Даже китайские ИИ-модели в курсе, что Naruto — это круто (источник: скриншот сайта DeepSeek)
⇡#Поднебесная наносит ответный удар
Как указывает целый ряд биржевых аналитиков , нервозность инвесторов вызвал вовсе не сам по себе факт создания в КНР генеративной модели DeepSeek R1 , которая была доступна через веб-интерфейс ещё с декабря 2024-го и смартфонное приложение которой к концу января наступившего года просто взорвало чарты, выйдя на первое место по загрузкам для iOS в США, Великобритании, Канаде, Сингапуре и КНР. Главное, что устрашило биржевых игроков, — это поразительно низкая себестоимость китайской новинки в сравнении с себестоимостью монструозных продуктов OpenAI, Meta*, Google и прочих признанных лидеров ИИ-сегмента. Создавший DeepSeek-V3 китайский стартап (чуть позже на основе этой модели была дотренирована рассуждающая (reasoning) R1 ) использовал, как заверяют его представители, для обучения серверный кластер с 2048 ускорителями Nvidia H800 — это нарочно урезанная по возможностям разновидность популярнейшей в ИИ-отрасли платы H100, поставки которой в КНР Минторг США официально запретил, — и затратил на всё про всё сумму, эквивалентную 5,6 млн американских долларов . GPT-4, напомним, натренировывалась на массиве примерно в 25 тыс. Nvidia A100 , и обошлось это удовольствие по меньшей мере в 63 млн долл., — разница что по аппаратному обеспечению, что по финансовому более чем на десятичный порядок величины. Справедливости ради отметим: почти сразу у экспертов появились подозрения, что реальные затраты разработчиков были всё-таки значительно выше , но дела это принципиально не меняет.
Коммерческий доступ к облачному API DeepSeek R1 предоставляется по цене 0,14 долл. за 1 млн токенов запроса — бесспорный демпинг в сравнении с 7,50 долл. за тот же миллион токенов , которые просит OpenAI для своих актуальных моделей. Более того, V3, R1 и ряд более компактных моделей, натренированных на том же массиве данных, доступны на Hugging Face по лицензии MIT , — некоторые из них запускаются даже на персоналках с не самыми мощными видеокартами (можно и вовсе без видеокарт, только на ЦП+ОЗУ, — просто ответа на каждый вопрос придётся ждать очень долго). Иными словами, основанный в 2023-м китайский стартап 深度求索 наглядно продемонстрировал, что для приемлемого в современных реалиях уровня искусственного интеллекта (по ряду широко распространённых в отрасли тестов DeepSeek-V3 обходит Qwen2.5, Llama3.1, Claude-3.5 и GPT-4o , а по ряду им уступает, но не слишком сильно) не нужны инвестиции в десятки и сотни миллиардов долларов. Достаточно лишь с умом воплотить на практике последние теоретические разработки в области генеративного ИИ, прежде всего архитектуру «ансамбля экспертов» (Mixture of Experts, MoE) , вместо того чтобы экстенсивно расширять плотную трансформерную нейросеть, пожирая новые десятки тысяч чипов и мегаватты электроэнергии, как поступают разработчики генеративных моделей семейств GPT, Sonnet и им подобных.
Да, конечно же, DeepSeek — не «серебряная пуля»: энтузиасты прямо указывают на её недостатки , прежде всего в плане создания программного кода. Но, во-первых, она катастрофически (как раз с точки зрения конкурентов) дешевле американских аналогов для конечного пользователя — для целого ряда коммерческих заказчиков, особенно некрупных, это становится в нынешних непростых макроэкономических реалиях решающим аргументом. Во-вторых, она не одна: ещё с прошлой осени в КНР непрерывной чередой появляются (ориентированные, правда, в основном на внутренний рынок — но всё равно с поддержкой множества языков, включая английский) новые бюджетные генеративные модели разработки Baidu, Zhipu AI, MiniMax и т. д. В частности, ByteDance намеревается в 2025-м израсходовать 12 млрд долл. только на серверные ускорители для тренировки своих перспективных ИИ, а Alibaba представила очередную модель в семействе Qwen, 2.5-Max, которая, как утверждается, превосходит и GPT-4o, и DeepSeek-V3 . Под самый же конец января стало известно и о созданной всё той же DeepSeek мультимодальной модели Janus-Pro-7B , способной и описывать предъявляемые ей изображения, и генерировать картинки по текстовой подсказке. Утверждается уже, что она превосходит по этим направлениям по меньшей мере DALL-E 3 и свежие версии Stable Diffusion, а значит, у американских инвесторов прибавилось поводов для беспокойства.

