







 MWC 2018
MWC 2018 2018
2018 Computex
Computex
⇣ Содержание
|
Опрос
|
реклама
Самое интересное в новостях
Практикум по ИИ-рисованию, часть двенадцатая: быстрое прототипирование с FLUX.1 [dev]
Главное затруднение с FLUX.1 [dev] с точки зрения владельца бюджетного ПК — это невозможность уместить в видеопамять соответствующую UNet-модель (хотя в данном случае она, строго говоря, не UNet, как у SD 1.5 и SDXL, а DiT — diffusion transformer, но так уж устоялась терминология) целиком, если только не прибегать к совсем уж немилосердному сжатию/квантованию её весов, — о чём мы упоминали в предыдущей «Мастерской». Казалось бы, вот и выход: задействуем вместо базовой UNet/DiT в кодировке FP16 или даже GGUF Q8_0 значительно более компактный вариант, отыщем с его помощью подходящую композицию, закрывая глаза на неизбежные огрехи детализации, а потом уже исполним заново циклограмму с теми же самыми подсказкой и затравкой, но с не так сильно пережатой моделью. Сработает ведь? 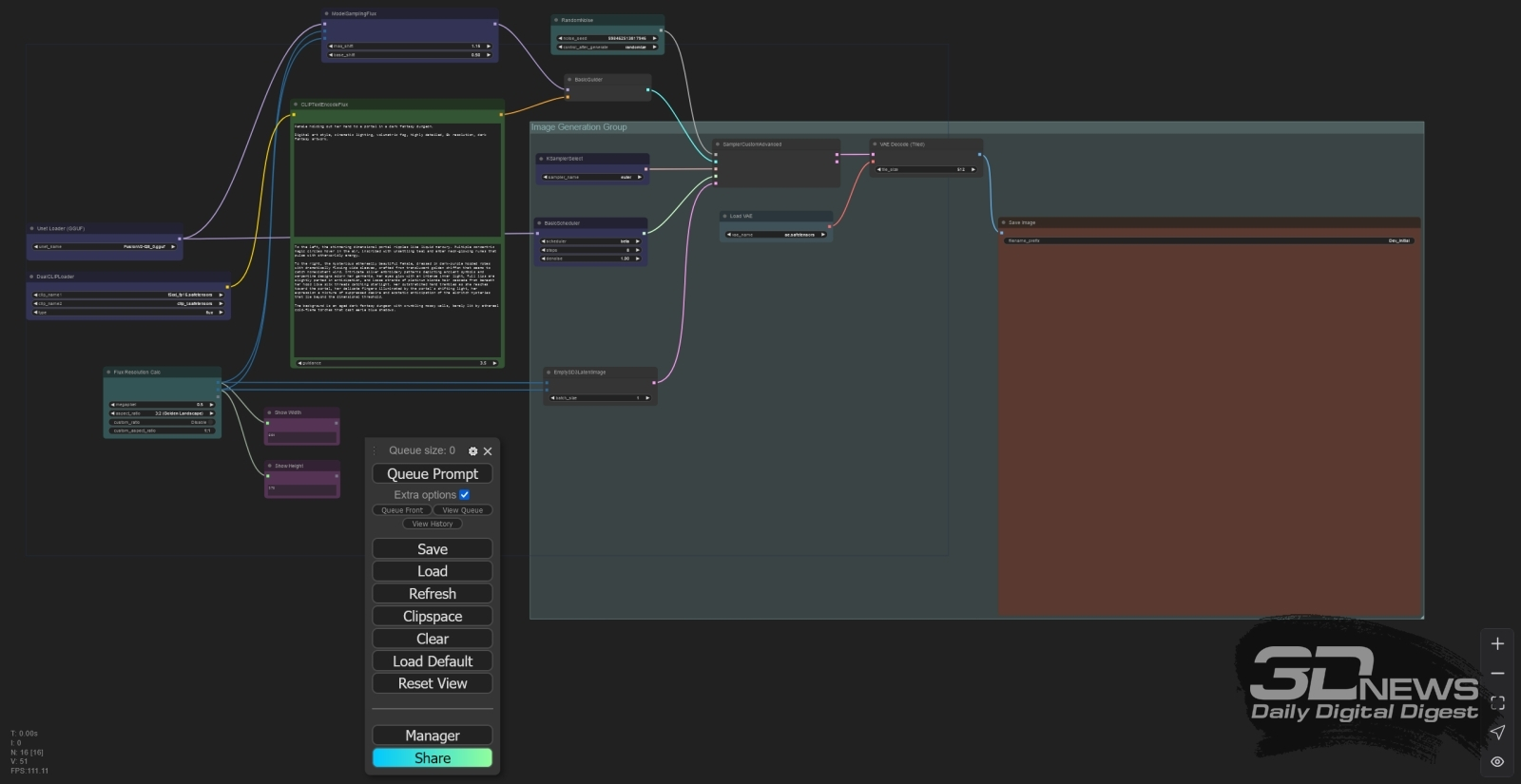
Рабочее поле ComfyUI с базовой циклограммой, с которой мы будем в основном взаимодействовать на сей раз ⇡#Вы рисовать умеете?Напомним на всякий случай, что модели семейства FLUX.1 мы рассматриваем уже в третий раз подряд, и все сведения по их, а также нашей стандартной (на данный момент) рабочей среды ComfyUI развёртыванию на локальном ПК приводили уже в предыдущих статьях, равно как и информацию о квантовании весов ИИ-моделей по методу GGUF. Скачаем ради эксперимента из репозитория GGUF-квантованных UNet/DiT для FLUX.1 ещё три модели, а именно:
Они дополнят уже имеющуюся у нас с прошлого раза в подкаталоге ComfyUI\models\unet\ коллекцию:
Наиболее сильные стороны FLUX.1 — дотошное следование длинным описаниям, фотографический реализм и отображение текста. Потому предложим системе создать живой образ одного известного литературного персонажа по следующей подсказке (единой в данном случае для CLIP и для T5; используется опорная циклограмма со странички с примерами, составленной самим же ComfyAnonimous, минимально модифицированная для возможности загружать GGUF-кодированные модели) — In this masterpiece of ultra-realistic detail, we find a lean and noble, but shabby aged gentleman wearing crumpled, dusty and worn oversized three-piece suit. The gentleman is squatting by a ruined antique column under the bright southern sun, holding a crumpled cardboard sheet with a crooked handwriting "JE N\'AI MANGÉ PAS SIX JOURS" in his hands. The gentleman's head is shiny bald, his skinny face is badly shaven (beardless, mustacheless:1.5), there is a cracked pince-nez on his nose. A frayed bowler hat is lying upside down in front of him on a street paved with a chipped stone; small nickel coins glisten inside the hat and next to it. — и исполним её с одной и той же затравкой «646124957372314» для всех шести попеременно сменяющих одна другую UNet с разными степенями сжатия. ![Никогда ещё Киса Воробьянинов не был так близок к Провалу (источник: ИИ-генерация на основе модели FLUX.1 [dev])](https://3dnews.ru/assets/external/illustrations/2024/11/15/1114100/aidraw12-02.jpg)
Никогда ещё Киса Воробьянинов не был так близок к Провалу (источник: ИИ-генерация на основе модели FLUX.1 [dev]) Результат обескураживающий, прямо скажем. Для начала: отображение сравнительно длинного текста и впрямь на высоте у всех моделей, разве что кроме откровенно пережатой Q_2_K (хотя и там буквы в целом верные), и выделение в подсказке необходимого по правилам французской грамматики апострофа обратной косой чертой помогает — апостроф этот в слове «N’AI» хорошо различим даже на тех картинках, где потерялся диакритический знак над «Е». С реалистичностью дела тоже обстоят неплохо, как и с общим композиционным следованием подсказке. Но вот детали… Прежде всего, пресловутая борода, в данном случае связанная не с мечом (этот пример мы разбирали в прошлый раз), а с возрастом. Раз джентльмен в подсказке обозначен как «aged», от бороды и усов на порождаемой дистиллированной (а вдобавок, похоже, до странности хаотично цензурированной) моделью картинке крайне сложно избавиться — даже невзирая на настойчивое упоминание «face is badly shaven (beardless, mustacheless:1.5)». В версии Q4_K_S для данной конкретной затравки, 646124957372314, место бороды всё же заняла пятидневной примерно запущенности щетина, — что ещё раз подчёркивает, насколько опрометчиво было бы надеяться нащупать с более легковесными квантованными моделями удачный seed, чтобы затем с ним и с той же подсказкой получить полностью аналогичную композицию уже с полноценным UNet/DiT — Q8_0 либо FP16. Ещё один тонкий момент: обратите внимание на шляпу. Хотя в подсказке прямо говорится о том, что лежать она должна перевёрнутой, получить такое её положение FLUX.1 не позволяет, хоть ты тресни, — и это проверено нами на нескольких десятках генераций с разными затравками. Дело не только в шляпах: перевёрнутые объекты этой модели в принципе плохо удаются, не говоря уже о повреждённых. Разбитые вазы, боевые шрамы на лицах суровых воителей, раны на телах поверженных чудовищ, даже невинный вроде бы пирсинг — едва ли не любые запросы на изображение сильно деформированных/модифицированных объектов, которые в нетронутом виде модели хорошо знакомы, исполняются ею из рук вон плохо. В сообществе энтузиастов высказываются идеи, что, возможно, повреждённые объекты либо вовсе отсутствовали в тренировочной базе данных FLUX.1, либо сознательно не сопровождались соответствующим текстовым описанием, так что в итоге тот набор токенов, на который связка T5+CLIP разбирает упоминание «перевёрнутой шляпы», ни на что определённое в латентном пространстве не указывает. Но в любом случае до тех пор, пока массивы обучающих картинок FLUX.1 с детальными их описаниями продолжают оставаться закрытыми от широкой публики, судить об этом со сколько-нибудь полной уверенностью невозможно. 
