MWC 2018
MWC 2018 2018
2018 Computex
Computex
⇣ Содержание
|
Опрос
|
реклама
Самое интересное в новостях
Сводное тестирование ATi Radeon 9700 Pro
 Использованы материалы тестирования Anandtech и THG Уже многие годы мы относимся к ATi как к догоняющей компании - любой ускоритель, который они бы ни выпустили, затмевается конкурирующими продуктами от nVidia. Через месяц после первого запуска Radeon улучшенные драйверы Detonator3 дали GeForce2 GTS достаточный прирост производительности для получения лидирующего положения. И кто может забыть выпуск драйверов Detonator4 прямо перед выходом ATi Radeon 8500, которые значительно повлияли на соотношение производительности карт. Каждый раз при разговоре с представителями компании нас убеждали, что следующий выпуск будет отличаться от предыдущего, что в следующий раз они смогут обогнать nVidia, но, как мы видим, следующего раза так и не случалось. С выпуском GeForce4 nVidia очень сильно упрочила свое лидерство. Флагманский ускоритель ATi Radeon 8500 смог соревноваться только лишь с самой дешевой $200 Ti 4200, не говоря уже о том, что результаты Ti 4600 стали недосягаемы. Соответственно когда представители ATi начали говорить о том, что R300 будет существенно быстрее любых карт nVidia - верилось в это с трудом. Однако как вы увидите ниже, ATi наконец-то выпустила ускоритель, который не только является явным лидером по производительности, но он также обладает всеми DirectX 9 функциями, которые nVidia реализует только лишь в ноябре.
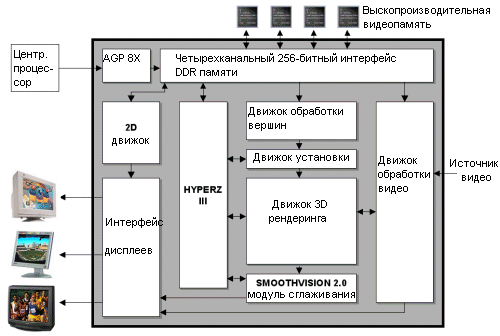
ATi ударила nVidia сразу на нескольких фронтах. На бюджетном сегменте линейке MX от nVidia придется конкурировать с ATi 9000 Pro, причем борьба будет тяжкая. Кроме выпуска чипа R300 и карты Radeon 9700 Pro, ATi провела презентацию нового 3D инструментария RenderMonkey, который вышел в июле в бета-версии на выставке SIGGRAPH. В отличие от предыдущих выпусков продуктов ATi, nVidia на сей раз не имеет в кармане никаких козырей для контратаки. Таинственный NV30, DX9 оружие nVidia, выйдет лишь через несколько месяцев. Так что гиганту из Санта-Клары придется пока что довольствоваться почетным вторым местом. Чип R300Наши предположения, высказанные на Computex, подтвердились, и R300 не только изготовляется по 0,15 мкм техпроцессу, но также обладает полной совместимостью с DX9. Подобная совместимость означает то, что конвейер R300 работает с числами с плавающей запятой по всему своему протяжению, от начала до конца. Такая функциональность значительно увеличивает число транзисторов чипа. Не забывайте, что чип оснащен восемью конвейерами рендеринга, так что в R300 мы получаем 110 млн транзисторов. И хотя 110 млн это меньше, чем в NV30, это больше, чем в любом сегодняшнем видеочипе. Скажем, в Matrox Parhelia используется "всего" 80 млн транзисторов, причем чип изготовляется по тому же 0,15 мкм техпроцессу.Одна из проблем, связанных с таким большим количеством транзисторов на 0,15 мкм чипе связана с размером - чип имеет очень большой размер. В свою очередь это приводит к трудностям с упаковкой и к низкому проценту выхода годных кристаллов. Чип R300 несет более тысячи ножек, больше, чем в будущем процессоре AMD ClawHammer. Частично такое большое число ножек обусловлено переходом на 256-битную шину памяти. К тому же немалое число выводов отведено под подачу энергии на различные участки массивного чипа. Из-за такого числа ножек ATi впервые стала использовать FC-BGA упаковку для видеочипа.
Как видим, чип внешне очень напоминает современные процессоры типа Pentium 3, Pentium 4 (без распределителя тепла) или Athlon XP. Преимущества FC-BGA упаковки заключаются в возможности разводки более 1000 ножек, равно как и в улучшенном охлаждении, что определенно необходимо для такого огромного чипа, работающего на столь высоких тактовых частотах. Следующая проблема заключается в выходе годных кристаллов. Для сохранения конкурентоспособности R300 его тактовые частоты должны быть, по крайней мере, равны GeForce4. nVidia смогла достичь 300 МГц на своем 0,15 мкм техпроцессе, но их чип имеет всего 63 млн транзисторов. В R300 же число транзисторов почти в два раза больше, при этом ATi нацелилась на частоты выше 300 МГц.
