







 MWC 2018
MWC 2018 2018
2018 Computex
Computex
⇣ Содержание
|
Опрос
|
реклама
Самое интересное в новостях
ИИтоги ноября 2024 г.: неужто чижик?

Источник: ИИ-генерация на основе модели FLUX.1 ⇡#Нужно больше золотаИскусственный интеллект — дорогое удовольствие. Настолько дорогое, что воротилы с Уолл-стрит ещё летом порицали большую ИИ-четвёрку — Amazon, Microsoft, Meta* и Alphabet — за чрезмерное, по мнению матёрых финансистов, расточительство. Действительно, вместо того, чтобы — как положено приличным акционерным обществам эпохи развитого монетаризма — выводить полученную прибыль целиком в качестве дивидендов, а на операционные расходы и дальнейшее развитие занимать средства у банков и инвестфондов (которые, в свою очередь, с охотой предложат наилучшие условия заёмщику, чьи акции стремительно растут), эти бунтари оголтело инвестируют честно заработанные деньги — отнимая их от обескровленных губ стейкхолдеров, по сути, — непосредственно в ИИ-разработки, ИИ-ЦОДы и прочую связанную с генеративными моделями активность. И вот теперь, как сообщает Bloomberg, совокупные капитальные затраты большой ИИ-четвёрки ещё более увеличатся вопреки всем предостережениям биржевиков, превзойдя по итогам только текущего года, по самой скромной оценке, 200 млрд долл. США (а в 2025-м, глядишь, и до 300 млрд докатятся). Для сравнения: примерно в ту же сумму обойдётся вся растянутая на годы программа модернизации наземной компоненты американских стратегических ядерных сил (смена 400 развёрнутых и 50 находящихся в резерве ракет Minuteman III на 400 + 250 новых Sentinel, плюс переоборудование боеголовок W78 и W87 в универсальные W87-1). Исполнительные директора ведущих цифровых компаний планеты успокаивают акционеров напоминаниями о том, что долгосрочные инвестиции в инфраструктуру — это нормально (те же дата-центры строятся не за месяц и даже не за полгода, — плюс ещё необходимо позаботиться об их энергообеспечении), и что сегодняшние вложения непременно себя окупят уже в среднесрочной перспективе. И судя по тому, что бумаги пресловутой Meta* выросли в цене на 60% с начала года, инвесторы, по меткому замечанию одного из биржевых экспертов, которого цитирует Bloomberg, «уже достаточно приучены к тому, чтобы воспринимать спокойствие как добродетель». 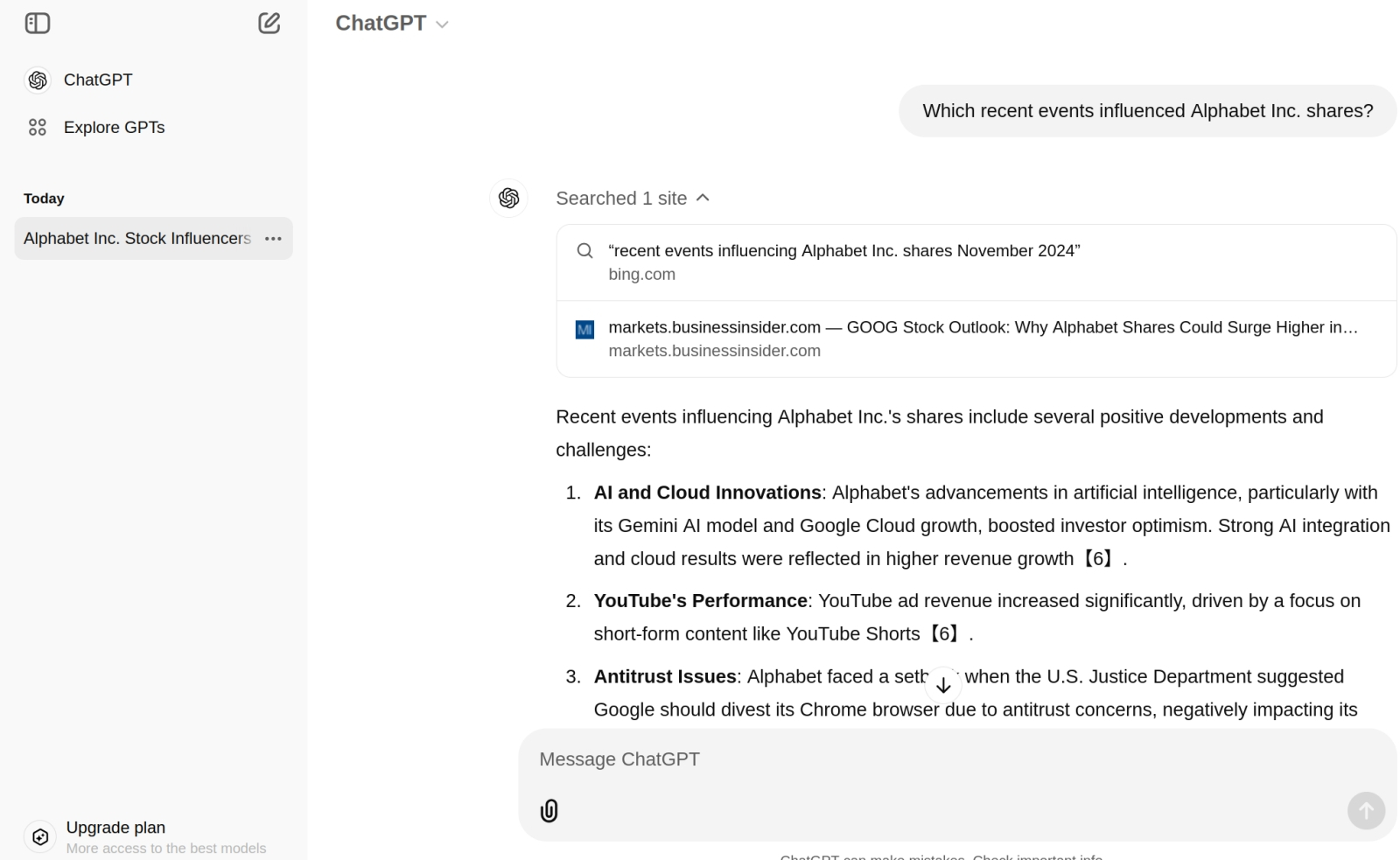
«Вы что же, и гуглить за меня теперь будете?» — «Ага!» (Источник: скриншот сайта ChatGPT.com) ⇡#Искать, ИИ! Искать!В середине нынешнего года OpenAI активно испытывала поисковую генеративную машину SearchGPT — однако ближе к его концу объявила, что как отдельный продукт выводить её на рынок не будет, а просто интегрирует поисковые возможности в ChatGPT. Сперва оценить их смогли платные подписчики сервиса, а ближе к середине ноября и все прочие его пользователи. Умный бот сам определяет, достаточно ли для ответа на очередной запрос тех данных, на которых он был исходно натренирован, или же требуется задействовать веб-поиск. Для подтверждения актуальности предлагаемой информации ответы сопровождаются ссылками на использованные онлайн-источники. Новая функциональность чат-бота призвана обеспечить ему превосходство над специализированными поисковиками, такими как Google, Bing или Perplexity. Причём представители OpenAI упомянули о «поиске информации в Сети в реальном масштабе времени» и о «прямом сотрудничестве с новостными агентствами и другими поставщиками данных», то есть в ChatGPT действительно интегрирована специально разработанная поисковая машина, и он не переадресует пользовательские запросы какому-то внешнему поисковику (хотя Bing, принадлежащий Microsoft, с которой у OpenAI крайне тесные связи, назван «важным инструментом» организации поиска, но не единственным и даже не ключевым). Машина эта, как теперь известно, базируется на специально дотренированной версии GPT-4o и активно использует сторонние источники данных — включая уже упомянутые новостные агентства, такие