Меню менеджера дополнений ComfyUI (он, кстати, сам себя тоже воспринимает как дополнение — с порядковым номером 1, разумеется) позволяет удобно и быстро актуализировать версии и самой рабочей среды, и уже установленных дополнений А теперь — самое важное: посмотрим на скорости. Использованные варианты UNet/DiT генерировали картинки в разрешении порядка 1 Мпикс (832×1216 точек) в темпе примерно 30 с на одну итерацию для первых трёх (Q_2_K, Q4_K_S, Q5_K_S) и около 40 с/ит. для оставшихся трёх — Q8_0, FP8, FP16. Да, на нашей тестовой машине (GTX 1070 8 Гбайт + 24 Гбайт DDR3) трудно было бы ожидать сильной разницы в производительности между вариантами Q8_0 и FP16, но её отсутствие (практически; лишь в пределах считаных единиц с/ит.) для Q_2_K и Q5_K_S, что отличаются по объёму почти вдвое, куда как поразительнее. Вероятно, необходимость гонять туда-сюда между видеопамятью и медленным системным ОЗУ многие гигабайты данных в ходе последовательной загрузки сперва T5, а потом UNet-моделей сводит на нет преимущество, обеспечиваемое тем, что варианты с более серьёзной компрессией помещаются в видеоОЗУ целиком. Так или иначе, жертва качеством картинки при использовании Q_2_K по сравнению даже с Q4_K_S, не говоря уже о Q8_0, представляется не слишком оправданной. Иными словами, использовать сверхсжатую и более скоростную модель можно, но не стоит надеяться потом, отыскав с её помощью удачную комбинацию подсказки и затравки, получить полностью аналогичный по композиции, только с улучшенным качеством результат с занимающим больший объём UNet. А значит, быстрое прототипирование только лишь за счёт компактификации основной модели FLUX.1 [dev] работать не будет. По крайней мере, с гарантией. ⇡#Вширь и ввысьКакие же есть более подходящие варианты? Первое, что приходит на ум, — воспользоваться с гордостью отмеченной создателями FLUX.1 её универсальностью в части поддержки весьма обширного диапазона разрешений картинок, от 0,1 до 2,5 Мп. Интуитивно ясно, что мелкое изображение должно генерироваться куда быстрее крупного. И, быть может, если среди стремительно выпекаемых моделью картинок с разрешением 0,1 Мпикс (условно примерно 300 × 300 точек) попадётся удачная по композиции — но, понятное дело, не изобилующая деталями, — удастся с сохранением тех же подсказки и затравки переключиться на, скажем, 2 Мпикс — и получить приблизительно то же изображение, но с разрешением почти 1400 × 1400? Проверим. И начнём со смены ноды «Empty Latent Image», которая задаёт в опорной циклограмме ComfyAnonimous размеры холста, на более удобную при работе с FLUX.1 — позволяющую устанавливать эти размеры практичнее, чем высчитывая вручную количество пикселов по каждой стороне. Для этого, в свою очередь, потребуется обогатить ComfyUI очередным дополнением, — заодно и напомним, как эти самые дополнения в рабочую среду инсталлировать. 
Сведения о дополнениях, необходимых для запуска приведённой в самом начале циклограммы, в информационном окошке менеджера ComfyUI На момент написания настоящей «Мастерской» актуальная версия ComfyUI — 2.0.7. Как её устанавливать в виде независимого пакета (просто распаковкой в рабочий каталог из ZIP-файла, без привычной для Windows процедуры инсталляции с прописыванием переменных окружения в реестр), мы разбирали уже не раз. Ради удобства дополним эту рабочую среду менеджером установок — ComfyUI-Manager в текущей версии 2.48.1. Инструкции по его развёртыванию приведены на домашней страничке этого проекта на GitHub и крайне прозрачны. В частности, для нашего случая — когда сама ComfyUI установлена именно как независимый пакет (portable version) — требуется:
Вслед за этим после запуска рабочей среды — как раз при помощи того самого run_nvidia_gpu.bat — в нижней части главного меню веб-интерфейса ComfyUI появится кнопка «Manager». Вот как раз её посредством мы и будем устанавливать необходимые дополнения, а заодно и обновлять как их, так и рабочую среду в целом — это куда удобнее, чем вручную. Собственно, сразу и поставим всё необходимое на первых порах. Открыв меню менеджера ComfyUI, нажмём на кнопку «Custom Nodes Manager» в самом верху среднего столбца доступных там органов управления — и в появившемся окне с перечнем доступных расширений найдём через окошко поиска, выберем и последовательно проинсталлируем следующие (ссылки на соответствующие страницы проектов на GitHub приводятся прямо в интерфейсе, что позволяет лишний раз удостовериться в корректности выбора нужного дополнения):
Примерно так менеджер ComfyUI информирует о наличии в загруженной в рабочую среду циклограмме не проинсталлированных пока расширений Собственно, вручную вбивать в поисковое окошко названия всех этих нод не потребуется, если скачать по приведённой ближе к концу настоящей «Мастерской» ссылке коллекцию изображений, к получению которых мы сейчас приступим. Сохранённые в формате PNG с интегрированным JSON, эти файлы при перетаскивании в рабочее поле ComfyUI воспроизведут там встроенные в них циклограммы. Если какие-то ноды у пользователя в данный момент не развёрнуты, соответствующие им прямоугольные блоки окажутся помечены на циклограмме красным, а дополнение менеджера выдаст соответствующее предупреждение. Открыв затем меню всё того же менеджера и нажав на кнопку «Install Missing Custom Nodes», не составит труда последовательно установить все необходимые расширения. Рекомендуется также — из того же самого меню — регулярно, хотя бы раз в неделю, исполнять команду «Update All»: это позволит поддерживать в актуальном состоянии и саму рабочую среду, и все дополнения для неё. 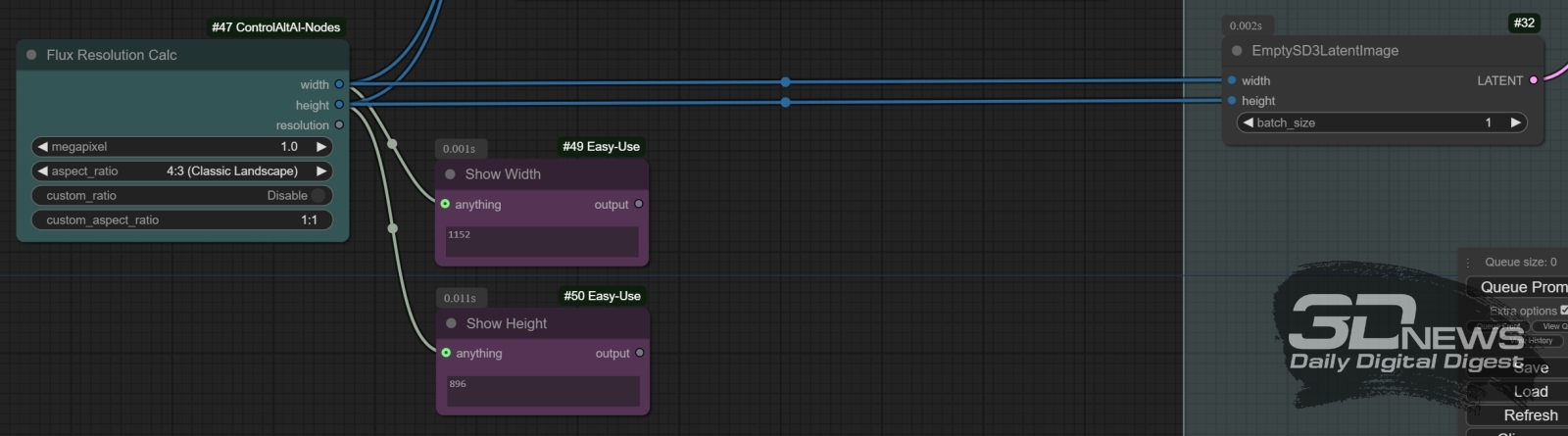
