







 MWC 2018
MWC 2018 2018
2018 Computex
ComputexКомпания NVIDIA опубликовала свежие данные о производительности своих ИИ-ускорителей H100, сравнив их с недавно представленными ускорителями Instinct MI300X от компании AMD. Этим сравнением NVIDIA решила показать, что на самом деле H100 обеспечивают более высокую производительность по сравнению с конкурентом, если использовать правильную программную среду для ИИ-вычислений. Компания AMD этого не учла в своём сравнении ускорителей, посчитали в NVIDIA.

Источник изображения: Wccftech
Во время презентации Advancing AI компания AMD официально представила специализированные ускорители вычислений для ИИ Instinct MI300X и сравнила их в различных бенчмарках и тестах с ускорителями H100 от NVIDIA. В частности, AMD заявила, что один ускоритель MI300X обеспечивает на 20 % более высокую производительность по сравнению с одним ускорителем H100, а сервер из восьми MI300X до 60 % быстрее сервера из восьми H100. NVIDIA опубликовала заметку на своём сайте, в которой утверждает, что эти заявления далеки от правды.
Ускорители вычислений NVIDIA H100 были выпущены в 2022 году и с тех пор получили различные улучшения на уровне программного обеспечения. Например, наиболее свежие улучшения, связанные с программной средой для ИИ-вычислений TensorRT-LLM позволили ещё больше повысить производительность H100 в рабочих нагрузках, специфичных для искусственного интеллекта, а также провести оптимизацию на уровне ядра. Всё это, по словам NVIDIA, позволяет чипам H100 эффективнее работать с такими большими языковыми моделями, как Llama 2 с 70 млрд параметров с использованием операций FP8.
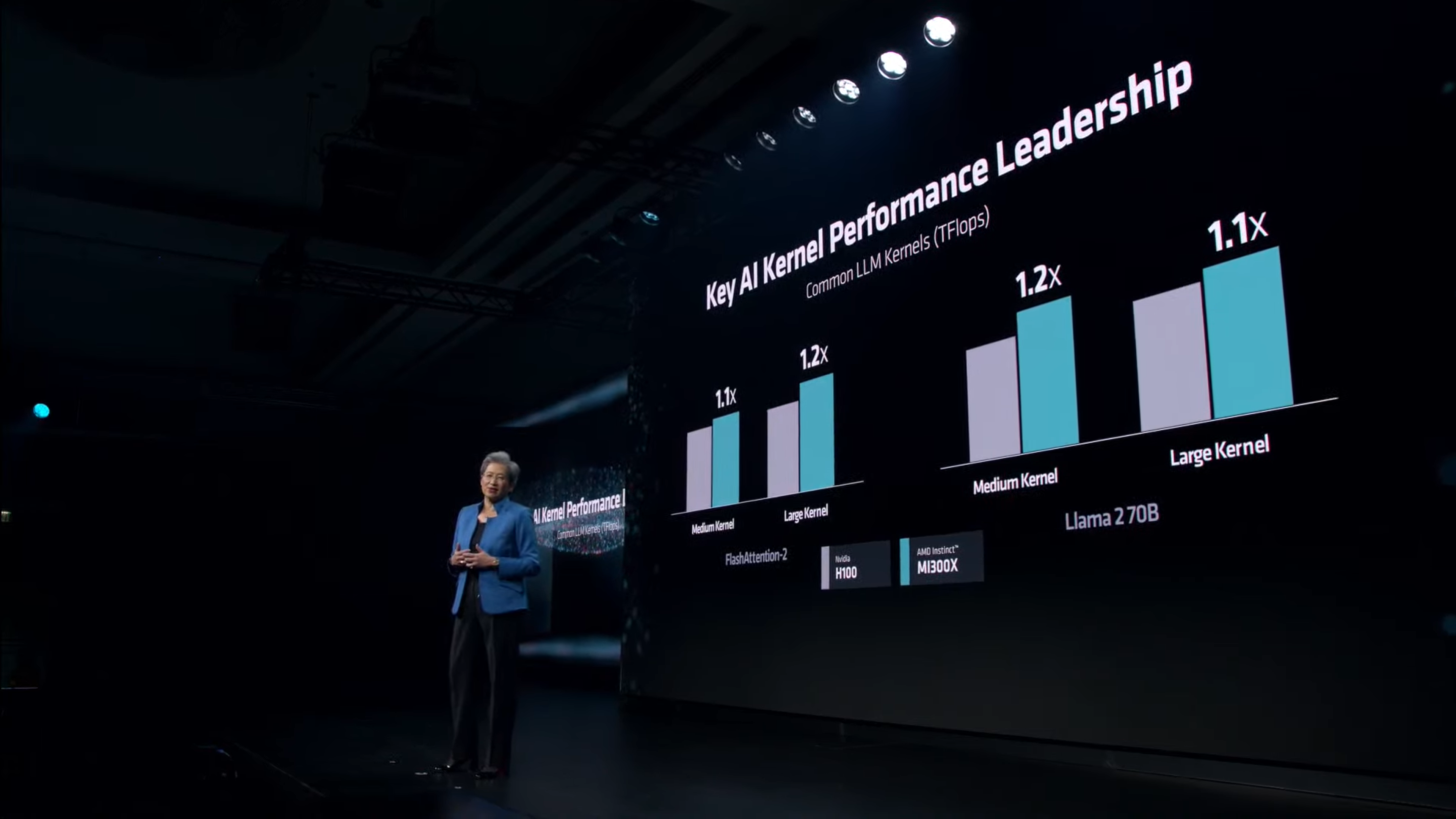
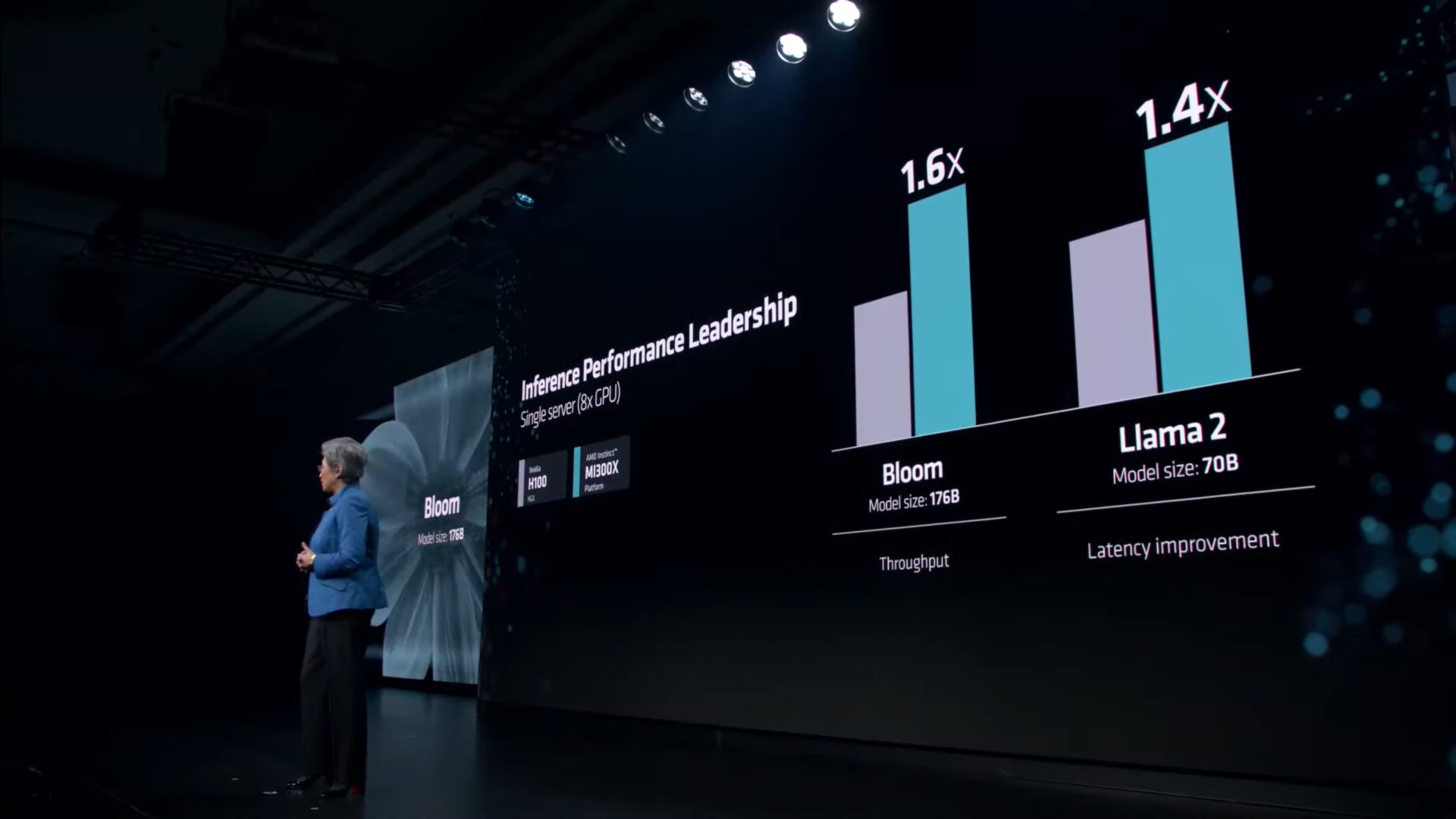
Сама AMD в своей презентации утверждала, что Instinct MI300X до 20 % быстрее H100 в Llama 2 70B, а также система из восьми ускорителей AMD обеспечивает превосходство по задержке на 40 % по сравнению с системой на восьми NVIDIA H100 в той же нейросети. Превосходство в операциях FP8 и FP16 составляет 30 % в пользу MI300X.
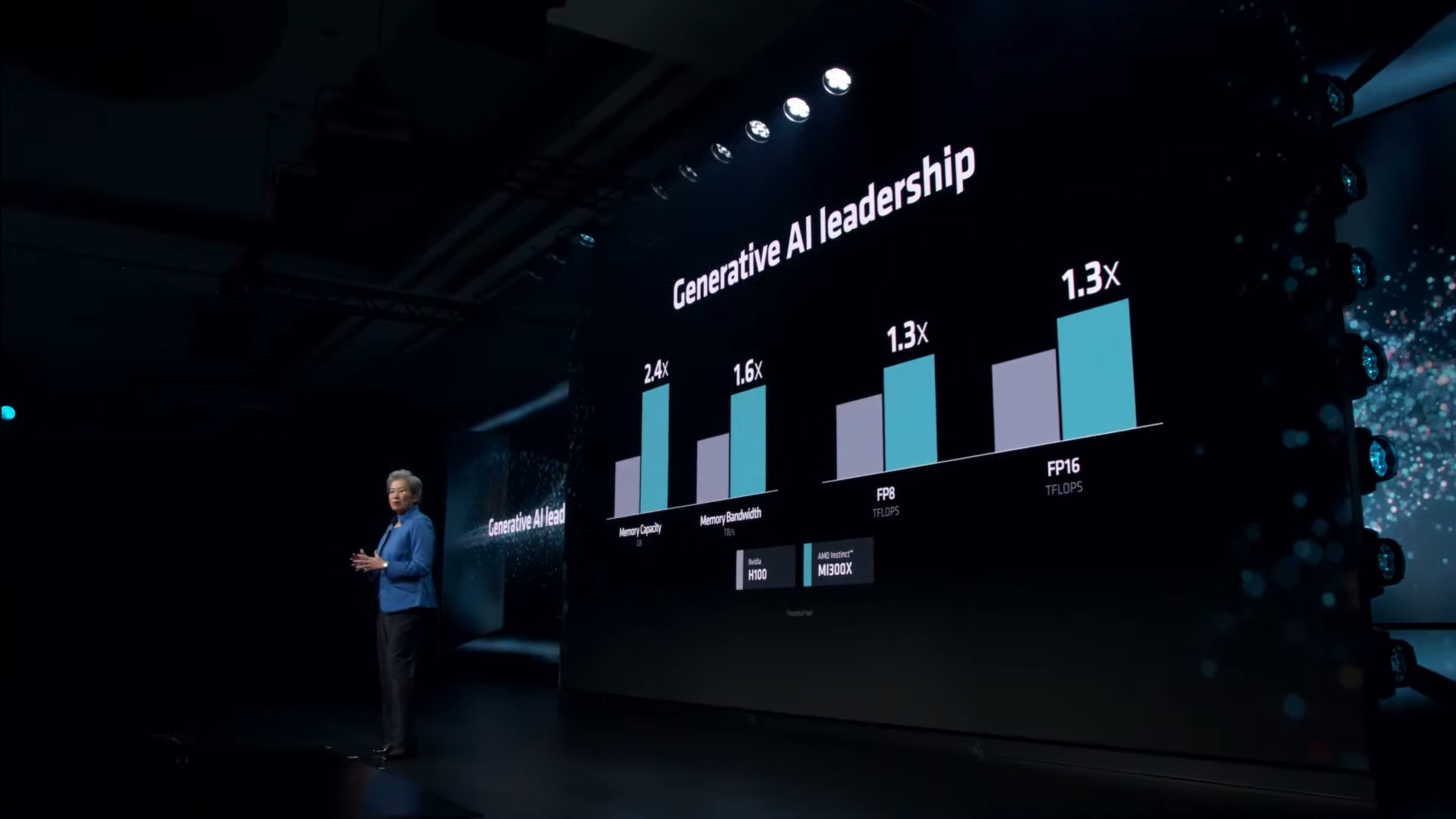