как The Associated Press, Reuters, Axel Springer, Condé Nast, Hearst, Dotdash Meredith, Financial Times, News Corp., Le Monde, The Atlantic, Time и Vox Media. Глава разработчика ChatGPT Сэм Альтман (Sam Altman), отвечая на вопросы пользователей Reddit о новых возможностях бота, заявил, что и вовсе «мечтает о будущем, в котором поисковый запрос сможет динамически порождать кастомизированную веб-страницу с искомым ответом». Все предпосылки к воплощению его мечты имеются: по крайней мере, сами веб-сёрферы к этому готовы. Как раз в ноябре, если верить приведённым Similarweb и Statscounter оценкам, аудитории браузера Chrome и умного бота ChatGPT практически сравнялись: 3,45 млрд активных пользователей в месяц у первого, 3,7 млрд регулярных посетителей у второго. ![Тони Фейделл (справа) поясняет ведущему, что в 2011 г. широкие массы были ещё далеки от позитивного восприятия ИИ: «Мы не могли говорить об ИИ, о машинном обучении [когда начинали продвигать свои умные термостаты], потому что народ дико этого опасался: „ИИ в моём доме? Ещё чего!“ А теперь? Теперь все хотят ИИ, и повсюду!» (источник: TechCrunch)](https://cdn.3dnews.ru/assets/external/illustrations/2024/12/03/1114890/ai-oct24-03.jpg)
Тони Фейделл (справа) поясняет ведущему, что в 2011 г. широкие массы были ещё далеки от позитивного восприятия ИИ: «Мы не могли говорить об ИИ, о машинном обучении [когда начинали продвигать свои умные термостаты], потому что народ дико этого опасался: „ИИ в моём доме? Ещё чего!“ А теперь? Теперь все хотят ИИ, и повсюду!» (Источник: TechCrunch) ⇡#Некоторые галлюцинируют, а некоторые такИскусственный интеллект не сводится к одному только генеративному, что оглушительно выстрелил благодаря ChatGPT почти ровно два года назад, — и об этом в ноябре 2024-го в ходе конференции TechCrunch Disrupt в Сан-Франциско напомнил в очередной раз Тони Фейделл (Tony Fadell), один из главных дизайнеров iPod, основатель Nest Labs (той самой, что в 2011 г. вывела на американский рынок «умные» термостаты) и активный инвестор в высокотехнологичные проекты: «Я пятнадцать лет занимался ИИ, народ, ей-ей. Я вам не Сэм Альтман, ясно?» Большие языковые модели (БЯМ), лежащие в основе практически всех наиболее громких на сегодня ИИ-проектов, имеют полное право на существование, но — подчеркнул Фейделл — лишь в ограниченных пределах, о которых и разработчикам, и пользователям необходимо постоянно помнить: «БЯМ пытаются объять необъятное — потому что мы, знаете ли, очень уж хотим научную фантастику сделать былью… БЯМ — всезнайки, а я терпеть не могу всезнаек». Помимо критики всеобщей увлечённости ChatGPT-подобными ботами, равно как и их разработчиков — порой наивных, порой искренне чрезмерно увлечённых, а порой просто расчётливо стригущих купоны на безудержном хайпе, — «папаша iPod» предложил и позитивную программу избавления от недостатков БЯМ, и в первую очередь от неизбежных просто по самой их природе галлюцинаций. Фейделл горячо ратует за ИИ-агенты — нейросетевые модели с сознательно зауженными возможностями, натренированные на специфичных для каждой отдельной задачи наборах данных и функционально более объяснимые (аналитически постижимые), чем глубокие сети с множественными слоями свёрток, интегрированными трансформерами и прочей цифровой машинерией. Которая, бесспорно, как-то работает — результаты ведь налицо, и часто очень даже достойные, — но как именно каждый удачный либо неудачный результат получается, понять во всех деталях невозможно. «Если я нанимаю ИИ-агента, чтобы он обучал меня, или работал для меня вторым пилотом, или вовсе заменил меня на рабочем месте, я совершенно точно хочу знать, чтó это за штука». В противном случае, продолжает Фейделл, использующие ИИ компании ставят свою репутацию в полную зависимость от «дерьмовой технологии» (так и сказал — «some bull$#!7 technology») — и даже не в состоянии вообразить, насколько серьёзными проблемами им это в перспективе грозит. 