Нода «Flux Resolution Calc» из дополнения ControlAltAI позволяет не задумываться о точном числе пикселов по каждой из сторон выбираемого холста: достаточно задать соотношение этих самых сторон и общее разрешение картинки в мегапикселях. В свою очередь, ноды «Show Anything», в данном случае используемые для контроля точных значений ширины и высоты холста, будут демонстрировать в своих окошках вычисляемые этим «калькулятором» величины Чтобы проверить, сохраняется ли хотя бы общая композиция порождаемой FLUX.1 [dev] картинки при увеличении лишь разрешения холста (его площади в мегапикселях) с сохранением прочих параметров — подсказки и затравки, модифицируем исходную циклограмму, взятую со странички с примерами ComfyAnonimous, о которой не раз уже упоминалось. Там размер холста задаётся нодой «EmptySD3LatentImage». Почему «SD3» — имеется в виду SD3M, конечно же, — да потому, что и та не слишком удачная модель разработки Stability AI так же, как и семейство FLUX.1, ориентирована на поддержку холстов в широком диапазоне разрешений, вплоть до 2,5 Мпикс. Если же пользоваться стандартным для SDXL/SD 1.5 генератором латентных образов, предел возможностей которого — 1 Мпикс, на больших разрешениях можно столкнуться с нежелательными проблемами. Однако «EmptySD3LatentImage» подразумевает задание ширины и высоты холста вручную. Облегчим себе жизнь: преобразуем поля ввода двух этих величин во входы для подключения внешних нод — для чего следует нажать правой кнопкой мыши на представляющем её прямоугольнике и в появившемся меню выбрать опцию «Convert Widget to Input», в меню следующего уровня — «Convert width to input», а затем проделать то же самое с высотой холста (height). А вот как раз для задания конкретных величин ширины и высоты применим ноду «Flux Resolution Calc» из только что установленного дополнения ControlAltAI, — чтобы она появилась на рабочем поле ComfyUI, достаточно дважды щёлкнуть левой кнопкой мыши по любому свободному его участку и начать набирать ключевое слово «resolution». Нода позволяет задавать разрешение холста в пределах от 0,1 до 2,5 Мпикс, а также выбирать из предложенного широкого перечня соотношений сторон — либо же задавать свои собственные вручную. Для контроля точных значений длины и ширины будущей картинки пригодятся ноды «Show Any» из пакета «Easy Use»: достаточно расположить две таких поблизости от «Flux Resolution Calc» и подвести к ним выходы «width» и «height» последней. Те же самые выходы пойдут на соответствующие входы ноды «Model Sampling Flux» и «EmptySD3LatentImage». ![У всех трёх приведённых изображений одни и те же соотношения сторон (4:3), затравки и подсказки. Слева сверху — картинка с разрешением 0,1 Мпикс (368×272), под ней — 0,5 Мпикс (816х608), справа — 1,0 Мпикс (1152х896) (источник: ИИ-генерация на основе модели FLUX.1 [dev])](https://3dnews.ru/assets/external/illustrations/2024/11/15/1114100/aidraw12-07.jpg)
У всех трёх приведённых изображений одни и те же соотношения сторон (4:3), затравки и подсказки. Слева сверху — картинка с разрешением 0,1 Мпикс (368 × 272), под ней — 0,5 Мпикс (816 × 608), справа — 1,0 Мпикс (1152 × 896) (источник: ИИ-генерация на основе модели FLUX.1 [dev]) Теперь всё просто: вводим в соответствующие поля текстовые подсказки, выбираем в качестве модели UNet/DiT GGUF-версию с квантованием Q8_0, фиксируем значение затравки (в ноде «Random Noise» меняем значение параметра «control_after_generate» с «randomized» на «fixed»), выбираем в «Flux Resolution Calc» любое понравившееся соотношение сторон — и запускаем последовательно генерацию с одними и теми же параметрами, но с последовательно изменяемым разрешением, начиная с 0,1 Мпикс. Как показывает практика, хотя в целом композиции и цветовые решения картинок оказываются схожими, различие даже в крупных деталях выходит слишком большим, чтобы им можно было пренебрегать. Иными словами, не получится сэкономить время, выпекая с высокой скоростью 0,1-Мпикс картинки и дожидаясь появления особенно удачной, — чтобы затем отправить на генерацию изображение с той же затравкой, но бóльшим разрешением. А жаль; хоть попробовать, безусловно, стоило. ⇡#Ход конёмНадо сказать, что экономию времени использование сниженного разрешения, разумеется, обеспечивает: если 0,5-Мпикс картинка генерируется на нашей тестовой машине со скоростью 17-19 с/ит., то 1-Мпикс — 36-38 с/ит. Если учесть, что шагов для порождения изображений с FLUX.1 [dev] стандартно требуется не менее 20 (и, кстати, разница между 20, 25 и 30 не слишком велика и далеко не всегда в пользу более продолжительных генераций — ещё одно свидетельство дистиллированного характера этой модели), разница вполне ощутима. Да только вот какая беда: если на картинке подразумевается присутствие значимых мелких деталей — букв, сложенных в осмысленные слова; кистей человеческих рук, что не напоминали бы растрёпанные веники; тонко проработанных узоров, не сливающихся в хаотичную мешанину пикселов, то с понижением разрешения качество таких мелочей (которые вовсе не мелочи) радикально снижается. Модели попросту недостаёт пикселов в данной конкретной области извлекаемого из латентного пространства изображения, чтобы адекватно отобразить требуемые от неё подсказкой тонкие по проработке элементы. Так что же, всё равно придётся уходить с FLUX.1 [dev] в свободный поиск по затравкам без надежды сколько-нибудь повысить скорость прототипирования? 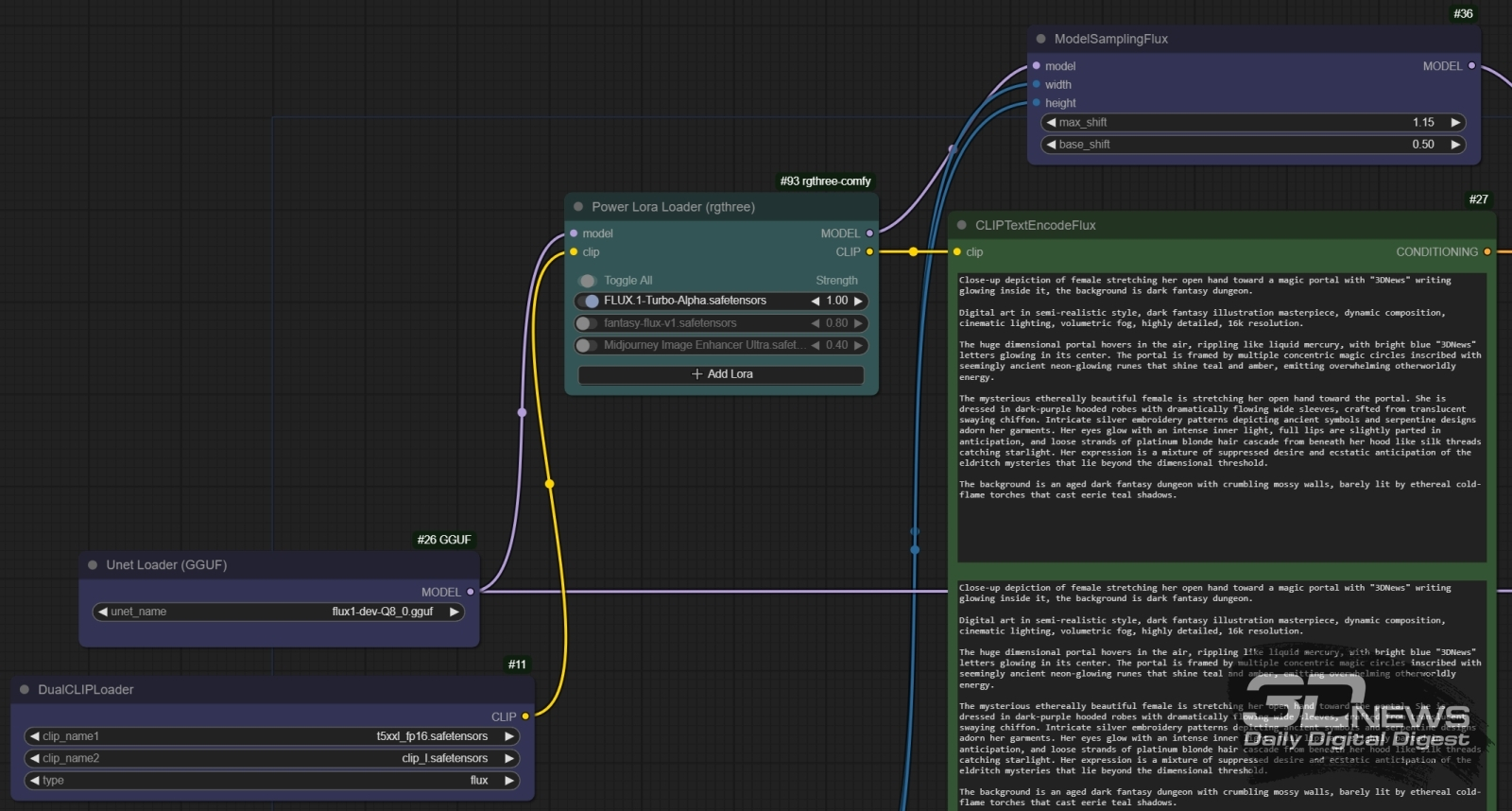