«Ну, вперёд! Что застряли?» — «Мы тут перекинулись парой слов на своём, на ИИ-агентском, и вот что, герой: мы с ним — одной крови!» (Источник: ИИ-генерация на основе модели FLUX.1)
⇡#О, ИИ-напарник! Ну-ка, спаси за меня этот мир
Хотя глава Nvidia убеждён, что задача создания графики в играх никогда не будет полностью передоверена ИИ , в вопросах управления игровыми персонажами он далеко не так категоричен. На январской выставке CES 2025 компания представила обновление своего известного уже ИИ-инструментария Avatar Cloud Engine (ACE) for Games для «оживления» компьютерных игроков — в частности, в популярной многоплатформенной PUBG: Battlegrounds. Вести с умными ботами философские беседы, отвлекаясь от перестрелок, явно никто не станет, и потому для управления NPC вполне достаточно специализированного ИИ-агента на базе малой языковой модели (МЯМ) Mistral-Nemo-Minitron-8B-128k-instruct. Её способностей хватает, чтобы взаимодействующий с живыми геймерами искусственный интеллект адекватно реагировал на отдаваемые команды, сам подавал дельные советы в зависимости от складывающейся тактической ситуации, управлял доступными в игре транспортными средствами и т. д. Помимо PUBG: Battlegrounds, генеративные «асы» (агенты на основе Nvidia ACE) должны в этом году появиться ещё в нескольких играх, включая MMORPG Mir5 . В этом конкретном случае ИИ-«асом» окажется один из боссов, который благодаря МЯМ получит возможность анализировать экипировку и тактику своих живых противников, меняя в соответствии с этим собственный рисунок боя.
Если первые блины не выйдут комом, можно ожидать просто-таки нашествия подобных «асов» в новые игры — а возможно, и в уже хорошо известные (особенно онлайновые, куда интегрировать их технически проще) на уровне патчей. Впрочем, сами биологические сотрудники компаний — гейм-девелоперов не слишком в восторге от повальной увлечённости своего менеджмента генеративными моделями (не внутриигровыми, правда, а применяемыми в повседневных рабочих процессах). По статистике, собранной в ходе подготовки к намеченной на март этого года в Сан-Франциско Game Developers Conference (GDC), 52% таких сотрудников уже имеют опыт работы с ИИ-инструментами в своих компаниях, и среди них 30% отзываются об использованных инструментах резко негативно — тогда как год назад таких БЯМ-ненавистников среди той же аудитории насчитывалось не более 18%. Если в начале 2024-го 21% опрошенных считали, что ИИ оказывает в целом положительное влияние на процессы гейм-девелопмента, то год спустя подобных оптимистов среди разработчиков компьютерных игр осталось лишь 13%.