В 1884 г. сопровождать на работу штрейкбрехеров, нанятых взамен затеявших стачку рабочих в городе Бактел, штат Огайо, пришлось вооружённым сотрудникам детективного агентства Пинкертона. В 2024-м для подмены бастующих в офисах достаточно функционирующего широкополосного канала, — и умные боты уже готовы примерять на себя белые воротнички; по крайней мере, глава Perplexity в этом уверен (источник: Wikimedia Commons) ⇡#Кожаные мешки — с вещами на выход!В начале ноября технические сотрудники New York Times объявили забастовку — с вполне разумными (по крайней мере, на сторонний незаинтересованный взгляд) требованиями, которые включали повышение окладов всего-то на 2,5% и ограничение (ныне, кстати, и так действующее — забастовщики захотели, чтобы оно стало перманентным) продолжительности обязательного появления в офисе двумя рабочими днями в неделю максимум. Дело для США обычное: профсоюзы в стране традиционно сильны, и особенную активность они проявляют в последние пару лет — на фоне явного наступления ИИ на самые различные сферы занятости «белых воротничков». Однако на сей раз работодатели получили нежданное подкрепление: глава ИИ-поисковика Perplexity Аравинд Шринивас (Aravind Srinivas) предложил услуги своих умных ботов для замещения вышедших на стачку ИТ-специалистов. Ситуацию дополнительно накалил тот факт, что объявлена была забастовку буквально за пару дней до президентских выборов, — можно только посочувствовать владельцам и менеджменту новостного издания, вся активность которого оказалась поставлена под удар в столь неподходящий момент. И это притом, что ранее, не далее как в октябре, адвокаты New York Times направляли в адрес Perplexity официальное письмо с предложением прекратить незаконную, на их взгляд, деятельность по использованию материалов издания для обучения своего ИИ. Похоже, классовая солидарность явно сильнее преходящего конфликта бизнес-интересов! А вот разработчики из игрового подразделения стримингового сервиса Netflix даже побастовать не успели: после увольнения 35 сотрудников буквально культовой студии, подарившей миру вселенные Halo и God of War, руководство компании заявило о намерении далее развивать это направление уже с использованием искусственного интеллекта. Бывший глава игрового подразделения Netflix Майк Верду (Mike Verdu), который ныне носит титул вице-президента по генеративному ИИ для игр (VP of GenAI for Games), назвал нынешнюю ситуацию в этой области «единственным при жизни целого поколения переломным моментом». Именно генеративные модели, как рассчитывает топ-менеджер, ускорят создание и внедрение в готовые продукты «нового геймерского опыта» — за которым с вожделением потянутся игроки. Солидарен с этой точкой зрения и вездесущий Илон Маск (Elon Musk), стартап xAI которого вот-вот «запустит игровую ИИ-студию, чтобы сделать игры снова великими». Только кто, спрашивается, будет трудиться в этой студии — люди или боты? Согласно опубликованной в ноябре оценке CompTIA, число открытых вакансий для разработчиков ПО в США упало на 56% от уровня 2019 г., а «джунов» без опыта и вовсе требуется на 67% меньше, чем пятью годами ранее. И это, кстати говоря, наиболее пугающая экспертов тенденция: экономя в моменте на найме малоквалифицированных программистов (которых ИИ как раз способен заменить блестяще), работодатели прерывают связь поколений. Не принятые в штат «джуны» не будут расти, перенимая опыт от «мидлов», и уже через несколько лет может сложиться крайне неприятная ситуация — когда для решения даже средних по сложности задач не будет в достатке ни кожаных мешков (их останется банально мало, с нужными-то компетенциями), ни ИИ. Если тот, конечно, не совершит в обозримой перспективе качественного рывка — во что, надо сказать, визионеры вроде Альтмана по-прежнему верят свято. 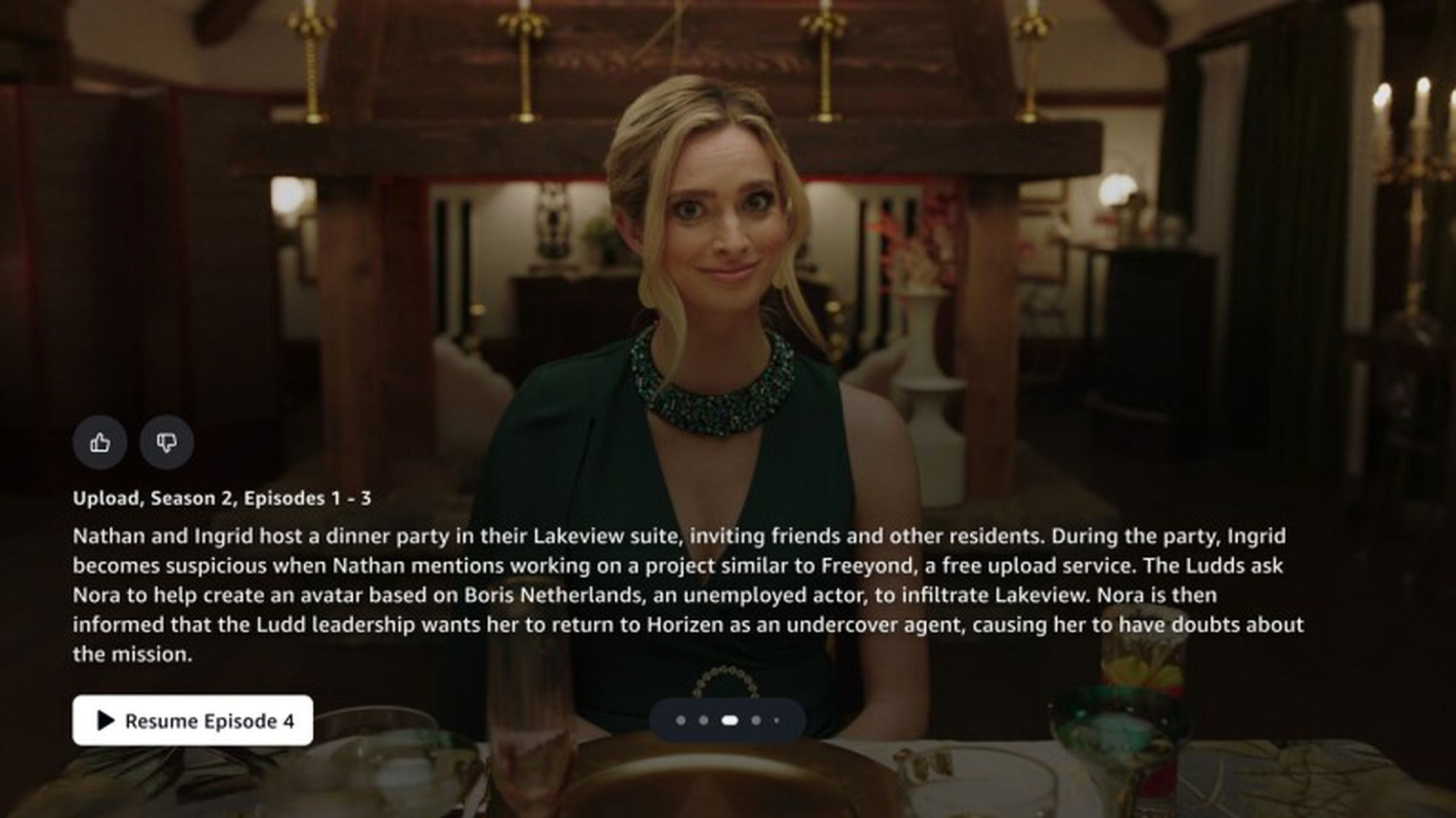