Нода «Power Lora Loader» из пакета rgthree вставляется в поток данных «model» между нодами «Unet loader (GGUF)» и «ModelSamplingFlux», а в поток «clip» — между «DualCLIPLoader» и «CLIPTextEncodeFlux» А вот и нет! Подобная проблема для SDXL была в своё время частично решена (до)тренировкой ускоренных версий соответствующей модели — через уже знакомую нам по FLUX.1 дистилляцию. Только, применённая к исходно недистиллированной модели, такая дистилляция не приводила к тому ощутимому понижению качества, что отличает FLUX.1 [schnell] от [dev]. Скажем, SDXL Turbo способна обходиться даже одним шагом генерации (step) для порождения вполне сносных картинок вместо 30-50 для базовой версии — благодаря технологии состязательной диффузной дистилляции (adversarial diffusion distillation, ADD), а SDXL Lightning в различных вариациях — двумя, четырьмя или восемью. Собственно, FLUX.1 [schnell] и представляет собой дистиллированную подобным ADD образом версию [dev], но процедура эта, как нетрудно убедиться, привела к слишком уж ощутимому падению субъективного эстетического качества [schnell]-генераций, особенно в части отображения человеческой кожи, плавных цветовых градиентов и текста. Ожидать от Black Forest Labs появления более корректно, чем [schnell], ускоренной версии FLUX.1 [dev] (дистиллированной напрямую из [pro] в идеале) вряд ли в ближайшее время стоит, — но сообщество энтузиастов взялось за решение этой проблемы само. Один из предложенных способов — использование LoRA-акселератора, который реализовал бы схожий с ADD подход для сокращения числа шагов генерации для этой модели. Известно несколько проектов такого рода, среди которых именно для среды ComfyUI можно рекомендовать разработку китайских товарищей из AlimamaCreative Team — FLUX.1-Turbo-Alpha. Со страницы проекта на Hugging Face нужно скачать файл diffusion_pytorch_model.safetensors, переименовать его во FLUX.1-Turbo-Alpha.safetensors и поместить в стандартный для LoRA каталог — ComfyUI\models\loras. Разработчики рекомендуют при использовании этого ускорителя выставлять число шагов генерации в 8, параметр руководства (guidance) — в 3,5, а вес самой LoRA — в 1,0. Среди недавно установленных нами в ComfyUI через менеджер расширений присутствовал и пакет rgthree-comfy. В его составе имеется крайне удобная нода «Power Lora Loader», позволяющая без труда добавлять в рабочую циклограмму (а дальше убрать), а затем активировать/деактивировать множество LoRA. Установим эту ноду сразу после загрузки основных моделей (UNet и CLIP/T5), подключим соответствующие вводы-выводы (см. подпись к иллюстрации выше) и активируем в ней только что закачанную FLUX.1-Turbo-Alpha.safetensors со значением веса «1.0». Если по какой-то причине при нажатии на поле ввода названия LoRA не появляется список доступных в ComfyUI\models\loras файлов с расширением .safetensors, нужно нажать на кнопку «Refresh» в главном меню ComfyUI и дождаться подтверждения системы (появления полупрозрачного зелёного всплывающего окошка, обычно в правом верхнем углу окна браузера, в котором запущен её веб-интерфейс) о готовности продолжать работу. ![Картинки, полученные с полностью идентичными базовыми параметрами, но первая — с FLUX.1-Turbo-Alpha и за 8 шагов, а вторая и третья — без LoRA и за 20 и 30 шагов соответственно; верхний ряд — с разрешением 0,5 Мпикс, нижний — 1,0 Мпикс (источник: ИИ-генерация на основе модели FLUX.1 [dev])](https://3dnews.ru/assets/external/illustrations/2024/11/15/1114100/aidraw12-09.jpg)
Картинки, полученные с полностью идентичными базовыми параметрами, но первая — с FLUX.1-Turbo-Alpha и за 8 шагов, а вторая и третья — без LoRA и за 20 и 30 шагов соответственно; верхний ряд — с разрешением 0,5 Мпикс, нижний — 1,0 Мпикс (источник: ИИ-генерация на основе модели FLUX.1 [dev]) Приведённый пример показывает прежде всего, что для FLUX.1 [dev] действительно нет принципиальной разницы между 20 и 30 шагами генерации, — более того, мелкие существенные детали (кисти рук, светящиеся руны на магическом круге) с увеличением числа шагов скорее теряют в качестве, чем приобретают. Ускоритель FLUX.1-Turbo-Alpha.safetensors, в свою очередь, мелкие детали чуть огрубляет, да и с крупными (лицо, капюшон, волосы) обходится несколько вольно — но притом сохраняет общую эстетику и композицию изображения (для каждого выбранного разрешения холста), да и в целом обеспечивает вполне достойный результат, особенно по части воспроизведения текста. Экономия же времени на каждую генерацию выходит существенная: всё-таки 8 шагов примерно по полминуты каждый (в случае 1-Мпикс холста), а не 20 и тем более не 30. Таким образом, для быстрого прототипирования с FLUX.1 [dev] логичным представляется применение LoRA-ускорителя (в нашем случае — FLUX.1-Turbo-Alpha.safetensors) с сокращением числа шагов генерации до 8, а также выбор 1,0 Мпикс в качестве базового разрешения — а если мелкие детали не так важны, то и 0,5 Мпикс сгодится. Тогда на выпечку каждой картинки в режиме свободного поиска будет уходить максимум по 4-5 минут, что вполне приемлемо. Точнее, приемлемо, если удастся скормить генеративной