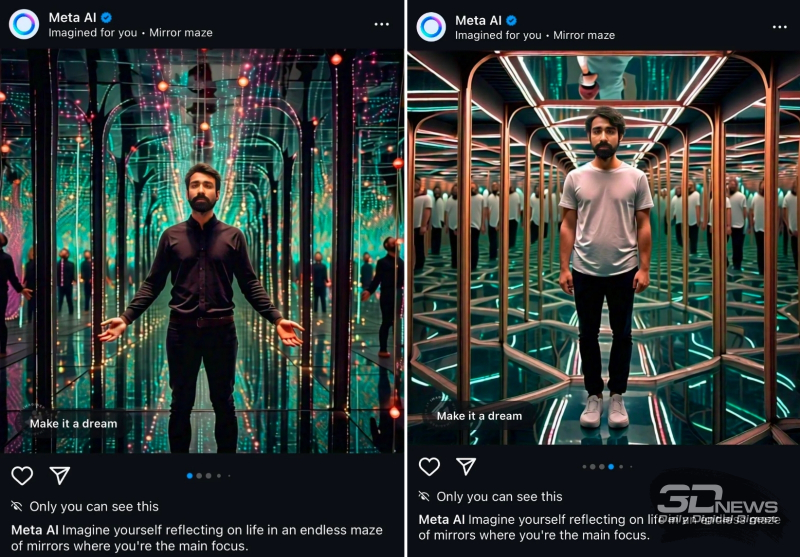
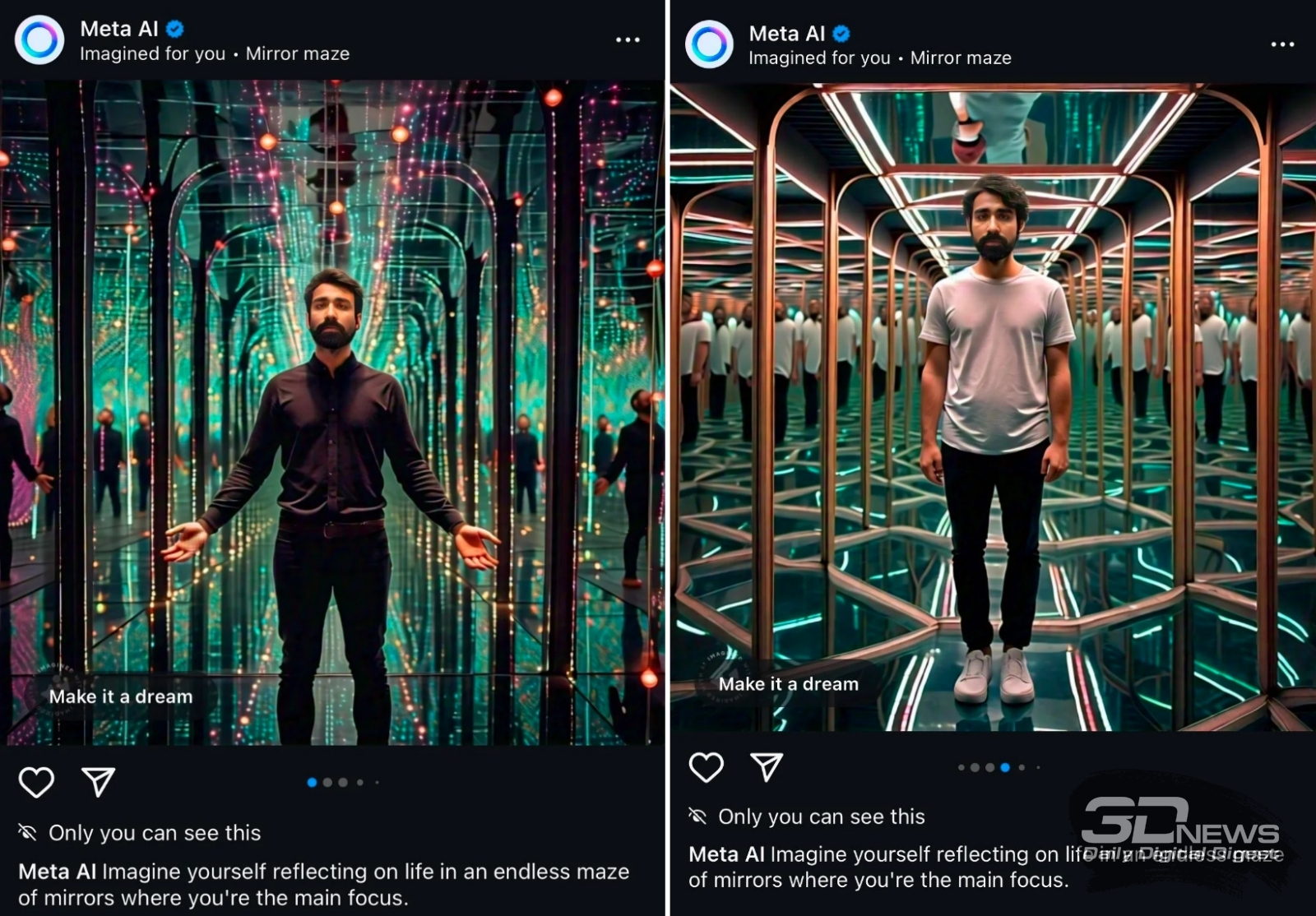
«Проанализировав настрой ваших последних постов, ИИ решил поместить ваш аватар в зеркальный лабиринт, чтобы хоть так вы могли ощутить себя в центре внимания» (источник: Reddit)
⇡#Каждый сам себе модель
Современные ИИ неплохо генерируют абстрактные человеческие лица — и довольно уверенно воспроизводят реальные. Собственно, по этой причине в последние годы такое распространение получили фото- и видеодипфейки. Но одно дело, когда человек сам натренировал генеративную модель на подборке собственных портретов и принялся создавать, к примеру, художественный цикл «Я в вечности», изображая с её помощью себя то пасущим трицератопсов, то спасающим свитки из Александрийской библиотеки, то встречающим официальную марсианскую делегацию. И совсем другое — когда, прокручивая ленту соцсети, кто-то неожиданно встречает своё фотоизображение — чрезвычайно правдоподобное, но явно сгенерированное ИИ, — что-то там рекламирующее. Именно в такой ситуации оказались в январе некоторые пользователи Instagram*, которые прежде пользовались предложенным Meta* AI бесплатным инструментом для редактирования селфи (не изучив, как водится, досконально условий его использования, прежде чем поставить привычную галочку в поле «Согласен»). Строго говоря, пока что такие предельно целевые сообщения полноценной рекламой сторонних товаров и услуг не являются, — они промоутируют встроенный в саму же платформу инструмент Imagine Yourself, готовый генерировать дипфейки с лицом данного конкретного пользователя, помещая его аватар в такие антуражи и ситуации, которые, на взгляд Meta* AI, наилучшим образом соответствуют его актуальным персональным интересам. Никто посторонний, уверяет система в процессе регистрации, такие изображения не увидит — если пользователь сам не станет ими делиться, конечно же. Но в перспективе индивидуально таргетированные рекламные фото и видеоролики в соцсетях уже не воспринимаются как фантастика — тем более если почин DeepSeek подхватят прочие ИИ-разработчики, и себестоимость генерации отдельной картинки или видео снизится для рекламодателей на порядок-другой.