Запамятовали, кто эта милая барышня, что взирает на сидящего напротив с таким неподдельным интересом, будто высчитывает, когда уже начнёт действовать подсыпанный ему в пончики цианид? X-Ray Recaps напомнит! (Источник: Amazon) ⇡#Бот в помощьВпрочем, генеративные модели — как и любой изобретённый человечеством инструмент — могут приносить как вред, так и пользу; всё зависит от того, каким образом их применять. Вот клиенты Amazon Prime Video, к примеру, получили в ноябре возможность не просматривать самостоятельно утомительно долгие сериалы, за доступ к которым они платят, а привлекать для составления краткого резюме заинтересовавшего их ролика умный инструмент X-Ray Recaps (пребывающий пока, правда, в состоянии бета-версии и работающий на данный момент лишь с продукцией Amazon MGM Studios Original). Да и не только ролика: новинка обеспечивает возможность получать краткую выжимку содержимого хоть целых сериальных сезонов, хоть отдельных сцен внутри одной серии — как пожелает зритель (хотя применимость этого термина к пользователю X-Ray Recaps довольно-таки сомнительна). Инструмент опирается не только на звуковую дорожку, но и на видеоряд и на субтитры, если те имеются, — словом, выступает как вполне современная мультимодальная ИИ-модель. Более того, в новую функциональность предусмотрительно встроены «поручни безопасности» (guardrails) — чтобы не проспойлерить слишком уж любопытному пользователю ключевые моменты, но вместе с тем всё-таки предоставить ему довольно информативное и внятное резюме сюжета. А вот в Физтех-школе прикладной математики и информатики Московского физико-технического института (МФТИ) решили практически обратную задачу — создали БЯМ-помощника для генерации сценариев художественных фильмов и сериалов. Получается, человек в этой области уже в недалёком будущем вроде бы как и вовсе окажется не нужен: одна модель напишет сценарий, другая снимет по нему видео, третья составит резюме, — это ж сколько времени и денег получится сэкономить! И не только в сериалостроении, но и в музыкодельческой индустрии: The Beatles (кто-то помнит ещё такую группу, распавшуюся полвека с лишним назад?) как раз в ноябре 2024-го оказались номинированы на премию «Грэмми» — с композицией «Now and Then». Её демозапись до самого последнего времени считалась непригодной для постобработки, но теперь пошла в дело — при содействии натренированной на песнях группы генеративной модели. Бестрепетно применяют ИИ в своей работе и сотрудники Northwell Health, крупнейшей в штате Нью-Йорк медицинской сети с 85-тыс. персоналом: не только для перевода (когда к англоговорящему врачу обращается испаноязычный пациент, например) и упрощения работы с массивом медкарт, но и для консультаций в ходе постановки диагноза. Правда, делается это не совсем гласно: в распоряжении издания 404 Media оказались презентация и записи внутренних чатов работников Northwell Health, — на основании их изучения и стало понятно, насколько активно применяют ИИ под названием AI Hub в этой организации. Помимо помощи с написанием текстов, сортировки анкет соискателей на открытые вакансии, решения различных административных вопросов AI Hub рекомендовано применять для «клинических или близких к клиническим» задач — например, для выявления рака поджелудочной железы (справедливости ради отметим, что диагностика рака генеративными моделями — давно уже не новость). Эксперты предполагают, что факт сокрытия активного использования ИИ медицинским учреждением может быть связан с опасениями по поводу судебных разбирательств — ведь дело касается персональных данных пациентов и потенциальной угрозы их здоровью. Но само намерение Northwell Health активнее задействовать искусственный интеллект в сфере здравоохранения вполне укладывается в русло актуальных тенденций. Обучили ведь разработчики из биотех-лаборатории Neiry совместно с учёными из МГУ самую обычную крысу (Rattus norvegicus), мозг которой через нейроинтерфейс соединён с исполняемой на компьютере генеративной моделью, пользоваться «подсказками от ИИ», чтобы давать корректные ответы на самые разные вопросы, не исключая и медицинских. Чем врачи вида Homo sapiens хуже? 