AMD проводила тесты своих ускорителей MI300X с использованием оптимизированных библиотек программной среды вычислений ROCm 6.0. Однако для NVIDIA H100 использовались данные без учёта применения оптимизированной программной среды TensorRT-LLM, предназначенной для этих задач. В свежей статье NVIDIA привела актуальные данные производительности одного DGX-сервера из восьми H100 в модели Llama 2 70B с учётом обработки одного программного пакета (Batch-1).
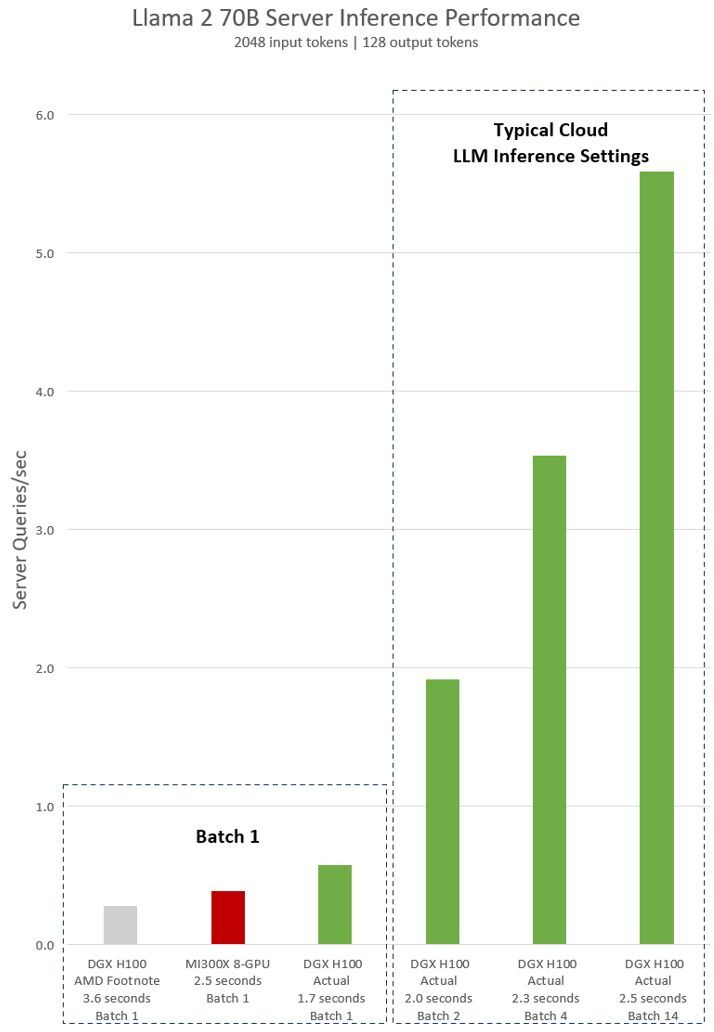
Источник изображения: NVIDIA
NVIDIA поясняет, что выводы AMD (серым и красным на графике выше) о превосходстве над H100 основаны на данных, представленных в сноске #MI300-38 к презентации AMD. Для их получения использовалась система NVIDIA DGX H100, фреймворк vLLM v.02.2.2 и модель Llama 2 70B с длиной входной последовательности 2048 и длиной выходной последовательности 128. NVIDIA отмечает, что в AMD сравнили систему из восьми MI300X с системой DGX H100 из восьми H100.
В свою очередь данные NVIDIA показаны на графике зелёным. Для их получения применена система DGX H100 из восьми NVIDIA H100 с 80 Гбайт памяти HBM3 в каждом, а также находящийся в открытом доступе фреймворк NVIDIA TensorRT-LLM v0.5.0 для расчёта Batch-1 и версии v0.6.1 для расчёта задержки. Рабочая нагрузка такая же, как указано в сноске AMD #MI300-38.