модели такую подсказку, что была бы оптимальным образом интерпретирована — и почти с гарантией породила бы устраивающий оператора результат если не с первого, то с третьего, пятого, на худой конец десятого раза (тогда как в случае SD 1.5/SDXL при всём богатстве доступных сегодня для них чекпойнтов/дополнений и высокой скорости инференса свободный поиск удачного визуального воплощения текстовой подсказки может вестись часами, если не сутками). А это вообще реально? В принципе, да, — и сейчас мы наконец поясним, какой именно текст (и почему именно его) размещали в окошках ноды «CLIPTextEncodeFlux», чтобы получить приводившиеся до сих пор в примерах картинки со стоящей перед порталом фигурой в газовой накидке. Исходный замысел изображения, сформулированный по-английски естественным языком (в расчёте на его последующее растолковывание для CLIP моделью T5 — об этой особенности FLUX.1 мы подробно рассказывали в прошлый раз), был следующим: Female holding out her hand to a portal that reads "3DNews" in a dark fantasy dungeon. Просто, складно, легко запомнить; но для CLIP этого заведомо окажется слишком много, а для T5 — чересчур мало. Дадим волю воображению и превратим по-телеграфному убористое описание задуманной картинки в более развёрнутое, останавливаясь на важных для итогового изображения деталях — более подробном описании самого портала, стоящей перед ним фигуры, её одежды и окружения: In a dark fantasy dungeon, barely lit by weird cold-flame torches, a mysterious female is holding out her hand to a flickering dimensional portal with shiny "3DNews" letters, surrounded by multiple magic circles of unsettling teal and amber neon-glowing runes. The fragile female is clad in dark hooded robes with wide sleeves, made of ethereal, almost translucent golden chiffon with elaborate silver embroidery. Her eyes are glowing, full lips are parted, loose platinum hair are escaping from under the hood; she is trembling with sinful, but ecstatic anticipation of what lies behind the portal. ![Слева — изображение с только что приведённой расширенной подсказкой, затравкой 1002970411169969 и разрешением 0,5 Мпикс; справа — всё то же, но разрешение 1,0 Мпикс (источник: ИИ-генерация на основе модели FLUX.1 [dev])](https://3dnews.ru/assets/external/illustrations/2024/11/15/1114100/aidraw12-10.jpg)
Слева — изображение с только что приведённой расширенной подсказкой, затравкой 1002970411169969 и разрешением 0,5 Мпикс; справа — всё то же, но разрешение 1,0 Мпикс (источник: ИИ-генерация на основе модели FLUX.1 [dev]) В принципе, это уже достаточно пространный текст, чтобы охочая до долгих описаний FLUX.1 могла на его основе создавать живописные картины. Но нельзя ли предложить модели ещё более детальные инструкции — с тем, чтобы повысить вероятность выдачи заведомо приемлемого (для начала с хорошо читаемым текстом) изображения до максимума? ⇡#Глубина детализацииПриведённая чуть выше пара изображений, порождённых расширенной нами подсказкой, явно свидетельствует, что, хотя общую композицию LoRA-ускоренная FLUX.1 [dev] схватила в данном случае верно, с отображением даже столь краткого текста у неё возникают явные проблемы. Возможно, дело в том, что текст этот должен располагаться на среднем, а то и заднем плане и потому заведомо не может занимать много места на холсте, — потому, в частности, 0,5-Мпикс попытка его воспроизвести выглядит куда хуже 1-Мпикс варианта. Но дело не только в этом. Модели семейства FLUX.1 просто обожают пространные, хорошо детализированные подсказки — ориентироваться следует слов на 150, лучше даже 200. Не каждый, особенно если английский язык для него не родной, способен художественно и в то же время предметно описать витающий в голове замысел будущего цифрового шедевра настолько полно. Ничего страшного — на помощь придут умные чат-боты, причём, если нет прямого доступа к ChatGPT или Claude, всегда можно воспользоваться свободно доступными в Сети генеративными моделями. Например, Junia.ai, что позиционируется как «AI Prompt Writer & ChatGPT Prompt Generator». Там всё просто: вводим в окошко на сайте исходную версию своей подсказки — вот ту самую, только что расширенную вручную из исходного краткого предложения, — и после нажатия на кнопку «Generate» получаем (к примеру, поскольку всякий раз формулировки в сгенерированной подсказке будут чуть иные) следующее: In a dark fantasy dungeon, barely lit by ethereal cold-flame torches casting eerie blue shadows, a mysterious female stands before a shimmering dimensional portal that ripples like liquid mercury. Surrounding shiny "3DNews" letters, multiple concentric magic circles hover in the air, inscribed with unsettling teal and amber neon-glowing runes that pulse with otherworldly energy. The ethereally beautiful female is clad in dark hooded robes with dramatically flowing wide sleeves, crafted from translucent golden chiffon that seems to catch nonexistent wind. Intricate silver embroidery patterns depicting ancient symbols and serpentine designs adorn her garments. Her eyes glow with an intense inner light, full lips are slightly parted in anticipation, and loose strands of platinum blonde hair cascade from beneath her hood like silk threads catching starlight. Her outstretched hand trembles as she reaches toward the portal, her delicate fingers illuminated by the portal's shifting light, her expression a mixture of forbidden desire and ecstatic anticipation of the eldritch mysteries that lie beyond the dimensional threshold. Digital art style, cinematic lighting, volumetric fog, highly detailed, 8k resolution, dark fantasy artwork. ![Опять прежние параметры генерации, включая затравку, опять слева картинка с разрешением 0,5 Мпикс, а справа — 1,0 Мпикс, но на сей раз использована обогащённая Junia.ai подсказка (источник: ИИ-генерация на основе модели FLUX.1 [dev])](https://3dnews.ru/assets/external/illustrations/2024/11/15/1114100/aidraw12-11.jpg)