«Генеративный деобфускатор, ТЫ НЕ ПРОЙДЁШЬ!» (Источник: ИИ-генерация на основе модели FLUX.1) ⇡#Чтобы думать, как код, надо быть кодомПрограммирование в самых разных его аспектах — одна из тех отраслей, для которых генеративный ИИ, как ожидается, подойдёт лучше всего: тут ведь надо порождать текст, воспринимаемый и интерпретируемый другой, менее «умной» машиной. И, как показывает практика, подобные рассуждения не лишены логики: по крайней мере, специалисты из ZeroPath успешно использовали натренированную ими генеративную модель для обнаружения уязвимостей нулевого дня (включая удалённое исполнение кода, обход систем аутентификации, а также небезопасные прямые ссылки на объекты) в целом ряде популярных приложений — как с открытым кодом, так и распространяемых под брендами Netflix, Salesforce, Hulu и т. п. Да, уязвимости эти достаточно просты, но обнаружение их в мегабайтах кода — крайне трудозатратный процесс, если выполняется человеком. Автоматические же алгоритмические сканеры, известные задолго до широкого распространения генеративных моделей, частенько пропускают отличающиеся от стандартных шаблонов уязвимости, — на радость злоумышленникам. ИИ позволяет автоматизировать выявление по крайней мере этих банальных прорех в безопасности, освобождая время и силы биологических экспертов для противодействия более серьёзным вызовам. Кстати, Google от обозначенного ZeroPath тренда тоже не отстаёт: её специализированный БЯМ-агент Big Sleep (на базе Gemini 1.5 Pro), плод сотрудничества подразделений Project Zero и DeepMind, в ноябре своевременно выявил уязвимость для переполнения буфера у очередной предрелизной версии крайне популярной (особенно для онлайн-проектов) СУБД SQLite. Впрочем, и сами реализации ИИ (как ни крути, остающиеся по сути своей программами, исполняемыми на фон-неймановских машинах) не свободны от уязвимостей. Силами команды Protect AI, запустившей первую в мире программу выплаты премий (bug bounty) за обнаружение уязвимостей в системах искусственного интеллекта и машинного обучения huntr, в различных генеративных моделях (по понятной причине в основном с открытым кодом и исполняемых локально — в таких проще выявлять баги) обнаружено уже 34 довольно серьёзных бреши. Те позволяют злоумышленникам выполнять разнообразные действия — от целевых DoS-атак до исполнения произвольного кода на компьютере жертвы. Надо полагать, следующим этапом станет обнаружение уязвимостей в ИИ при помощи ИИ — а там, глядишь, и до практического воплощения машинной рефлексии недалеко! 
«Прекрасно. Следующий вопрос: на ближайшем повороте направо застрял асфальтоукладчик, слева сигналит скорая, перед вами телега с запутавшейся в постромках лошадью, на светофоре загорается зелёный, — ваши действия?» (Источник: ИИ-генерация на основе модели FLUX.1) ⇡#Нет, ИИ, ты не понялДавно уже очевидный для специалистов трюизм — что генеративный ИИ (и не он один, а все действующие на сегодня разработки в сфере машинного обучения) не понимает информации, которую обрабатывает, — лишний раз подтвердили исследователи из Массачусетского технологического института (MIT). Да, сложные модели выдают порой весьма правдоподобные ответы, но никого ведь почему-то не удивляет способность электронной таблицы сортировать данные в определённом столбце по алфавиту, верно? То же самое, по сути, делает и ИИ, только на более сложном уровне и с огромным числом параметров одновременно: он сперва — в процессе обучения — ставит в соответствие некоему информационному примитиву (который для человека — вполне осмысленное слово, имя/название или устойчивое выражение, и за ним — масса воспоминаний и личных ассоциаций, а для машины он же — лишь цифровой токен, не более) многомерный вектор в условном пространстве своих рабочих параметров, а затем производит над такого рода величинами довольно несложные по сути, но крайне трудоёмкие в вычислительном плане операции матричного умножения. В последнее время успешность моделей с трансформерами — которые суть особые вспомогательные нейросети, расширяющие возможность генеративного ИИ воспринимать длинные информационные ряды, — начала склонять ряд комментаторов к допущению, что GPT-4 (особенно в версии «o») и ряд сопоставимых с ним по сложности систем всё-таки могут претендовать на некоторое, пусть и не подлинно человеческое, понимание пропускаемой через них информации. Эту гипотезу и взялись проверить в MIT, предложив генеративной модели две практические задачи: провести условный автомобиль по улицам Нью-Йорка от одной точки до другой — и сыграть в «Отелло», далеко не самую сложную игру с компактным набором внятных правил. Собственно, целью эксперимента и было установить, способна ли система понимать