Приведённые NVIDIA результаты показывают, что сервер DGX H100 вдвое быстрее при использовании оптимизированных фреймворков, чем заявляет AMD. Кроме того, сервер с восемью H100 до 47 % быстрее системы с восемью AMD MI300X.
«Система DGX H100 способна обработать один инференс-запрос размером в один пакет (Batch-1) или иными словами, один запрос вывода за раз, за 1,7 секунды. Запрос уровня Batch-1 обеспечивает максимально быстрый показатель времени отклика для обработки модели. Для оптимизации времени отклика и пропускной способности ЦОД облачные сервисы устанавливают фиксированное время ответа для конкретной задачи. Это позволяет операторам ЦОД объединять несколько запросов на вывод в более крупные “пакеты” и увеличивать общее количество выводов сервера в секунду. Стандартные отраслевые тесты вроде MLPerf также измеряют производительность с помощью этого фиксированного показателя времени отклика», — продолжает NVIDIA.
В NVIDIA поясняют, что небольшие компромиссы в вопросе времени отклика системы могут привести к увеличению количества запросов на вывод, которые сервер может обработать в реальном времени. Используя фиксированный бюджет времени отклика в 2,5 секунды, сервер DGX H100 с восемью графическими процессорами может обработать более пяти инференс-запросов Llama 2 70B за раз.
Источники:






 Обзор Ryzen 5 8600G: новый король бюджетных сборок (нет)
50
Обзор Ryzen 5 8600G: новый король бюджетных сборок (нет)
50
 OpenAI представила ИИ-модель GPT-4o — она гораздо умнее старых версий и будет доступна бесплатно
27
OpenAI представила ИИ-модель GPT-4o — она гораздо умнее старых версий и будет доступна бесплатно
27
 Учёные случайно создали конденсатор, который можно зарядить в 19 раз сильнее обычного
25
Учёные случайно создали конденсатор, который можно зарядить в 19 раз сильнее обычного
25
 Представители британской прессы заявили, что нововведения Apple iOS оставят их без средств к существованию
21
Представители британской прессы заявили, что нововведения Apple iOS оставят их без средств к существованию
21
 Подписаться
Подписаться