В соответствие со словами одного из инженеров ATi, компания смогла достичь столь высоких тактовых частот (учитывая, что 3DLabs и Matrox не смогли заметно превзойти 200 МГц) по причине отличного подхода к дизайну чипа. Инженеры компании вручную проработали различные участки чипа для достижения приемлемых тактовых частот при нормальном проценте выхода годных кристаллов. ATi уже определилась с финальными значениями тактовых частот, у Radeon 9700 Pro частота работы ядра составляет 325 МГц.
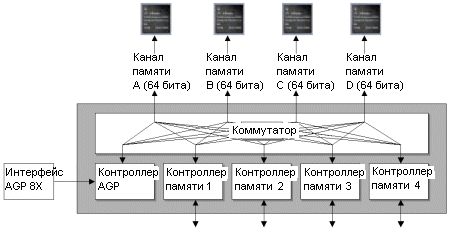
Как и Matrox Parhelia, R300 использует 256-битную DDR шину памяти, работающую с четырьмя раздельными 64-битными контроллерами памяти, почти как в перекрестной архитектуре памяти от nVidia. На Radeon 9700 Pro память работала на 325 МГц DDR (эффективное значение 620 МГц). ATi оговорила, что R300 может поддерживать DDR-II, но как мы думаем, для такой поддержки требуется некоторый редизайн контроллера памяти. Впрочем, мы еще поговорим о будущем R300 чуть позже...
Остальные спецификации R300 таковы:
Как видим, по сравнению с другими чипами R300 имеет впечатляющие технические спецификации. При количестве транзисторов от 100 до 110 миллионов (в разных документах ATi указывается разное значение), чип на 40 миллионов транзисторов больше GeForce4 Ti. Также на чипе присутствует четыре блока вершинных программ и восемь пиксельных конвейеров - в два раза больше флагмана nVidia. Однако последняя часть утверждения верна наполовину, поскольку пиксельные конвейеры R300 могут обрабатывать только одну текстуру за такт, по сравнению с двумя у GeForce4. Если говорить простым человеческим языком, то 9700 примерно в два раза быстрее GeForce4 при наложении одной текстуры. При использовании мультитекстурирования оба чипа примерно равны по скорости. По крайней мере, в теории. На практике же ни одна карта не может загрузить пиксельные конвейеры полностью - для 100% эффективности просто не хватает данных. Причина заключается в низкой пропускной способности памяти. Хотя она то у Radeon 9700 в два раза выше GeForce4 Ti. Трехмерный конвейер в R300Конвейер R300 на высоком уровне стандартен, но для поддержки будущих спецификаций DX9 ATi ввела некоторые улучшения в конвейер. Следует напомнить, что и R300, и NV30 будут совместимы с DX9, поэтому у них будет очень схожий конвейер.
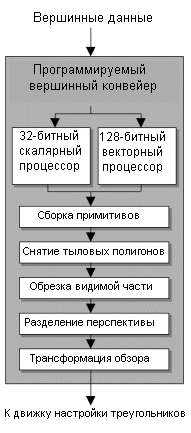
Мы постараемся вкратце пройти по каждой ступени конвейера, уделив особое внимание перспективам R300 и изменениям в конвейере, связанным с инновациями ATi. При возможности мы попытаемся провести аналогии с GeForce4 и с другими конкурирующими продуктами. AGP 8XПервая ступень 3D конвейера вполне очевидна и связана с отсылкой команд и данных для выполнения на графический чип. Инициатором отсылки является программное обеспечение, работающее на центральном процессоре. Данные и команды пересылаются по AGP шине и, в конце концов, достигают графического чипа.В R300 скорость передачи увеличена благодаря использованию интерфейса AGP 8X между видеочипом и северным мостом чипсета. Спецификация AGP 8X (AGP 3.0) предусматривает работу шины на 66 МГц с передачей восьми битов за такт. 32-битная шина AGP в режиме 8X обладает суммарной пропускной способностью 2,1 Гбайт/с. И хотя мы до сих пор вряд ли можем назвать ситуации, где бы жизненно необходима была даже AGP 4X, в увеличении скоростей передачи ничего плохого нет. R300 обратно совместим с AGP 4X, так что карту можно будет использовать в большинстве современных систем. GeForce4 и все конкурирующие решения сегодня основаны на интерфейсе AGP 4X, но к концу года мы наверняка увидим обновленные версии видеокарт с интерфейсом AGP 8X. ATi не была первой с AGP 8X картой, поскольку SiS уже стала пионером со своей Xabre. Однако не следует думать, что поддержка AGP 8X сразу же приведет к росту производительности. Обработка вершин - удвоенная скорость по сравнению с GeForce4Сейчас видепроцессор знает, какие данные ему нужны для обработки, и что с ними нужно сделать. Данные, посылаемые видеопроцессору, состоят из вершин полигонов, которые нужно отобразить на экране. Первую исполнительную ступень графического конвейера раньше часто называли T&L. На ней происходит трансформация вершинных данных, посланных графическому процессору, в 3D сцену. Ступень трансформации использует большое количество матричных вычислений с плавающей точкой. Затем происходит вычисление освещения для каждой из вершин. В программируемом видеопроцессоре начальный этап обработки вершин поддается программированию, то есть чип может запускать короткие вершинные программы (шейдеры), которые могут управлять различными характеристиками вершин для изменения формы, вида или поведения модели среди прочих вещей.