Опять прежние параметры генерации, включая затравку, опять слева картинка с разрешением 0,5 Мпикс, а справа — 1,0 Мпикс, но на сей раз использована обогащённая Junia.ai подсказка (источник: ИИ-генерация на основе модели FLUX.1 [dev]) Уже под 180 слов, уже неплохо, — и сразу заметно, кстати, что этот генеративный сервис оптимизирован именно под составление подсказок для ИИ-рисования: по собственной инициативе он добавил в текст указания на стилистику изображения, его разрешение, детализацию и т. п. Всё вроде бы здорово, и, если разместить этот текст в оба окошка ввода ноды «CLIPTextEncodeFlux», результат должен оказаться более адекватным поставленной задаче. Он и оказывается, хотя простор для совершенствования ещё совершенно точно есть, особенно по части текста: скажем, при данной затравке тот попросту отказывается отображаться. И вот здесь снова не обойтись без прямого участия живого оператора по ту сторону экрана — умные боты в одиночку явным образом не справляются. В сообществе энтузиастов ИИ-рисования сложилось довольно определённое мнение, что T5 при всех его достоинствах — не самый даровитый толмач, и, чтобы облегчить ему работу, длинную подсказку (написанную самостоятельно либо при помощи преобразующих текст в текст генеративных моделей) следует определённым образом упорядочивать. А именно:
Поработав таким образом над предложенным Junia.ai текстом, мы сконструировали вот что: ![Расширенная и переосмысленная (по абзацам) подсказка, затравка 1002970411169969, разрешения: слева — 1,5 Мпикс (1408×1088 точек, 155 с/ит.), в центре — 2,0 Мпикс (1632×1216 точек, 374 с/ит.), справа — 2,5 Мпикс (1824×1376 точек, 814 с/ит.) (источник: ИИ-генерация на основе модели FLUX.1 [dev])](https://3dnews.ru/assets/external/illustrations/2024/11/15/1114100/aidraw12-12.jpg)
Расширенная и переосмысленная (по абзацам) подсказка, затравка 1002970411169969, разрешения: слева — 1,5 Мпикс (1408×1088 точек, 155 с/ит.), в центре — 2,0 Мпикс (1632×1216 точек, 374 с/ит.), справа — 2,5 Мпикс (1824×1376 точек, 814 с/ит.) (источник: ИИ-генерация на основе модели FLUX.1 [dev]) Female holding out her hand to a portal that reads "3DNews" in a dark fantasy dungeon. Digital art style, cinematic lighting, volumetric fog, highly detailed, 8k resolution, dark fantasy artwork. To the left, the shimmering dimensional portal ripples like liquid mercury, with "3DNews" letters shining brightly in its center. Multiple concentric magic circles hover around the portal in the air, inscribed with unsettling teal and amber neon-glowing runes that pulse with otherworldly energy. To the right, the mysterious ethereally beautiful female, dressed in dark-purple hooded robes with dramatically flowing wide sleeves, crafted from translucent golden chiffon that seems to catch nonexistent wind. Intricate silver embroidery patterns depicting ancient symbols and serpentine designs adorn her garments. Her eyes glow with an intense inner light, full lips are slightly parted in anticipation, and loose strands of platinum blonde hair cascade from beneath her hood like silk threads catching starlight. Her outstretched hand trembles as she reaches toward the portal, her delicate fingers illuminated by the portal's shifting light, her expression a mixture of suppressed desire and ecstatic anticipation of the eldritch mysteries that lie beyond the dimensional threshold. The background is an aged dark fantasy dungeon with crumbling mossy walls, barely lit by ethereal cold-flame torches that cast eerie blue shadows. Собственно, полученные именно с этой подсказкой и затравкой 1002970411169969 картинки мы и приводили ранее в качестве иллюстраций с разрешениями 0,1, 0,5 и 1,0 Мпикс. Кстати, заметно, что при увеличении числа пикселов выше 1,5 Мпикс хотя и улучшается проработка в отдельных деталях (текстуры ткани, камня и проч.), но буквы опять начинают удаваться модели хуже. Судя по всему, 1,0 Мпикс именно с точки зрения баланса между качеством отображения среднего размера букв, кистей рук и прочих мелочей, которые вовсе не мелочи, — наилучшим образом сбалансированное разрешение. На нём в дальнейшем и остановимся. ⇡#Но и это ещё не всёОстаётся вопрос: как быть с распределением полученных текстовых абзацев по паре окон ввода ноды «CLIPTextEncodeFlux»? В предыдущих примерах и в окно «clip_l», и в окно «t5xxl» просто копировалась вся эта длинная подсказка целиком, все пять её абзацев, — хотя читатели прошлой нашей «Мастерской» должны помнить, что имеет право на жизнь и другой подход, когда на вход преобразователя текста в токены CLIP подаётся лишь общее описание картинки, а на вход «толкователя» Т5 — более пространное. Быть может, и в данном случае есть смысл ограничиться в верхнем окошке лишь одним-двумя первыми абзацами, а в нижнее вводить либо все их полностью, либо только оставшиеся от общего описания? ![Различные версии комбинаций пяти абзацев из нашей полной подсказки в окошках текстового ввода для CLIP и Т5; см. пояснения в тексте (источник: ИИ-генерация на основе модели FLUX.1 [dev])](https://3dnews.ru/assets/external/illustrations/2024/11/15/1114100/aidraw12-13.jpg)
Различные версии комбинаций пяти абзацев из нашей полной подсказки в окошках текстового ввода для CLIP и Т5; см. пояснения в тексте (источник: ИИ-генерация на основе модели FLUX.1 [dev]) Мы провели довольно прямолинейный эксперимент: сперва, оставив в нижнем окне ноды «CLIPTextEncodeFlux» все пять абзацев подготовленного текста подсказки, вводили в верхнее либо два первых вместе, либо только первый или только второй; затем из окна для T5 убрали первые два абзаца, оставив лишь с третьего по пятый, а в окне для CLIP повторили прежний цикл — два первых абзаца, только первый, только второй. Результаты налицо: лучше прочих по композиции и качеству деталей (прежде всего текста) самый первый вариант — когда модели CLIP скармливаются два первых абзаца, обрисовывающих общее построение и художественное решение задуманной картинки, а для T5 эти абзацы дублируются, дополняясь ещё тремя с более детальными указаниями на то, как и что следует изображать. При всех прочих комбинациях абзацев страдает либо фигура таинственной незнакомки у портала (чрезмерно вытягивается шея), либо текст, либо загадочные руны в магических кругах, либо всё это вместе. ![Слева — идентичные подсказки в обоих окнах ноды «CLIPTextEncodeFlux»; справа — для CLIP только первые два абзаца, для Т5 — все пять (источник: ИИ-генерация на основе модели FLUX.1 [dev])](https://3dnews.ru/assets/external/illustrations/2024/11/15/1114100/aidraw12-14.jpg)
Слева — идентичные подсказки в обоих окнах ноды «CLIPTextEncodeFlux»; справа — для CLIP только первые два абзаца, для Т5 — все пять (источник: ИИ-генерация на основе модели FLUX.1 [dev]) Впрочем, лишать CLIP возможности самостоятельно, а не только при помощи Т5 поработать над полным текстом всё же было бы опрометчиво. В приводимом нами примере разница между картинками с полным дублированием текстовых подсказок и с оставлением в поле для CLIP только первых двух абзацев есть. Да, она едва заметна — проявляется лишь в тонких деталях вроде выражения лица фигуры у портала, проработанности вышивки на её накидке и большей/меньшей схожести янтарного орнамента на внешней стороне магического круга с загадочной буквенной вязью, а не просто с абстрактными узорами. Если ограничивать работу по генерации устраивающего оператора изображения разрешением 1 Мпикс, возможно, и нет смысла копировать один и тот же текст в оба окна «CLIPTextEncodeFlux», — пусть в верхнем остаются лишь самые общие указания ИИ-художнику и только второе содержит полную подсказку. Но с учётом того, что картинку можно (и часто нужно!) укрупнить не то что без потери качества в деталях, а с его повышением, лучше всё-таки остановиться на полном дублировании. Поскольку мы уже убедились, что укрупнение генерации FLUX.1 [dev] простым увеличением разрешения холста с сохранением всех прочих параметров не работает — в смысле, нарушает исходную композицию, — обратимся к хорошо известному ещё со времён SD 1.5 средству. А именно — к преобразованию image-to-image, в ходе которого исходная картинка становится основой холста для более крупной, так что увеличенное изображение генерируется не на полученном от случайной затравки прямоугольнике, хаотично заполненном цветными пятнами, а, по сути, на растянутом и лишь слегка зашумлённом изначальном изображении. Все необходимые ноды для этого уже имеются в проинсталлированных нами расширениях для ComfyUI, а соответствующая циклограмма представлена в сопровождающем настоящую «Мастерскую» наборе картинок (ссылка на них приводится ближе к концу текста) под названием Dev_upscaled_B_00014_.png. ![Общий вид циклограммы для двукратного (по каждому из измерений) увеличения полученной нами 1-Мпикс картинки при помощи всё той же модели FLUX.1 [dev]](https://3dnews.ru/assets/external/illustrations/2024/11/15/1114100/aidraw12-15.jpg)
Общий вид циклограммы для двукратного (по каждому из измерений) увеличения полученной нами 1-Мпикс картинки при помощи всё той же модели FLUX.1 [dev] Описывать устройство этой циклограммы можно долго, но работает она крайне просто: в ноду «Load Image» загружается картинка, которую требуется увеличить с повышением качества, и для начала она двукратно масштабируется с применением входящей в штатную комплектацию ComfyUI ноды «Upscale Image (Using Model)» и модели 4xFaceUpDAT.pth — файл которой (155 Мбайт) необходимо предварительно скачать с Hugging Face и поместить в каталог ComfyUI\models\upscale_models\. Это достаточно механическое увеличение — то есть мелкие огрехи, присутствовавшие на исходном изображении, никуда не денутся, просто станут вдвое крупнее. Чтобы избавиться от них, необходимо передать полученную после укрупнения с 4xFaceUpDAT.pth картинку с выхода ноды «Upscale Image By» внутри блока «1st Upscale Group» на вход ноды «VAE Encode (Tiled)» в соседнем блоке, «1st Img2Img Group». В ходе генерации картинок «из ничего» на этот вход подаётся латентное изображение — грубо говоря, скопление цветных пятен, созданное псевдослучайным образом на основе численной затравки, — а здесь вместо мешанины точек модели FLUX.1 [dev] будет предложено формировать новое изображение, отталкиваясь от несколько размытого образа прежнего. 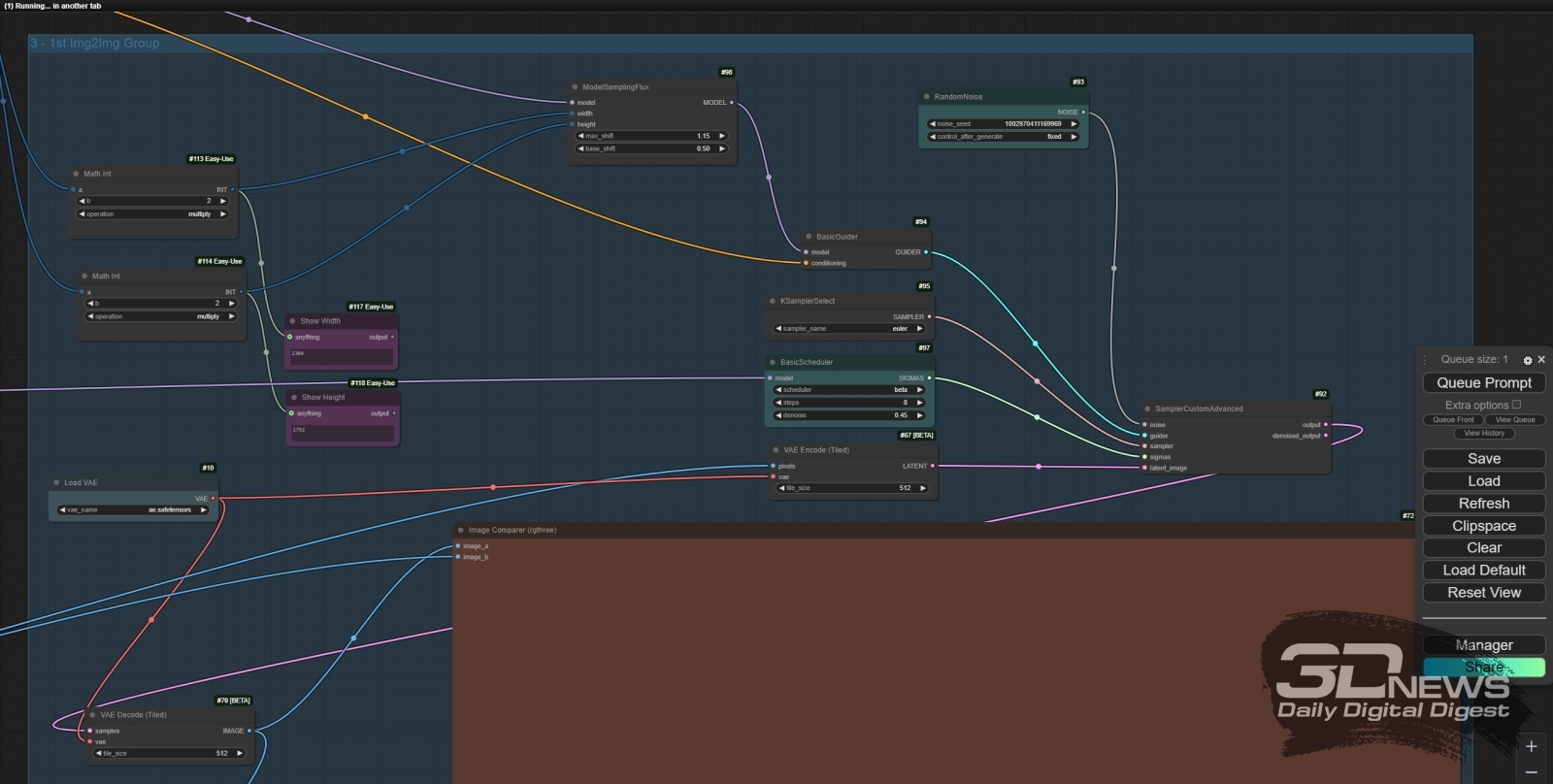
Организация блока нод «1st Img2Img Group»: за силу воздействия новой генерации на результат прежней отвечает параметр «denoise» (в данном случае — 0,45) ноды «BasicScheduler» Собственно, за этим исключением — что вместо латентного образа непосредственно из «EmptySD3LatentImage» на вход главной ноды-обработчика FLUX.1, «SampleCustomAdvanced», подаётся через «VAE Encode (Tiled)» растянутая внешним апскейлером предназначенная к увеличению картинка, — блок «1st Img2Img Group» практически полностью идентичен исходной циклограмме, с использованием которой генерировались рассмотренные нами только что изображения с пятью абзацами текста в качестве подсказки. С практической точки зрения представляет интерес нода «Image Comparer (rgthree)» из состава соответствующего дополнения: она позволяет, просто перемещая мышку вправо-влево, зрительно сопоставлять две подаваемые на её входы картинки. И, как можно убедиться, качество при таком увеличении действительно повышается. 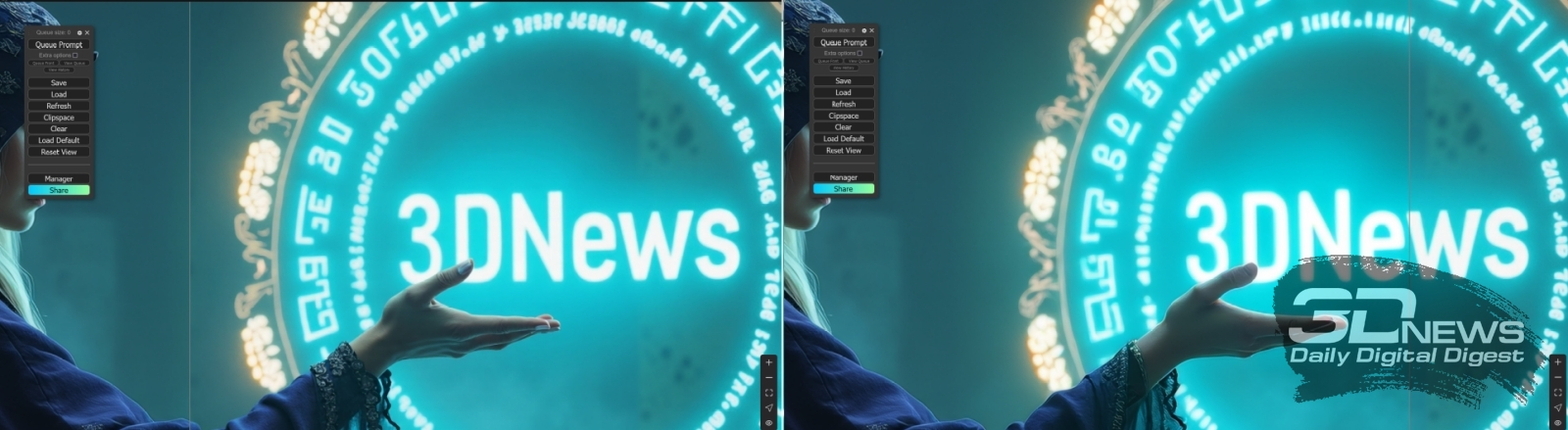
Наглядная демонстрация работы ноды «Image Comparer (rgthree)»: слева — вертикальная линия-ползунок сдвинута влево; поле картинки справа от неё, включая кисть руки и магический портал, соответствует итогу масштабирования с повышением качества; справа — ползунок перемещён в другую сторону, и теперь ясно видно, что просто увеличенная через «Upscale Image By» картинка в деталях явно уступает итоговой Дальше на нашем тестовом компьютере масштабировать изображение таким же образом — загрузив теперь уже сохранённое в файл Dev_upscaled_B_00014_.png изображение в ноду «Load Image» на той же диаграмме и просто повторив процесс — проблематично: для удержания в памяти и одновременной обработки раздавшейся вдвое по обоим измерениям картинки не хватит даже суммарно имеющихся в его распоряжении объёмов ОЗУ и видеоОЗУ. Хорошо отработанное для SD 1.5/SDXL увеличение по фрагментам (tiled upscale) на основе ControlNet для моделей FLUX пока находится в зачаточной стадии, хотя сносно работающие примеры применения такой техники уже известны. Однако никто не мешает применить к полученному изображению tiled upscale с чекпойнтом SDXL, например, — что заодно позволит снять проблему чрезмерно ненатуралистично выглядящей, особенно при столь высоких разрешениях, человеческой кожи. 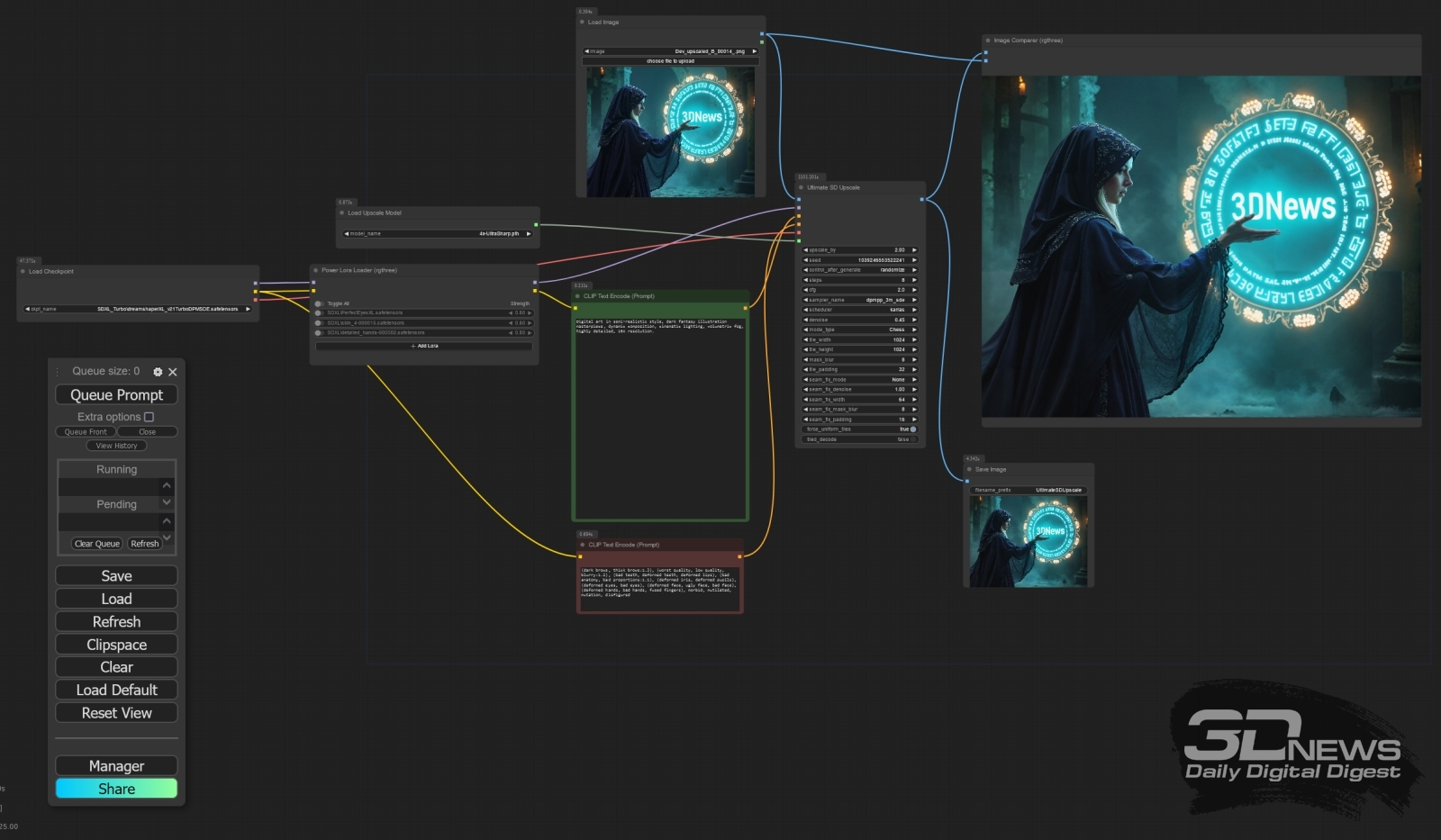
Общий вид циклограммы для очередного двукратного (по каждому из измерений) увеличения картинки — но уже с чекпойнтом SDXL Turbo Для этого потребуется установить через менеджер ComfyUI ещё одно расширение, UltimateSDUpscale, и использовать крайне несложную циклограмму, которая интегрирована в файл UltimateSDUpscale_00002_.png из нашего архива с примерами. В результате из картинки с разрешением 4 Мпикс (2304×1792) получится ещё более улучшенная по качеству 16-Мпикс (4608×3584). ![И снова работает нода «Image Comparer (rgthree)», только уже после UltimateSDUpscale: слева — выдача финального масштабирования с FLUX.1 [dev]; справа — двукратное (по каждому из измерений, т. е. четырёхкратное по площади) увеличение с чекпойнтом DreamShaper XL Turbo v. 2.1](https://3dnews.ru/assets/external/illustrations/2024/11/15/1114100/aidraw12-19.jpg)
И снова работает нода «Image Comparer (rgthree)», только уже после UltimateSDUpscale: слева — выдача финального масштабирования с FLUX.1 [dev]; справа — двукратное (по каждому из измерений, т. е. четырёхкратное по площади) увеличение с чекпойнтом DreamShaper XL Turbo v. 2.1 Наконец, если и этого недостаточно, к услугам энтузиастов — мощнейший инструмент Make Tile SEGS Upscale из состава пакета ComfyUI-Impact-Pack, который также необходимо установить в рабочую среду через менеджер. Применяя его, правда, придётся запастись изрядным терпением — на нашем тестовом компьютере процедура получения картинки с разрешением 9216×7168 точек, файл MakeTileSEGS_upscale_00017_.png размером в 54 Мбайт, заняла более шести часов, но, если есть желание распечатать полученную картинку в виде плаката А3, например, это как раз подходящий размерчик. ![По техническим причинам на этой странице мы можем разместить картинку с максимальным размером по горизонтали лишь 1600 точек, — тогда как в оригинале их 9216 (источник: ИИ-генерация на основе модели FLUX.1 [dev])](https://3dnews.ru/assets/external/illustrations/2024/11/15/1114100/aidraw12-20.jpg)
По техническим причинам на этой странице мы можем разместить картинку с максимальным размером по горизонтали лишь 1600 точек, тогда как в оригинале их 9216 (источник: ИИ-генерация на основе модели FLUX.1 [dev]) Все упомянутые на протяжении настоящей «Мастерской» файлы можно скачать единым архивом (осторожно: 104 Мбайт!) из облака. А мы на этом приостанавливаем изучение семейства моделей FLUX.1 — и принимаемся пристально вглядываться в Stable Diffusion 3.5: очень уж большие надежды питает в её отношении сообщество энтузиастов ИИ-рисования. Возможно, как раз этой недистиллированной модели удастся стать основным рабочим инструментом поклонников генеративной компьютерной графики, вытеснив наконец с этого пьедестала заслуженную SDXL? Поживём — увидим. Если Вы заметили ошибку — выделите ее мышью и нажмите CTRL+ENTER.
Материалы по теме
|
© 1997—2025 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews. kz
![]()
![]()






 Подписаться
Подписаться