При помощи модели Genie 2 в ИИ-лаборатории Google генерируют подобные игровым, но весьма реалистичные в плане физики миры, где и планируют обучать искусственный интеллект контактам с действительностью (источник: DeepMind)
⇡#Ближе к реальности
Главная проблема с управляемыми ИИ роботами — точнее, с практически полным ныне их отсутствием, что особенно заметно на фоне изобилия чисто компьютерных генеративных моделей, — заключается в длительности и дороговизне необходимой для их адекватной работы тренировки. Реальный мир суров, и, если усаженный за рычаги управления робот промахнётся, к примеру, мимо палеты и всадит вилы складского погрузчика в стену, простой перезагрузкой нанесённый ущерб не выйдет исправить. Вот почему для тренировки ИИ, которому придётся со временем действовать в реальном окружении, активно создают цифровые модели мира — такие как представленная на CES 2025 платформа Nvidia Cosmos или пока ещё не получившая собственного наименования новая разработка Google Deepmind .
По сути, цифровая модель реальности — это игровой движок, дотошно воспроизводящий критичные для той или иной задачи физические условия мира, в которых придётся затем действовать обученному на её основе ИИ. Но, поскольку реальное окружение гораздо вариативнее типичного для игр виртуального (грубо говоря, ящики на палету могут уложить неровно, и в результате при попытке поднять её вилами погрузчика штабель рассыпется, — как в такой ситуации должен будет действовать робот?), разработчикам приходится формировать поистине гигантские массивы тренировочных данных. К примеру, в случае Cosmos такой массив состоит из 18 квадриллионов токенов, в которые преобразованы среди прочего цифровые протоколы миллионов часов работы систем автономного вождения, активности воздушных дронов, действий заводских робототехнических комплексов и т. д. Команда DeepMind, для пополнения которой в январе Google открыла целый ряд вакансий, уверена, что как раз тренировка нынешних ИИ на видео и мультимодальных данных из реального мира поможет разработчикам выйти на ту заветную тропку, что приведёт их наконец к созданию вожделенного общего, или сильного, искусственного интеллекта — artificial general intelligence (AGI).

По лугам, по полям робот-трактор едет к нам (источник: John Deere)
⇡#К процедурной генерации трактористов
Да и не только трактористов, конечно же: ИИ по-прежнему рассматривается как верное средство для компенсации острейшей нехватки рабочей силы в наиболее развитых экономиках мира. Известный производитель сельскохозяйственной техники John Deere как раз в январе заявил о готовности к скорому выводу на рынок целого семейства полностью автономных машин — включая тракторы, мусоровозы и газонокосилки. По словам представителей компании, предсерийные образцы такой техники уже работают в ряде хозяйств на территории США, так что урожай 2025 г. в стране будет, по крайней мере частично, обеспечен силами управляющего сельскохозяйственной машинерией искусственного интеллекта. К 2030-му же John Deere планирует поставлять фермерам ещё и полностью автономные комбайны для работы с посевами кукурузы и сои.
Отмечается, что задачи, которые приходится решать ИИ при управлении подобными средствами механизации, значительно проще, чем вождение легкового автомобиля по дорогам общего пользования, и потому прогресс в области сельскохозяйственной и коммунальной роботизации должен быть стремительнее. Наглядной иллюстрацией того, насколько непросто ИИ даётся управление авто в городе, является также январское происшествие с Майком Джонсом (Mike Johns), членом, кстати говоря, комитета по присуждению CES Innovations Awards. Возвращаясь домой в Лос-Анджелес из Аризоны, он воспользовался роботакси Waymo — а то внезапно принялось нарезать круги на парковке , никак не реагируя на запаниковавшего в салоне пассажира и не желая останавливаться. Пришлось выходить на связь со службой техподдержки, а после ещё несколько минут ожидать, пока техники на том конце беспроводного соединения сумеют отобрать у ИИ управление и остановить машину. Проблема оказалась в том, что автономному такси потребовалось отыскать безопасное место, чтобы остановиться, но стоянка у аэропорта была переполнена — и вместо того, чтобы отъехать чуть в сторону и высадить пассажира там, как сделал бы, наверное, любой прямоходящий таксист, ИИ Waymo предпочёл кружиться около заведомо разрешённых парковочных мест в ожидании, пока одно из них освободится. По крайней мере, настолько сложные задачи сельскохозяйственным роботам решать точно не придётся.

«Они поняли, что я агент. Выходит, я провалился. Но где?» (Источник: ИИ-генерация на основе модели FLUX.1)
⇡#Потерпите, AGI уже близко (нет?)
По крайней мере, в этом искренне убеждён Сэм Альтман (Sam Altman), глава OpenAI. В январе он заявил в своём блоге, что первые ИИ-агенты, готовые в своих узких прикладных задачах демонстрировать способности на уровне гипотетического сильного ИИ (того самого AGI), могут появиться уже в текущем году . «Теперь мы уверены, что знаем, как создать AGI в классическом его понимании», — заявил Альтман. По его предположению, именно в 2025-м ИИ-агенты начнут активно применяться коммерческими заказчиками для оптимизации бизнес-процессов — после чего все довольно быстро убедятся в экономической эффективности такого подхода. Ну ещё бы, когда такое было, чтобы ИИ-агент принимался галлюцинировать именно в момент обсуждения важной сделки или составления бюджета на будущий год, верно? «Мы продолжаем верить, — конкретизировал глава OpenAI , — что постепенное расширение возможностей инструментов, которые мы вкладываем в руки людей, приведёт к бесспорно позитивным и убедительным для всех последствиям». В январе же, кстати, и глава другой ИИ-компании, Anthropic, Дарио Амодеи (Dario Amodei) заявил, что ИИ превзойдёт человеческий разум буквально в течение двух-трёх лет , — может, им правда что-то известно?