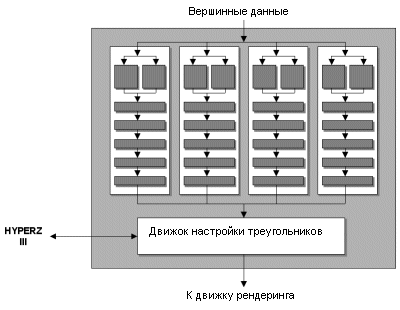
R300 использует четыре программируемых вершинных конвейера, почти как в Matrox Parhelia. Различие между R300 и Parhelia состоит в том, что R300 обладает намного более улучшенным движком настройки треугольников (triangle setup), поэтому если Parhelia и может похвастаться большими значениями пропускной способности вершин, то у нее в силу вступают ограничения движка настройки треугольников. Соответственно в играх с очень низким числом пропускаемых треугольников Parhelia не способна обогнать даже GeForce4 с меньшим числом вершинных конвейеров. Учитывая, что движок настройки треугольников у Parhelia не мощнее GeForce4, да и работает он на меньшей тактовой частоте, Parhelia не обладает достаточной мощью по обработке треугольников для загрузки своих вершинных конвейеров.
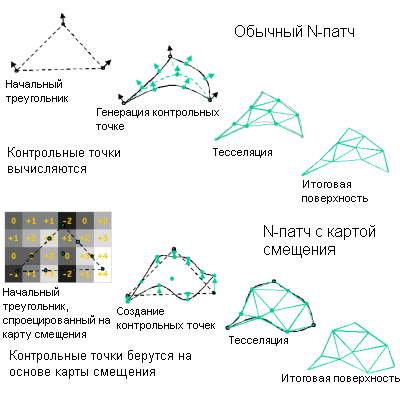
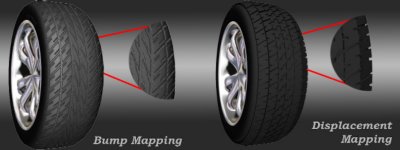
ATi решила данную проблему в R300, и чип способен обрабатывать более 300 млн треугольников в секунду (поскольку за такт обрабатывается одна вершина). Это более чем в два раза больше GeForce4 Ti 4600, что вполне логично, так как и число вершинных конвейеров у R300 тоже в два раза больше. Итак, мы видим первую область, в которой R300 демонстрирует свое превосходство. Здесь также работает технология ATi HyperZ, но мы рассмотрим ее отдельно чуть ниже. Поддержка вершинных программ 2.0R300 соответствует спецификации вершинных программ 2.0, что входит в Microsoft DX9. Параллельно с этим добавлена аппаратная поддержка карт смещения (Hardware Displacement Mapping). Как вы помните, эта технология была разработана Matrox и впервые она появилась в Parhelia. Хотя в настоящее время реальной надобности от нее нет, поскольку разработчикам требуется определенное время для ее применения.
ATi приводит хороший пример для демонстрации преимуществ карт смещения по сравнению с отображением неровностей dot3. Как вы можете наглядно увидеть, шина с картой смещений выглядит так, как будто бы она создана с помощью большей геометрии, однако на самом деле количество вершин не увеличивается.
Немаловажное преимущество спецификации 2.0 состоит в управлении потоком (flow control) и в увеличенном числе инструкций, которые могут быть выполнены за один проход. Управление потоком подразумевает, что вершинные программы сейчас могут содержать циклы, переходы и процедуры, что очень важно для обеспечения небольшого размера программ и их эффективности. Благодаря таким нововведениям можно избежать повторяющихся фрагментов кода, равно как и уменьшить число инструкций в программе. Преимущества управления потоком можно проиллюстрировать на следующем примере.
Без управления потоком программа будет выглядеть следующим образом. ...
