки, GeForce RTX 3080 Ti становится на 8–12 % быстрее, а RTX 4070 Ti — на 19–20 %.
⇡#Игровые тесты в разгоне
Тактовые частоты шейдерного домена GPU около 3 ГГц и повышенная до 22 Гбит/с пропускная способность чипов памяти оказали громадное влияние на результаты игровых бенчмарков Radeon RX 7900 XT: средний фреймрейт в 4К увеличился на 13 %, и в результате предтоповая модель 7000-й линейки лишь на 7% отстает от GeForce RTX 4080.
От Radeon RX 7900 XTX нам также удалось добиться существенной прибавки в 8% быстродействия, которая обеспечила преимущество в 16 % перед GeForce RTX 4080 и позволила сократить дистанцию между RX 7900 XTX и GeForce RTX 4090 до 14 % FPS.
⇡#Тесты в рабочих приложениях
Результаты рабочих бенчмарков, как обычно, подвержены колебаниям в зависимости от оптимизации конкретных приложений под ту или иную архитектуру и поддержки специфических функций GPU. Эту динамику можно заметить даже в пределах одного тестового пакета. Так, в Premiere Pro новинки AMD не продемонстрировали никакого практического преимущества перед старшими моделями Radeon 6000-й серии по скорости проигрывания ProRes 422 и RED R3D в режиме MultiCam, зато воспроизводят H.264 почти на полной кадровой частоте исходников (60 FPS), опережая даже новейшие GPU от NVIDIA.
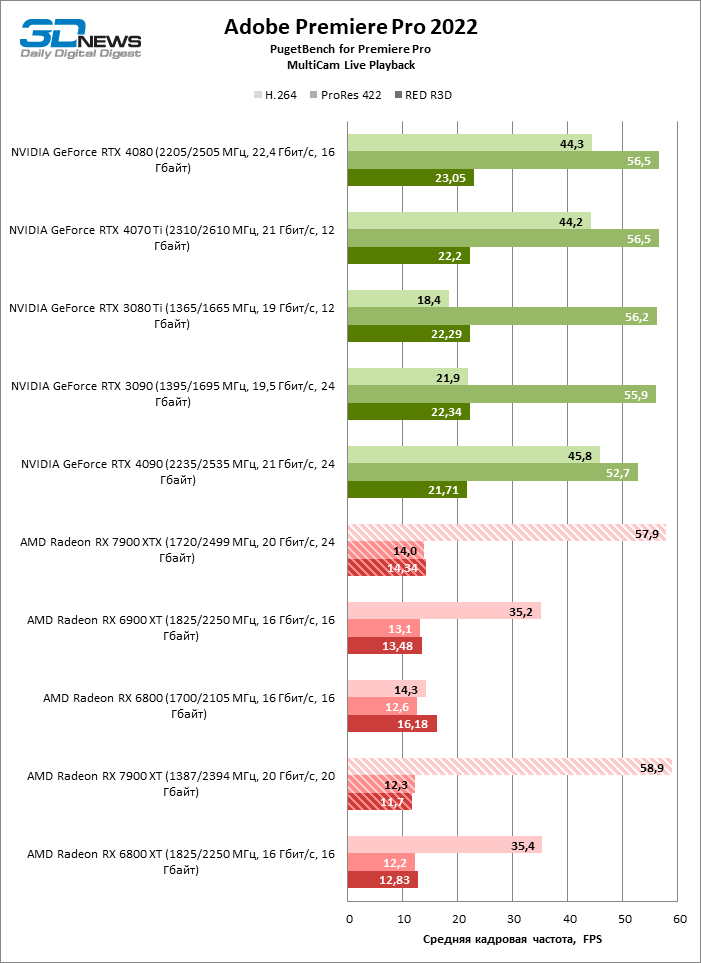
Скорость экспорта видео с требовательными эффектами также существенно увеличилась по сравнению с видеокартами Radeon 6000-й серии, но старшие модели GeForce 40 справляются с этой задачей лучше. Radeon RX 7900 XTX занял промежуточное место между GeForce RTX 4070 Ti с одной стороны и RTX 3080 Ti с другой (причем RTX 3080 Ti в этом тесте опережает RTX 4070 Ti). В свою очередь, Radeon RX 7900 XT уступает GeForce RTX 4070 Ti при максимальной сложности эффектов, но опережает соперника при более щадящей нагрузке.
Видеоредактор DaVinci Resolve использует возможности «красных» GPU более эффективно, нежели Premiere Pro. Radeon RX 7900 XTX занял четвертое место на графике скорости рендеринга эффектов после топовых моделей GeForce RTX 40-й серии и GeForce RTX 3090, а Radeon RX 7900 XT превосходит GeForce RTX 4070 Ti и уступил место GeForce RTX 3080 Ti.
По скорости конвертации форматов видео новинки не уступают «зеленым» соперникам при работе с RED R3D и радикально превосходят новые устройства NVIDIA, когда речь идет об H.264 и ProRes.
Cycles, стандартный рендерер Blender, по-прежнему игнорирует возможность аппаратного рейтрейсинга на чипах AMD (поддержка этих функций запланирована в грядущем релизе 3.5, который сейчас находится в статусе альфы). Однако и при рендеринге только на шейдерных ALU Radeon RX 7900 XTX демонстрирует громадное преимущество перед 6000-й серией и способен конкурировать с предтоповой видеокартой NVIDIA прошлого поколения — GeForce RTX 3090. Что касается Radeon RX 7900 XT, то урезанная конфигурация не так уж сильно ударила по его быстродействию, но GeForce RTX 3080 Ti пришлось пропустить вперед.
⇡#Кодирование/декодирование видео
Как и пообещала AMD, быстродействие аппаратного декодера в Navi 31 увеличилось радикально. Новая логика обеспечивает наивысшую скорость декодирования H.264 среди всех соперников. В работе с HEVC и VP9 декодеры NVIDIA и Intel по-прежнему лидируют, но преимущество нового кремния перед ASIC, интегрированным в чипы Navi второго поколения, стремится к двукратным значениям при максимальном разрешении кадра. Рост производительности при декодировании AV1 дался AMD еще труднее, и все же можно сказать, что видеокарты Radeon теперь справляются с любым стандартом доставки видеоконтента при разрешении вплоть до 8К и кадровой частоте выше 60 FPS.
В задаче кодирования H.264 и HEVC с высоким разрешением — 4К или 8К соответственно — производительность ASIC увеличилась примерно на 50 %. В результате чип AMD все еще уступает решениям NVIDIA, но достиг одного уровня с Intel Arc. Скорости кодировщика хватает для стриминга или записи в 4К с кадровой частотой вплоть до 150–160 FPS.
Пакет FFmpeg уже научился использовать свежие GPU NVIDIA и Intel для аппаратного кодирования AV1, но соответствующая функция еще недоступна графическим процессорам AMD, так что сравнение кодировщиков в работе с этим форматом мы вынуждены отложить до появления будущих видеокарт нового поколения.
⇡#Производительность на ватт
Благодаря тонкому техпроцессу и массе архитектурных оптимизаций Radeon RX 7900 XTX развивает на 28 % большую энергоэффективность по отношению к Radeon RX 6900 XT в играх без трассировки лучей. Жаль, до обещанных 54 % Navi 31 явно не дотягивает (и переход к трассированным бенчмаркам вряд ли смог бы исправить ситуацию). Вместе с тем Radeon RX 7900 XTX обеспечивает на 34 % больше FPS на ватт, чем устройства NVIDIA прошлого поколения — GeForce RTX 3080 Ti и RTX 3090. Однако «зеленые» новинки выигрывают по этому параметру на 8–10 %, если взять для сравнения GeForce RTX 4080 и RTX 4090.
В свою очередь, Radeon RX 7900 XT уступает 4 % производительности на ватт как флагманской модели 7000-й линейки, так и GeForce RTX 4070 Ti.
| Производитель | AMD | NVIDIA |
|---|
| Модель |
Radeon RX 7900 XTX |
Radeon RX 7900 XT |
Radeon RX 6800 |
Radeon RX 6800 XT |
Radeon RX 6900 XT |
GeForce RTX 3080 Ti |
GeForce RTX 3090 |
GeForce RTX 4070 Ti |
GeForce RTX 4080 |
GeForce RTX 4090 |
| Графический процессор |
Navi 31 XTX |
Navi 31 XT |
Navi 21 XL |
Navi 21 XT |
Navi 21 XT |
GA102 |
GA102 |
AD104 |
AD103 |
AD102 |
| Микроархитектура |
RDNA 3 |
RDNA 3 |
RDNA 2 |
RDNA 2 |
RDNA 2 |
Ampere |
Ampere |
Ada Lovelace |
Ada Lovelace |
Ada Lovelace |
| Техпроцесс, нм |
TSMC N5/N6 |
TSMC N5/N6 |
TSMC N7 |
TSMC N7 |
TSMC N7 |
Samsung 8N |
Samsung 8N |
TSMC 4N |
TSMC 4N |
TSMC 4N |
| Число транзисторов, млрд |
57,7 |
57,7 |
26,8 |
26,8 |
26,8 |
28,3 |
28,3 |
35,8 |
45,9 |
76,3 |
| Площадь чипа, кв. мм |
522 |
522 |
519,8 |
519,8 |
519,8 |
628 |
628 |
294,5 |
378,6 |
608,6 |
| Средняя потребляемая мощность (Cyberpunk 2077), Вт |
365 |
330 |
235 |
272 |
303 |
348 |
367 |
267 |
311 |
408 |
| Производительность/Вт |
100% |
−4% |
−19% |
−18% |
−22% |
−26% |
−25% |
−0% |
+8% |
+10% |
| Производительность/млн транзисторов |
100% |
−13% |
+12% |
+31% |
+40% |
+45% |
+53% |
+18% |
+16% |
−7% |
| Производительность/кв. мм |
100% |
−13% |
−48% |
−39% |
−35% |
−41% |
−38% |
+29% |
+27% |
+5% |
|
|
|
|
|
|
|
|
|
|
|
| Производительность/Вт (обратное сравнение) |
100% |
+4% |
+24% |
+22% |
+28% |
+34% |
+34% |
+0% |
−7% |
−9% |
| Производительность/млн транзисторов (обратное сравнение) |
100% |
+15% |
−11% |
−24% |
−29% |
−31% |
−35% |
−15% |
−14% |
+8% |
| Производительность/кв. мм (обратное сравнение) |
100% |
+15% |
+91% |
+63% |
+53% |
+69% |
+60% |
−23% |
−21% |
−5% |
⇡#Результаты игровых тестов и цены
| 1920 × 1080 |
|---|
|
Полноэкранное сглаживание |
AMD Radeon RX 7900 XTX |
AMD Radeon RX 7900 XT |
AMD Radeon RX 6800 |
AMD Radeon RX 6800 XT |
AMD Radeon RX 6900 XT |
NVIDIA GeForce RTX 3080 Ti |
NVIDIA GeForce RTX 3090 |
NVIDIA GeForce RTX 4070 Ti |
NVIDIA GeForce RTX 4080 |
NVIDIA GeForce RTX 4090 |
| Assassin's Creed Valhalla |
TAA High |
45 / 205 |
43 / 190 |
46 / 130 |
48 / 148 |
49 / 161 |
71 / 141 |
48 / 144 |
78 / 162 |
81 / 177 |
90 / 195 |
| Borderlands 3 |
TAA |
161 / 220 |
125 / 208 |
125 / 143 |
109 / 162 |
156 / 183 |
143 / 166 |
115 / 172 |
116 / 180 |
167 / 209 |
142 / 227 |
| Cyberpunk 2077 |
TAA |
137 / 184 |
132 / 176 |
94 / 117 |
111 / 135 |
115 / 143 |
113 / 142 |
115 / 148 |
115 / 155 |
112 / 174 |
127 / 192 |
| DOOM Eternal |
TSSAA |
244 / 381 |
247 / 379 |
201 / 301 |
231 / 342 |
242 / 362 |
222 / 378 |
238 / 385 |
246 / 409 |
261 / 433 |
276 / 448 |
| Far Cry 6 |
TAA |
94 / 137 |
93 / 134 |
85 / 124 |
82 / 125 |
86 / 124 |
92 / 128 |
92 / 129 |
86 / 124 |
90 / 128 |
91 / 127 |
| Metro Exodus |
TAA |
79 / 135 |
74 / 124 |
44 / 73 |
54 / 91 |
56 / 95 |
61 / 109 |
63 / 115 |
66 / 120 |
71 / 140 |
78 / 157 |
| Red Dead Redemption 2 |
TAA High |
116 / 122 |
104 / 110 |
63 / 67 |
70 / 75 |
75 / 79 |
48 / 89 |
51 / 94 |
55 / 101 |
66 / 120 |
83 / 150 |
| Total War: WARHAMMER III |
TAA High |
142 / 172 |
126 / 152 |
74 / 89 |
84 / 102 |
90 / 108 |
105 / 127 |
111 / 132 |
119 / 140 |
142 / 167 |
159 / 195 |
| Watch Dogs: Legion |
TAA |
93 / 138 |
92 / 135 |
73 / 106 |
91 / 129 |
87 / 132 |
79 / 112 |
82 / 115 |
86 / 125 |
89 / 127 |
89 / 129 |
| Макс. |
|
|
−1% |
−9% |
−7% |
−4% |
−1% |
+1% |
+7% |
+14% |
+23% |
| Средн. |
|
|
−6% |
−33% |
−24% |
−20% |
−20% |
−17% |
−13% |
−3% |
+7% |
| Мин. |
|
|
−12% |
−48% |
−41% |
−37% |
−31% |
−30% |
−21% |
−14% |
−7% |
| 2560 × 1440 |
|---|
|
Полноэкранное сглаживание |
AMD Radeon RX 7900 XTX |
AMD Radeon RX 7900 XT |
AMD Radeon RX 6800 |
AMD Radeon RX 6800 XT |
AMD Radeon RX 6900 XT |
NVIDIA GeForce RTX 3080 Ti |
NVIDIA GeForce RTX 3090 |
NVIDIA GeForce RTX 4070 Ti |
NVIDIA GeForce RTX 4080 |
NVIDIA GeForce RTX 4090 |
| Assassin's Creed Valhalla |
TAA High |
42 / 166 |
41 / 152 |
42 / 100 |
43 / 114 |
45 / 123 |
60 / 112 |
54 / 117 |
63 / 127 |
78 / 148 |
81 / 171 |
| Borderlands 3 |
TAA |
169 / 186 |
152 / 168 |
91 / 101 |
105 / 118 |
117 / 130 |
104 / 120 |
112 / 129 |
116 / 130 |
133 / 160 |
159 / 207 |
| Cyberpunk 2077 |
TAA |
114 / 138 |
102 / 124 |
65 / 76 |
75 / 87 |
81 / 94 |
82 / 95 |
86 / 101 |
88 / 103 |
104 / 124 |
129 / 162 |
| DOOM Eternal |
TSSAA |
243 / 374 |
246 / 354 |
164 / 234 |
189 / 266 |
203 / 289 |
191 / 299 |
204 / 323 |
225 / 349 |
249 / 400 |
273 / 443 |
| Far Cry 6 |
TAA |
91 / 133 |
89 / 133 |
86 / 109 |
85 / 119 |
87 / 123 |
88 / 119 |
88 / 123 |
86 / 123 |
90 / 126 |
88 / 125 |
| Metro Exodus |
TAA |
71 / 117 |
65 / 105 |
38 / 63 |
47 / 77 |
49 / 81 |
54 / 91 |
56 / 97 |
58 / 101 |
65 / 122 |
74 / 144 |
| Red Dead Redemption 2 |
TAA High |
102 / 108 |
88 / 95 |
54 / 58 |
63 / 66 |
66 / 70 |
42 / 78 |
43 / 82 |
47 / 86 |
56 / 104 |
74 / 134 |
| Total War: WARHAMMER III |
TAA High |
103 / 125 |
84 / 106 |
51 / 62 |
58 / 71 |
61 / 76 |
74 / 92 |
78 / 96 |
77 / 97 |
100 / 122 |
131 / 162 |
| Watch Dogs: Legion |
TAA |
93 / 133 |
89 / 127 |
59 / 80 |
70 / 97 |
75 / 105 |
67 / 90 |
69 / 95 |
76 / 103 |
84 / 118 |
87 / 126 |
| Макс. |
|
|
0% |
−18% |
−11% |
−8% |
−11% |
−8% |
−7% |
+7% |
+30% |
| Средн. |
|
|
−8% |
−41% |
−32% |
−27% |
−26% |
−22% |
−19% |
−5% |
+13% |
| Мин. |
|
|
−15% |
−50% |
−43% |
−39% |
−35% |
−31% |
−30% |
−14% |
−6% |
| 3840 × 2160 |
|---|
|
Полноэкранное сглаживание |
AMD Radeon RX 7900 XTX |
AMD Radeon RX 7900 XT |
AMD Radeon RX 6800 |
AMD Radeon RX 6800 XT |
AMD Radeon RX 6900 XT |
NVIDIA GeForce RTX 3080 Ti |
NVIDIA GeForce RTX 3090 |
NVIDIA GeForce RTX 4070 Ti |
NVIDIA GeForce RTX 4080 |
NVIDIA GeForce RTX 4090 |
| Assassin's Creed Valhalla |
TAA High |
36 / 101 |
34 / 89 |
31 / 55 |
34 / 64 |
35 / 69 |
37 / 70 |
47 / 74 |
45 / 74 |
52 / 94 |
53 / 112 |
| Borderlands 3 |
TAA |
95 / 105 |
81 / 90 |
48 / 54 |
57 / 63 |
62 / 70 |
61 / 69 |
65 / 74 |
61 / 68 |
78 / 87 |
113 / 127 |
| Cyberpunk 2077 |
TAA |
62 / 70 |
54 / 61 |
31 / 35 |
35 / 41 |
38 / 43 |
43 / 49 |
46 / 52 |
44 / 49 |
55 / 62 |
75 / 84 |
| DOOM Eternal |
TSSAA |
181 / 239 |
160 / 207 |
99 / 128 |
113 / 145 |
123 / 159 |
129 / 176 |
138 / 192 |
150 / 201 |
184 / 251 |
244 / 347 |
| Far Cry 6 |
TAA |
96 / 117 |
95 / 104 |
60 / 65 |
69 / 75 |
74 / 80 |
75 / 81 |
76 / 86 |
77 / 82 |
87 / 100 |
90 / 116 |
| Metro Exodus |
TAA |
53 / 83 |
46 / 71 |
29 / 44 |
35 / 52 |
36 / 55 |
40 / 63 |
43 / 67 |
45 / 68 |
54 / 86 |
65 / 116 |
| Red Dead Redemption 2 |
TAA High |
75 / 79 |
64 / 69 |
41 / 43 |
45 / 48 |
49 / 52 |
30 / 57 |
30 / 59 |
29 / 57 |
40 / 74 |
50 / 95 |
| Total War: WARHAMMER III |
TAA High |
54 / 69 |
44 / 57 |
26 / 33 |
30 / 37 |
31 / 39 |
41 / 53 |
43 / 56 |
40 / 51 |
52 / 65 |
75 / 93 |
| Watch Dogs: Legion |
TAA |
71 / 92 |
63 / 80 |
38 / 47 |
45 / 56 |
48 / 60 |
46 / 58 |
50 / 62 |
51 / 63 |
64 / 79 |
83 / 106 |
| Макс. |
|
|
−11% |
−44% |
−36% |
−32% |
−23% |
−19% |
−16% |
+5% |
+45% |
| Средн. |
|
|
−13% |
−48% |
−39% |
−35% |
−29% |
−25% |
−27% |
−8% |
+23% |
| Мин. |
|
|
−17% |
−52% |
−46% |
−43% |
−37% |
−33% |
−35% |
−17% |
−1% |
⇡#Результаты игровых тестов с трассировкой лучей и цены
| 1920 × 1080 |
|---|
|
Полноэкранное сглаживание |
AMD Radeon RX 7900 XTX |
AMD Radeon RX 7900 XT |
AMD Radeon RX 6800 |
AMD Radeon RX 6800 XT |
AMD Radeon RX 6900 XT |
NVIDIA GeForce RTX 3080 Ti |
NVIDIA GeForce RTX 3090 |
NVIDIA GeForce RTX 4070 Ti |
NVIDIA GeForce RTX 4080 |
NVIDIA GeForce RTX 4090 |
| Cyberpunk 2077 |
TAA |
48 / 57 |
43 / 52 |
23 / 29 |
28 / 34 |
30 / 37 |
53 / 61 |
56 / 65 |
59 / 69 |
74 / 85 |
94 / 114 |
| DOOM Eternal |
TSSAA |
212 / 298 |
194 / 273 |
108 / 159 |
124 / 185 |
132 / 197 |
176 / 269 |
191 / 276 |
211 / 303 |
218 / 329 |
235 / 356 |
| Far Cry 6 |
TAA |
81 / 112 |
82 / 113 |
49 / 103 |
78 / 104 |
79 / 106 |
79 / 101 |
79 / 103 |
80 / 104 |
79 / 104 |
78 / 103 |
| Metro Exodus Enchanced Edition |
TAA |
68 / 100 |
61 / 90 |
36 / 53 |
43 / 63 |
46 / 68 |
52 / 81 |
56 / 86 |
58 / 93 |
67 / 113 |
75 / 133 |
| Minecraft with RTX Beta |
TAA |
81 / 98 |
75 / 87 |
39 / 46 |
46 / 54 |
50 / 58 |
111 / 133 |
79 / 141 |
126 / 144 |
95 / 178 |
63 / 168 |
| Quake II RTX |
TAA |
Н/Д / 134 |
Н/Д / 117 |
Н/Д / 64 |
Н/Д / 76 |
Н/Д / 83 |
Н/Д / 139 |
Н/Д / 146 |
Н/Д / 162 |
Н/Д / 201 |
Н/Д / 247 |
| Watch Dogs: Legion |
TAA |
70 / 96 |
64 / 88 |
40 / 52 |
48 / 63 |
52 / 68 |
60 / 76 |
62 / 81 |
65 / 86 |
70 / 90 |
71 / 93 |
| Макс. |
|
|
+1% |
−8% |
−7% |
−5% |
+36% |
+44% |
+47% |
+82% |
+100% |
| Средн. |
|
|
−8% |
−43% |
−35% |
−31% |
−2% |
+3% |
+9% |
+27% |
+42% |
| Мин. |
|
|
−13% |
−53% |
−45% |
−41% |
−21% |
−16% |
−10% |
−7% |
−8% |
| 2560 × 1440 |
|---|
|
Полноэкранное сглаживание |
AMD Radeon RX 7900 XTX |
AMD Radeon RX 7900 XT |
AMD Radeon RX 6800 |
AMD Radeon RX 6800 XT |
AMD Radeon RX 6900 XT |
NVIDIA GeForce RTX 3080 Ti |
NVIDIA GeForce RTX 3090 |
NVIDIA GeForce RTX 4070 Ti |
NVIDIA GeForce RTX 4080 |
NVIDIA GeForce RTX 4090 |
| Cyberpunk 2077 |
TAA |
31 / 37 |
27 / 33 |
14 / 18 |
16 / 21 |
18 / 23 |
34 / 40 |
36 / 42 |
37 / 43 |
47 / 54 |
66 / 77 |
| DOOM Eternal |
TSSAA |
172 / 235 |
153 / 209 |
85 / 121 |
95 / 134 |
97 / 144 |
148 / 213 |
157 / 227 |
170 / 242 |
207 / 282 |
138 / 327 |
| Far Cry 6 |
TAA |
81 / 111 |
82 / 111 |
78 / 93 |
77 / 100 |
77 / 102 |
77 / 97 |
78 / 101 |
79 / 102 |
78 / 99 |
78 / 101 |
| Metro Exodus Enchanced Edition |
TAA |
54 / 77 |
48 / 68 |
29 / 39 |
35 / 47 |
37 / 50 |
44 / 62 |
46 / 66 |
48 / 71 |
58 / 89 |
73 / 119 |
| Minecraft with RTX Beta |
TAA |
54 / 61 |
47 / 54 |
24 / 27 |
28 / 32 |
31 / 35 |
76 / 83 |
77 / 89 |
80 / 88 |
104 / 113 |
79 / 160 |
| Quake II RTX |
TAA |
Н/Д / 79 |
Н/Д / 69 |
Н/Д / 38 |
Н/Д / 43 |
Н/Д / 47 |
Н/Д / 82 |
Н/Д / 87 |
Н/Д / 92 |
Н/Д / 121 |
Н/Д / 166 |
| Watch Dogs: Legion |
TAA |
54 / 72 |
49 / 64 |
28 / 36 |
31 / 43 |
34 / 45 |
47 / 57 |
48 / 60 |
52 / 62 |
62 / 77 |
71 / 93 |
| Макс. |
|
|
0% |
−16% |
−10% |
−8% |
+36% |
+46% |
+44% |
+85% |
+162% |
| Средн. |
|
|
−10% |
−46% |
−38% |
−34% |
−2% |
+4% |
+7% |
+31% |
+71% |
| Мин. |
|
|
−13% |
−56% |
−48% |
−43% |
−21% |
−17% |
−14% |
−11% |
−9% |
| 3840 × 2160 |
|---|
|
Полноэкранное сглаживание |
AMD Radeon RX 7900 XTX |
AMD Radeon RX 7900 XT |
AMD Radeon RX 6800 |
AMD Radeon RX 6800 XT |
AMD Radeon RX 6900 XT |
NVIDIA GeForce RTX 3080 Ti |
NVIDIA GeForce RTX 3090 |
NVIDIA GeForce RTX 4070 Ti |
NVIDIA GeForce RTX 4080 |
NVIDIA GeForce RTX 4090 |
| Cyberpunk 2077 |
TAA |
14 / 18 |
12 / 16 |
6 / 8 |
7 / 10 |
8 / 10 |
15 / 19 |
16 / 20 |
15 / 20 |
23 / 26 |
33 / 39 |
| DOOM Eternal |
TSSAA |
101 / 137 |
92 / 119 |
45 / 64 |
53 / 73 |
57 / 79 |
96 / 127 |
104 / 135 |
108 / 139 |
133 / 173 |
180 / 237 |
| Far Cry 6 |
TAA |
85 / 99 |
81 / 89 |
51 / 57 |
59 / 67 |
61 / 70 |
63 / 71 |
67 / 76 |
69 / 74 |
77 / 86 |
79 / 92 |
| Metro Exodus Enchanced Edition |
TAA |
34 / 44 |
30 / 38 |
16 / 22 |
20 / 25 |
21 / 27 |
27 / 37 |
29 / 40 |
32 / 41 |
40 / 52 |
54 / 75 |
| Minecraft with RTX Beta |
TAA |
24 / 29 |
22 / 26 |
11 / 14 |
13 / 15 |
14 / 18 |
36 / 39 |
38 / 42 |
37 / 42 |
49 / 53 |
73 / 78 |
| Quake II RTX |
TAA |
Н/Д / 36 |
Н/Д / 31 |
Н/Д / 17 |
Н/Д / 20 |
Н/Д / 21 |
Н/Д / 40 |
Н/Д / 42 |
Н/Д / 42 |
Н/Д / 54 |
Н/Д / 76 |
| Watch Dogs: Legion |
TAA |
28 / 39 |
23 / 33 |
14 / 19 |
17 / 22 |
18 / 24 |
28 / 33 |
29 / 35 |
29 / 34 |
37 / 44 |
51 / 61 |
| Макс. |
|
|
−10% |
−42% |
−32% |
−29% |
+34% |
+45% |
+45% |
+83% |
+169% |
| Средн. |
|
|
−13% |
−51% |
−43% |
−39% |
−2% |
+4% |
+4% |
+32% |
+84% |
| Мин. |
|
|
−15% |
−56% |
−48% |
−44% |
−28% |
−23% |
−25% |
−13% |
−7% |
⇡#Выводы
Графический процессор Navi 31 создан по революционной чиплетной технологии — одного этого достаточно, чтобы он занял почетное место в истории GPU. Однако и логика чипсета вобрала в себя такую массу изменений, которая тянет на крупнейшее обновление архитектуры со времен первой версии RDNA. В некоторых аспектах RDNA 3 производит впечатление компромиссного продукта, но, если взглянуть под другим углом, инженеры AMD приняли оптимальные технические решения, чтобы сэкономить компонентный бюджет GPU и одновременно достигнуть паритета функциональности с NVIDIA и Intel. Несмотря на слабость выделенных механизмов трассировки лучей, Navi 31 лучше справляется с рейтрейсингом, чем его предшественники, и наконец-то получил возможность быстрых матричных вычислений — пока, увы, совершенно бесполезную для геймеров.