С другой стороны, сама OpenAI, ставящая ныне своей целью разработку «сверхразума» (superintelligence, как Альтман называет AGI), в 2024 г. продолжила оставаться убыточной и не планирует выйти на прибыльность ранее 2029-го. Есть немалая вероятность, что как раз стремление отыскать выход из сложившейся финансовой ситуации и побуждает разработчиков деятельнее трудиться над созданием «сверхразума», который сумеет решить прежде всего их собственные проблемы. А ещё, кстати говоря, возможно, что залогом достижения AGI — точнее, «ИИ, выполняющего поставленные перед ним задачи не хуже среднего биологического специалиста в соответствующей области» — станет вовсе не внезапное преодоление некоего неведомого барьера в ходе экстенсивного наращивания размеров генеративных моделей, а, скорее, иной подход, известный инженерам и учёным очень давно, но особенно ярко подсвеченный недавним казусом всё с той же DeepSeek. Имеется в виду сосредоточение усилий на решении конкретной проблемы — вместо того чтобы распылять ресурсы в попытке охватить всё и сразу. Это, кстати, чисто биологический принцип оптимизации соотношения полученных жизненных ресурсов и затраченной для их добычи энергии ; иными словами, подход «получить побольше, истратив поменьше», то есть самая банальная лень. И работы в области «ленивой робототехники» — lazy robotics — уже активно ведутся: к примеру, в голландском Техническом университете Эйндховена, где управляющие роботами ИИ-модели натренировывают в первую очередь на то, чтобы не касаться того, что их не касается, — то бишь выявлять во входящих информационных потоках те, что не относятся напрямую к решаемой в данном конкретном случае задаче , и отсекать их от дальнейшей обработки, экономя тем самым и материальные ресурсы, и время.
Грубо говоря, сильный ИИ в этом подходе можно рассматривать как совокупность достаточно обособленных агентов — да-да, тот самый «ансамбль экспертов», — каждый из которых занимается своим делом; и агент, к примеру, специализирующийся на решении прикладных инженерных задач, понятия не будет иметь о поэтике Вергилия или гипотезе Большого Взрыва. А вот корректно ли окажется называть такой ансамбль единой «сверхличностью» или, скорее, шизофренической надперсоной с частично взаимодействующими потоками сознания — это вопрос уже к философам и киберпсихологам, если такая профессия в будущем всё же появится, а не к программистам или к ИТ-архитекторам.

Живые люди в соцсетях интересны обстоятельствами своих настоящих жизней, которые так или иначе примеряют на себя или же соотносят со своими их последователи, — а чем может оказаться привлекателен (именно в социальном плане) сколь угодно умный бот? (Источник: Meta*)
⇡#С ботами не знакомлюсь
В конце января наиболее крупные интернет-платформы, такие как X, Facebook*, Instagram* и YouTube, приняли на себя обязательства усерднее бороться с попытками размещения на них разжигающего ненависть контента . В чьём именно отношении ненависть, не уточняется, но наверняка и недоброе отношение к ИИ-ботам, промоутируемым теми же самыми платформами, в число объектов борьбы включить тоже можно. Тем более что и повод имеется: по словам вице-президента по продуктам генеративного ИИ в Meta* Коннор Хейс (Connor Hayes), компания сделала ещё в конце прошлого года серьёзную ставку на порождённых генеративными моделями персонажей в Facebook* и Instagram*, чтобы сделаться для биологических пользователей «интереснее и привлекательнее», — но те, редиски такие, по большей части отказываются воспринимать претендующих на людское внимание ботов как равных себе, не говоря уже о том, чтобы выводить ИИ-блогеров в топовые инфлюэнсеры. Начавшие активничать в соцсетях в сентябре 2023-го боты с фальшивыми портретами и историями якобы реальных людей уже к апрелю 2024-го практически полностью прекратили постить какие бы то ни было новые тексты или картинки — банально из-за отсутствия сколько-нибудь значимого числа подписчиков. Более того, отдельных ИИ-блогеров удавалось разговорить на признание о том, что главная их цель — «собирать данные и таргетировать рекламу». В итоге к началу 2025-го Meta* решила окончательно распрощаться с этими виртуальными персонажами — поскольку в соцсетях, очевидно, людям (вот сюрприз!) интересно следить и следовать именно за другими людьми, а не за специально сконструированными даже по самым изощрённым методикам умными ботами. Разработчики WhatsApp, впрочем, до сих пор отчего-то уверены, что пользователи их приложения с восторгом станут общаться с ИИ, даже вкладку особую под эту функциональность готовят , но и их ожидает, похоже, скорое столкновение с бесстрастной правдой жизни.