предложенные ей правила, восстанавливая по ним логику функционирования иных, хотя и схожих систем, — или же она даже при наличии трансформеров не более чем Excel-сортировщик, только производящий упорядочение огромной базы данных сразу по множеству неоднозначных параметров. Увы (хотя для кого-то, наверное, всё же ура), соответствующим истине оказалось именно второе предположение. Да, поскольку трансформеры натренированы образовывать связи между далеко отстоящими один от другого информационными блоками (и потому, в частности, модели для ИИ-рисования с трансформерами лучше воспринимают длинные витиеватые подсказки), какая-то картина этих связей в их «сознании» — в виде весов на входах их перцептронов — воспроизводится. Но она соответствует реальной лишь до тех пор, пока от системы требуют воспроизводить нечто в целом адекватное именно тому набору данных, на котором она обучалась. Исследователи приводят такой пример: на полной карте Нью-Йорка (с его строгой прямоугольной планировкой: «на север с юга идут авеню, на запад с востока — стриты», как писал поэт) ИИ великолепно справлялся с задачей проложить маршрут для автомобиля из точки А в точку Б, поскольку обучался на огромном массиве выстраиваемых живыми водителями маршрутов. Но стоило экспериментаторам условно перекрыть всего лишь примерно 1% проездов, как соответствие проложенного маршрута реальности разом упало с почти 100% до 67%. Иными словами, цифровая система не поняла простейших на человеческий взгляд правил — вроде «чтобы объехать перекрытый участок, проследуй на один квартал дальше, поверни там, а потом сделай обратный поворот и вернись на прежнюю трассу». И широко разрекламированные сегодня «рассуждающие» (reasoning) модели — они, увы, лишь имитируют логику рассуждений, не разбираясь в ней как таковой: нечем им пока разбираться. Трансформеры — неплохая заявка на успех, но нужно нечто принципиально иное, чтобы если не убедить исследователей в наличии у ИИ подлинного интеллекта, то хотя бы заставить их крепко усомниться в бесспорности его отсутствия. Тут есть над чем поработать! 
«Крупная распродажа ботов, господа! Рекомендую: поёт, играет, за клерков почту разбирает!» (Источник: ИИ-генерация на основе модели FLUX.1) ⇡#Ничто человеческоеПока отдельные пишипропальщики без устали предрекают скорый крах экономики, которая-де не выдержит замещения десятков и сотен миллионов нынешних «белых воротничков» умными ботами, сами заводчики этих ботов явно не спешат доверять им наиболее ответственную, прекрасно измеримую в плане эффективности и чрезвычайно важную для их бизнеса в целом работу. А именно — продажу самих же этих ботов. Как сообщало в ноябре издание Bloomberg, компания Salesforce, разработчик крайне популярной облачной CRM-системы (стоящий на этом сегменте ИТ-рынка в одном ряду с Oracle, SAP, Google и Microsoft, даром что по условной капитализации далеко от них отстаёт), планирует нанять тысячу сотрудников в придачу к уже находящимся в её штате более чем 72 тыс. — специально для того, чтобы продавать свои генеративные ИИ-агенты. Эти небольшие (по сравнению с универсалами вроде GPT-4o) модели сосредоточены на исполнении ограниченного круга задач без участия человека — и, как правило, делают это лучше (если сравнивать частоту появления галлюцинаций), чем широко известные БЯМ. И такие продажи уже идут довольно бойко — достаточно сказать, что ИИ-агент Agentforce (с доступом, как и все прочие продукты Salesforce, через облако) обходится заказчикам в сумму от 2 долл. США всего лишь за одну сессию взаимодействия с ним. Тем не менее руководство компании явно сочло, что натренировать специализированного ИИ-агента для продажи других таких агентов кожаным мешкам обойдётся дороже (и/или не будет сопоставимо по эффективности), чем нанять тысячу тех же мешков для реализации своего передового продукта. И кстати, просто предоставлять возможность для активации такого продукта на подходящем «железе», не особенно заботясь о том, кто, в каких ситуациях и по какой причине захочет такой услугой воспользоваться, в случае Agentforce явно не вариант. Марк Бениофф (Marc Benioff), старший исполнительный директор и сооснователь Salesforce, не раз критиковал, в частности, Microsoft за вялую организацию продаж её собственных агентов, не особенно стесняясь в выражениях: «Вы только посмотрите, как информацию о Copilot доводят до клиентов, — это же сплошное разочарование!» И действительно, как можно себе представить ИИ-бота, ведущего эффективные переговоры с потенциальным заказчиком в ресторане — ну или хотя бы в бане? Так что, пока принятие решений о покупках такого рода не передоверят генеративным же моделям, живым продажникам беспокоиться явно не о чем. 