Старшая модель новой серии, Radeon RX 7900 XTX, развивает производительность на 25–52 % выше, чем Radeon RX 6900 XT, в играх без трассировки лучей при разрешении от 1080p до 2160p, а конкретно в режиме 4К гарантирует частоту смены кадров не меньше 60 FPS. В гибридных и полностью трассированных проектах быстродействие Radeon RX 7900 XTX уже на 44–64 % выше, что, как правило, позволяет обойтись без масштабирования кадров при разрешении вплоть до 1440p.
Энергоэффективность тоже возросла по сравнению с Radeon RX 6900 XT, пусть и не настолько, как запланировали, — лишь 28 % вместо теоретически возможных 54. Однако по неким причинам AMD остановилась на довольно консервативном рубеже мощности в 335 Вт, а тактовые частоты выше 3 ГГц остались на бумаге. В результате разрыв между топовыми решениями NVIDIA и AMD не только не стал меньше, но даже увеличился. Если GeForce RTX 3090 превосходит Radeon RX 6900 XT на 16 % FPS в стандартных 4К-тестах и на 72 % с трассировкой лучей, то GeForce RTX 4090 ушел вперед от Radeon RX 7900 XTX на 23 и 84 % соответственно.
Впрочем, пусть новинка и не претендует на почетный статус самого мощного игрового ускорителя, она в любом случае располагает большей производительностью, чем любое устройство прошлого поколения и при этом не стала ни на цент дороже Radeon RX 6900 XT: оба поступили в продажу по рекомендованной цене $999, в то время как GeForce RTX 4090 официально стоит не меньше $1 599.
Более подходящим конкурентом для RX 7900 XTX является GeForce RTX 4080. Несмотря на то, что продукт NVIDIA опять-таки дороже ($1 199), в 4К без рейтрейсинга AMD уверенно побеждает с преимуществом в 8 %. На стороне RTX 4080 лучшие результаты трассированных бенчмарков (18 % при гибридном рендеринге и 32 % в целом), тут RX 7900 XTX может поспорить разве что с GeForce RTX 4070 Ti. Кроме того, покупателям «зеленых» видеокарт уже сейчас доступна зрелая технология интеллектуального апскейлинга DLSS, в то время как AMD даже не обещает официально, что грядущая версия FSR опирается на матричные вычисления (хотя мы будем удивлены, если это не так).
Из Radeon RX 7900 XTX получился отличный ускоритель рабочих приложений, особенно если требуется больше 20 Гбайт VRAM. Новинке даже удалось потеснить старшие модели NVIDIA в определенных задачах, хотя главной проблемой для AMD в сфере рабочих станций остается не производительность, а многолетняя оптимизация программ под другую архитектуру и задержки с внедрением нужных функций. Наконец, аппаратный видеокодек Navi 31 подтянули к уровню конкурентов, и, в отличие от 40-й серии GeForce, новые «Радеоны» имеют выход DisplayPort 2.1, который позволяет комбинировать высокое разрешение и частоту обновления с HDR без компрессии сигнала.
В целом же Radeon RX 7900 XTX кажется более выгодной покупкой, чем GeForce RTX 4080 (или по меньшей мере привлекательной альтернативой ему) с поправкой на относительно низкую (но уже очень даже приличную) скорость рейтрейсинга и временное отсутствие полноценного аналога DLSS в арсенале AMD. Но лишь при условии, что розничные цены опустятся до рекомендованных значений. Пока ускоритель в дефиците, его продают даже за бóльшие суммы, чем GeForce RTX 4080. С приобретением новейшего железа, как обычно, лучше не спешить.
Что касается младшей модели, Radeon RX 7900 XT, то смысл существования этой видеокарты при действующей ценовой политике AMD нам не до конца ясен. Она тоже тянет большинство игр при разрешении 4К, опережая GeForce RTX 4070 Ti на 18 % FPS, и даже в тайтлах с гибридным рендерингом ее производительность в среднем на 7 % выше. Беда в том, что Radeon RX 7900 XT уступает флагману 13% игрового быстродействия в 4К, несет 20 вместо 24 Гбайт VRAM, а стоит всего на 10 % меньше ($899), хотя предтоповые позиции традиционно предлагают больше FPS на единицу MSRP. Такое впечатление, что и сам Radeon RX 7900 XT делали по шаблону GeForce RTX 4070 Ti, а его основная функция — подтолкнуть покупателей в сторону XTX. Россиянам точно надо забыть о версии XT, пока рынок еще не насыщен, а GeForce RTX 4070 Ti позволяет сэкономить добрых 20 тыс. рублей.
Напоследок скажем пару слов об ускорителях SAPPHIRE NITRO+, которые представляют дебютантов 7000-й линейки в нашем обзоре. Обе модели укомплектованы мощным и качественным VRM, причем у XT и XTX он одинаковый, а главное, одной из самых тихих систем охлаждения в новом и прошлом поколении видеокарт. По разгону NITRO+ хорошо видно, насколько AMD перестраховалась