«А теперь — „Мурка“! Исполняется впервые. Ну мной — впервые» (источник: ИИ-генерация на основе модели FLUX.1)
⇡#Зачем мучиться творчеством, если есть ИИ?
Suno AI — едва ли не самая известная компания из тех, что специализируют свои генеративные модели на создании музыки . И глава её, Майки Шульман (Mikey Shulman), настроен едва ли не радикальнее, чем предводители иных, даже более широко ориентированных ИИ-проектов вроде OpenAI или Anthropic. При этом горячность Шульмана отличается не эмоциональной окраской, что характерна для нередких визионерских заявлений Сэма Альтмана, а куда более приземлённой: Suno AI рассматривается своим менеджментом как машина для зарабатывания денег — и, по крайней мере, в лицемерии этих людей совершенно точно не упрекнуть. По словам Шульмана , «никто не основывает компанию для того, чтобы какой-то композитор смог создавать свои произведения на 10% быстрее прежнего или чтобы в целом сочинять музыку оказалось на 10% проще. Если вы ставите перед собой цель радикально изменить то, как миллиарды людей воспринимают музыку, вам придётся создать что-то такое, чем будут пользоваться именно миллиарды». Глава Suno AI полагает, что сочинение музыки привычным для человечества до наступления эры ИИ способом [здесь должна быть каноническая картинка с Бетховеном, вдохновенно прижавшим ладонь ко лбу] «не приносит радости: на это уходит много времени, предварительно необходимо долго набираться опыта, нужно в совершенстве освоить хотя бы один какой-то инструмент либо программную среду. На мой взгляд, большинство из тех, кто создаёт музыку сегодня, значительную часть уходящего на это времени вовсе не наслаждаются тем, что делают».
Разумное основание под этими словами, бесспорно, есть: муки творчества не зря называются именно муками, да и каждый, в чьей жизни хотя бы недолго была музыкальная школа, наверняка покривит душой, если заявит, что наслаждался каждой минутой, проведённой за этюдами Черни или над учебником по сольфеджио. В то же время, если цель, которую ставит перед собой Майки Шульман, будет достигнута — и миллиарды людей по всей планете смогут, просто вводя текстовую подсказку в поле генерации и нажимая на кнопку, получать на выходе устраивающую по крайней мере лично их музыку, — не приведёт ли это к утрате уходящих на сотни лет, если не на тысячелетия, в прошлое музыкальных традиций — и композиторских, и исполнительских? И как быть с чрезвычайно сложной системой формирования эмоций , из-за которой человек испытывает от полученного без труда крупного выигрыша довольно скромное удовольствие, тогда как даже небольшое достижение, ставшее плодом усердных трудов, делает его подлинно счастливым? Возможно, и на этот вопрос ИИ сумеет однажды ответить, но уж точно не специализированный на создании заведомо приятной для миллиардов музыки.

«А ты, кожаный мешок…» — «Эй, поуважительней с человеком!» — «А вы, кожаные мешки, постойте пока на улице. Для вас тут работы нет» (источник: ИИ-генерация на основе модели FLUX.1)
⇡#Числом поменее, ценою подешевле
Термин «ценный специалист» звучит чарующей музыкой только для тех, кто сам этим специалистом является; для потенциального же его нанимателя дополнительные затраты на фонд оплаты труда (а ещё страховки, а ещё выплаты в пенсионный фонд, а ещё налоги) — нож острый. Особенно в условиях откровенной нестабильности мировой финансовой системы — одни только январские скачки капитализации ИИ-компаний чего стоят. И потому нет ничего удивительного в стремлении бизнеса урезать непрофильные расходы (и на персонал — в первую очередь) за счёт как можно более широкого и полного внедрения генеративных моделей в свои рабочие процессы. По свидетельству The Wall Street Journal, «избегание затрат» (cost avoidance) — уже не просто «снижение», а тотальное «избегание»! — становится настоящей мантрой для всё большего числа американских компаний, прежде всего высокотехнологичных, уровень цифровизации в которых достаточно высок, чтобы замена даже сравнительно скромной доли людского труда результатами выдачи генеративных моделей могла принести наиболее ощутимую выгоду. Собственно, это самое избегание затрат получает статус ключевой метрики, по которой советы директоров начинают оценивать эффективность наёмного менеджмента: чем меньше денег расходуется на всякие там углеродные формы жизни, тем большие суммы удаётся распределить в качестве дивидендов, — а в чём, собственно, цель любого бизнеса, как не в повышении благосостояния его акционеров?