С использованием же спецификации вершинных программ 2.0 тот же самый код можно уменьшить до двух строчек. for (x=0;x<5;x++)
Первая строчка инициализирует переменную X, увеличивает ее значение на 1 при каждом проходе цикла, а затем продолжает исполнять следующую команду до тех пор, пока значение X не станет равным 5.
Вершинные программы теперь могут состоять из 1024 инструкций (раньше было возможно только 128 инструкций), но это только теоретическое значение, поскольку циклы и переходы позволяют исполнять намного большее количество инструкций. Количество констант было увеличено до 256, и что важно, новые спецификации позволяют использовать цвет со 128-битной точностью (с плавающей точкой). Восемь пиксельных конвейеров рендеринга - эра DX9 начинаетсяОдна из причин лидерства nVidia заключается в том, что компания достаточно давно ввела архитектуру с четырьмя пиксельными конвейерами рендеринга. Это произошло в 1999 году, за два года до того, как ATi ввела четыре конвейера рендеринга в чипе R200 в августе 2001 года.
На сей раз, ATi оказалась первой компанией, оснастившей свой чип восемью 128-битными пиксельными конвейерами рендеринга с плавающей точкой. Довольно сильный шаг, учитывая, что в GeForce4 и Radeon 8500 используются четыре 64-битных пиксельных целочисленных конвейера рендеринга. Этим же можно объяснить и огромное число транзисторов в R300. ATi не только увеличила число пиксельных конвейеров рендеринга, но также удвоила точность и сделала переход к конвейеру, полностью работающему с числами с плавающей точкой для еще большего увеличения точности. Такой конвейер является обязательным требованием совместимости с DX9. Восемь конвейеров рендеринга дают R300 значительный отрыв по скорости заполнения от всех существующих карт, что также объясняет хорошую производительность R300. Скорость заполнения R300 на частоте 325 МГц равна 8*325 = 2600 Мпикселей/с. Каждый пиксельный конвейер рендеринга оснащен одним текстурным блоком, так что скорость заполнения при мультитекстурировании не будет отличаться. Может показаться, что один текстурный блок на конвейер - это слишком мало, но давайте посчитаем требования к пропускной способности памяти при существовании восьми параллельных конвейеров с одним текстурным блоком и обработке трилинейной 32-битной текстуры: 32 бита * 8 (трилинейная фильтрация требует чтения 8 текселей) * 8 (восемь конвейеров) = 2048 бит. То есть за один такт должно быть считано 2048 бит. Однако 256-битная DDR шина дает нам только 512 бит за такт. Даже билинейная фильтрация потребует 1024 бит за такт. Так что два текстурных блока на конвейер никогда не смогут получить достаточную пропускную способность памяти. Поэтому их и нет.
Каждый пиксельный конвейер Radeon 9700 Pro может независимо выполнять пиксельную программу. В соответствии со спецификацией пиксельных программ 2.0, они могут состоять из 160 инструкций. Каждая программа может осуществлять до 32 операций семплирования текстур с использованием до 16 различных текстурных карт и дополнительно 64 цветовые операции за проход. Количество тактов на проход, конечно же, может быть разным. Оно может достигать довольно больших значений, особенно при параллельном использовании анизотропной фильтрации. Полный переход к конвейеру с плавающей точкой позволит достичь 3D графике еще большей точности. Для подтверждения этого тезиса рассмотрим общий случай, когда число с плавающей точкой передается целочисленному конвейеру. Предположим, на целочисленный конвейер пересылается число 10.0523432543890, при этом оно округляется до целого. Если вы создаете какую-то примитивную картинку, то потеря точности никакой проблемы не создаст, однако если вам требуется фотореалистичное изображение, то подобные ошибки округления могут свести всю реалистичность на нет.
Так что в следующем году уже можно ожидать действительно реалистичных эффектов от ускорителей. Поддержка пиксельных программ 2.0R300 поддерживает спецификацию пиксельных программ Microsoft версии 2.0, что опять же включено в DX9. Во второй версии сделано множество улучшений, которые проиллюстрированы следующей таблицей.
Обратите внимание, что новая спецификация пиксельных программ поддерживает 16 текстурных входов. В результате мы получаем возможность накладывать 16 текстур за проход, что несколько отличается от шести в GeForce4 и Radeon 8500. Если посмотреть на использование такого количества входов на грядущих играх, то Doom3, к примеру, будет использовать пиксельные программы с пятью-шестью текстурными входами, которые R300 может выполнять за один проход. Однако следует отдать должное и некоторым DX8 решениям, которые смогут выполнять то же самое за один проход, так что у R300 есть еще место для более полного использования возможностей ускорителя. Спецификация пиксельных программ 2.0 также предусматривает более гибкие операции, увеличивающие программируемость чипа. R300 может выполнять до 160 пиксельных инструкций за проход, большее же число инструкций потребует нескольких проходов. На сегодняшний день подобная программируемость наиболее востребована в приложениях 3D рендеринга. На R300 (равно как и на других будущих DX9 ускорителях) можно будет компилировать и исполнять код (к примеру, код 3D Studio Max или RenderMan) на самом ускорителе. Сегодня рендеринг выполняется целиком центральным процессором, однако с должной программной поддержкой скорость рендеринга может быть увеличена.
Возможность обрабатывать 160 инструкций за проход крайне полезна в 3D рендеринге, поскольку самые сложные 3D вычисления сейчас можно выполнять за один проход. Согласитесь, намного интереснее высчитывать сцену в 3D Studio Max на скорости 0,1 fps, а не ждать, пока центральный процессор выведет один кадр за 10 минут. И вновь здесь возникает потребность в использовании конвейера с плавающей точкой, так что и R300, и NV30 будут поддерживать указанные нами функции. Одним из самых интересных применений такого конвейера является качественное освещение, которое жизненно необходимо для реалистичных сцен. На сегодняшний момент даже качественные 3D игры все еще далеки от реализма, и свою роль в этом играют не только текстуры с низким разрешением и малое число полигонов, но и недостатки освещения. Итак, конвейер с плавающей точкой позволяет улучшать точность освещения. На старом 32-битном целочисленном конвейере каждое значение RBGA ограничивалось 8-ю битами, или 256-ю различными значениями. Ниже вы видите очень сложную сцену, для которой мы желаем изменить яркость.
Проблема 256-ти различных цветов заключается в том, что при повышении яркости всех цветов в 64 раза, самые яркие цветовые участки сцены будут ограничены 8-битным представлением. В результате, несмотря на то, что общая яркость сцены повысилась, пропорциональное отношение яркости различных участков не сохранилось.
То же самое относится и к уменьшению яркости. Если мы уменьшим яркость в 64 раза, то все станет очень темным. Даже если все в комнате стало темным, то источники света не должны были стать настолько темными.
Теперь давайте взглянем на ту же сцену, но с использованием цветов с плавающей точкой для отражения большего диапазона уровней яркости.
Теперь вместо 256-ти значений на цвет, каждый цвет представлен, фактически, бесконечным числом оттенков, что дает действительно огромный динамический диапазон яркости. Постараемся объяснить это несколько более подробно. Как мы уже сказали, 32-битное представление цвета дает по восемь бит на каждый цветовой канал из трех, оставшиеся восемь бит расходуются на значение прозрачности альфа. Соответственно мы можем указывать значение каждого цвета от 0 до 255. Такой цвет не назовешь динамическим, поскольку он имеет всего 255 дискретных значений. С таким цветом уже давно борются разработчики, поскольку им нужен как очень темный цвет, так и очень светлый. Для таких цветов недостаточно значений от 1 до 255. В компьютерном мире существует два различных способа работы с числами. Легче всего, конечно же, понять целые числа, которые хранятся "как они есть". Числа с плавающей точкой представлены по-другому. В данном случае число состоит из бита знака, нескольких бит экспоненты и довольно много бит отводится под мантиссу. Формула числа получается x = m*2e , где x - число, m - мантисса, а e - экспонента. Как вы можете заметить, минимальное и максимальное число указывается с помощью экспоненты, в то время как мантисса определяет точность. В случае 128-битного числа с плавающей точкой, каждый цветовой канал имеет 32-битную точность и состоит из 1 бита знака, 8 бит экспоненты (7 бит плюс знак) и 23 бит мантиссы. В результате мы получаем числа диапазона от 0,00000000000000000000000000000000000000294 (=2-128) до 170 000 000 000 000 000 000 000 000 000 000 000 000 (=2127) . Учитывая 23-битную мантиссу, мы получаем большую точность, нежели 8 бит. Приведем также еще несколько наглядных примеров, показывающих превосходство цвета с повышенной точностью.
С левой стороны картинки вы видите сцену в 32-битном цвете, а справа вы можете заметить значительное увеличение качества в силу использования 128-битного цвета с плавающей точкой. ATi показала демонстрацию машины с низким числом полигонов, которая была улучшена с помощью dot3 с использованием 64-битной карты нормалей. Такое качество попросту было недостижимым при использовании 32-битных карт нормалей.
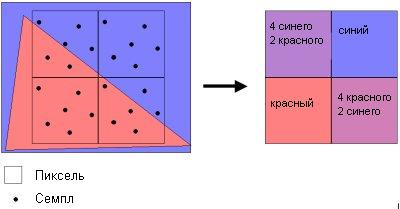
К сожалению, 128-битный цвет требует в четыре раза большую пропускную способность, нежели 32-битный цвет. К счастью, пропускная способность памяти уже давно к этому готовилась. Остается добавить, что DX9 также поддерживает технологию нескольких целей рендеринга (Multiple Render Targets, MTR), которая позволяет назначать несколько объектов на сцене для пиксельной программы. Подобный метод будет крайне полезен для сложных пиксельных программ. То есть вместо прогона программы для каждого объекта сцены, можно использовать MRT для сокращения числа прогонов. SmoothVision 2.0 - мультисемплингКогда только вышел Radeon 8500, нас очень разочаровало сглаживание SmoothVision, базировавшееся на алгоритме суперсемплинга, в то время как nVidia уже начала использовать алгоритм мультисемплинга.Мы уже объясняли раньше алгоритм суперсемплинга ATI (RGSS), который создает несколько копий сцены и сдвигает их на некоторое расстояние относительно центра. Затем эти копии накладываются друг на друга для получения окончательной картинки. Такой подход приводит к великолепному разрешению текстур и в то же время он позволяет избавиться от "лесенок", однако он очень сильно ударяет по производительности, поскольку нужно отрисовывать сцену несколько раз. Мультисемплинг, с другой стороны, работает на основе значений Z (глубина) для каждого пикселя. В зависимости от степени покрытия каждого пикселя вычисляется усредненное значение между цветами заднего и переднего участков, которое затем и используется. Преимущество такого подхода заключается в том, что вам не нужно создавать несколько копий сцены, зато при этом теряется разрешение текстур, и производятся дополнительные обращения к Z-буферу. Алгоритм мультисемплинга R300 отличается от алгоритма nVidia, поскольку семплы саб-пикселей здесь другие. Ниже показан фрагмент при 6x сглаживании ATi.
Кроме того, SmoothVision 2.0 поддерживает еще одну функцию - патентованный алгоритм гамма-коррекции, который обеспечивает точность передачи цветовых градиентов при сглаживании. Многие мониторы имеют нелинейный градиент гаммы, что учитывается алгоритмом коррекции ATi.
Нам посчастливилось посмотреть на демонстрацию колеса со спицами на Radeon 9700 Pro и параллельно на GeForce4, причем обе карты работали с 4X сглаживанием. На Radeon 9700 Pro колесо выглядело на порядок лучше.
R300 поддерживает и суперсемплинг и мультисемплинг (R200 поддерживал только суперсемплинг), однако в драйверах вы можете выбрать только мультисемплинг. Впрочем, это может измениться к моменту выхода карты. Как мы уже упомянули выше, мультисемплинг увеличивает число обращений к Z-буферу, но поскольку R300 использует сжатие Z, эти обращения не сильно съедают пропускную способность. В технической документации ATi указывает степень сжатия на уровне 50-75% благодаря использованию HyperZ III. У нас не было много времени для доскональной оценки алгоритма сглаживания ATi, но как заявляет компания, он будет обладать лучшим качеством, нежели алгоритм nVidia, в ситуациях, где используются прозрачные текстуры. Лучшим примером может служить уровень DM-Antalus в UT2003, где великолепная трава является ничем иным, как текстурой с высоким разрешением и прозрачностью, в результате чего вы можете видеть сквозь нее. Как считает ATi, алгоритм мультисемплинг-сглаживания от nVidia будет попросту игнорировать "лесенки" по краям этого полигона в силу их прозрачности, а R300 не будет. Через несколько недель мы постараемся более подробно рассмотреть эту ситуацию в отдельной статье.
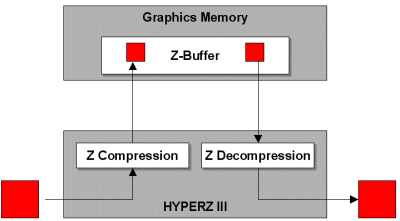
Исправленная анизотропная фильтрацияВ R300 исправлена еще одна проблема, досаждающая в R200 и связанная с анизотропной фильтрацией. В Radeon 8500 ATi ввела алгоритм адаптивной анизотропной фильтрации, который определяет число семплов, которое нужно отфильтровать на основе положения семпла по осям X и Y по отношению к пользователю. В результате в ситуациях, где необходим максимальный уровень анизотропии, ускоритель берет максимальное количество семплов, указанное в драйвере (16X максимум).Единственная проблема с алгоритмом ATi заключается в отсутствии обработки поворотов по осям X, Y и Z. В большинстве случаев при повороте вдоль оси Z чип будет применять минимальный метод фильтрации - билинейный, который не слишком то хорошо выглядит. R300 не только поддерживает трилинейную фильтрацию вместе с анизотропной, но также в нем была исправлена ошибка с Z-поворотом. Мы уже давно подстрекаем nVidia к применению такой же формы анизотропной фильтрации, поскольку различия в качестве картинок между адаптивным алгоритмом ATi и подходом nVidia пренебрежимо малы в большинстве случаев, зато алгоритм ATi наносит меньший урон по производительности. В соответствии с данными ATi, производительность R300 не будет падать вообще при включении билинейной и 16X анизотропной фильтрации, и лишь небольшое падение производительности будет наблюдаться при включении трилинейной фильтрации. Отметим, что раньше nVidia жаловалась на то, что при включении анизотропной фильтрации ATi берет билинейные семплы, а nVidia - трилинейные, съедающие в два раза большую пропускную способность памяти. Сейчас же у Radeon 9700 Pro появилась возможность включить либо "производительную" анизотропную фильтрацию (с билинейной), либо "качественную" (с трилинейной). Так что nVidia будет довольна. HyperZ IIIATi стала первой компанией, внедрившей технологию отсечения невидимых полигонов, которую они назвали HyperZ. В R300 используется третье поколение HyperZ, которая отличается от HyperZ II ускоренными версиями всех трех компонент.ATi не слишком подробно указывает улучшения HyperZ III, поэтому, как нам кажется, HyperZ III работает быстрее по причине более высокой тактовой частоты R300, внедрением "ранней Z" (объяснено чуть ниже) и, возможно, увеличением числа пикселей, которые компонента "иерархия-Z" может отбрасывать в один момент времени. Вкратце напомним состав и функциональность HyperZ III: Технология ATi HyperZ состоит из трех функциональных компонент, работающих совместно друг с другом для оптимизации использования пропускной способности памяти. Три компоненты - это Иерархия-Z (Hierarchical-Z), Z-сжатие (Z-Compression) и быстрая Z-очистка (Fast Z-Clear). Ниже мы рассмотрим каждую из этих компонент, равно как и их влияние на производительность. Следует также напомнить, что HyperZ разделяет кадровый буфер и Z-буфер на блоки 8x8 пикселей, с которыми намного более удобно работать. Сейчас давайте вспомним некоторые основы традиционного 3D рендеринга. Z-буфер - это часть памяти, которая отводится под хранение значений координаты Z выводимых пикселей. Значения Z определяют, какой пиксель, и какой полигон будут выведены перед другими на экране. Традиционный 3D ускоритель обрабатывает каждый принятый полигон, без учета его положения относительно сцены. Следовательно, каждый выводимый полигон будет освещен и текстурирован. Z-буфер, как мы уже упоминали, используется для хранения значения глубины каждого пикселя в "заднем" буфере. Каждый пиксель каждого полигона должен быть проверен через Z буфер на предмет того, находится ли он ближе к наблюдателю, чем другой пиксель, уже хранящийся в буфере. Проверка Z-буфера должна быть проведена уже после того, как пиксель будет освещен и текстурирован. Если пиксель должен выводиться перед существующим пикселем, то новый пиксель замещает (или смешивается, при условии прозрачности) текущий пиксель в "заднем" буфере, а глубина Z-буфера для данного пикселя изменяется. Если новый пиксель выводится позади текущего пикселя, то новый пиксель отбрасывается и никаких изменений "заднего" буфера не происходит (или опять же происходит смешение двух пикселей). Если подобные бесполезные пиксели все же будут выводиться на экран, то такой дефект называется "перерисовкой" (overdraw). Скажем, в некоторых ситуациях типичной является перерисовка трех пикселей. Как только сцена заполнится, "задний" буфер переносится в "передний" буфер для вывода на монитор. Только что мы описали способ, известный как "прямое отображение" (immediate mode rendering), подобный способ используется со времен 60-х годов для рендеринга в системах CAD, архитектурных программах, приложениях по созданию спецэффектов и сегодня - в большинстве видеоускорителей. К сожалению, такой метод приводит к большому проценту перерисовки, когда обрабатываются даже невидимые объекты.
И хотя R300 не использует мозаичный рендеринг, он все же применяет некоторые методы отложенного рендеринга для увеличения использования пропускной способности памяти. Из приведенного выше примера вы можете легко догадаться о том количестве обращений к Z-буферу, которые требуются для вывода одной сцены. ATi HyperZ увеличивает эффективность этих обращений, так что вместо предотвращения корня проблемы (перерисовки), ATi уменьшает негативные последствия - частые обращения к Z-буферу. Первой компонентой HyperZ является Иерархия-Z, которая позволяет ускорителю проверять Z-буфер для данного пикселя еще до того, как пиксель попадает на конвейер рендеринга. В результате ненужные пиксели отбрасываются на ранней стадии, перед тем, как R300 начнет их обрабатывать. В R300 добавлена технология "ранняя-Z" (Early-Z), которая подразделяет Z-буфер на уровне пикселей, так что карта достигает близкой к 100% эффективности при отбрасывании перекрытых пикселей. Иерархия-Z использует флаг для каждого из 8x8 блоков Z-буфера. Флаг содержит минимальное значение Z, из всех значений Z данного блока. Затем значение Z пикселя, поступившего из движка настройки треугольников, сравнивается со значением флага данного блока. Если значение Z поступившего пикселя меньше значения флага, то пиксель отбрасывается, и блок не читается из Z-буфера в кэш. Если же значение Z у пикселя больше значения блока, то блок считывается из Z-буфера в кэш, по пути проходя через Z-декомпрессию.
Затем следует Z-сжатие. Как говорит название, потери данных при этом не происходит. Z-сжатие компрессирует значение Z у пикселей блока с коэффициентом от 2:1 до 4:1 перед передачей блоков в Z-буфер, что заметно экономит пропускную способность памяти.
Последняя компонента HyperZ - быстрая Z-очистка, которая позволяет быстро очищать Z-буфер после полного отображения сцены. Кстати, метод очистки Z-буфера у ATi значительно быстрее методов конкурентов. Быстрая Z-очистка изменяет только лишь флаг для каждого блока, ускоряя процесс очистки.
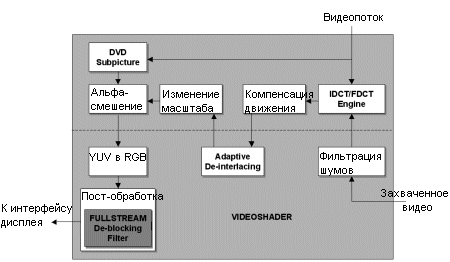
Как мы уже упоминали выше, технология ATi HyperZ III как нельзя более полезна при улучшении производительности сглаживания по причине Z-сжатия. В случае 6X сглаживания сжатие Z (равно как и сжатие цвета) может достигать значения 1:24. Обработка видео через 3D конвейерЕще одной впечатляющей возможностью R300 является обработка видеопотока через 3D конвейер вместо стандартного пропускания через DAC. Благодаря такой способности не только отпадает необходимость проигрывать видео через оверлей, но появляется возможность выводить на экран несколько видеопотоков.Как и в RV250, R300 поддерживает технологию FULLSTREAM.
Возможность запускать пиксельные программы при выводе видеопотока (Videoshader) открывает новые возможности, и ATi FULLSTREAM является одной из реализаций данной технологии. При должной программной поддержке (на сегодня это только RealPlayer), FULLSTREAM поможет устранить артефакты высоких степеней сжатия на потоках с низким битрейтом. Как видим, после обработки получается несколько размытая картинка, зато блоков уже почти не заметно.
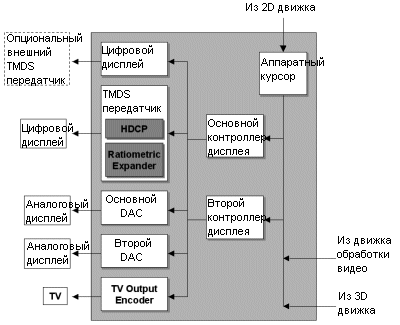
Как видим, использование пиксельных программ позволяет карте выполнять великое множество функций без специального видеочипа. Мы еще более подробно остановимся на функциях R300 и нового чипа ATi Rage Theater осенью, когда ATi выпустит R300 версию All-in-Wonder Radeon. Выход на дисплеиВ Parhelia Matrox уже реализовала цветовую точность 10/10/10 бит, которая позволит получить более качественные цвета на выходе. Обычный 32-битный цвет использует только 24 бита для цветовой информации, в то время как оставшиеся 8 бит не используются для вывода на ЭЛТ или ЖК монитор. Radeon 9700 Pro также может использовать 10 бит точности на каждый цветовой канал, что дает 1024 различных уровня красного, зеленого и синего вместо 256 уровней. От этого выиграют, прежде всего, аналоговые устройства вывода, а вот как к дополнительным двум битам отнесутся ЖК мониторы пока что предположить трудно.Итак, Radeon 9700 Pro оснащен двумя встроенными 400 МГц RAMDAC с 10-ю битами на канал для вывода на ЭЛТ и одним встроенным 165 МГц TMDS передатчиком для ЖК мониторов. Встроенный ТВ-выход поддерживает форматы NTSC/PAL/SECAM с разрешением вплоть до 1024x768.
⇣ Содержание
Если Вы заметили ошибку — выделите ее мышью и нажмите CTRL+ENTER.
Материалы по теме
|
© 1997—2025 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews. kz
![]()
![]()