с тактовыми частотами. Если отталкиваться от референсных спецификаций, из Navi 31 нетрудно выжать еще 380–450 МГц, которые могли бы внести крупные поправки в исход сравнительных тестов.
Если Вы заметили ошибку — выделите ее мышью и нажмите CTRL+ENTER.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex

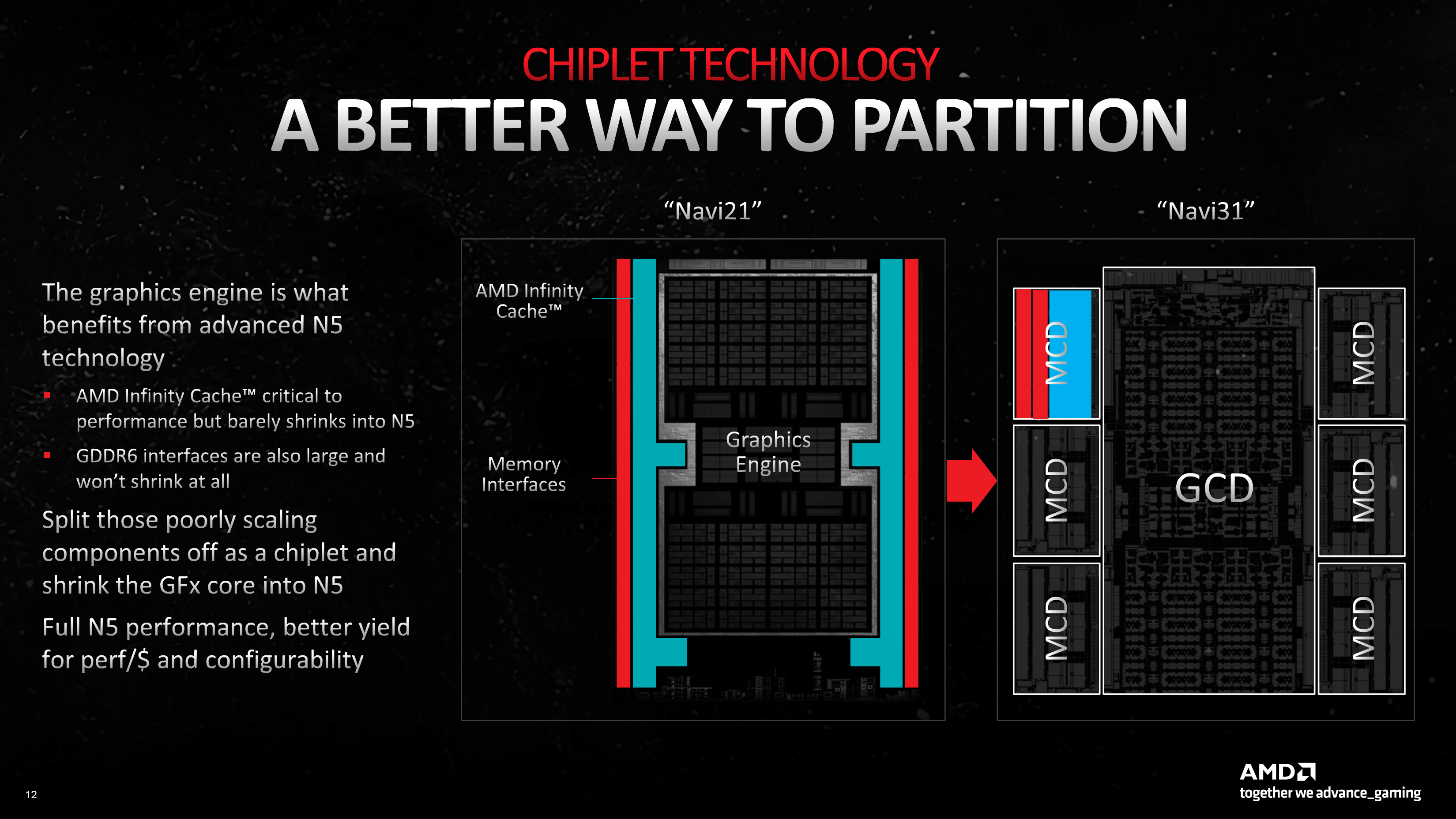


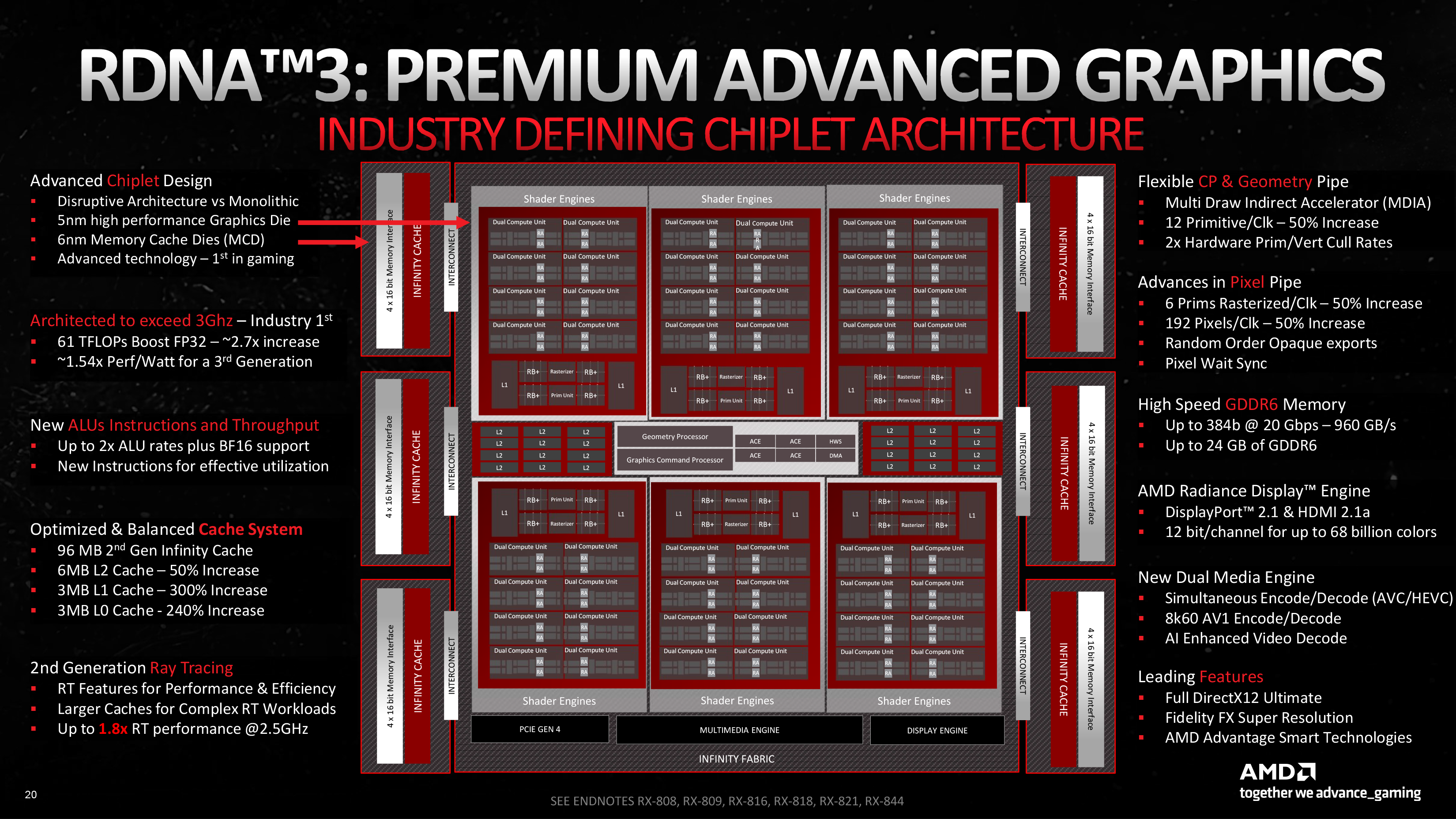

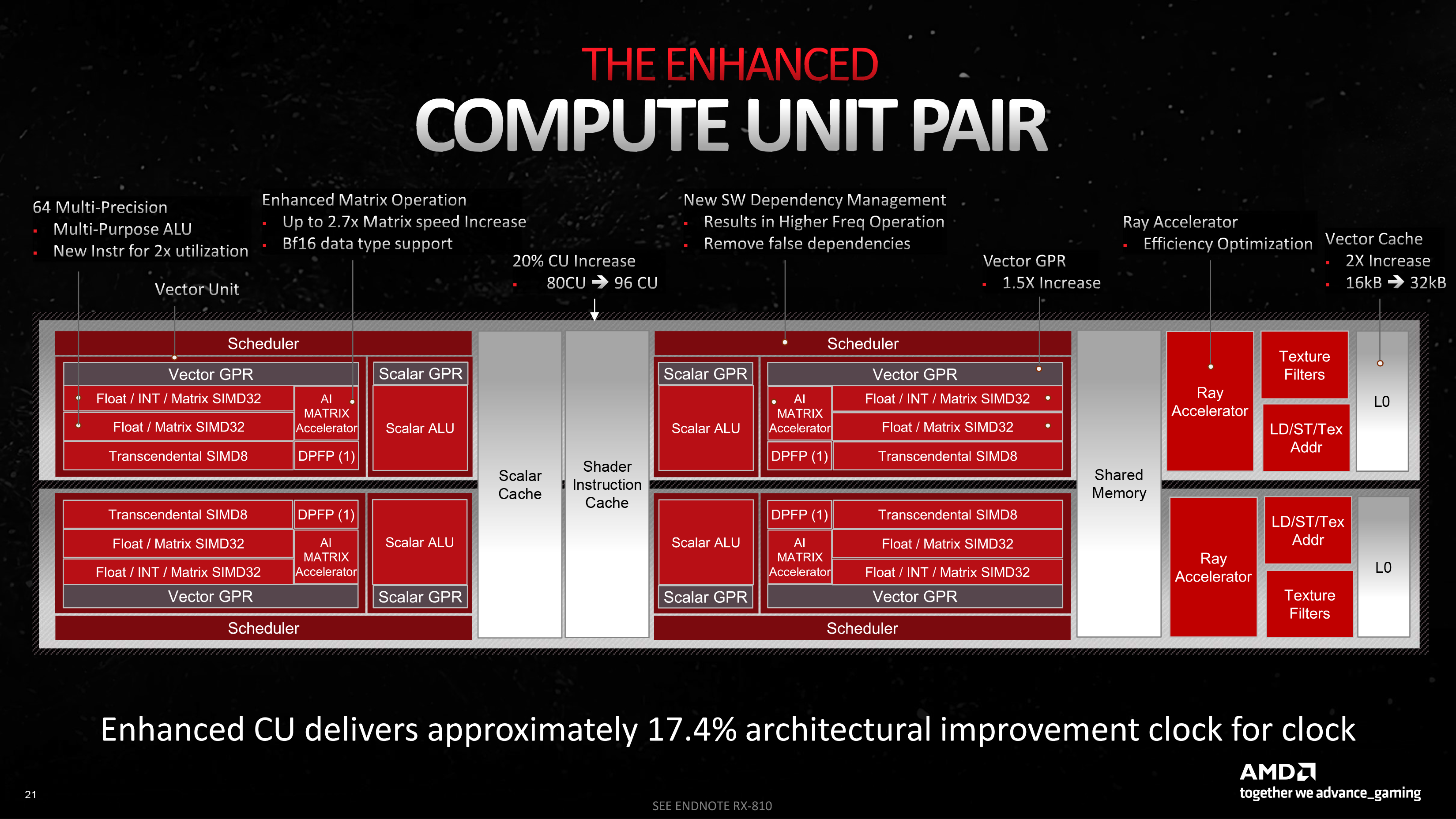




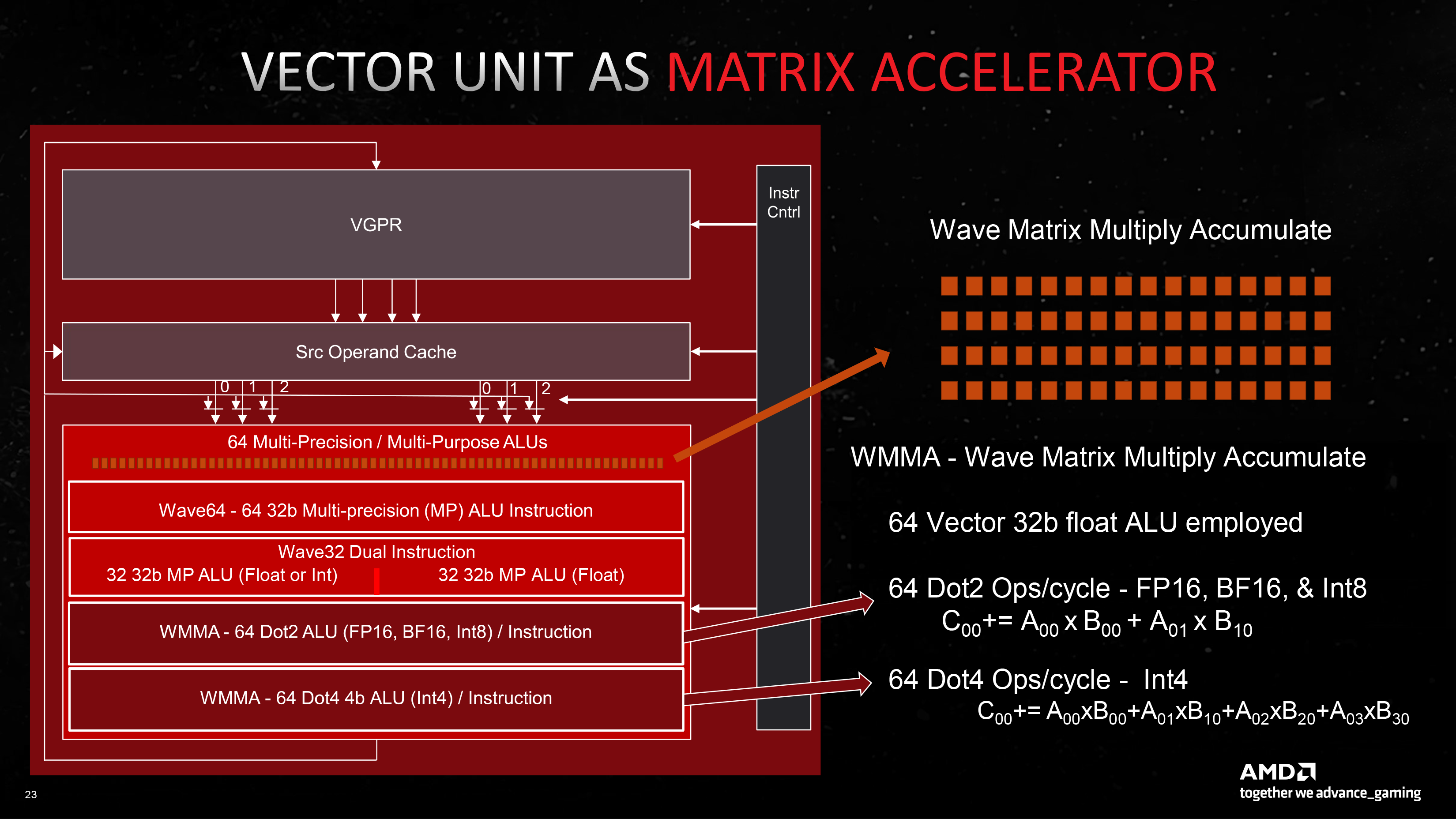
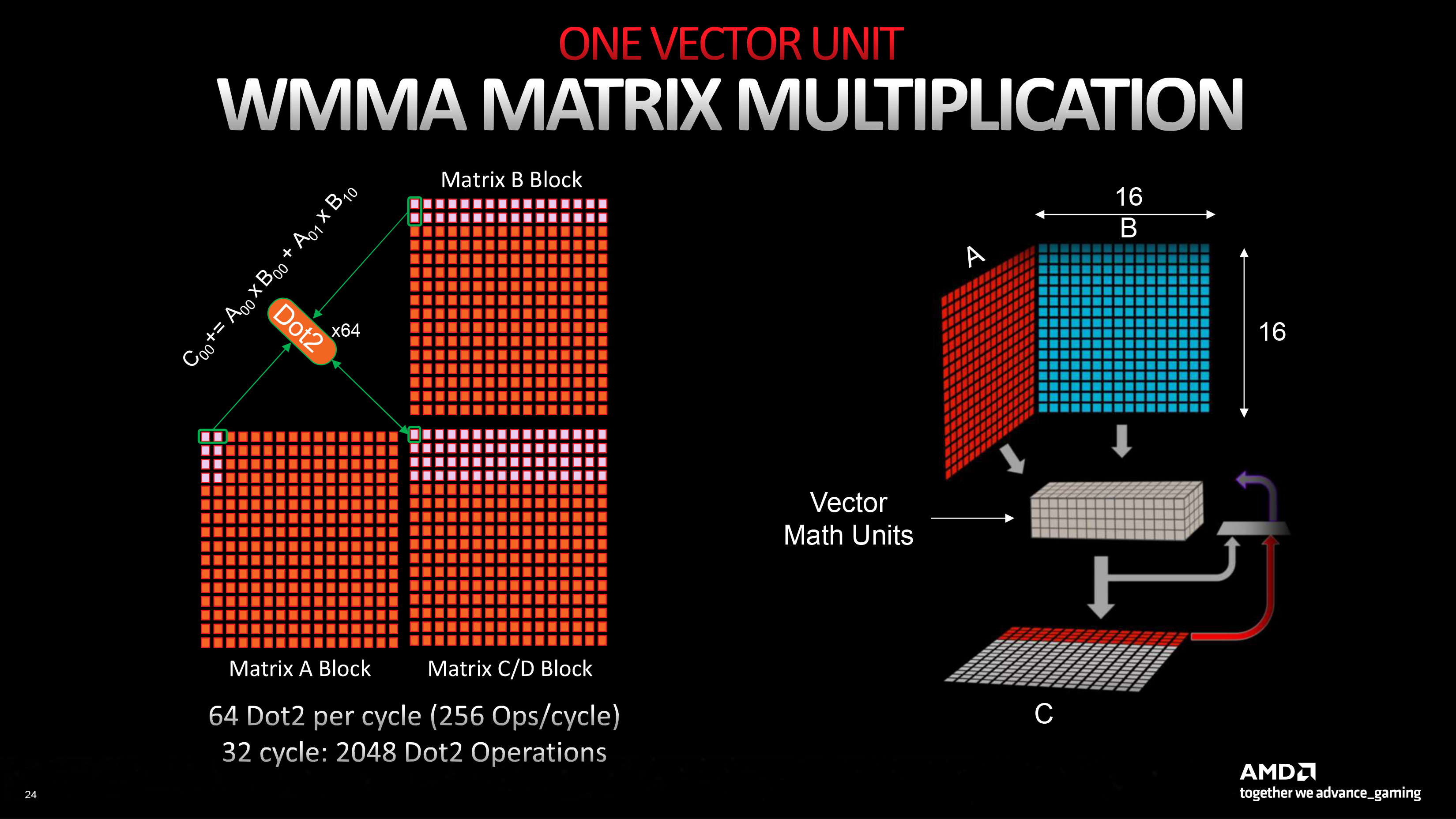


















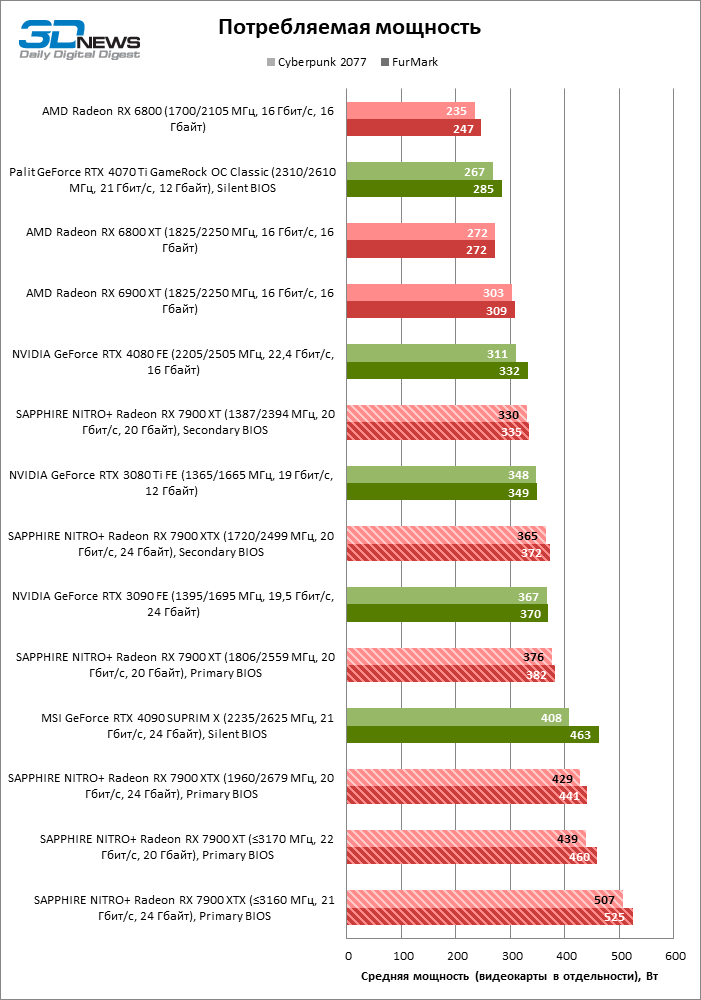
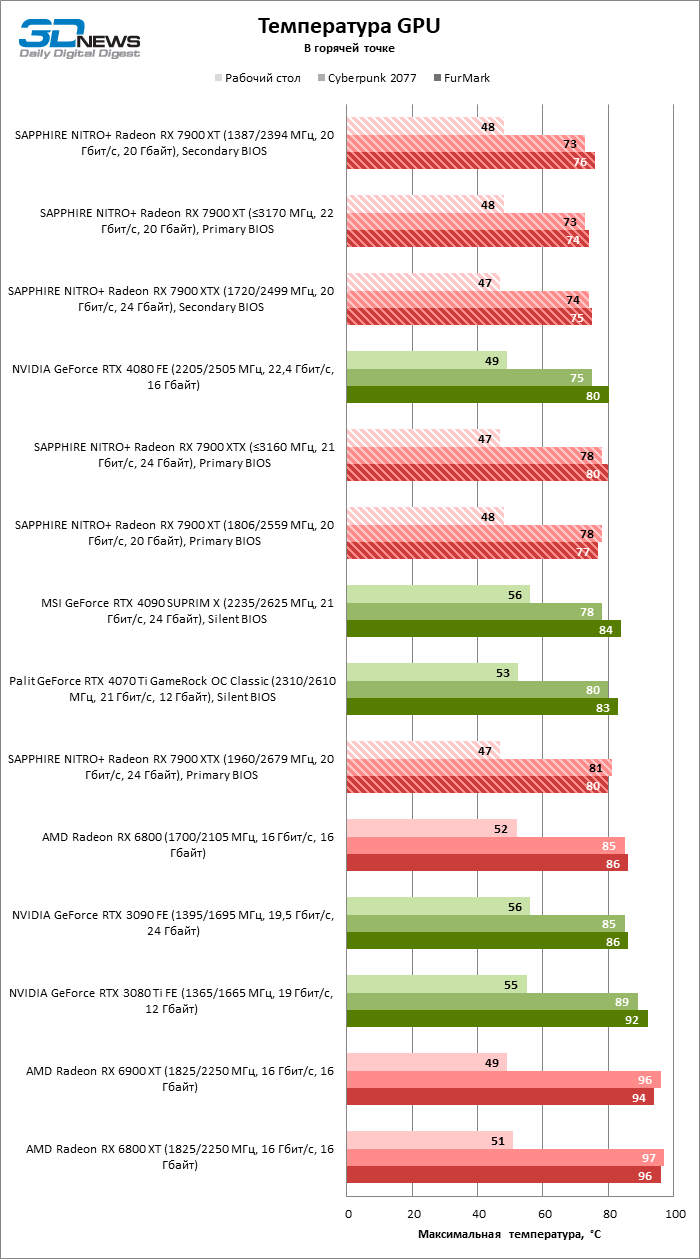
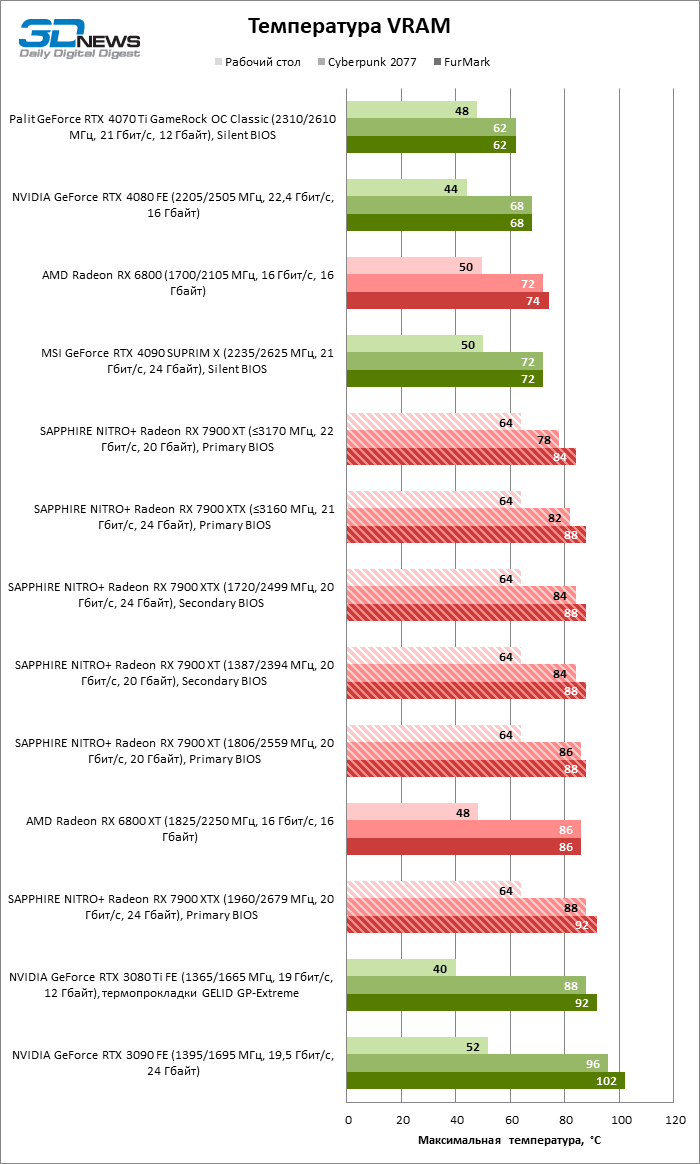
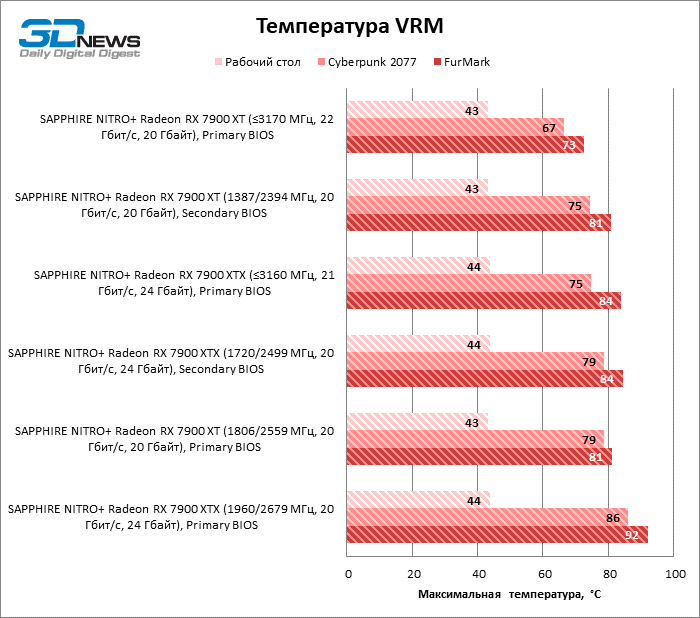
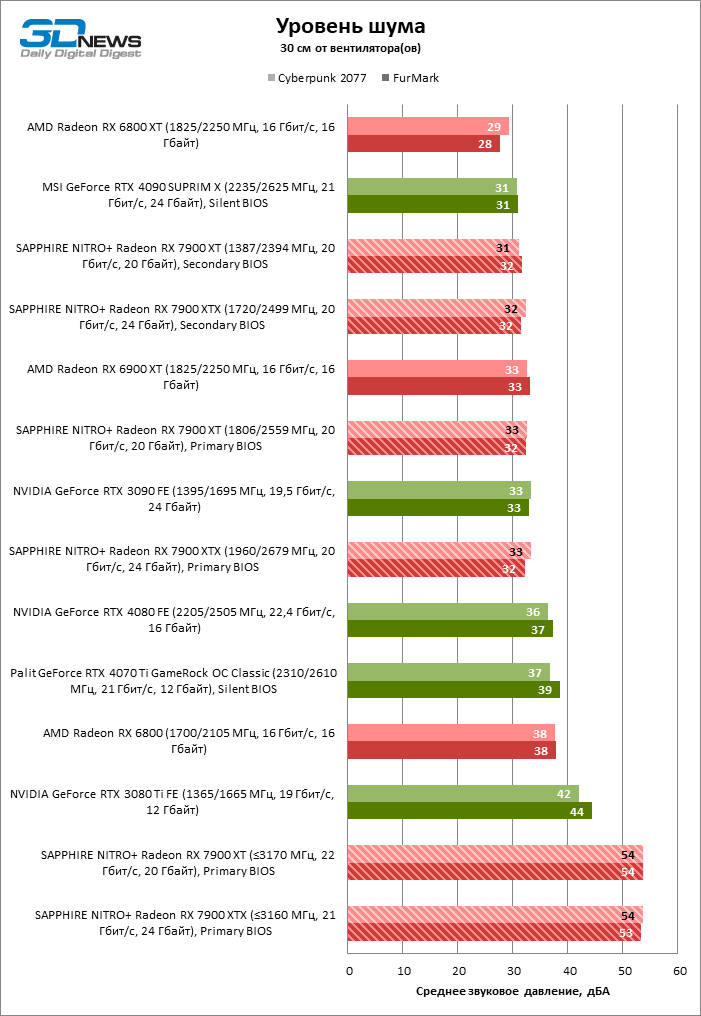
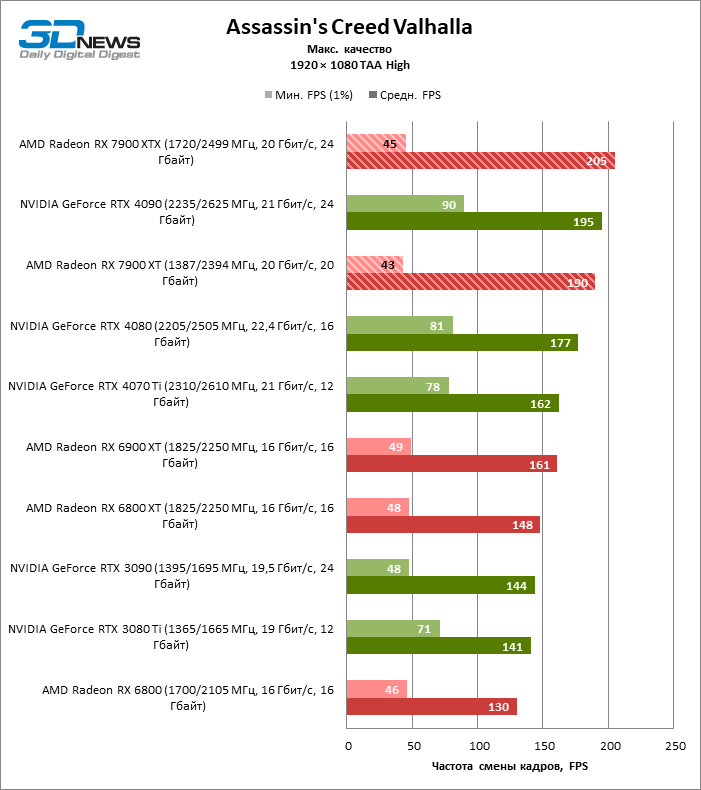
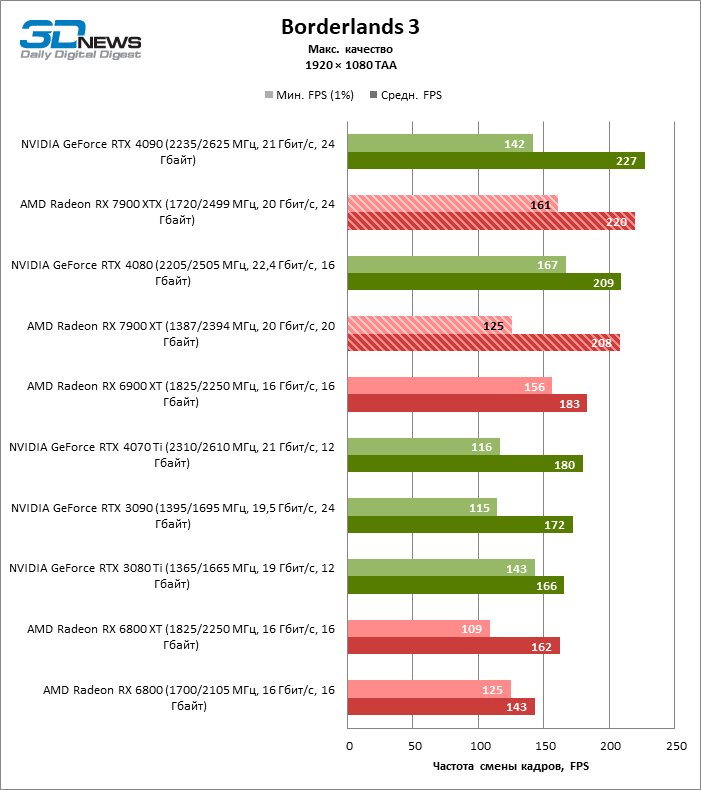
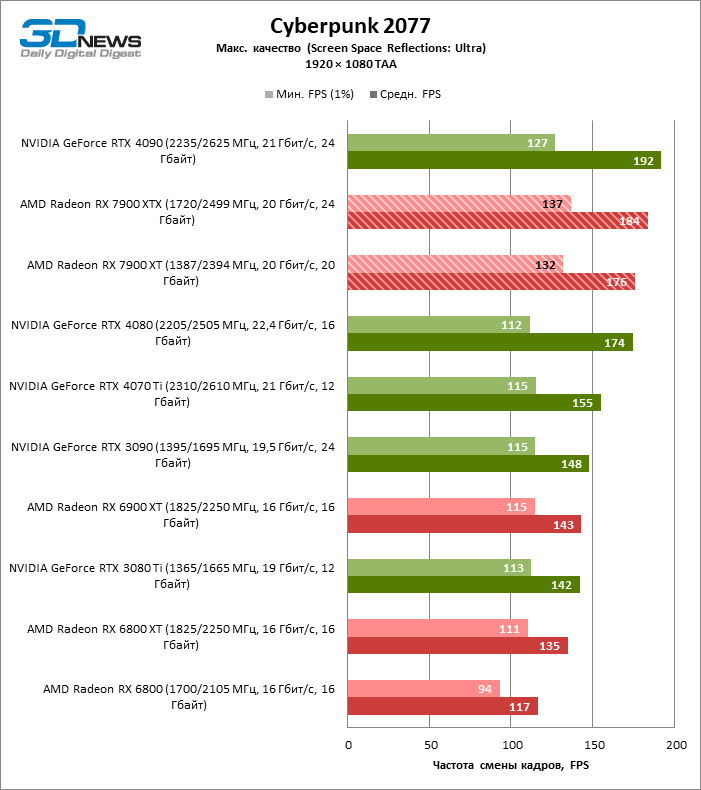
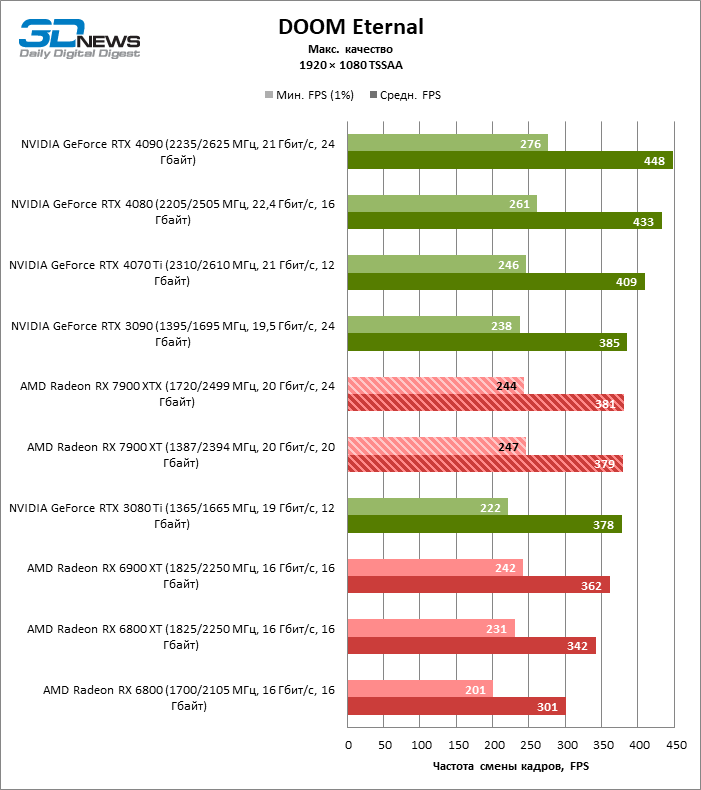
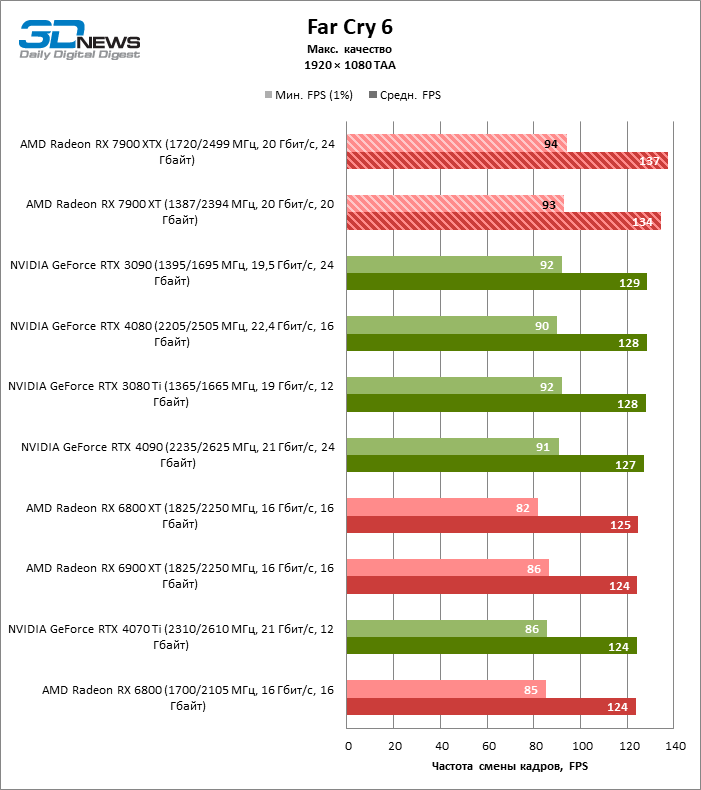
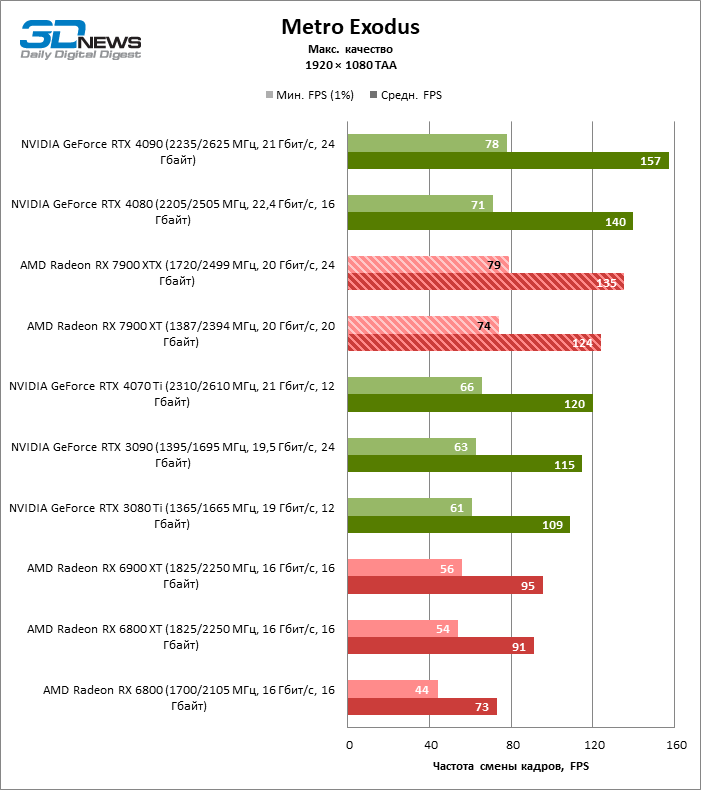
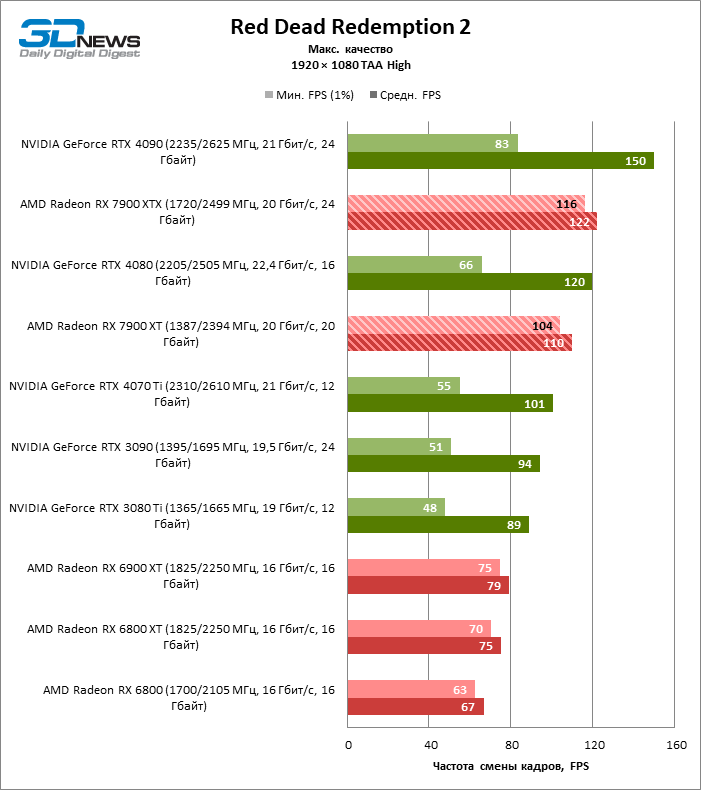
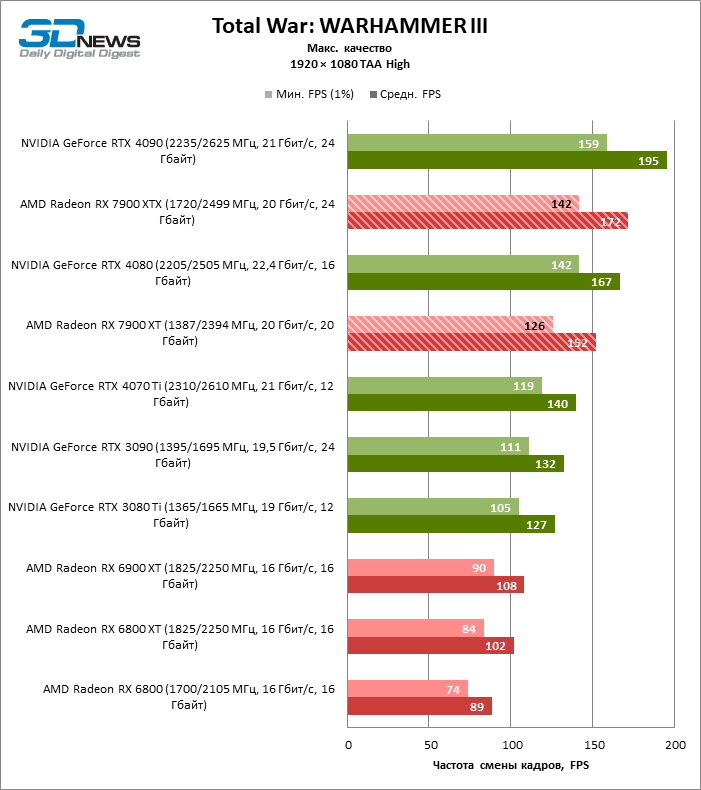
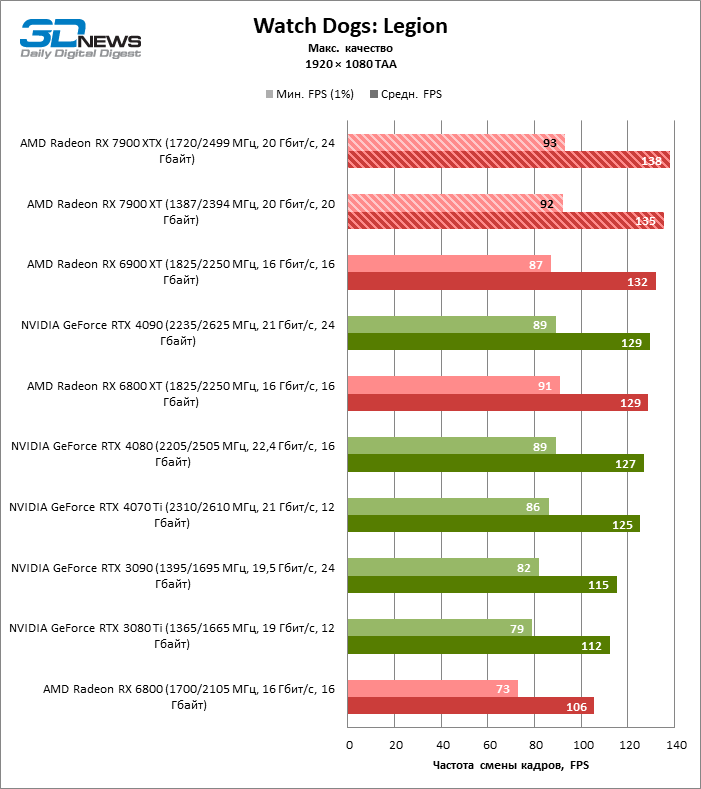