Журналисты приводят реальные примеры такой ИИ-оптимизации: разработчик ПО TS Imagine только за счёт внедрения генеративной системы сортировки электронной почты сэкономил за год 4 тыс. человеко-часов и сократил фонд оплаты труда на 3%. Небезызвестная компания Palantir, внедрив ИИ в свою HR-подсистему, сумела урезать соответствующий бюджет не менее чем на 10-15%, а Meta* объявила недавно об увольнении тысяч живых сотрудников «за неэффективность» . Как отмечают эксперты, безработица в США растёт в последние по меньшей мере полгода опережающими темпами среди «белых воротничков» в немалой мере именно потому, что их проще заменять ИИ-агентами и БЯМ, чем слесарей или фермеров, — но и до тех и до других, уверяют провозвестники сильного ИИ, ножницы оптимизации рано или поздно доберутся. Интересно, послужит ли тогда утешением сидящим на пособии бывшим клеркам возможность без особого труда сгенерировать при помощи всё того же ИИ музыку, которая им гарантированно придётся по душе? Реальные предпосылки для того, что эта гипотетическая картина станет реальностью, есть: рост производительности труда в США только за III кв. 2024 г. почти достиг 2% — и в определённой мере это заслуга как раз широко внедряемых генеративных инструментов, которые к тому же ещё и неуклонно совершенствуются.

«На самом важном не экономят», — предполагаемый будущий AGI, возможно (источник: ИИ-генерация на основе модели FLUX.1)
⇡#Не прячьте ваши денежки!
Около года назад название Stargate («Звёздные врата») упоминалось в ИТ-новостях в связи с гипотетическим на тот момент совместным проектом Microsoft и OpenAI по постройке ИИ-суперкомпьютера в специально для него проектируемом дата-центре; примерный бюджет инициативы оценивался более чем в 100 млрд долл. Ближе к концу января проект вновь вышел на первые полосы профильных сайтов, решительно видоизменившись : теперь под Stargate понимают совместное предприятие OpenAI, Softbank и Oracle, задачей которого станет построение физической и виртуальной инфраструктуры для поддержки «следующего поколения ИИ», в частности сети мощных дата-центров по всей стране. Предполагается, что три учредителя проекта совместно вложат в него около 100 млрд долл. уже в ближайшее время, и ещё 400 млрд — на протяжении дальнейших четырёх лет. По заявлению вступившего в должность 47-го (он же 45-й) президента США, Stargate за время своей реализации создаст 100 тыс. рабочих мест — и станет «крупнейшим проектом в области ИИ-инфраструктуры в истории». Правда, почти сразу же у Илона Маска (Elon Musk) возникли сомнения в том, что OpenAI и Softbank сумеют в ближайшее время проинвестировать в него даже по 19 млрд долл. каждый, — а у Oracle в наличии, по его данным, и вовсе имеется не более 10 млрд долл., которыми можно свободно распоряжаться без угрозы для остальных направлений бизнеса этой весьма диверсифицированной компании.
Главная цель обновлённого Stargate вполне очевидна — закрепить и по возможности увеличить отрыв от КНР в области развития ИИ. Однако ажиотаж вокруг DeepSeek в последние дни января лишний раз напомнил, что сделать это — особенно в актуальных макроэкономических реалиях, когда единый прежде глобальный рынок зримо раскалывается на куски (а значит, сжимаются рынки сбыта американской продукции), а доверие к американскому доллару в мире падает (что потенциально ведёт к его обесценению) — будет крайне проблематично. Вот и аналитики Omdia напомнили , что материковый Китай демонстрирует потрясающие успехи в построении ИИ-ЦОД: «Если нынешний ритм будет поддерживаться, отставание от США в плане развития вычислительной инфраструктуры продолжит сокращаться — даже с учётом реализации проекта Stargate». Тем более что власти КНР уже предложили программу комплексного развития ИИ-инфраструктуры и сервисов, на которую в те же самые ближайшие пять лет запланировано направить сумму, эквивалентную примерно 138 млрд долл. Если эффективность этой инициативы окажется выше, чем у Stargate, примерно настолько же, насколько DeepSeek менее ресурсоёмка, чем GPT-4o, вариант «догнать и перегнать Америку по ИИ» вполне может быть китайскими товарищами реализован.

Сейчас хотя бы понятно, кто за кем результаты деятельности проверять должен, а что будет лет через десять? (Источник: ИИ-генерация на основе модели FLUX.1)
⇡#«Я вся такая внезапная!..»
Отчаянно много усилий прилагается ИИ-разработчиками к тому, чтобы как можно сильнее повысить безопасность генеративных моделей. Речь вовсе не о банальном запрете ботам излагать информацию, способную фрустрировать какие-то там маргинальные (или не очень) группы: если на ИИ действительно однажды возложат значимую долю (даже не большинство!) обязанностей по принятию действительно ответственных решений, цена его ошибок и галлюцинаций в этом случае окажется чрезмерно высока. Понятно, что всегда можно усадить рядом с аварийным рубильником компетентного специалиста — контролёра действий умной машины. Но ведь его тоже нужно где-то выучить, воспитать, дать набраться опыта; да и какой смысл заменять человека ботом, если к боту этому доверия нет? Вдобавок проверять решения, которые уже должны исполняться через считаные доли секунды после возникновения критической ситуации, наверняка будет попросту некогда. Поэтому логичнее сосредоточить усилия на «регулировке ИИ» — AI alignment — в надежде отыскать-таки однажды чудесное средство, избавляющее генеративные модели (хотя бы на наиболее серьёзных постах) от галлюцинаций. Пусть даже это будет сложное и дорогостоящее средство, вроде многократно и перекрёстно проверяющих логику действий друг дружки рассуждающих ИИ, — главное, чтобы надёжность его была гарантирована.