А по-русски сможет? А «Мурку»?! (Источник: Microsoft) ⇡#Даже «Блокнот», Карл!Хотя в Microsoft Office ИИ-возможности, похоже, станут доступны пользователям бесплатно (правда — по крайней мере, пока — в ограниченном числе стран), для обращения к генеративному помощнику в старом добром «Блокноте» (Notepad) почти наверняка придётся раскошелиться. Всё верно, это не опечатка: ноябрьский блог самой компании-разработчика подтверждает, что и Notepad, и Paint — два некогда самых простых и доступных интерактивных творческих инструмента в комплекте поставки этой ОС — обогатятся вскоре ИИ-функциональностью. Для базового графического редактора это будет «умное заполнение» (generative fill), благодаря которому, к примеру, на многим изрядно набившем оскомину зелёном холмистом лужке стандартных обоев Windows XP можно будет выделить прямоугольник, написать в поле ввода подсказки «medieval castle» — и получить там органично вписанный в пейзаж премиленький замок с башенками. Появится и обратный этому инструмент — «умный ластик» (generative erase), убирающий с картинки ненужный объект и дорисовывающий на его месте правдоподобный участок фона. «Блокнот» же в грядущей версии 11.2410.17.0 сможет с использованием генеративного ИИ перефразировать и редактировать введённый текст (функция Rewrite) — сокращать или удлинять его, менять тон и формат изложения. Опция эта в предварительном варианте будет доступна на первых порах лишь пользователям в США, Франции, Великобритании, Канаде, Италии и Германии — и лишь при условии входа в систему с учётной записью Microsoft. На этом фоне как-то даже теряется сообщение о новой возможности ИИ-помощника Claude компании Anthropic — тот теперь способен «имитировать уникальный стиль пользователя», помогая ему в создании текстов. Ещё бы он не был на такое способен, если даже «Блокнот» сумел! 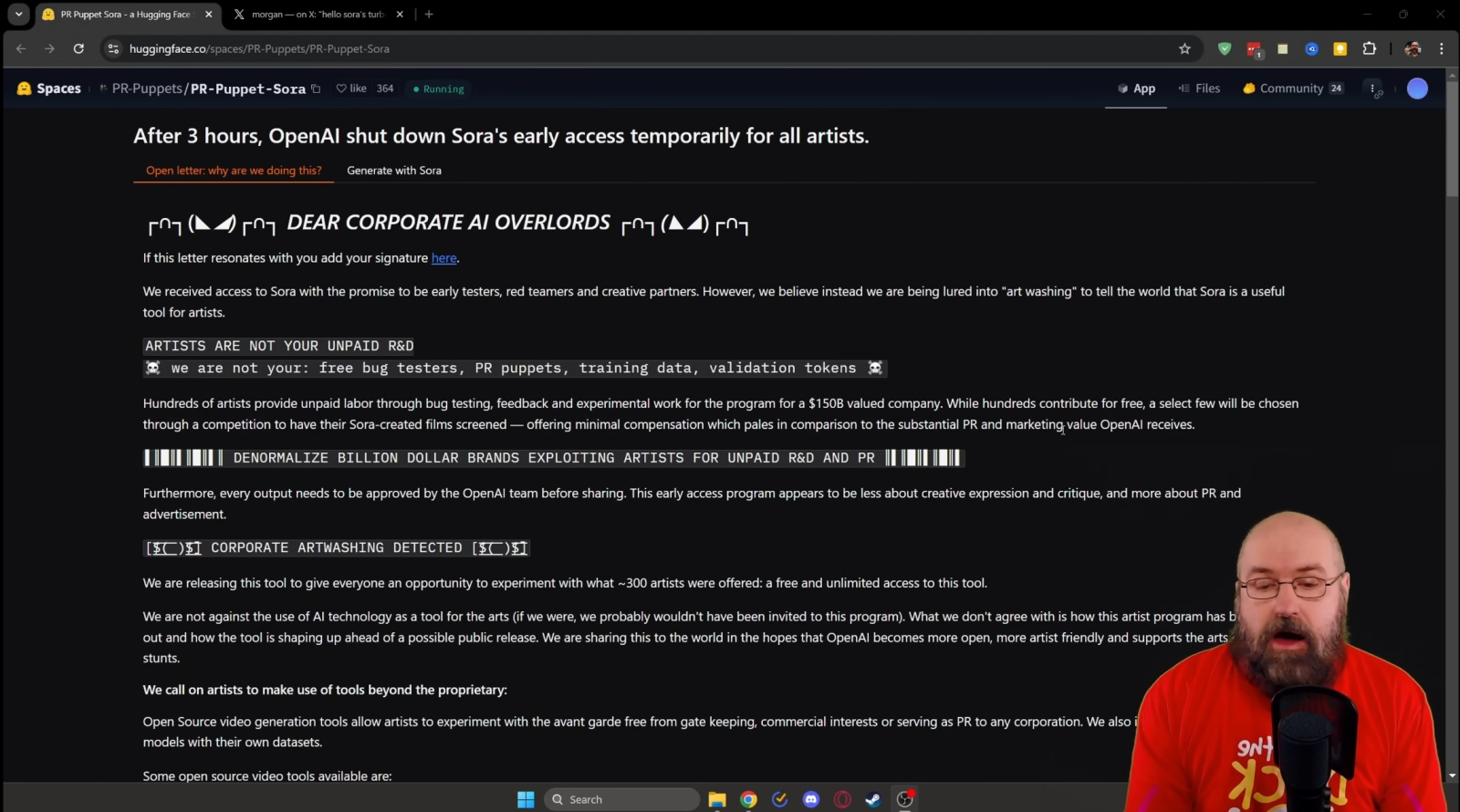
Манифест протестующих против «корпоративного рабства» и «отмывания искусства» участников закрытого тестирования Sora доступен в посвящённых этому скандалу видеоблогах — как и ролики, сделанные оперативно воспользовавшимися ситуацией энтузиастами (источник: скриншот сайта YouTube) ⇡#Вынос Sora из избыOpenAI уже так долго работает в полузакрытом режиме над своим генератором видео по подсказкам Sora, что ждать хоть каких-то ощутимых результатов становится невмоготу даже самим участникам кулуарного тестирования новой модели. Ближе к концу ноября на сайте Hugging Face появился API для подключения к работающей на серверах OpenAI версии Sora — причём слили возможность доступа, по некоторым данным, сами же участники этого ограниченного тестирования с использованием выделенных им разработчиком аутентификационных токенов. Как бы то ни было, на короткое время — пока в самой компании не спохватились — буквально каждый, обладавший этой информацией, смог подключиться через API к умному генератору видео и совершенно бесплатно получить по краткой текстовой подсказке десятисекундный ролик в разрешении до 1080p. Организаторы утечки сопроводили свои действия кратким манифестом, в котором выразили несогласие с «двурушничеством» (duplicity) OpenAI — которая якобы, с одной стороны, привержена сохранению прав творцов видеоконтента и заботится о законности сбора данных для тренировки своей модели, а с другой — попросту занимается «отмыванием искусства» (art washing), когда под прикрытием полученных от ряда творцов разрешений на использование их контента формируется куда более обширная база, как раз и позволяющая добиваться наилучших результатов с наименьшими финансово-организационными затратами. Главный специалист по продуктам OpenAI Кевин Вейл (Kevin Weil) заявил, что действительно подзатянувшийся выход Sora на рынок связан с «необходимостью довести модель до совершенства, правильным образом настроить её безопасность и возможности имитации реальных лиц [тут явно идёт речь о внедрении guardrails против создания дипфейков знаменитостей], а также отладить масштабирование с расчётом на самое широкое использование». Последний аргумент — вовсе не пустая отговорка: та версия генеративной видеомодели, что была показана на одной из самых ранних своих стадий ещё в феврале текущего года, тратила более 10 минут на создание 1-минутного ролика — и не отличалась высокой самосогласованностью (грубо говоря, масть собаки, катящейся в кадре на скейте, за минуту экранного времени легко могла несколько раз поменяться, — и хорошо, если только масть, а не порода). Сейчас, судя по всему, через выложенный API энтузиасты получили ненадолго доступ к более поздней разработке, а именно к скоростной турборедакции Sora, — и, надо полагать, в недрах OpenAI продолжается также разработка основной модели. Именно выхода последней на рынок и опасаются сильнее всего независимые малобюджетные видеостудии: соперничать с ней, если она достигнет заявленных высот функциональности, кому-то вне Голливуда будет крайне сложно. 
Источник: ИИ-генерация на основе модели FLUX.1 ⇡#Рыба? Мясо? Соевый шрот?«ИИ — это прекрасно; он помогает», — говорят одни. «Чудовищно! — восклицают другие — ИИ портит всё, к чему его ни приложи!» Есть, однако, ситуации, в которых так сходу и не понять, чего от применения генеративных моделей в той или иной области больше, добра или худа, — и такое складывается впечатление, что возникают подобные неопределённости всё чаще. Вот, к примеру, результаты исследования платформы, помогающей соискателям, — Resume Genius: среди 1 тысячи ищущих работу в США специалистов 69% сомневаются в способности ИИ повысить производительность их труда на рабочем месте. Лишь 34% опасаются, что умный бот или иная реализация модной генеративной модели целиком и полностью примет на себя их рабочие обязанности, и всего только 30% страшатся негативного влияния ИИ на уровни конкуренции и зарплат по их направлениям деятельности. Интересно, что выявленная картина практически не зависит от возраста респондентов: не только завершающие свою карьеру «бумеры», но и представители «поколения Z» в целом не рассматривают искусственный интеллект как реальную опасность для своей занятости. Мало того: проведённое ещё летом исследование Upwork показало, что 77% сотрудников, которых начальство принудило использовать ИИ-инструменты в работе, заметили, что вследствие этого их производительность снизилась. Амбивалентно как-то всё выходит. 
Источник: ИИ-генерация на основе модели FLUX.1 ⇡#Железно!Чтобы ИИ стал умнее, надо построить дата-центры помощней и набить их ещё бóльшим количеством самых передовых графических ускорителей, верно? До самого недавнего времени так, похоже, значительная доля принимающих в ИТ-индустрии решения людей и рассуждала, пока как раз к концу нынешнего ноября не начали особенно ощутимо проявляться признаки торможения взятого пару лет назад высокого темпа развития ИИ. Экстенсивный рост возможностей генеративных моделей, прямо пропорциональный числу адаптеров Nvidia в серверных стойках, завершается — об этом говорится в материале Financial Times. Статья исполнена искреннего беспокойства о перспективах этой (до недавних пор крайне узкой) отрасли ИТ-рынка, в которую вдруг хлынули какие-то совершенно невообразимые инвестиции — с явной надеждой инвесторов на ещё более умопомрачительные прибыли. А перспективы эти туманны: не зря Илья Суцкевер (Ilya Sutskever), один из сооснователей OpenAI, прямо назвал эпохой масштабирования уже минувшие 2010-е годы — тогда как теперь, по его мнению, для ИИ-сектора вновь наступает пора «открытий и изумления». Изумления, в частности, перед тем, что накопленных человечеством данных для обучения ещё более крупных моделей уже откровенно недостаёт, что подлинно «рассуждающие» генеративные модели так и не появились, а потребности заказчиков во всё новых серверных ускорителях никак не в силах удовлетворить глобальная чипмейкерская индустрия. Wall Street Journal приводит слова главы Nvidia Дженсена Хуанга (Jensen Huang), который красочно обозначил масштабы аппаратного бедствия (точнее, для кого-то бедствия, а как раз его компания прекрасно себя при этом чувствует): если современный крупнейший вычислительный узел для ИИ, такой как построенный Маском Неугомонным Colossus, нуждается в сотне тысяч чипов Nvidia Hopper, то для тренировки моделей следующего поколения потребуется также около 100 тыс. ускорителей, только уже архитектуры Blackwell. «Это примерно даёт представление о том, куда движется индустрия», — скромно отметил глава компании, квартальная выручка которой за два года ИИ-бума выросла с 7 млрд до 35 млрд долл. И, надо полагать, сокращаться она начнёт ещё очень нескоро, невзирая на все связанные с ИИ-отраслью неопределённости. ________________ * Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»
⇣ Содержание
Если Вы заметили ошибку — выделите ее мышью и нажмите CTRL+ENTER.
|
© 1997—2025 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews. kz
![]()
![]()