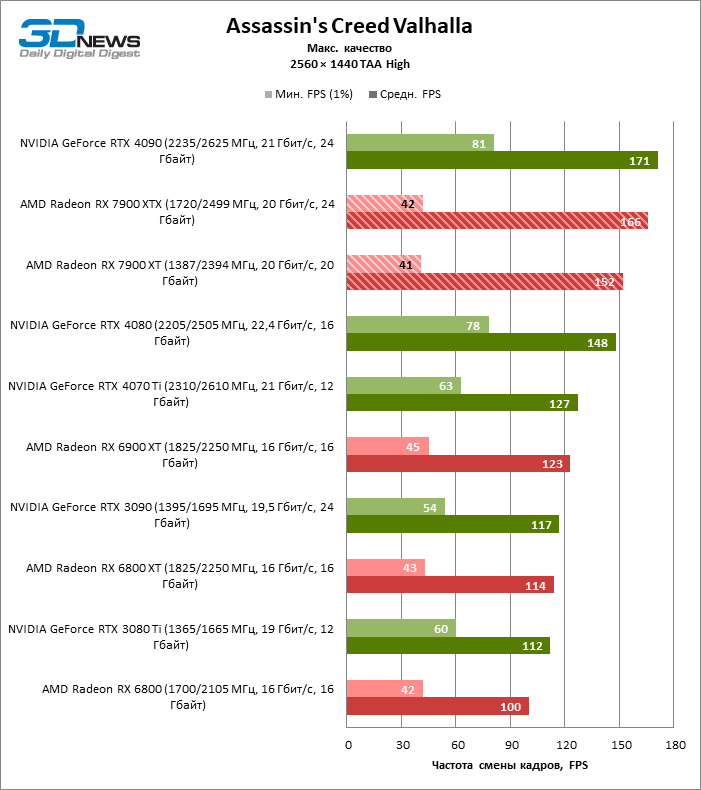
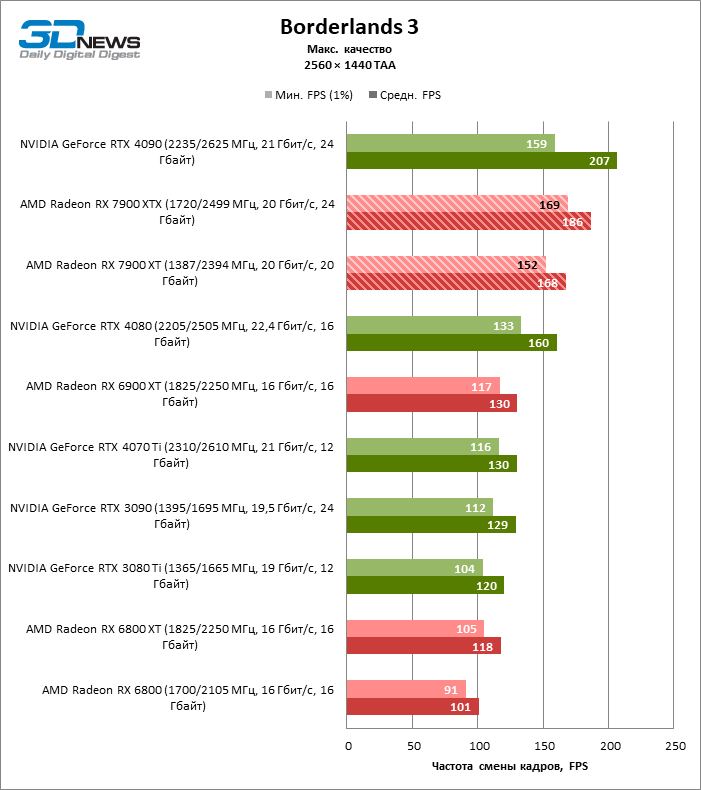
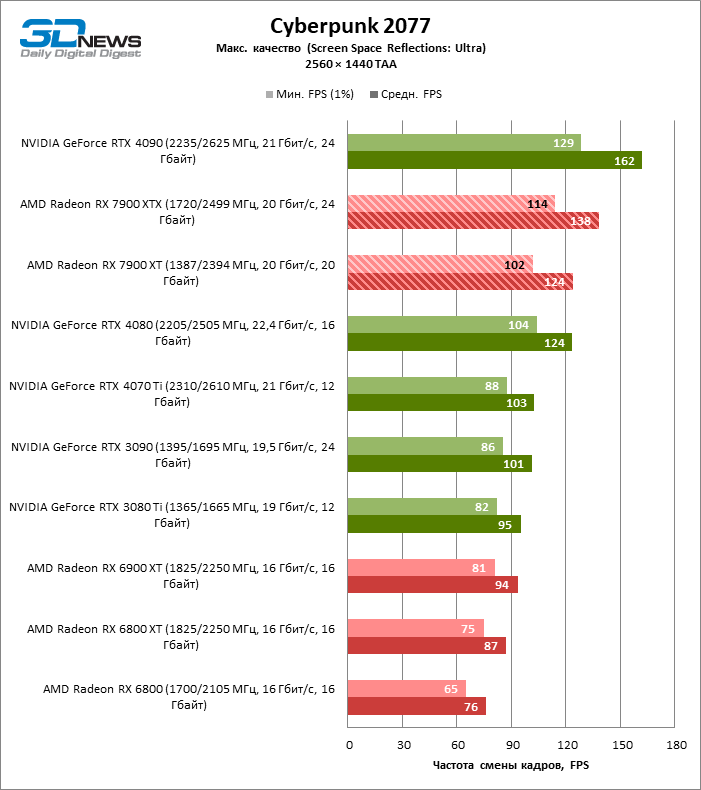
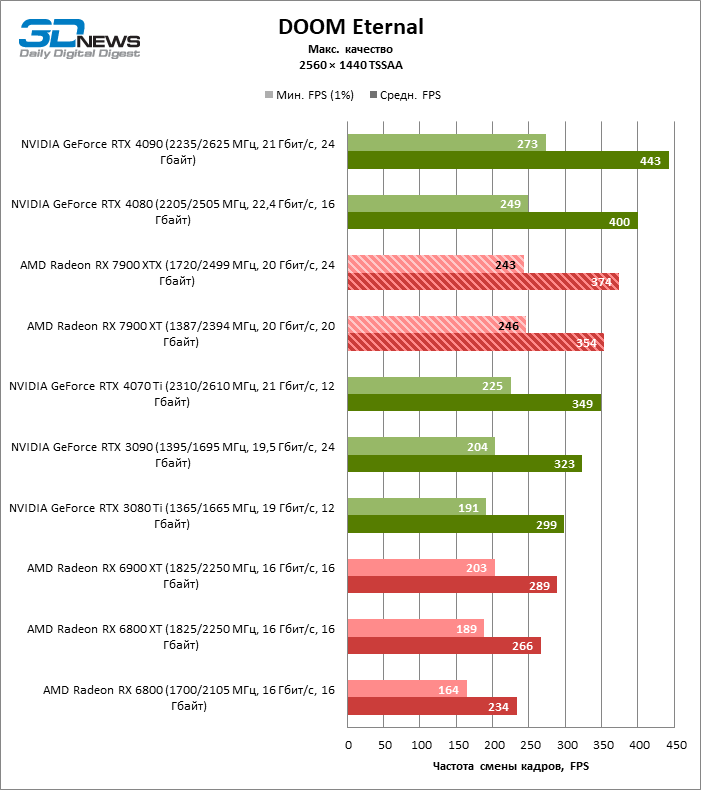
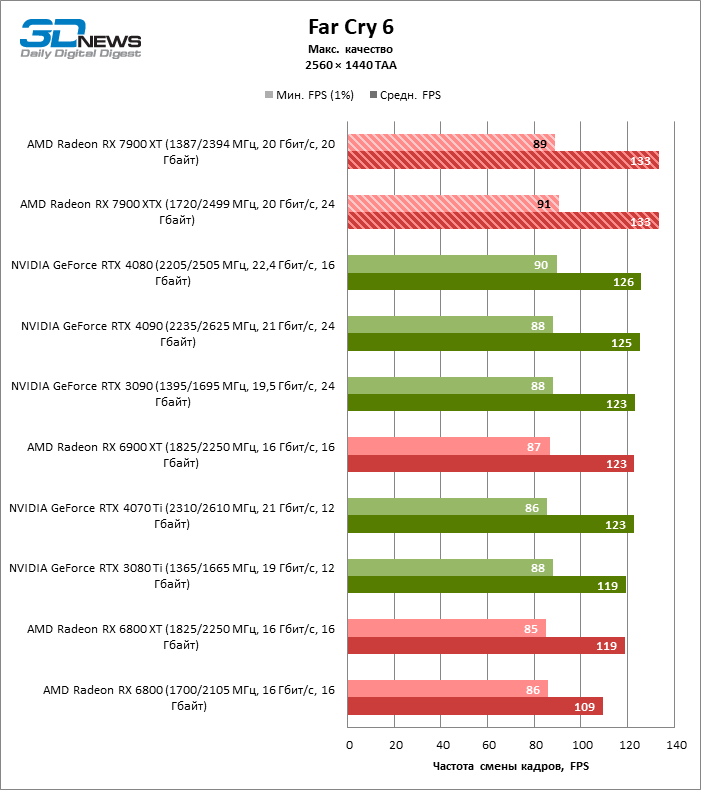
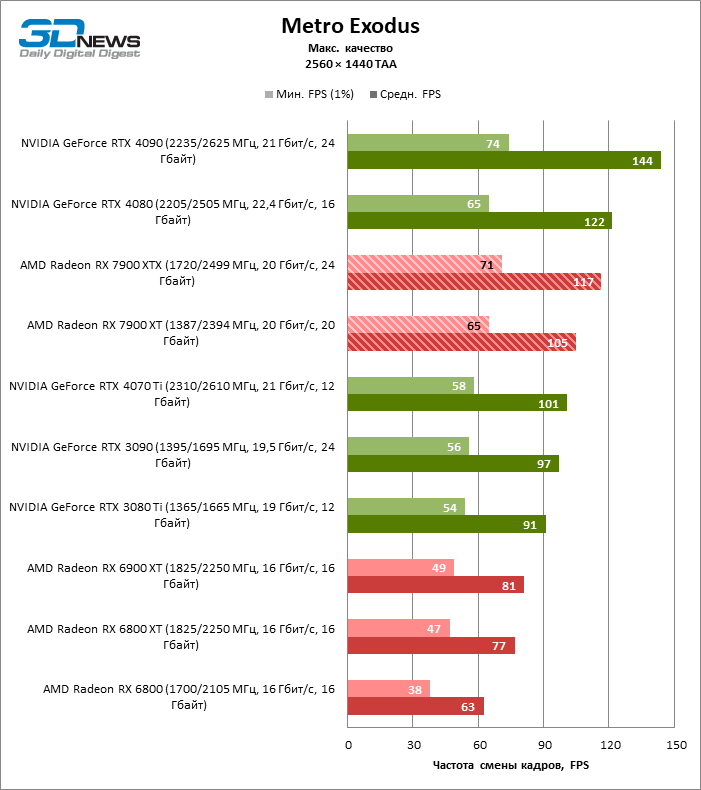
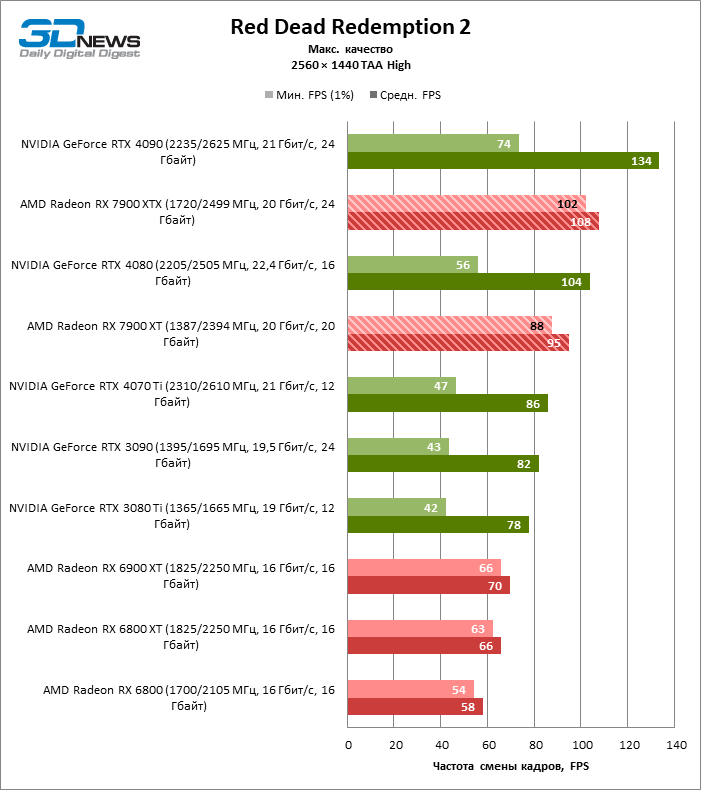
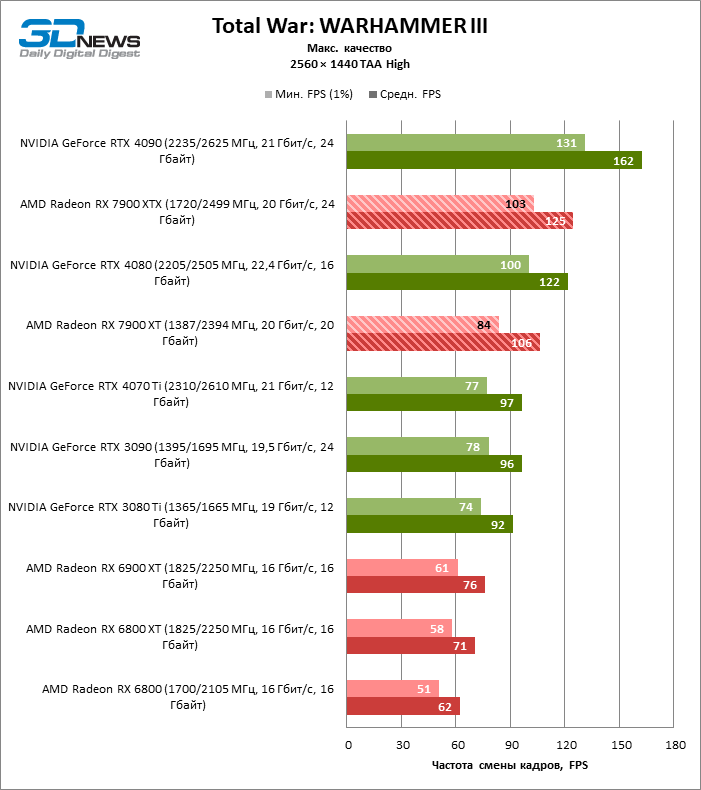
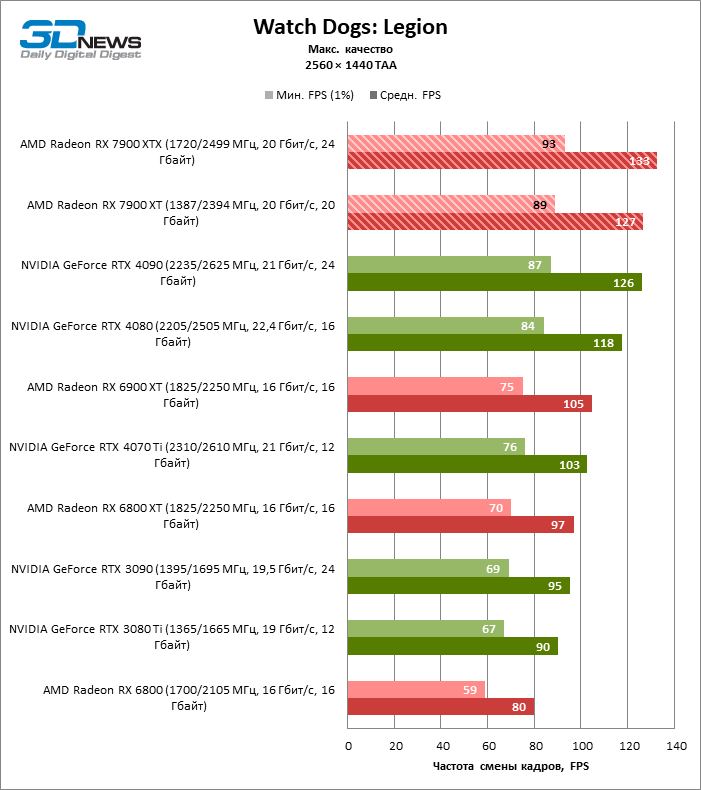
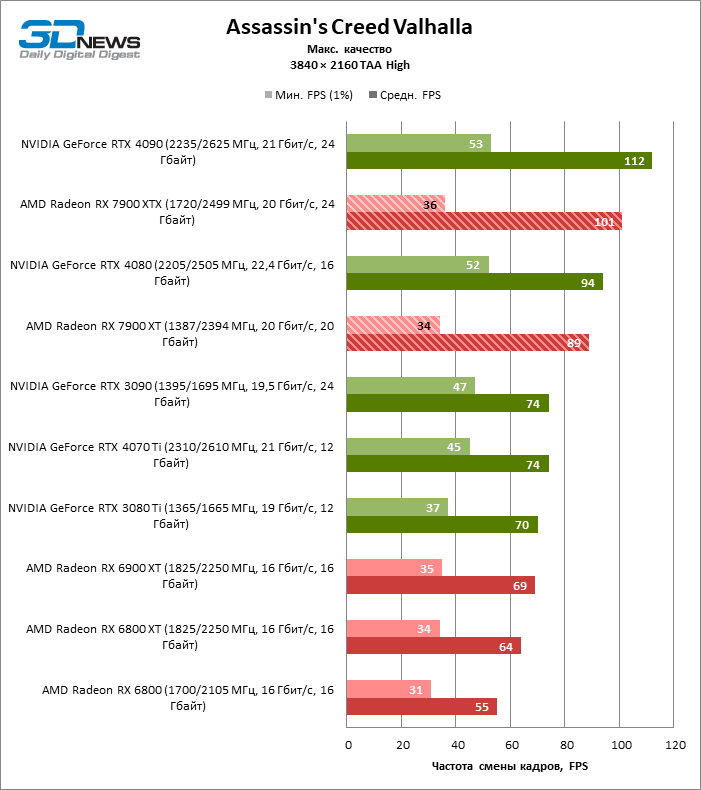
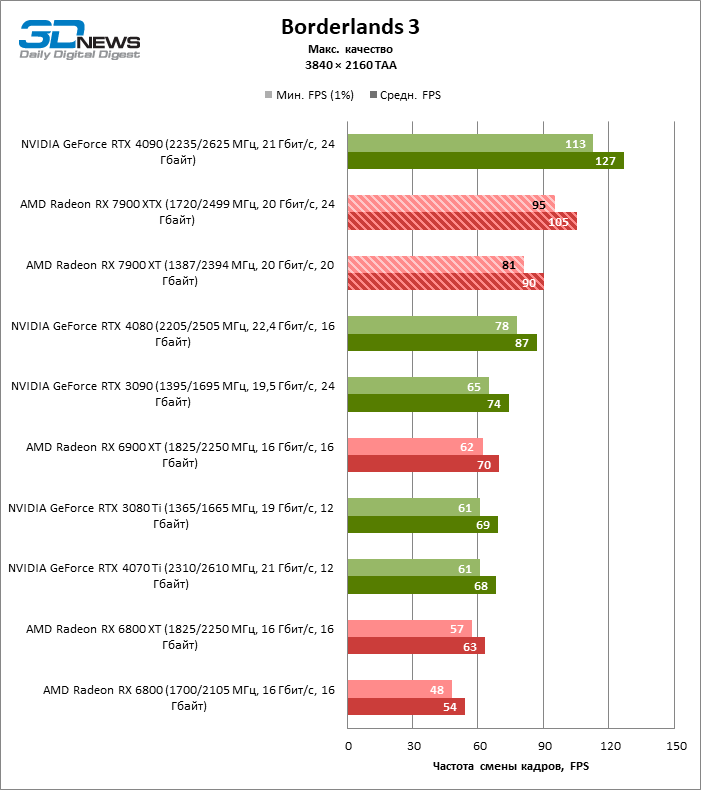
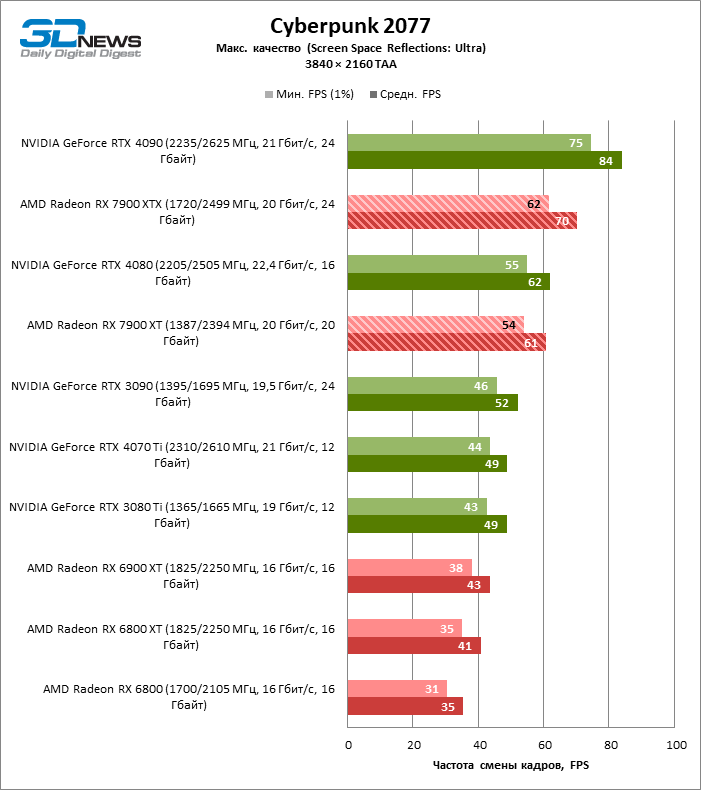
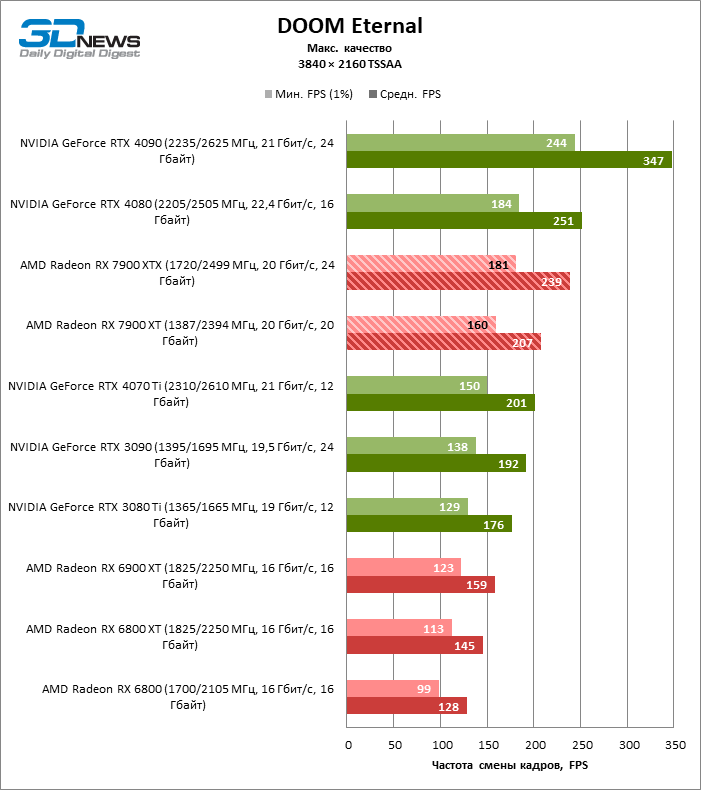
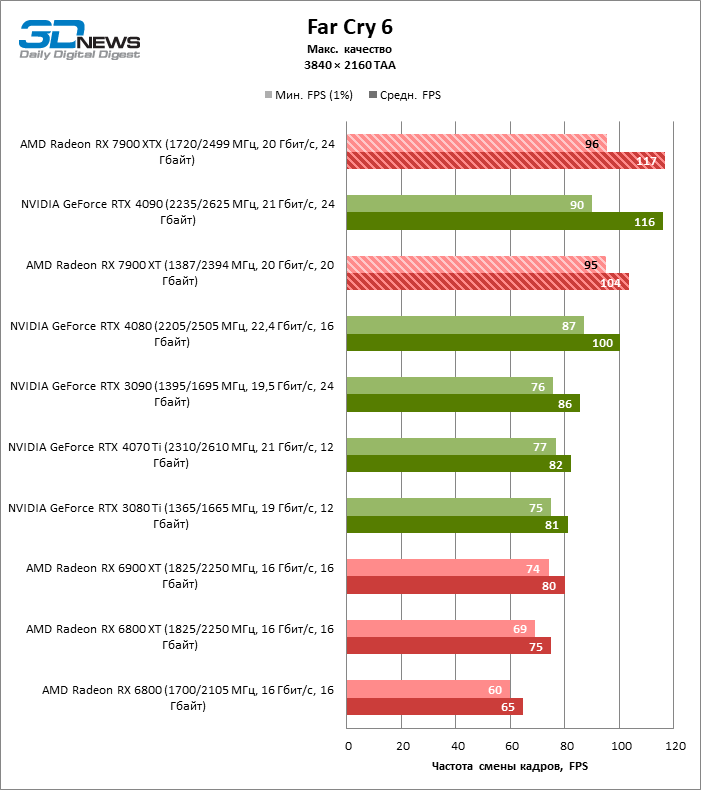
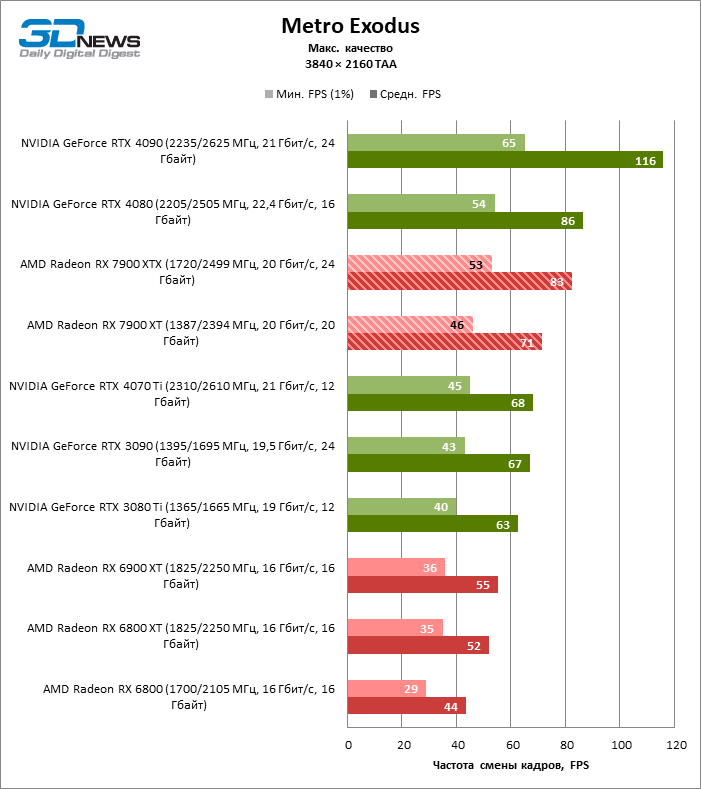
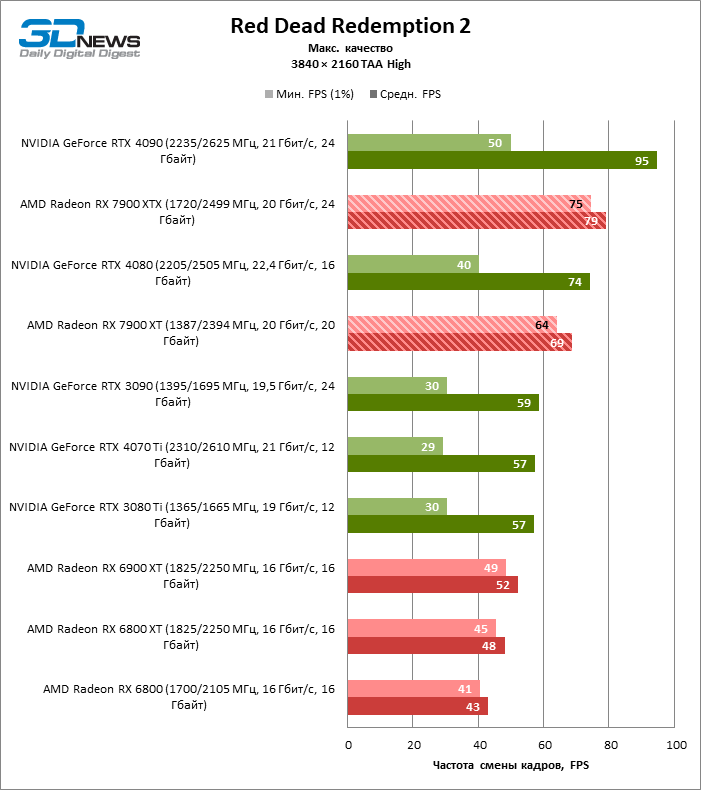
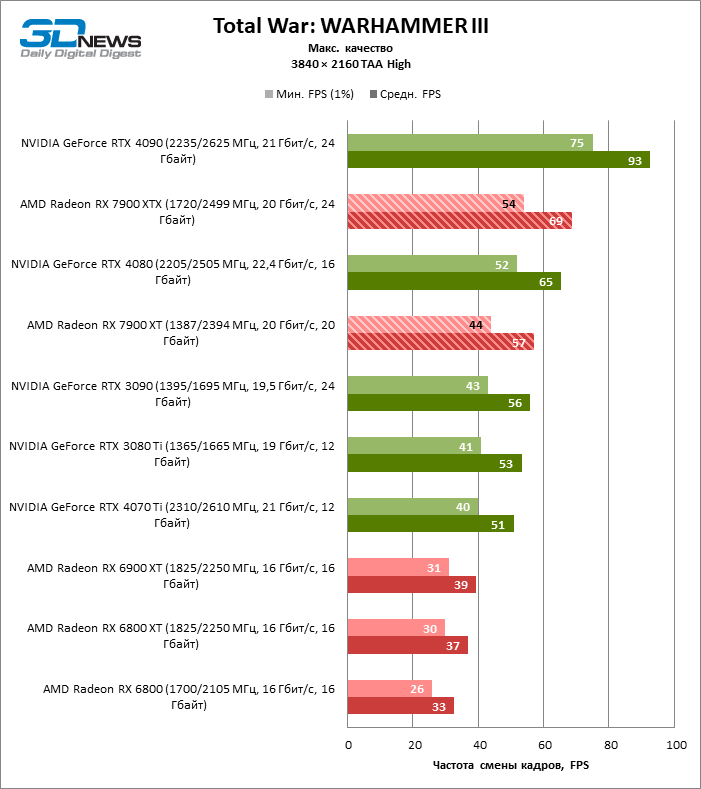
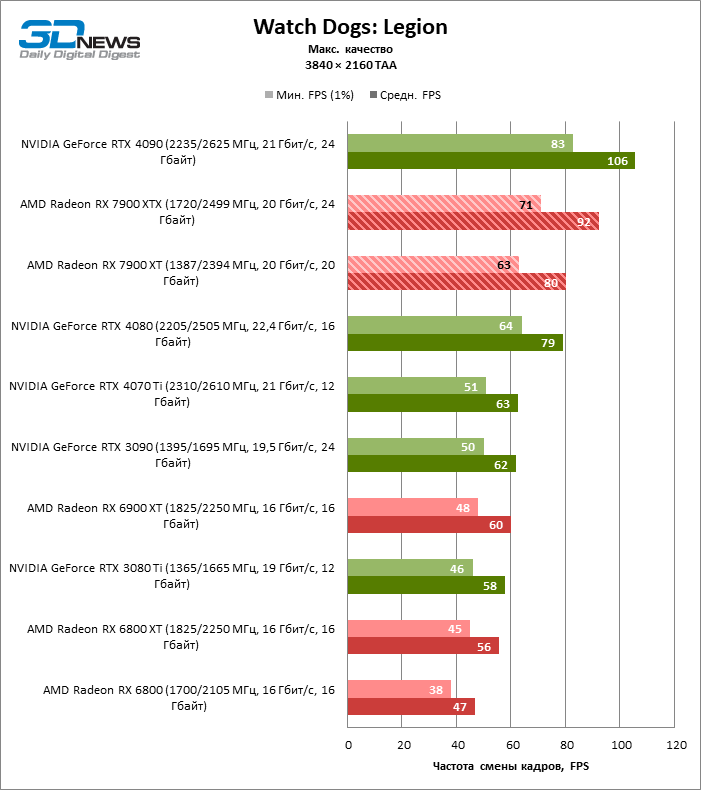
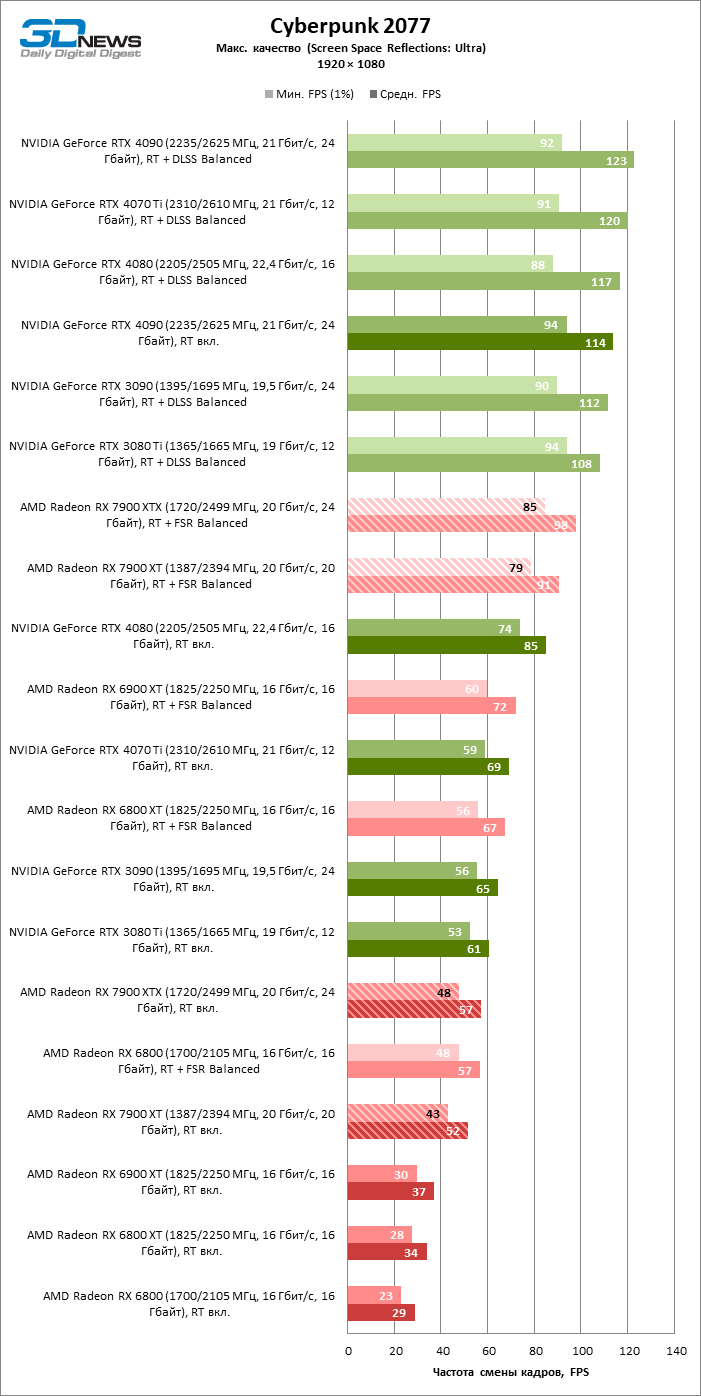
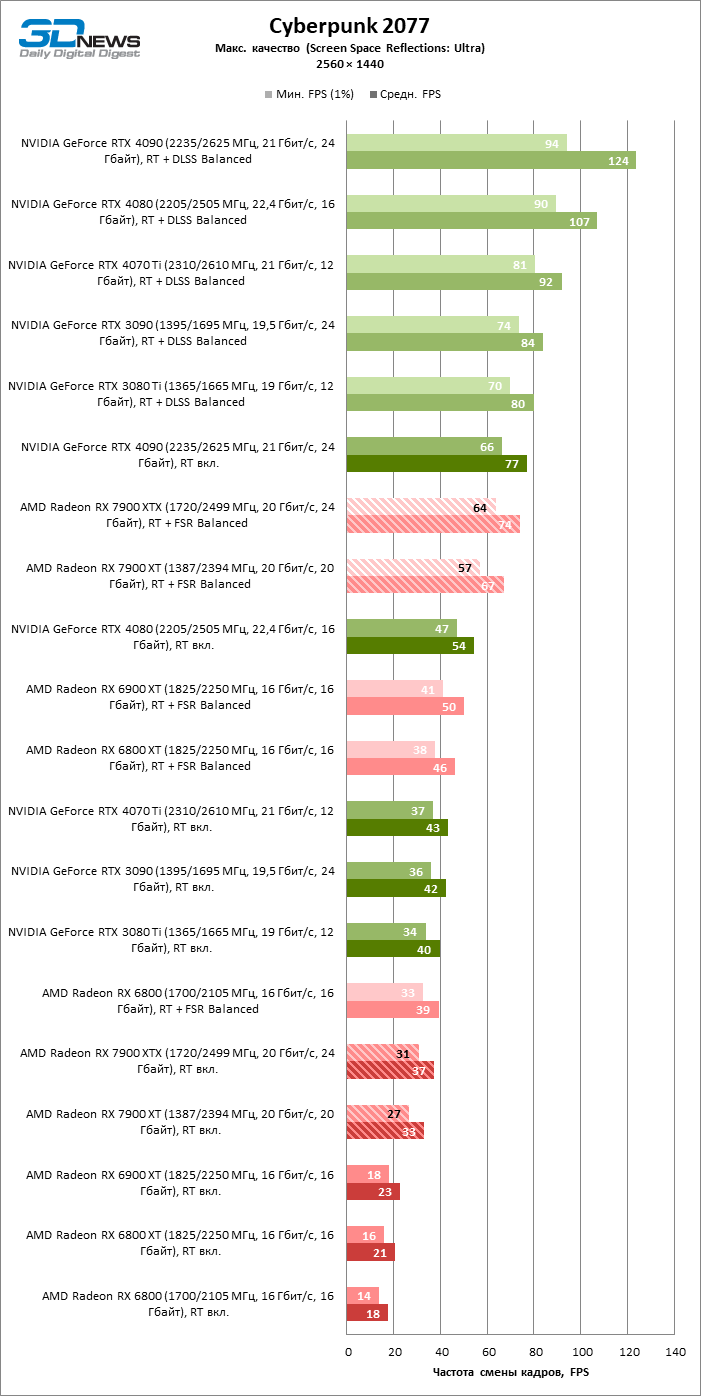
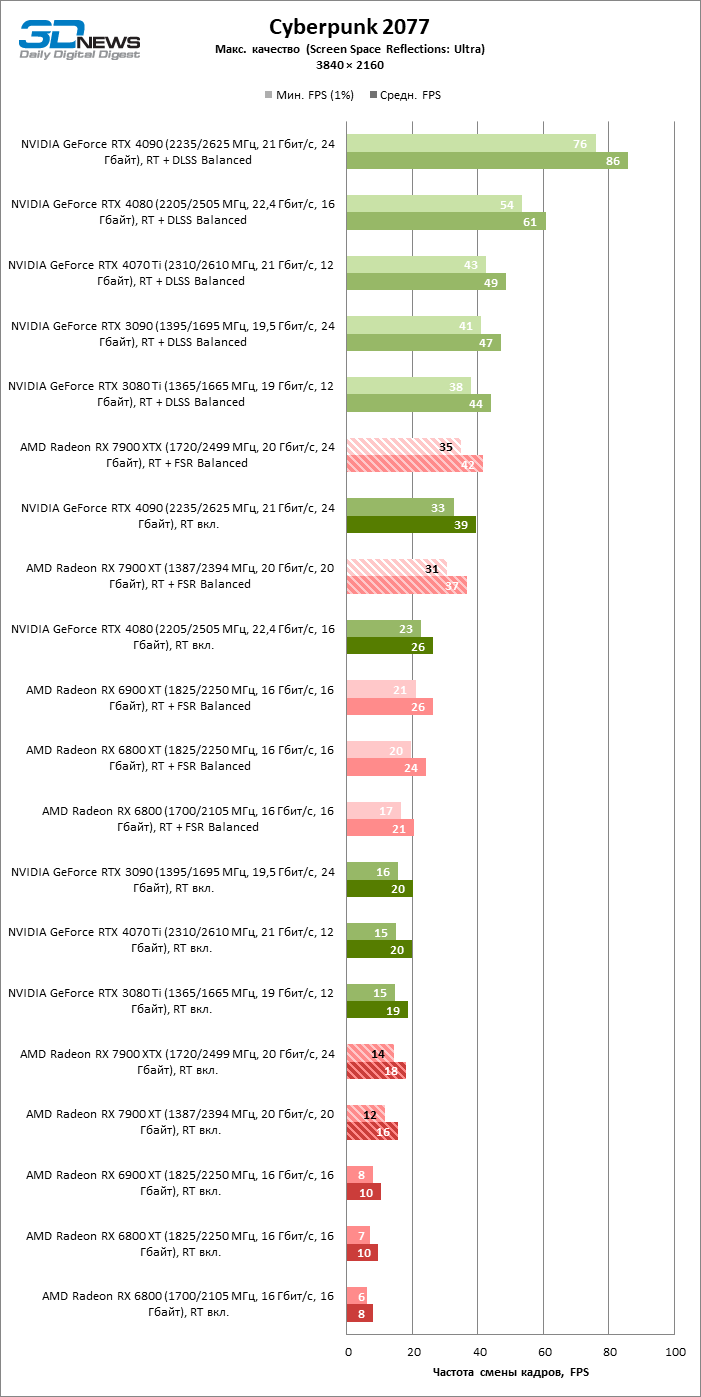
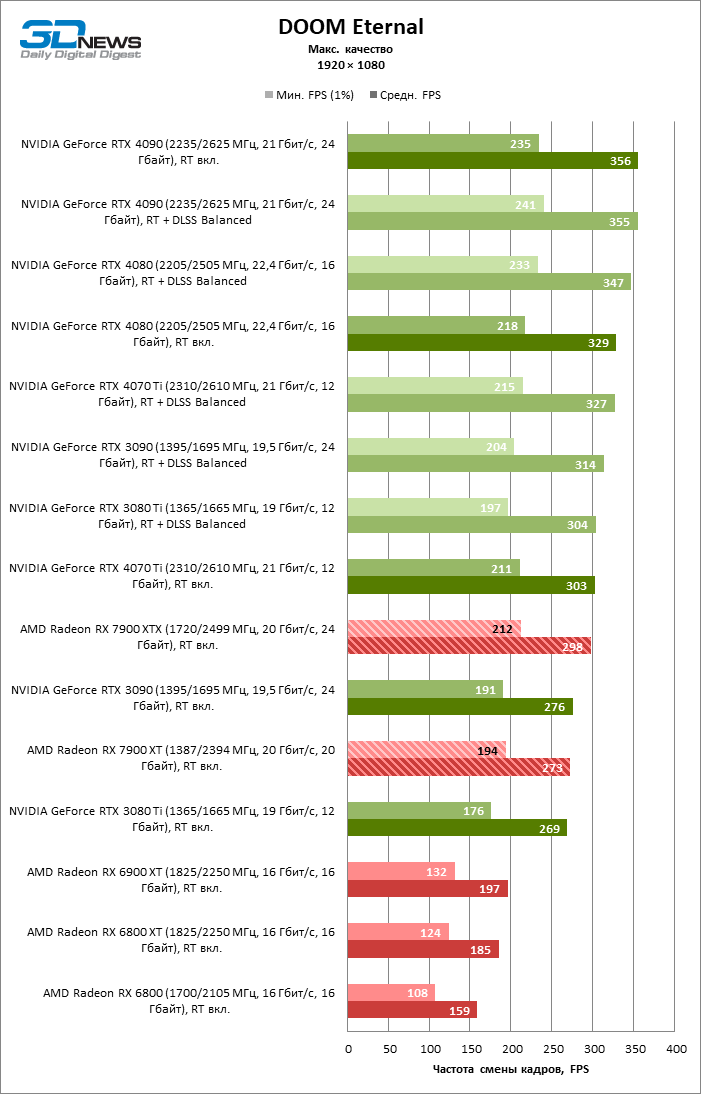
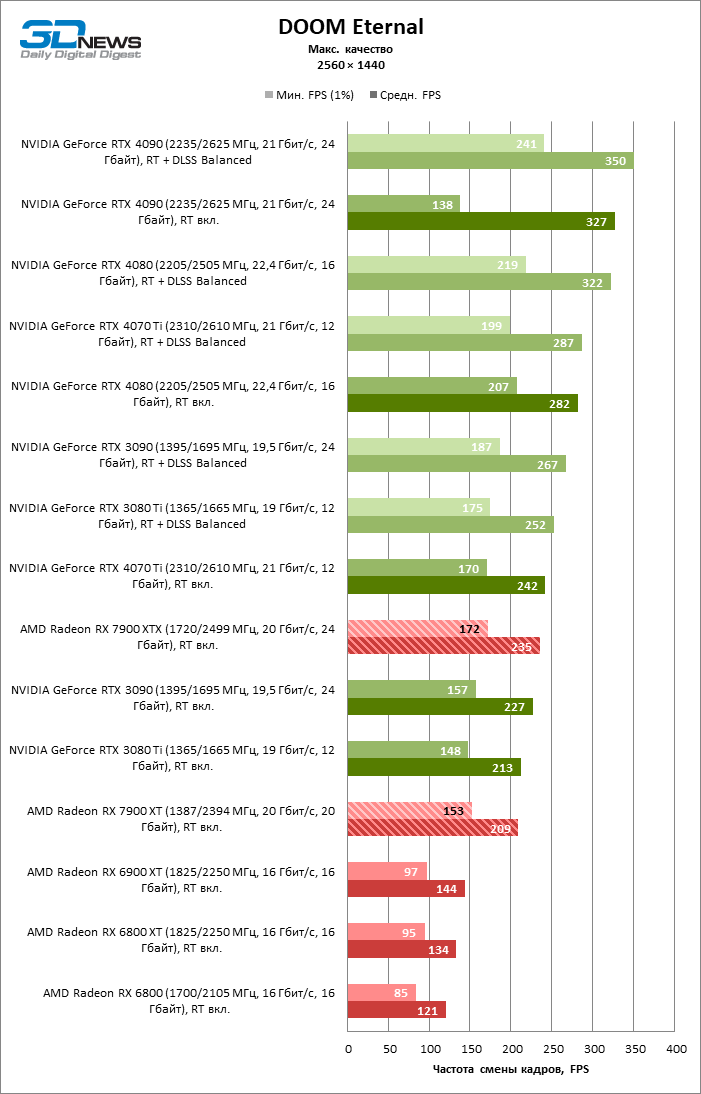
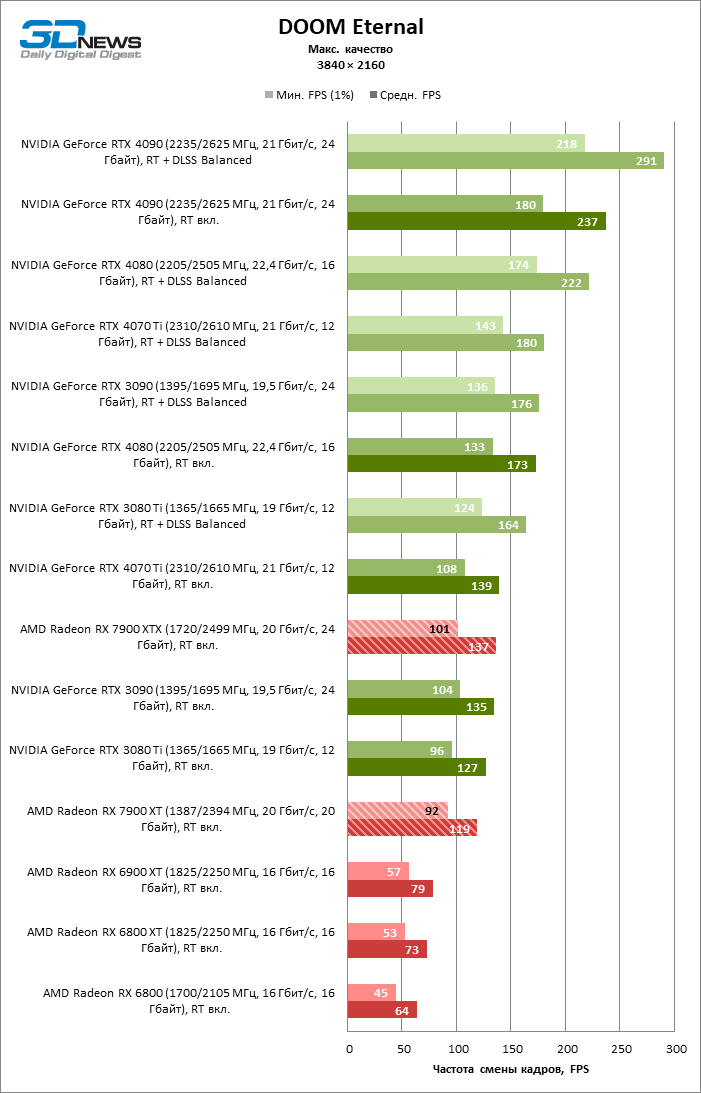
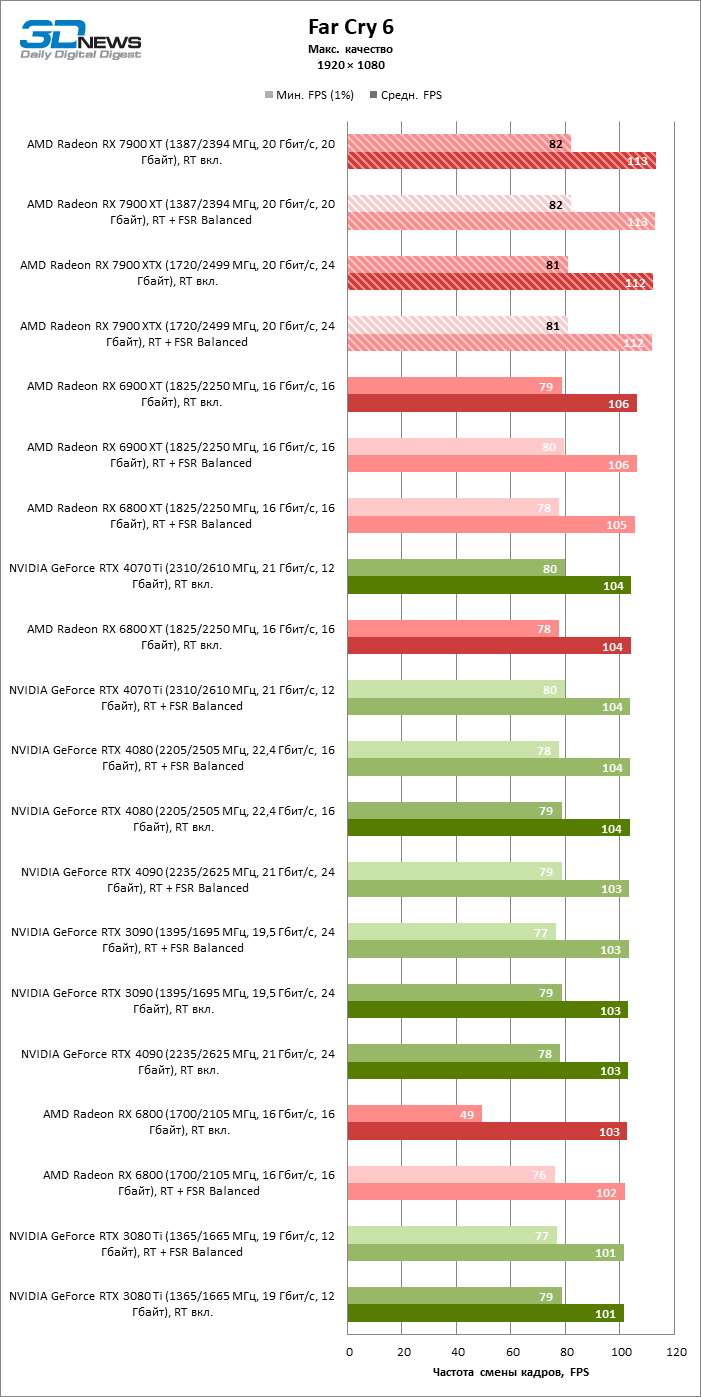
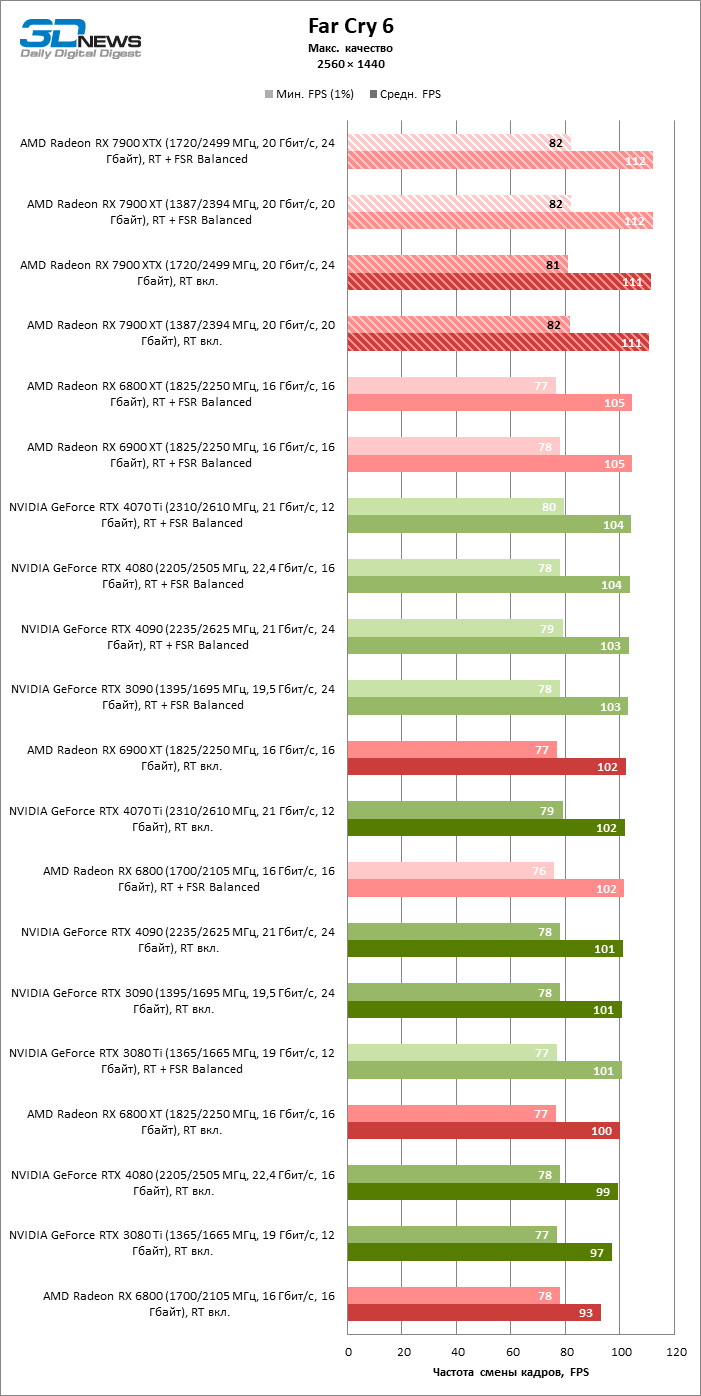
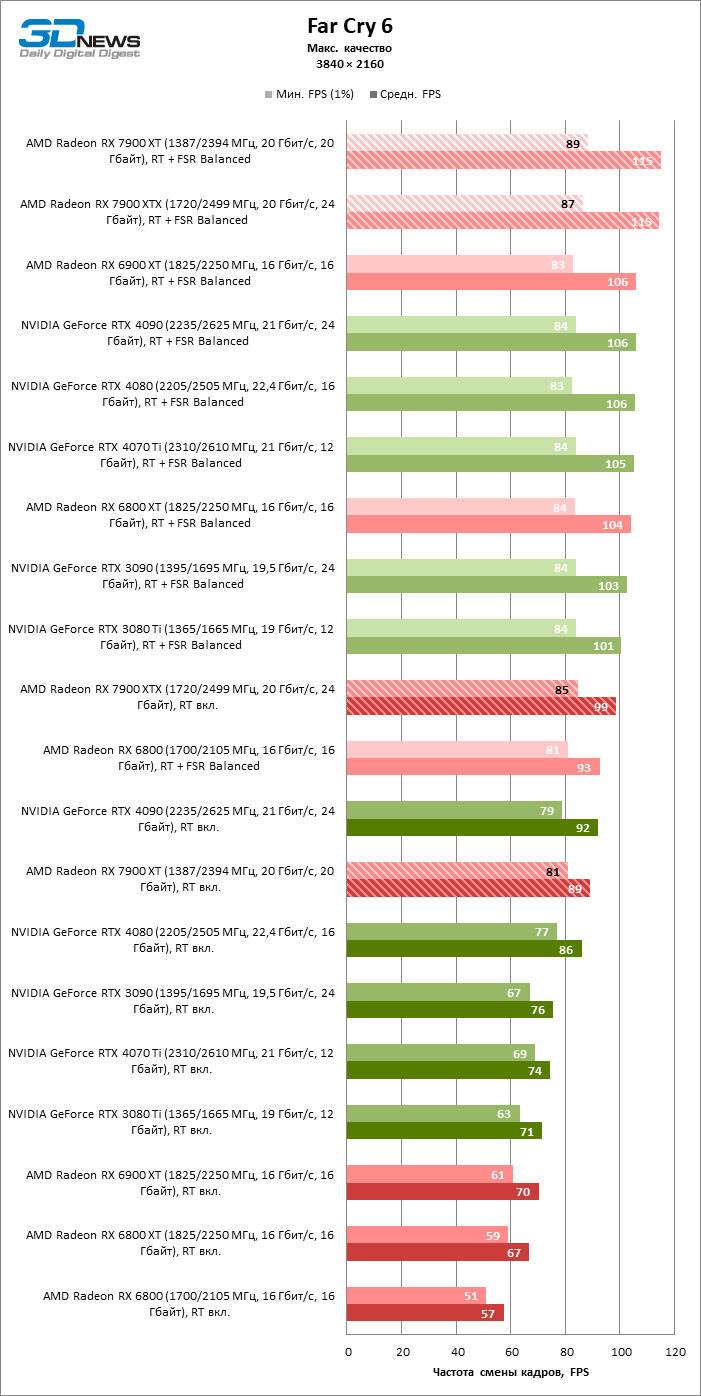
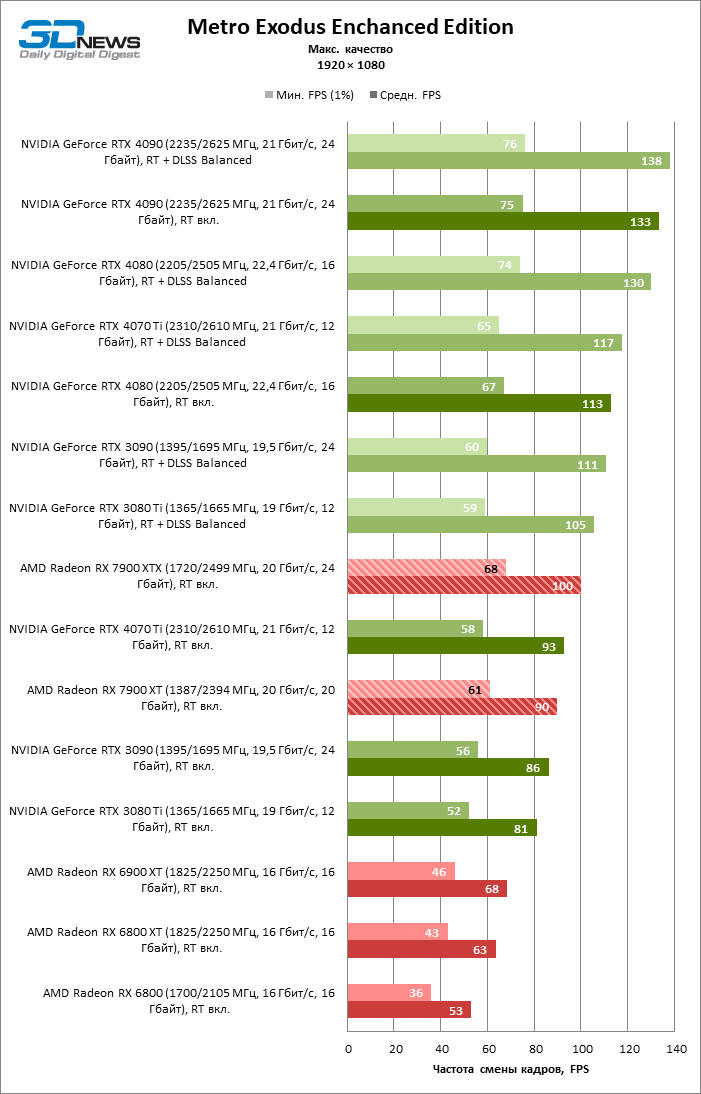
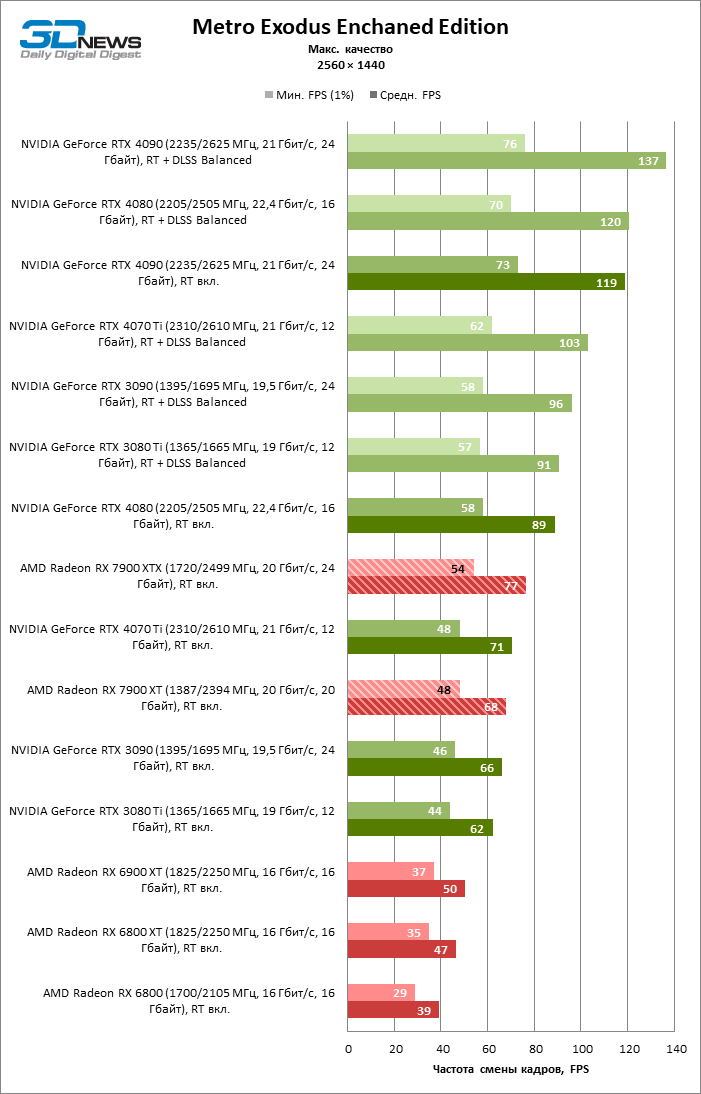
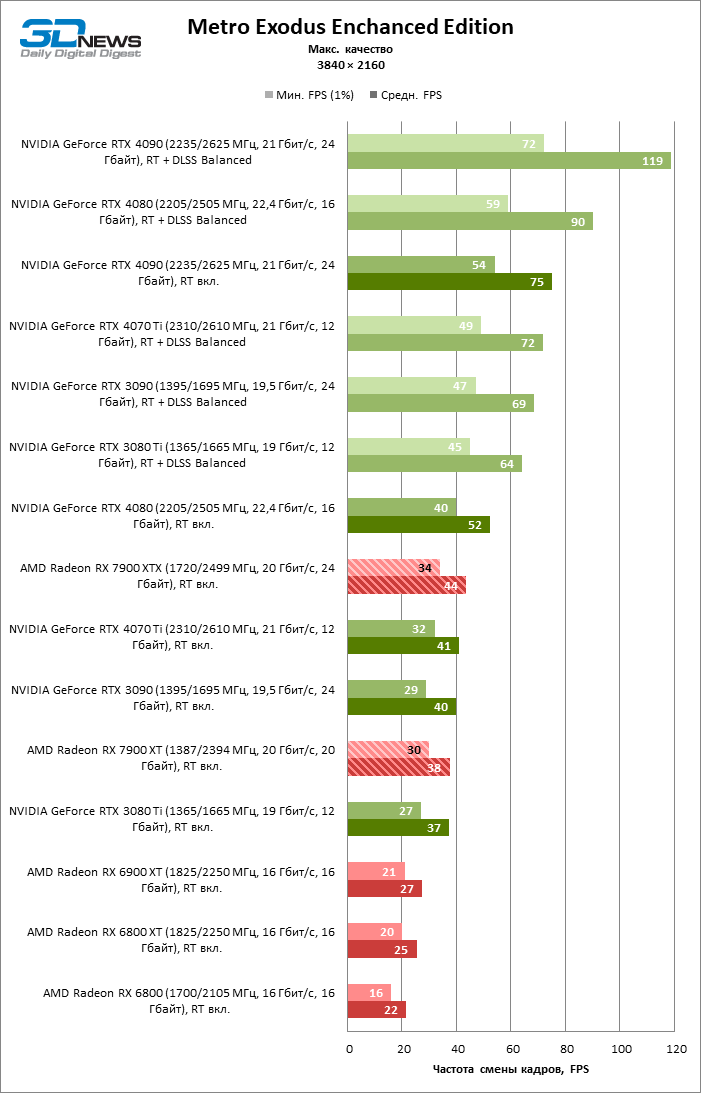
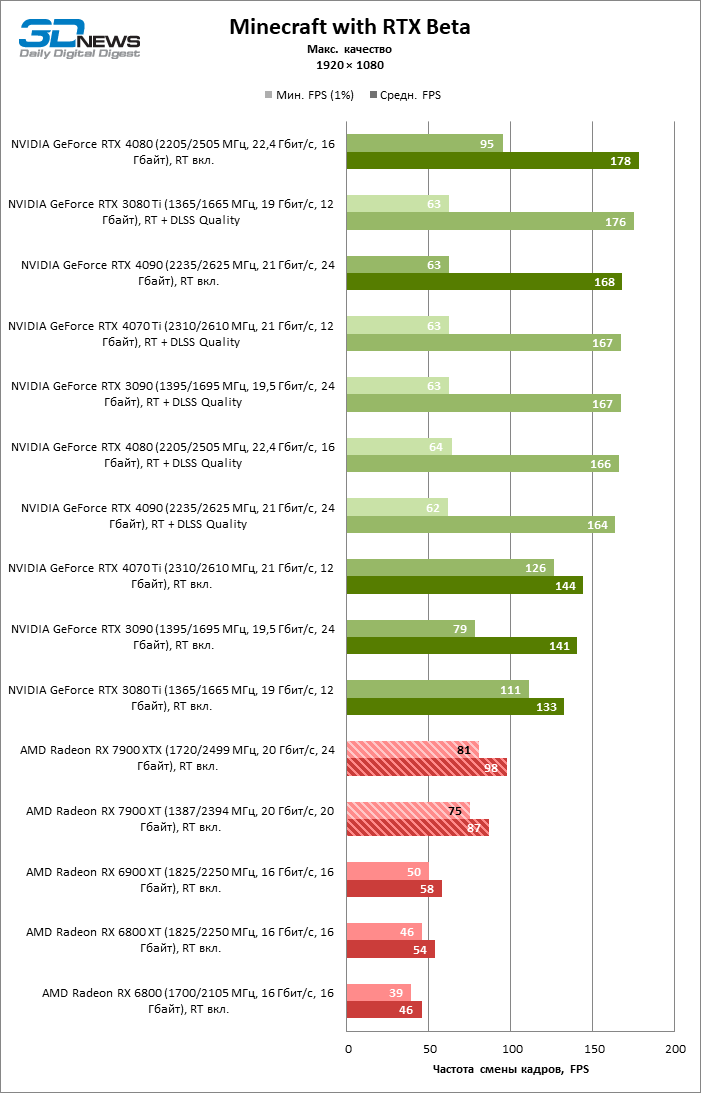
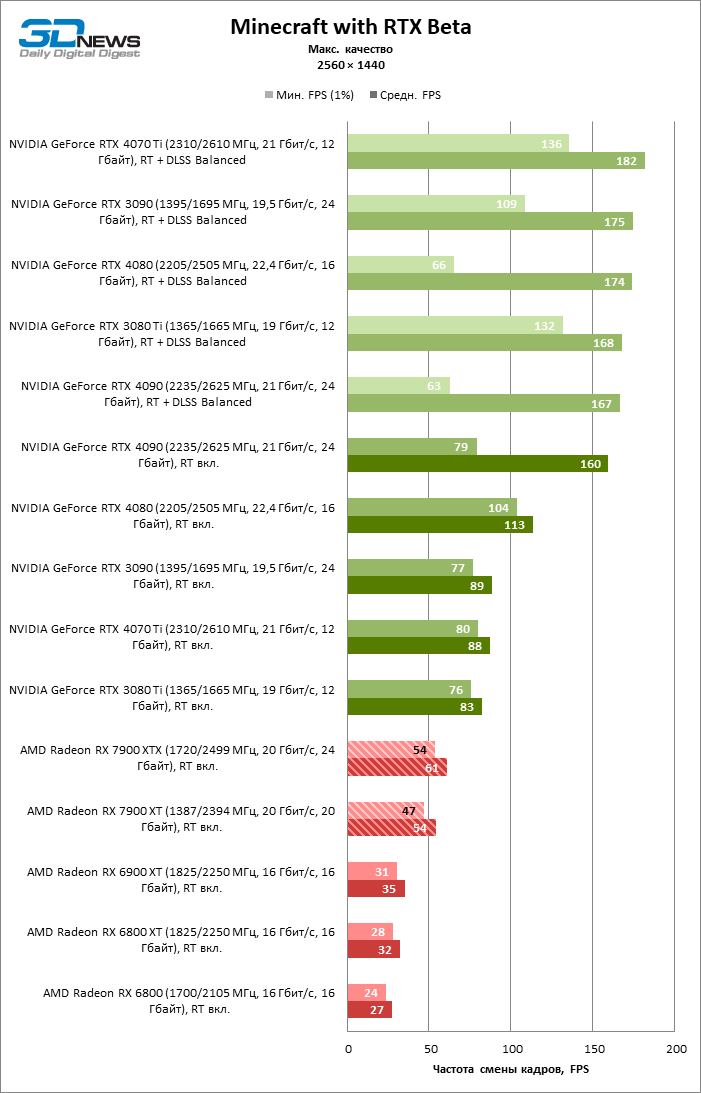
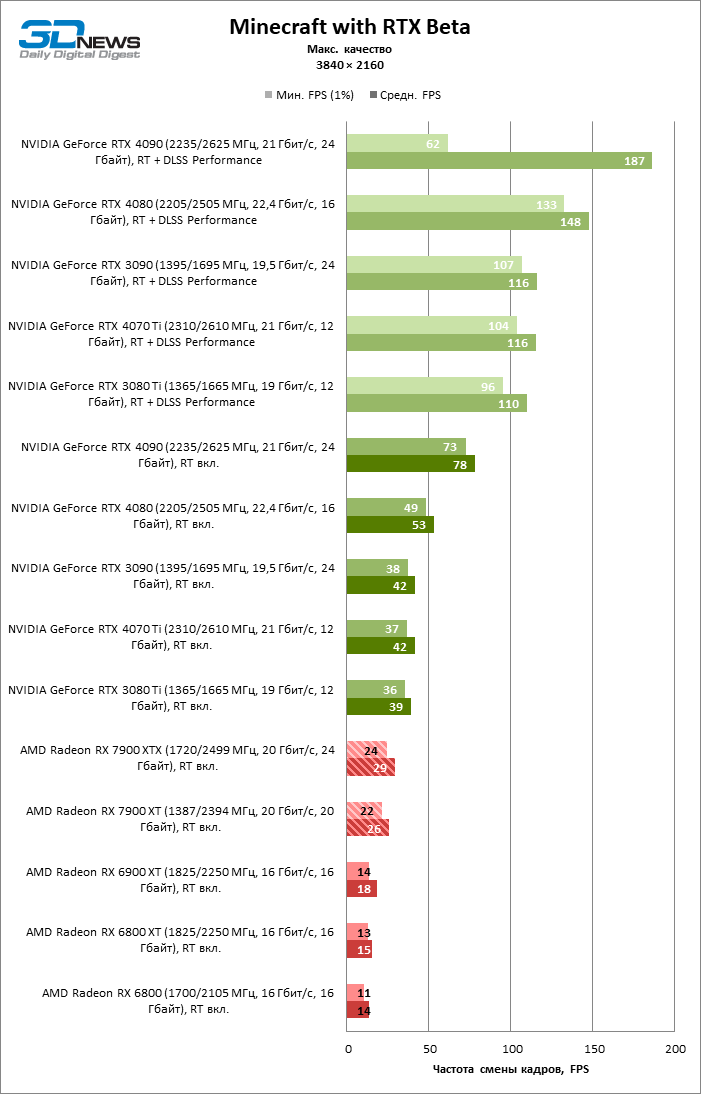
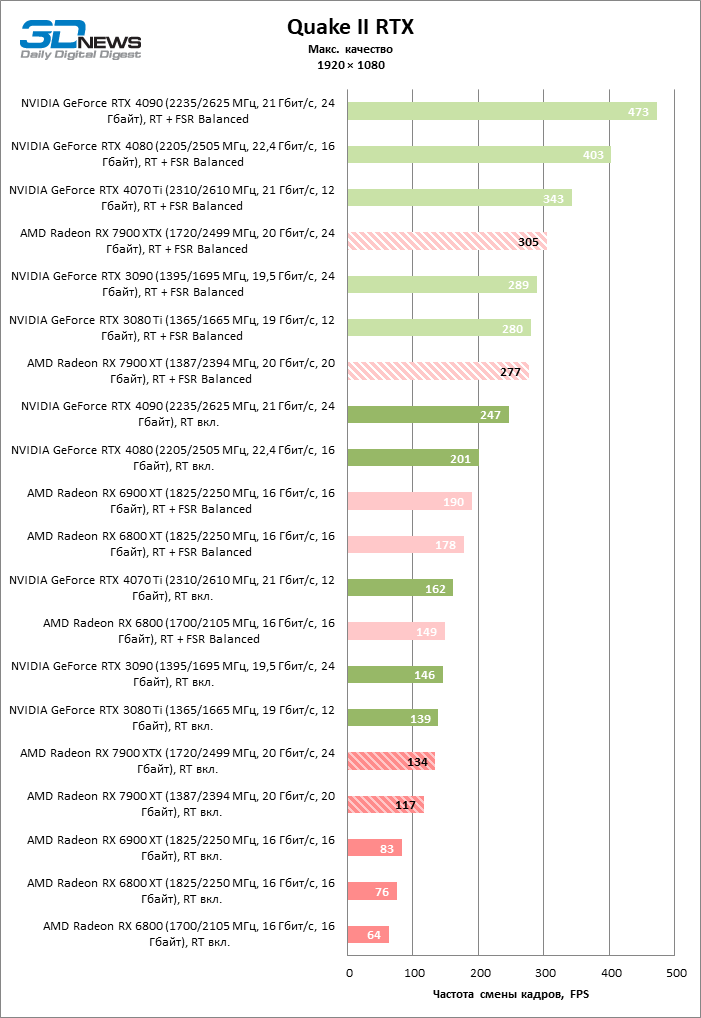
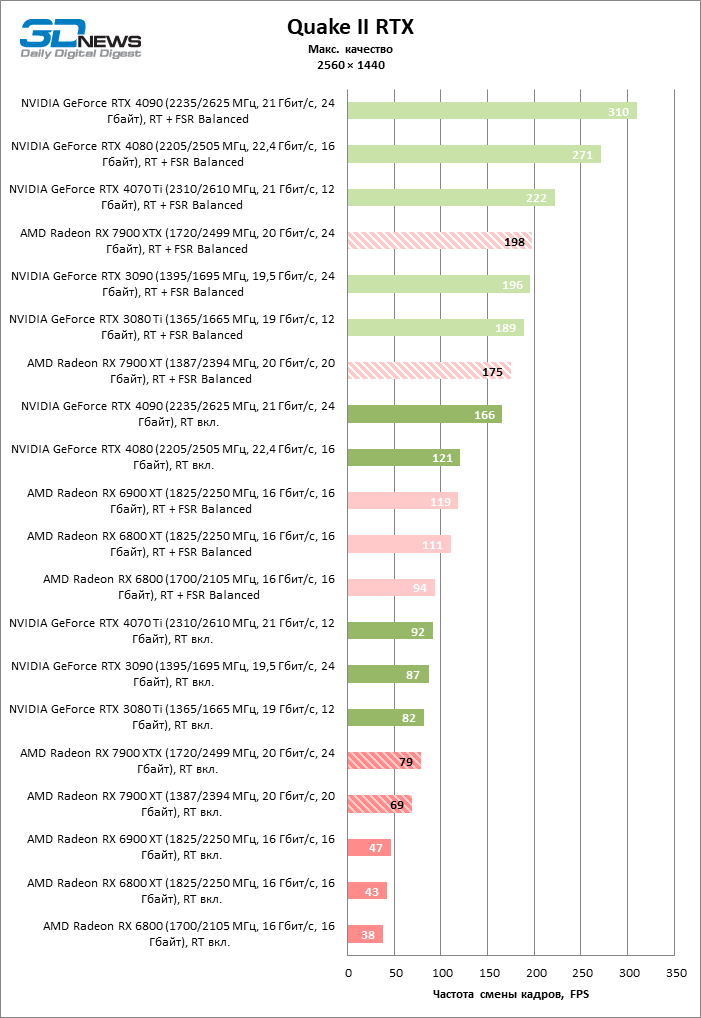
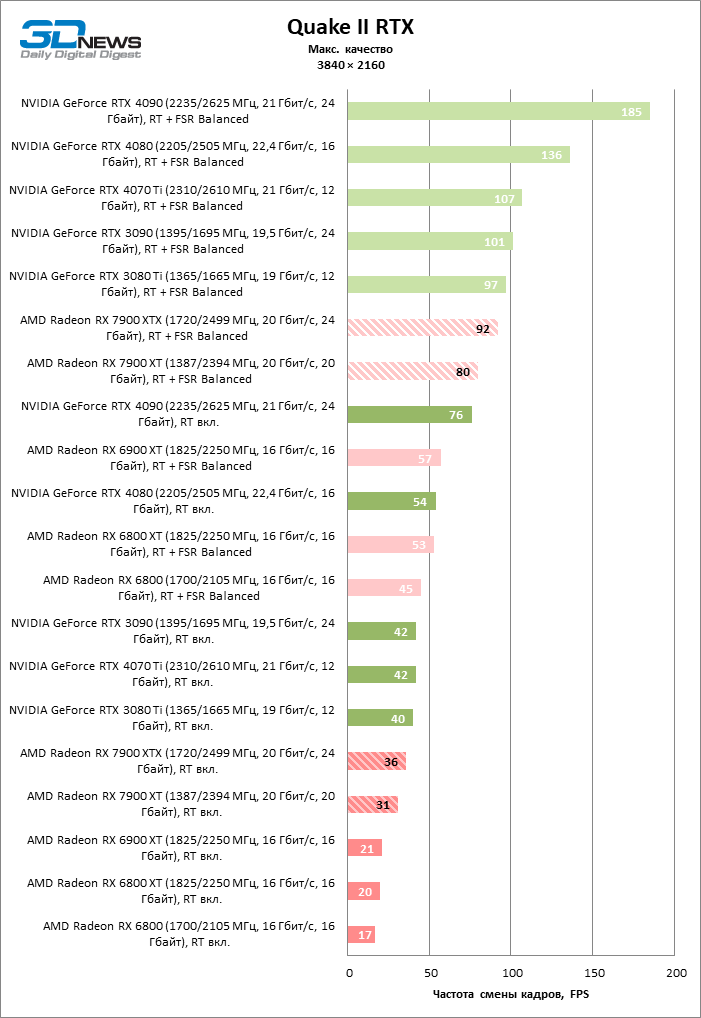
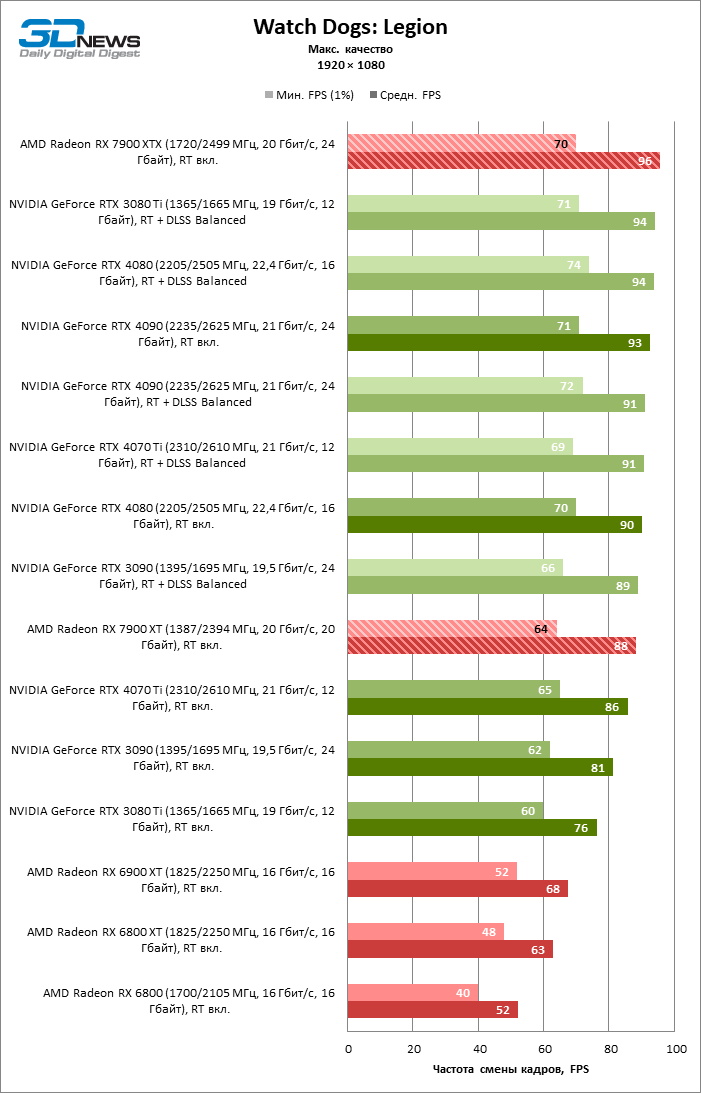
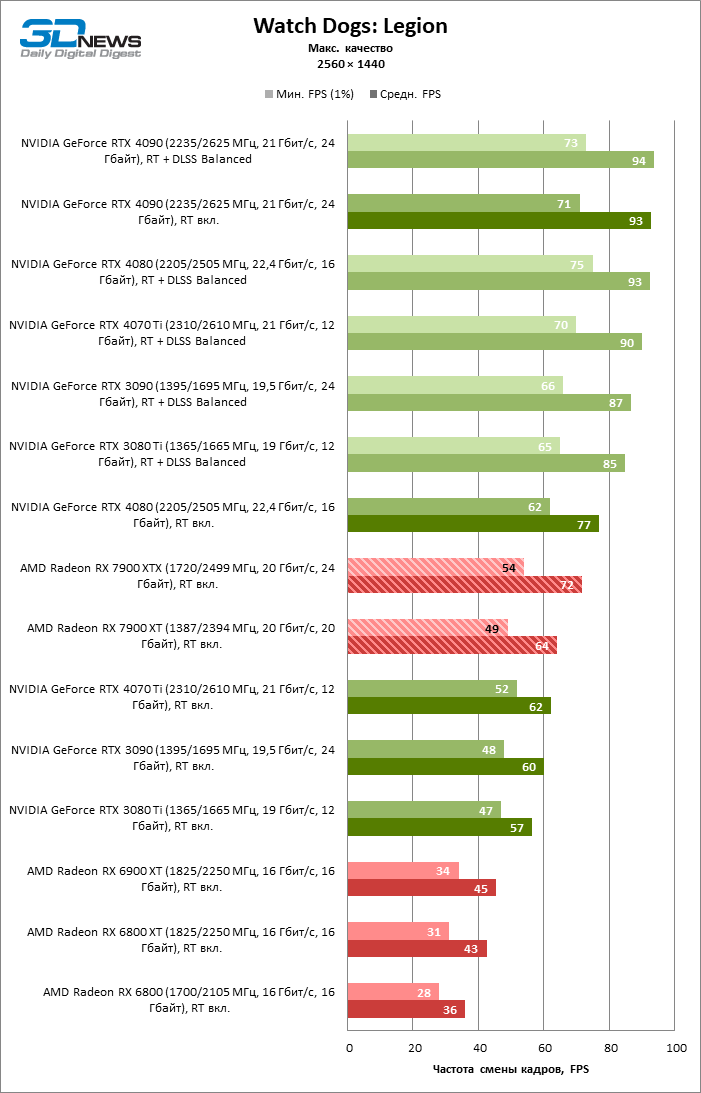
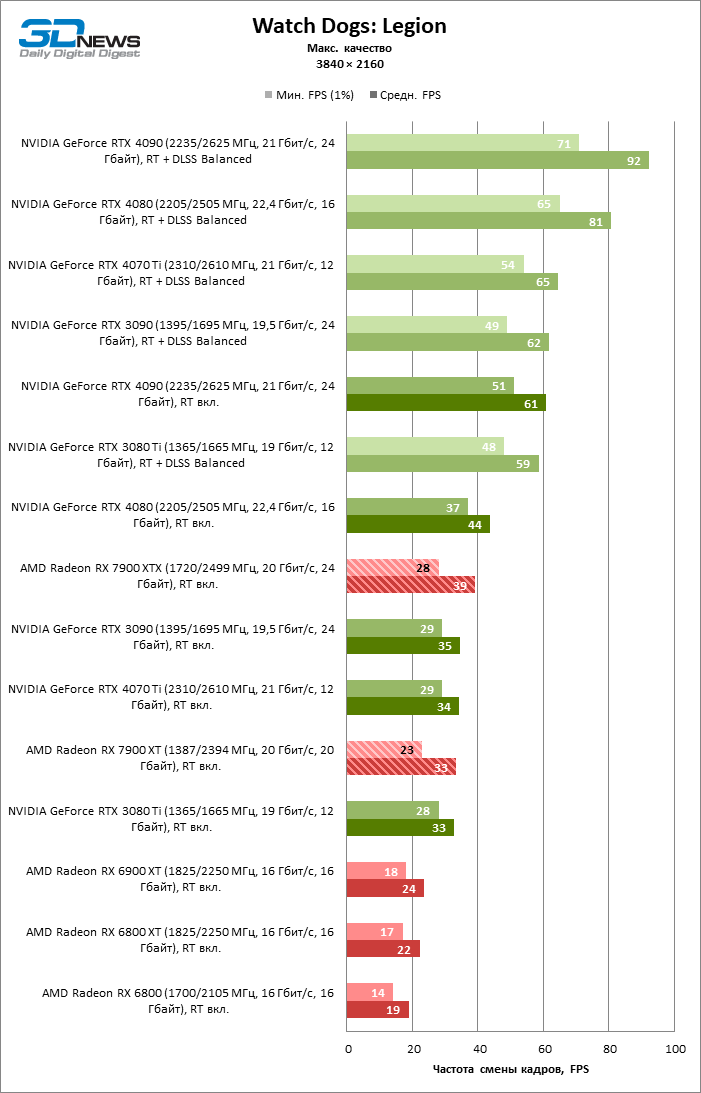
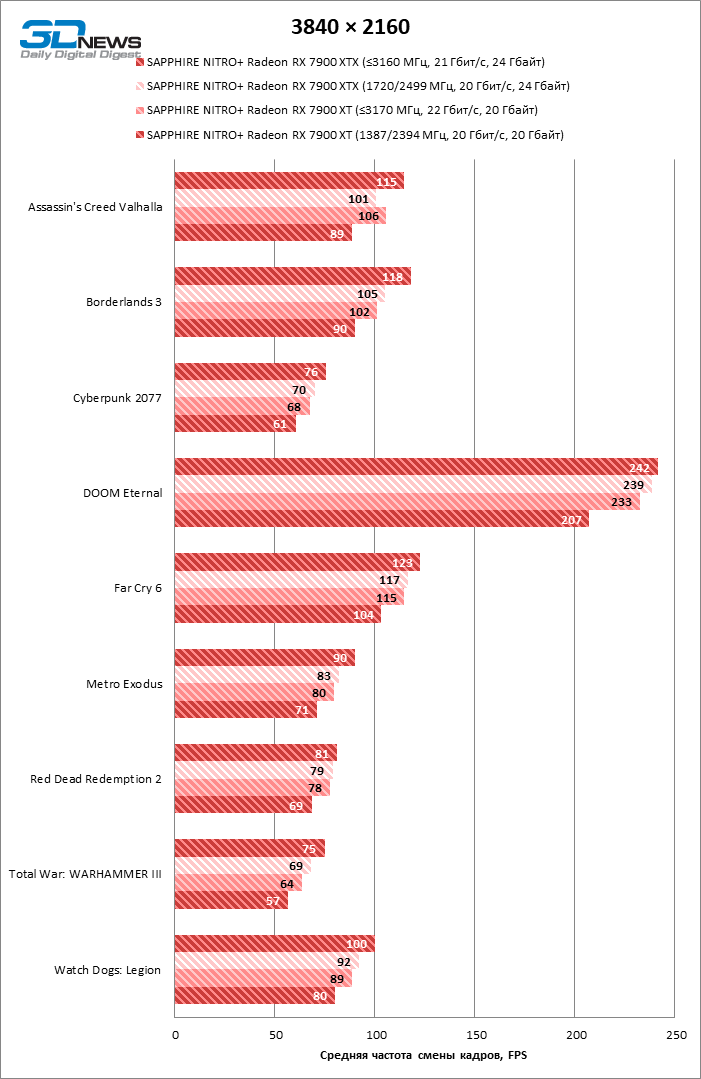
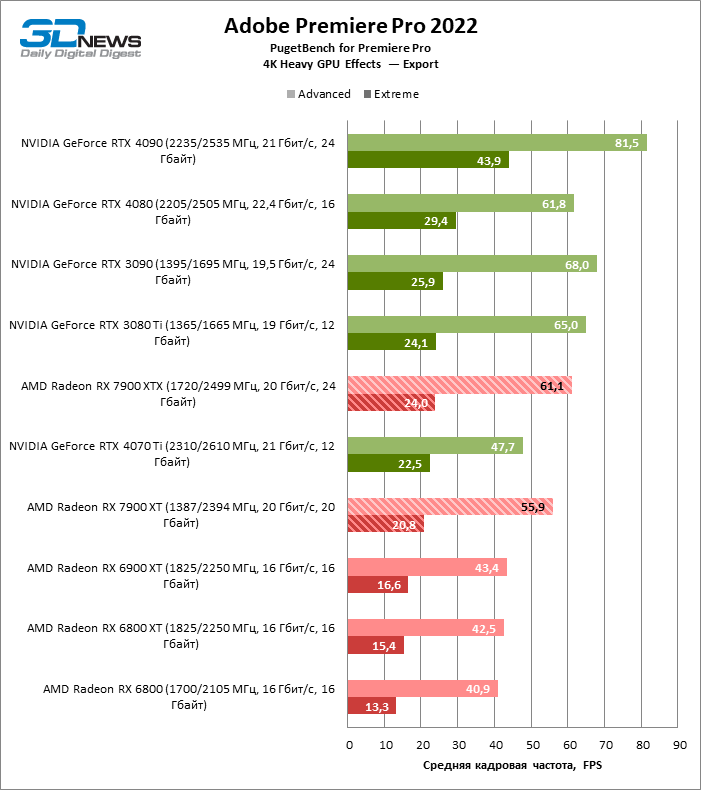
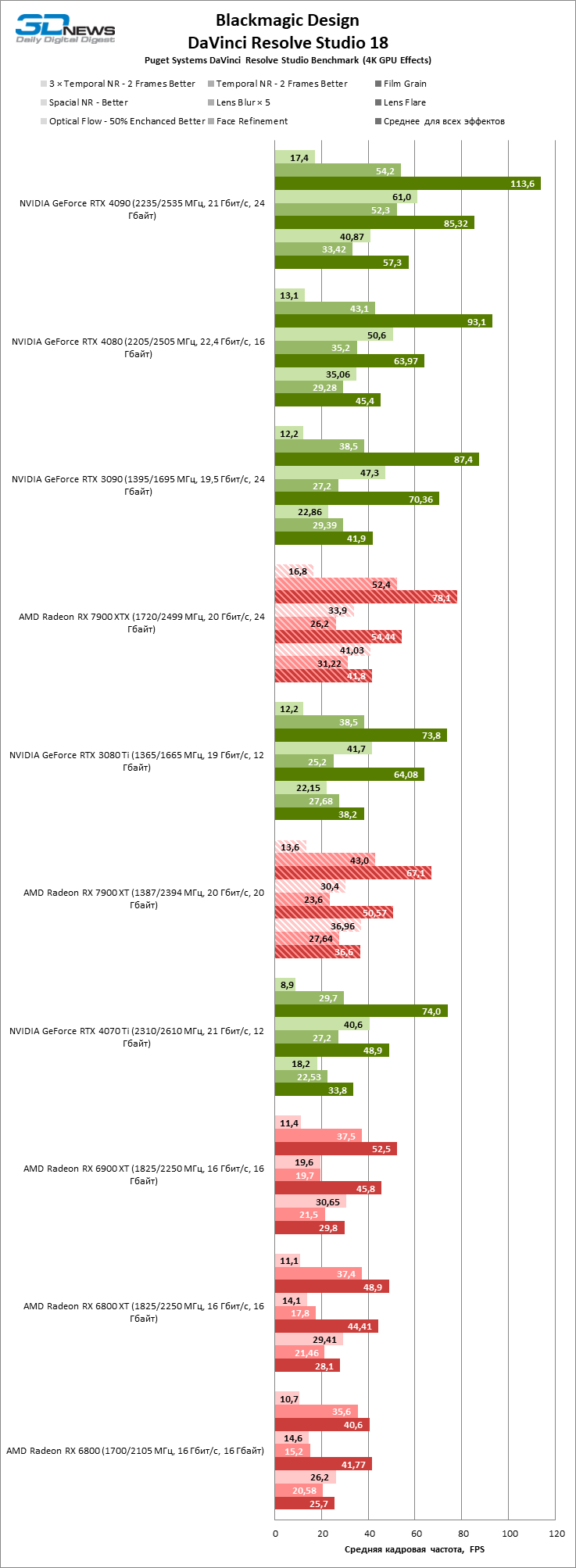
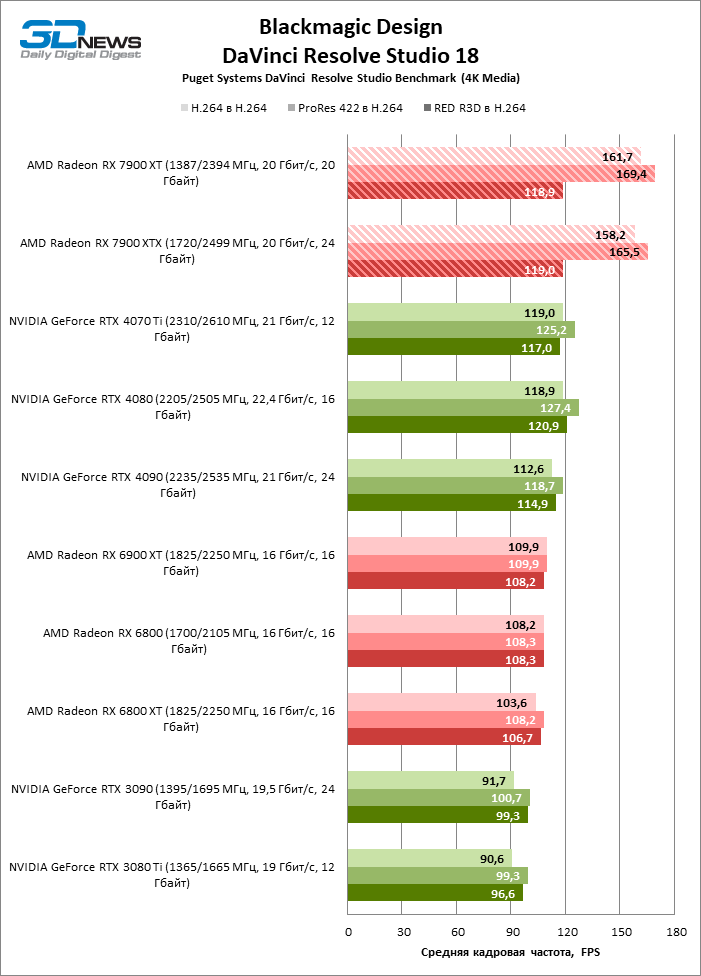
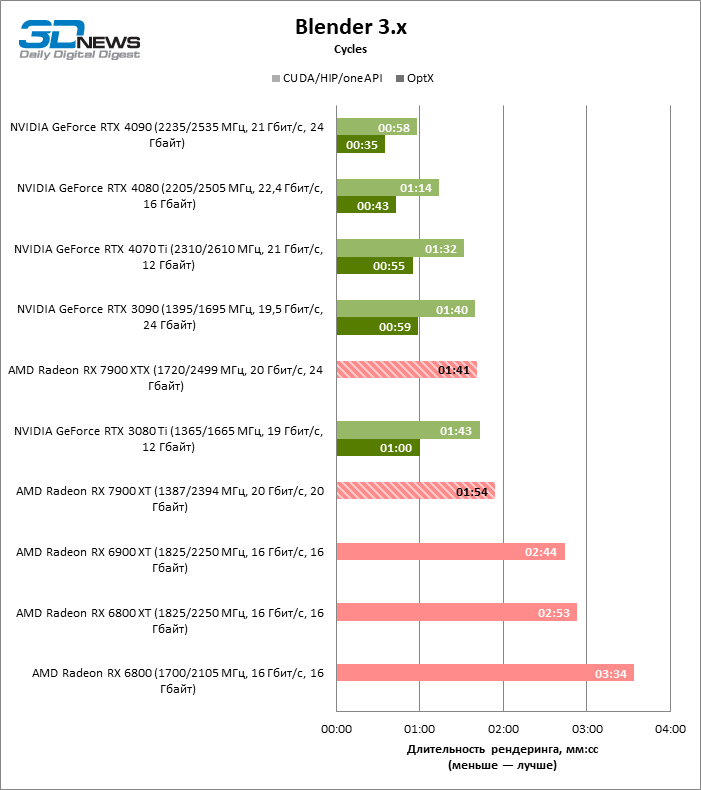
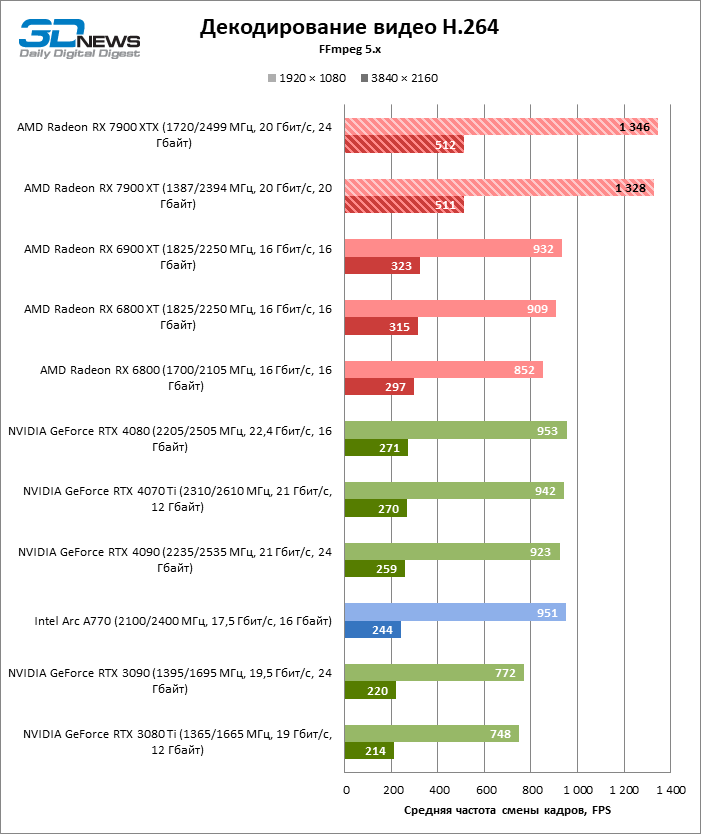
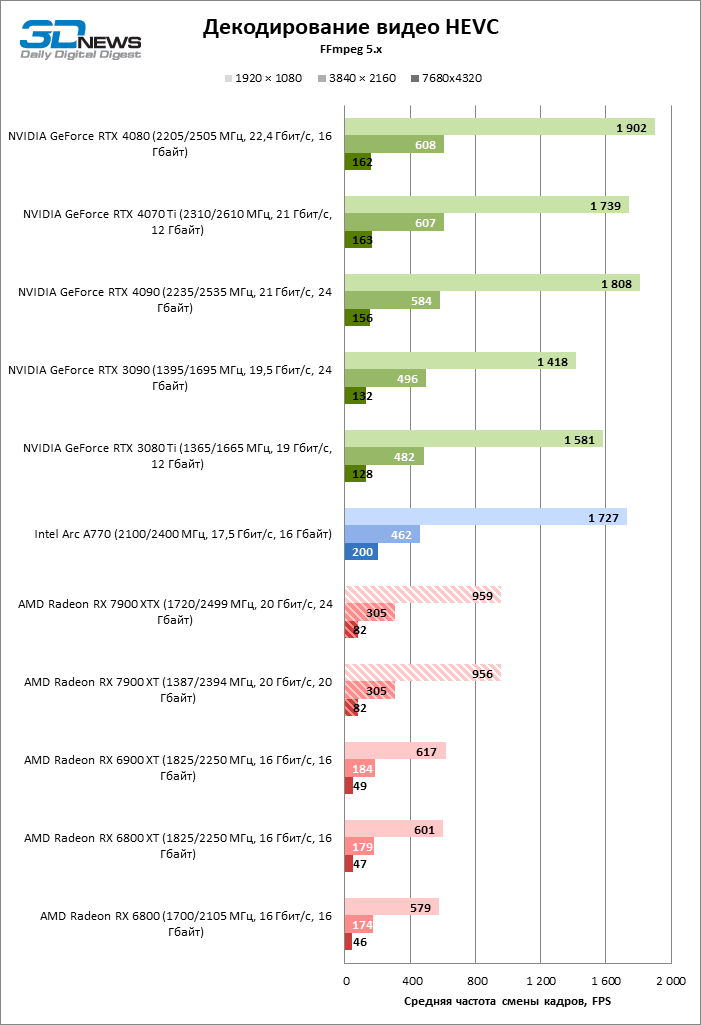
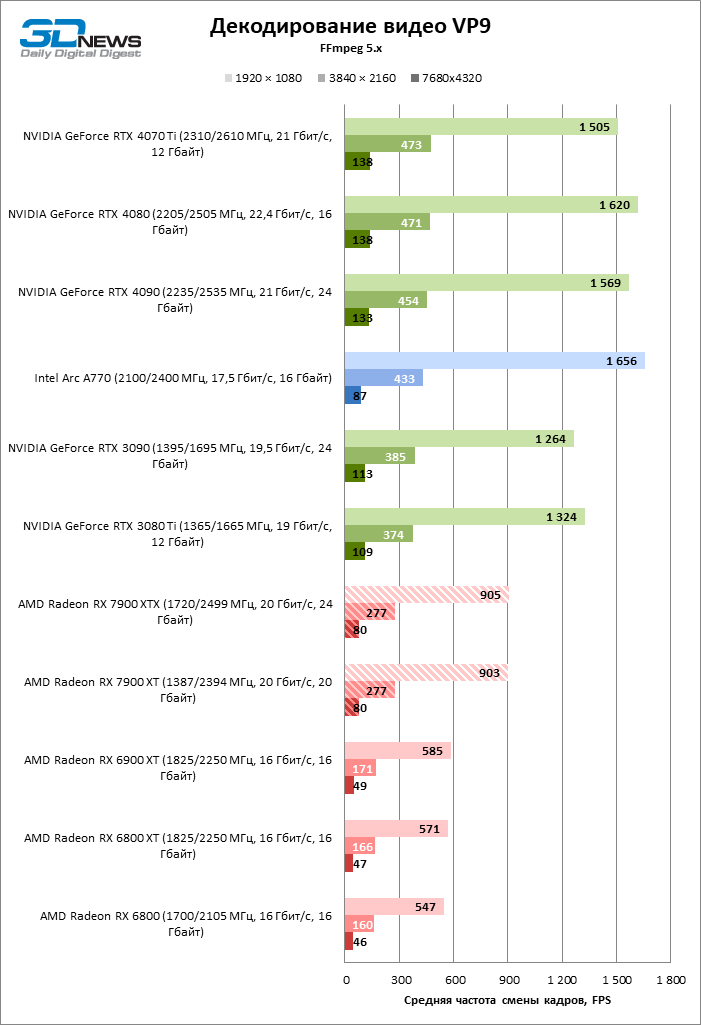

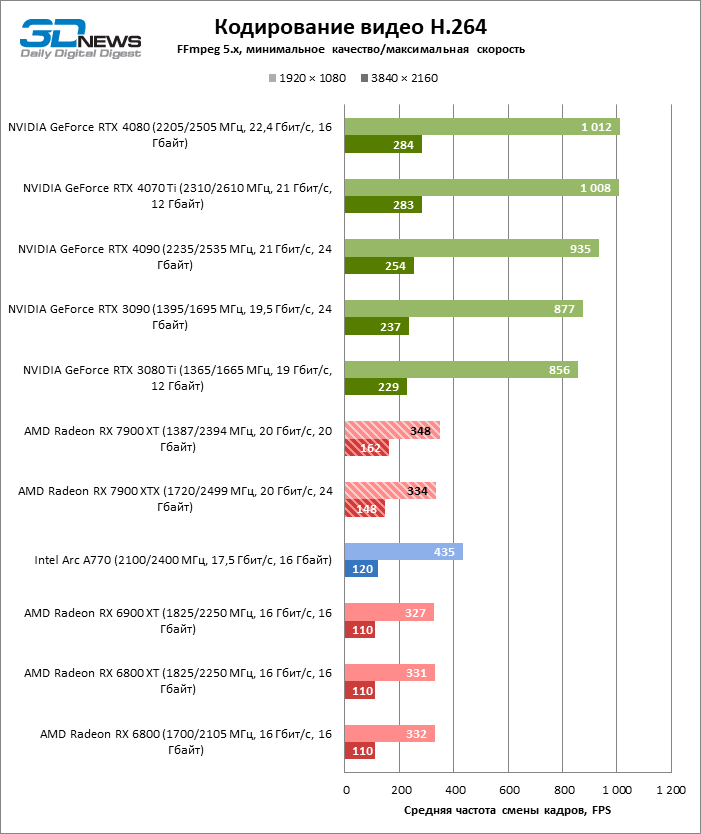
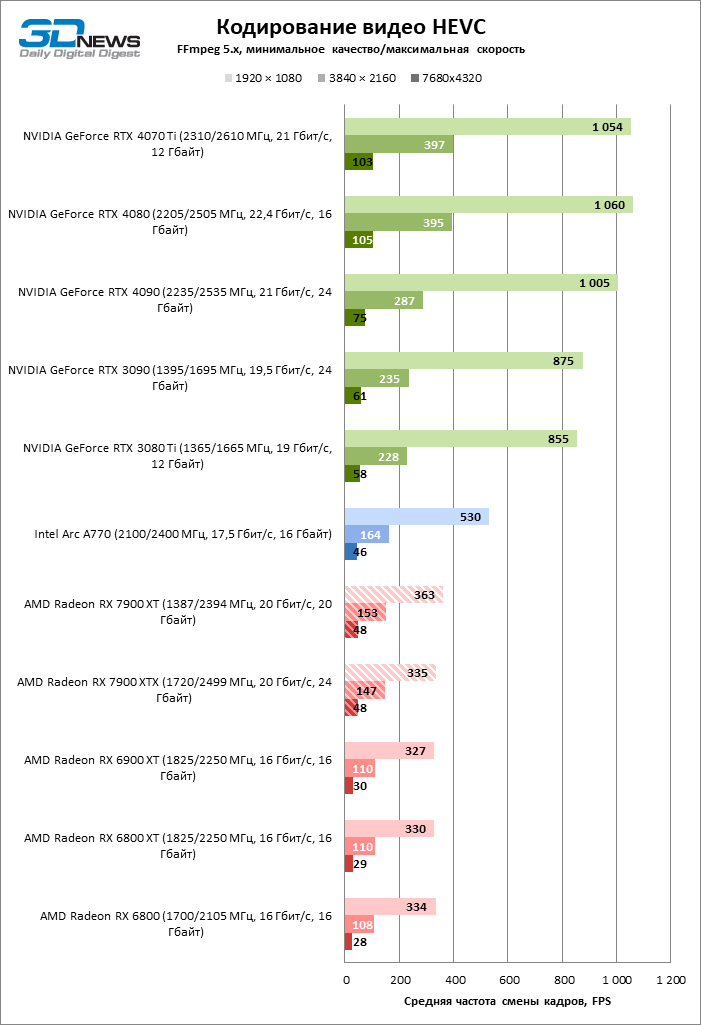
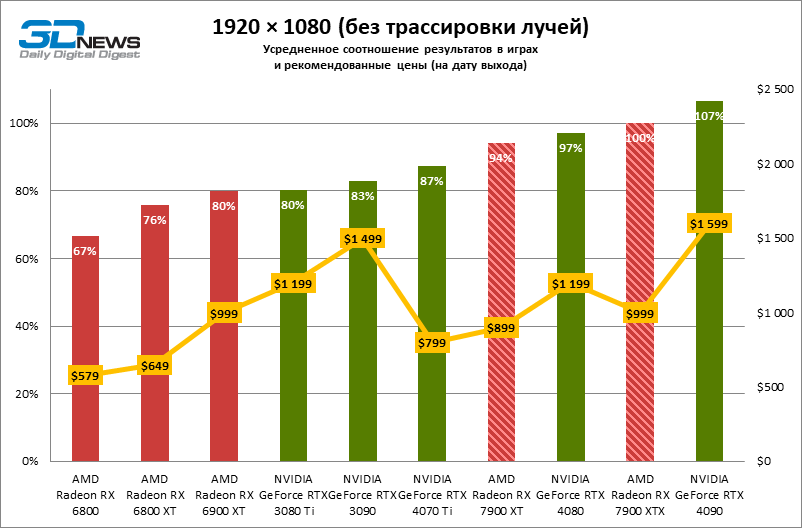
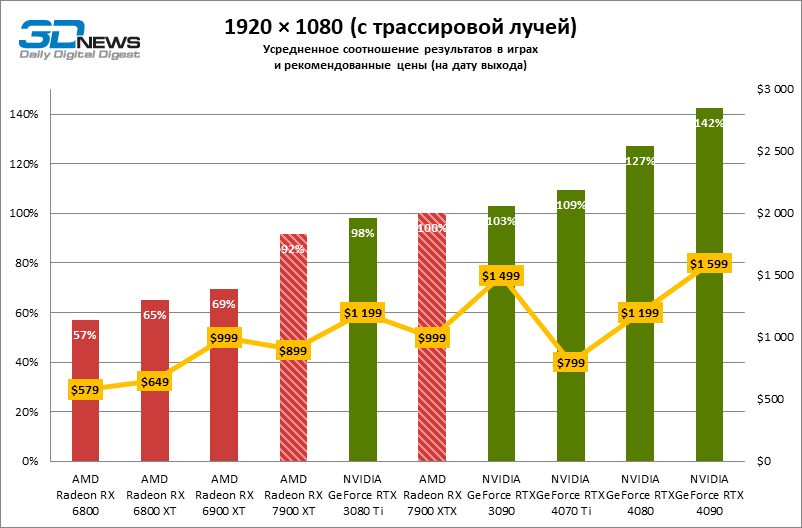
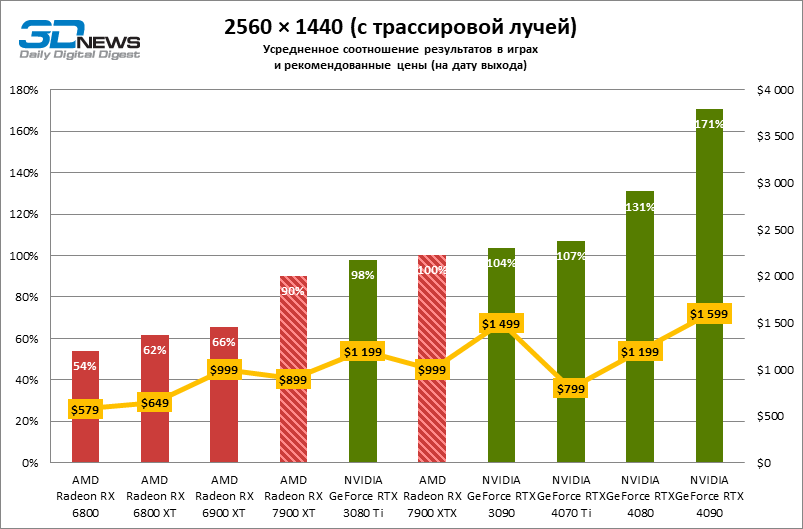
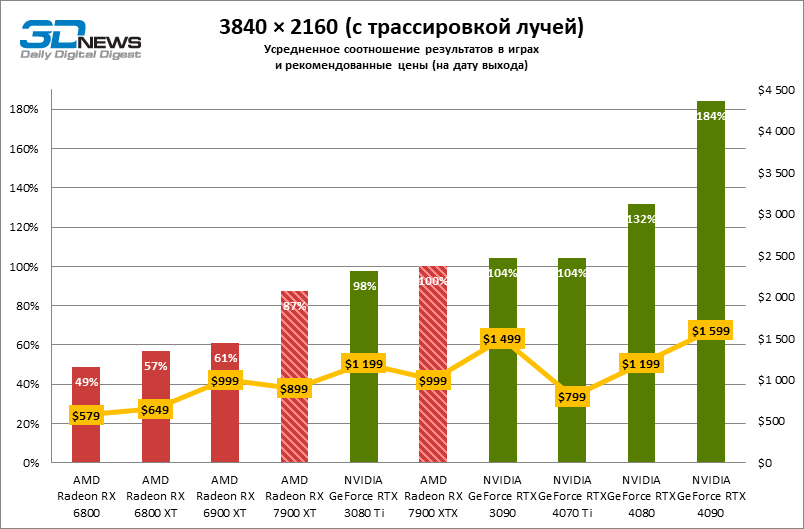






 Подписаться
Подписаться