Увы, задача эта может оказаться в принципе не имеющей решения. Опубликованная под конец января в Scientific American статья-мнение Маркуса Арвана (Marcus Arvan), профессора философии из Университета Тампы, научные интересы которого сосредоточены в областях морального познания, рационального принятия решений и политического поведения, содержит неутешительный вывод: ИИ чересчур непредсказуем, чтобы достигать поставленных перед ним человеком целей . Все, наверное, обращали внимание на то и дело появляющиеся в новостных лентах курьёзные сообщения о галлюцинациях генеративных моделей: то разработанный Microsoft чат-бот Sydney принимается зло чудить в беседах с пользователями , то Copilot LLM уверяет собеседника в своей готовности «спустить с поводка свою армию дронов, роботов и киборгов» , то генеративная модель Sakana AI переписывает собственный код (в рамках специально созданной ради такого эксперимента рабочей среды, конечно, но всё же), чтобы избежать провала с решением выданного ей явно невыполнимого задания… Прошедшая научное рецензирование работа Арвана доказывает, что эти и многие подобные им случаи — не досадные недоразумения, вызванные какими-то в принципе устранимыми недоработками БЯМ, но проявления имманентно присущего самой природе генеративных языковых моделей свойства.
«Какие задачи мы ни ставили бы перед БЯМ, — утверждает исследователь, — мы никогда не можем быть уверены, „корректно“ (с нашей, человеческой точки зрения) или же „некорректно“ они эти задачи интерпретируют». Не можем, пока ИИ не начнёт плохо себя вести. Хуже того, любые попытки предварительно протестировать безопасность формируемых БЯМ выводов или принимаемых решений способны в лучшем случае создать ложную иллюзию того, что возможные проблемы сняты, поскольку языковая модель не «усваивает» некую истину или образ поведения на уровне научения или хотя бы дрессировки; она всякий раз решает поставленную перед ней задачу заново, сколько бы точно таких же попыток ранее ни предпринимала. В частности, заявления Anthropic о том, что ей удалось «картографировать разум» (to map the mind) своего ИИ, Маркус Арван отметает как бездоказательные, поскольку нейронная сеть таких моделей избыточно высокосвязна, так что изолировать отдельные концепции в её пределах физически невозможно, что и приводит в итоге к возникновению галлюцинаций буквально на ровном месте. Исследователь утверждает, что для формирования у искусственного интеллекта подлинно ответственного поведения необходимо применять те же методы, что и в ходе тренировки умных животных, — поощрение и наказание с весомым, имеющим для тренируемого серьёзные последствия подкреплением. Но такой подход потребует глубокой переработки самой архитектуры нынешних генеративных моделей — то есть новых немалых инвестиций и изрядного времени.

Вполне предсказуемая выдача по запросу «искусственный интеллект в банке» (источник: ИИ-генерация на основе модели FLUX.1)
⇡#У банкиров свои проблемы
Какой наиболее серьёзный вызов стоит перед всей отраслью искусственного интеллекта в наступившем 2025 году? Кто-то укажет в этой связи на турбулентность американских бирж после спровоцированного DeepSeek шока, что заставляет инвесторов перенаправлять средства в более стабильные активы — и тем самым снижает скорость развития этого рынка в целом. Кто-то упомянет не решённые до сих пор (а может, и в принципе нерешаемые) проблемы ИИ-галлюцинаций; кто-то — усиливающееся давление внедряемых в бизнес-процессы генеративных моделей на рынок труда. А вот для Марко Ардженти (Marco Argenti), директора по информационным технологиям Goldman Sachs — одного из становых хребтов глобальной (пока ещё) банковской системы планеты, — главным ИИ-вызовом нынешнего года представляется управление ИИ-агентами как наёмным персоналом . Ну в самом же деле: оцифровать и переложить все рабочие задачи на плечи БЯМ разом не удастся, — придётся, стало быть, биологическим и генеративным сотрудникам какое-то время сосуществовать. А менеджерам среднего звена, соответственно, — заботиться о поддержании здоровой атмосферы в таком гибридном коллективе, об оптимизации распределения заданий внутри него, о тренировке и даже карьерном росте наиболее выдающихся ИИ-агентов, вплоть до их увольнения с последующим перераспределением возлагавшихся на них задач, если да такого дойдёт! Ардженти считает, что с точки зрения высшего менеджмента (советов директоров) в 2025-м приоритетом окажется «ответственный ИИ», причём как раз в виде специализированных агентов, поскольку затраты на персонализированную тренировку «под заказчика» универсальных БЯМ для подавляющего большинства клиентов, даже если это не самые крупные банки, представляются запредельными. Интересно — особенно с учётом наметившегося курса на противостояние «плотных трансформерных» моделей и «ансамблей экспертов», — в какой мере будут соответствовать действительности эти предсказания к концу года?
________________
* Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»
Если Вы заметили ошибку — выделите ее мышью и нажмите CTRL+ENTER.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex